This document describes an example of a pipeline implemented in Google Cloud that performs propensity modeling. It's intended for data engineers, machine learning engineers, or marketing science teams that create and deploy machine learning models. The document assumes that you know machine learning concepts and that you are familiar with Google Cloud, BigQuery, Vertex AI Pipelines, Python, and Jupyter notebooks. It also assumes that you have an understanding of Google Analytics 4 and of the raw export feature in BigQuery.
The pipeline that you work with uses Google Analytics sample data. The pipeline builds several models by using BigQuery ML and XGBoost, and you run the pipeline by using Vertex AI Pipelines. This document describes the processes of training the models, evaluating them, and deploying them. It also describes how you can automate the entire process.
The full pipeline code is in a Jupyter notebook in a GitHub repository.
What is propensity modeling?
Propensity modeling predicts actions that a consumer might take. Examples of propensity modeling include predicting which consumers are likely to buy a product, to sign up for a service, or even to churn and no longer be an active customer for a brand.
The output of a propensity model is a score between 0 and 1 for each consumer, where this score represents how likely the consumer is to take that action. One of the key drivers pushing organizations toward propensity modeling is the need to do more with first-party data. For marketing use cases, the best propensity models include signals both from online and offline sources, such as site analytics and CRM data.
This demo uses GA4 sample data that's in BigQuery. For your use case, you might want to consider additional offline signals.
How MLOps simplifies your ML pipelines
Most ML models aren't used in production. Model results generate insights, and frequently after data science teams finish a model, an ML engineering or software engineering team needs to wrap it in code for production using a framework such as Flask or FastAPI. This process often requires the model to be built in a new framework, which means that the data must be retransformed. This work can take weeks or months, and many models therefore don't make it to production.
Machine learning operations (MLOps) has become important for getting value from ML projects, and MLOps and is now an evolving skill set for data science organizations. To help organizations understand this value, Google Cloud has published a Practitioners Guide to MLOps that provides an overview of MLOps.
By using MLOps principles and Google Cloud, you can push models to an endpoint using an automatic process that removes much of the complexity of the manual process. The tools and process described in this document discuss an approach to owning your pipeline end to end, which helps you get your models into production. The practitioners guide document mentioned earlier provides a horizontal solution and an outline of what's possible using MLOps and Google Cloud.
What is Vertex AI Pipelines?
Vertex AI Pipelines lets you run ML pipelines that were built using either Kubeflow Pipelines SDK or TensorFlow Extended (TFX). Without Vertex AI, running either of these open source frameworks at scale requires you to set up and maintain your own Kubernetes clusters. Vertex AI Pipelines addresses this challenge. Because it's a managed service, it scales up or scales down as required, and it doesn't require ongoing maintenance.
Each step in the Vertex AI Pipelines process consists of an independent container that can take input or produce output in the form of artifacts. For example, if a step in the process builds your dataset, the output is the dataset artifact. This dataset artifact can be used as the input to the next step. Because each component is a separate container, you need to provide information for each component of the pipeline, such as the name of the base image and a list of any dependencies.
The pipeline build process
The example described in this document uses a Jupyter notebook to create the pipeline components and to compile, run, and automate them. As noted earlier, the notebook is in a GitHub repository.
You can run the notebook code using a Vertex AI Workbench user-managed notebooks instance, which handles authentication for you. Vertex AI Workbench lets you work with notebooks to create machines, build notebooks, and connect to Git. (Vertex AI Workbench includes many more features, but those aren't covered in this document.)
