Neste documento, descrevemos uma arquitetura de referência que ajuda você a criar um mecanismo de exportação de registros escalonável, tolerante a falhas e pronto para produção que transmite registros e eventos dos seus recursos no Google Cloud para o Splunk. O Splunk é uma ferramenta de análise conhecida que oferece uma plataforma unificada de segurança e observabilidade. Na verdade, é possível exportar os dados de registro para o Splunk Enterprise ou para o Splunk Cloud Platform. Se você é um administrador, também pode usar essa arquitetura para casos de uso de operações de TI ou de segurança.
Esta arquitetura de referência pressupõe uma hierarquia de recursos semelhante ao diagrama a seguir. Todos os registros de recursos Google Cloud dos níveis da organização, da pasta e do projeto são reunidos em um coletor agregado. Em seguida, esse coletor agregado envia os registros para um pipeline de exportação de registros, que os processa e os exporta para o Splunk.

Arquitetura
O diagrama a seguir mostra a arquitetura de referência que você usa ao implantar essa solução. Este diagrama demonstra como os dados de registro fluem do Google Cloud para o Splunk.

Essa arquitetura inclui os seguintes componentes:
- Cloud Logging: para iniciar o processo, o Cloud Logging coleta os registros em um coletor de registros agregado no nível da organização e os envia ao Pub/Sub.
- Pub/Sub: o serviço Pub/Sub cria um único tópico e uma única assinatura para os registros e os encaminha ao pipeline principal do Dataflow.
- Dataflow: há dois
pipelines do Dataflow nesta arquitetura de referência:
- Pipeline principal do Dataflow: ele está no centro do processo e é um pipeline de streaming do Pub/Sub para o Splunk que extrai registros da assinatura do Pub/Sub e os entrega ao Splunk.
- Pipeline secundário do Dataflow: paralelo ao pipeline principal do Dataflow, o pipeline secundário é um pipeline de streaming do Pub/Sub para o Pub/Sub que repete mensagens quando uma entrega falha.
- Splunk: no final do processo, o Splunk Enterprise ou o Splunk Cloud Platform atua como um coletor de eventos HTTP (HEC) que recebe os registros para análises mais detalhadas. É possível implantar o Splunk no local, no Google Cloud como SaaS ou por meio de uma abordagem híbrida.
Caso de uso
Esta arquitetura de referência usa uma abordagem de nuvem baseada em push. Neste método baseado em push, você usa o modelo do Dataflow do Pub/Sub para o Splunk a fim de transmitir registros para um coletor de eventos HTTP (HEC) do Splunk. Essa arquitetura também aborda o planejamento de capacidade do pipeline do Dataflow e como lidar com possíveis falhas na entrega em caso de problemas temporários na rede ou no servidor.
Embora essa arquitetura de referência se concentre nos registros do Google Cloud , ela também pode ser usada para exportar outros dados do Google Cloud , como mudanças de recursos em tempo real e descobertas de segurança. Ao integrar os registros do Cloud Logging, é possível continuar usando os serviços de parceiros atuais, como o Splunk, como uma solução unificada de análise de registros.
O método baseado em push para fazer streaming de dados Google Cloud para o Splunk tem as seguintes vantagens:
- Serviço gerenciado. Como um serviço gerenciado, o Dataflow mantém os recursos necessários no Google Cloud para tarefas de processamento de dados, como a exportação de registros.
- Carga de trabalho distribuída. Esse método permite distribuir cargas de trabalho em vários workers para processamento paralelo, o que garante que não haja um ponto único de falha.
- Segurança. Como o Google Cloud envia seus dados para o HEC do Splunk, não há sobrecarga de manutenção e segurança associada à criação e ao gerenciamento de chaves de conta de serviço.
- Escalonamento automático. O serviço Dataflow faz o escalonamento automático do número de workers em resposta a variações no backlog e no volume de registros de entrada.
