This guide shows security practitioners how to onboard Google Cloud logs to be used in security analytics. By performing security analytics, you help your organization prevent, detect, and respond to threats like malware, phishing, ransomware, and poorly configured assets.
This guide shows you how to do the following:
- Enable the logs to be analyzed.
- Route those logs to a single destination depending on your choice of security analytics tool, such as Log Analytics, BigQuery, Google Security Operations, or a third-party security information and event management (SIEM) technology.
- Analyze those logs to audit your cloud usage and detect potential threats to your data and workloads, using sample queries from the Community Security Analytics (CSA) project.
The information in this guide is part of Google Cloud Autonomic Security Operations, which includes engineering-led transformation of detection and response practices and security analytics to improve your threat detection capabilities.
In this guide, logs provide the data source to be analyzed. However, you can apply the concepts from this guide to analysis of other complementary security-related data from Google Cloud, such as security findings from Security Command Center. Provided in Security Command Center Premium is a list of regularly-updated managed detectors that are designed to identify threats, vulnerabilities, and misconfigurations within your systems in near real-time. By analyzing these signals from Security Command Center and correlating them with logs ingested in your security analytics tool as described in this guide, you can achieve a broader perspective of potential security threats.
The following diagram shows how security data sources, security analytics tools, and CSA queries work together.
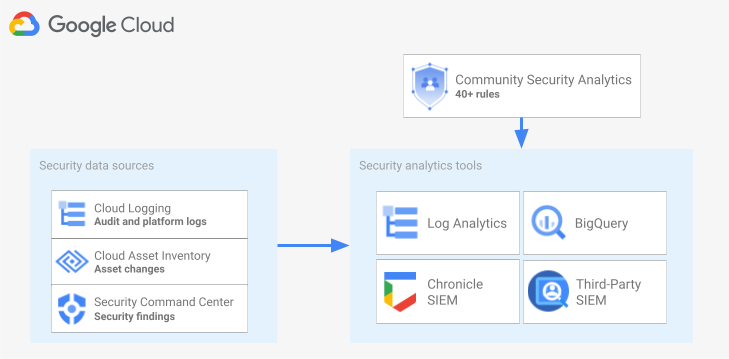
The diagram starts with the following security data sources: logs from Cloud Logging, asset changes from Cloud Asset Inventory, and security findings from Security Command Center. The diagram then shows these security data sources being routed into the security analytics tool of your choice: Log Analytics in Cloud Logging, BigQuery, Google Security Operations, or a third-party SIEM. Finally, the diagram shows using CSA queries with your analytics tool to analyze the collated security data.
Security log analytics workflow
This section describe the steps to set up security log analytics in Google Cloud. The workflow consists of the three steps shown in the following diagram and described in the following paragraphs:
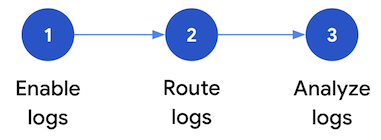
Enable logs: There are many security logs available in Google Cloud. Each log has different information that can be useful in answering specific security questions. Some logs like Admin Activity audit logs are enabled by default; others need to be manually enabled because they incur additional ingestion costs in Cloud Logging. Therefore, the first step in the workflow is to prioritize the security logs that are most relevant for your security analysis needs and to individually enable those specific logs.
To help you evaluate logs in terms of the visibility and threat detection coverage they provide, this guide includes a log scoping tool. This tool maps each log to relevant threat tactics and techniques in the MITRE ATT&CK® Matrix for Enterprise. The tool also maps Event Threat Detection rules in Security Command Center to the logs on which they rely. You can use the log scoping tool to evaluate logs regardless of the analytics tool that you use.
Route logs: After identifying and enabling the logs to be analyzed, the next step is to route and aggregate the logs from your organization, including any contained folders, projects, and billing accounts. How you route logs depends on the analytics tool that you use.
This guide describes common log routing destinations, and shows you how to use a Cloud Logging aggregated sink to route organization-wide logs into a Cloud Logging log bucket or a BigQuery dataset depending on whether you choose to use Log Analytics or BigQuery for analytics.
Analyze logs: After you route the logs into an analytics tool, the next step is to perform an analysis of these logs to identify any potential security threats. How you analyze the logs depends on the analytics tool that you use. If you use Log Analytics or BigQuery, you can analyze the logs by using SQL queries. If you use Google Security Operations, you analyze the logs by using YARA-L rules. If you are using a third-party SIEM tool, you use the query language specified by that tool.
In this guide, you'll find SQL queries that you can use to analyze the logs in either Log Analytics or BigQuery. The SQL queries provided in this guide come from the Community Security Analytics (CSA) project. CSA is an open-source set of foundational security analytics designed to provide you with a baseline of pre-built queries and rules that you can reuse to start analyzing your Google Cloud logs.
The following sections provide detailed information on how to set up and apply each step in the security logs analytics workflow.
Enable logs
The process of enabling logs involves the following steps:
- Identify the logs you need by using the log scoping tool in this guide.
- Record the log filter generated by the log scoping tool for use later when configuring the log sink.
- Enable logging for each identified log type or Google Cloud service. Depending on the service, you might have to also enable the corresponding Data Access audit logs as detailed later in this section.
