This tutorial is the second part of a series that shows you how to build an end-to-end solution to give data analysts secure access to data when using business intelligence (BI) tools.
This tutorial is intended for operators and IT administrators who set up environments that provide data and processing capabilities to the business intelligence (BI) tools used by data analysts.
Tableau is used as the BI tool in this tutorial. To follow along with this tutorial, you must have Tableau Desktop installed on your workstation.
The series is made up of the following parts:
- The first part of the series, Architecture for connecting visualization software to Hadoop on Google Cloud, defines the architecture of the solution, its components, and how the components interact.
- This second part of the series tells you how to set up the architecture components that make up the end-to-end Hive topology on Google Cloud. The tutorial uses open source tools from the Hadoop ecosystem, with Tableau as the BI tool.
The code snippets in this tutorial are available in a GitHub repository. The GitHub repository also includes Terraform configuration files to help you set up a working prototype.
Throughout the tutorial, you use the name sara as the fictitious user identity
of a data analyst. This user identity is in the LDAP directory that
both Apache Knox and Apache Ranger use. You can also choose to configure LDAP groups, but this procedure is
outside the scope of this tutorial.
Objectives
- Create an end-to-end setup that enables a BI tool to use data from a Hadoop environment.
- Authenticate and authorize user requests.
- Set up and use secure communication channels between the BI tool and the cluster.
Costs
In this document, you use the following billable components of Google Cloud:
To generate a cost estimate based on your projected usage,
use the pricing calculator.
Before you begin
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Cloud SQL, and Cloud Key Management Service (Cloud KMS) APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Cloud SQL, and Cloud Key Management Service (Cloud KMS) APIs.
Initializing your environment
-
In the Google Cloud console, activate Cloud Shell.
In Cloud Shell, set environment variables with your project ID, and the region and zones of the Dataproc clusters:
export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-bYou can choose any region and zone, but keep them consistent as you follow this tutorial.
Setting up a service account
In Cloud Shell, create a service account.
gcloud iam service-accounts create cluster-service-account \ --description="The service account for the cluster to be authenticated as." \ --display-name="Cluster service account"The cluster uses this account to access Google Cloud resources.
Add the following roles to the service account:
- Dataproc Worker: to create and manage Dataproc clusters.
- Cloud SQL Editor: for Ranger to connect to its database using Cloud SQL Proxy.
Cloud KMS CryptoKey Decrypter: to decrypt the passwords encrypted with Cloud KMS.
bash -c 'array=( dataproc.worker cloudsql.editor cloudkms.cryptoKeyDecrypter ) for i in "${array[@]}" do gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "serviceAccount:cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com" \ --role roles/$i done'
Creating the backend cluster
In this section, you create the backend cluster where Ranger is located. You also create the Ranger database to store the policy rules, and a sample table in Hive to apply the Ranger policies.
Create the Ranger database instance
Create a MySQL instance to store the Apache Ranger policies:
export CLOUD_SQL_NAME=cloudsql-mysql gcloud sql instances create ${CLOUD_SQL_NAME} \ --tier=db-n1-standard-1 --region=${REGION}This command creates an instance called
cloudsql-mysqlwith the machine typedb-n1-standard-1located in the region specified by the${REGION}variable. For more information, see the Cloud SQL documentation.Set the instance password for the user
rootconnecting from any host. You can use the example password for demonstrative purposes, or create your own. If you create your own password, use a minimum of eight characters, including at least one letter and one number.gcloud sql users set-password root \ --host=% --instance ${CLOUD_SQL_NAME} --password mysql-root-password-99
Encrypt the passwords
In this section, you create a cryptographic key to encrypt the passwords for Ranger and MySQL. To prevent exfiltration, you store the cryptographic key in Cloud KMS. For security purposes, you can't view, extract, or export the key bits.
You use the cryptographic key to encrypt the passwords and write them into files.
You upload these files into a Cloud Storage bucket so that they are
accessible to the service account that is acting on behalf of the clusters.
The service account can decrypt these files because it has the
cloudkms.cryptoKeyDecrypter role and access to the files and the cryptographic
key. Even if a file is exfiltrated, the file can't be decrypted without the role
and the key.
As an extra security measure, you create separate password files for each service. This action minimizes the potential impacted area if a password is exfiltrated.
For more information about key management, see the Cloud KMS documentation.