- Tolerância a falhas. Se houver problemas temporários no servidor ou na rede, o método baseado em push tentará reenviar automaticamente os dados para o HEC do Splunk. Ele também aceita tópicos não processados (também conhecidos como tópicos de mensagens inativas) para mensagens de registro não entregues a fim de evitar a perda de dados.
- Simplicidade. Você evita a sobrecarga de gerenciamento e o custo de executar um ou mais encaminhadores pesados no Splunk.
Esta arquitetura de referência se aplica a empresas em muitos segmentos diferentes do setor, incluindo as regulamentadas, como as de serviços farmacêuticos e financeiros. É possível exportar seus dados do Google Cloud para o Splunk pelos seguintes motivos:
- Análise de negócios
- Operações de TI
- Monitoramento do desempenho de aplicativos
- Operações de segurança
- Compliance
Alternativas de design
Um método alternativo de exportação de registros para o Splunk é aquele em que você extrai os registros do Google Cloud. Nesse método baseado em pull, você usa as APIs do Google Cloud para buscar os dados usando o complemento do Splunk para Google Cloud. É possível usar o método baseado em pull nas seguintes situações:
- Sua implantação do Splunk não oferece um endpoint do HEC do Splunk.
- O volume de registros é baixo.
- Você quer exportar e analisar métricas do Cloud Monitoring, objetos do Cloud Storage, metadados da API Resource Manager do Cloud, dados do Cloud Billing ou registros de baixo volume.
- Você já gerencia um ou mais encaminhamentos pesados no Splunk.
- Use o Gerenciador de dados de entradas para Splunk Cloud hospedado.
Além disso, tenha em mente as outras considerações que surgem quando você usa esse método baseado em pull:
- A carga de trabalho de ingestão de dados é processada por um único worker, que não oferece recursos de escalonamento automático.
- No Splunk, o uso de um encaminhador pesado para extrair dados pode causar um ponto único de falha.
- O método baseado em pull requer que você crie e gerencie as chaves da conta de serviço usadas para configurar o complemento do Splunk para Google Cloud.
Antes de usar o complemento do Splunk, as entradas de registro precisam ser roteadas para o Pub/Sub usando um coletor de registros. Para criar um coletor de registros com o tópico do Pub/Sub como destino, consulte Criar um coletor.
Conceda o papel de Publicador do Pub/Sub
(roles/pubsub.publisher) à identidade do gravador do coletor nesse
destino do tópico do Pub/Sub. Para mais
informações sobre como configurar as permissões de destino do coletor, consulte
Definir permissões de destino.
Para ativar o complemento do Splunk, siga estas etapas:
- No Splunk, siga as instruções para instalar o complemento do Splunk para Google Cloud.
- Crie uma assinatura de pull do Pub/Sub para o tópico do Pub/Sub para onde os registros são roteados, se você ainda não tiver uma.
- Crie uma conta de serviço.
- Crie uma chave de conta de serviço para a conta de serviço que você acabou de criar.
- Conceda os papéis de Leitor (
roles/pubsub.viewer) e Assinante (roles/pubsub.subscriber) do Pub/Sub à conta de serviço para permitir que ela receba mensagens da assinatura do Pub/Sub. No Splunk, siga as instruções para configurar uma nova entrada do Pub/Sub no complemento do Splunk para Google Cloud.
As mensagens do Pub/Sub provenientes da exportação de registros aparecem no Splunk.
Para verificar se o complemento está funcionando, siga estas etapas:
- No Cloud Monitoring, abra o Metrics Explorer.
- No menu Recursos, selecione
pubsub_subscription. - Nas categorias Métrica, selecione
pubsub/subscription/pull_message_operation_count. - Monitore o número de operações de pull de mensagens por um período de um a dois minutos.
