Este documento mostra como começar a usar a ciência de dados em escala com o R no Google Cloud. Ele é destinado a quem tem alguma experiência com R e com notebooks Jupyter, além de se sentir confortável com SQL.
Este documento se concentra na análise de dados exploratória usando instâncias do Vertex AI Workbench e BigQuery. É possível encontrar o código complementar em um notebook do Jupyter que está no GitHub.
Visão geral
R é uma das linguagens de programação mais usadas para modelagem estatística. Ela tem uma comunidade grande e ativa de cientistas de dados e profissionais de machine learning (ML, na sigla em inglês). Com mais de 20.000 pacotes no repositório de código aberto da Comprehensive R Archive Network (CRAN) (em inglês), a R tem ferramentas para todos os aplicativos de análise de dados estatísticos, ML e visualização. A R tem crescido constante nas últimas duas décadas devido à expressividade da sintaxe e à amplitude de dados e bibliotecas de ML.
Como cientista de dados, é possível usar o conjunto de habilidades que você possui com a R e também aproveitar as vantagens dos serviços em nuvem totalmente gerenciados e escalonáveis para ciência de dados.
Arquitetura
Neste tutorial, você vai usar instâncias do Vertex AI Workbench como ambientes de ciência de dados para realizar a análise exploratória de dados (EDA). Você usa R em dados extraídos neste tutorial do BigQuery, o data warehouse em nuvem sem servidor, altamente escalonável e econômico do Google. Depois de analisar e processar os dados, os dados transformados são armazenados no Cloud Storage para outras tarefas de ML. Esse fluxo é mostrado no diagrama a seguir:

Dados de exemplo
Os dados de exemplo deste documento são do conjunto de dados de viagens de táxi da cidade de Nova York do BigQuery.
Esse conjunto de dados público inclui informações sobre os milhões de corridas de táxi que acontecem em Nova York todos os anos. Neste documento, você vai usar os dados de 2022, que estão na tabela bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022 no BigQuery.
Este documento se concentra na EDA e na visualização usando a R e o BigQuery. As etapas neste documento preparam você para uma meta de ML de prever o valor da tarifa de táxi (o valor antes de tributos, taxas e outros extras), considerando vários fatores sobre a viagem. A criação do modelo em si não é abordada neste documento.
Vertex AI Workbench
O Vertex AI Workbench é um serviço que oferece um ambiente integrado do JupyterLab, com os seguintes recursos:
- Implantação com um clique É possível usar um único clique para iniciar uma instância do JupyterLab pré-configurada com os frameworks de machine learning e ciência de dados mais recentes.
- Escalonamento por demanda. Comece com uma configuração de máquina pequena (por exemplo, 4 vCPUs e 16 GB de RAM, como neste documento). Quando seus dados ficarem muito grandes para uma máquina, você poderá escalonar verticalmente adicionando CPUs, RAM e GPUs.
- Google Cloud integration. As instâncias do Vertex AI Workbench são integradas a serviços do Google Cloud , como o BigQuery. Essa integração facilita o processo de ingestão de dados, pré-processamento e exploração.
- Cobrança por utilização. Não há taxa mínima nem compromissos imediatos. Para mais informações, consulte preços do Vertex AI Workbench. Você também paga pelos recursos do Google Cloud usados nos notebooks, como BigQuery e Cloud Storage.
Os notebooks de instâncias do Vertex AI Workbench são executados em Deep Learning VM Images. Este documento ajuda a criar uma instância do Vertex AI Workbench com o R 4.3.
Trabalhar com o BigQuery usando R
O BigQuery não requer gerenciamento de infraestrutura. Portanto, você pode se concentrar na descoberta de insights significativos. Você pode analisar grandes quantidades de dados em escala e preparar conjuntos de dados para ML usando os recursos analíticos avançados do BigQuery.
Para consultar dados do BigQuery usando R, use a bigrquery, uma biblioteca de código aberto da R. No pacote bigrquery, são fornecidos os seguintes níveis de abstração sobre o BigQuery:
- A API de nível inferior fornece wrappers finos sobre a API REST do BigQuery.
- A interface DBI envolve a API de nível inferior e torna o trabalho com o BigQuery semelhante a qualquer outro sistema de banco de dados. Essa é a camada mais conveniente, se você quiser executar consultas SQL no BigQuery ou fazer upload de menos de 100 MB.
