This document answers frequently asked questions (FAQs) about NetApp Cloud Volumes Service for Google Cloud.
Application resilience FAQs
The following sections provide answers to frequently asked questions about application resilience in NetApp Cloud Volumes Service for Google Cloud.
Do I need to take special precautions for SMB-based applications?
Yes. SMB Transparent Failover is required for certain SMB-based applications. SMB Transparent Failover enables maintenance operations on SMB volumes within Cloud Volumes Service without interrupting connectivity to server applications storing and accessing data. Cloud Volumes Service supports the SMB Continuously Available shares option to make sure specific applications support SMB Transparent Failover. Using SMB Continuously Available shares is only supported for workloads on the following applications:
FSLogix user profile containers
Microsoft SQL Server
Linux SQL Server isn't supported.
Custom applications aren't supported with SMB Continuously Available shares.
Performance FAQs
The following list of FAQs include commonly asked questions about NetApp Cloud Volumes Service performance.
How do I measure volume performance?
Performance depends on latency and workload parameters. Use the I/O generator tool, fio to test performance.
Learn how to measure volume performance.
How can I read fio results?
Fio applies a workload, which you can specify through a command line interface or a configuration file. While running, fio shows a progress indicator with current throughput and input and output operations per second (IOPS) numbers. After it ends, a detailed summary displays.
The following examples show a single-threaded, 4k random write job running for
60 seconds which is a useful way to measure baseline latency. In the following
commands, the -directory parameter points to a folder with a
mounted and mapped cloud volume share:
$ fio --directory=/netapp --ioengine=libaio --rw=randwrite --bs=4k --iodepth=1 --size=10g --fallocate=none --direct=1 --runtime=60 --time_based --ramp_time=5 --name=cvs
cvs: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=1
fio-3.28
Starting 1 process
cvs: Laying out IO file (1 file / 10240MiB)
Jobs: 1 (f=1): [w(1)][100.0%][w=7856KiB/s][w=1964 IOPS][eta 00m:00s]
cvs: (groupid=0, jobs=1): err= 0: pid=1891: Wed Dec 21 14:56:37 2022
write: IOPS=1999, BW=7999KiB/s (8191kB/s)(469MiB/60001msec); 0 zone resets
slat (usec): min=4, max=417, avg=12.06, stdev= 5.71
clat (usec): min=366, max=27978, avg=483.59, stdev=91.34
lat (usec): min=382, max=28001, avg=495.96, stdev=91.89
clat percentiles (usec):
| 1.00th=[ 408], 5.00th=[ 429], 10.00th=[ 437], 20.00th=[ 449],
| 30.00th=[ 461], 40.00th=[ 469], 50.00th=[ 482], 60.00th=[ 490],
| 70.00th=[ 498], 80.00th=[ 515], 90.00th=[ 529], 95.00th=[ 553],
| 99.00th=[ 611], 99.50th=[ 652], 99.90th=[ 807], 99.95th=[ 873],
| 99.99th=[ 1020]
bw ( KiB/s): min= 7408, max= 8336, per=100.00%, avg=8002.05, stdev=140.09, samples=120
iops : min= 1852, max= 2084, avg=2000.45, stdev=35.06, samples=120
lat (usec) : 500=70.67%, 750=29.17%, 1000=0.15%
lat (msec) : 2=0.01%, 4=0.01%, 50=0.01%
cpu : usr=2.04%, sys=3.25%, ctx=120561, majf=0, minf=58
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,119984,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=7999KiB/s (8191kB/s), 7999KiB/s-7999KiB/s (8191kB/s-8191kB/s), io=469MiB (491MB), run=60001-60001msec
The following lines are relevant:
Latency:
lat (usec): min=382, max=28001, avg=495.96, stdev=91.89The average latency is 495.96 microseconds (usec), which is roughly 0.5 microseconds, an ideal latency.
IOPS:
iops : min= 1852, max= 2084, avg=2000.45, stdev=35.06, samples=120The preceding example shows an average of 2000 IOPS. That value is expected for a single-threaded job with 0.5 ms latency (IOPS = 1000 ms/0.5 ms = 2000).
Throughput:
bw ( KiB/s): min= 7408, max= 8336, per=100.00%, avg=8002.05, stdev=140.09,The throughout average is 8002 KiB/s, which is the expected result for 2000 IOPS with a block size of 4 KiB (2000 1/s * 4 KiB = 8000 KiB/s).
