Neste documento, descrevemos como implantar um pipeline do Dataflow para processar arquivos de imagem em grande escala com a API Cloud Vision. Esse pipeline armazena os resultados dos arquivos processados no BigQuery. É possível usar os arquivos para fins analíticos ou para treinar modelos do BigQuery ML.
O pipeline do Dataflow criado nessa implantação pode processar milhões de imagens por dia. O único limite é sua cota da API Vision. É possível aumentar a cota da API Vision com base nos seus requisitos de escala.
Estas instruções são destinadas a engenheiros dados e cientistas de dados. Neste documento, consideramos que você tem conhecimento básico sobre a criação de pipelines do Dataflow usando o SDK do Apache Beam para Java, o GoogleSQL para BigQuery e scripts de shell básicos. Também consideramos que você tem familiaridade com a API Vision.
Arquitetura
O diagrama a seguir ilustra o fluxo do sistema para criar uma solução de análise de visão de ML.

No diagrama anterior, as informações fluem pela arquitetura da seguinte maneira:
- Um cliente faz upload de arquivos de imagem para um bucket do Cloud Storage.
- O Cloud Storage envia uma mensagem sobre o upload de dados para o Pub/Sub.
- O Pub/Sub notifica o Dataflow sobre o upload.
- O pipeline do Dataflow envia as imagens para a API Vision.
- A API Vision processa as imagens e retorna as anotações.
- O pipeline envia os arquivos anotados ao BigQuery para você analisar.
Objetivos
- Criar um pipeline do Apache Beam para análise das imagens carregadas no Cloud Storage.
- Usar o Dataflow Runner v2 para executar o pipeline do Apache Beam em modo de streaming e analisar as imagens assim que o upload delas for feito.
- Usar a API Vision para analisar imagens de um conjunto de tipos de recursos.
- Analisar anotações com o BigQuery.
Custos
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na sua projeção de uso,
use a calculadora de preços.
Quando você terminar de criar o aplicativo de exemplo, exclua os recursos criados para evitar a cobrança contínua. Saiba mais em Limpeza.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
- Clone o repositório do GitHub que contém o código-fonte do pipeline do Dataflow:
git clone https://github.com/GoogleCloudPlatform/dataflow-vision-analytics.git - Acesse a pasta raiz do repositório:
cd dataflow-vision-analytics - Siga as instruções na seção Primeiros passos do repositório dataflow-vision-analytics no GitHub para realizar as seguintes tarefas:
- Ative várias APIs.
- Criar um bucket do Cloud Storage.
- Criar um tópico e uma assinatura do Pub/Sub
- Crie um conjunto de dados do BigQuery.
- Configure diversas variáveis de ambiente para esta implantação.
Como executar o pipeline do Dataflow para todos os recursos da API Vision implementados
O pipeline do Dataflow solicita e processa um conjunto específico de recursos e atributos da API Vision nos arquivos anotados.
Os parâmetros listados na tabela a seguir são específicos para o pipeline do Dataflow nesta implantação. Para ver a lista completa de parâmetros de execução padrão do Dataflow, consulte Definir opções de pipeline do Dataflow.