Considerações sobre o design
As diretrizes a seguir podem ajudar você a desenvolver uma arquitetura que atenda aos requisitos da sua organização para segurança, privacidade, compliance, eficiência operacional, confiabilidade, tolerância a falhas, desempenho e otimização de custos.
segurança, privacidade e conformidade
As seções a seguir descrevem as considerações de segurança para a arquitetura de referência:
- Usar endereços IP particulares para proteger as VMs compatíveis com o pipeline do Dataflow
- ativar o Acesso privado do Google
- Restringir o tráfego de entrada do HEC do Splunk a endereços IP conhecidos usados pelo Cloud NAT
- Armazenar o token do HEC do Splunk no Secret Manager
- Criar uma conta de serviço personalizada de worker do Dataflow para seguir as práticas recomendadas de privilégio mínimo
- Configurar a validação SSL com um certificado de CA raiz interno ao usar uma AC particular
Usar endereços IP particulares para proteger as VMs compatíveis com o pipeline do Dataflow
Restrinja o acesso às VMs de worker usadas no pipeline do Dataflow. Para restringir o acesso, implante essas VMs com endereços IP particulares. No entanto, essas VMs também precisam usar HTTPS para fazer streaming dos registros exportados para o Splunk e acessar a Internet. Para fornecer esse acesso HTTPS, você precisa de um gateway do Cloud NAT que aloque automaticamente os endereços IP do Cloud NAT para as VMs que precisam deles. Mapeie a sub-rede que contém as VMs para o gateway do Cloud NAT.
ativar o Acesso privado do Google
Quando você cria um gateway do Cloud NAT, o Acesso privado do Google é ativado automaticamente. No entanto, para permitir que os workers do Dataflow com endereços IP particulares acessem os endereços IP externos que os serviços e as APIs do Google Cloud usam, ative manualmente o Acesso privado do Google na sub-rede.
Restringir o tráfego de entrada do HEC do Splunk a endereços IP conhecidos usados pelo Cloud NAT
Se você quiser restringir o tráfego que chega ao HEC do Splunk a um subconjunto de endereços IP conhecidos, reserve endereços IP estáticos e atribua-os manualmente ao gateway do Cloud NAT. Dependendo da implantação do Splunk, será possível configurar as regras de firewall de entrada do HEC do Splunk usando esses endereços IP estáticos. Para mais informações sobre o Cloud NAT, consulte Configurar e gerenciar a conversão de endereços de rede com o Cloud NAT.
Armazenar o token do HEC do Splunk no Secret Manager
Ao implantar o pipeline do Dataflow, é possível transmitir o valor do token de uma das seguintes maneiras:
- Texto simples
- Texto criptografado com uma chave do Cloud Key Management Service
- Versão do secret criptografada e gerenciada pelo Secret Manager
Nesta arquitetura de referência, você usa a opção Secret Manager, porque ela oferece a maneira menos complexa e mais eficiente de proteger o token do HEC do Splunk. Essa opção também impede o vazamento do token do HEC do Splunk do console do Dataflow ou dos detalhes do job.
Um secret no Secret Manager contém uma coleção de versões de secrets. Cada versão de secret armazena os dados reais do secret, como o token do HEC do Splunk. Se você optar por alternar o token do HEC do Splunk mais tarde como uma medida de segurança extra, será possível adicionar o novo token ao secret como uma nova versão de secret. Para informações gerais sobre a rotação de secrets, consulte Sobre as programações de rotação.
Criar uma conta de serviço personalizada de worker do Dataflow para seguir as práticas recomendadas de privilégio mínimo
Os workers no pipeline do Dataflow usam a conta de serviço de worker do Dataflow para acessar recursos e executar operações. Por padrão, os workers usam a conta de serviço padrão do Compute Engine do projeto como a conta de serviço do worker, o que concede a eles amplas permissões para todos os recursos do projeto. No entanto, para executar jobs do Dataflow em produção, recomendamos que você crie uma conta de serviço personalizada com um conjunto mínimo de papéis e permissões. Em seguida, é possível atribuir essa conta de serviço personalizada aos workers do pipeline do Dataflow.