Measure latency
Latency is a fundamental metric for volume performance. It is a result of client and server capabilities, the distance between the client and the server (your volume), and the equipment in between. The main component of the metric is distance-induced latency.
You can measure latency by pinging the IP address of your volume. The round-trip time is the estimated latency. This measurement only works for volumes of the CVS-Performance type. Volumes of the CVS service type don't answer the Internet Control Message Protocol requests.
Latency also depends on the block size and whether you are performing read or write operations. NetApp recommends that you use the following parameters to measure the baseline latency between your client and a volume:
Linux:
fio --directory=/netapp \ --ioengine=libaio \ --rw=randwrite \ --bs=4k \ --iodepth=1 \ --size=10g \ --fallocate=none \ --direct=1 \ --runtime=60 \ --time_based \ --ramp_time=5 \ --name=cvsWindows: (volume mapped to drive `Z:`)
fio --directory=Z\:\ --ioengine=windowsaio \ --thread \ --rw=randwrite \ --bs=4k \ --iodepth=1 \ --size=10g \ --fallocate=none \ --direct=1 \ --runtime=60 \ --time_based \ --ramp_time=5 \ --name=cvs
Replace the parameters for rw (read/write/randread/randwrite) and bs (block
size), to fit your workload. Larger block sizes result in higher latency,
where reads are faster than writes. The results can be found in the lat row
as described previously.
Measure IOPS
IOPS are a direct result of latency and concurrency.
Linux:
fio --directory=/netapp \ --ioengine=libaio \ --rw=randread \ --bs=8k \ --iodepth=32 \ --size=10g \ --fallocate=none \ --direct=1 \ --runtime=60 \ --time_based \ --ramp_time=5 \ --name=cvsWindows: volume mapped to drive
Z:\fio --directory=Z\:\ --ioengine=windowsaio \ --thread \ --rw=randread \ --bs=8k \ --iodepth=32 \ --size=10g \ --fallocate=none \ --direct=1 \ --runtime=60 \ --time_based \ --ramp_time=5 \ --name=cvs
Replace the parameters for rw (read/write/randread/randwrite) and bs
(block size), and iodepth (concurrency), to fit your workload. The results can
be found in the iops row as described previously.
Measure throughput
Throughput is IOPS multiplied by block size.
Linux:
fio --directory=/netapp \ --ioengine=libaio \ --rw=read \ --bs=64k \ --iodepth=32 \ --size=10g \ --fallocate=none \ --direct=1 \ --runtime=60 \ --time_based \ --ramp_time=5 \ --name=cvsWindows: volume mapped to drive
Z:\fio --directory=Z\:\ --ioengine=windowsaio \ --thread \ --rw=randread \ --bs=8k \ --iodepth=32 \ --size=10g \ --fallocate=none \ --direct=1 \ --runtime=60 \ --time_based \ --ramp_time=5 \ --name=cvs
Replace the parameters for rw (read, write, randread, and randwrite), bs
(blocksize), and iodepth (concurrency), to fit your workload. High throughput can
only be achieved using large block sizes (64k or larger) and high concurrency.
The results can be found in the bw row as described previously.
What kind of client tuning enhances performance?
The capabilities and location of the client impact latency results, especially location. Place the client in the same region as the volume or as close as possible. For the CVS service type, place the client in the same zone. For CVS-Performance, test the zonal impact by testing latency from a client in each zone. Not all zones in a region have the same latency to CVS-Performance. After testing, use the zone with the lowest latency.
Make sure your client is fast enough to meet your performance goals. Different instance types have varying network capabilities. The network capabilities of Compute Engine VMs depend on the instance type used. Typically, larger instances can drive more network throughput. For more information about Compute Engine network capabilities, see Compute Engine documentation on network bandwidth.
If your application requires high throughput, you might eventually saturate the single TCP session underlying a normal Network File System (NFS) and Server Message Block (SMB) session. For such cases, try increasing the number of Transmission Control Protocol (TCP) connections your NFS and SMB connection uses.
For Linux based clients, use the
nconnect mount option when
mounting the NFS share. Recommended values for nconnect are 4, 6, or 8.