Identify logs using the log scoping tool
To help you identify the logs that meet your security and compliance needs, you can use the log scoping tool shown in this section. This tool provides an interactive table that lists valuable security-relevant logs across Google Cloud including Cloud Audit Logs, Access Transparency logs, network logs, and several platform logs. This tool maps each log type to the following areas:
- MITRE ATT&CK threat tactics and techniques that can be monitored with that log.
- CIS Google Cloud Computing Platform compliance violations that can be detected in that log.
- Event Threat Detection rules that rely on that log.
The log scoping tool also generates a log filter which appears immediately after the table. As you identify the logs that you need, select those logs in the tool to automatically update that log filter.
The following short procedures explain how to use the log scoping tool:
- To select or remove a log in the log scoping tool, click the toggle next to the name of the log.
- To select or remove all the logs, click the toggle next to the Log type heading.
- To see which MITRE ATT&CK techniques can be monitored by each log type, click next to the MITRE ATT&CK tactics and techniques heading.
Log scoping tool
Record the log filter
The log filter that is automatically generated by the log scoping tool contains all of the logs that you have selected in the tool. You can use the filter as is or you can refine the log filter further depending on your requirements. For example, you can include (or exclude) resources only in one or more specific projects. After you have a log filter that meets your logging requirements, you need to save the filter for use when routing the logs. For instance, you can save the filter in a text editor or save it in an environment variable as follows:
- In the "Auto-generated log filter" section that follows the tool, copy the code for the log filter.
- Optional: Edit the copied code to refine the filter.
In Cloud Shell, create a variable to save the log filter:
export LOG_FILTER='LOG_FILTER'Replace
LOG_FILTERwith the code for the log filter.
Enable service-specific platform logs
For each of the platform logs that you select in the log scoping tool, those logs must be enabled (typically at the resource level) on a service-by-service basis. For example, Cloud DNS logs are enabled at the VPC-network level. Likewise, VPC Flow Logs are enabled at the subnet level for all VMs in the subnet, and logs from Firewall Rules Logging are enabled at the individual firewall rule level.
Each platform log has its own instructions on how to enable logging. However, you can use the log scoping tool to quickly open the relevant instructions for each platform log.
To learn how to enable logging for a specific platform log, do the following:
- In the log scoping tool, locate the platform log that you want to enable.
- In the Enabled by default column, click the Enable link that corresponds to that log. The link takes you to detailed instructions on how to enable logging for that service.
Enable the Data Access audit logs
As you can see in the log scoping tool, the Data Access audit logs from Cloud Audit Logs provide broad threat detection coverage. However, their volume can be quite large. Enabling these Data Access audit logs might therefore result in additional charges related to ingesting, storing, exporting, and processing these logs. This section both explains how to enable these logs and presents some best practices to help you with making the tradeoff between value and cost.
Data Access audit logs—except for BigQuery—are disabled by default. To configure Data Access audit logs for Google Cloud services other than BigQuery, you must explicitly enable them either by using the Google Cloud console or by using the Google Cloud CLI to edit Identity and Access Management (IAM) policy objects. When you enable Data Access audit logs, you can also configure which types of operations are recorded. There are three Data Access audit log types:
ADMIN_READ: Records operations that read metadata or configuration information.DATA_READ: Records operations that read user-provided data.DATA_WRITE: Records operations that write user-provided data.
Note that you can't configure the recording of ADMIN_WRITE operations, which
are operations that write metadata or configuration information. ADMIN_WRITE
operations are included in Admin Activity audit logs from Cloud Audit Logs
and therefore can't be disabled.
Manage the volume of Data Access audit logs
When enabling Data Access audit logs, the goal is to maximize their value in terms of security visibility while also limiting their cost and management overhead. To help you achieve that goal, we recommend that you do the following to filter out low-value, high-volume logs:
- Prioritize relevant services such as services that host sensitive workloads, keys and data. For specific examples of services that you might want to prioritize over others, see Example Data Access audit log configuration.
Prioritize relevant projects such as projects that host production workloads as opposed to projects that host developer and staging environments. To filter out all logs from a particular project, add the following expression to your log filter for your sink. Replace PROJECT_ID with the ID of the project from which you want to filter out all logs:
Project Log filter expression Exclude all logs from a given project NOT logName =~ "^projects/PROJECT_ID"
Prioritize a subset of data access operations such as
ADMIN_READ,DATA_READ, orDATA_WRITEfor a minimal set of recorded operations. For example, some services like Cloud DNS write all three types of operations, but you can enable logging for onlyADMIN_READoperations. After you have configured one of more of these three types of data access operations, you might want to exclude specific operations that are particularly high volume. You can exclude these high volume operations by modifying the sink's log filter. For example, you decide to enable full Data Access audit logging, includingDATA_READoperations on some critical storage services. To exclude specific high-traffic data read operations in this situation, you can add the following recommended log filter expressions to your sink's log filter:Service Log filter expression Exclude high volume logs from Cloud Storage NOT (resource.type="gcs_bucket" AND (protoPayload.methodName="storage.buckets.get" OR protoPayload.methodName="storage.buckets.list"))
Exclude high volume logs from Cloud SQL NOT (resource.type="cloudsql_database" AND protoPayload.request.cmd="select")
Prioritize relevant resources such as resources that host your most sensitive workloads and data. You can classify your resources based on the value of the data that they process, and their security risk such as whether they are externally accessible or not. Although Data Access audit logs are enabled per service, you can filter out specific resources or resource types through the log filter.