| Nome do parâmetro | Descrição |
|---|---|
|
O número de imagens a serem incluídas em uma solicitação à API Vision. O padrão é 1. É possível aumentar esse valor até um máximo de 16. |
|
O nome do conjunto de dados de saída do BigQuery. |
|
Uma lista de recursos de processamento de imagem. O pipeline é compatível com os recursos de rótulo, ponto de referência, logotipo, rosto, dica de corte e propriedades da imagem. |
|
O parâmetro que define o número máximo de chamadas paralelas para a API Vision. O padrão é 1. |
|
Parâmetros de string com nomes de tabela para várias anotações. Os valores padrão são fornecidos para cada tabela, por exemplo, label_annotation. |
|
O tempo de espera antes de processar imagens quando há um lote incompleto de imagens. O padrão é 30 segundos. |
|
O ID da assinatura do Pub/Sub que recebe notificações de entrada do Cloud Storage. |
|
O ID do projeto a ser usado para a API Vision. |
No Cloud Shell, execute o seguinte comando para processar imagens de todos os tipos de recursos compatíveis com o pipeline do Dataflow:
./gradlew run --args=" \ --jobName=test-vision-analytics \ --streaming \ --runner=DataflowRunner \ --enableStreamingEngine \ --diskSizeGb=30 \ --project=${PROJECT} \ --datasetName=${BIGQUERY_DATASET} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=IMAGE_PROPERTIES,LABEL_DETECTION,LANDMARK_DETECTION,LOGO_DETECTION,CROP_HINTS,FACE_DETECTION"A conta de serviço dedicada precisa ter acesso de leitura ao bucket que contém as imagens. Em outras palavras, essa conta precisa ter o papel
roles/storage.objectViewerconcedido nesse bucket.Para mais informações sobre como usar uma conta de serviço dedicada, consulte Segurança e permissões do Dataflow.
Abra o URL exibido em uma nova guia do navegador ou acesse a página Jobs do Dataflow e selecione o pipeline test-vision-analytics.
Após alguns segundos, o gráfico do job do Dataflow é exibido:
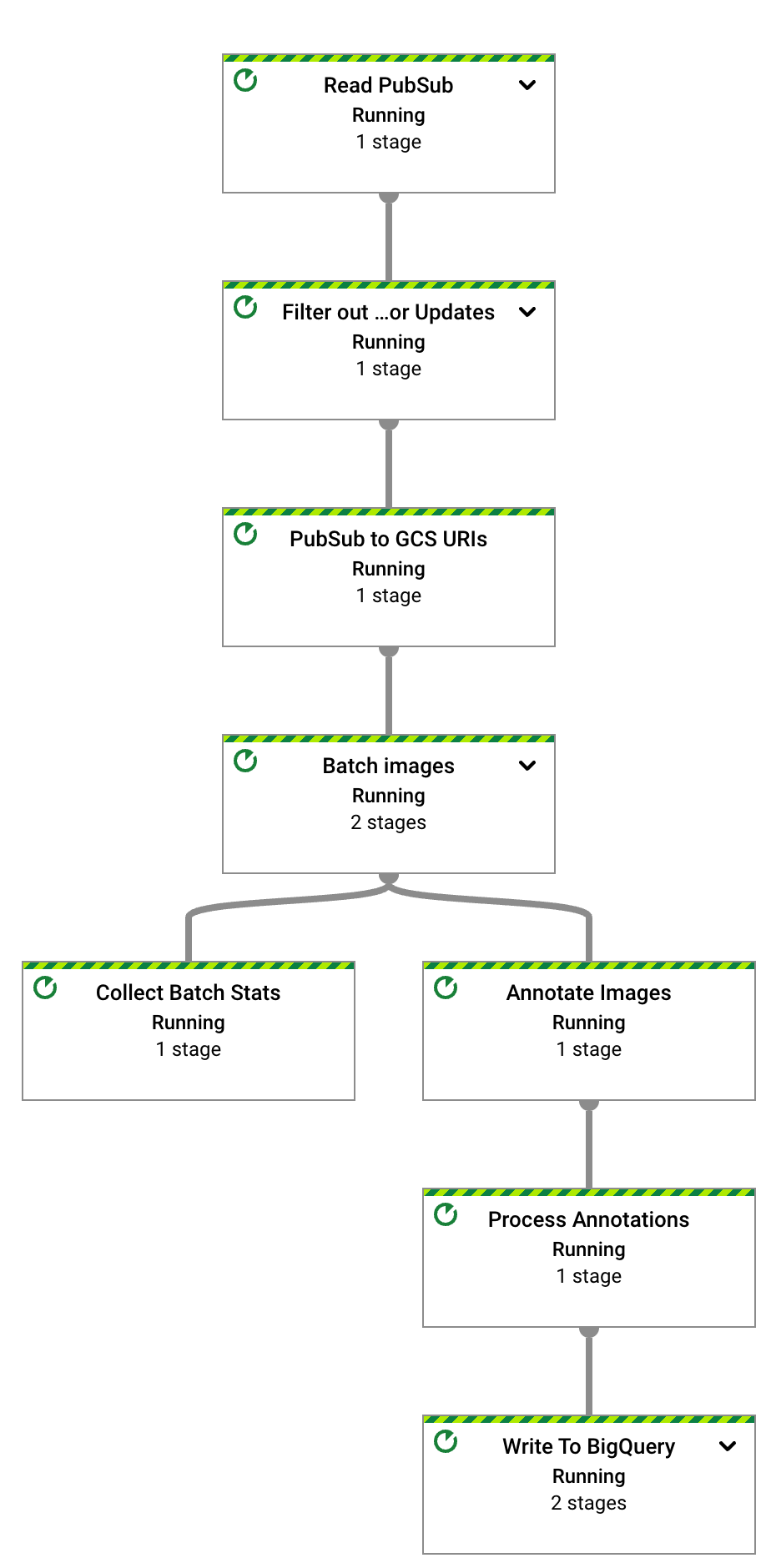
O pipeline do Dataflow está agora em execução e aguardando receber notificações de entrada da assinatura do Pub/Sub.
