Dataproc and Google Cloud contain several features that can help secure your data. This guide explains how Hadoop security works and how it translates to Google Cloud, providing guidance on how to architect security when deploying on Google Cloud.
Overview
The typical security model and mechanism for an on-premises Hadoop deployment are different than the security model and mechanism provided by the cloud. Understanding security on Hadoop can help you to better architect security when deploying on Google Cloud.
You can deploy Hadoop on Google Cloud in two ways: as Google-managed clusters (Dataproc), or as user-managed clusters (Hadoop on Compute Engine). Most of the content and technical guidance in this guide applies to both forms of deployment. This guide uses the term Dataproc/Hadoop when referring to concepts or procedures that apply to either type of deployment. The guide points out the few cases where deploying to Dataproc differs from deploying to Hadoop on Compute Engine.
Typical on-premises Hadoop security
The following diagram shows a typical on-premises Hadoop infrastructure and how it is secured. Note how the basic Hadoop components interact with each other and with user management systems.
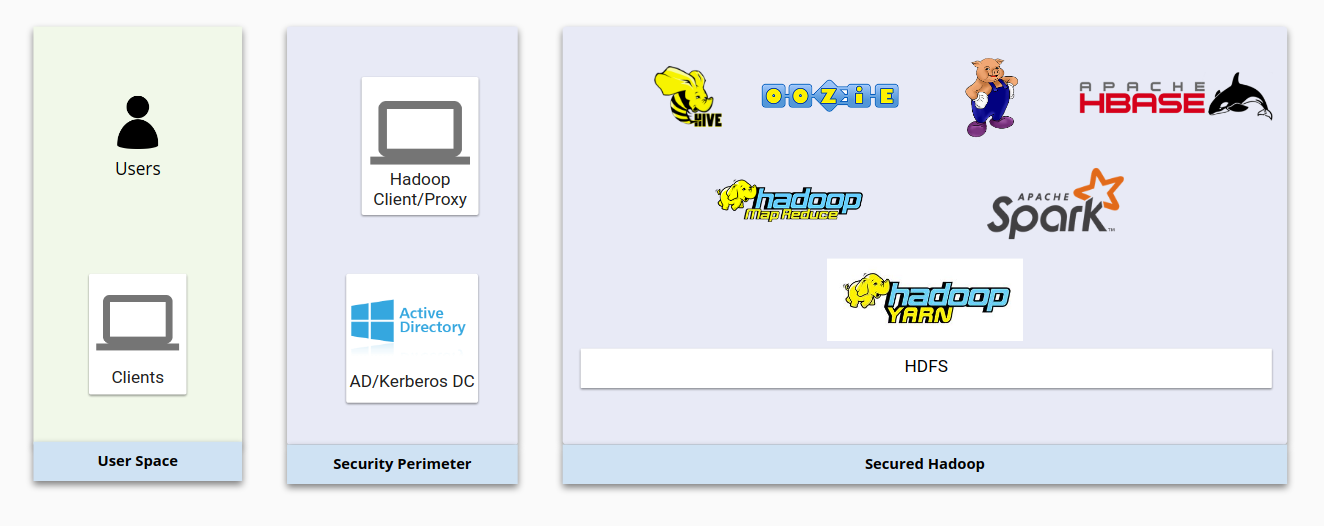
Overall, Hadoop security is based on these four pillars:
- Authentication is provided through Kerberos integrated with LDAP or Active Directory
- Authorization is provided through HDFS and security products like Apache Sentry or Apache Ranger, which ensure that users have the right access to Hadoop resources.
- Encryption is provided through network encryption and HDFS encryption, which together secure data both in transit and at rest.
- Auditing is provided by vendor-supplied products such as Cloudera Navigator.
From the perspective of the user account, Hadoop has its own user and group structure to both manage identities and to run daemons. The Hadoop HDFS and YARN daemons, for example, run as Unix users hdfs and yarn, as explained in Hadoop in Secure Mode.
Hadoop users are usually mapped from Linux system users or Active Directory/LDAP users. Active Directory users and groups are synced by tools such as Centrify or RedHat SSSD.
Hadoop on-premises authentication
A secure system requires users and services to prove themselves to the system. Hadoop secure mode uses Kerberos for authentication. Most Hadoop components are designed to use Kerberos for authentication. Kerberos is usually implemented within enterprise authentication systems such as Active Directory or LDAP-compliant systems.
Kerberos principals
A user in Kerberos is called a principal. In a Hadoop deployment, there are user principals and service principals. User principals are usually synced from Active Directory or other user management systems to a key distribution center (KDC). One user principal represents one human user. A service principal is unique to a service per server, so each service on each server has one unique principal to represent it.
Keytab files
A keytab file contains Kerberos principals and their keys. Users and services can use keytabs to authenticate against Hadoop services without using interactive tools and entering passwords. Hadoop creates service principals for each service on each node. These principals are stored in keytab files on Hadoop nodes.
SPNEGO
If you are accessing a Kerberized cluster using a web browser, the browser must know how to pass Kerberos keys. This is where Simple and Protected GSS-API Negotiation Mechanism (SPNEGO) comes in, which provides a way to use Kerberos in web applications.
Integration
Hadoop integrates with Kerberos not only for user authentication, but also for service authentication. Any Hadoop service on any node will have its own Kerberos principal, which it uses to authenticate. Services usually have keytab files stored on the server that contain a random password.
To be able to interact with services, human users usually need to obtain their
Kerberos ticket via the kinit command or Centrify or SSSD.