Exclude specific principals from having their data accesses recorded. For example, you can exempt your internal testing accounts from having their operations recorded. To learn more, see Set exemptions in Data Access audit logs documentation.
Example Data Access audit log configuration
The following table provides a baseline Data Access audit log configuration that you can use for Google Cloud projects to limit log volumes while gaining valuable security visibility:
| Tier | Services | Data Access audit log types | MITRE ATT&CK tactics |
|---|---|---|---|
| Authentication & authorization services | IAM Identity-Aware Proxy (IAP)1 Cloud KMS Secret Manager Resource Manager |
ADMIN_READ DATA_READ |
Discovery Credential Access Privilege Escalation |
| Storage services | BigQuery (enabled by default) Cloud Storage1, 2 |
DATA_READ DATA_WRITE |
Collection Exfiltration |
| Infrastructure services | Compute Engine Organization Policy |
ADMIN_READ | Discovery |
1 Enabling Data Access audit logs for IAP or Cloud Storage can generate large log volumes when there is high traffic to IAP-protected web resources or to Cloud Storage objects.
2 Enabling Data Access audit logs for Cloud Storage might break the use of authenticated browser downloads for non-public objects. For more details and suggested workarounds to this issue, see the Cloud Storage troubleshooting guide.
In the example configuration, notice how services are grouped in tiers of sensitivity based on their underlying data, metadata, or configuration. These tiers demonstrate the following recommended granularity of Data Access audit logging:
- Authentication & authorization services: For this tier of services, we recommend auditing all data access operations. This level of auditing helps you monitor access to your sensitive keys, secrets, and IAM policies. Monitoring this access might help you detect MITRE ATT&CK tactics like Discovery, Credential Access, and Privilege Escalation.
- Storage services: For this tier of services, we recommend auditing data access operations that involve user-provided data. This level of auditing helps you monitor access to your valuable and sensitive data. Monitoring this access might help you detect MITRE ATT&CK tactics like Collection and Exfiltration against your data.
- Infrastructure services: For this tier of services, we recommend auditing data access operations that involve metadata or configuration information. This level of auditing helps you monitor for scanning of infrastructure configuration. Monitoring this access might help you detect MITRE ATT&CK tactics like Discovery against your workloads.
Route logs
After the logs are identified and enabled, the next step is to route the logs to a single destination. The routing destination, path and complexity vary depending on the analytics tools that you use, as shown in the following diagram.
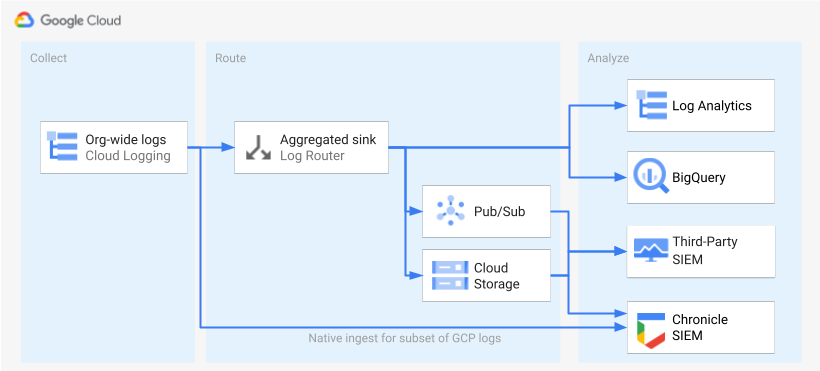
The diagram shows the following routing options:
If you use Log Analytics, you need an aggregated sink to aggregate the logs from across your Google Cloud organization into a single Cloud Logging bucket.
If you use BigQuery, you need an aggregated sink to aggregate the logs from across your Google Cloud organization into a single BigQuery dataset.
If you use Google Security Operations and this predefined subset of logs meets your security analysis needs, you can automatically aggregate these logs into your Google Security Operations account using the built-in Google Security Operations ingest. You can also view this predefined set of logs by looking at the Exportable directly to Google Security Operations column of the log scoping tool. For more information about exporting these predefined logs, see Ingest Google Cloud logs to Google Security Operations.
If you use BigQuery or a third-party SIEM or want to export an expanded set of logs into Google Security Operations, the diagram shows that an additional step is needed between enabling the logs and analyzing them. This additional step consists of configuring an aggregated sink that routes the selected logs appropriately. If you're using BigQuery, this sink is all that you need to route the logs to BigQuery. If you're using a third-party SIEM, you need to have the sink aggregate the selected logs in Pub/Sub or Cloud Storage before the logs can be pulled into your analytics tool.
The routing options to Google Security Operations and a third-party SIEM aren't covered in this guide. However, the following sections provide the detailed steps to route logs to Log Analytics or BigQuery:
- Set up a single destination
- Create an aggregated log sink.