- A interface dbplyr permite tratar tabelas do BigQuery como frames de dados na memória. Essa é a camada mais conveniente se você não quiser gravar SQL, mas quiser que o dbplyr a grave para você.
Este documento usa a API de baixo nível do bigrquery, sem a necessidade de DBI ou dbplyr.
Objetivos
- Crie uma instância do Vertex AI Workbench com suporte para R.
- Consulte e analise dados do BigQuery usando a biblioteca R do bigrquery.
- Preparar e armazenar dados para ML no Cloud Storage.
Custos
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
- BigQuery
- Vertex AI Workbench instances. You are also charged for resources used within notebooks, including compute resources, BigQuery, and API requests.
- Cloud Storage
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. No console Google Cloud , acesse a página Workbench.
Na guia Instâncias, clique em Criar nova.
Na janela Nova instância, clique em Criar. Para este tutorial, mantenha todos os valores padrão.
A instância do Vertex AI Workbench pode levar de 2 a 3 minutos para ser iniciada. Quando estiver pronta, a instância será listada automaticamente no painel Instâncias de notebook, e um link Abrir JupyterLab vai aparecer ao lado do nome da instância. Se o link para abrir o JupyterLab não aparecer na lista depois de alguns minutos, atualize a página.
Na lista de instâncias, clique em Abrir o JupyterLab. Isso abre o ambiente do JupyterLab em outra guia do navegador.
No ambiente do JupyterLab, clique em Novo acesso rápido e, em seguida, na guia Acesso rápido, clique em Terminal.
No painel do terminal, instale o R:
conda create -n r conda activate r conda install -c r r-essentials r-base=4.3.2Durante a instalação, sempre que for solicitado a continuar, digite
y. A instalação pode levar alguns minutos para ser concluída. Quando a instalação for concluída, a saída será semelhante a esta:done Executing transaction: done ® jupyter@instance-INSTANCE_NUMBER:~$Em que INSTANCE_NUMBER é o número exclusivo atribuído à instância do Vertex AI Workbench.
Depois que os comandos terminarem de ser executados no terminal, atualize a página do navegador e abra o acesso rápido clicando em Novo acesso rápido.
A guia "Acesso rápido" mostra opções para iniciar o R em um notebook ou no console e para criar um arquivo R.
Clique na guia Terminal e clone o repositório do GitHub vertex-ai-samples:
git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.gitQuando o comando for concluído, você verá a pasta
vertex-ai-samplesno painel do navegador de arquivos do ambiente do JupyterLab.No navegador de arquivos, abra
vertex-ai-samples>notebooks>community>exploratory_data_analysis. O notebookeda_with_r_and_bigquery.ipynbvai aparecer.No navegador de arquivos, abra o notebook
eda_with_r_and_bigquery.ipynb.Este notebook aborda a análise exploratória de dados com R e BigQuery. Durante o restante deste documento, você vai trabalhar no notebook e executar o código que aparece nele.
Verifique a versão do R que o notebook está usando:
versionO campo
version.stringna saída vai mostrarR version 4.3.2, que você instalou na seção anterior.Verifique e instale os pacotes R necessários, caso eles ainda não estejam disponíveis na sessão atual:
# List the necessary packages needed_packages <- c("dplyr", "ggplot2", "bigrquery") # Check if packages are installed installed_packages <- .packages(all.available = TRUE) missing_packages <- needed_packages[!(needed_packages %in% installed_packages)] # If any packages are missing, install them if (length(missing_packages) > 0) { install.packages(missing_packages) }Carregue os pacotes necessários:
# Load the required packages lapply(needed_packages, library, character.only = TRUE)Autentique
bigrqueryusando a autenticação fora da banda:bq_auth(use_oob = True)Defina o nome do projeto que você quer usar para este notebook substituindo
[YOUR-PROJECT-ID]por um nome:# Set the project ID PROJECT_ID <- "[YOUR-PROJECT-ID]"Defina o nome do bucket do Cloud Storage em que os dados de saída serão armazenados. Para isso, substitua
[YOUR-BUCKET-NAME]por um nome globalmente exclusivo:BUCKET_NAME <- "[YOUR-BUCKET-NAME]"Defina a altura e a largura padrão para os gráficos que serão gerados mais tarde no notebook:
options(repr.plot.height = 9, repr.plot.width = 16)Crie uma instrução SQL do BigQuery que extraia alguns possíveis indicadores e a variável de previsão de destino para uma amostra de viagens. A consulta a seguir filtra alguns valores discrepantes ou sem sentido nos campos que estão sendo lidos para análise.