Hadoop on-premises authorization
After an identity has been validated, the authorization system checks what type of access the user or service has. On Hadoop, some open source projects such as Apache Sentry and Apache Ranger are used to provide authorization.
Apache Sentry and Apache Ranger
Apache Sentry and Apache Ranger are common authorization mechanisms used on Hadoop clusters. Components on Hadoop implement their own plugins to Sentry or Ranger to specify how to behave when Sentry or Ranger confirms or denies access to an identity. Sentry and Ranger rely on authentication systems such as Kerberos, LDAP, or AD. The group mapping mechanism in Hadoop makes sure that Sentry or Ranger sees the same group mapping that the other components of the Hadoop ecosystem see.
HDFS permissions and ACL
HDFS uses a POSIX-like permission system with an access control list (ACL) to determine whether users have access to files. Each file and directory is associated with an owner and a group. The structure has a root folder that's owned by a superuser. Different levels of the structure can have different encryption, and different ownership, permissions, and extended ACL (facl).
As shown in the following diagram, permissions are usually granted at the directory level to specific groups based on their access needs. Access patterns are identified as different roles and map to Active Directory groups. Objects belonging to a single dataset generally reside at the layer that has permissions for a specific group, with different directories for different data categories.
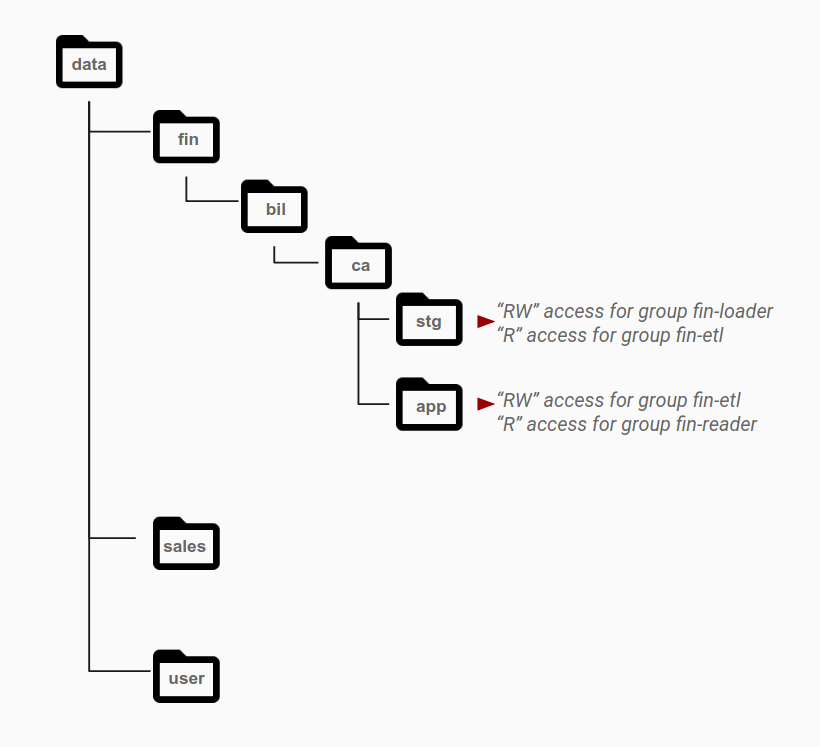
For example, the stg directory is the staging area for financial data. The
stg folder has read and write permissions for the fin-loader group. From
this staging area, another application account group, fin-etl, which
represents ETL pipelines, has read-only access to this directory. ETL pipelines
process data and save them into the app directory to be served. To enable this
access pattern, the app directory has read/write access for the fin-etl
group, which is the identity that is used to write the ETL data, and read-only
access for the fin-reader group, which consumes the resulting data.
Hadoop on-premises encryption
Hadoop provides ways to encrypt data at rest and data in transit. To encrypt data at rest, you can encrypt HDFS by using Java-based key encryption or vendor-supplied encryption solutions. HDFS supports encryption zones to provide the ability to encrypt different files using different keys. Each encryption zone is associated with a single encryption zone key that is specified when the zone is created.
Each file within an encryption zone has a unique data encryption key (DEK). DEKs are never handled directly by HDFS. Instead, HDFS only ever handles an encrypted data encryption key (EDEK). Clients decrypt an EDEK, and then use the subsequent DEK to read and write data. HDFS data nodes simply see a stream of encrypted bytes.
Data transit between Hadoop nodes can be encrypted using Transport Layer Security (TLS). TLS provides encryption and authentication in communication between any two components from Hadoop. Usually Hadoop would use internal CA-signed certificates for TLS between components.
Hadoop on-premises auditing
An important part of security is auditing. Auditing helps you find suspicious activity and provides a record of who has had access to resources. Cloudera Navigator and other third-party tools are usually used for data management purposes, such as audit tracing on Hadoop. These tools provide visibility into and control over the data in Hadoop datastores and over the computations performed on that data. Data auditing can capture a complete and immutable record of all activity within a system.
Hadoop on Google Cloud
In a traditional on-premises Hadoop environment, the four pillars of Hadoop security (authentication, authorization, encryption, and audit) are integrated and handled by different components. On Google Cloud, they are handled by different Google Cloud components external to both Dataproc and Hadoop on Compute Engine.
You can manage Google Cloud resources using the Google Cloud console, which is a web-based interface. You can also use the Google Cloud CLI, which can be faster and more convenient if you are comfortable working at the command line. You can run gcloud commands by installing the gcloud CLI on your local computer, or by using an instance of Cloud Shell.