- Grant access to the sink.
- Configure read access to the destination.
- Verify that the logs are routed to the destination.
Set up a single destination
Log Analytics
Open the Google Cloud console in the Google Cloud project that you want to aggregate logs into.
In a Cloud Shell terminal, run the following
gcloudcommand to create a log bucket:gcloud logging buckets create BUCKET_NAME \ --location=BUCKET_LOCATION \ --project=PROJECT_IDReplace the following:
PROJECT_ID: the ID of the Google Cloud project where the aggregated logs will be stored.BUCKET_NAME: the name of the new Logging bucket.BUCKET_LOCATION: the geographical location of the new Logging bucket. The supported locations areglobal,us, oreu. To learn more about these storage regions, refer to Supported regions. If you don't specify a location, then theglobalregion is used, which means that the logs could be physically located in any of the regions.
Verify that the bucket was created:
gcloud logging buckets list --project=PROJECT_ID(Optional) Set the retention period of the logs in the bucket. The following example extends the retention of logs stored in the bucket to 365 days:
gcloud logging buckets update BUCKET_NAME \ --location=BUCKET_LOCATION \ --project=PROJECT_ID \ --retention-days=365Upgrade your new bucket to use Log Analytics by following these steps.
BigQuery
Open the Google Cloud console in the Google Cloud project that you want to aggregate logs into.
In a Cloud Shell terminal, run the following
bq mkcommand to create a dataset:bq --location=DATASET_LOCATION mk \ --dataset \ --default_partition_expiration=PARTITION_EXPIRATION \ PROJECT_ID:DATASET_IDReplace the following:
PROJECT_ID: the ID of the Google Cloud project where the aggregated logs will be stored.DATASET_ID: the ID of the new BigQuery dataset.DATASET_LOCATION: the geographic location of the dataset. After a dataset is created, the location can't be changed.PARTITION_EXPIRATION: the default lifetime (in seconds) for the partitions in the partitioned tables that are created by the log sink. You configure the log sink in the next section. The log sink that you configure uses partitioned tables that are partitioned by day based on the log entry's timestamp. Partitions (including associated log entries) are deletedPARTITION_EXPIRATIONseconds after the partition's date.
Create an aggregated log sink
You route your organization logs into your destination by creating an aggregated sink at the organization level. To include all the logs you selected in the log scoping tool, you configure the sink with the log filter generated by the log scoping tool.
Log Analytics
In a Cloud Shell terminal, run the following
gcloudcommand to create an aggregated sink at the organization level:gcloud logging sinks create SINK_NAME \ logging.googleapis.com/projects/PROJECT_ID/locations/BUCKET_LOCATION/buckets/BUCKET_NAME \ --log-filter="LOG_FILTER" \ --organization=ORGANIZATION_ID \ --include-childrenReplace the following:
SINK_NAME: the name of the sink that routes the logs.PROJECT_ID: the ID of the Google Cloud project where the aggregated logs will be stored.BUCKET_LOCATION: the location of the Logging bucket that you created for log storage.BUCKET_NAME: the name of the Logging bucket that you created for log storage.LOG_FILTER: the log filter that you saved from the log scoping tool.ORGANIZATION_ID: the resource ID for your organization.
The
--include-childrenflag is important so that logs from all the Google Cloud projects within your organization are also included. For more information, see Collate and route organization-level logs to supported destinations.Verify the sink was created:
gcloud logging sinks list --organization=ORGANIZATION_IDGet the name of the service account associated with the sink that you just created:
gcloud logging sinks describe SINK_NAME --organization=ORGANIZATION_IDThe output looks similar to the following:
writerIdentity: serviceAccount:p1234567890-12345@logging-o1234567890.iam.gserviceaccount.com`Copy the entire string for
writerIdentitystarting with serviceAccount:. This identifier is the sink's service account. Until you grant this service account write access to the log bucket, log routing from this sink will fail. You grant write access to the sink's writer identity in the next section.
BigQuery
In a Cloud Shell terminal, run the following
gcloudcommand to create an aggregated sink at the organization level:gcloud logging sinks create SINK_NAME \ bigquery.googleapis.com/projects/PROJECT_ID/datasets/DATASET_ID \ --log-filter="LOG_FILTER" \ --organization=ORGANIZATION_ID \ --use-partitioned-tables \ --include-childrenReplace the following:
SINK_NAME: the name of the sink that routes the logs.PROJECT_ID: the ID for the Google Cloud project you want to aggregate the logs into.DATASET_ID: the ID of the BigQuery dataset you created.LOG_FILTER: the log filter that you saved from the log scoping tool.ORGANIZATION_ID: the resource ID for your organization.
