Ce document explique aux chercheurs, aux data scientists et aux analystes métier les processus et considérations à prendre en compte concernant l'analyse des données FHIR (Fast Healthcare Interoperability Resources) dans BigQuery.
Ce document se concentre en particulier sur les données de ressources patient exportées depuis le magasin FHIR dans l'API Cloud Healthcare. Il décrit également une série de requêtes illustrant le fonctionnement des données de schéma FHIR dans un format relationnel, et vous montre comment accéder à ces requêtes pour les réutiliser via des vues.
Utiliser BigQuery pour analyser des données FHIR
L'API spécifique à FHIR de l'API Cloud Healthcare est conçue pour permettre une interaction transactionnelle en temps réel avec des données FHIR au niveau d'une seule ressource FHIR ou d'une collection de ressources FHIR. Toutefois, l'API FHIR n'est pas conçue pour les cas d'utilisation analytiques. Pour ces cas d'utilisation, nous vous recommandons d'exporter vos données de l'API FHIR vers BigQuery. BigQuery est un entrepôt de données évolutif sans serveur qui vous permet d'analyser de grandes quantités de données de manière rétrospective ou prospective.
En outre, BigQuery est conforme à la norme ANSI SQL:2011, ce qui rend les données accessibles aux data scientists et aux analystes métier via des outils qu'ils utilisent généralement, tels que Tableau, Looker ou Vertex AI Workbench.
Dans certaines applications, telles que Vertex AI Workbench, vous avez accès à des clients intégrés, comme la Bibliothèque cliente Python pour BigQuery. Dans ces cas, les données renvoyées à l'application sont disponibles via des structures de données de langage intégrées.
Accéder à BigQuery
Vous pouvez accéder à BigQuery via l'interface utilisateur Web de BigQuery dans la console Google Cloud, ainsi qu'avec les outils suivants :
- L'outil de ligne de commande BigQuery
- L'API REST ou les bibliothèques clientes BigQuery
- Pilotes ODBC et JDBC
Grâce à ces outils, vous pouvez intégrer BigQuery à presque toutes les applications.
Travailler avec la structure de données FHIR
La structure de données standard FHIR intégrée est complexe, avec des types de données FHIR imbriqués et intégrés dans toute ressource FHIR. Ces types de données FHIR intégrables sont appelés types de données complexes.
Les tableaux et les structures sont également appelés types de données complexes dans les bases de données relationnelles. La structure de données standard FHIR intégrée fonctionne bien lorsqu'elle sérialisée en fichiers XML ou JSON dans un système orienté documents, mais elle peut être difficile à utiliser lorsqu'elle est traduite en bases de données relationnelles.
La capture d'écran suivante montre une vue partielle d'un type de données FHIR patient resource, illustrant la nature complexe de la structure de données standard FHIR intégrée.
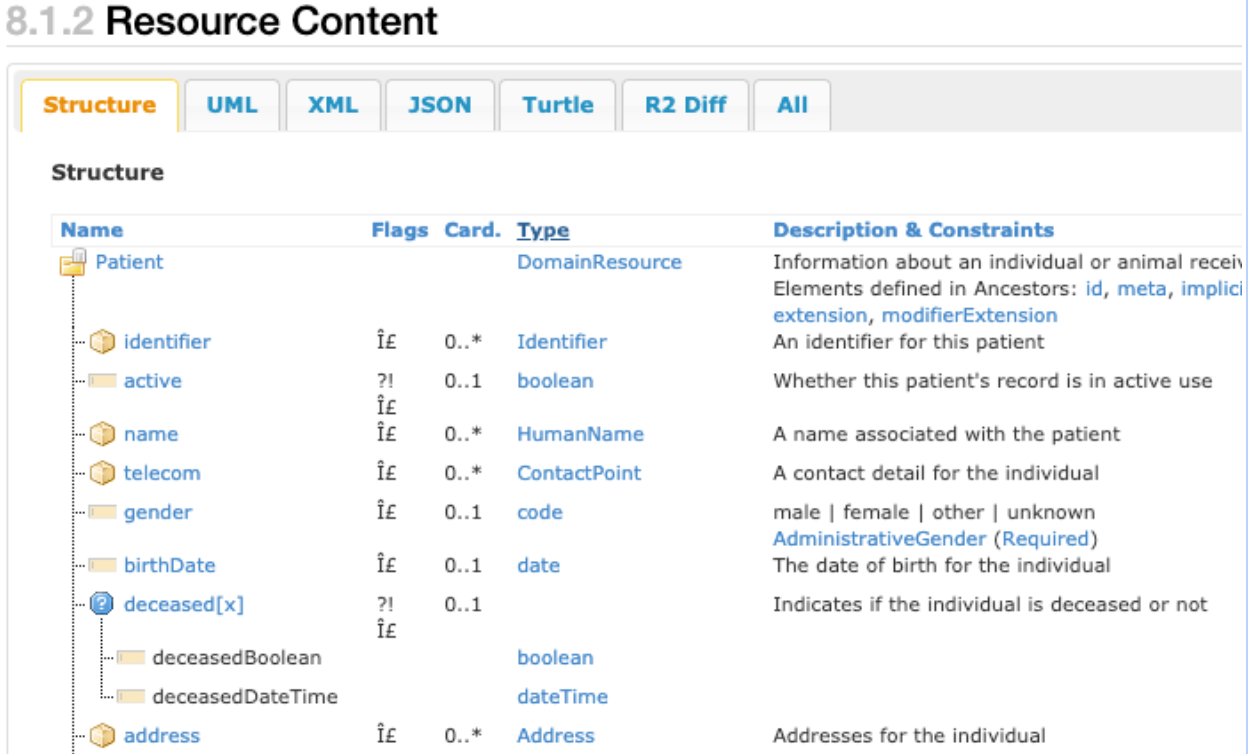
La capture d'écran précédente montre les composants principaux d'un type de données FHIR patient
resource. Par exemple, la colonne cardinalité (nommée Card. dans le tableau) présente plusieurs éléments pouvant avoir zéro, une ou plusieurs entrées. La colonne Type indique les types d'entrées Identifier, HumanName et Address, qui sont des exemples de types de données complexes comprenant le type de données patient
resource. Chacune de ces lignes peut être enregistrée plusieurs fois, sous la forme d'un tableau de structures.
Utiliser des tableaux et des structures
BigQuery accepte les tableaux et les types de données STRUCT (des structures de données imbriquées et répétées), car ils sont représentés dans les ressources FHIR, ce qui rend possible la conversion des données de FHIR vers BigQuery.
Dans BigQuery, un tableau est une liste ordonnée composée de zéro, une ou plusieurs valeurs du même type de données. Vous pouvez construire des tableaux de types de données simples, tels que INT64, et de types de données complexes, tels que STRUCT. La seule exception est le type de données ARRAY, car les tableaux de tableaux ne sont actuellement pas compatibles. Dans BigQuery, un tableau de structures apparaît sous la forme d'un enregistrement reproductible.
Vous pouvez spécifier des données imbriquées, ou des données imbriquées et répétées, dans l'interface utilisateur de BigQuery ou dans un fichier de schéma JSON. Pour spécifier des colonnes imbriquées ou des colonnes imbriquées et répétées, utilisez le type de données RECORD (STRUCT).
L'API Cloud Healthcare est compatible avec le schéma SQL sur FHIR dans BigQuery. Ce schéma d'analyse est le schéma par défaut de la méthode ExportResources() et la compatibilité est assurée par la communauté FHIR.
BigQuery accepte les données dénormalisées. Cela signifie que lorsque vous stockez vos données, plutôt que de créer un schéma relationnel en étoile ou en flocon, vous pouvez dénormaliser vos données et utiliser des colonnes imbriquées et répétées. Les colonnes imbriquées et répétées permettent de maintenir les relations entre les éléments de données et d'éviter l'altération des performances inhérente à un schéma relationnel (normalisé).
Accéder à vos données via l'opérateur UNNEST
Chaque ressource FHIR de l'API FHIR est exportée dans BigQuery sous forme d'une ligne de données. Vous pouvez considérer un tableau ou une structure dans une ligne comme une table intégrée. Vous pouvez accéder aux données de cette "table" soit dans la clause SELECT, soit dans la clause WHERE de votre requête en aplatissant le tableau ou la structure à l'aide de l'opérateur UNNEST.
L'opérateur UNNEST prend un tableau et renvoie une table avec une seule ligne pour chaque élément du tableau. Pour en savoir plus, consultez la section Utiliser des tableaux en langage SQL standard.
L'opération UNNEST ne conserve pas l'ordre des éléments du tableau, mais vous pouvez réorganiser la table à l'aide de la clause facultative WITH OFFSET. Cela renvoie une colonne supplémentaire avec la clause OFFSET pour chaque élément du tableau.
Vous pouvez ensuite utiliser la clause ORDER BY pour classer les lignes en fonction de leur décalage.
Lorsque vous joignez des données non imbriquées, BigQuery utilise une opération CROSS JOIN corrélée qui référence la colonne de tableaux de chaque élément du tableau à la table source, qui précède directement l'appel à UNNEST dans la clause FROM. Pour chaque ligne de la table source, l'opération UNNEST aplatit le tableau de cette ligne en un ensemble de lignes contenant les éléments du tableau. L'opération CROSS JOIN corrélée joint ce nouvel ensemble de lignes à la ligne unique de la table source.
Examiner le schéma à l'aide de requêtes
Pour interroger des données FHIR dans BigQuery, il est important de comprendre le schéma créé via le processus d'exportation. BigQuery vous permet d'inspecter la structure des colonnes de chaque table dans l'ensemble de données via la fonctionnalité INFORMATION_SCHEMA, une série de vues affichant des métadonnées. La suite de ce document fait référence au schéma SQL sur FHIR, conçu pour permettre la récupération des données.
L'exemple de requête suivant explore les détails des colonnes de la table patient dans le schéma SQL sur FHIR. La requête référence l'ensemble de données public de données synthétiques générées Synthea dans FHIR, qui héberge plus d'un million d'enregistrements Patient synthétiques générés aux formats Synthea et FHIR.
Lorsque vous lancez une requête sur la vue INFORMATION_SCHEMA.COLUMNS, les résultats de la requête contiennent une ligne pour chaque colonne (champ) d'une table. La requête suivante renvoie toutes les colonnes de la table patient :
SELECT * FROM `bigquery-public-data.fhir_synthea.INFORMATION_SCHEMA.COLUMNS` WHERE table_name='patient'
La capture d'écran du résultat de la requête suivante montre le type de données identifier, et le tableau du type de données contenant les types de données STRUCT.

Utiliser la ressource patient FHIR dans BigQuery
Le numéro de dossier médical du patient (MRN, Medical Record Number), une information essentielle stockée dans vos données FHIR, est utilisé dans tous les systèmes de données cliniques et opérationnels de l'organisation pour tous les patients. Toute méthode d'accès aux données d'un patient individuel ou d'un groupe de patients doit filtrer ou renvoyer le MRN, ou les deux.
L'exemple de requête suivant renvoie l'identifiant de serveur FHIR interne à la ressource patient elle-même, y compris le MRN et la date de naissance de tous les patients. Le filtre pour interroger sur un MRN spécifique est également inclus, mais est commenté dans cet exemple.
Dans cette requête, vous annulez l'imbrication du type de données complexe identifier deux fois. Vous utilisez également des opérations CROSS JOIN corrélées pour joindre des données non imbriquées à sa table source.
La table bigquery-public-data.fhir_synthea.patient de la requête a été créée à l'aide de la version de schéma SQL sur FHIR de l'exportation FHIR vers BigQuery.
SELECT id, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b"
Le résultat ressemble à ce qui suit :
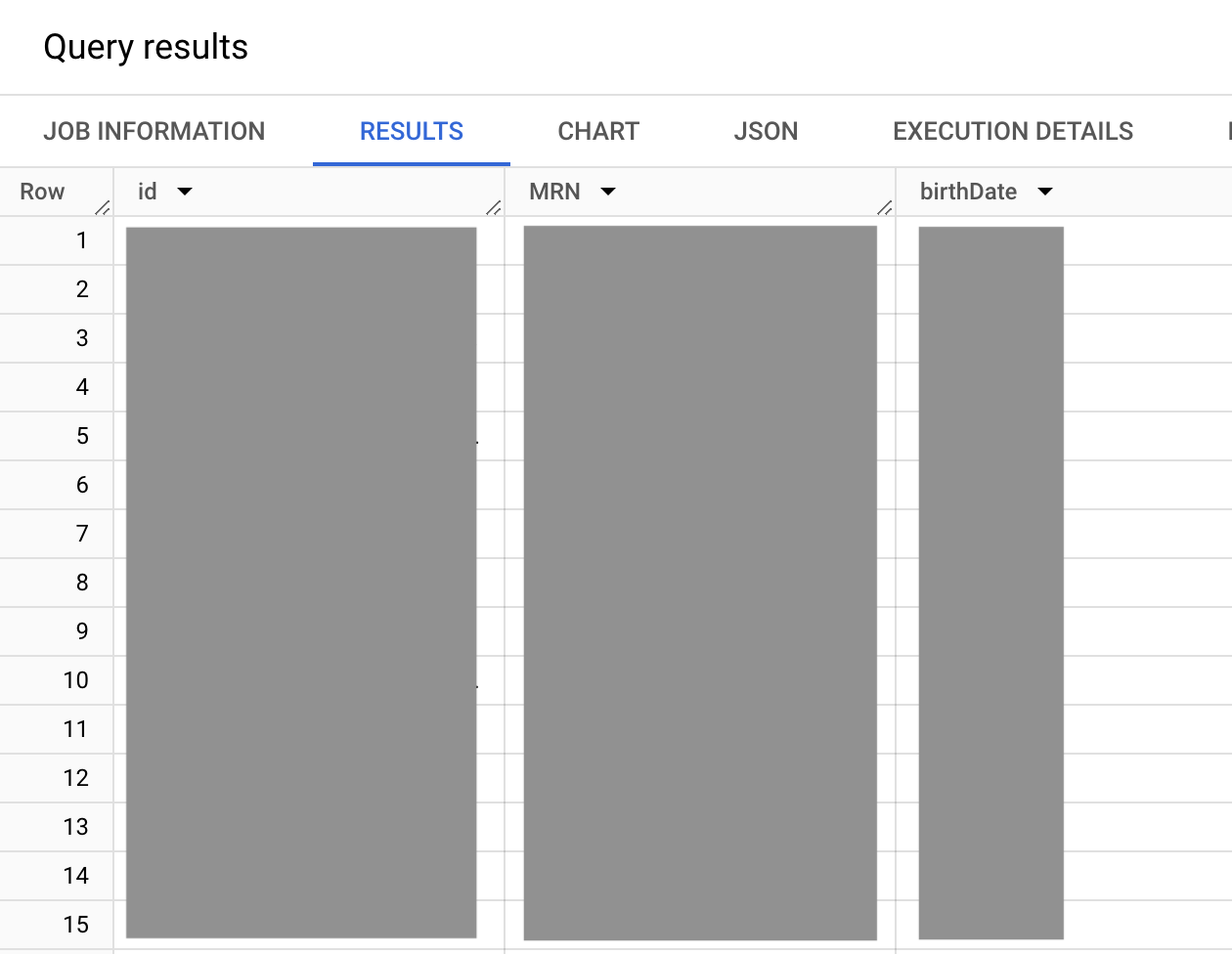
Dans la requête précédente, l'ensemble de valeurs identifier.type.coding.code correspond à l'ensemble de valeurs FHIR identifier qui énumère les types de données d'identité disponibles, tels que le MRN (type de données d'identité MR), le permis de conduire (type de données d'identité DL) et le numéro de passeport (type de données d'identité PPN). Étant donné que l'ensemble de valeurs identifier.type.coding est un tableau, un nombre quelconque d'identifiants peuvent être répertoriés pour un patient. Mais dans ce cas, vous voulez le MRN (type de données d'identité MR).
Associer la table patient à d'autres tables
En créant la requête de table patient, vous pouvez joindre la table patient à d'autres tables de cet ensemble de données, telles que la table des conditions. La table des conditions est l'endroit où sont enregistrés les diagnostics des patients.
L'exemple de requête suivant récupère toutes les entrées liées aux pathologies qui concernent l'hypertension.
SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003'
Le résultat ressemble à ce qui suit :
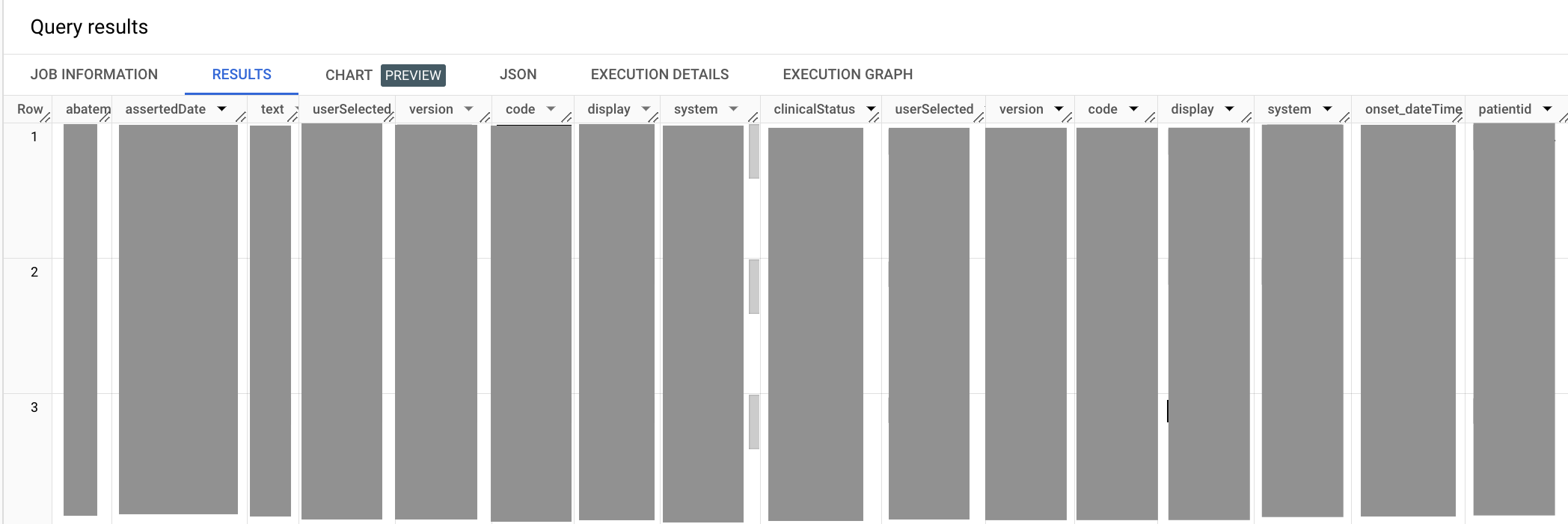
Dans la requête précédente, vous réutilisez la méthode UNNEST pour aplatir le champ code.coding. Les éléments de code abatement.dateTime et onset.dateTime de l'instruction SELECT sont des alias, car ils se terminent tous deux par dateTime, ce qui entraînerait des noms de colonne ambigus dans le résultat d'une instruction SELECT. Lorsque vous sélectionnez le code Hypertension, vous devez également déclarer le système de terminologie dont il provient (dans ce cas, le système de terminologie SNOMED CT).
Enfin, vous utilisez la clé subject.patientid pour joindre la table des conditions à la table des patients. Cette clé pointe vers l'identifiant de la ressource patient elle-même dans le serveur FHIR.
Rassembler les requêtes
Dans l'exemple de requête suivant, vous utilisez les requêtes des deux sections précédentes et les associez à l'aide de la clause WITH, tout en effectuant des calculs simples.
WITH patient AS ( SELECT id as patientid, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b" ), condition AS ( SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003' ) SELECT patient.patientid, patient.MRN, patient.birthDate as birthDate_string, #current patient age. now - birthdate CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH)/12 AS INT) as patient_current_age_years, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH) AS INT) as patient_current_age_months, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),DAY) AS INT) as patient_current_age_days, #age at onset. onset date - birthdate DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset, condition.onset_dateTime, condition.code.code, condition.code.display, condition.code.system FROM patient JOIN condition ON patient.patientid = condition.patientid
Le résultat ressemble à ce qui suit :
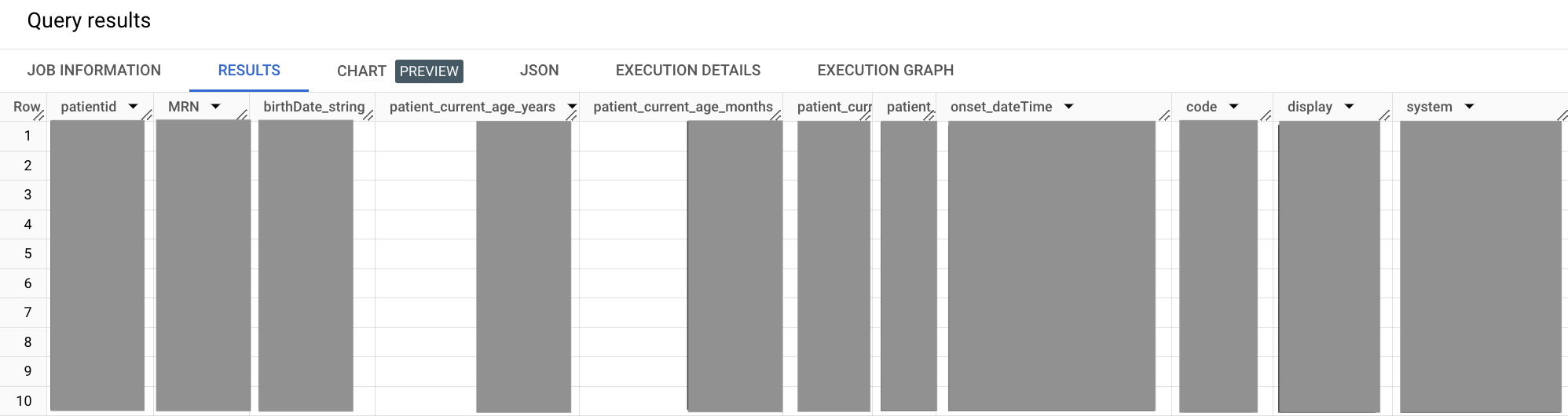
Dans l'exemple de requête précédent, la clause WITH vous permet d'isoler des sous-requêtes dans leurs propres segments définis. Cette approche peut améliorer la lisibilité, ce qui devient plus important à mesure que votre requête s'agrandit. Dans cette requête, vous isolez la sous-requête pour les patients et les conditions dans leurs propres segments WITH, puis les joignez dans le segment SELECT principal.
Vous pouvez également appliquer des calculs aux données brutes. L'exemple de code suivant, une instruction SELECT, montre comment calculer l'âge du patient à l'apparition de la maladie.
DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset
Comme indiqué dans l'exemple de code précédent, vous pouvez effectuer un certain nombre d'opérations sur la chaîne dateTime fournie, condition.onset_dateTime. Commencez par sélectionner le composant de date de la chaîne avec la valeur SUBSTR. Vous convertissez ensuite la chaîne en un type de données DATE à l'aide de la syntaxe CAST. Vous pouvez également convertir le champ patient.birthDate en champ DATE.
Enfin, vous calculez la différence entre les deux dates à l'aide de la fonction DATE_DIFF.
Étape suivante
- Analyser des données cliniques à l'aide de BigQuery et d'AI Platform Notebooks.
- Visualiser des données BigQuery dans un notebook Jupyter.
- Sécurité de l'API Cloud Healthcare
- Contrôle des accès dans BigQuery
- Consultez la page Solutions pour le secteur médical et les sciences de la vie disponibles sur Google Cloud Marketplace.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.