sql_query_template <- " SELECT TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes, passenger_count, ROUND(trip_distance, 1) AS trip_distance_miles, rate_code, /* Mapping from rate code to type from description column in BigQuery table schema */ (CASE WHEN rate_code = '1.0' THEN 'Standard rate' WHEN rate_code = '2.0' THEN 'JFK' WHEN rate_code = '3.0' THEN 'Newark' WHEN rate_code = '4.0' THEN 'Nassau or Westchester' WHEN rate_code = '5.0' THEN 'Negotiated fare' WHEN rate_code = '6.0' THEN 'Group ride' /* Several NULL AND some '99.0' values go here */ ELSE 'Unknown' END) AS rate_type, fare_amount, CAST(ABS(FARM_FINGERPRINT( CONCAT( CAST(trip_distance AS STRING), CAST(fare_amount AS STRING) ) )) AS STRING) AS key FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` /* Filter out some outlier or hard to understand values */ WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) LIMIT %s "A coluna
keyé um identificador de linha gerado com base nos valores concatenados das colunastrip_distanceefare_amount.Execute a consulta e recupere os mesmos dados como um tibble na memória, que é como um dataframe.
sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) taxi_trip_data <- bq_table_download( bq_project_query( PROJECT_ID, query = sql_query ) )Veja os resultados recuperados:
head(taxi_trip_data)A saída é uma tabela semelhante à imagem a seguir:
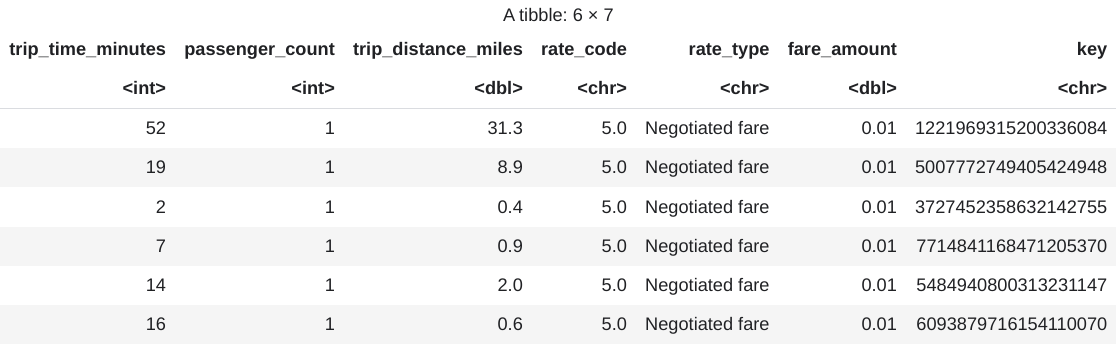
Os resultados mostram estas colunas de dados de viagem:
- Número inteiro
trip_time_minutes - Número inteiro