Selecting a value over 8 has diminishing returns. Only use nconnect for
clients requiring high bandwidth levels. Overuse can oversubscribe the
NFS operations queue of the NFS server, which results in higher latencies. For
more information, see What are the Linux NFS concurrency recommendations?.
For Windows-based clients, enable SMB Multichannel on the share.
Learn more about SMB Multichannel benefits and performance in our SMB Performance FAQs.
How do I use Cloud Monitoring to track volume performance statistics?
Cloud Monitoring tracks multiple performance metrics per volume. The metrics update every five minutes and provide a good overview of performance trends for periods of one day or longer. See Cloud Monitoring for details. To observe current current, short-lived, or both, performance events, consider using the monitoring tools available on the clients.
How do I collect NFS performance statistics on Linux?
The NFS client built into Linux provides detailed statistics on its activities.
nfsiostat provides information like IOPS (ops/s), throughput (kB/s), block
size (kB/op), and latency (avg RTT (ms)). The information is split into
read and write per NFS mount. It can be used to monitor traffic in real time.
mountstats shows detailed information on each NFS mount, split by NFS
operation type. Each operation type shows the number of requests, the average
number of transferred bytes, and the average latency.
nfsstat shows how often the different NFS operations are called. This
statistic can be used to determine the read and write ratio of your workload and
helps to determine how metadata-intensive, metadata operations versus read+write,
it is.
If your Linux installation doesn't provide these tools, consult your
distributions package management system to determine which package provides them.
For Debian-based systems like Ubuntu, they are provided in nfs-common.
How do I collect SMB performance statistics on Windows?
Windows clients provide real-time performance metrics using the Windows Performance Monitor.
The Performance Monitor app and command line,
perfmon,
can be used to access the metrics. The Performance Monitor shows real-time graphs
and collects data to create reports.
You can map a network share to see performance metrics like IOPS and latency. SMB metrics are found under SMB Client Shares. Metrics are available for every mapped share.
The following table shows the Cloud Volumes Service metrics and their corresponding names in the Windows Performance Monitor.
| Metric | SMB client shares performance monitor name |
|---|---|
| Block size | Average data bytes per request |
| Latency | Average second per data request
Use scale 1000 for milliseconds. |
| IOPS | Data requests per second |
| Throughput | Data bytes per second |
| Concurrency | Average data queue length
Current data queue length |
| Read and write ratio | Read bytes per second versus write bytes per second |
| Non-read and write requests, like listing a directory, reading file attributes, and deleting files. |
Metadata requests per second |
Security FAQs
The following section provides answers to frequently asked questions about the security and architecture elements of the Cloud Volumes Service for Google Cloud.
For details, including information about how data is encrypted, see the NetApp technical report TR-4918: Security overview - NetApp Cloud Volumes Service in Google Cloud.
Is the data encrypted in transit between a cloud volume and a Compute Engine instance?
Data traverses over standard Virtual Private Cloud constructs between a cloud volume and a Compute Engine instance that inherit any in-transit encryption features provided by those constructs.
You can enable SMB encryption on a volume.
You can enable NFSv4.1 Kerberos encryption on a volume of the CVS-Performance service type.
How is access to the data in a cloud volume restricted to specific Compute Engine instances or users?
For NFS volumes, access to mount volumes is controlled by export policies. You can set up to five export policies per volume to control which instances—by IP addresses—have access and what kind of access (read only, read/write) they have.
For SMB volumes, a user-supplied Active Directory server is required. The Active Directory server handles authentication and authorization to the SMB cloud volume, and you can configure it to handle granular access with NTFS ACLs.
Are there IAM controls to specify who can administer Cloud Volumes Service?
Yes. Cloud Volumes Service provides granular permissions for all objects in the
Cloud Volumes Service API such as volumes, snapshots, and Active Directory.
These granular permissions are fully integrated into the IAM
framework. The permissions are integrated into two predefined roles:
netappcloudvolumes.admin and netappcloudvolumes.viewer. You can
assign these roles to users and groups per project to control administration
rights for Cloud Volumes Service. For more information, see
Permissions for Cloud Volumes Service.
How is access to the Cloud Volumes Service API secured?
There are two layers of security to access the Cloud Volumes Service API:
Authentication: The caller of the API is required to supply valid JSON web tokens. For details, see Manage API authentication. You can disable or delete service accounts to revoke the ability to make calls to the Cloud Volumes Service API.