Acione o processamento de imagens do Dataflow fazendo upload dos seis arquivos de amostra no bucket de entrada:
gcloud storage cp data-sample/* gs://${IMAGE_BUCKET}No console do Google Cloud, localize o painel "Contadores personalizados" e use-o para analisar esses contadores no Dataflow e verificar se o Dataflow processou as seis imagens. Use a funcionalidade de filtro do painel para navegar até as métricas corretas. Para exibir apenas os contadores que começam com o prefixo
numberOf, digitenumberOfno filtro.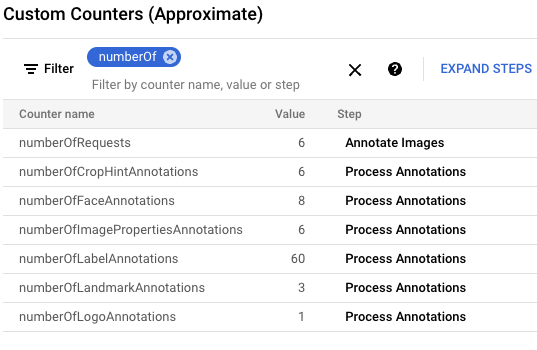
No Cloud Shell, confirme se as tabelas foram criadas automaticamente:
bq query --nouse_legacy_sql "SELECT table_name FROM ${BIGQUERY_DATASET}.INFORMATION_SCHEMA.TABLES ORDER BY table_name"A resposta é a seguinte:
+----------------------+ | table_name | +----------------------+ | crop_hint_annotation | | face_annotation | | image_properties | | label_annotation | | landmark_annotation | | logo_annotation | +----------------------+
Visualize o esquema da tabela
landmark_annotation. O recursoLANDMARK_DETECTIONcaptura os atributos retornados da chamada de API.bq show --schema --format=prettyjson ${BIGQUERY_DATASET}.landmark_annotationA saída será a seguinte:
[ { "name":"gcs_uri", "type":"STRING" }, { "name":"feature_type", "type":"STRING" }, { "name":"transaction_timestamp", "type":"STRING" }, { "name":"mid", "type":"STRING" }, { "name":"description", "type":"STRING" }, { "name":"score", "type":"FLOAT" }, { "fields":[ { "fields":[ { "name":"x", "type":"INTEGER" }, { "name":"y", "type":"INTEGER" } ], "mode":"REPEATED", "name":"vertices", "type":"RECORD" } ], "name":"boundingPoly", "type":"RECORD" }, { "fields":[ { "fields":[ { "name":"latitude", "type":"FLOAT" }, { "name":"longitude", "type":"FLOAT" } ], "name":"latLon", "type":"RECORD" } ], "mode":"REPEATED", "name":"locations", "type":"RECORD" } ]Confira os dados de anotação produzidos pela API executando os seguintes comandos
bq querypara ver todos os pontos de referência encontrados nessas seis imagens ordenados pela pontuação mais provável:bq query --nouse_legacy_sql "SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score, locations FROM ${BIGQUERY_DATASET}.landmark_annotation ORDER BY score DESC"O resultado será assim:
+------------------+-------------------+------------+---------------------------------+ | file_name | description | score | locations | +------------------+-------------------+------------+---------------------------------+ | eiffel_tower.jpg | Eiffel Tower | 0.7251996 | ["POINT(2.2944813 48.8583701)"] | | eiffel_tower.jpg | Trocadéro Gardens | 0.69601923 | ["POINT(2.2892823 48.8615963)"] | | eiffel_tower.jpg | Champ De Mars | 0.6800974 | ["POINT(2.2986304 48.8556475)"] | +------------------+-------------------+------------+---------------------------------+
Para ver descrições detalhadas de todas as colunas específicas de anotações, consulte
AnnotateImageResponse.Para interromper o pipeline de streaming, execute o comando a seguir. O pipeline continua em execução mesmo que não haja mais notificações do Pub/Sub para processar.