passenger_count trip_distance_milesduplarate_codecaractererate_typecaracterefare_amountduplakeycaractere
- Número inteiro
Veja o número de linhas e tipos de dados de cada coluna:
str(taxi_trip_data)A saída será assim:
tibble [10,000 x 7] (S3: tbl_df/tbl/data.frame) $ trip_time_minutes : int [1:10000] 52 19 2 7 14 16 1 2 2 6 ... $ passenger_count : int [1:10000] 1 1 1 1 1 1 1 1 3 1 ... $ trip_distance_miles: num [1:10000] 31.3 8.9 0.4 0.9 2 0.6 1.7 0.4 0.5 0.2 ... $ rate_code : chr [1:10000] "5.0" "5.0" "5.0" "5.0" ... $ rate_type : chr [1:10000] "Negotiated fare" "Negotiated fare" "Negotiated fare" "Negotiated fare" ... $ fare_amount : num [1:10000] 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 ... $ key : chr [1:10000] "1221969315200336084" 5007772749405424948" "3727452358632142755" "77714841168471205370" ...Veja um resumo dos dados recuperados:
summary(taxi_trip_data)O resultado será assim:
trip_time_minutes passenger_count trip_distance_miles rate_code Min. : 1.00 Min. :1.000 Min. : 0.000 Length:10000 1st Qu.: 20.00 1st Qu.:1.000 1st Qu.: 3.700 Class :character Median : 24.00 Median :1.000 Median : 4.800 Mode :character Mean : 30.32 Mean :1.465 Mean : 9.639 3rd Qu.: 39.00 3rd Qu.:2.000 3rd Qu.:17.600 Max. :120.00 Max. :9.000 Max. :43.700 rate_type fare_amount key Length:10000 Min. : 0.01 Length:10000 Class :character 1st Qu.: 16.50 Class :character Mode :character Median : 16.50 Mode :character Mean : 31.22 3rd Qu.: 52.00 Max. :182.50Exiba a distribuição dos valores
