In diesem Dokument erfahren Sie, wie Sie mit Data Science in großem Umfang mit R inGoogle Cloudloslegen können. Diese Anleitung richtet sich an Personen, die bereits mit R und Jupyter-Notebooks sowie mit SQL vertraut sind.
In diesem Dokument geht es um die Durchführung einer explorativen Datenanalyse mit Vertex AI Workbench-Instanzen und BigQuery. Den zugehörigen Code finden Sie in einem Jupyter Notebook auf GitHub.
Übersicht
R ist eine der am häufigsten verwendeten Programmiersprachen für die statistische Modellierung. Sie hat eine große und aktive Community von Data Scientists und ML-Experten. Mit über 20.000 Paketen im Open-Source-Repository des Comprehensive R Archive Network (CRAN) verfügt R über Tools für alle statistischen Datenanalyseanwendungen, ML und Visualisierung. R ist in den letzten zwei Jahrzehnten wegen der Ausdruckskraft seiner Syntax und aufgrund seiner umfassenden Daten- und ML-Bibliotheken stetig gewachsen.
Als Data Scientist möchten Sie möglicherweise wissen, wie Sie Ihr Know-how mit R nutzen können und wie Sie von den Vorteilen der skalierbaren, vollständig verwalteten Cloud-Dienste für Data Science profitieren können.
Architektur
In diesem Walkthrough verwenden Sie Vertex AI Workbench-Instanzen als Data-Science-Umgebungen zur Durchführung einer explorativen Datenanalyse. Sie verwenden R mit Daten, die Sie in dieser Anleitung aus BigQuery, dem serverlosen, hoch skalierbaren und kostengünstigen Cloud Data Warehouse von Google, extrahieren. Nachdem Sie die Daten analysiert und verarbeitet haben, werden die transformierten Daten in Cloud Storage für weitere potenzielle ML-Aufgaben gespeichert. Dieser Ablauf wird im folgenden Diagramm dargestellt:

Beispieldaten
Die Beispieldaten für dieses Dokument stammen aus dem BigQuery-Dataset „New York City Taxi Trips“.
Dieses öffentliche Dataset enthält Informationen zu den Millionen von Taxifahrten, die jedes Jahr in New York City stattfinden. In diesem Dokument verwenden Sie die Daten aus dem Jahr 2022, die sich in der Tabelle bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022 in BigQuery befinden.
Der Schwerpunkt dieses Dokuments liegt auf EDA und Visualisierungen mit R und BigQuery. In diesem Dokument wird beschrieben, wie Sie ein ML-Zielvorhaben einrichten, um den Betrag einer Taxifahrt (den Betrag vor Steuern, Gebühren und anderen Extras) anhand einer Reihe von Faktoren zur Fahrt vorherzusagen. Die eigentliche Modellerstellung wird in diesem Dokument nicht behandelt.
Vertex AI Workbench
Vertex AI Workbench ist ein Dienst, der eine integrierte JupyterLab-Umgebung mit den folgenden Funktionen bietet:
- Bereitstellung mit nur einem Klick. Mit einem einzigen Klick können Sie eine JupyterLab-Instanz starten, die mit den neuesten Frameworks für maschinelles Lernen und Data-Science vorkonfiguriert ist.
- Nach Bedarf skalierbar. Sie können mit einer kleinen Maschinenkonfiguration beginnen, z. B. 4 vCPUs und 16 GB RAM, wie in diesem Dokument. Wenn Ihre Daten für eine Maschine zu groß werden, können Sie sie mit CPUs, RAM und GPUs hochskalieren.
- Google Cloud integration. Vertex AI Workbench-Instanzen sind in Google Cloud -Dienste wie BigQuery eingebunden. Diese Integration vereinfacht den Weg von der Datenaufnahme zur Vorverarbeitung und Exploration.
- Nutzungsbasierter Tarif. Es gibt keine Mindestgebühren oder Vorabverpflichtungen. Weitere Informationen finden Sie unter Preise für Vertex AI Workbench. Sie zahlen auch für die Google Cloud Ressourcen, die Sie in den Notebooks verwenden, z. B. BigQuery und Cloud Storage.
Notebooks für Vertex AI Workbench-Instanzen werden auf Deep Learning VM Images ausgeführt. In diesem Dokument wird das Erstellen einer Vertex AI Workbench-Instanz mit R 4.3 unterstützt.
Mit R in BigQuery arbeiten
BigQuery erfordert keine Infrastrukturverwaltung, sodass Sie sich darauf konzentrieren können, aussagekräftige Erkenntnisse zu gewinnen. Sie können große Datenmengen in umfangreichen Projekten analysieren und Datasets mithilfe der umfassenden SQL-Analysefunktionen von BigQuery auf ML vorbereiten.