gcloud dataflow jobs cancel --region ${REGION} $(gcloud dataflow jobs list --region ${REGION} --filter="NAME:test-vision-analytics AND STATE:Running" --format="get(JOB_ID)")A seção a seguir contém mais exemplos de consultas que analisam diferentes recursos de imagem das imagens.
Como analisar um conjunto de dados do Flickr30K
Nesta seção, você detecta rótulos e pontos de referência no conjunto de dados público de imagens do Flickr30k hospedado no Kaggle.
No Cloud Shell, altere os parâmetros do pipeline do Dataflow para que ele seja otimizado para um conjunto de dados grande. Para permitir maior capacidade de processamento, aumente também os valores
batchSizeekeyRange. O Dataflow escalona o número de workers conforme necessário../gradlew run --args=" \ --runner=DataflowRunner \ --jobName=vision-analytics-flickr \ --streaming \ --enableStreamingEngine \ --diskSizeGb=30 \ --autoscalingAlgorithm=THROUGHPUT_BASED \ --maxNumWorkers=5 \ --project=${PROJECT} \ --region=${REGION} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=LABEL_DETECTION,LANDMARK_DETECTION \ --datasetName=${BIGQUERY_DATASET} \ --batchSize=16 \ --keyRange=5"Como o conjunto de dados é grande, não é possível usar o Cloud Shell para recuperar as imagens do Kaggle e enviá-las para o bucket do Cloud Storage. Você precisa usar uma VM com um tamanho de disco maior para fazer isso.
Para recuperar imagens baseadas no Kaggle e enviá-las para o bucket do Cloud Storage, siga as instruções na seção Simular as imagens que estão sendo transferidas para o bucket de armazenamento no repositório do GitHub.
Para observar o progresso do processo de cópia analisando as métricas personalizadas disponíveis na interface do Dataflow, navegue até a página Jobs do Dataflow e selecione o pipeline
vision-analytics-flickr. Os contadores do cliente precisam mudar periodicamente até que o pipeline do Dataflow processe todos os arquivos.A saída é semelhante à captura de tela a seguir do painel "Contadores personalizados". Um dos arquivos no conjunto de dados tem o tipo errado, e o contador
rejectedFilesreflete isso. Esses valores de contador são aproximados. Talvez você veja números mais altos. Além disso, o número de anotações provavelmente mudará devido ao aumento da acurácia do processamento da API Vision.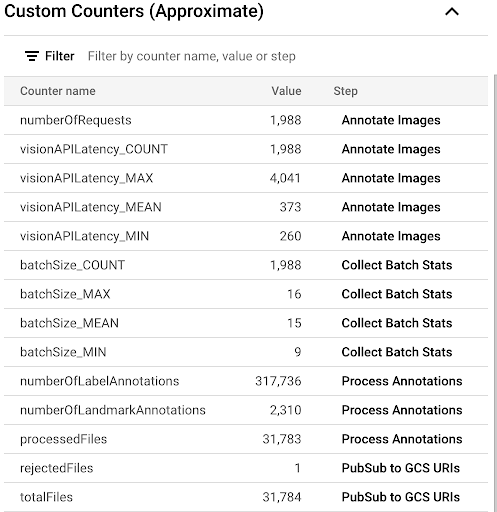
Para determinar se você está se aproximando ou excedendo os recursos disponíveis, consulte a página de cotas da API Vision.