fare_amountusando um histograma:ggplot( data = taxi_trip_data, aes(x = fare_amount) ) + geom_histogram(bins = 100)O gráfico resultante é semelhante ao da imagem a seguir:
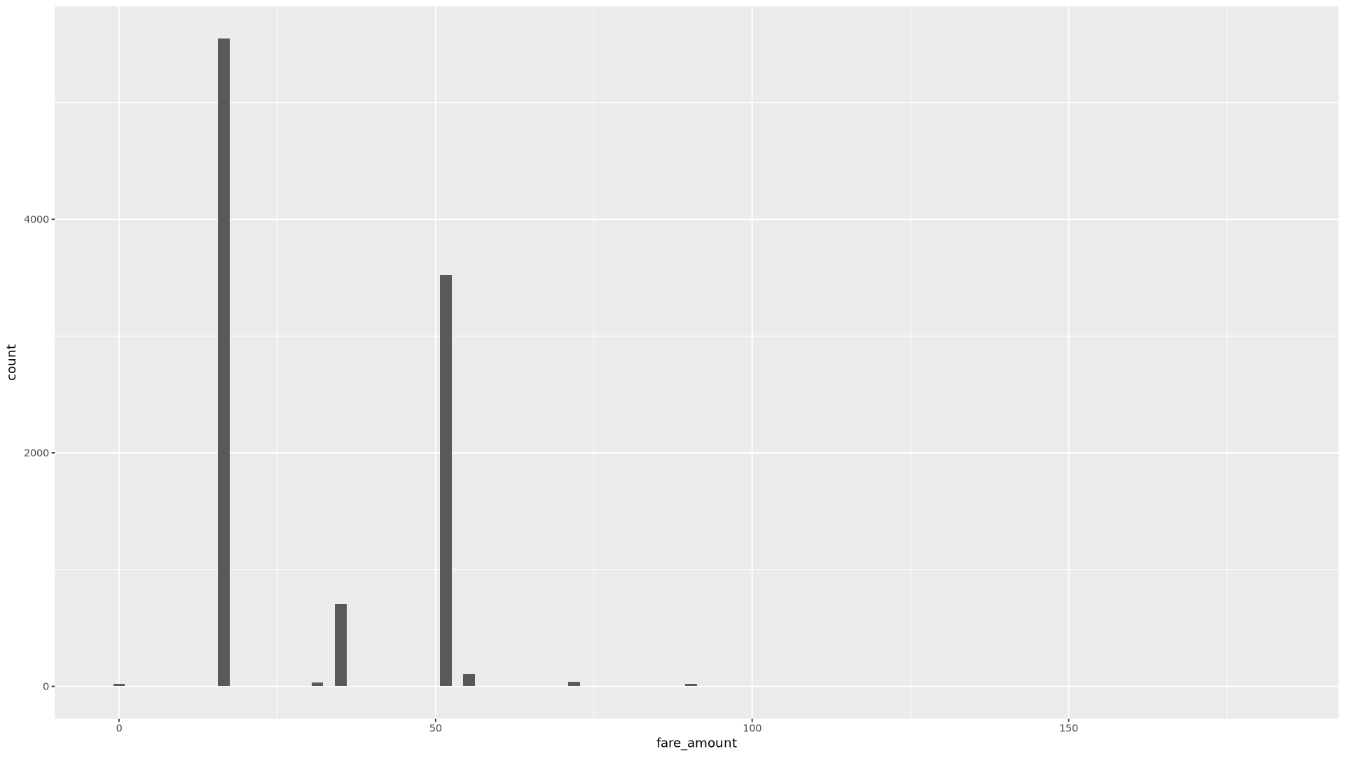
Exiba o relacionamento entre
trip_distanceefare_amountusando um gráfico de dispersão:ggplot( data = taxi_trip_data, aes(x = trip_distance_miles, y = fare_amount) ) + geom_point() + geom_smooth(method = "lm")O gráfico resultante é semelhante ao da imagem a seguir:
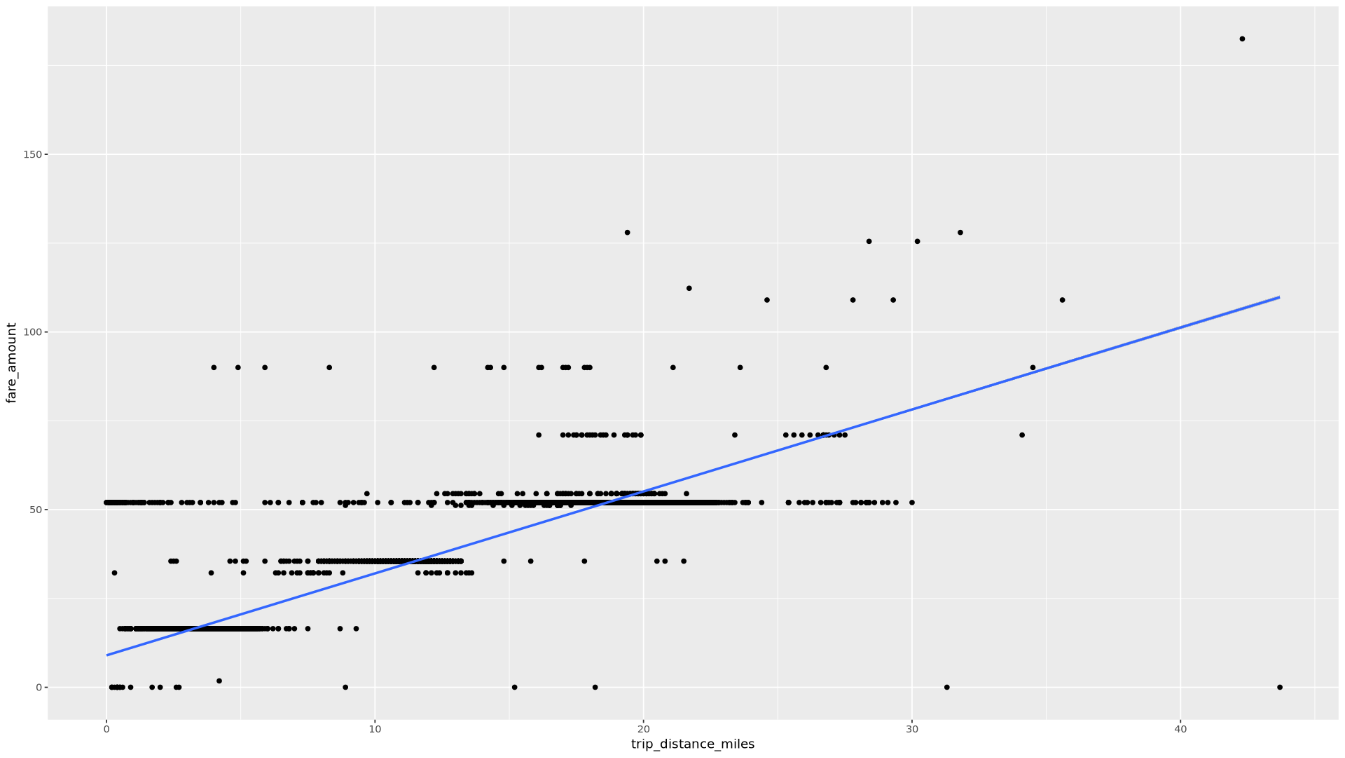
No notebook, crie uma função que encontre o número de viagens e o valor médio da tarifa para cada valor da coluna escolhida:
get_distinct_value_aggregates <- function(column) { query <- paste0( 'SELECT ', column, ', COUNT(1) AS num_trips, AVG(fare_amount) AS avg_fare_amount FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) GROUP BY 1 ' ) bq_table_download( bq_project_query( PROJECT_ID, query = query ) ) }Invoque a função usando a coluna
trip_time_minutes, que é definida com a funcionalidade de carimbo de data/hora no BigQuery:df <- get_distinct_value_aggregates( 'TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes') ggplot( data = df, aes(x = trip_time_minutes, y = num_trips) ) + geom_line() ggplot( data = df, aes(x = trip_time_minutes, y = avg_fare_amount) ) + geom_line()O notebook mostra dois gráficos. O primeiro gráfico mostra o número de viagens por duração em minutos. O segundo gráfico mostra o valor médio da tarifa das viagens por tempo de viagem.