Sie können bigrquery, eine Open-Source-R-Bibliothek, verwenden, um BigQuery-Daten mit R abzufragen. Das bigrquery-Paket bietet die folgenden Abstraktionsebenen zusätzlich zu BigQuery:
- Die Low-Level-API bietet Thin Wrapper über die zugrunde liegende BigQuery REST-API.
- Die DBI-Schnittstelle umschließt die Low-Level-API und führt dazu, dass die Arbeit mit BigQuery ähnlich verläuft wie mit jedem anderen Datenbanksystem. Diese Ebene eignet sich insbesondere dann, wenn Sie SQL-Abfragen in BigQuery ausführen oder weniger als 100 MB hochladen möchten.
- Mit der Schnittstelle dbplyr können Sie BigQuery-Tabellen wie speicherinterne Datenframes verarbeiten. Dies ist die praktischste Ebene, wenn Sie keine SQL-Abfrage schreiben möchten, aber dbplyr sie für Sie schreiben soll.
In diesem Dokument wird die Low-Level-API aus „bigrquery“ verwendet, ohne dass DBI oder dbplyr erforderlich ist.
Ziele
- Vertex AI Workbench-Instanz mit R-Unterstützung erstellen.
- Daten aus BigQuery mit der R-Bibliothek "bigrquery" abfragen und analysieren.
- Daten für ML in Cloud Storage vorbereiten und speichern.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- BigQuery
- Vertex AI Workbench instances. You are also charged for resources used within notebooks, including compute resources, BigQuery, and API requests.
- Cloud Storage
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweis
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Rufen Sie in der Google Cloud Console die Seite Workbench auf.
Klicken Sie auf dem Tab Instanzen auf Neu erstellen.
Klicken Sie im Fenster Neue Instanz auf Erstellen. Übernehmen Sie für diese Anleitung alle Standardwerte.
Das Starten der Vertex AI Workbench-Instanz kann 2 bis 3 Minuten dauern. Wenn sie fertig ist, wird die Instanz automatisch im Bereich Notebook-Instanzen aufgeführt und neben dem Instanznamen wird der Link JupyterLab öffnen angezeigt. Wenn der Link zum Öffnen von JupyterLab nach einigen Minuten nicht in der Liste angezeigt wird, aktualisieren Sie die Seite.
Klicken Sie in der Instanzliste auf Jupyterlab öffnen. Dadurch wird die JupyterLab-Umgebung in einem anderen Tab in Ihrem Browser geöffnet.
Klicken Sie in der JupyterLab-Umgebung auf New Launcher (Neuer Launcher) und dann auf dem Tab Launcher auf Terminal.
Installieren Sie R im Terminalbereich:
conda create -n r conda activate r conda install -c r r-essentials r-base=4.3.2Geben Sie bei der Installation jedes Mal, wenn Sie zum Fortfahren aufgefordert werden,
yein. Die Installation kann einige Minuten dauern. Wenn die Installation abgeschlossen ist, sieht die Ausgabe in etwa so aus:done Executing transaction: done ® jupyter@instance-INSTANCE_NUMBER:~$Dabei ist INSTANCE_NUMBER die eindeutige Nummer, die Ihrer Vertex AI Workbench-Instanz zugewiesen ist.
Nachdem die Befehle im Terminal ausgeführt wurden, aktualisieren Sie die Browserseite und öffnen Sie den Launcher, indem Sie auf Neuer Launcher klicken.
Auf dem Tab „Launcher“ werden Optionen zum Starten von R in einem Notebook oder in der Konsole sowie zum Erstellen einer R-Datei angezeigt.
Klicken Sie auf den Tab Terminal und klonen Sie dann das GitHub-Repository vertex-ai-samples:
git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.gitWenn der Befehl ausgeführt ist, wird der Ordner
vertex-ai-samplesim Dateibrowserbereich der JupyterLab-Umgebung angezeigt.Öffnen Sie im Dateibrowser
vertex-ai-samples>notebooks>community>exploratory_data_analysis. Das Notebookeda_with_r_and_bigquery.ipynbwird angezeigt.Öffnen Sie im Dateibrowser das Notebook
eda_with_r_and_bigquery.ipynb.In diesem Notebook wird die explorative Datenanalyse mit R und BigQuery beschrieben. Im restlichen Teil dieses Dokuments arbeiten Sie im Notebook und führen den Code aus dem Jupyter-Notebook selbst aus.