The
--include-childrenflag is important so that logs from all the Google Cloud projects within your organization are also included. For more information, see Collate and route organization-level logs to supported destinations.The
--use-partitioned-tablesflag is important so that data is partitioned by day based on the log entry'stimestampfield. This simplifies querying of the data and helps reduce query costs by reducing the amount of data scanned by queries. Another benefit of partitioned tables is that you can set a default partition expiration at the dataset level to meet your log retention requirements. You have already set a default partition expiration when you created the dataset destination in the previous section. You might also choose to set a partition expiration at the individual table level, providing you with fine-grained data retention controls based on log type.Verify the sink was created:
gcloud logging sinks list --organization=ORGANIZATION_IDGet the name of the service account associated with the sink that you just created:
gcloud logging sinks describe SINK_NAME --organization=ORGANIZATION_IDThe output looks similar to the following:
writerIdentity: serviceAccount:p1234567890-12345@logging-o1234567890.iam.gserviceaccount.com`Copy the entire string for
writerIdentitystarting with serviceAccount:. This identifier is the sink's service account. Until you grant this service account write access to the BigQuery dataset, log routing from this sink will fail. You grant write access to the sink's writer identity in the next section.
Grant access to the sink
After creating the log sink, you must grant your sink access to write to its destination, be it the Logging bucket or the BigQuery dataset.
Log Analytics
To add the permissions to the sink's service account, follow these steps:
In the Google Cloud console, go to the IAM page:
Make sure that you've selected the destination Google Cloud project that contains the Logging bucket you created for central log storage.
Click person_add Grant access.
In the New principals field, enter the sink's service account without the
serviceAccount:prefix. Recall that this identity comes from thewriterIdentityfield you retrieved in the previous section after you created the sink.In the Select a role drop-down menu, select Logs Bucket Writer.
Click Add IAM condition to restrict the service account's access to only the log bucket you created.
Enter a Title and Description for the condition.
In the Condition type drop-down menu, select Resource > Name.
In the Operator drop-down menu, select Ends with.
In the Value field, enter the bucket's location and name as follows:
locations/BUCKET_LOCATION/buckets/BUCKET_NAMEClick Save to add the condition.
Click Save to set the permissions.
BigQuery
To add the permissions to the sink's service account, follow these steps:
In the Google Cloud console, go to BigQuery:
Open the BigQuery dataset that you created for central log storage.
In the Dataset info tab, click the Sharingkeyboard_arrow_down drop-down menu, and then click Permissions.
In the Dataset Permissions side panel, click Add Principal.
In the New principals field, enter the sink's service account without the
serviceAccount:prefix. Recall that this identity comes from thewriterIdentityfield you retrieved in the previous section after you created the sink.In the Role drop-down menu, select BigQuery Data Editor.
Click Save.
After you grant access to the sink, log entries begin to populate the sink destination: the Logging bucket or the BigQuery dataset.
Configure read access to the destination
Now that your log sink routes logs from your entire organization into one single destination, you can search across all of these logs. Use IAM permissions to manage permissions and grant access as needed.
Log Analytics
To grant access to view and query the logs in your new log bucket, follow these steps.
In the Google Cloud console, go to the IAM page:
Make sure you've selected the Google Cloud project you're using to aggregate the logs.
Click person_add Add.
In the New principal field, add your email account.
In the Select a role drop-down menu, select Logs Views Accessor.
This role provides the newly added principal with read access to all views for any buckets in the Google Cloud project. To limit a user's access, add a condition that lets the user read only from your new bucket only.
Click Add condition.
Enter a Title and Description for the condition.
In the Condition type drop-down menu, select Resource > Name.
In the Operator drop-down menu, select Ends with.
In the Value field, enter the bucket's location and name, and the default log view
_AllLogsas follows:locations/BUCKET_LOCATION/buckets/BUCKET_NAME/views/_AllLogsClick Save to add the condition.
Click Save to set the permissions.
BigQuery
To grant access to view and query the logs in your BigQuery dataset, follow the steps in the Granting access to a dataset section of the BigQuery documentation.
Verify that the logs are routed to the destination
Log Analytics
When you route logs to a log bucket upgraded to Log Analytics, you can view and query all log entries through a single log view with a unified schema for all log types. Follow these steps to verify the logs are correctly routed.
In the Google Cloud console, go to Log Analytics page:
Make sure you've selected the Google Cloud project you're using to aggregate the logs.
Click on Log Views tab.
Expand the log views under the log bucket that you have created (that is
BUCKET_NAME) if it is not expanded already.Select the default log view
_AllLogs. You can now inspect the entire log schema in the right panel, as shown in the following screenshot: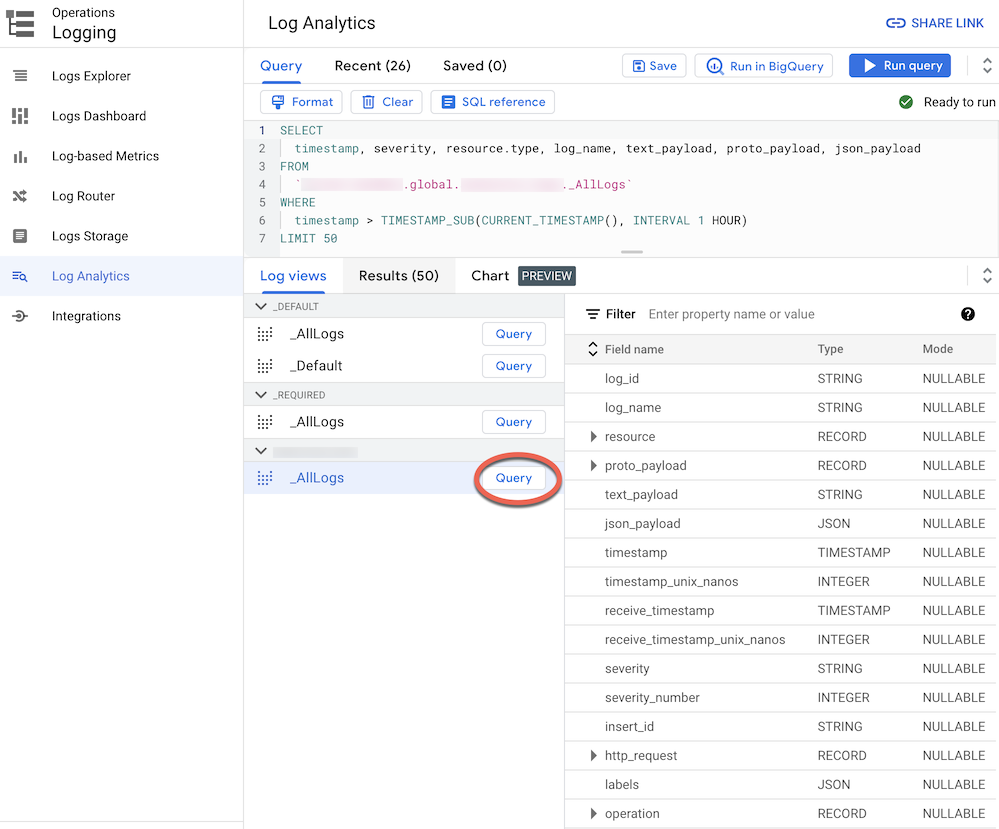
Next to
_AllLogs, click Query . This populates the Query editor with a SQL sample query to retrieve recently routed log entries.Click Run query to view recently routed log entries.
Depending on level of activity in Google Cloud projects in your organization, you might have to wait a few minutes until some logs get generated, and then routed to your log bucket.
BigQuery
When you route logs to a BigQuery dataset, Cloud Logging creates BigQuery tables to hold the log entries as shown in the following screenshot:
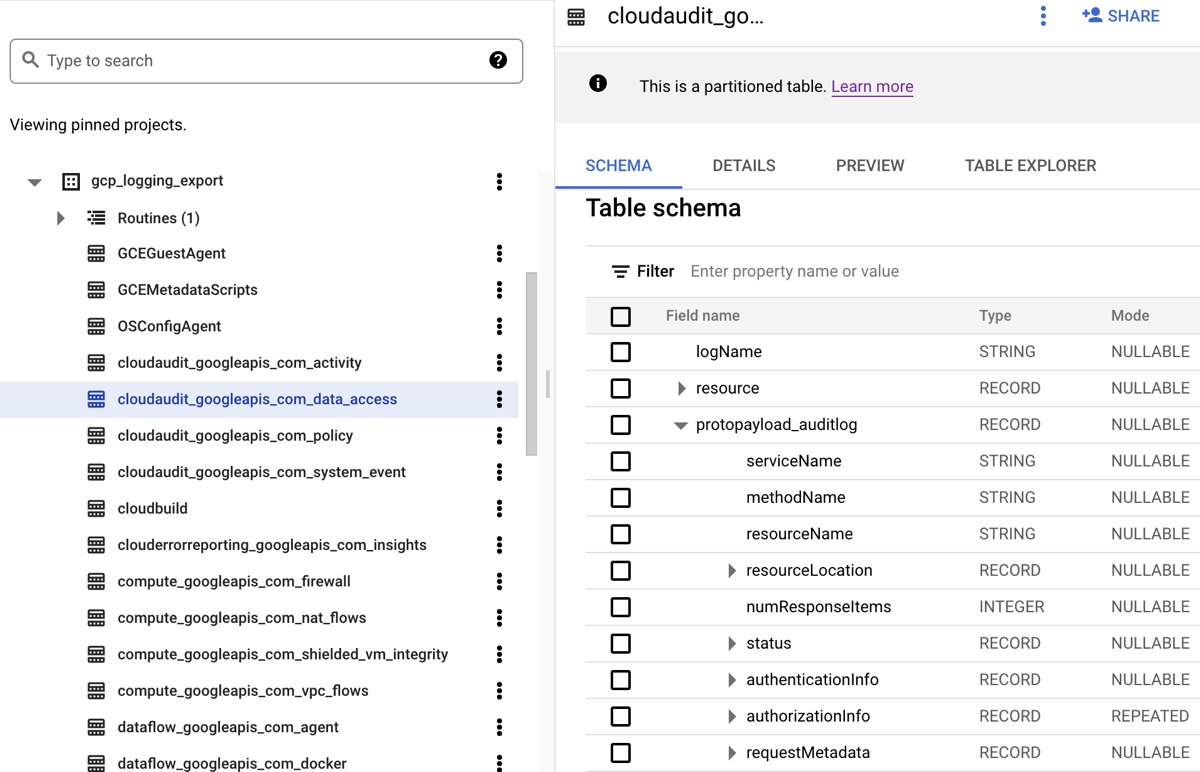
The screenshot shows how Cloud Logging names each BigQuery
table based on the name of the log to which a log entry belongs. For example,
the cloudaudit_googleapis_com_data_access table that is selected in the
screenshot contains Data Access audit logs whose log ID is
cloudaudit.googleapis.com%2Fdata_access. In addition to being named based on
the corresponding log entry, each table is also partitioned based on the
timestamps for each log entry.