In Cloud Shell, create a Cloud KMS key ring to hold your keys:
gcloud kms keyrings create my-keyring --location globalTo encrypt your passwords, create a Cloud KMS cryptographic key:
gcloud kms keys create my-key \ --location global \ --keyring my-keyring \ --purpose encryptionEncrypt your Ranger admin user password using the key. You can use the example password or create your own. Your password must be a minimum of eight characters, including at least one letter and one number.
echo "ranger-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-admin-password.encryptedEncrypt your Ranger database admin user password with the key:
echo "ranger-db-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-db-admin-password.encryptedEncrypt your MySQL root password with the key:
echo "mysql-root-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=mysql-root-password.encryptedCreate a Cloud Storage bucket to store encrypted password files:
gcloud storage buckets create gs://${PROJECT_ID}-ranger --location=${REGION}Upload the encrypted password files to the Cloud Storage bucket:
gcloud storage cp *.encrypted gs://${PROJECT_ID}-ranger
Create the cluster
In this section, you create a backend cluster with Ranger support. For more information about the Ranger optional component in Dataproc, see the Dataproc Ranger Component documentation page.
In Cloud Shell, create a Cloud Storage bucket to store the Apache Solr audit logs:
gcloud storage buckets create gs://${PROJECT_ID}-solr --location=${REGION}Export all the variables required in order to create the cluster:
export BACKEND_CLUSTER=backend-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-b export CLOUD_SQL_NAME=cloudsql-mysql export RANGER_KMS_KEY_URI=\ projects/${PROJECT_ID}/locations/global/keyRings/my-keyring/cryptoKeys/my-key export RANGER_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-admin-password.encrypted export RANGER_DB_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-db-admin-password.encrypted export MYSQL_ROOT_PWD_URI=\ gs://${PROJECT_ID}-ranger/mysql-root-password.encryptedFor convenience, some of the variables that you set before are repeated in this command so you can modify them as you require.
The new variables contain:
- The name of the backend cluster.
- The URI of the cryptographic key so that the service account can decrypt the passwords.
- The URI of the files containing the encrypted passwords.
If you used a different key ring or key, or different filenames, use the corresponding values in your command.
Create the backend Dataproc cluster:
gcloud beta dataproc clusters create ${BACKEND_CLUSTER} \ --optional-components=SOLR,RANGER \ --region ${REGION} \ --zone ${ZONE} \ --enable-component-gateway \ --scopes=default,sql-admin \ --service-account=cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com \ --properties="\ dataproc:ranger.kms.key.uri=${RANGER_KMS_KEY_URI},\ dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PWD_URI},\ dataproc:ranger.db.admin.password.uri=${RANGER_DB_ADMIN_PWD_URI},\ dataproc:ranger.cloud-sql.instance.connection.name=${PROJECT_ID}:${REGION}:${CLOUD_SQL_NAME},\ dataproc:ranger.cloud-sql.root.password.uri=${MYSQL_ROOT_PWD_URI},\ dataproc:solr.gcs.path=gs://${PROJECT_ID}-solr,\ hive:hive.server2.thrift.http.port=10000,\ hive:hive.server2.thrift.http.path=cliservice,\ hive:hive.server2.transport.mode=http"This command has the following properties:
- The final three lines in the command are the Hive properties to configure HiveServer2 in HTTP mode, so that Apache Knox can call Apache Hive through HTTP.
- The other parameters in the command operate as follows:
- The
--optional-components=SOLR,RANGERparameter enables Apache Ranger and its Solr dependency. - The
--enable-component-gatewayparameter enables the Dataproc Component Gateway to make the Ranger and other Hadoop user interfaces available directly from the cluster page in Google Cloud console. When you set this parameter, there is no need for SSH tunneling to the backend master node. - The
--scopes=default,sql-adminparameter authorizes Apache Ranger to access its Cloud SQL database.
- The
If you need to create an external Hive metastore that persists beyond the lifetime
of any cluster and can be used across multiple clusters, see Using Apache Hive on Dataproc.
To run the procedure, you must run the table creation examples directly
on Beeline. While the gcloud dataproc jobs submit hive commands use Hive binary transport, these commands
aren't compatible with HiveServer2 when it's configured in HTTP mode.