Prüfen Sie die R-Version, die im Notebook verwendet wird:
versionIm Feld
version.stringin der Ausgabe sollteR version 4.3.2angezeigt werden, das Sie im vorherigen Abschnitt installiert haben.Prüfen Sie, ob die erforderlichen R-Pakete in der aktuellen Sitzung verfügbar sind, und installieren Sie sie gegebenenfalls:
# List the necessary packages needed_packages <- c("dplyr", "ggplot2", "bigrquery") # Check if packages are installed installed_packages <- .packages(all.available = TRUE) missing_packages <- needed_packages[!(needed_packages %in% installed_packages)] # If any packages are missing, install them if (length(missing_packages) > 0) { install.packages(missing_packages) }Laden Sie die erforderlichen Pakete:
# Load the required packages lapply(needed_packages, library, character.only = TRUE)Authentifizieren Sie
bigrquerymit Out-of-Band-Authentifizierung:bq_auth(use_oob = True)Legen Sie den Namen des Projekts fest, das Sie für dieses Notebook verwenden möchten, indem Sie
[YOUR-PROJECT-ID]durch einen Namen ersetzen:# Set the project ID PROJECT_ID <- "[YOUR-PROJECT-ID]"Legen Sie den Namen des Cloud Storage-Bucket fest, in dem Ausgabedaten gespeichert werden sollen. Ersetzen Sie dazu
[YOUR-BUCKET-NAME]durch einen global eindeutigen Namen:BUCKET_NAME <- "[YOUR-BUCKET-NAME]"Legen Sie die Standardhöhe und ‑breite für Diagramme fest, die später im Notebook generiert werden:
options(repr.plot.height = 9, repr.plot.width = 16)Erstellen Sie eine BigQuery-SQL-Anweisung, die einige mögliche Vorhersagen und die Zielvorhersagevariable für eine Stichprobe von Fahrten extrahiert. Mit der folgenden Abfrage werden einige Ausreißer oder unsinnige Werte in den Feldern herausgefiltert, die für die Analyse eingelesen werden.
sql_query_template <- " SELECT TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes, passenger_count, ROUND(trip_distance, 1) AS trip_distance_miles, rate_code, /* Mapping from rate code to type from description column in BigQuery table schema */ (CASE WHEN rate_code = '1.0' THEN 'Standard rate' WHEN rate_code = '2.0' THEN 'JFK' WHEN rate_code = '3.0' THEN 'Newark' WHEN rate_code = '4.0' THEN 'Nassau or Westchester' WHEN rate_code = '5.0' THEN 'Negotiated fare' WHEN rate_code = '6.0' THEN 'Group ride' /* Several NULL AND some '99.0' values go here */ ELSE 'Unknown' END) AS rate_type, fare_amount, CAST(ABS(FARM_FINGERPRINT( CONCAT( CAST(trip_distance AS STRING), CAST(fare_amount AS STRING) ) )) AS STRING) AS key FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` /* Filter out some outlier or hard to understand values */ WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) LIMIT %s "Die Spalte
keyist eine generierte Zeilen-ID, die auf den verketteten Werten der Spaltentrip_distanceundfare_amountbasiert.Führen Sie die Abfrage aus und rufen Sie dieselben Daten als speicherinternes Tibble ab, das einem Dataframe ähnelt.
sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) taxi_trip_data <- bq_table_download( bq_project_query( PROJECT_ID, query = sql_query ) )Die abgerufenen Ergebnisse anzeigen:
head(taxi_trip_data)Die Ausgabe ist eine Tabelle, die dem folgenden Bild ähnelt:
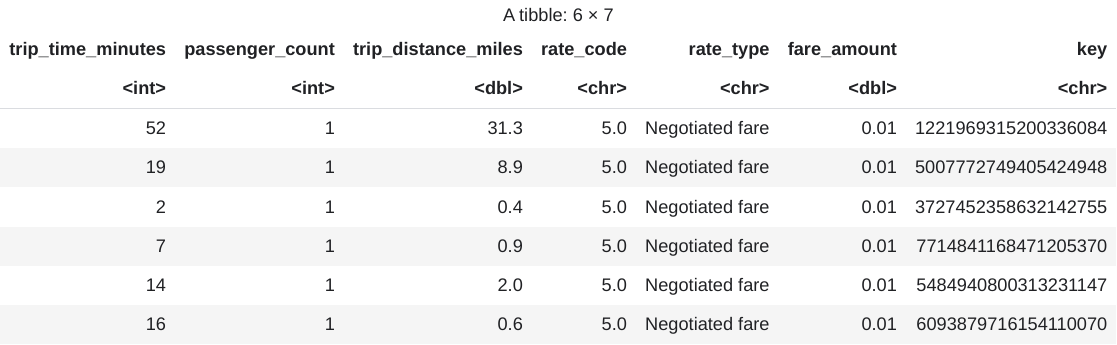
Die Ergebnisse enthalten die folgenden Spalten mit Fahrtdaten:
trip_time_minutes– Ganzzahlpassenger_count– Ganzzahl- Double von
trip_distance_miles rate_codeZeichenrate_typeZeichen- Double von
fare_amount keyZeichen
Anzahl der Zeilen und Datentypen jeder Spalte anzeigen:
str(taxi_trip_data)Die Ausgabe sieht etwa so aus:
tibble [10,000 x 7] (S3: tbl_df/tbl/data.frame) $ trip_time_minutes : int [1:10000] 52 19 2 7 14 16 1 2 2 6 ... $ passenger_count : int [1:10000] 1 1 1 1 1 1 1 1 3 1 ... $ trip_distance_miles: num [1:10000] 31.3 8.9 0.4 0.9 2 0.6 1.7 0.4 0.5 0.2 ... $ rate_code : chr [1:10000] "5.0" "5.0" "5.0" "5.0" ... $ rate_type : chr [1:10000] "Negotiated fare" "Negotiated fare" "Negotiated fare" "Negotiated fare" ... $ fare_amount : num [1:10000] 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 ... $ key : chr [1:10000] "1221969315200336084" 5007772749405424948" "3727452358632142755" "77714841168471205370" ...Zusammenfassung der abgerufenen Daten anzeigen:
summary(taxi_trip_data)Die Ausgabe sieht etwa so aus:
trip_time_minutes passenger_count trip_distance_miles rate_code Min. : 1.00 Min. :1.000 Min. : 0.000 Length:10000 1st Qu.: 20.00 1st Qu.:1.000 1st Qu.: 3.700 Class :character Median : 24.00 Median :1.000 Median : 4.800 Mode :character Mean : 30.32 Mean :1.465 Mean : 9.639 3rd Qu.: 39.00 3rd Qu.:2.000 3rd Qu.:17.600 Max. :120.00 Max. :9.000 Max. :43.700 rate_type fare_amount key Length:10000 Min. : 0.01 Length:10000 Class :character 1st Qu.: 16.50 Class :character Mode :character Median : 16.50 Mode :character Mean : 31.22 3rd Qu.: 52.00 Max. :182.50Stellen Sie die Verteilung der