Depending on level of activity in Google Cloud projects in your organization, you might have to wait a few minutes until some logs get generated, and then routed to your BigQuery dataset.
Analyze logs
You can run a broad range of queries against your audit and platform logs. The following list provides a set of sample security questions that you might want to ask of your own logs. For each question in this list, there are two versions of the corresponding CSA query: one for use with Log Analytics and one for use with BigQuery. Use the query version that matches the sink destination that you previously set up.
Log Analytics
Before using any of the SQL queries below, replace MY_PROJECT_ID
with the ID of the Google Cloud project where you created the log bucket (that is PROJECT_ID), and MY_DATASET_ID with the region and name of that log bucket (that is
BUCKET_LOCATION.BUCKET_NAME).
BigQuery
Before using any of the SQL queries below, replace MY_PROJECT_ID
with the ID of the Google Cloud project where you created the BigQuery dataset (that is PROJECT_ID), and MY_DATASET_ID with the name of that dataset, that is DATASET_ID.
- Login and access questions
- Permission changes questions
- Provisioning activity questions
- Workload usage questions
- Data access questions
- Which users most frequently accessed data in the past week?
- Which users accessed the data in the "accounts" table last month?
- What tables are most frequently accessed and by whom?
- What are the top 10 queries against BigQuery in the past week?
- What are the most common actions recorded in the data access log over the past month?
- Network security questions
Login and access questions
These sample queries perform analysis to detect suspicious login attempts or initial access attempts to your Google Cloud environment.
Any suspicious login attempt flagged by Google Workspace?
By searching Cloud Identity logs that are part of Google Workspace Login Audit, the following query detects suspicious login attempts flagged by Google Workspace. Such login attempts might be from the Google Cloud console, Admin console, or the gcloud CLI.
Log Analytics
BigQuery
Any excessive login failures from any user identity?
By searching Cloud Identity logs that are part of Google Workspace Login Audit, the following query detects users who have had three or more successive login failures within the last 24 hours.
Log Analytics
BigQuery
Any access attempts violating VPC Service Controls?
By analyzing Policy Denied audit logs from Cloud Audit Logs, the following query detects access attempts blocked by VPC Service Controls. Any query results might indicate potential malicious activity like access attempts from unauthorized networks using stolen credentials.
Log Analytics
BigQuery
Any access attempts violating IAP access controls?
By analyzing external Application Load Balancer logs, the following query detects access attempts blocked by IAP. Any query results might indicate an initial access attempt or vulnerability exploit attempt.
Log Analytics
BigQuery
Permission changes questions
These sample queries perform analysis over administrator activity that changes permissions, including changes in IAM policies, groups and group memberships, service accounts, and any associated keys. Such permission changes might provide a high level of access to sensitive data or environments.
Any user added to highly-privileged groups?
By analyzing Google Workspace Admin Audit
audit logs, the following query detects users who have been added to any of the
highly-privileged groups listed in the query. You use the regular expression in
the query to define which groups (such as admin@example.com or prod@example.com)
to monitor. Any query results might indicate a malicious or accidental privilege
escalation.
Log Analytics
BigQuery
Any permissions granted over a service account?
By analyzing Admin Activity audit logs from Cloud Audit Logs, the following query detects any permissions that have been granted to any principal over a service account. Examples of permissions that might be granted are the ability to impersonate that service account or create service account keys. Any query results might indicate an instance of privilege escalation or a risk of credentials leakage.
Log Analytics
BigQuery
Any service accounts or keys created by non-approved identity?
By analyzing Admin Activity audit logs, the following query detects any service accounts or keys that have been manually created by a user. For example, you might follow a best practice to only allow service accounts to be created by an approved service account as part of an automated workflow. Therefore, any service account creation outside of that workflow is considered non-compliant and possibly malicious.
Log Analytics
BigQuery
Any user added to (or removed from) sensitive IAM policy?
By searching Admin Activity audit logs, the following query detects any user or
group access change for an IAP-secured resource such as a
Compute Engine backend service. The following query searches all IAM
policy updates for IAP resources involving the IAM
role roles/iap.httpsResourceAccessor. This role provides permissions to access
the HTTPS resource or the backend service. Any query results might indicate
attempts to bypass the defenses of a backend service that might be exposed to
the internet.
Log Analytics
BigQuery
Provisioning activity questions
These sample queries perform analysis to detect suspicious or anomalous admin activity like provisioning and configuring resources.
Any changes made to logging settings?
By searching Admin Activity audit logs, the following query detects any change made to logging settings. Monitoring logging settings helps you detect accidental or malicious disabling of audit logs and similar defense evasion techniques.
Log Analytics
BigQuery
Any VPC Flow Logs actively disabled?