When the pipeline run finishes, a diagram similar to the following one is generated in Vertex AI Pipelines:
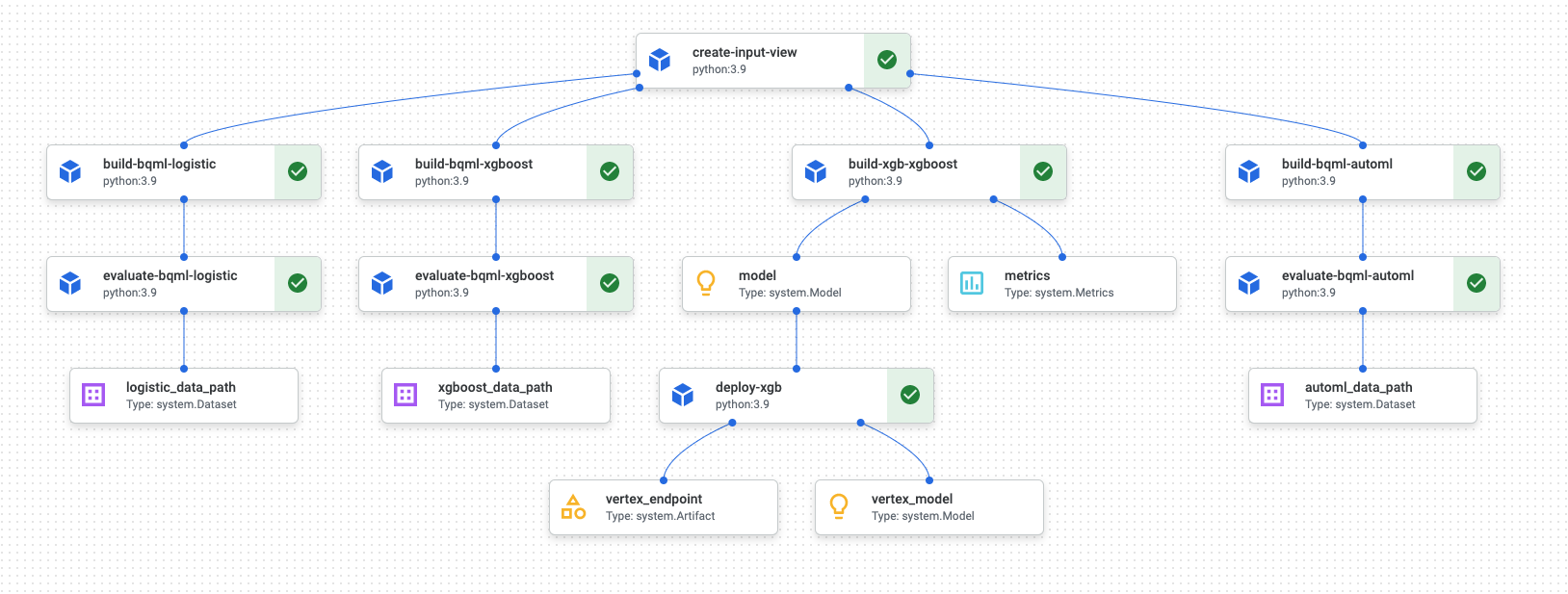
The preceding diagram is a directed acyclic graph (DAG). Building and reviewing the DAG is a central step to understanding your data or ML pipeline. The key attributes of DAGs are that components flow in a single direction (in this case, from top to bottom) and that no cycle occurs—that is, a parent component doesn't rely on its child component. Some components can occur in parallel, while others have dependencies and therefore occur in series.
The green checkbox in each component signifies that the code ran properly. If errors occurred, then you see a red exclamation point. You can click each component in the diagram to view more details of the job.
The DAG diagram is included in this section of the document to serve as a blueprint for each component that's built by the pipeline. The following list provides a description of each component.
The complete pipeline performs the following steps, as shown in the DAG diagram:
create-input-view: This component creates a BigQuery view. The component copies SQL from a Cloud Storage bucket and fills in parameter values that you provide. This BigQuery view is the input dataset that's used for all models later in the pipeline.build-bqml-logistic: The pipeline uses BigQuery ML to create a logistic regression model. When this component completes, a new model is viewable in the BigQuery console. You can use this model object to view model performance and later to build predictions.evaluate-bqml-logistic: The pipeline uses this component to create a precision/recall curve (logistic_data_pathin the DAG diagram) for the logistic regression. This artifact is stored in a Cloud Storage bucket.build-bqml-xgboost: This component creates an XGBoost model by using BigQuery ML. When this component completes, you can view a new model object (system.Model) in the BigQuery console. You can use this object to view model performance and later to build predictions.evaluate-bqml-xgboost: This component creates a precision/recall curve namedxgboost_data_pathfor the XGBoost model. This artifact is stored in a Cloud Storage bucket.build-xgb-xgboost: The pipeline creates an XGBoost model. This component uses Python instead of BigQuery ML so that you can see different approaches to creating the model. When this component completes, it stores a model object and performance metrics in a Cloud Storage bucket.deploy-xgb: This component deploys the XGBoost model. It creates an endpoint that allows either batch or online predictions. You can explore the endpoint in the Models tab in the Vertex AI console page. The endpoint autoscales to match traffic.build-bqml-automl: The pipeline creates an AutoML model by using BigQuery ML. When this component completes, a new model object is viewable in the BigQuery console. You can use this object to view model performance and later to build predictions.evaluate-bqml-automl: The pipeline creates a precision/recall curve for the AutoML model. The artifact is stored in a Cloud Storage bucket.
Notice that the process doesn't push the BigQuery ML models to an endpoint. That's because you can generate predictions directly from the model object that's in BigQuery. As you decide between using BigQuery ML and using other libraries for your solution, consider how predictions need to be generated. If a daily batch prediction satisfies your needs, then staying in the BigQuery environment can simplify your workflow. However, if you require real-time predictions, or if your scenario needs functionality that's in another library, then follow the steps in this document to push your saved model to an endpoint.
Costs
In this document, you use the following billable components of Google Cloud:
To generate a cost estimate based on your projected usage,
use the pricing calculator.
Before you begin
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
The Jupyter notebook for this scenario
The tasks for creating and building the pipeline are built into a Jupyter notebook that's in a GitHub repository.
To perform the tasks, you get the notebook and then run the code cells in the notebook in order. The flow described in this document assumes you're running the notebooks in Vertex AI Workbench.
Open the Vertex AI Workbench environment
You start by cloning the GitHub repository into a Vertex AI Workbench environment.
- In the Google Cloud console, select the project where you want to create the notebook.
Go to the Vertex AI Workbench page.
On the User-managed notebooks tab, click New Notebook.
In the list of notebook types, choose a Python 3 notebook.
In the New notebook, dialog, click Advanced Options and then under Machine type, select the machine type that you want to use. If you are unsure, then choose n1-standard-1 (1 cVPU, 3.75 GB RAM).
Click Create.
It takes a few moments for the notebook environment to be created.
When the notebook has been created, select the notebook, and then click Open Jupyterlab.
The JupyterLab environment opens in your browser.
To launch a terminal tab, select File > New > Launcher.
Click the Terminal icon in the Launcher tab.
In the terminal, clone the
mlops-on-gcpGitHub repository:git clone https://github.com/GoogleCloudPlatform/cloud-for-marketing/
When the command finishes, you see the
cloud-for-marketingfolder in the file browser.
Configure notebooks settings
Before you run the notebook, you must configure it. The notebook requires a Cloud Storage bucket to store pipeline artifacts, so you start by creating that bucket.
- Create a Cloud Storage bucket where the notebook can store pipeline artifacts. The name of the bucket must be globally unique.
- In the
cloud-for-marketing/marketing-analytics/predicting/kfp_pipeline/folder, open thePropensity_Pipeline.ipynbnotebook. - In the notebook, set the value of the
PROJECT_IDvariable to the ID of the Google Cloud project where you want to run the pipeline. - Set the value of the
BUCKET_NAMEvariable to the name of the bucket that you just created.
The remainder of this document describes code snippets that are important for understanding how the pipeline works. For the complete implementation, see the GitHub repository.
Build the BigQuery view
The first step in the pipeline generates the input data, which will be used to build each model. This Vertex AI Pipelines component generates a BigQuery view. To simplify the process of creating the view, some SQL has already been generated and saved in a text file in GitHub.
The code for each component begins by decorating (modifying a parent class or
function through attributes) the Vertex AI Pipelines component class. The code
then defines the create_input_view function, which is a step in the pipeline.
The function requires several inputs. Some of these values are currently
hardcoded into the code, like the start date and end date. When you automate
your pipeline, you can modify the code to use suitable values (for example,
using the
CURRENT_DATE
function for a date), or you can update the component to take these values as
parameters rather than keeping them hard-coded. You must also change the value
of ga_data_ref to the name of your GA4 table, and set the value of the
conversion variable to your conversion. (This example uses the public GA4
sample data.)
The following listing shows the code for the create-input-view component.
@component( # this component builds a BigQuery view, which will be the underlying source for model packages_to_install=["google-cloud-bigquery", "google-cloud-storage"], base_image="python:3.9", output_component_file="output_component/create_input_view.yaml", ) def create_input_view(view_name: str, data_set_id: str, project_id: str, bucket_name: str, blob_path: str ): from google.cloud import bigquery from google.cloud import storage client = bigquery.Client(project=project_id) dataset = client.dataset(data_set_id) table_ref = dataset.table(view_name) ga_data_ref = 'bigquery-public-data.google_analytics_sample.ga_sessions_*' conversion = "hits.page.pageTitle like '%Shopping Cart%'" start_date = '20170101' end_date = '20170131' def get_sql(bucket_name, blob_path): from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket(bucket_name) blob = bucket.get_blob(blob_path) content = blob.download_as_string() return content def if_tbl_exists(client, table_ref): ... else: content = get_sql() content = str(content, 'utf-8') create_base_feature_set_query = content. format(start_date = start_date, end_date = end_date, ga_data_ref = ga_data_ref, conversion = conversion) shared_dataset_ref = client.dataset(data_set_id) base_feature_set_view_ref = shared_dataset_ref.table(view_name) base_feature_set_view = bigquery.Table(base_feature_set_view_ref) base_feature_set_view.view_query = create_base_feature_set_query.format(project_id) base_feature_set_view = client.create_table(base_feature_set_view)
Build the BigQuery ML model
After the view is created, you run the component named build_bqml_logistic to
build a BigQuery ML model. This block of the notebook is a core
component. Using the training view that you created in the first block, it
builds a BigQuery ML model. In this example, the notebook uses
logistic regression.
For information about model types and the hyperparameters available, see the BigQuery ML reference documentation.
The following listing shows the code for this component.
@component( # this component builds a logistic regression with BigQuery ML packages_to_install=["google-cloud-bigquery"], base_image="python:3.9", output_component_file="output_component/create_bqml_model_logistic.yaml" ) def build_bqml_logistic(project_id: str, data_set_id: str, model_name: str, training_view: str ): from google.cloud import bigquery client = bigquery.Client(project=project_id) model_name = f"{project_id}.{data_set_id}.{model_name}" training_set = f"{project_id}.{data_set_id}.{training_view}" build_model_query_bqml_logistic = ''' CREATE OR REPLACE MODEL `{model_name}` OPTIONS(model_type='logistic_reg' , INPUT_LABEL_COLS = ['label'] , L1_REG = 1 , DATA_SPLIT_METHOD = 'RANDOM' , DATA_SPLIT_EVAL_FRACTION = 0.20 ) AS SELECT * EXCEPT (fullVisitorId, label), CASE WHEN label is null then 0 ELSE label end as label FROM `{training_set}` '''.format(model_name = model_name, training_set = training_set) job_config = bigquery.QueryJobConfig() client.query(build_model_query_bqml_logistic, job_config=job_config)
Use XGBoost instead of BigQuery ML
The component illustrated in the previous section uses BigQuery ML. The next section of the notebooks shows you how to use XGBoost in Python directly instead of using BigQuery ML.
You run the component named build_bqml_xgboost to build the component to run a
standard XGBoost classification model with a grid search. The code then saves
the model as an artifact in the Cloud Storage bucket that you created.
The function supports additional parameters (metrics and model) for output
artifacts; these parameters are required by Vertex AI Pipelines.
@component( # this component builds an xgboost classifier with xgboost packages_to_install=["google-cloud-bigquery", "xgboost", "pandas", "sklearn", "joblib", "pyarrow"], base_image="python:3.9", output_component_file="output_component/create_xgb_model_xgboost.yaml" ) def build_xgb_xgboost(project_id: str, data_set_id: str, training_view: str, metrics: Output[Metrics], model: Output[Model] ): ... data_set = f"{project_id}.{data_set_id}.{training_view}" build_df_for_xgboost = ''' SELECT * FROM `{data_set}` '''.format(data_set = data_set) ... xgb_model = XGBClassifier(n_estimators=50, objective='binary:hinge', silent=True, nthread=1, eval_metric="auc") random_search = RandomizedSearchCV(xgb_model, param_distributions=params, n_iter=param_comb, scoring='precision', n_jobs=4, cv=skf.split(X_train,y_train), verbose=3, random_state=1001 ) random_search.fit(X_train, y_train) xgb_model_best = random_search.best_estimator_ predictions = xgb_model_best.predict(X_test) score = accuracy_score(y_test, predictions) auc = roc_auc_score(y_test, predictions) precision_recall = precision_recall_curve(y_test, predictions) metrics.log_metric("accuracy",(score * 100.0)) metrics.log_metric("framework", "xgboost") metrics.log_metric("dataset_size", len(df)) metrics.log_metric("AUC", auc) dump(xgb_model_best, model.path + ".joblib")
Build an endpoint
You run the component named deploy_xgb to build an endpoint by using the
XGBoost model from the previous section. The component takes the previous
XGBoost model artifact, builds a container, and then deploys the endpoint, while
also providing the endpoint URL as an artifact so that you can view it. When
this step is completed, a Vertex AI endpoint has been created and
you can view the endpoint in the console page for Vertex AI.
@component( # Deploys xgboost model packages_to_install=["google-cloud-aiplatform", "joblib", "sklearn", "xgboost"], base_image="python:3.9", output_component_file="output_component/xgboost_deploy_component.yaml", ) def deploy_xgb( model: Input[Model], project_id: str, vertex_endpoint: Output[Artifact], vertex_model: Output[Model] ): from google.cloud import aiplatform aiplatform.init(project=project_id) deployed_model = aiplatform.Model.upload( display_name="tai-propensity-test-pipeline", artifact_uri = model.uri.replace("model", ""), serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/xgboost-cpu.1-4:latest" ) endpoint = deployed_model.deploy(machine_type="n1-standard-4") # Save data to the output params vertex_endpoint.uri = endpoint.resource_name vertex_model.uri = deployed_model.resource_name
Define the pipeline
To define the pipeline, you define each operation based on the components that you created previously. You can then specify the order of the pipeline elements if those aren't explicitly called in the component.
For example, the following code in the notebook defines a pipeline. In this
case, the code requires the build_bqml_logistic_op component to run after the
create_input_view_op component.
@dsl.pipeline( # Default pipeline root. You can override it when submitting the pipeline. pipeline_root=PIPELINE_ROOT, # A name for the pipeline. name="pipeline-test", description='Propensity BigQuery ML Test' ) def pipeline(): create_input_view_op = create_input_view( view_name = VIEW_NAME, data_set_id = DATA_SET_ID, project_id = PROJECT_ID, bucket_name = BUCKET_NAME, blob_path = BLOB_PATH ) build_bqml_logistic_op = build_bqml_logistic( project_id = PROJECT_ID, data_set_id = DATA_SET_ID, model_name = 'bqml_logistic_model', training_view = VIEW_NAME ) # several components have been deleted for brevity build_bqml_logistic_op.after(create_input_view_op) build_bqml_xgboost_op.after(create_input_view_op) build_bqml_automl_op.after(create_input_view_op) build_xgb_xgboost_op.after(create_input_view_op) evaluate_bqml_logistic_op.after(build_bqml_logistic_op) evaluate_bqml_xgboost_op.after(build_bqml_xgboost_op) evaluate_bqml_automl_op.after(build_bqml_automl_op)
Compile and run the pipeline
You can now compile and run the pipeline.
The following code in the notebook sets the enable_caching value to true in
order to enable caching. When caching is enabled, any previous runs where a
component has successfully completed won't be re-run. This flag is useful
especially when you're testing the pipeline because when caching is enabled, the
run completes faster and uses fewer resources.
compiler.Compiler().compile( pipeline_func=pipeline, package_path="pipeline.json" ) TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S") run = pipeline_jobs.PipelineJob( display_name="test-pipeine", template_path="pipeline.json", job_id="test-{0}".format(TIMESTAMP), enable_caching=True ) run.run()
Automate the pipeline
At this stage, you've launched the first pipeline. You can check the Vertex AI Pipelines page in the console to see the status of this job. You can watch as each container is built and run. You can also track errors for specific components in this section by clicking each one.
To schedule the pipeline, you build a Cloud Run function and use a scheduler that's similar to a cron job.
The code in the last section of the notebook schedules the pipeline to run once a day, as shown in the following code snippet:
from kfp.v2.google.client import AIPlatformClient api_client = AIPlatformClient(project_id=PROJECT_ID, region='us-central1' ) api_client.create_schedule_from_job_spec( job_spec_path='pipeline.json', schedule='0 * * * *', enable_caching=False )
Use the finished pipeline in production
The completed pipeline has performed the following tasks:
- Created an input dataset.
- Trained several models using both BigQuery ML as well as Python's XGBoost.
- Analyzed model results.
- Deployed the XGBoost model.
You've also automated the pipeline by using Cloud Run functions and Cloud Scheduler to run daily.
The pipeline that's defined in the notebook was created to illustrate ways to create various models. You wouldn't run the pipeline as it is currently built in a production scenario. However, you can use this pipeline as a guide and modify the components to suit your needs. For example, you can edit the feature-creation process to take advantage of your data, modify date ranges, and perhaps build alternative models. You would also pick the model from among those illustrated that best meets your production requirements.
When the pipeline is ready for production, you might implement additional tasks. For example, you might implement a champion/challenger model, where each day a new model is created and both the new model (the challenger) and the existing one (the champion) are scored on new data. You put the new model into production only if its performance is better than the performance of the current model. To monitor progress of your system, you might also keep a record of each day's model performance and visualize trending performance.
Clean up
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
What's next
- To learn about using MLOps to create production-ready ML systems, see Practitioners Guide to MLOps.
- To learn about Vertex AI, see the Vertex AI documentation.
- To learn about Kubeflow Pipelines, see the KFP documentation.
- To learn about TensorFlow Extended, see the TFX User Guide.
- For an overview of architectural principles and recommendations that are specific to AI and ML workloads in Google Cloud, see the AI and ML perspective in the Well-Architected Framework.
- For more reference architectures, diagrams, and best practices, explore the Cloud Architecture Center.
Contributors
Author: Tai Conley | Cloud Customer Engineer
Other contributor: Lars Ahlfors | Cloud Customer Engineer