fare_amount-Werte in einem Histogramm dar:ggplot( data = taxi_trip_data, aes(x = fare_amount) ) + geom_histogram(bins = 100)Die resultierende Darstellung sieht in etwa so aus:
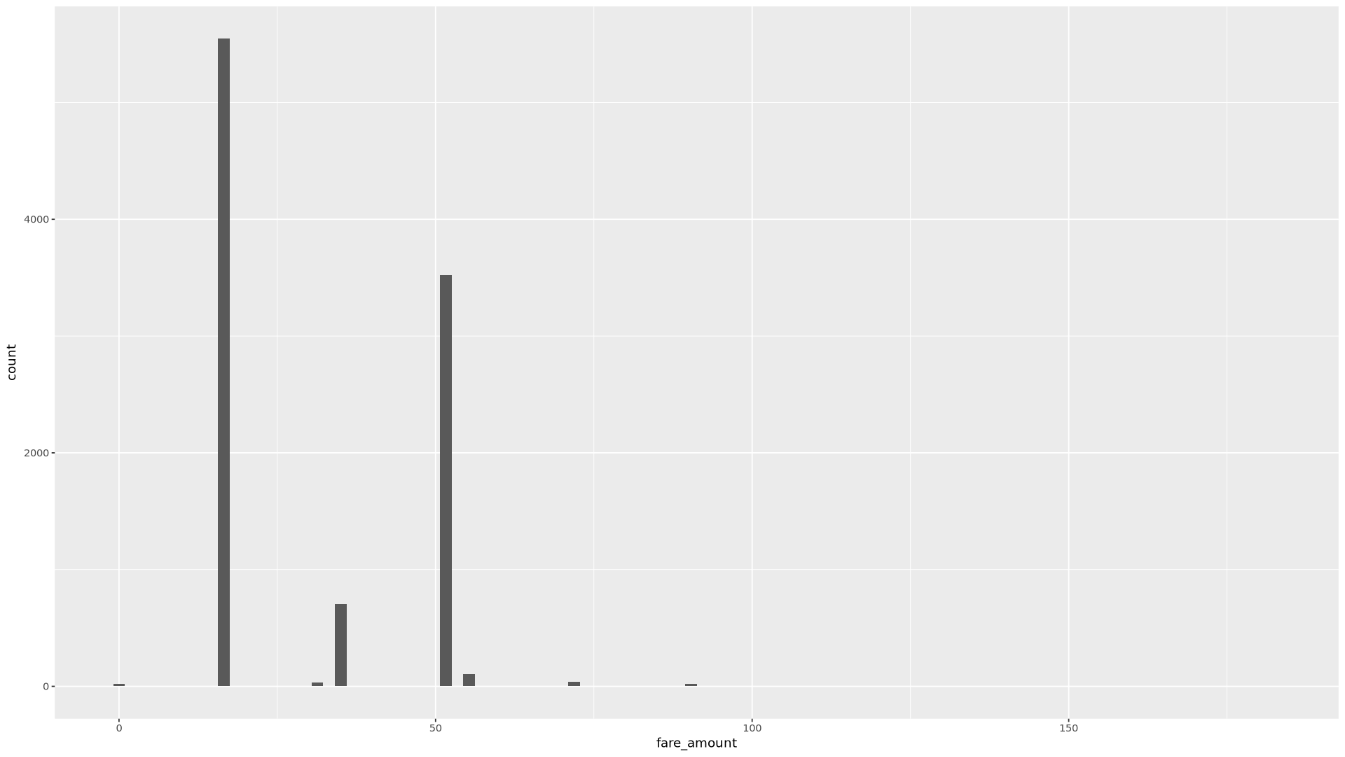
Stellen Sie die Beziehung zwischen
trip_distanceundfare_amountin einem Streudiagramm dar:ggplot( data = taxi_trip_data, aes(x = trip_distance_miles, y = fare_amount) ) + geom_point() + geom_smooth(method = "lm")Die resultierende Darstellung sieht in etwa so aus:
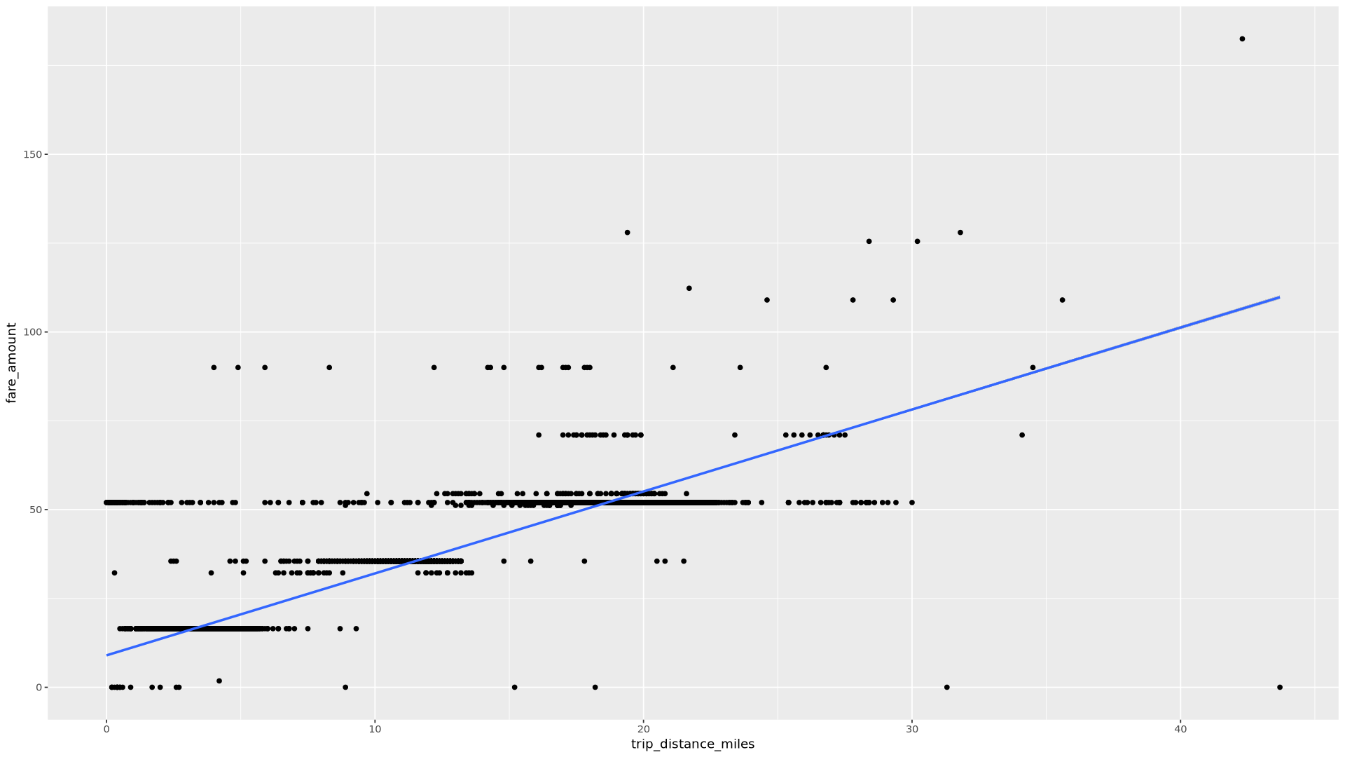
Erstellen Sie im Notebook eine Funktion, die die Anzahl der Fahrten und den durchschnittlichen Fahrpreisbetrag für jeden Wert der ausgewählten Spalte ermittelt:
get_distinct_value_aggregates <- function(column) { query <- paste0( 'SELECT ', column, ', COUNT(1) AS num_trips, AVG(fare_amount) AS avg_fare_amount FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) GROUP BY 1 ' ) bq_table_download( bq_project_query( PROJECT_ID, query = query ) ) }Rufen Sie die Funktion mit der Spalte
trip_time_minutesauf, die mit der Timestamp-Funktion in BigQuery definiert ist:df <- get_distinct_value_aggregates( 'TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes') ggplot( data = df, aes(x = trip_time_minutes, y = num_trips) ) + geom_line() ggplot( data = df, aes(x = trip_time_minutes, y = avg_fare_amount) ) + geom_line()Im Notebook werden zwei Grafiken angezeigt. Das erste Diagramm zeigt die Anzahl der Fahrten nach Fahrtdauer in Minuten. Das zweite Diagramm zeigt den durchschnittlichen Fahrpreis nach Fahrzeit.