By searching Admin Activity audit logs, the following query detects any subnet whose VPC Flow Logs were actively disabled . Monitoring VPC Flow Logs settings helps you detect accidental or malicious disabling of VPC Flow Logs and similar defense evasion techniques.
Log Analytics
BigQuery
Any unusually high number of firewall rules modified in the past week?
By searching Admin Activity audit logs, the following query detects any unusually high number of firewall rules changes on any given day in the past week. To determine whether there is an outlier, the query performs statistical analysis over the daily counts of firewall rules changes. Averages and standard deviations are computed for each day by looking back at the preceding daily counts with a lookback window of 90 days. An outlier is considered when the daily count is more than two standard deviations above the mean. The query, including the standard deviation factor and the lookback windows, can all be configured to fit your cloud provisioning activity profile and to minimize false positives.
Log Analytics
BigQuery
Any VMs deleted in the past week?
By searching Admin Activity audit logs, the following query lists any Compute Engine instances deleted in the past week. This query can help you audit resource deletions and detect potential malicious activity.
Log Analytics
BigQuery
Workload usage questions
These sample queries perform analysis to understand who and what is consuming your cloud workloads and APIs, and help you detect potential malicious behavior internally or externally.
Any unusually high API usage by any user identity in the past week?
By analyzing all Cloud Audit Logs, the following query detects unusually high API usage by any user identity on any given day in the past week. Such unusually high usage might be an indicator of potential API abuse, insider threat, or leaked credentials. To determine whether there is an outlier, this query performs statistical analysis over the daily count of actions per principal. Averages and standard deviations are computed for each day and for each principal by looking back at the preceding daily counts with a lookback window of 60 days. An outlier is considered when the daily count for a user is more than three standard deviations above their mean. The query, including the standard deviation factor and the lookback windows, are all configurable to fit your cloud provisioning activity profile and to minimize false positives.
Log Analytics
BigQuery
What is the autoscaling usage per day in the past month?
By analyzing Admin Activity audit logs, the following query reports the autoscaling usage by day for the last month. This query can be used to identify patterns or anomalies that warrant further security investigation.
Log Analytics
BigQuery
Data access questions
These sample queries perform analysis to understand who is accessing or modifying data in Google Cloud.
Which users most frequently accessed data in the past week?
The following query uses the Data Access audit logs to find the user identities that most frequently accessed BigQuery tables data over the past week.
Log Analytics
BigQuery
Which users accessed the data in the "accounts" table last month?
The following query uses the Data Access audit logs to find the user
identities that most frequently queried a given accounts table over the past month.
Besides the MY_DATASET_ID and
MY_PROJECT_ID placeholders for your BigQuery
export destination, the following query uses the DATASET_ID
and PROJECT_ID placeholders. You need to replace to the
DATASET_ID and PROJECT_ID
placeholders in order to specify the target table whose access is being analyzed,
such as the accounts table in this example.
Log Analytics
BigQuery
What tables are most frequently accessed and by whom?
The following query uses the Data Access audit logs to find the BigQuery tables with most frequently read and modified data over the past month. It displays the associated user identity along with breakdown of total number of times data was read versus modified.
Log Analytics
BigQuery
What are the top 10 queries against BigQuery in the past week?
The following query uses the Data Access audit logs to find the most common queries over the past week. It also lists the corresponding users and the referenced tables.
Log Analytics
BigQuery
What are the most common actions recorded in the data access log over the past month?
The following query uses all logs from Cloud Audit Logs to find the 100 most frequent actions recorded over the past month.
Log Analytics
BigQuery
Network security questions
These sample queries perform analysis over your network activity in Google Cloud.
Any connections from a new IP address to a specific subnetwork?
The following query detects connections from any new source IP address to a given subnet by analyzing VPC Flow Logs. In this example, a source IP address is considered new if it was seen for the first time in the last 24 hours over a lookback window of 60 days. You might want to use and tune this query on a subnet that is in-scope for a particular compliance requirement like PCI.
Log Analytics
BigQuery
Any connections blocked by Google Cloud Armor?
The following query helps detect potential exploit attempts by analyzing external Application Load Balancer logs to find any connection blocked by the security policy configured in Google Cloud Armor. This query assumes that you have a Google Cloud Armor security policy configured on your external Application Load Balancer. This query also assumes that you have enabled external Application Load Balancer logging as described in the instructions that are provided by the Enable link in the log scoping tool.
Log Analytics
BigQuery
Any high-severity virus or malware detected by Cloud IDS?
The following query shows any high-severity virus or malware detected by Cloud IDS by searching Cloud IDS Threat Logs. This query assumes that you have a Cloud IDS endpoint configured.
Log Analytics
BigQuery
What are the top Cloud DNS queried domains from your VPC network?
The following query lists the top 10 Cloud DNS queried domains from your VPC network(s) over the last 60 days. This query assumes that you have enabled Cloud DNS logging for your VPC network(s) as described in the instructions that are provided by the Enable link in the log scoping tool.
Log Analytics
BigQuery
What's next
Look at how to stream logs from Google Cloud to Splunk.
Explore reference architectures, diagrams, and best practices about Google Cloud. Take a look at our Cloud Architecture Center.