No diagrama a seguir, listamos os papéis que você precisa atribuir a uma conta de serviço para permitir que os workers do Dataflow executem um job do Dataflow com êxito.
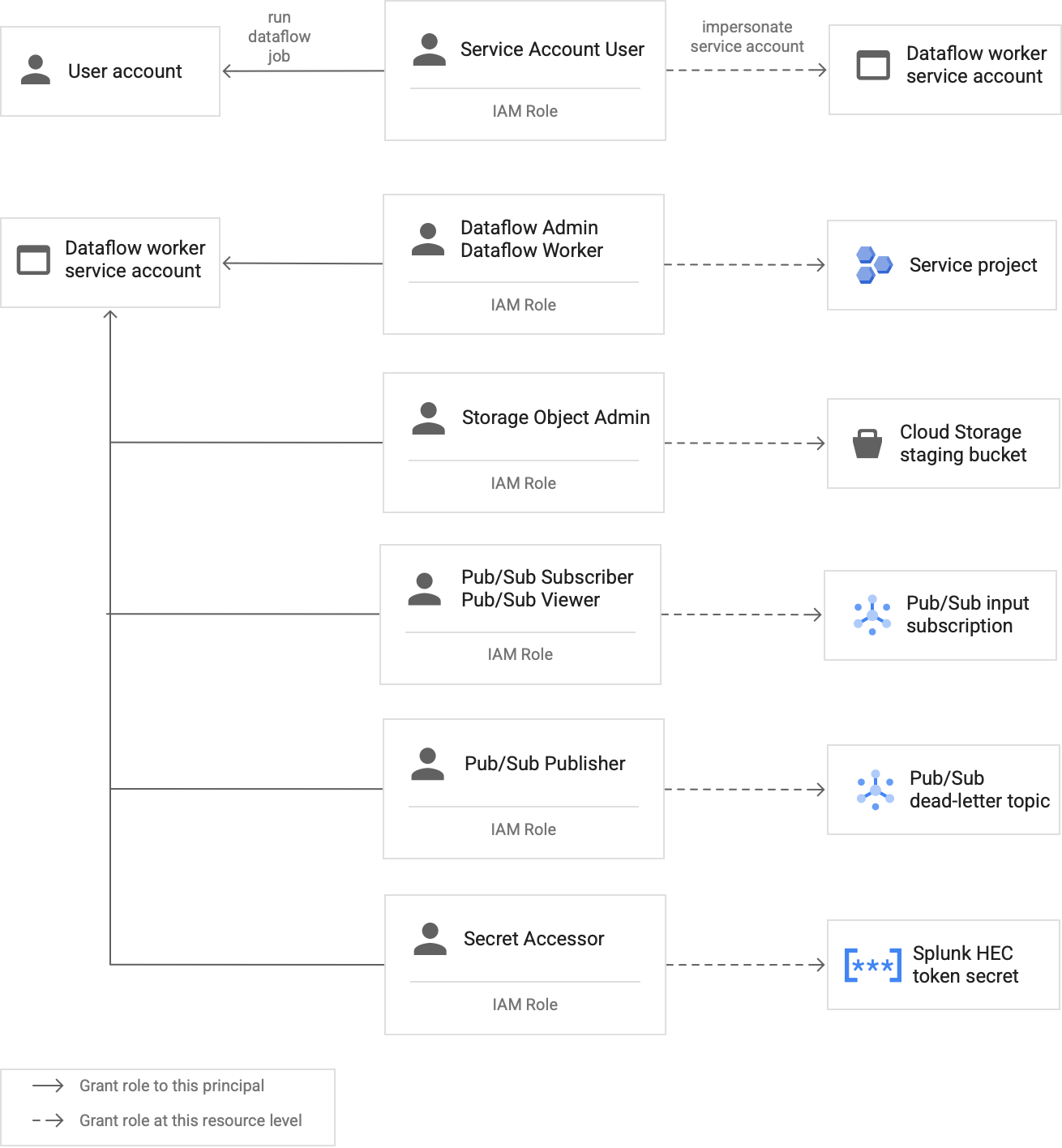
Conforme mostrado no diagrama, você precisa atribuir os seguintes papéis à conta de serviço de worker do Dataflow:
- Administrador do Dataflow
- Worker do Dataflow
- Administrador de objetos do Storage
- Assinante do Pub/Sub
- Leitor do Pub/Sub
- Publicador do Pub/Sub
- Acessador de secrets
Configurar a validação SSL com um certificado de CA raiz interno ao usar uma AC particular
Por padrão, o pipeline do Dataflow usa o repositório de confiança padrão do worker do Dataflow para validar o certificado SSL do endpoint do HEC do Splunk. Se você usar uma autoridade certificadora (AC) particular para assinar um certificado SSL usado pelo endpoint do HEC do Splunk, será possível importar o certificado da CA raiz interno para o repositório de confiança. Os workers do Dataflow podem usar o certificado importado para a validação de certificado SSL.
É possível usar e importar seu próprio certificado de CA raiz interno para as implantações do Splunk com certificados autoassinados ou assinados de maneira particular. Também é possível desativar completamente a validação SSL para fins de desenvolvimento e teste internos. Esse método de AC raiz interno funciona melhor para implantações internas do Splunk que não são voltadas à Internet.
Para mais informações, consulte os
parâmetros do modelo do Dataflow do Pub/Sub para o Splunk
rootCaCertificatePath e disableCertificateValidation.
Eficiência operacional
As seções a seguir descrevem as considerações de eficiência operacional desta arquitetura de referência:
Usar a UDF para transformar registros ou eventos em trânsito
O modelo do Dataflow do Pub/Sub para o Splunk oferece suporte a funções definidas pelo usuário (UDF) para transformação personalizada de eventos. Os exemplos de casos de uso incluem o aprimoramento de registros com campos extras, a edição de alguns campos confidenciais ou a filtragem de registros indesejados. A UDF permite alterar o formato de saída do pipeline do Dataflow sem precisar recompilar ou manter o próprio código do modelo. Esta arquitetura de referência usa uma UDF para processar mensagens que o pipeline não consegue entregar ao Splunk.
Repetir mensagens não processadas
Às vezes, o pipeline recebe erros de entrega e não tenta entregar novamente a mensagem. Nesse caso, o Dataflow envia essas mensagens não processadas para um tópico não processado, conforme mostrado no diagrama a seguir. Depois de corrigir a causa raiz da falha na entrega, é possível reproduzir as mensagens não processadas.
As etapas abaixo descrevem o processo mostrado no diagrama anterior:
- O principal pipeline de entrega do Pub/Sub para o Splunk encaminha automaticamente mensagens não entregues ao tópico não processado para investigação do usuário.
O operador ou engenheiro de confiabilidade do site (SRE) investiga as mensagens com falha na assinatura não processada. O operador soluciona o problema e corrige a causa raiz da falha na entrega. Por exemplo, corrigir uma configuração incorreta do token do HEC pode permitir que as mensagens sejam entregues.
O operador aciona o pipeline de repetição de mensagens com falha. Esse pipeline do Pub/Sub para o Pub/Sub (destacado na seção pontilhada do diagrama anterior) é temporário e move as mensagens com falha da assinatura não processada de volta para o tópico original do coletor de registros.
O pipeline de entrega principal reprocessa as mensagens que falharam anteriormente. Essa etapa exige que o pipeline use uma UDF para detectar e decodificar corretamente os payloads das mensagens que falharam. O código abaixo é um exemplo de função que implementa essa lógica de decodificação condicional, incluindo uma contagem de tentativas de envio para fins de rastreamento:
// If the message has already been converted to a Splunk HEC object // with a stringified obj.event JSON payload, then it's a replay of // a previously failed delivery. // Unnest and parse the obj.event. Drop the previously injected // obj.attributes such as errorMessage and timestamp if (obj.event) { try { event = JSON.parse(obj.event); redelivery = true; } catch(e) { event = obj; } } else { event = obj; } // Keep a tally of delivery attempts event.delivery_attempt = event.delivery_attempt || 1; if (redelivery) { event.delivery_attempt += 1; }
Confiabilidade e tolerância a falhas
Em relação à confiabilidade e à tolerância a falhas, a Tabela 1 a seguir
lista alguns possíveis erros de entrega do Splunk. Ela também lista os
atributos errorMessage correspondentes que o pipeline registra com cada
mensagem antes de encaminhá-las ao tópico não processado.
Tabela 1: tipos de erro de entrega do Splunk
| Tipo de erro de entrega | Foi repetido automaticamente pelo pipeline? | Exemplo de atributo errorMessage |
|---|---|---|
Erro de rede temporário |
Sim |
ou
|
Erro 5xx do servidor do Splunk |
Sim |
|
Erro 4xx no servidor do Splunk |
Não |
|
Servidor do Splunk inativo |
Não |
|
O certificado SSL do Splunk é inválido |
Não |
|
Erro de sintaxe JavaScript na função definida pelo usuário (UDF) |
Não |
|
Em alguns casos, o pipeline aplica a
espera exponencial e
tenta entregar a mensagem novamente de maneira automática. Por exemplo, quando o servidor do Splunk
gera um código de erro 5xx, o pipeline precisa reenviar a
mensagem. Esses códigos de erro ocorrem quando o endpoint do HEC do Splunk está sobrecarregado.
Eles também podem ocorrer quando há um problema persistente que impede que uma mensagem seja enviada ao endpoint do HEC. No caso de problemas persistentes, o pipeline não tenta entregar a mensagem novamente. Veja os seguintes exemplos de problemas persistentes:
- Um erro de sintaxe na função UDF.
- Um token do HEC inválido que faz com que o servidor do Splunk gere uma resposta de servidor
4xx"Proibido".
Otimização de desempenho e custo
Em relação à otimização de desempenho e de custos, você precisa determinar o tamanho e a capacidade de processamento máximos do pipeline do Dataflow. É preciso calcular os valores corretos de tamanho e capacidade de processamento para que o pipeline possa lidar com o volume máximo de registros diários (GB/dia) e a taxa de mensagens de registro (eventos por segundo ou EPS) da assinatura upstream do Pub/Sub.
Selecione os valores de tamanho e capacidade de processamento para que o sistema não tenha nenhum dos seguintes problemas:
- Atrasos causados pelo backlog ou pela limitação das mensagens.
- Custos extras devido ao superprovisionamento de um pipeline.
Depois de realizar os cálculos de tamanho e capacidade de processamento, use os resultados para configurar um pipeline ideal que equilibre o desempenho e o custo. Para definir a capacidade do pipeline, use as seguintes configurações:
- As flags Tipo de máquina e Contagem de máquinas fazem parte do comando gcloud que implanta o job do Dataflow. Com essas flags, é possível definir o tipo e o número de VMs a serem usadas.
- Os parâmetros Paralelismo e Contagem de lotes fazem parte do modelo do Dataflow do Pub/Sub para o Splunk. Esses parâmetros são importantes para aumentar o EPS e evitar a sobrecarga do endpoint do HEC do Splunk.
As seções abaixo explicam essas configurações. Quando aplicável, essas seções também fornecem fórmulas e cálculos de exemplo que usam cada fórmula. Os cálculos de exemplo e os valores resultantes pressupõem uma organização com as seguintes características:
- gera 1 TB de registros diariamente;
- gera mensagens com um tamanho médio de 1 KB;
- tem uma taxa de mensagens de pico contínuo que representa o dobro da taxa média.