Hadoop Google Cloud authentication
There are two kinds of Google identities within Google Cloud: service accounts and user accounts. Most Google APIs require authentication with a Google identity. A limited number of Google Cloud APIs will work without authentication (using API keys), but we recommend using all APIs with service account authentication.
Service accounts use private keys to establish identity. User accounts use the OAUTH 2.0 protocol to authenticate end users. For more information, see Authentication Overview.
Hadoop Google Cloud authorization
Google Cloud provides multiple ways to specify what permissions an authenticated identity has for a set of resources.
IAM
Google Cloud offers Identity and Access Management (IAM), which lets you manage access control by defining which users (principals) have what access (role) for which resource.
With IAM, you can grant access to Google Cloud resources and prevent unwanted access to other resources. IAM lets you implement the security principle of least privilege, so you grant only the minimum necessary access to your resources.
Service accounts
A service account is a special type of Google account that belongs to your application or a virtual machine (VM) instead of to an individual end user. Applications can use service account credentials to authenticate themselves with other Cloud APIs. In addition, you can create firewall rules that allow or deny traffic to and from instances based on the service account assigned to each instance.
Dataproc clusters are built on top of Compute Engine VMs. Assigning a custom service account when creating a Dataproc cluster will assign that service account to all VMs in your cluster. This gives your cluster fine-grained access and control to Google Cloud resources. If you do not specify a service account, Dataproc VMs use the default Google-managed Compute Engine service account. This account by default has the broad project editor role, giving it a wide range of permissions. We recommend not using the default service account to create a Dataproc cluster in a production environment.
Service account permissions
When you assign a custom service account to a Dataproc/Hadoop cluster, that service account's level of access is determined by the combination of access scopes granted to the cluster's VM instances and the IAM roles granted to your service account. To set up an instance using your custom service account, you need to configure both access scopes and IAM roles. Essentially, these mechanisms interact in this way:
- Access scopes authorize the access that an instance has.
- IAM restricts that access to the roles granted to the service account that the instance uses.
- The permissions at the intersection of access scopes and IAM roles are the final permissions that the instance has.
When you create a Dataproc cluster or Compute Engine instance in the Google Cloud console, you select the access scope of the instance:
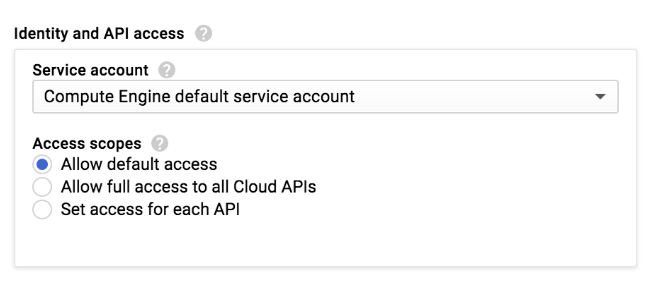
A Dataproc cluster or Compute Engine instance has a set of access scopes defined for use with the Allow default access setting:
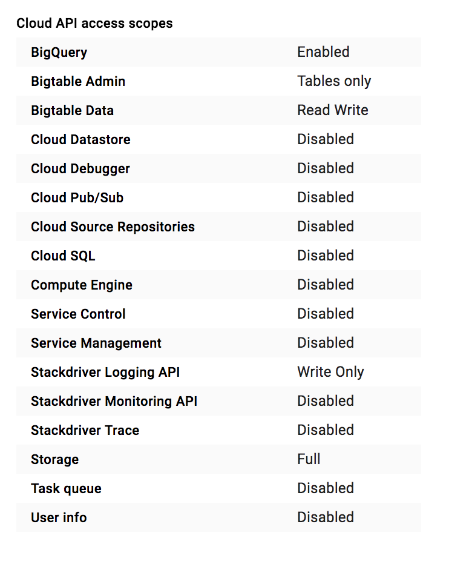
There are
many access scopes
that you can choose from. We recommend that when you create a new VM instance or
cluster, you set Allow full access to all Cloud APIs (in the console) or
https://www.googleapis.com/auth/cloud-platform access scope (if you use the
Google Cloud CLI). These scopes authorize access to all
Google Cloud services. After you've set the scope, we recommend that you
then limit that access by assigning IAM roles to the cluster
service account.
The account cannot perform any actions outside of these roles, despite the Google Cloud access scope. For more details, see the service account permissions documentation.
Comparing IAM with Apache Sentry and Apache Ranger
IAM plays a role similar to Apache Sentry and Apache Ranger. IAM defines access through roles. Access to other Google Cloud components is defined in these roles and is associated with service accounts. This means that all of the instances that use the same service account have the same access to other Google Cloud resources. Anyone who has access to these instances also has the same access to these Google Cloud resources as the service account has.
Dataproc clusters and Compute Engine instances don't have a mechanism to map Google users and groups to Linux users and groups. But, you can create Linux users and groups. Inside the Dataproc cluster or inside Compute Engine VMs, HDFS permissions and Hadoop user and group mapping still work. This mapping can be used to restrict access to HDFS or to enforce resource allocation by using a YARN queue.
When applications on a Dataproc cluster or Compute Engine VM need to access outside resources such as Cloud Storage or BigQuery, those applications are authenticated as the identity of the service account that you assigned to the VMs in the cluster. You then use IAM to grant your cluster's custom service account the minimum level of access needed by your application.