Die Ausgabe des ersten
ggplot-Befehls sieht so aus und zeigt die Anzahl der Fahrten nach Fahrtdauer (in Minuten):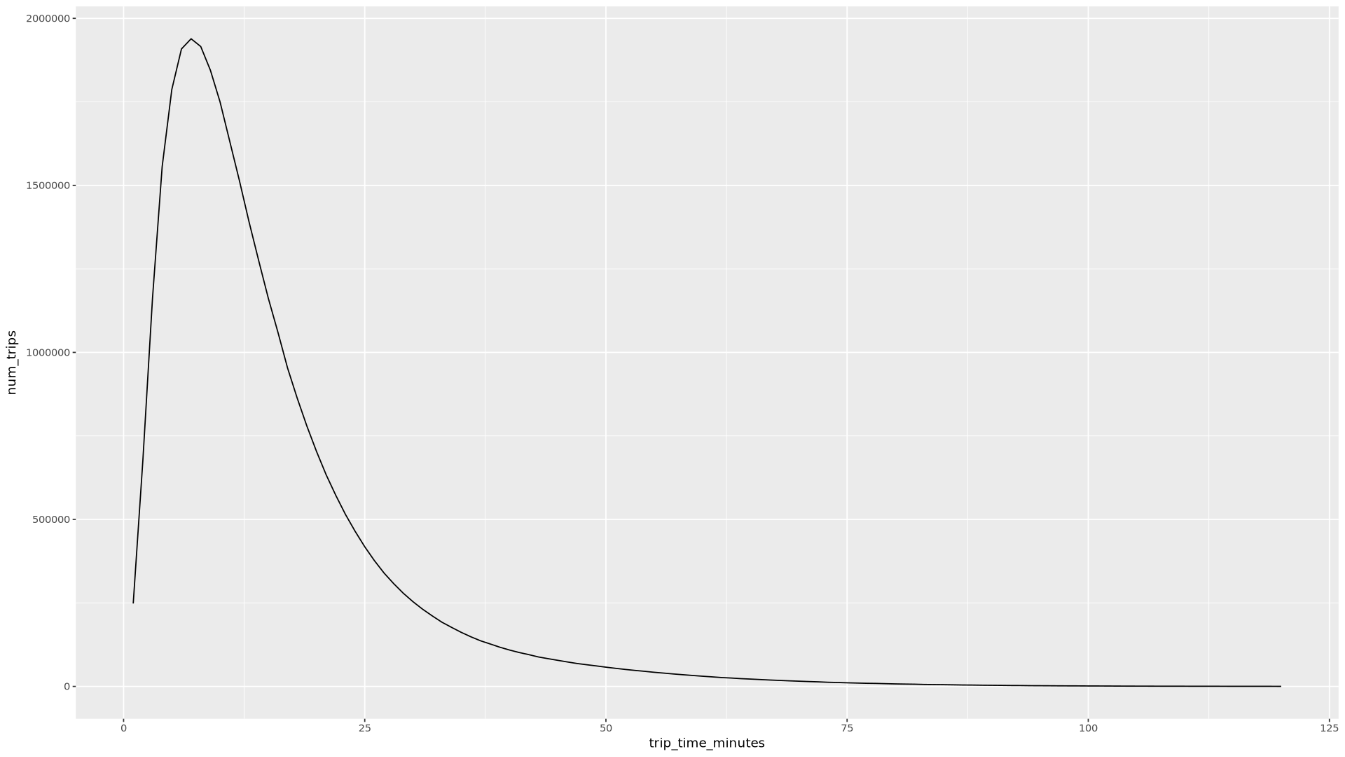
Die Ausgabe des zweiten
ggplot-Befehls sieht so aus: Sie zeigt den durchschnittlichen Fahrpreis von Fahrten nach Fahrzeit.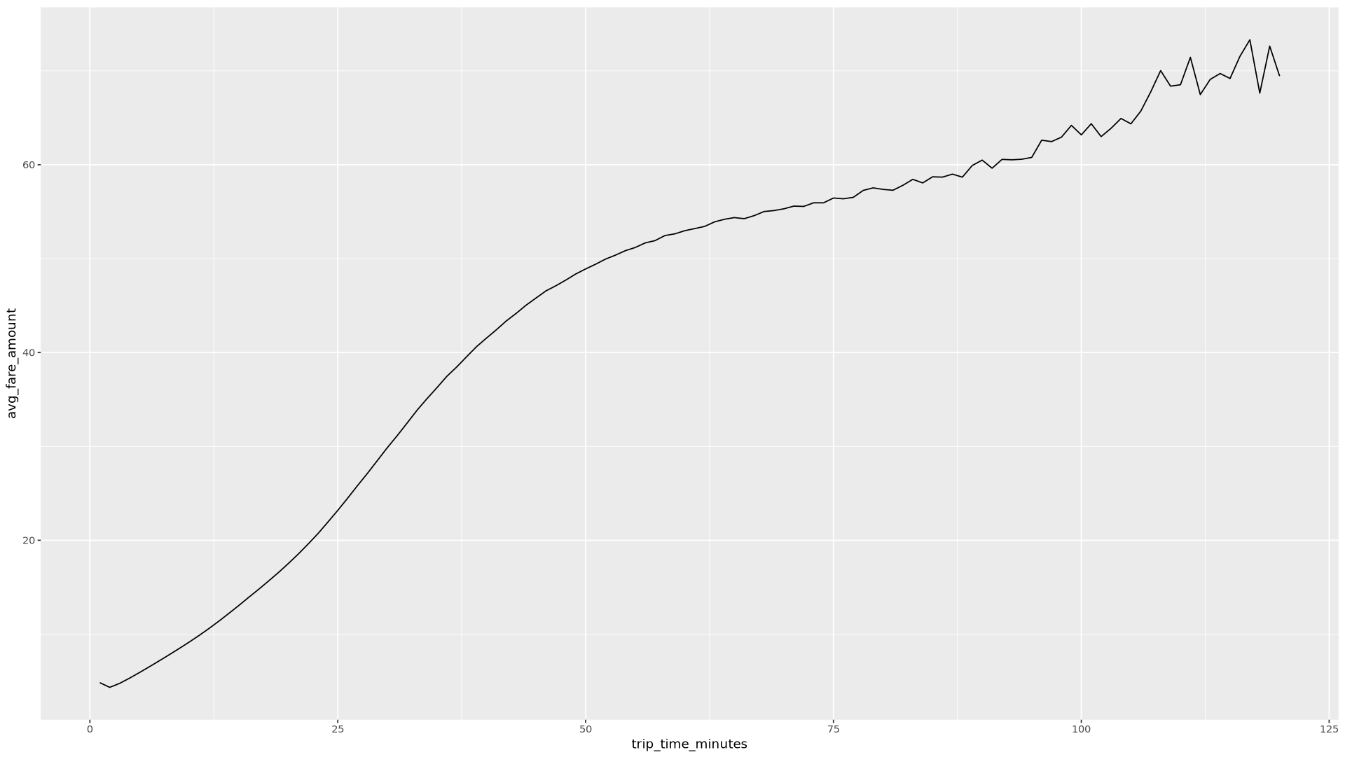
Weitere Beispiele zur Visualisierung mit anderen Feldern in den Daten finden Sie im Notebook.
Laden Sie im Notebook Trainings- und Evaluationsdaten aus BigQuery nach R:
# Prepare training and evaluation data from BigQuery sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) # Split data into 75% training, 25% evaluation train_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) <= 75') eval_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) > 75') # Load training data to data frame train_data <- bq_table_download( bq_project_query( PROJECT_ID, query = train_query ) ) # Load evaluation data to data frame eval_data <- bq_table_download( bq_project_query( PROJECT_ID, query = eval_query ) )Anzahl der Beobachtungen in jedem Dataset prüfen:
print(paste0("Training instances count: ", nrow(train_data))) print(paste0("Evaluation instances count: ", nrow(eval_data)))Etwa 75% der Gesamtinstanzen sollten für das Training und etwa 25% der verbleibenden Instanzen für die Bewertung verwendet werden.