A saída do primeiro comando
ggploté a seguinte, mostrando o número de viagens por duração (em minutos):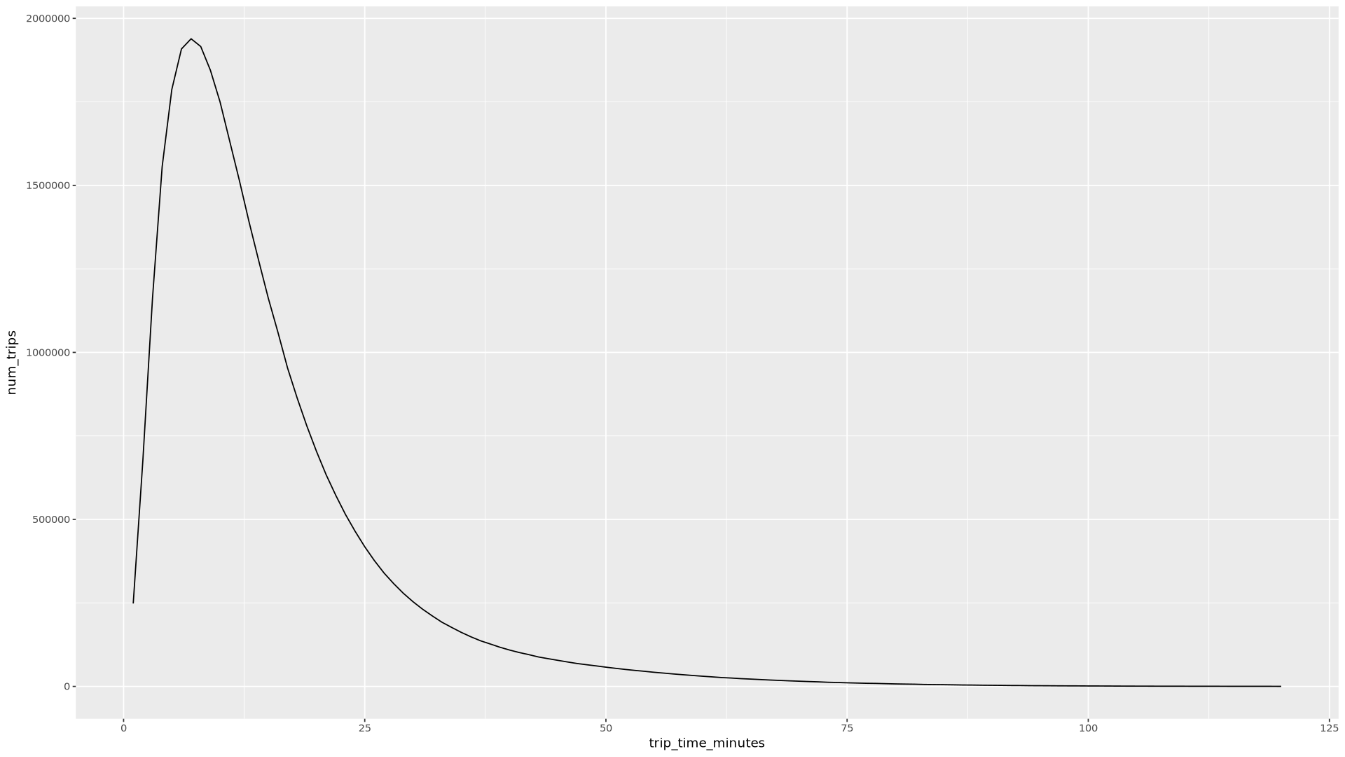
A saída do segundo comando