Cloud Storage permissions
Dataproc uses Cloud Storage for its storage system. Dataproc also provides a local HDFS system, but HDFS will be unavailable if the Dataproc cluster is deleted. If the application does not strictly depend on HDFS, it's best to use Cloud Storage to fully take advantage of Google Cloud.
Cloud Storage does not have storage hierarchies. Directory structure simulates the structure of a file system. It also does not have POSIX-like permissions. Access control by IAM user accounts and service accounts can be set at the bucket level. It does not enforce permissions based on Linux users.
Hadoop Google Cloud encryption
With a few minor exceptions, Google Cloud services encrypt customer content at rest and in transit using a variety of encryption methods. Encryption is automatic, and no customer action is required.
For example, any new data stored in persistent disks is encrypted using the 256-bit Advanced Encryption Standard (AES-256), and each encryption key is itself encrypted with a regularly rotated set of root (master) keys. Google Cloud uses the same encryption and key management policies, cryptographic libraries, and root of trust that are used for many of Google's production services, including Gmail and Google's own corporate data.
Because encryption is a default feature of Google Cloud (unlike most on-premises Hadoop implementations), you don't need to worry about implementing encryption unless you want to use your own encryption key. Google Cloud also provides a customer-managed encryption keys solution and a customer-supplied encryption keys solution. If you need to manage encryption keys yourself or to store encryption keys on-premises, you can.
For more details, see encryption at rest and encryption in transit.
Hadoop Google Cloud auditing
Cloud Audit Logs can maintain a few types of logs for each project and organization. Google Cloud services write audit log entries to these logs to help you answer the questions "who did what, where, and when?" within your Google Cloud projects.
For more information about audit logs and services that write audit logs, see the Cloud Audit Logs documentation.
Migration process
To help run a secure and efficient operation of Hadoop on Google Cloud, follow the process laid out in this section.
In this section, we assume that you've set up your Google Cloud environment. This includes creating users and groups in Google Workspace. These users and groups are either managed manually or synced with Active Directory, and you've configured everything so that Google Cloud is fully functional in terms of authenticating users.
Determine who will manage identities
Most Google customers use Cloud Identity to manage identities. But some manage their corporate identities independently of Google Cloud identities. In that case, their POSIX and SSH permissions dictate end-user access to cloud resources.
If you have an independent identity system, you start by creating Google Cloud service account keys and downloading them. You can then bridge your on-premises POSIX and SSH security model with the Google Cloud model by granting appropriate POSIX-style access permissions to the downloaded service account key files. You allow or deny your on-premises identities access to these keyfiles.
If you follow this route, auditability is in the hands of your own identity management systems. To provide an audit trail, you can use the SSH logs (which hold the service-account keyfiles) of user logins on edge nodes, or you can opt for a more heavyweight and explicit keystore mechanism to fetch service-account credentials from users. In that case, the "service account impersonation" is audit-logged at the keystore layer.
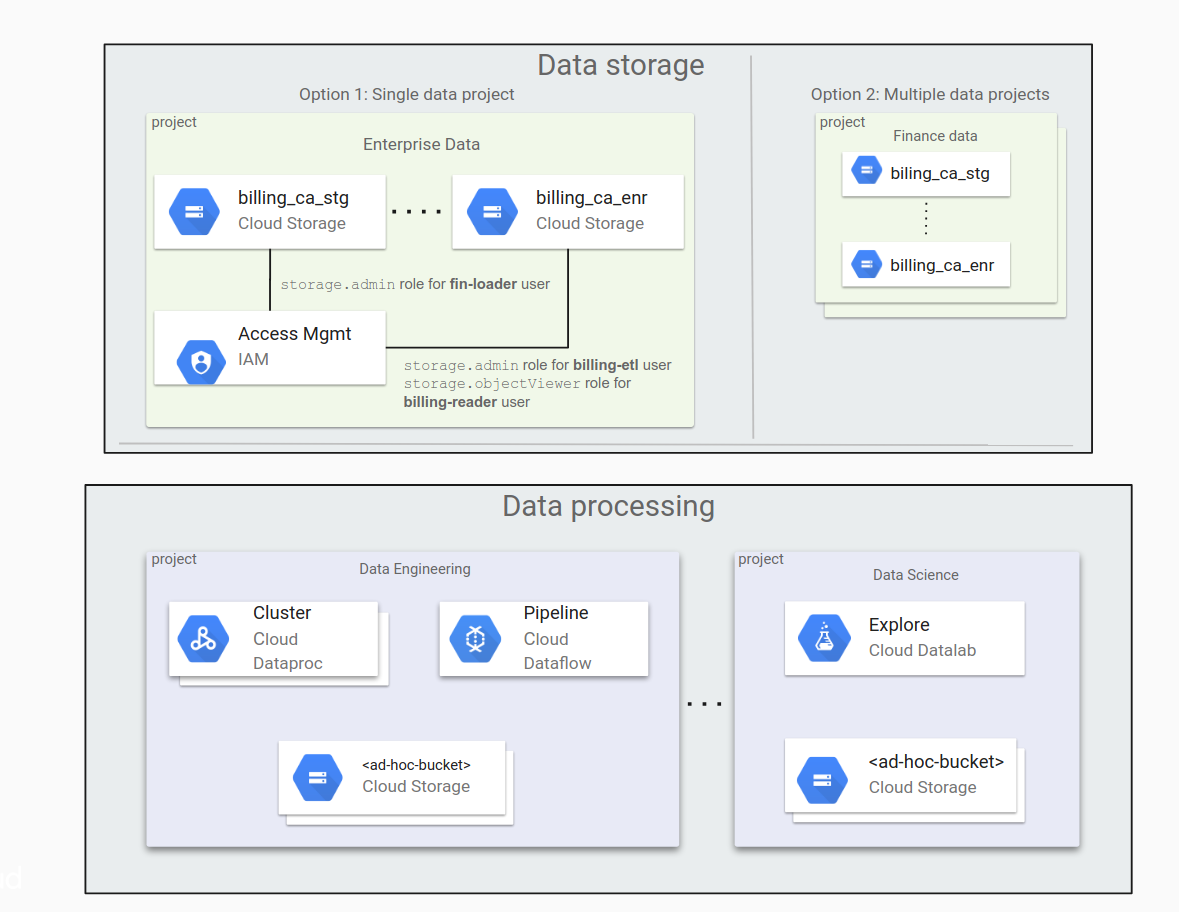
Determine whether to use a single data project or multiple data projects
If your organization has a lot of data, it means dividing the data into different Cloud Storage buckets. You also need to think about how to distribute these data buckets among your projects. You might be tempted to move over a small amount of data when you get started on Google Cloud, moving more and more data over time as workloads and applications move.
It can seem convenient to leave all your data buckets under one project, but doing so is often not a good approach. To manage access to the data, you use a flattened directory structure with IAM roles for buckets. It can become unwieldy to manage as the number of buckets grows.
An alternative is to store data in multiple projects that are each dedicated to different organizations—a project for the finance department, another one for the legal group, and so on. In this case, each group manages its own permissions independently.
During data processing, it might be necessary to access or create ad hoc buckets. Processing might be split across trust boundaries, such as data scientists accessing data that is produced by a process that they don't own.
The following diagram shows a typical organization of data in Cloud Storage under a single data project and under multiple data projects.
Here are the main points to consider when deciding which approach is best for your organization.
With a single data project:
- It's easy to manage all the buckets, as long as the number of buckets is small.
- Permission granting is mostly done by members of the admin group.
With multiple data projects:
- It's easier to delegate management responsibilities to project owners.
- This approach is useful for organizations that have different permission-granting processes. For example, the permission-granting process might be different for marketing department projects than it is for legal department projects.
Identify applications and create service accounts
When Dataproc/Hadoop clusters interact with other
Google Cloud resources such as with Cloud Storage, you should
identify all applications that will run on Dataproc/Hadoop and
the access they will need. For example, imagine that there is an ETL job that
populates financial data in California to the financial-ca bucket. This ETL
job will need read and write access to the bucket. After you identify
applications that will use Hadoop, you can create service accounts for each of
these applications.
Remember that this access does not affect Linux users inside of the Dataproc cluster or in Hadoop on Compute Engine.
For more information about Service Accounts, see Creating and Managing Service Accounts.
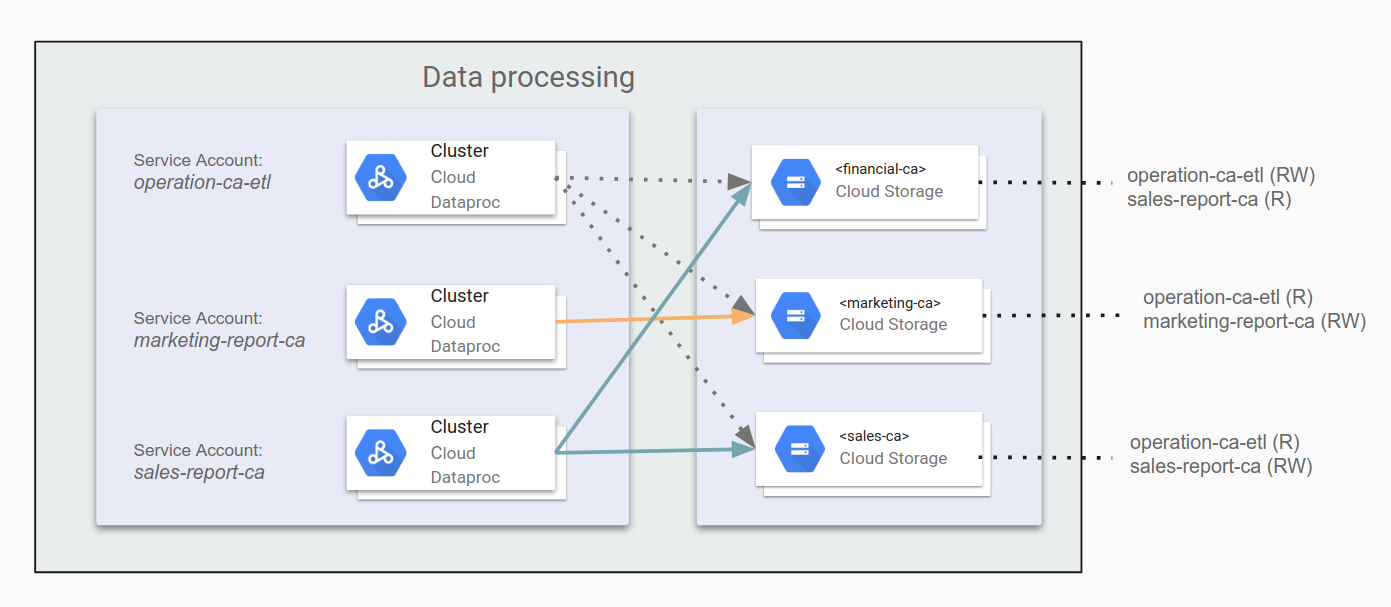
Grant permissions to service accounts
When you know what access each application should have to different Cloud Storage buckets, you can set those permissions on the relevant application service accounts. If your applications also need to access other Google Cloud components, such as BigQuery or Bigtable, you can also grant permissions to these components using service accounts.
For example, you might specify operation-ca-etl as an ETL application to
generate operation reports by assembling marketing and sales data from
California, granting it permission to write reports to the financial department
data bucket. Then you might set marketing-report-ca and sales-report-ca
applications to each have read and write access to their own departments. The
following diagram illustrates this setup.
You should follow the principle of least privilege. The principle specifies that you give to each user or service account only the minimum permissions that it needs in order to perform its task or tasks. Default permissions in Google Cloud are optimized to provide ease of use and reduce setup time. To build Hadoop infrastructures that are likely to pass security and compliance reviews, you must design more restrictive permissions. Investing effort early on, and documenting those strategies, not only helps provide a secure and compliant pipeline, but also helps when it comes time to review the architecture with security and compliance teams.
Create clusters
After you have planned and configured access, you can create Dataproc clusters or Hadoop on Compute Engine with the service accounts you've created. Each cluster will have access to other Google Cloud components based on the permissions that you have given to that service account. Make sure you give the correct access scope or scopes for access to Google Cloud and then adjust with service account access. If an access issue ever arises, especially for Hadoop on Compute Engine, be sure to check these permissions.
To create a Dataproc cluster with a specific service account, use
this gcloud command:
gcloud dataproc clusters create [CLUSTER_NAME] \
--service-account=[SERVICE_ACCOUNT_NAME]@[PROJECT+_ID].iam.gserviceaccount.com \
--scopes=scope[, ...]
For the following reasons, it is best to avoid using the default Compute Engine service account:
- If multiple clusters and Compute Engine VMs use the default Compute Engine service account, auditing becomes difficult.
- The project setting for the default Compute Engine service account can vary, which means that it might have more privileges than your cluster needs.
- Changes to the default Compute Engine service account might unintentionally affect, or even break, your clusters and the applications that run in them.
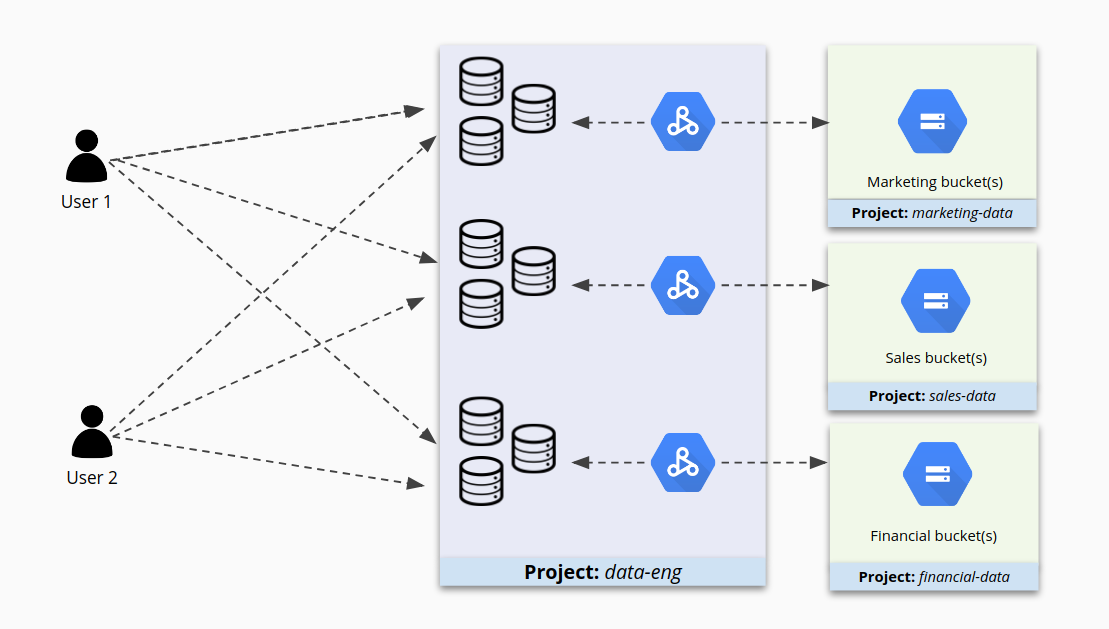
Consider setting IAM permissions for each cluster
Placing many clusters under one project can make managing those clusters convenient, but it might not be the best way to secure access to them. For example, given cluster 1 and 2 in project A, some users might have the right privileges to work on cluster 1, but might also have too many permissions for cluster 2. Or even worse, they might have access to cluster 2 simply because it is in that project when they should not have any access.
When projects contain many clusters, access to those clusters can become a tangle, as shown in the following figure.
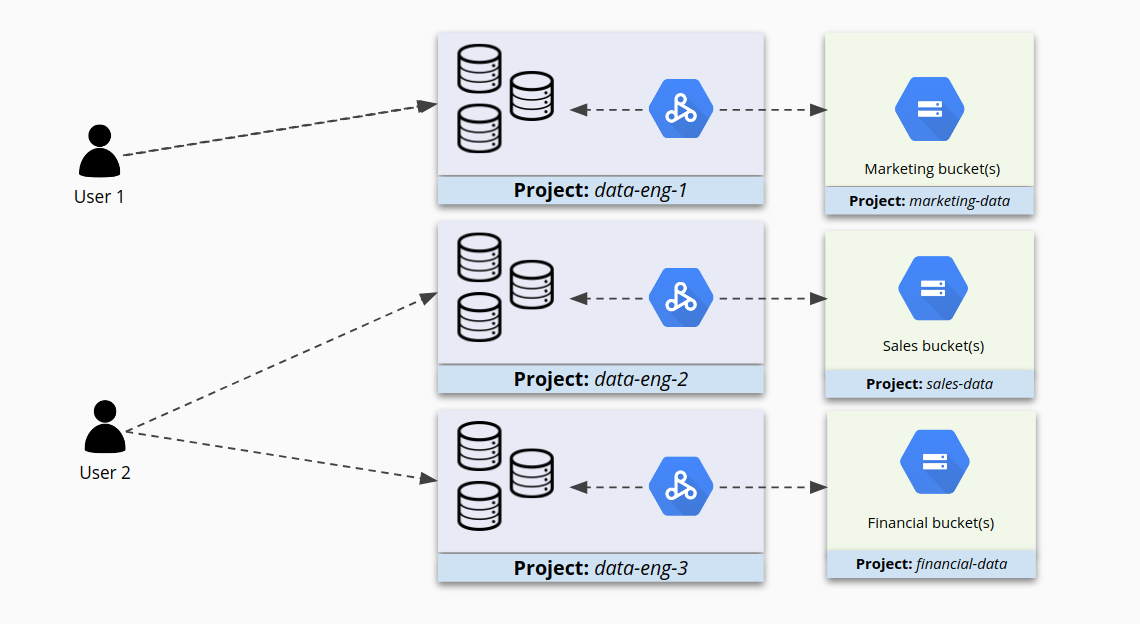
If you instead group like clusters together into smaller projects, and then configure IAM separately for each cluster, you will have a finer degree of control over access. Now users have access to the clusters intended for them and are restricted from accessing others.
Restrict access to clusters
Setting access using service accounts secures the interactions between Dataproc/Hadoop and other Google Cloud components. However, it does not fully control who can access Dataproc/Hadoop. For example, a user in the cluster who has the IP address of the Dataproc/Hadoop cluster nodes can still use SSH to connect to it (in some cases) or submit jobs to it. In the on-premises environment, the system administrator usually has subnets, firewall rules, Linux authentication, and other strategies to restrict access to Hadoop clusters.
There are many ways to restrict access at the level of Google Workspace or Google Cloud authentication when you are running Dataproc/Hadoop on Compute Engine. However, this guide focuses on access at the level of the Google Cloud components.
Restricting SSH login using OS login
In the on-premises environment, to restrict users from connecting to a Hadoop node, you need to set up perimeter access control, Linux-level SSH access, and sudoer files.
On Google Cloud, you can configure user-level SSH restrictions for connecting to Compute Engine instances by using the following process:
- Enable the OS Login feature on your project or on individual instances.
- Grant the necessary IAM roles to yourself and other principals.
- Optionally, add custom SSH keys to user accounts for yourself and other principals. Alternatively, Compute Engine can automatically generate these keys for you when you connect to instances.
After you enable OS Login on one or more instances in your project, those instances accept connections only from user accounts that have the necessary IAM roles in your project or organization.
As an example, you might grant instance access to your users with the following process:
Grant the necessary instance access roles to the user. Users must have the following roles:
- The
iam.serviceAccountUserrole One of the following login roles:
- The
compute.osLoginrole, which does not grant administrator permissions - The
compute.osAdminLoginrole, which grants administrator permissions
- The
- The
If you are an organization administrator who wants to allow Google identities from outside of your organization to access your instances, grant those outside identities the
compute.osLoginExternalUserrole at your organization level. You must then also grant those outside identities either thecompute.osLoginorcompute.osAdminLoginrole at your project or organization level .
After you configure the necessary roles, connect to an instance using Compute Engine tools. Compute Engine automatically generates SSH keys and associates them with your user account.
For more information about the OS Login feature, see Managing Instance Access Using OS Login.
Restricting network access using firewall rules
On Google Cloud, you can also create firewall rules that use service accounts to filter ingress or egress traffic. This approach can work particularly well in these circumstances:
- You have a wide range of users or applications that need access to Hadoop, which means that creating rules based on the IP is challenging.
- You are running ephemeral Hadoop clusters or client VMs, so that the IP addresses change frequently.
Using firewall rules in combination with service accounts, you can set the access to a particular Dataproc/Hadoop cluster to allow only a certain service account. That way, only the VMs running as that service account will have access at the specified level to the cluster.
The following diagram illustrates the process of using service accounts to
restrict access. dataproc-app-1, dataproc-1, dataproc-2, and
app-1-client are all service accounts. Firewall rules allow dataproc-app-1to access dataproc-1 and dataproc-2, and allow clients using app-1-client
to access dataproc-1. On the storage side, Cloud Storage access and
permissions are restricted by Cloud Storage permissions to service
accounts instead of firewall rules.