Schreiben Sie die Daten in eine lokale CSV-Datei:
# Write data frames to local CSV files, with headers dir.create(file.path('data'), showWarnings = FALSE) write.table(train_data, "data/train_data.csv", row.names = FALSE, col.names = TRUE, sep = ",") write.table(eval_data, "data/eval_data.csv", row.names = FALSE, col.names = TRUE, sep = ",")Laden Sie die CSV-Dateien in Cloud Storage hoch, indem Sie an das System übergebene
gsutil-Befehle umhüllen:# Upload CSV data to Cloud Storage by passing gsutil commands to system gcs_url <- paste0("gs://", BUCKET_NAME, "/") command <- paste("gsutil mb", gcs_url) system(command) gcs_data_dir <- paste0("gs://", BUCKET_NAME, "/data") command <- paste("gsutil cp data/*_data.csv", gcs_data_dir) system(command) command <- paste("gsutil ls -l", gcs_data_dir) system(command, intern = TRUE)Sie können CSV-Dateien auch mit der googleCloudStorageR-Bibliothek in Cloud Storage hochladen. Dabei wird die Cloud Storage JSON API aufgerufen.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In der Dokumentation zu bigrquery erfahren, wie Sie BigQuery-Daten in Ihren R-Notebooks verwenden können
- Maschinelles Lernen: Best Practices für ML-Entwicklung
- Eine Übersicht über Architekturprinzipien und Empfehlungen, die speziell für KI- und ML-Arbeitslasten in Google Cloudgelten, finden Sie im Well-Architected Framework in der KI- und ML-Perspektive.
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.
- Jason Davenport | Developer Advocate
- Firat Tekiner | Senior Product Manager
Vertex AI Workbench-Instanz erstellen
Im ersten Schritt erstellen Sie eine Vertex AI Workbench-Instanz, die Sie für diese Anleitung verwenden können.
JupyterLab öffnen und R installieren
Um die Anleitung im Notebook durchzugehen, müssen Sie die JupyterLab-Umgebung öffnen, R installieren, das vertex-ai-samples-GitHub-Repository klonen und dann das Notebook öffnen.
Notebook öffnen und R einrichten
Daten aus BigQuery abfragen
In diesem Abschnitt des Notebooks werden die Ergebnisse der Ausführung einer BigQuery-SQL-Anweisung in R beschrieben und die Daten vorab geprüft.
Daten mit ggplot2 visualisieren
In diesem Abschnitt des Notebooks verwenden Sie die Bibliothek ggplot2 in R, um einige Variablen aus dem Beispieldataset zu untersuchen.
Daten in BigQuery aus R verarbeiten
Wenn Sie mit großen Datasets arbeiten, empfehlen wir, dass Sie in BigQuery so viele Analysen wie möglich ausführen (Zusammenfassung, Filterung, Join-Verknüpfungen, Computing-Spalten usw.) und dann die Ergebnisse abrufen. Das Ausführen dieser Aufgaben in R ist weniger effizient. Bei der Verwendung von BigQuery für Analysen wird die Skalierbarkeit und Leistung von BigQuery genutzt und es wird sichergestellt, dass die zurückgegebenen Ergebnisse in den Arbeitsspeicher von R passen.
Daten als CSV-Dateien in Cloud Storage speichern
Als Nächstes müssen Sie extrahierte Daten aus BigQuery als CSV-Dateien in Cloud Storage speichern, um sie für weitere ML-Aufgaben zu verwenden.
Mit bigrquery können Sie auch Daten aus R zurück in BigQuery schreiben. Das Zurückschreiben in BigQuery erfolgt in der Regel nach Abschluss einer Vorverarbeitung oder nach dem Generieren von Ergebnissen, die für weitere Analysen verwendet werden sollen.
Bereinigen
Entfernen Sie die in diesem Dokument verwendeten Ressourcen, um zu vermeiden, dass Ihrem Google Cloud Konto dafür Gebühren berechnet werden.
Projekt löschen
Am einfachsten vermeiden Sie weitere Kosten, indem Sie das erstellte Projekt löschen. Wenn Sie mehrere Architekturen, Anleitungen oder Kurzanleitungen durcharbeiten möchten, können Sie die Überschreitung von Projektkontingenten verhindern, wenn Sie Projekte wiederverwenden.
Nächste Schritte
Beitragende
Autor: Alok Pattani | Developer Advocate
Weitere Beitragende: