Neste artigo, descrevemos várias arquiteturas que fornecem alta disponibilidade (HA, na sigla em inglês) para implantações do PostgreSQL no Google Cloud. Alta disponibilidade é a medida da resiliência do sistema em resposta a uma falha de infraestrutura subjacente. Neste documento, alta disponibilidade refere-se à disponibilidade dos clusters do PostgreSQL em uma única região de nuvem ou entre várias regiões, dependendo da arquitetura de alta disponibilidade.
Este documento é destinado a administradores de bancos de dados, arquitetos de nuvem e engenheiros de DevOps, que querem aprender como aumentar a confiabilidade do nível de dados do PostgreSQL melhorando o tempo de atividade geral do sistema. Neste documento, discutimos conceitos relevantes para a execução do PostgreSQL no Compute Engine. O documento não discute o uso do Cloud SQL para PostgreSQL.
Se um sistema ou aplicativo exigir um estado persistente para processar solicitações ou transações, a camada de persistência de dados (o nível de dados) precisará estar disponível para processar solicitações de consultas de dados ou mutações. A inatividade no nível de dados impede que o sistema ou o aplicativo execute as tarefas necessárias.
Dependendo dos objetivos de nível de serviço (SLOs) do sistema, talvez você precise de uma arquitetura que forneça um nível maior de disponibilidade. Há mais de uma maneira de conseguir alta disponibilidade, mas, em geral, você provisiona infraestruturas redundantes que podem ficar rapidamente acessíveis para o aplicativo.
Neste documento, falamos sobre os tópicos a seguir:
- Definição de termos relacionados aos conceitos do banco de dados de alta disponibilidade.
- Opções para topologias do PostgreSQL de alta disponibilidade.
- Informações contextuais para a consideração de cada opção de arquitetura.
Terminologia
Os termos e conceitos a seguir são padrão do setor e são úteis para entender o propósito deste documento.
- replicação
-
O processo pelo qual as transações de gravação (
INSERT,UPDATEouDELETE) e alterações de esquema (Linguagem de definição de dados (DDL, na sigla em inglês)) são capturadas, registradas e aplicadas em série a todos os nós de réplica do banco de dados downstream na arquitetura. - nó principal
- O nó que fornece uma leitura com o estado mais atualizado de dados persistidos. Todas as gravações no banco de dados precisam ser direcionadas para um nó principal.
- nó de réplica (secundário)
- Uma cópia on-line do nó principal do banco de dados. As alterações são replicadas de maneira síncrona ou assíncrona para replicar nós do nó principal. É possível fazer a leitura a partir de nós de réplica, considerando que os dados podem ter um ligeiro atraso devido ao atraso de replicação.
- Atraso de replicação
- Uma medida, no número da sequência do registro (LSN, na sigla em inglês), código da transação ou horário. O atraso de replicação expressa a diferença entre quando as operações de alteração são aplicadas à réplica e quando são aplicadas ao nó principal.
- arquivamento contínuo
- Um backup incremental no qual o banco de dados salva continuamente transações sequenciais em um arquivo.
- registro gravado com antecedência (WAL)
- Um registro prévio de escrita (WAL) é um arquivo de registros que registra alterações em arquivos de dados antes que qualquer alteração seja realmente feita nos arquivos. Em caso de falha no servidor, o WAL é uma maneira padrão de garantir a integridade dos dados e a durabilidade das suas gravações.
- registro WAL
- Um registro de uma transação aplicada ao banco de dados. Um registro WAL é formatado e armazenado como uma série de registros que descrevem mudanças no nível de página do arquivo de dados.
- Número de sequência do registro (LSN, na sigla em inglês)
- As transações criam registros WAL que são anexados ao arquivo WAL. A posição em que a inserção ocorre é chamada de número sequencial do registro (LSN, na sigla em inglês). É um número inteiro de 64 bits, representado como dois números hexadecimais separados por uma barra (XXXXXXXX/YYZZZZZZ). "Z" representa a posição de deslocamento no arquivo WAL.
- segmentar arquivos
- Arquivos que contêm o maior número possível de registros WAL, dependendo do tamanho do arquivo que você configurar. Arquivos de segmento têm nomes de arquivo monotonicamente crescentes e um tamanho de arquivo padrão de 16 MB.
- replicação síncrona
-
Uma forma de replicação em que o servidor principal aguarda a réplica para
confirmar se os dados foram gravados no registro de transações da réplica antes de
confirmar uma confirmação para o cliente. Ao executar a replicação de streaming,
é possível usar a opção
synchronous_commitdo PostgreSQL para configurar as garantias de consistência. - replicação assíncrona
- Uma forma de replicação na qual o servidor principal não aguarda a réplica para confirmar se a transação foi recebida antes de confirmar uma confirmação para o cliente. A replicação assíncrona tem latência mais baixa quando comparada à replicação síncrona. No entanto, se o servidor principal falhar e as transações confirmadas não forem transferidas para a réplica, há uma chance de perda de dados. A replicação assíncrona é o modo padrão de replicação no PostgreSQL, usando envio de registros baseado em arquivos ou replicação de streaming.
- envio de registros baseado em arquivo
- Um método de replicação no PostgreSQL que transfere os arquivos de segmento WAL do servidor de banco de dados principal para a réplica. O servidor principal opera no modo de arquivamento contínuo, enquanto cada serviço em espera opera no modo de recuperação contínuo para ler os arquivos WAL. Essa replicação é assíncrona.
- replicação de streaming
- Um método de replicação em que a réplica se conecta ao principal e recebe continuamente uma sequência contínua de alterações. Como as atualizações chegam por meio de um stream, esse método mantém a réplica mais atualizada com o servidor principal quando comparada à replicação de envio de registros. Embora a replicação seja assíncrona por padrão, é possível configurar a replicação síncrona.