Authorization: Cloud Volumes Service checks the granular permission against IAM for each operation requested on the API—when an authenticated request is received. Authentication alone is not sufficient to access the API.
For more information about how to set up a service account, obtain permissions, and call the Cloud Volumes Service API, see Cloud Volumes APIs.
I can't see my VPCs in the Cloud Volumes Service user interface. What's wrong?
When you create a storage pool or a volume, you need to specify which VPC to attach it to. The dialog VPC Network Name is provided to select available VPCs. For shared VPCs, a host project can be specified to list the shared VPCs.
If the VPC Network Name dialog doesn't list your host project or the shared VPCs of the host project, this is an indication that your user account is missing Identity and Access Management permissions to look up the necessary networks.
Add the following permissions from the host project to your user account to find the VPCs:
compute.networks.list: Queries for Shared VPC networks in host project.resourcemanager.projects.get: Queries for host project name.servicenetworking.services.get: Queries for PSA configuration.
If the standalone project doesn't show local VPCs, add compute.networks.list
to your user account in the standalone project.
How does Cloud Volumes Service support the Netlogon protocol changes related to CVE-2022-38023?
In June 2023, NetApp added support for RPC Sealing with the Netlogon protocol to Cloud Volumes Service. The service now works with prior Windows Server releases as well as those updated to address the vulnerability described in CVE-2022-38023.
For more information, see KB5021130: How to manage the Netlogon protocol changes related to CVE-2022-38023.
NFS FAQs
This section provides answers to FAQs about the NFS elements of the Cloud Volumes Service for Google Cloud.
How does NFSv4.1 handle user identifiers?
Cloud Volumes Service enables numerical user identifiers for NFSv4.1
using sec=sys. That means Unix user IDs and group identifiers are used to
identify users and groups. It also means that NFSv4.1 clients should work
immediately without complex user identity management. The only exception is the
root user, who functions properly as root, but gets displayed as
UID=4294967294 (nobody) in the ls output. To fix this, edit the
/etc/idmapd.conf configuration file in your clients to contain the following:
domain = defaultv4iddomain.com
If you're using LDAP, then use the fully qualified domain name (FQDN) for your AD domain:
domain = FQDN_of_AD_domain
Modern Linux clients are configured to support numerical IDs by default. If your client doesn't, you can enable numerical IDs with the following command:
echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping
Why are some files owned by user nobody when using NFSv4.1?
See How does NFSv4.1 handle user identifiers?
What are the Linux NFS concurrency recommendations?
NFSv3 does not have a mechanism to negotiate concurrency between the client and
the server. The client and the server each defines its limit without consulting
the other. For the best performance, use the maximum number of client-side
sunrpc slot table entries that doesn't cause pushback on the server. When a
client overwhelms the server network stack's ability to process a workload, the
server responds by decreasing the window size for the connection, which can
decrease performance.
By default, modern Linux kernels define the per-connection slot table entry size
(sunrpc.max_tcp_slot_table_entries) as supporting 65,536 outstanding
operations, and volumes of the CVS service type enforce a limit of 128 slots for
each NFS TCP connection. You do not need to use values this high. In queueing
theory,
Little's Law
says that concurrency is the product of the operation rate and the latency. This
means that the I/O rate is determined by concurrency, that is, outstanding I/O,
and latency. 65,536 is orders of magnitude more than the number of slots needed
for even extremely demanding workloads.
For example, a latency of 0.5 ms and a concurrency of 128 can achieve up to 256,000 IOPS. A latency of 1 ms and a concurrency of 128 can achieve up to 128,000 IOPS.
Recommendations
- NFS clients with normal traffic infrequently use more than 128 slots, so you do not need to take any action for these clients.
If you have a few clients that need to push heavy NFS traffic (for example, databases or compute applications), limit their queues to 128 slots by setting the kernel parameter
sunrpc.tcp_max_slot_table_entriesto 128. The way to make the setting persist depends on the Linux distribution:- Red Hat Enterprise Linux: How do I configure TCP maximum slot table entries to 128 for RHEL 7/8 NFS clients?
- SUSE Linux Enterprise: SLES 12 (or higher) NFS client has occasional slow performance against NetApp NFS server
If your application requires higher IOPS, consider using the
nconnectmount option to use multiple TCP connections.If you have many clients—more than 30—that need to push heavy NFS traffic—such as in compute farms for high performance computing (HPC) or electronic design automation (EDA) workflows—consider setting
sunrpc.tcp_max_slot_table_entriesto 16 to improve aggregated performance. Thesunrpc.tcp_max_slot_table_entrieskernel parameter is only available after thesunrpckernel module is loaded. It is loaded automatically by thenfskernel module.
SMB FAQs
This section provides answers to FAQs about the SMB elements of the Cloud Volumes Service for Google Cloud.
Why does the cloud volumes SMB NetBIOS name not reflect the name configured for the cloud volume?
NetBIOS names have a length of 15 characters. You can specify up to 10 characters, and Cloud Volumes Service adds a suffix of a hyphen and 4 random hexadecimal digits to form the full NetBIOS name.
Example: \\myvolname becomes \\myvolname-c372
Why can't my client resolve the SMB NetBIOS name?
You can map or mount an SMB share created with Cloud Volumes Service by using
its uniform naming convention (UNC) path, which the UI displays. A UNC path
follows the pattern \\HOSTNAME\SHARENAME
(for example, \\cvssmb-d2e6.cvsdemo.internal\quirky-youthful-hermann). The
hostname is only resolvable through the AD's built-in DNS servers.
NetApp recommends following the best practices for running Active Directory onGoogle Cloud. These best practices provide recommendations on how to connect Microsoft Active Directory DNS to Cloud DNS using a private forward zone. After you set up Cloud DNS private forwarding zones, your Compute Engine VMs can resolve DNS names managed by AD.
If you need to resolve hostnames to IPs without creating the DNS forward, you can use the following commands:
Linux:
dig @AD_SERVER_IP_ADDRESS +short cvssmb-d2e6.cvsdemo.internal
Windows:
nslookup cvssmb-d2e6.cvsdemo.internal AD_SERVER_IP_ADDRESS
How can I check whether my SMB share is using SMB encryption?
When you map an SMB share, the client and server negotiate the SMB version and features, such as SMB encryption. After you enable SMB encryption for a volume, the CVS SMB server requires SMB encryption. This means that only SMB3 clients that support SMB encryption can access the volume.
To verify whether your SMB connection is using SMB encryption, map a CVS share and run the following PowerShell command:
Get-SmbConnection -servername [CVS_IP_OR_NETBIOS_NAME] | Select-Object -Property Encrypted
How can I identify Active Directory domain controllers used by the CVS and CVS-Performance service types?
Cloud Volumes Service uses Active Directory connections to configure volumes of the CVS and CVS-Performance service types. Each service type can have one AD connection for each Google Cloud region.
Microsoft recommends placing Active Directory domain controllers (DCs) close to SMB servers for good performance. For Google Cloud, place DCs in the same region where Cloud Volumes Service is used. For the CVS service type, DCs must be in the same region; otherwise, volumes of the CVS service type can't connect to DCs. NetApp recommends having at least two DCs for each region, for service resilience.
Cloud Volumes Service uses standard DNS-based discovery to find suitable DCs. Use the following query to get the list of all DCs in your domain:
Windows:
nslookup -type=srv _ldap._tcp.dc._msdcs.<domain-name> <dns-server>Linux:
dig @<dns-server> +short SRV _ldap._tcp.dc._msdcs.<domain-name>
For volumes of the CVS service type, you must limit the list to DCs installed only in a given Google Cloud region. For volumes of the CVS-Performance service type, limiting the list is recommended, but not required. When you create an Active Directory site, make sure that it contains only DCs located in the desired Google Cloud region. After you create a site, use the following command to check which DCs are contained in the list:
Windows:
nslookup -type=srv _ldap._tcp.<site_name>._sites.dc._msdcs.<domain-name> <dns-server>Linux:
dig @<dns-server> +short SRV _ldap._tcp.<site_name>._sites.dc._msdcs.<domain-name>
Verify that the returned list only contains DCs that are in the desired Google Cloud region.
In your Active Directory connection configuration, enter the AD site name.
Which permissions are needed to create Active Directory machine accounts?
To add CVS machine objects to a Windows Active Directory, you need an account that either has administrative rights to the domain or has delegated permissions to create and modify machine account objects to a specified organizational unit (OU). You can grant these permissions with the Delegation of Control Wizard in Active Directory by creating a custom task that provides a user access to creation and deletion of computer objects with the following access permissions provided:
Read/Write
Create/Delete All Child Objects
Read/Write All Properties
Change/Reset Password (Read and write domain password and lockout policies)
Creating this custom task adds a security ACL for the defined user to the organizational unit in Active Directory and minimizes the access to the Active Directory environment. When a user is delegated, that username and password can be provided as Active Directory credentials in this window.
SMB performance FAQs
This section answers FAQs about SMB performance best practices for Cloud Volumes Service for Google Cloud.
Is SMB Multichannel enabled by default in SMB shares?
Yes, SMB Multichannel is enabled by default. All existing SMB volumes have the feature enabled, and all newly created volumes also have the feature enabled.
You need to reset any SMB connection established prior to the feature enablement to take advantage of the SMB Multichannel functionality. To reset, disconnect and reconnect the SMB share.
Does Cloud Volumes Service support receive-side scaling (RSS)?
With SMB Multichannel enabled, an SMB3 client establishes multiple TCP connections to the Cloud Volumes Service SMB server over a network interface card (NIC) that is single RSS capable.
Which Windows versions support SMB Multichannel?
Windows has supported SMB Multichannel since Windows 2012. For more information, see Deploy SMB Multichannel and The basics of SMB Multichannel.
Do Google Cloud virtual machines support RSS?
To see if your Google Cloud virtual machine NICs support RSS,
run the command
Get-SmbClientNetworkInterface from PowerShell. Then in the output, check the
RSS Capable column:

Does Cloud Volumes Service for Google Cloud support SMB Direct?
No, SMB Direct is not supported at the moment.
What is the benefit of SMB Multichannel?
The SMB Multichannel feature enables an SMB3 client to establish a pool of connections over a single network interface card (NIC) or multiple NICs and to use them to send requests for a single SMB session. In contrast, by design, SMB1 and SMB2 require the client to establish one connection and send all the SMB traffic for a given session over that connection. This single connection limits the overall protocol performance from a single client.
Is there value in configuring multiple NICs on the SMB client?
Each Cloud Volumes Service volume is only attached to a single VPC network. Google Compute Engine VMs only support one NIC per VPC network. You can't configure multiple NICs to access a single Cloud Volumes Service volume.
Is NIC Teaming supported in Cloud Volumes Service for Google Cloud?
NIC Teaming is not supported in Cloud Volumes Service for Google Cloud. Although multiple network interfaces are supported on Google Cloud virtual machines, each interface is attached to a different VPC network. Also, the bandwidth available to a Google Cloud virtual machine is calculated for the machine itself and not any individual network interface.
What's the performance for SMB Multichannel?
SMB Multichannel only applies to volumes of the CVS-Performance service type.
The following tests and graphs demonstrate the power of SMB Multichannel on single-instance workloads.
Random I/O
With SMB Multichannel disabled on the client, 4-KiB read and write tests were
performed using FIO and a 40-GiB working set. The SMB share was detached between
each test, with increments of the SMB client connection count per RSS network
interface settings of 1,4,8,6,
set-SmbClientConfiguration-ConnectionCountPerRSSNetworkInterface count.
The tests show that the default setting of 4 is sufficient for I/O intensive
workloads; incrementing to 8 and 16 has no effect and as such has been left off
of the following graph.

During the test, the command netstat -na | findstr 445 shows that additional
connections were established with increments from 1 to 4, to 8, and to 16. Four
CPU cores were fully utilized for SMB during each test, as confirmed by the
perfmon Per Processor Network Activity Cycles statistic—not included in this
document.
Sequential I/O
Tests similar to the random I/O tests were performed with 64-KiB sequential I/O. As with the random I/O tests, increasing the client connection count per RSS network interface beyond four had no noticeable effect on sequential I/O. The following graph compares the sequential throughput tests.

Therefore, it's best to follow the Microsoft best practice to use default RSS network tunables.
What test parameters were used to produce the performance graphs above?
The following configuration file was used with the Flexible IO (fio) load
generator. Note that the iodepth parameter is marked as TBD. By
increasing the iodepth value test by test, IO and throughput maximums were
determined.
[global]
name=fio-test
directory=.\ #This is the directory where files are written
direct=1 #Use directio
numjobs=1 #To match how many users on the system
nrfiles=4 #Num files per job
runtime=300 #If time_based is set, run for this amount of time
time_based #This setting says run the jobs until run time elapses
bs=64K||4K
rw=rw||randrw #choose rw if sequential io, choose randrw for random io
rwmixread=100||0 #<-- Modify to get different i/o distributions
iodepth=TBD #<-- Modify this to get the i/o they want (latency * target op count)
size=40G #Aggregate file size per job (if nrfiles = 4, files=2.5GiB)
ramp_time=20 #Warm up
[test]
What performance is expected with a single VM with a 1 TiB dataset?
SMB Multichannel only applies to volumes of the CVS-Performance service type.
To provide more detailed insight into workloads with read/write mixes, the
following two charts show the performance of a single, Extreme service-level
cloud volume of 50 TiB with a 1 TiB dataset and with an SMB multichannel of 4.
An optimal IODepth of 16 was used, and Flexible I/O (fio) parameters were used to
ensure the full use of the network bandwidth (numjobs=16).
The following chart shows the results for 4k random I/O, with a single VM instance and a read/write mix at 10% intervals:

The following chart shows the results for sequential I/O:

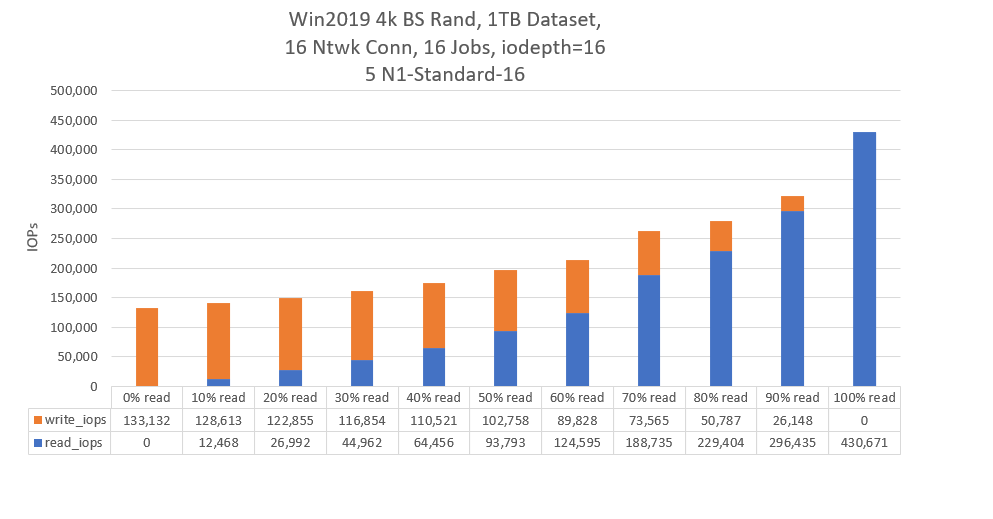
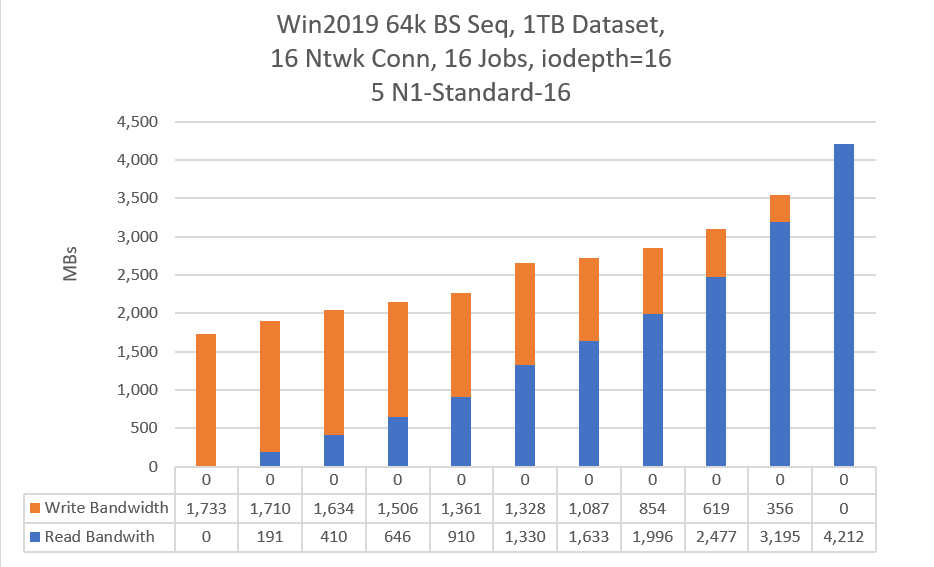
What performance is expected when scaling out using 5 VMs with a 1 TiB dataset?
SMB Multichannel only applies to volumes of the CVS-Performance service type.
These tests with five VMs use the same testing environment as the single VM, with each process writing to its own file.
The following chart shows the results for random I/O:
The following chart shows the results for sequential I/O:
How do you monitor VirtIO ethernet adapters and ensure that you maximize network capacity?
One strategy used in testing with fio is to set numjobs=16. Doing so forks
each job into 16 specific instances to maximize the Google VirtIO Ethernet
Adapter.
You can check for activity on each of the adapters in Windows Performance Monitor using the following steps:
Go to Performance monitor.
Select Add counters.
Select Network interface.
Select Google VirtIO ethernet adapter.
After you have data traffic running in your volumes, you can monitor your adapters in Windows Performance Monitor. If you do not use all of these 16 virtual adapters, you might not maximize your network bandwidth capacity.
Are jumbo frames supported?
Jumbo frames are not supported with Compute Engine virtual machines.
What is SMB Signing, and is it supported by Cloud Volumes Service for Google Cloud?
The SMB protocol provides the basis for file and print sharing and other networking operations such as remote Windows administration. To prevent man-in-the-middle attacks that modify SMB packets in transit, the SMB protocol supports the digital signing of SMB packets.
SMB Signing is supported for all SMB protocol versions that are supported by Cloud Volumes Service for Google Cloud.
What is the performance impact of SMB Signing?
SMB Signing has a detrimental effect upon SMB performance. Among other potential causes of the performance degradation, the digital signing of each packet consumes additional client-side CPU. In this case, Core 0 appears responsible for SMB, including SMB Signing. A comparison using the CVS-Performance service type with the non-multichannel sequential read throughput numbers from the sequential I/O section shows that SMB Signing reduces overall throughput from 875 MiB/s to approximately 250 MiB/s.
Capacity management FAQs
This section provides answers to FAQs about the capacity-management elements of the Cloud Volumes Service for Google Cloud.
How do I determine if a directory is approaching the limit size?
You can use the stat command from a Cloud Volumes Service client to see
whether a directory is approaching the maximum size limit (320 MB).
For a 320 MB directory, the number of 512-byte blocks is 655360 (320x1024x1024/512).
Examples:
[makam@cycrh6rtp07 ~]$ stat bin
File: 'bin'
Size: 4096 Blocks: 8 IO Block: 65536 directory
[makam@cycrh6rtp07 ~]$ stat tmp
File: 'tmp'
Size: 12288 Blocks: 24 IO Block: 65536 directory
[makam@cycrh6rtp07 ~]$ stat tmp1
File: 'tmp1'
Size: 4096 Blocks: 8 IO Block: 65536 directory
Billing FAQs
This section provides answers to billing-related FAQs about the Cloud Volumes Service for Google Cloud.
How do I change the billing account for Cloud Volumes Service?
You can change the billing account used for Cloud Volumes Service by first enabling the service with the new billing account. After you've enabled the new account, disable the old account. To learn more, see Change the Cloud Billing account linked to a project.
Can I be billed for accessing my cloud volume from a Compute Engine instance located in a different region or zone?
Yes, standard Google Cloud inter-region data movement is charged according to the transfer rates.
CVS service-type volumes: If your Compute Engine instance is located within the same zone as the cloud volume, you are not charged for any traffic movement. If your Compute Engine instance is located in a different zone than the cloud volume, you are charged for traffic movement between zones.
CVS-Performance service-type volumes: If your Compute Engine instance is located within the same region as the cloud volume, you are not charged for any traffic movement, even if that movement occurs within different zones in a region.