Create a sample Hive table
In Cloud Shell, create a Cloud Storage bucket to store a sample Apache Parquet file:
gcloud buckets create gs://${PROJECT_ID}-hive --location=${REGION}Copy a publicly available sample Parquet file into your bucket:
gcloud storage cp gs://hive-solution/part-00000.parquet \ gs://${PROJECT_ID}-hive/dataset/transactions/part-00000.parquetConnect to the master node of the backend cluster you created in the previous section using SSH:
gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-mThe name of your cluster master node is the name of the cluster followed by
-m.The HA cluster master node names have an extra suffix.If it's your first time connecting to your master node from Cloud Shell, you are prompted to generate SSH keys.
In the terminal you opened with SSH, connect to the local HiveServer2 using Apache Beeline, which is pre-installed on the master node:
beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice admin admin-password"\ --hivevar PROJECT_ID=$(gcloud info --format='value(config.project)')This command starts the Beeline command-line tool and passes the name of your Google Cloud project in an environment variable.
Hive isn't performing any user authentication, but to perform most tasks it requires a user identity. The
adminuser here is a default user that's configured in Hive. The identity provider that you configure with Apache Knox later in this tutorial handles user authentication for any requests that come from BI tools.In the Beeline prompt, create a table using the Parquet file you previously copied to your Hive bucket:
CREATE EXTERNAL TABLE transactions (SubmissionDate DATE, TransactionAmount DOUBLE, TransactionType STRING) STORED AS PARQUET LOCATION 'gs://${PROJECT_ID}-hive/dataset/transactions';Verify that the table was created correctly:
SELECT * FROM transactions LIMIT 10; SELECT TransactionType, AVG(TransactionAmount) AS AverageAmount FROM transactions WHERE SubmissionDate = '2017-12-22' GROUP BY TransactionType;The results of the two queries appear in the Beeline prompt.
Exit the Beeline command-line tool:
!quitCopy the internal DNS name of the backend master:
hostname -A | tr -d '[:space:]'; echoYou use this name in the next section as
backend-master-internal-dns-nameto configure the Apache Knox topology. You also use the name to configure a service in Ranger.Exit the terminal on the node:
exit
Creating the proxy cluster
In this section, you create the proxy cluster that has the Apache Knox initialization action.
Create a topology
In Cloud Shell, clone the Dataproc initialization-actions GitHub repository:
git clone https://github.com/GoogleCloudDataproc/initialization-actions.gitCreate a topology for the backend cluster:
export KNOX_INIT_FOLDER=`pwd`/initialization-actions/knox cd ${KNOX_INIT_FOLDER}/topologies/ mv example-hive-nonpii.xml hive-us-transactions.xmlApache Knox uses the name of the file as the URL path for the topology. In this step, you change the name to represent a topology called
hive-us-transactions. You can then access the fictitious transaction data that you loaded into Hive in Create a sample Hive tableEdit the topology file:
vi hive-us-transactions.xmlTo see how backend services are configured, see the topology descriptor file. This file defines a topology that points to one or more backend services. Two services are configured with sample values: WebHDFS and HIVE. The file also defines the authentication provider for the services in this topology and the authorization ACLs.
Add the data analyst sample LDAP user identity
sara.<param> <name>hive.acl</name> <value>admin,sara;*;*</value> </param>Adding the sample identity lets the user access the Hive backend service through Apache Knox.
Change the HIVE URL to point to the backend cluster Hive service. You can find the HIVE service definition at the bottom of the file, under WebHDFS.
<service> <role>HIVE</role> <url>http://<backend-master-internal-dns-name>:10000/cliservice</url> </service>Replace the
<backend-master-internal-dns-name>placeholder with the internal DNS name of the backend cluster that you acquired in Create a sample Hive table.Save the file and close the editor.
To create additional topologies, repeat the steps in this section. Create one independent XML descriptor for each topology.
In Create the proxy cluster you copy these files into a Cloud Storage bucket. To create new topologies, or change them after you create the proxy cluster, modify the files, and upload them again to the bucket. The Apache Knox initialization action creates a cron job that regularly copies changes from the bucket to the proxy cluster.
Configure the SSL/TLS certificate
A client uses an SSL/TLS certificate when it communicates with Apache Knox. The initialization action can generate a self-signed certificate, or you can provide your CA-signed certificate.