- replicação física de streaming
- Um método de replicação que transporta alterações para a réplica. Esse método usa os registros WAL que contêm as alterações de dados físicos na forma de endereços de bloco de disco e alterações byte por byte.
- replicação lógica de streaming
- Um método de replicação que captura alterações com base na identidade de replicação (chave primária) que permite mais controle sobre como os dados são replicados em comparação com a replicação física. Devido a restrições na replicação lógica do PostgreSQL, a replicação lógica de streaming requer uma configuração especial para uma configuração de alta disponibilidade. Este guia aborda a replicação física padrão e não aborda a replicação lógica.
- tempo de atividade
- A porcentagem de tempo que um recurso está funcionando e é capaz de enviar uma resposta a uma solicitação.
- detecção de falhas
- O processo de identificar que ocorreu uma falha na infraestrutura.
- failover
- O processo em que a infraestrutura de backup ou espera (neste caso, o nó de réplica) é promovida a infraestrutura principal. Durante o failover, o nó da réplica se torna o nó principal.
- alternânca
- O processo de execução de um failover manual em um sistema de produção. Uma alternância testa se o sistema está funcionando bem ou retira o nó principal atual do cluster para manutenção.
- objetivo de tempo de recuperação (RTO, na sigla em inglês)
- A duração decorrida em tempo real para o processo de failover do nível de dados ser concluído. O RTO depende do tempo aceitável a partir de uma perspectiva de negócios.
- objetivo de ponto de recuperação (RPO)
- A quantidade de dados perdidos (em tempo real decorrido) para a camada de dados se manter como resultado do failover. O RPO depende da quantidade de dados perdidos que é aceitável do ponto de vista comercial.
- fallback
- O processo de restabelecimento do antigo nó principal após a condição que causou o failover é resolvido.
- autocorreção
- A capacidade de um sistema resolver problemas sem ações externas de um operador humano.
- partição de rede
- Uma condição quando dois nós em uma arquitetura (por exemplo, os nós principais e de réplica) não podem se comunicar por meio da rede.
- dupla personalidade
- Uma condição que ocorre quando dois nós acreditam simultaneamente que são o nó principal.
- grupo de nós
- Um conjunto de recursos de computação que fornecem um serviço. Neste documento, esse serviço é o nível de permanência de dados.
- nó de quórum ou testemunha
- Um recurso de computação separado que ajuda um grupo de nós a determinar o que fazer quando ocorre uma condição de dupla personalidade.
- eleição do líder ou principal
- O processo pelo qual um grupo de nós cientes uns dos outros, incluindo nós de testemunha, determina qual nó deve ser o nó principal.
Quando considerar uma arquitetura de alta disponibilidade
As arquiteturas de alta disponibilidade aumentaram a proteção contra o tempo de inatividade no nível de dados em comparação com configurações de banco de dados de nó único. Para selecionar a melhor opção para seu caso de uso comercial, você precisa entender a tolerância para o tempo de inatividade e as respectivas compensações das várias arquiteturas.
Use uma arquitetura de alta disponibilidade quando quiser fornecer maior tempo de atividade no nível dos dados para atender aos requisitos de confiabilidade de suas cargas de trabalho e serviços. Se seu ambiente tolera uma certa quantidade de inatividade, uma arquitetura de alta disponibilidade pode gerar custo e complexidade desnecessários. Por exemplo, ambientes de desenvolvimento ou teste raramente precisam de alta disponibilidade de nível de banco de dados.
Avalie os requisitos para alta disponibilidade
Veja abaixo várias perguntas que ajudarão você a decidir qual é a melhor opção de alta disponibilidade do PostgreSQL para sua empresa:
- Qual nível de disponibilidade você espera alcançar? Você precisa de uma opção que permita que o serviço continue funcionando durante apenas uma zona ou falha regional completa? Algumas opções de alta disponibilidade são limitadas a uma região, enquanto outras podem ser multirregionais.
- Quais serviços ou clientes dependem do seu nível de dados e qual é o custo para seu negócio se houver inatividade no nível de persistência de dados? Se um serviço atende apenas a clientes internos que exigem uso ocasional do sistema, ele provavelmente tem requisitos de disponibilidade mais baixos do que um serviço voltado ao cliente final que atende continuamente.
- Qual é seu orçamento operacional? O custo é algo importante a se considerar: para fornecer alta disponibilidade, os custos de infraestrutura e armazenamento provavelmente aumentarão.
- O quão automatizado o processo precisa ser e com que rapidez você precisa fazer o failover? (Qual é seu RTO?) As opções de alta disponibilidade variam pela rapidez com que o sistema pode fazer o failover e estar disponível para os clientes.
- Você pode perder dados por causa do failover? (Qual é seu RPO?) Devido à natureza distribuída das topologias de alta disponibilidade, há uma compensação entre latência da confirmação e risco de perda de dados devido a uma falha.
Como a alta disponibilidade funciona
Nesta seção, descrevemos o streaming e a replicação síncrona de streaming que sustentam as arquiteturas de alta disponibilidade do PostgreSQL.
Replicação de streaming
A replicação de streaming é uma abordagem de replicação em que a réplica se conecta ao principal e recebe continuamente um stream de registros WAL. Em comparação com a replicação de envio de registros, a replicação de streaming permite que a réplica fique mais atualizada com a principal. O PostgreSQL oferece replicação integrada de streaming a partir da versão 9. Muitas soluções de alta disponibilidade do PostgreSQL usam a replicação de streaming integrada para fornecer o mecanismo para que vários nós de réplica do PostgreSQL fiquem sincronizados com o principal. Várias dessas opções são discutidas na seção Arquiteturas de alta disponibilidade do PostgreSQL mais adiante neste documento.
Cada nó de réplica requer recursos de computação e armazenamento dedicados. A infraestrutura do nó de réplica é independente da principal. É possível usar nós de réplica como esperas ativas para atender consultas de cliente somente leitura. Essa abordagem permite o balanceamento de carga de consultas somente leitura na primária e em uma ou mais réplicas.
A replicação de streaming é assíncrona por padrão; a primária não aguarda a confirmação de uma réplica antes de confirmar a confirmação da transação ao cliente. Se uma principal apresentar falha após confirmar a transação, mas antes de uma réplica receber a transação, a replicação assíncrona poderá resultar em perda de dados. Se a réplica for promovida para se tornar uma nova primária, não haverá transação.
Replicação síncrona de streaming
É possível configurar a replicação de streaming como síncrona escolhendo uma ou mais réplicas como uma espera síncrona. Se você configurar sua arquitetura para replicação síncrona, a principal não confirmará uma confirmação de transação até que a réplica reconheça a persistência da transação. A replicação de streaming síncrona oferece maior durabilidade em retorno para uma latência de transação maior.
A opção de configuração synchronous_commit também permite configurar as
seguintes garantias de durabilidade de réplica progressiva para a transação:
on[padrão]: as réplicas de espera síncronas gravam as transações confirmadas na WAL antes de enviarem confirmação para a principal. O uso da configuraçãoongarante que a transação só possa ser perdida se a réplica primária e todas as réplicas em espera síncronas apresentarem falhas simultâneas no armazenamento. Como as réplicas só enviam uma confirmação depois de gravar registros WAL, os clientes que consultam a réplica não vão ver alterações até que os respectivos registros de WAL sejam aplicados ao banco de dados de réplica.remote_write: as réplicas de espera síncronas confirmam o recebimento do registro WAL no nível do SO, mas não garantem que o registro WAL tenha sido gravado no disco. Comoremote_writenão garante que a WAL tenha sido gravada, a transação poderá ser perdida se houver qualquer falha na primária e na secundária antes que os registros sejam gravados.remote_writetem menor durabilidade que a opçãoon.remote_apply: as réplicas de espera síncronas confirmam o recebimento da transação e a aplicação bem-sucedida ao banco de dados antes de confirmar a confirmação da transação ao cliente. O uso da configuraçãoremote_applygarante que a transação seja mantida na réplica e que os resultados da consulta do cliente incluam imediatamente os efeitos da transação.remote_applyaumenta a durabilidade e a consistência em comparação comoneremote_write.
Arquiteturas de alta disponibilidade do PostgreSQL
No nível mais básico, a alta disponibilidade da camada de dados consiste no seguinte:
- Um mecanismo para identificar se uma falha do nó principal ocorre.
- Um processo para realizar um failover em que o nó de réplica é promovido como nó principal.
- Um processo para alterar o roteamento de consultas, de modo que as solicitações de aplicativos cheguem ao novo nó principal.
- Opcionalmente, um método para substituir a arquitetura original usando nós de pré-failover principal e de réplica nas capacidades originais.
As seções a seguir fornecem uma visão geral das seguintes arquiteturas de alta disponibilidade:
- O modelo Patroni
- extensão e serviço pg_auto_failover
- MIGs com estado e disco permanente regional
Essas soluções de alta disponibilidade minimizam o tempo de inatividade se houver uma infraestrutura ou interrupção zonal. Ao escolher entre essas opções, equilibre a latência de confirmação e a durabilidade com base nas necessidades dos negócios.
Um aspecto fundamental de uma arquitetura de alta disponibilidade é o tempo e o esforço manual necessários para preparar um novo ambiente de espera para failover ou substituição subsequente. Caso contrário, o sistema poderá suportar apenas uma falha, e o serviço não terá proteção contra uma violação do SLA. Recomendamos que você selecione uma arquitetura de alta disponibilidade que possa realizar failovers ou trocas manuais com a infraestrutura de produção.
Alta disponibilidade usando o modelo Patroni
O Patroni é um modelo de software de código aberto, maduro e licenciado (administrado por MIT) que fornece as ferramentas para configurar, implantar e operar uma arquitetura de alta disponibilidade do PostgreSQL. O Patroni fornece um estado de cluster compartilhado e uma configuração de arquitetura que é mantida em um armazenamento de configuração distribuída (DCS, na sigla em inglês). As opções para implementar um DCS incluem: etcd, Consul, Apache ZooKeeper ou Kubernetes. O diagrama a seguir mostra os principais componentes de um cluster do Patroni.
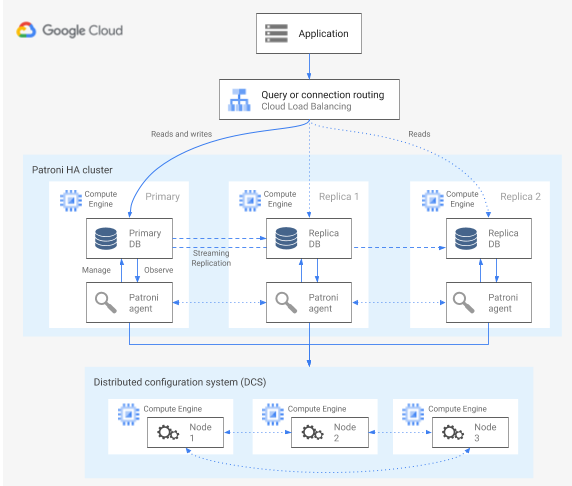
Figura 1. Diagrama dos principais componentes de um cluster do Patroni.
Na figura 1, os balanceadores de carga estão na frente dos nós do PostgreSQL, e os agentes DCS e Patroni operam nos nós do PostgreSQL.
O Patroni executa um processo de agente em cada nó do PostgreSQL. O processo do agente gerencia o processo do PostgreSQL e a configuração do nó de dados. O agente do Patroni coordena com outros nós pelo DCS. O processo do agente do Patroni também expõe uma API REST que você pode consultar para determinar a integridade e a configuração do serviço do PostgreSQL de cada nó.
Para declarar o papel de associação do cluster, o nó principal atualiza regularmente a chave líder no DCS. A chave líder inclui um período de vida útil (TTL, na sigla em inglês). Se o TTL terminar sem uma atualização, a chave líder será removida do DCS e a eleição do líder começará a selecionar um novo principal no pool de candidatos.
O diagrama a seguir mostra um cluster íntegro em que o nó A atualiza o bloqueio líder.
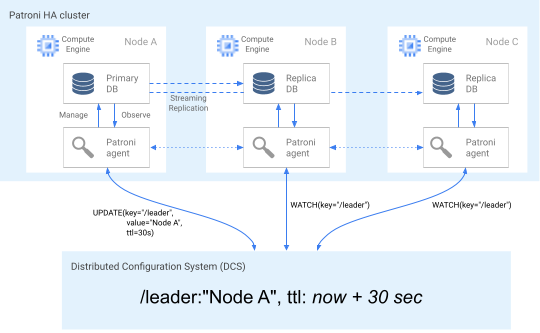
Figura 2. Diagrama de um cluster íntegro.
A Figura 2 mostra um cluster íntegro: o nó B e o nó C enquanto o nó A atualiza a chave líder.
Detecção de falhas
Ao atualizar a chave no DCS, o agente do Patroni continuamente comunica a integridade dele. Ao mesmo tempo, o agente valida a integridade do PostgreSQL. Se o agente detectar um problema, ele se isolará do nó ao se desligar ou rebaixará o nó a uma réplica. Conforme mostrado no diagrama a seguir, se o nó comprometido for o principal, sua chave líder no DCS expira, e uma nova eleição líder ocorre.
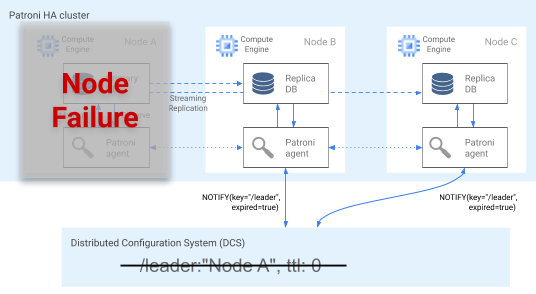
Figura 3. Diagrama de um cluster comprometido.
A Figura 3 mostra um cluster comprometido: um nó principal inativo não atualizou recentemente a chave líder no DCS, e as réplicas não líderes são notificadas de que a chave líder expirou.
Em hosts do Linux, o Patroni também executa um watchdog de nível de SO em nós principais. Esse watchdog escuta mensagens de sinal de atividade do processo do agente do Patroni. Se o processo parar de responder e o sinal de atividade não for enviado, o watchdog reiniciará o host. O watchdog ajuda a evitar uma condição de dupla personalidade em que o nó do PostgreSQL continua a servir como principal, mas a chave líder no DCS expirou devido a uma falha de agente e um principal (líder) foi eleito.
Processo de failover
Se o bloqueio de líder expirar no DCS, os nós de réplica do candidato iniciam uma eleição de líder. Quando uma réplica encontra um bloqueio líder ausente, ela verifica a posição de replicação em comparação com as outras réplicas. Cada réplica usa a API REST para conseguir as posições de registro WAL dos outros nós de réplica, como mostrado no diagrama a seguir.
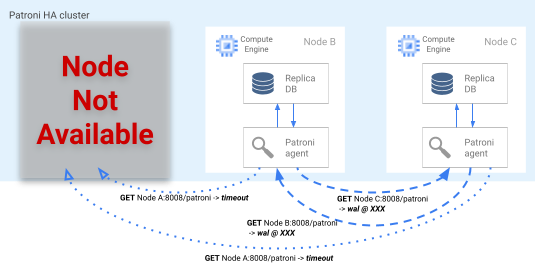
Figura 4 Diagrama do processo de failover do Patroni.
A Figura 4 mostra as consultas de posição de registro WAL e os respectivos resultados dos nós de réplica ativos. O nó A não está disponível e os nós íntegros B e C retornam a mesma posição WAL entre si.
O nó mais atualizado (ou nós, se estiverem na mesma posição) tenta adquirir o bloqueio líder no DCS simultaneamente. No entanto, apenas um nó pode criar a chave líder no DCS. O primeiro nó que criar a chave líder é o vencedor da corrida líder, conforme mostrado no diagrama a seguir.
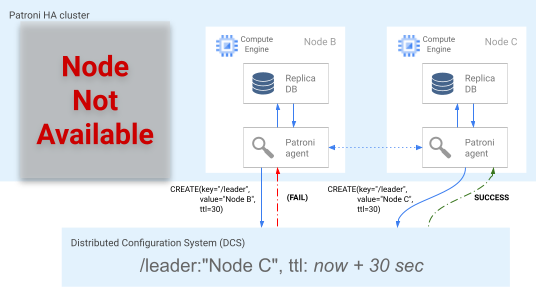
Figura 5. Diagrama da corrida líder.
A Figura 5 mostra uma corrida líder: dois candidatos líderes tentam conseguir o bloqueio líder, mas somente um dos dois nós, o nó C, configura a chave líder corretamente e vence a corrida.
Ao ganhar a eleição de líderes, a réplica se promove como a nova primária. A partir do momento em que a réplica se promove, o novo principal atualiza a chave líder no DCS para manter o bloqueio líder e os outros nós servem como réplicas.
O Patroni também oferece a ferramenta de controle patronictl, que permite executar
alternâncias para testar o processo de failover do Nodal. Essa ferramenta ajuda os operadores a
testar as configurações de alta disponibilidade na produção.
Roteamento de consultas
O processo do agente do Patroni executado em cada nó mostra os endpoints da API REST que revelam o papel atual do nó: principal ou réplica.
| Endpoint REST | Código de retorno HTTP se for principal | Código de retorno HTTP se for réplica |
|---|---|---|
/primary |
200 |
503 |
/replica |
503 |
200 |
Como as verificações de integridade relevantes alteram as próprias respostas caso um nó específico altere o papel, a verificação de integridade do balanceador de carga pode usar esses endpoints para informar o roteamento de tráfego do nó principal e réplica. O projeto Patroni fornece configurações de modelo para o balanceador de carga do proxy de alta disponibilidade. O balanceador de carga de rede de passagem interna pode usar essas mesmas verificações de integridade para fornecer funcionalidade semelhante.
Processo de fallback
Quando há uma falha no nó, o cluster fica em estado degradado. O processo de fallback do Patroni ajuda a restaurar um cluster de alta disponibilidade para um estado íntegro após um failover. O processo de fallback gerencia o retorno do cluster para o estado original inicializando automaticamente o nó afetado como uma réplica do cluster.
Por exemplo, um nó pode ser reiniciado devido a uma falha no sistema operacional ou na infraestrutura subjacente. Se o nó for o principal e demorar mais do que o TTL da chave líder para ser reiniciado, uma eleição de líder será acionada e um novo nó principal será selecionado e promovido. Quando o processo principal de desatualizado é iniciado, ele detecta que não tem o bloqueio líder, rebaixa-se automaticamente para uma réplica e une o cluster nessa capacidade.
Se houver uma falha de nó irrecuperável, como uma falha improvável de zona, você precisará iniciar um novo nó. Um operador de banco de dados pode iniciar manualmente um novo nó ou você pode usar um grupo gerenciado de instâncias regionais (MIG, na sigla em inglês) com estado com uma quantidade mínima de nós para automatizar o processo. Depois que o novo nó é criado, o Patroni detecta que o novo nó faz parte de um cluster atual e inicializa automaticamente o nó como uma réplica.
Alta disponibilidade usando a extensão e o serviço pg_auto_failover
pg_auto_failover é uma extensão do PostgreSQL de código aberto (licença do PostgreSQL) desenvolvida ativamente. pg_auto_failover configura uma arquitetura de alta disponibilidade estendendo os recursos atuais do PostgreSQL. pg_auto_failover não tem dependências além do PostgreSQL.
Para usar a extensão pg_auto_failover com uma arquitetura de alta disponibilidade, você precisa de pelo menos três nós, cada um executando o PostgreSQL com a extensão ativada. Qualquer um dos
nós pode falhar sem afetar o tempo de atividade do grupo de banco de dados. Uma
coleção de nós gerenciados por pg_auto_failover é chamada de forma. O
diagrama a seguir mostra uma arquitetura pg_auto_failover.
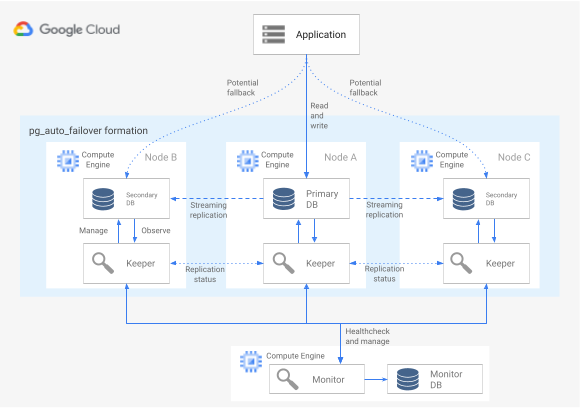
Figura 6. Diagrama de uma arquitetura pg_auto_failover.
A Figura 6 mostra uma arquitetura pg_auto_failover que consiste em dois componentes principais: o serviço de monitoramento e o agente do Keeper. Tanto o Keeper quanto o monitoramento estão na extensão pg_auto_failover.
Monitorar serviço
O serviço de monitoramento do pg_auto_failover é implementado como uma extensão do PostgreSQL. Quando o serviço cria um nó de monitoramento, ele inicia uma instância do PostgreSQL com a extensão pg_auto_failover ativada. O monitoramento mantém o estado global da formação, recebe o status da verificação de integridade dos nós de dados do PostgreSQL membro e orquestra o grupo usando as regras estabelecidas por uma máquina de estado finito (FSM). De acordo com as regras da FSM para transições de estado, o monitoramento comunica instruções aos nós do grupo para ações como promoção, rebaixamento e alterações de configuração.
Agente do Keeper
Em cada nó de dados pg_auto_failover, a extensão inicia um processo do agente do Keeper. Esse processo do Keeper observa e gerencia o serviço PostgreSQL. O Keeper atualiza as atualizações de status para o nó de monitoramento e recebe e executa ações que o monitoramento envia em resposta.
Por padrão, pg_auto_failover configura todos os nós de dados secundários de grupos como
réplicas síncronas. O número de réplicas síncronas necessárias para uma confirmação
é baseado na configuração de number_sync_standby que você definiu no
monitoramento.
Detecção de falhas
Os agentes do Keeper nos nós de dados principais e secundários se conectam periodicamente ao nó de monitoramento para comunicar seu estado atual e verificam se há alguma ação a ser executada. O nó de monitoramento também se conecta aos nós de dados para executar uma verificação de integridade executando as chamadas de API do protocolo PostgreSQL (libpq), imitando o aplicativo cliente do PostgreSQL pg_isready(). Se nenhuma dessas ações for bem-sucedida após um período (30 segundos por padrão), o nó de monitoramento determinará que ocorreu uma falha no nó de dados. É possível alterar as definições de configuração do PostgreSQL para personalizar o tempo do monitoramento e o número de novas tentativas. Para mais informações, consulte Tolerância de failover e falhas.
Se ocorrer uma falha em um único nó, uma das seguintes situações será verdadeira:
- Se o nó de dados não íntegro for um principal, o monitoramento iniciará um failover.
- Se o nó de dados não íntegro for um secundário, o monitoramento desativará a replicação síncrona do nó não íntegro.
- Se o nó com falha for o nó de monitoramento, o failover automático não será possível. Para evitar esse único ponto de falha, garanta que o monitoramento correto e a recuperação de desastres estejam em vigor.
No diagrama a seguir, veja os cenários de falha e os estados de resultado da formação descritos na lista anterior.
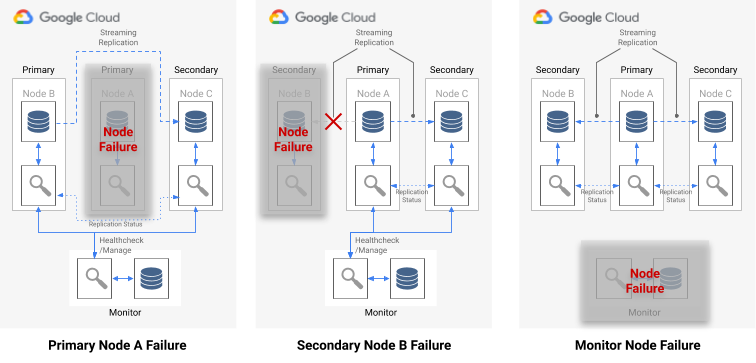
Figura 7. Diagrama dos cenários de falha pg_auto_failover.
Processo de failover
Cada nó do banco de dados no grupo tem as seguintes opções de configuração que determinam o processo de failover:
replication_quorum: uma opção booleana. Sereplication_quorumfor definido comotrue, o nó será considerado como possível candidato de failovercandidate_priority: um valor inteiro de 0 a 100.candidate_prioritytem um valor padrão de 50 que pode ser alterado para afetar a prioridade do failover. Os nós são priorizados como possíveis candidatos para failover com base no valor decandidate_priority. Os nós que têm um valorcandidate_prioritymaior têm prioridade mais alta. O processo de failover requer que pelo menos dois nós tenham prioridade de candidato diferente de zero em qualquer formação pg_auto_failover.
Se houver uma falha no nó principal, os nós secundários serão considerados
para promoção para principal se tiverem replicação síncrona ativa e se forem
membros do replication_quorum.
Os nós secundários são considerados para promoção de acordo com os seguintes critérios progressivos:
- Nós com a maior prioridade do candidato
- Em espera com a posição de registro WAL mais avançada publicada no monitoramento
- Seleção aleatória como uma pausa de empate final
Um candidato a failover é um candidato secundário quando não publica a posição LSN mais avançada no WAL. Nesse cenário, o pg_auto_failover orquestra uma etapa intermediária no mecanismo de failover: o candidato secundário busca os bytes WAL ausentes de um nó em espera que tem a posição LSN mais avançada. O nó de espera é então promovido. O Postgres permite essa operação porque a replicação em cascata permite que qualquer processo em espera atue como o nó upstream de outra instância de espera.
Roteamento de consultas
O pg_auto_failure não oferece recursos de encaminhamento de consultas do lado do servidor.
Em vez disso, o pg_auto_failure depende do encaminhament de consultas do lado do cliente que usa o
driver oficial do cliente PostgreSQL
libpq.
Quando você define o URI de conexão, o driver pode aceitar vários hosts na
palavra-chave host.
A biblioteca de cliente usada pelo aplicativo precisa encapsular a libpq ou implementar a capacidade de fornecer vários hosts para a arquitetura oferecer suporte a um failover totalmente automatizado.
Processos de fallback e alternância
Quando o processo do Keeper reinicia um nó com falha ou inicia um novo nó de substituição, o processo verifica o nó de monitoramento para determinar a próxima ação a ser executada. Se um nó com falha reiniciado anteriormente era o principal e o monitoramento já tiver escolhido um novo principal de acordo com o processo de failover, o Keeper irá reiniciar o principal desatualizado como réplica secundária.
pg_auto_failure fornece a ferramenta pg_autoctl, que permite executar alternâncias
para testar o processo de failover do nó. Além de permitir que os operadores testem as configurações de
alta disponibilidade em produção, a ferramenta ajuda a restaurar o cluster de alta disponibilidade para que volte a um estado
íntegro após um failover.
Alta disponibilidade usando MIGs com estado e disco permanente regional
Nesta seção, descrevemos uma abordagem de alta disponibilidade que usa os seguintes componentes do Google Cloud:
- Disco permanente regional Quando você usa discos permanentes regionais, os dados são replicados de forma síncrona entre duas zonas em uma região. Assim, não é necessário usar a replicação de streaming. No entanto, a alta disponibilidade é limitada a exatamente duas zonas em uma região.
- Grupos gerenciados de instâncias com estado Um par de MIGs com estado é usado como parte de um plano de controle para manter um nó principal do PostgreSQL em execução. Quando o MIG com estado inicia uma nova instância, ele pode anexar o disco permanente regional atual. Em um momento específico, apenas um dos dois MIGs terá uma instância em execução.