Em nosso exemplo, o pipeline do Dataflow usou apenas cerca de 50% da cota. Com base na porcentagem da cota usada, é possível decidir aumentar o paralelismo do pipeline aumentando o valor do parâmetro
keyRange.Encerre o pipeline:
gcloud dataflow jobs list --region $REGION --filter="NAME:vision-analytics-flickr AND STATE:Running" --format="get(JOB_ID)"
Analisar anotações no BigQuery
Nesta implantação, você processou mais de 30.000 imagens para anotações de rótulos e pontos de referência. Nesta seção, você reunirá estatísticas sobre esses arquivos. É possível executar essas consultas no espaço de trabalho do GoogleSQL para BigQuery ou usar a ferramenta de linha de comando bq.
Os números exibidos podem ser diferentes dos resultados da consulta de amostra nesta implantação. A API Vision melhora constantemente a acurácia da análise. Ela pode produzir resultados aprimorados ao analisar a mesma imagem depois que você testa a solução inicialmente.
No console do Google Cloud, acesse a página Editor de consultas do BigQuery e execute o seguinte comando para ver os 20 principais rótulos no conjunto de dados:
SELECT description, count(*)ascount \ FROM vision_analytics.label_annotation GROUP BY description ORDER BY count DESC LIMIT 20O resultado será assim:
+------------------+-------+ | description | count | +------------------+-------+ | Leisure | 7663 | | Plant | 6858 | | Event | 6044 | | Sky | 6016 | | Tree | 5610 | | Fun | 5008 | | Grass | 4279 | | Recreation | 4176 | | Shorts | 3765 | | Happy | 3494 | | Wheel | 3372 | | Tire | 3371 | | Water | 3344 | | Vehicle | 3068 | | People in nature | 2962 | | Gesture | 2909 | | Sports equipment | 2861 | | Building | 2824 | | T-shirt | 2728 | | Wood | 2606 | +------------------+-------+
Determine quais outros rótulos estão presentes em uma imagem com um rótulo específico, classificados por frequência:
DECLARE label STRING DEFAULT 'Plucked string instruments'; WITH other_labels AS ( SELECT description, COUNT(*) count FROM vision_analytics.label_annotation WHERE gcs_uri IN ( SELECT gcs_uri FROM vision_analytics.label_annotation WHERE description = label ) AND description != label GROUP BY description) SELECT description, count, RANK() OVER (ORDER BY count DESC) rank FROM other_labels ORDER BY rank LIMIT 20;A resposta é a seguinte: Para o rótulo Instrumentos de cordas dedilhadas usado no comando anterior, você verá:
+------------------------------+-------+------+ | description | count | rank | +------------------------------+-------+------+ | String instrument | 397 | 1 | | Musical instrument | 236 | 2 | | Musician | 207 | 3 | | Guitar | 168 | 4 | | Guitar accessory | 135 | 5 | | String instrument accessory | 99 | 6 | | Music | 88 | 7 | | Musical instrument accessory | 72 | 8 | | Guitarist | 72 | 8 | | Microphone | 52 | 10 | | Folk instrument | 44 | 11 | | Violin family | 28 | 12 | | Hat | 23 | 13 | | Entertainment | 22 | 14 | | Band plays | 21 | 15 | | Jeans | 17 | 16 | | Plant | 16 | 17 | | Public address system | 16 | 17 | | Artist | 16 | 17 | | Leisure | 14 | 20 | +------------------------------+-------+------+
Veja os 10 principais pontos de referência detectados:
SELECT description, COUNT(description) AS count FROM vision_analytics.landmark_annotation GROUP BY description ORDER BY count DESC LIMIT 10A saída será a seguinte:
+--------------------+-------+ | description | count | +--------------------+-------+ | Times Square | 55 | | Rockefeller Center | 21 | | St. Mark's Square | 16 | | Bryant Park | 13 | | Millennium Park | 13 | | Ponte Vecchio | 13 | | Tuileries Garden | 13 | | Central Park | 12 | | Starbucks | 12 | | National Mall | 11 | +--------------------+-------+
Determine as imagens que provavelmente contêm cachoeiras:
SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score FROM vision_analytics.landmark_annotation WHERE LOWER(description) LIKE '%fall%' ORDER BY score DESC LIMIT 10A saída será a seguinte:
+----------------+----------------------------+-----------+ | file_name | description | score | +----------------+----------------------------+-----------+ | 895502702.jpg | Waterfall Carispaccha | 0.6181358 | | 3639105305.jpg | Sahalie Falls Viewpoint | 0.44379658 | | 3672309620.jpg | Gullfoss Falls | 0.41680416 | | 2452686995.jpg | Wahclella Falls | 0.39005348 | | 2452686995.jpg | Wahclella Falls | 0.3792498 | | 3484649669.jpg | Kodiveri Waterfalls | 0.35024035 | | 539801139.jpg | Mallela Thirtham Waterfall | 0.29260656 | | 3639105305.jpg | Sahalie Falls | 0.2807213 | | 3050114829.jpg | Kawasan Falls | 0.27511594 | | 4707103760.jpg | Niagara Falls | 0.18691841 | +----------------+----------------------------+-----------+
Encontre imagens de pontos de referência dentro de três quilômetros do Coliseu em Roma (a função