In Cloud Shell, edit the Apache Knox general configuration file:
vi ${KNOX_INIT_FOLDER}/knox-config.yamlReplace
HOSTNAMEwith the external DNS name of your proxy master node as the value for thecertificate_hostnameattribute. For this tutorial, uselocalhost.certificate_hostname: localhostLater in this tutorial, you create an SSH tunnel and the proxy cluster for the
localhostvalue.The Apache Knox general configuration file also contains the
master_keythat encrypts the certificates BI tools use to communicate with the proxy cluster. By default, this key is the wordsecret.If you are providing your own certificate, change the following two properties:
generate_cert: false custom_cert_name: <filename-of-your-custom-certificate>Save the file and close the editor.
If you are providing your own certificate, you can specify it in the property
custom_cert_name.
Create the proxy cluster
In Cloud Shell, create a Cloud Storage bucket:
gcloud storage buckets create gs://${PROJECT_ID}-knox --location=${REGION}This bucket provides the configurations you created in the previous section to the Apache Knox initialization action.
Copy all the files from the Apache Knox initialization action folder to the bucket:
gcloud storage cp ${KNOX_INIT_FOLDER}/* gs://${PROJECT_ID}-knox --recursiveExport all the variables required in order to create the cluster:
export PROXY_CLUSTER=proxy-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-bIn this step, some of the variables that you set before are repeated so that you can make modifications as required.
Create the proxy cluster:
gcloud dataproc clusters create ${PROXY_CLUSTER} \ --region ${REGION} \ --zone ${ZONE} \ --service-account=cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com \ --initialization-actions gs://goog-dataproc-initialization-actions-${REGION}/knox/knox.sh \ --metadata knox-gw-config=gs://${PROJECT_ID}-knox
Verify the connection through proxy
After the proxy cluster is created, use SSH to connect to its master node from Cloud Shell:
gcloud compute ssh --zone ${ZONE} ${PROXY_CLUSTER}-mFrom the terminal of the proxy cluster's master node, run the following query:
beeline -u "jdbc:hive2://localhost:8443/;\ ssl=true;sslTrustStore=/usr/lib/knox/data/security/keystores/gateway-client.jks;trustStorePassword=secret;\ transportMode=http;httpPath=gateway/hive-us-transactions/hive"\ -e "SELECT SubmissionDate, TransactionType FROM transactions LIMIT 10;"\ -n admin -p admin-password
This command has the following properties:
- The
beelinecommand useslocalhostinstead of the DNS internal name because the certificate that you generated when you configured Apache Knox specifieslocalhostas the host name. If you are using your own DNS name or certificate, use the corresponding host name. - The port is
8443, which corresponds to the Apache Knox default SSL port. - The line that begins
ssl=trueenables SSL and provides the path and password for the SSL Trust Store to be used by client applications such as Beeline. - The
transportModeline indicates that the request should be sent over HTTP and provides the path for the HiveServer2 service. The path is composed of the keywordgateway, the topology name that you defined in a previous section, and the service name configured in the same topology, in this casehive. - The
-eparameter provides the query to run on Hive. If you omit this parameter, you open an interactive session in the Beeline command-line tool. - The
-nparameter provides a user identity and password. In this step, you are using the default Hiveadminuser. In the next sections, you create an analyst user identity and set up credentials and authorization policies for this user.
Add a user to the authentication store
By default, Apache Knox includes an authentication provider that is based on
Apache Shiro.
This authentication provider is configured with BASIC authentication against an
ApacheDS LDAP store. In this section, you add a sample data analyst
user identity sara to the authentication store.
From the terminal in the proxy's master node, install the LDAP utilities:
sudo apt-get install ldap-utilsCreate an LDAP Data Interchange Format (LDIF) file for the new user
sara:export USER_ID=sara printf '%s\n'\ "# entry for user ${USER_ID}"\ "dn: uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org"\ "objectclass:top"\ "objectclass:person"\ "objectclass:organizationalPerson"\ "objectclass:inetOrgPerson"\ "cn: ${USER_ID}"\ "sn: ${USER_ID}"\ "uid: ${USER_ID}"\ "userPassword:${USER_ID}-password"\ > new-user.ldifAdd the user ID to the LDAP directory:
ldapadd -f new-user.ldif \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389The
-Dparameter specifies the distinguished name (DN) to bind when the user that is represented byldapaddaccesses the directory. The DN must be a user identity that is already in the directory, in this case the useradmin.Verify that the new user is in the authentication store:
ldapsearch -b "uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org" \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389The user details appear in your terminal.