- Cloud Storage. Um objeto em um bucket do Cloud Storage contém uma configuração que indica qual dos dois MIGs está executando o nó do banco de dados primário e onde um MIG deve ser criado uma instância de failover.
- Verificações de integridade e recuperação automática do MIG. A verificação de integridade monitora a integridade da instância. Se o nó em execução se tornar não íntegro, a verificação de integridade iniciará o processo de recuperação automática.
- Geração de registros. Quando a recuperação automática interrompe o nó principal, uma entrada é registrada no Logging. As entradas de registro pertinentes são exportadas para um tópico de coletor do Pub/Sub usando um filtro.
- Funções do Cloud Run orientadas a eventos. A mensagem do Pub/Sub aciona as funções do Cloud Run. As funções do Cloud Run usam a configuração do Cloud Storage para determinar quais ações precisam ser realizadas para cada MIG com estado.
- Balanceador de carga de rede de passagem interna. O balanceador de carga fornece roteamento para a instância em execução no grupo. Isso garante que uma alteração do endereço IP da instância causada pela recriação da instância seja abstraída do cliente.
O diagrama a seguir mostra um exemplo de alta disponibilidade usando MIGs com estado e discos permanentes regionais:

Figura 8. Diagrama de uma alta disponibilidade que usa MIGs com estado e discos permanentes regionais.
A figura 8 mostra um nó principal íntegro que atende o tráfego do cliente. Os clientes se conectam ao endereço IP estático do balanceador de carga de rede interno. O balanceador de carga encaminha as solicitações de clientes para a VM que está sendo executada como parte do MIG. Os volumes de dados são armazenados em discos permanentes regionais montados.
Para implementar essa abordagem, crie uma imagem de VM com o PostgreSQL que inicia na inicialização para ser usada como o modelo de instância do MIG. Também é necessário configurar uma verificação de integridade baseada em HTTP, como pgDoctor, no nó. Uma verificação de integridade baseada em HTTP ajuda a garantir que o balanceador de carga e o grupo de instâncias possam determinar a integridade do nó do PostgreSQL.
Disco permanente regional
Para provisionar um dispositivo de armazenamento em blocos que oferece replicação síncrona de dados entre duas zonas em uma região, use a opção de armazenamento do disco permanente regional do Compute Engine. Um disco permanente regional pode fornecer um elemento básico fundamental para implementar uma opção de alta disponibilidade do PostgreSQL que não dependa da replicação de streaming integrada do PostgreSQL.
Se a instância de VM do nó principal ficar indisponível devido a uma falha de infraestrutura ou interrupção de zona, force a anexação do disco permanente regional a uma instância de VM na zona de backup da mesma região.
Para anexar o disco permanente regional a uma instância de VM na sua zona de backup, realize uma das seguintes ações:
- Mantenha uma instância de VM de espera passiva na zona de backup. Uma instância de VM em espera passiva é uma instância de VM interrompida que não tem um disco permanente regional ativado, mas é uma instância de VM idêntica à instância de VM do nó principal. Se houver uma falha, a VM de espera passiva será iniciada e o disco permanente regional será ativado. A instância de espera passiva e a instância do nó principal têm os mesmos dados.
- Crie um par de MIGs com estado usando o mesmo modelo de instância. Os MIGs fornecem verificações de integridade e servem como parte do plano de controle. Se o nó principal falhar, uma instância de failover será criada no MIG de destino de maneira declarativa. O MIG de destino é definido no objeto do Cloud Storage. Uma configuração por instância é usada para anexar o disco permanente regional.
Se a interrupção do serviço de dados for imediatamente identificada, a operação de anexação forçada normalmente será concluída em menos de um minuto. Portanto, uma RTO medida em minutos é inatingível.
Se sua empresa puder tolerar o tempo de inatividade adicional necessário para você detectar e comunicar uma interrupção e para realizar o failover manualmente, não será preciso automatizar o processo de anexação forçada. Se a tolerância de RTO for menor, será possível automatizar o processo de detecção e failover. Como alternativa, o Cloud SQL para PostgreSQL também oferece uma implementação totalmente gerenciada dessa abordagem de alta disponibilidade.
Detecção de falhas e processo de failover
A abordagem de alta disponibilidade usa os recursos de recuperação automática de grupos de instâncias para monitorar a integridade do nó usando uma verificação de integridade. Se houver uma falha na verificação de integridade, a instância atual será considerada não íntegra e a instância será interrompida. Essa parada inicia o processo de failover usando o Logging, o Pub/Sub e a função das funções do Cloud Run acionada.
Para atender ao requisito de que essa VM sempre tenha o disco regional ativado, um dos dois MIGs será configurado pelas funções do Cloud Run para criar uma instância em uma das duas zonas em que o disco permanente regional está disponível. Em caso de falha no nó, a instância de substituição é iniciada, de acordo com o estado mantido no Cloud Storage, na zona alternativa.

Figura 9. Diagrama de uma falha zonal em um MIG.
Na figura 9, o antigo nó principal na Zona A teve uma falha e as funções do Cloud Run configuraram o MIG B para iniciar uma nova instância principal na Zona B. O mecanismo de detecção de falhas é configurado automaticamente para monitorar a integridade do novo nó principal.
Roteamento de consultas
O balanceador de carga de rede de passagem interna encaminha os clientes para a instância que está executando o serviço PostgreSQL. O balanceador de carga usa a mesma verificação de integridade que o grupo de instâncias para determinar se a instância está disponível para exibir consultas. Se o nó estiver indisponível porque está sendo recriado, as conexões falharão. Após o backup da instância, as verificações de integridade começam a ser transmitidas e as novas conexões são roteadas para o nó disponível. Não há nós somente leitura nesta configuração, porque há apenas um nó em execução.