ST_GEOPOINTusa a longitude e a latitude do Coliseu):WITH landmarksWithDistances AS ( SELECT gcs_uri, description, location, ST_DISTANCE(location, ST_GEOGPOINT(12.492231, 41.890222)) distance_in_meters, FROM `vision_analytics.landmark_annotation` landmarks CROSS JOIN UNNEST(landmarks.locations) AS location ) SELECT SPLIT(gcs_uri,"/")[OFFSET(3)] file, description, ROUND(distance_in_meters) distance_in_meters, location, CONCAT("https://storage.cloud.google.com/", SUBSTR(gcs_uri, 6)) AS image_url FROM landmarksWithDistances WHERE distance_in_meters < 3000 ORDER BY distance_in_meters LIMIT 100Ao executar a consulta, você verá várias imagens do Coliseu, mas também do Arco de Constantino, do Monte Palatino e de vários outros lugares fotografados com frequência.
Para ver os dados no BigQuery Geo Viz, cole na consulta anterior. Selecione um ponto no mapa para ver os detalhes. O atributo
Image_urlcontém um link para o arquivo de imagem.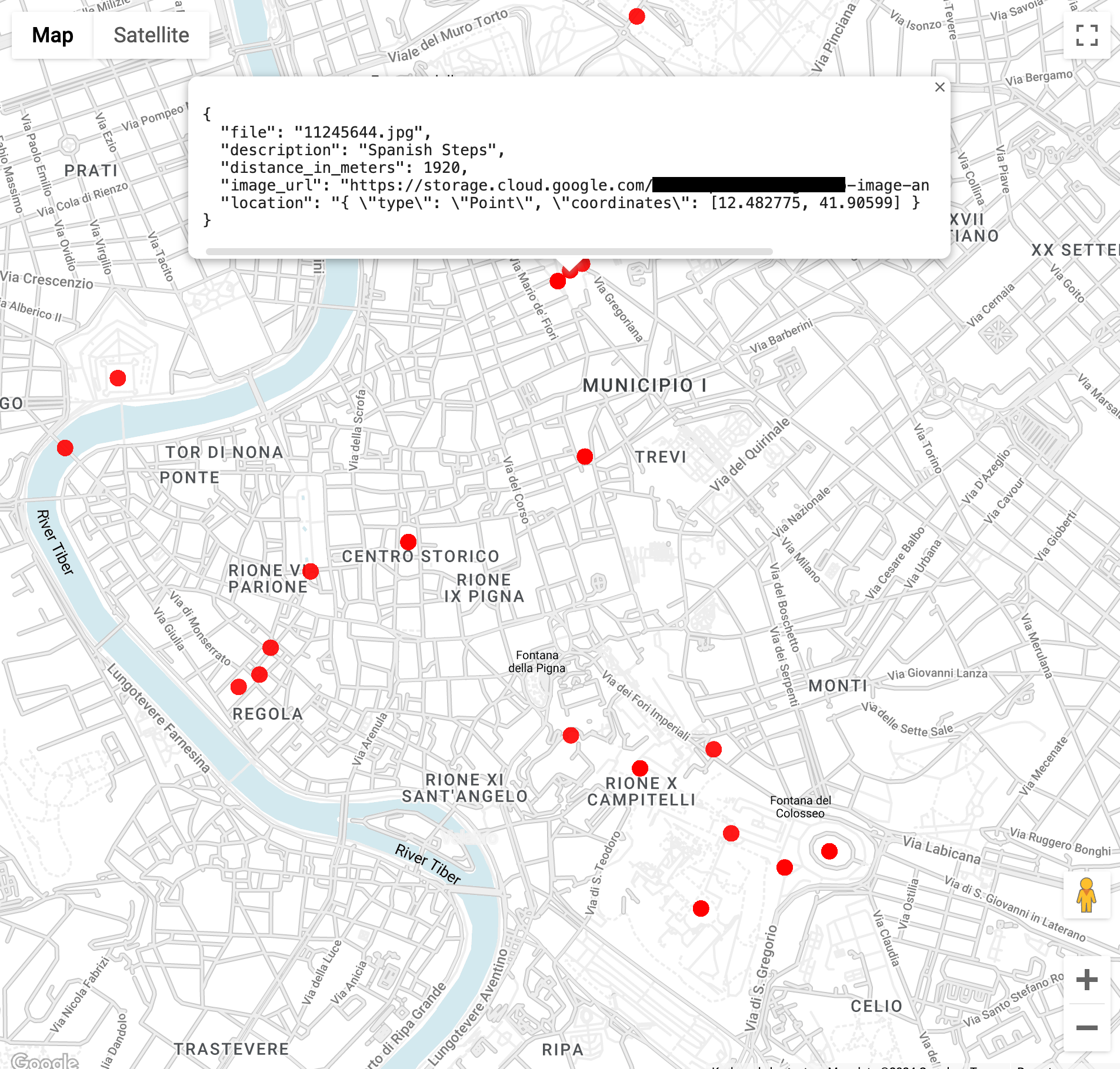
Uma observação sobre os resultados da consulta. Geralmente, as informações de local estão presentes para pontos de referência. A mesma imagem pode conter vários locais do mesmo ponto de referência.
Essa funcionalidade é descrita no tipo AnnotateImageResponse.
Como um local pode indicar o local da cena na imagem, vários elementos LocationInfo podem estar presentes. Outro local pode indicar onde a imagem foi
tirada.
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste guia, exclua o projeto que contém eles ou mantenha o projeto e exclua os recursos individuais.
Excluir o projeto do Google Cloud
A maneira mais fácil de eliminar o faturamento é excluir o projeto do Google Cloud criado para o tutorial.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Se você decidir excluir recursos individualmente, siga as etapas na seção Limpeza do repositório do GitHub.
A seguir
- Para mais arquiteturas de referência, diagramas e práticas recomendadas, confira a Central de arquitetura do Cloud.
Colaboradores
Autores:
- Masud Hasan | Gerente de engenharia de confiabilidade do site
- Sergei Lilichenko, Arquiteto de soluções
- Lakshmanan Sethu | Gerente técnico de contas
Outros colaboradores:
- Jiyeon Kang | Engenheira de clientes
- Sunil Kumar Jang Bahadur | Engenheiro de clientes
Para ver perfis não públicos do LinkedIn, faça login na plataforma.