ggploté a seguinte, mostrando o valor médio da tarifa das viagens por tempo de viagem: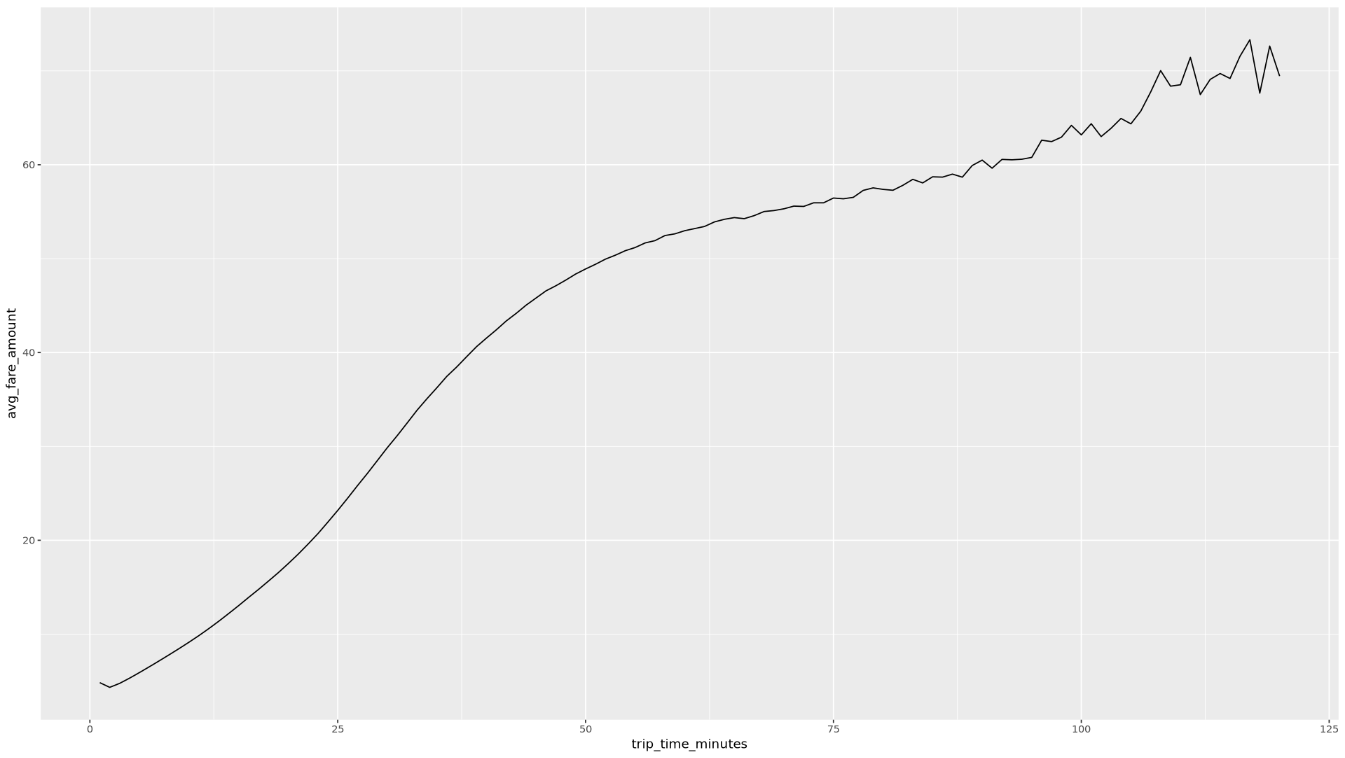
Para ver mais exemplos de visualização com outros campos nos dados, consulte o notebook.