Como seu ambiente do Dataflow é único, substitua os valores de exemplo por valores da sua própria organização ao seguir as etapas.
Tipo de máquina
Prática recomendada: defina a
flag --worker-machine-type como n2-standard-4 para
selecionar um tamanho de máquina que ofereça a melhor relação custo-benefício.
Como o tipo de máquina n2-standard-4 pode lidar com 12 mil EPS, recomendamos que
você o use como valor de referência para todos os workers
do Dataflow.
Para esta arquitetura de referência, defina a flag --worker-machine-type com um valor
de n2-standard-4.
Contagem de máquinas
Prática recomendada: defina a
flag --max-workers para controlar o número máximo de
workers necessários para lidar com o EPS máximo esperado.
O escalonamento automático do Dataflow permite que o serviço altere de maneira adaptável o
número de workers usados para executar o pipeline de streaming quando há alterações
no uso e na carga dos recursos. Para evitar o superprovisionamento durante o escalonamento automático, recomendamos que você sempre defina o número máximo de máquinas virtuais
usadas como workers do Dataflow. Defina o número máximo de máquinas virtuais com a flag --max-workers ao implantar o
pipeline do Dataflow.
O Dataflow provisiona estaticamente o componente de armazenamento da seguinte maneira:
Um pipeline de escalonamento automático implanta um disco permanente de dados para cada possível worker de streaming. O tamanho padrão do disco permanente é de 400 GB, e você define o número máximo de workers com a flag
--max-workers. Os discos são montados nos workers em execução a qualquer momento, incluindo na inicialização.Como cada instância de worker é limitada a 15 discos permanentes, o número mínimo de workers iniciais é de
⌈--max-workers/15⌉. Assim, se o valor padrão for--max-workers=20, o uso (e o custo) do pipeline será conforme descrito abaixo:- Armazenamento: estático com 20 discos permanentes.
- Computação: dinâmico com, no mínimo, duas instâncias de worker (⌈20/15⌉ = 2) e, no máximo, 20.
Esse valor é equivalente a 8 TB de um disco permanente. Esse tamanho do disco permanente pode gerar custos desnecessários quando os discos não são totalmente usados, especialmente se apenas um ou dois workers estão em execução na maior parte do tempo.
Para determinar o número máximo de workers necessários para o pipeline, use as seguintes fórmulas em sequência:
Determine a média de eventos por segundo (EPS) usando a seguinte fórmula:
\( {AverageEventsPerSecond}\simeq\frac{TotalDailyLogsInTB}{AverageMessageSizeInKB}\times\frac{10^9}{24\times3600} \)Cálculo de exemplo: com base nos valores de exemplo de 1 TB de registros por dia e um tamanho médio de mensagem de 1 KB, essa fórmula gera um valor médio de 11,5 mil EPS.
Determine o EPS máximo sustentado usando a seguinte fórmula, em que o multiplicador N representa a natureza intermitente da geração de registros:
\( {PeakEventsPerSecond = N \times\ AverageEventsPerSecond} \)Cálculo de exemplo: com base em um valor de exemplo de N=2 e no valor médio de EPS de 11,5 mil, calculado na etapa anterior, essa fórmula gera um EPS máximo sustentado de 23 mil EPS.
Determine o número máximo necessário de vCPUs usando a seguinte fórmula:
\( {maxCPUs = ⌈PeakEventsPerSecond / 3k ⌉} \)Cálculo de exemplo: usando o valor de EPS máximo sustentado de 23 mil que você calculou na etapa anterior, esta fórmula gera um máximo de ⌈23/3⌉ = 8 núcleos de vCPU.
Use a seguinte fórmula para determinar o número máximo de workers do Dataflow:
\( maxNumWorkers = ⌈maxCPUs / 4 ⌉ \)Cálculo de exemplo: usando o valor máximo de vCPUs de exemplo de 8 que foi calculado na etapa anterior, esta fórmula [8/4] gera um número máximo de 2 para um tipo de máquina
n2-standard-4.
Neste exemplo, você definiria a flag --max-workers como um valor de 2
com base no conjunto anterior de cálculos de exemplo. No entanto, lembre-se de usar seus
próprios valores e cálculos exclusivos ao implantar esta arquitetura de referência
no ambiente.
Paralelismo
Prática recomendada: defina o
parâmetro parallelism
no modelo do Dataflow do Pub/Sub para o Splunk como o dobro
do número de vCPUs usadas pelo número máximo de workers do
Dataflow.
O parâmetro parallelism ajuda a maximizar o número de conexões paralelas do HEC
do Splunk, o que maximiza a taxa de EPS do pipeline.
O valor parallelism padrão de 1 desativa o paralelismo e limita a
taxa de saída. É preciso substituir essa configuração padrão para considerar de duas a quatro
conexões paralelas por vCPU, com o número máximo de workers implantados. Como
regra, calcule o valor de substituição dessa configuração multiplicando o
número máximo de workers do Dataflow pelo número de vCPUs por
worker e, em seguida, dobrando esse valor.
Para determinar o número total de conexões paralelas com o HEC do Splunk em todos os workers do Dataflow, use a seguinte fórmula:
Cálculo de exemplo: usando o valor máximo de vCPUs de exemplo de 8 que foi calculado anteriormente para a contagem de máquinas, esta fórmula gera o número de conexões paralelas como 8 x 2 = 16.
Neste exemplo, você definiria o parâmetro parallelism como um valor de 16
com base no cálculo de exemplo anterior. No entanto, lembre-se de usar seus próprios
valores e cálculos exclusivos ao implantar esta arquitetura de referência
no ambiente.
Contagem de lotes
Prática recomendada: para permitir que o HEC do Splunk
processe eventos em lotes, e não um por vez, defina o
parâmetro batchCount com um valor entre 10 e 50 eventos/solicitação de registros.
A configuração da contagem de lotes ajuda a aumentar o EPS e reduzir a carga no
endpoint do HEC do Splunk. Essa configuração combina vários eventos em um único lote
para tornar o processamento mais eficiente. Recomendamos que você defina o parâmetro batchCount
como um valor entre 10 e 50 eventos/solicitação para registros, desde que o atraso máximo
de armazenamento em buffer de dois segundos seja aceitável.
Como o tamanho médio da mensagem de registro é de 1 KB neste exemplo, recomendamos
agrupar pelo menos 10 eventos por solicitação. Neste exemplo, você definiria o
parâmetro batchCount como um valor de 10. No entanto, lembre-se de usar seus próprios
valores e cálculos exclusivos ao implantar esta arquitetura de referência
no ambiente.
Para mais informações sobre essas recomendações de otimização de desempenho e custos, consulte Planejamento do pipeline do Dataflow.
A seguir
- Para acessar uma lista completa de parâmetros de modelo do Pub/Sub para o Splunk Dataflow, consulte a documentação do Pub/Sub para o Splunk Dataflow.
- Para acessar os modelos correspondentes do Terraform a fim de ter ajuda na implantação desta arquitetura
de referência, consulte o
repositório do GitHub
terraform-splunk-log-export. Ele inclui um painel predefinido do Cloud Monitoring para monitorar o pipeline do Dataflow do Splunk. - Para mais detalhes sobre as métricas personalizadas e a geração de registros do Splunk Dataflow, para monitorar e solucionar problemas dos pipelines do Splunk Dataflow, consulte este blog Novos recursos de observabilidade para os pipelines de streaming do Splunk Dataflow.
- Para mais arquiteturas de referência, diagramas e práticas recomendadas, confira a Central de arquitetura do Cloud.