Copy and save the internal DNS name of the proxy master node:
hostname -A | tr -d '[:space:]'; echoYou use this name in the next section as
<proxy-master-internal-dns-name>to configure the LDAP synchronization.Exit the terminal on the node:
exit
Setting up authorization
In this section, you configure identity synchronization between the LDAP service and Ranger.
Sync user identities into Ranger
To ensure that Ranger policies apply to the same user identities as Apache Knox, you configure the Ranger UserSync daemon to sync the identities from the same directory.
In this example, you connect to the local LDAP directory that is available by default with Apache Knox. However, in a production environment, we recommend that you set up an external identity directory. For more information, see the Apache Knox User's Guide and the Google Cloud Cloud Identity, Managed Active Directory, and Federated AD documentation.
Using SSH, connect to the master node of the backend cluster that you created:
export BACKEND_CLUSTER=backend-cluster gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-mIn the terminal, edit the
UserSyncconfiguration file:sudo vi /etc/ranger/usersync/conf/ranger-ugsync-site.xmlSet the values of the following LDAP properties. Make sure that you modify the
userproperties and not thegroupproperties, which have similar names.<property> <name>ranger.usersync.sync.source</name> <value>ldap</value> </property> <property> <name>ranger.usersync.ldap.url</name> <value>ldap://<proxy-master-internal-dns-name>:33389</value> </property> <property> <name>ranger.usersync.ldap.binddn</name> <value>uid=admin,ou=people,dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.ldap.ldapbindpassword</name> <value>admin-password</value> </property> <property> <name>ranger.usersync.ldap.user.searchbase</name> <value>dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.source.impl.class</name> <value>org.apache.ranger.ldapusersync.process.LdapUserGroupBuilder</value> </property>Replace the
<proxy-master-internal-dns-name>placeholder with the internal DNS name of the proxy server, which you retrieved in the last section.These properties are a subset of a full LDAP configuration that syncs both users and groups. For more information, see How to integrate Ranger with LDAP.
Save the file and close the editor.
Restart the
ranger-usersyncdaemon:sudo service ranger-usersync restartRun the following command:
grep sara /var/log/ranger-usersync/*If the identities are synched, you see at least one log line for the user
sara.
Creating Ranger policies
In this section, you configure a new Hive service in Ranger. You also set up and test a Ranger policy to limit the access to the Hive data for a specific identity.
Configure the Ranger service
From the terminal of the master node, edit the Ranger Hive configuration:
sudo vi /etc/hive/conf/ranger-hive-security.xmlEdit the
<value>property of theranger.plugin.hive.service.nameproperty:<property> <name>ranger.plugin.hive.service.name</name> <value>ranger-hive-service-01</value> <description> Name of the Ranger service containing policies for this YARN instance </description> </property>Save the file and close the editor.
Restart the HiveServer2 Admin service:
sudo service hive-server2 restartYou are ready to create Ranger policies.
Set up the service in the Ranger Admin console
In the Google Cloud console, go to the Dataproc page.
Click your backend cluster name, and then click Web Interfaces.
Because you created your cluster with Component Gateway, you see a list of the Hadoop components that are installed in your cluster.
Click the Ranger link to open the Ranger console.
Log in to Ranger with the user
adminand your Ranger admin password. The Ranger console shows the Service Manager page with a list of services.Click the plus sign in the HIVE group to create a new Hive service.

In the form, set the following values:
- Service name:
ranger-hive-service-01. You previously defined this name in theranger-hive-security.xmlconfiguration file. - Username:
admin - Password:
admin-password jdbc.driverClassName: keep the default name asorg.apache.hive.jdbc.HiveDriverjdbc.url:jdbc:hive2:<backend-master-internal-dns-name>:10000/;transportMode=http;httpPath=cliservice- Replace the
<backend-master-internal-dns-name>placeholder with the name you retrieved in a previous section.
- Service name:
Click Add.
Each Ranger plugin installation supports a single Hive service. An easy way to configure additional Hive services is to start up additional backend clusters. Each cluster has its own Ranger plugin. These clusters can share the same Ranger DB, so that you have a unified view of all the services whenever you access the Ranger Admin console from any of those clusters.
Set up a Ranger policy with limited permissions
The policy allows the sample analyst LDAP user sara access to specific
columns of the Hive table.
On the Service Manager window, click the name of the service you created.
The Ranger Admin console shows the Policies window.
Click Add New Policy.