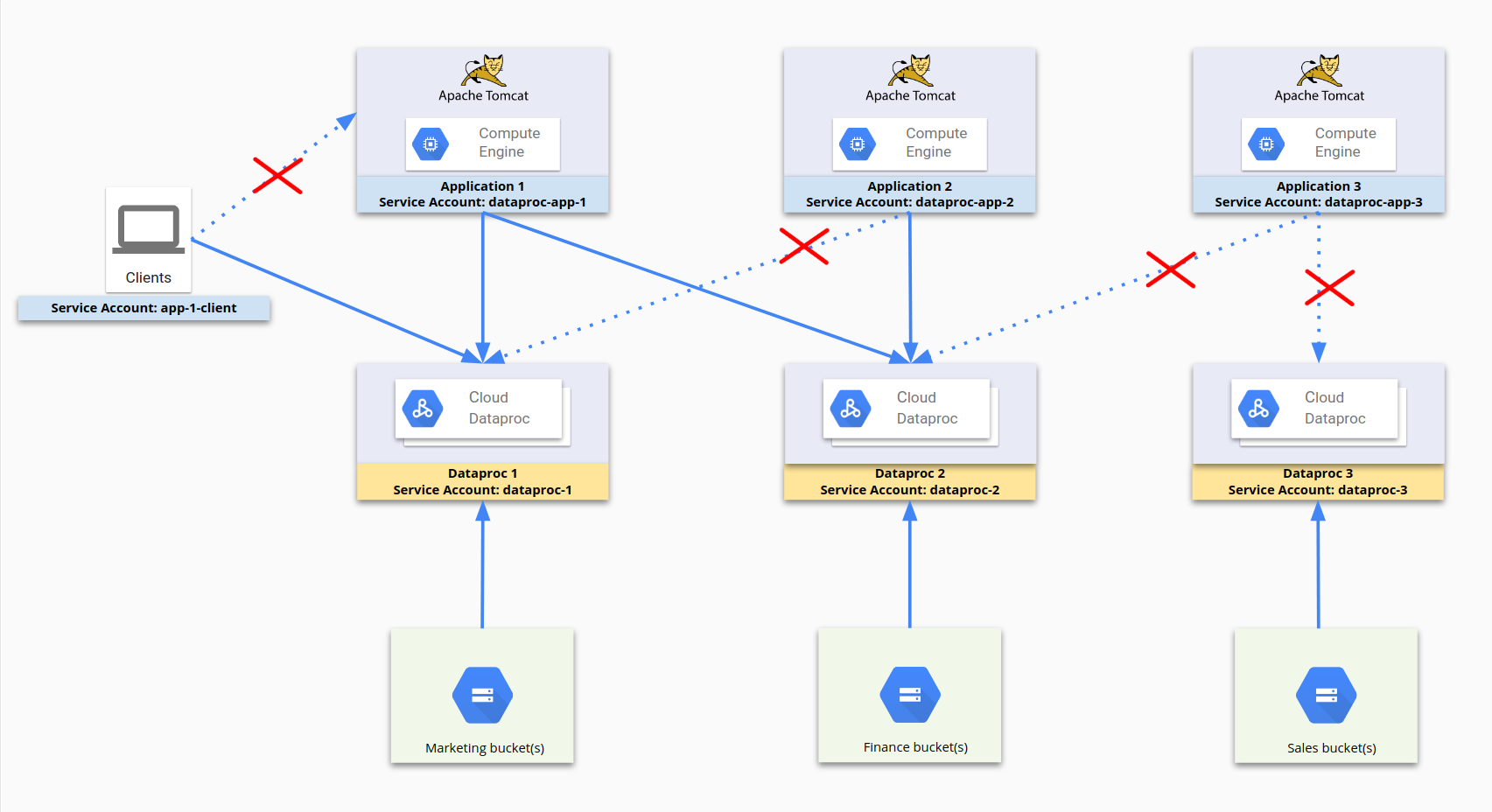
For this configuration, the following firewall rules have been established:
| Rule name | Settings |
|---|---|
dp1 |
Target: dataproc-1Source: [IP Range] Source SA: dataproc-app-1Allow [ports] |
dp2 |
Target: dataproc-2Source: [IP Range] Source SA: dataproc-app-2Allow [ports] |
dp2-2 |
Target: dataproc-2Source: [IP Range] Source SA: dataproc-app-1Allow [ports] |
app-1-client |
Target: dataproc-1Source: [IP Range] Source SA: app-1-clientAllow [ports] |
For more information about using firewall rules with service accounts, see Source and target filtering by service account.
Check for inadvertently open firewall ports
Having appropriate firewall rules in place is also important for exposing Web-based user interfaces that run on the cluster. Ensure that you do not have open firewall ports from the Internet that connect to these interfaces. Open ports and improperly configured firewall rules can allow unauthorized users to execute arbitrary code.
For example, Apache Hadoop YARN provides REST APIs that share the same ports as the YARN web interfaces. By default, users who can access the YARN web interface can create applications, submit jobs, and might be able to perform Cloud Storage operations.
Review Dataproc networking configurations. and Create an SSH tunnel. to establish a secure connection to your cluster's controller. For more information about using firewall rules with service accounts, see Source and target filtering by service account..
What about multi-tenant clusters?
In general, it's a best practice to run separate Dataproc/Hadoop clusters for different applications. But if you have to use a multi-tenant cluster and do not want to violate security requirements, you can create Linux users and groups inside the Dataproc/Hadoop clusters to provide authorization and resource allocation through a YARN queue. The authentication has to be implemented by you because there is no direct mapping between Google users and Linux users. Enabling Kerberos on the cluster can strengthen the authentication level within the scope of the cluster.
Sometimes, human users such as a group of data scientists use a Hadoop cluster to discover data and build models. In a situation like this, grouping users that share the same access to data together and creating one dedicated Dataproc/Hadoop cluster would be a good choice. This way, you can add users to the group that has permission to access the data. Cluster resources can also be allocated based on their Linux users.