Processo de fallback
Se o nó do banco de dados estiver falhando em uma verificação de integridade devido a um problema de hardware subjacente, o nó será recriado em uma instância subjacente diferente. Nesse momento, a arquitetura retorna ao estado original sem nenhuma etapa adicional. No entanto, se houver uma falha zonal, a configuração continuará sendo executada em estado degradado até a primeira zona se recuperar. Embora seja pouco provável, se houver falhas simultâneas em ambas as zonas configuradas para a replicação de Persistent Disk regional e MIG com estado, a instância do PostgreSQL não poderá se recuperar. O banco de dados não fica disponível para atender às solicitações durante a interrupção.
Comparação entre as opções de alta disponibilidade
Nas tabelas a seguir, veja uma comparação entre as opções de alta disponibilidade disponíveis no Patroni, pg_auto_failover e nos MIGS com estado com discos permanentes regionais.
Configuração e arquitetura
| Patroni | pg_auto_failover | MIGs com estado com discos permanentes regionais |
|---|---|---|
|
Requer uma arquitetura de alta disponibilidade, uma configuração de DCS, além de monitoramento e alerta. A configuração do agente em nós de dados é relativamente simples. |
Não requer dependências externas, exceto o PostgreSQL. Requer um nó dedicado como monitoramento. O nó de monitoramento exige alta disponibilidade e recuperação de desastres para garantir que não haja um ponto único de falha (SPOF, na sigla em inglês). | Arquitetura que consiste exclusivamente em serviços do Google Cloud. Você executa apenas um nó de banco de dados ativo por vez. |
Configurabilidade de alta disponibilidade
| Patroni | pg_auto_failover | MIGs com estado com discos permanentes regionais |
|---|---|---|
| Extremamente configurável: compatível com replicação síncrona e assíncrona e permite especificar quais nós precisam ser síncronos e assíncronos. Inclui o gerenciamento automático dos nós síncronos. Permite configurações de alta disponibilidade com várias zonas e regiões. O DCS precisa ser acessível. | Semelhante ao Patroni: muito configurável. No entanto, como o monitoramento está disponível apenas como uma única instância, qualquer tipo de configuração precisa considerar o acesso a esse nó. | Limitado a duas zonas em uma única região com replicação síncrona. |
Capacidade de lidar com a partição de rede
| Patroni | pg_auto_failover | MIGs com estado com discos permanentes regionais |
|---|---|---|
| O autoisolamento junto com um monitor no nível do SO oferece proteção contra a dupla personalidade. Qualquer falha na conexão com o DCS resulta no rebaixamento principal para uma réplica e aciona um failover para garantir a durabilidade em relação à disponibilidade. | Usa uma combinação de verificações de integridade do principal para o monitoramento e para a réplica para detectar uma partição de rede e se rebaixa, se necessário. | Não aplicável: há apenas um nó do PostgreSQL ativo por vez. Portanto, não há uma partição de rede. |
Configuração do cliente
| Patroni | pg_auto_failover | MIGs com estado com discos permanentes regionais |
|---|---|---|
| Transparente ao cliente porque ele se conecta a um balanceador de carga. | Requer uma biblioteca de cliente compatível com a definição de vários hosts na configuração, porque ele não é facilmente equipado com um balanceador de carga. | Transparente ao cliente porque ele se conecta a um balanceador de carga. |
Automação de inicialização de nós do PostgreSQL, gerenciamento de configuração
| Patroni | pg_auto_failover | MIGs com estado com discos permanentes regionais |
|---|---|---|
Fornece ferramentas para gerenciar a configuração do PostgreSQL (patronictl
edit-config) e inicializa automaticamente novos nós ou nós
reiniciados no cluster. É possível inicializar nós usando
pg_basebackup ou outras ferramentas, como WALL-E e barman.
|
Inicializa nós automaticamente, mas apenas limitado a usar
pg_basebackup ao inicializar um novo nó de réplica.
O gerenciamento de configurações é limitado a configurações relacionadas a
pg_auto_failover.
|
O grupo de instâncias com estado com disco compartilhado elimina a necessidade de qualquer inicialização de nó do PostgreSQL. Como há apenas um nó em execução, o gerenciamento de configuração está em um único nó. |
Personalização e riqueza de recursos
| Patroni | pg_auto_failover | MIGs com estado com discos permanentes regionais |
|---|---|---|
|
Fornece uma interface de gancho para permitir que ações do usuário possam ser chamadas nas etapas principais, como no rebaixamento ou na promoção. Configurabilidade rica em recursos, como suporte para diferentes tipos de DCS, meios diferentes de inicializar réplicas e maneiras diferentes de fornecer a configuração do PostgreSQL. Permite configurar clusters em espera que permitam que os clusters de réplica em cascata facilitem a migração entre os clusters. |
Limitado porque é um projeto relativamente novo. | Não relevante. |
Maturidade
| Patroni | pg_auto_failover | MIGs com estado com discos permanentes regionais |
|---|---|---|
| O projeto é disponibilizado desde 2015 e é usado na produção por grandes empresas como Zalano e GitLab. | Um projeto relativamente novo anunciado no início de 2019. | Composta inteiramente por produtos do Google Cloud com disponibilidade geral. |
A seguir
- Leia sobre a configuração de alta disponibilidade do Cloud SQL.
- Saiba mais sobre as opções de alta disponibilidade usando discos permanentes regionais.
- Leia sobre o Patroni.
- Leia sobre pg_auto_failover.
- Confira arquiteturas de referência, diagramas e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.