With this policy, you give
sarathe permission to see only the columnssubmissionDateandtransactionTypefrom table transactions.In the form, set the following values:
- Policy name: any name, for example
allow-tx-columns - Database:
default - Table:
transactions - Hive column:
submissionDate, transactionType - Allow conditions:
- Select user:
sara - Permissions:
select
- Select user:
- Policy name: any name, for example
At the bottom of the screen, click Add.
Test the policy with Beeline
In the master node terminal, start the Beeline command-line tool with the user
sara.beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice sara user-password"Although the Beeline command-line tool doesn't enforce the password, you must provide a password to run the preceding command.
Run the following query to verify that Ranger blocks it.
SELECT * FROM transactions LIMIT 10;The query includes the column
transactionAmount, whichsaradoesn't have permission to select.A
Permission deniederror displays.Verify that Ranger allows the following query:
SELECT submissionDate, transactionType FROM transactions LIMIT 10;Exit the Beeline command-line tool:
!quitExit the terminal:
exitIn the Ranger console, click the Audit tab. Both denied and allowed events display. You can filter the events by the service name you previously defined, for example,
ranger-hive-service-01.
Connecting from a BI tool
The final step in this tutorial is to query the Hive data from Tableau Desktop.
Create a firewall rule
- Copy and save your public IP address.
In Cloud Shell, create a firewall rule that opens TCP port
8443for ingress from your workstation:gcloud compute firewall-rules create allow-knox\ --project=${PROJECT_ID} --direction=INGRESS --priority=1000 \ --network=default --action=ALLOW --rules=tcp:8443 \ --target-tags=knox-gateway \ --source-ranges=<your-public-ip>/32Replace the
<your-public-ip>placeholder with your public IP address.Apply the network tag from the firewall rule to the proxy cluster's master node:
gcloud compute instances add-tags ${PROXY_CLUSTER}-m --zone=${ZONE} \ --tags=knox-gateway
Create an SSH tunnel
This procedure is only necessary if you're using a self-signed certificate
valid for localhost. If you are using your own certificate or your proxy master
node has its own external DNS name, you can skip to Connect to Hive.
In Cloud Shell, generate the command to create the tunnel:
echo "gcloud compute ssh ${PROXY_CLUSTER}-m \ --project ${PROJECT_ID} \ --zone ${ZONE} \ -- -L 8443:localhost:8443"Run
gcloud initto authenticate your user account and grant access permissions.Open a terminal in your workstation.
Create an SSH tunnel to forward port
8443. Copy the command generated in the first step and paste it into the workstation terminal, and then run the command.Leave the terminal open so that the tunnel remains active.
Connect to Hive
- On your workstation, install the Hive ODBC driver.
- Open Tableau Desktop, or restart it if it was open.
- On the home page under Connect / To a Server, select More.
- Search for and then select Cloudera Hadoop.
Using the sample data analyst LDAP user
saraas the user identity, fill out the fields as follows:- Server: If you created a tunnel, use
localhost. If you didn't create a tunnel, use the external DNS name of your proxy master node. - Port:
8443 - Type:
HiveServer2 - Authentication:
UsernameandPassword - Username:
sara - Password:
sara-password - HTTP Path:
gateway/hive-us-transactions/hive - Require SSL:
yes
- Server: If you created a tunnel, use
Click Sign In.

Query Hive data
- On the Data Source screen, click Select Schema and search for
default. Double-click the
defaultschema name.The Table panel loads.
In the Table panel, double-click New Custom SQL.
The Edit Custom SQL window opens.
Enter the following query, which selects the date and transaction type from the transactions table:
SELECT `submissiondate`, `transactiontype` FROM `default`.`transactions`Click OK.
The metadata for the query is retrieved from Hive.
Click Update Now.
Tableau retrieves the data from Hive because
sarais authorized to read these two columns from thetransactionstable.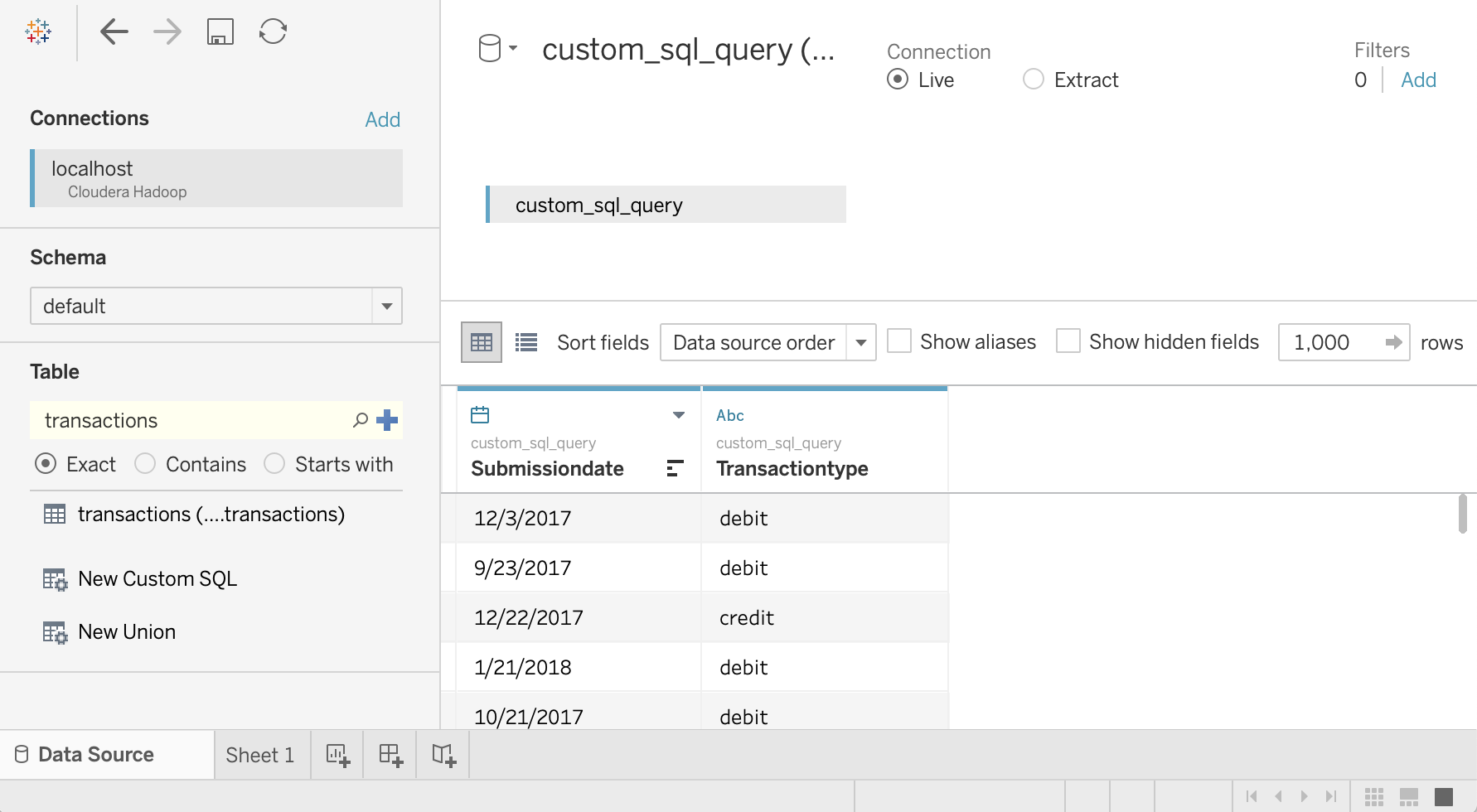
To try to select all columns from the
transactionstable, in the Table panel, double-click New Custom SQL again. The Edit Custom SQL window opens.Enter the following query:
SELECT * FROM `default`.`transactions`Click OK. The following error message displays:
Permission denied: user [sara] does not have [SELECT] privilege on [default/transactions/*].Because
saradoesn't have authorization from Ranger to read thetransactionAmountcolumn, this message is expected. This example shows how you can limit what data Tableau users can access.To see all the columns, repeat the steps using the user
admin.Close Tableau and your terminal window.
Clean up
To avoid incurring charges to your Google Cloud account for the resources used in this tutorial, either delete the project that contains the resources, or keep the project and delete the individual resources.
Delete the project
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
What's next
- Read the first part of this series: Architecture to connect your Visualization Software to Hadoop on Google Cloud.
- Read the Hadoop migration Security Guide.
- Learn how to migrate on-premises Hadoop infrastructure to Google Cloud.
- Explore reference architectures, diagrams, and best practices about Google Cloud. Take a look at our Cloud Architecture Center.