No notebook, carregue os dados de treinamento e avaliação do BigQuery em R:
# Prepare training and evaluation data from BigQuery sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) # Split data into 75% training, 25% evaluation train_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) <= 75') eval_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) > 75') # Load training data to data frame train_data <- bq_table_download( bq_project_query( PROJECT_ID, query = train_query ) ) # Load evaluation data to data frame eval_data <- bq_table_download( bq_project_query( PROJECT_ID, query = eval_query ) )Verifique o número de observações em cada conjunto de dados:
print(paste0("Training instances count: ", nrow(train_data))) print(paste0("Evaluation instances count: ", nrow(eval_data)))Aproximadamente 75% do total de instâncias devem estar no treinamento, e cerca de 25% das instâncias restantes na avaliação.
Grave os dados em um arquivo CSV local:
# Write data frames to local CSV files, with headers dir.create(file.path('data'), showWarnings = FALSE) write.table(train_data, "data/train_data.csv", row.names = FALSE, col.names = TRUE, sep = ",") write.table(eval_data, "data/eval_data.csv", row.names = FALSE, col.names = TRUE, sep = ",")Faça o upload dos arquivos CSV para o Cloud Storage unindo comandos
gsutilque são passados para o sistema:# Upload CSV data to Cloud Storage by passing gsutil commands to system gcs_url <- paste0("gs://", BUCKET_NAME, "/") command <- paste("gsutil mb", gcs_url) system(command) gcs_data_dir <- paste0("gs://", BUCKET_NAME, "/data") command <- paste("gsutil cp data/*_data.csv", gcs_data_dir) system(command) command <- paste("gsutil ls -l", gcs_data_dir) system(command, intern = TRUE)Também é possível fazer upload de arquivos CSV para o Cloud Storage usando a biblioteca googleCloudStorageR, que invoca a API JSON do Cloud Storage.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Saiba mais sobre como usar os dados do BigQuery nos seus notebooks R na documentação do bigrquery.
- Conheça as práticas recomendadas para engenharia de ML em Regras de ML.
- Para uma visão geral dos princípios e recomendações de arquitetura específicos para cargas de trabalho de IA e ML no Google Cloud, consulte a perspectiva de IA e ML no framework bem arquitetado.
- Para mais arquiteturas de referência, diagramas e práticas recomendadas, confira a Central de arquitetura do Cloud.
- Jason Davenport | Mediador de desenvolvedores
- Firat Tekiner | Gerente de produtos sênior
Criar uma instância do Vertex AI Workbench
A primeira etapa é criar uma instância do Vertex AI Workbench que você pode usar neste tutorial.
Abrir o JupyterLab e instalar o R
Para concluir o tutorial no notebook, abra o ambiente do JupyterLab, instale o R, clone o repositório do GitHub vertex-ai-samples e abra o notebook.
Abra o notebook e configure o R
Consultar dados do BigQuery
Nesta seção do notebook, leia os resultados da execução de uma instrução SQL do BigQuery em R e analise detalhadamente os dados.
Visualizar dados usando ggplot2
Nesta seção do notebook, você usa a biblioteca ggplot2 em R para estudar algumas das variáveis do conjunto de dados de exemplo.
Processar os dados no BigQuery com o R
Ao trabalhar com grandes conjuntos de dados, recomendamos que você faça o maior número de análises possíveis (agregação, filtragem, mesclagem, computação de colunas etc.) no BigQuery e recupere os resultados. Executar essas tarefas em R é menos eficiente. O uso do BigQuery para análise aproveita a escalonabilidade e o desempenho do BigQuery, além de garantir que os resultados retornados possam caber na memória no R.
Salvar dados como arquivos CSV no Cloud Storage
A próxima tarefa é salvar dados extraídos do BigQuery como arquivos CSV no Cloud Storage para usá-los em outras tarefas de ML.
Também é possível usar bigrquery para gravar dados do R de volta no BigQuery. A gravação de volta no BigQuery geralmente é feita após a conclusão de algum pré-processamento ou a geração de resultados que serão usados para análises mais detalhadas.
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste documento, remova-os.
Excluir o projeto
A maneira mais fácil de evitar cobranças é excluir o projeto criado. Se você planeja explorar várias arquiteturas, tutoriais ou guias de início rápido, a reutilização de projetos pode evitar que você exceda os limites da cota.
A seguir
Colaboradores
Autor: Alok Pattani | Mediador de desenvolvedores
Outros colaboradores: