多くのお客様にとって、 Google Cloudプロダクト導入の最初のステップは、 Google Cloudにデータを取り込むことです。このドキュメントでは、データ移転の計画から、計画の実装におけるベスト プラクティスの使用まで、データ取り込みのプロセスについて説明します。
大規模なデータセットを転送するには、適切なチームを構築し、早期に計画を立て、本番環境に実装する前に転送計画をテストする必要があります。これらの手順は移行そのものと同じくらいの時間がかかることもありますが、移行中の業務の中断を最小限に抑えることができます。
このドキュメントは、Google Cloudへの移行に関する次の複数のパートからなるシリーズの一部です。
- Migrate to Google Cloud: スタートガイド
- Google Cloudへの移行: ワークロードの評価と検出
- Migrate to Google Cloud: 基盤の計画と構築
- Google Cloudに移行する: 大規模なデータセットを転送する(このドキュメント)
- Migrate to Google Cloud: ワークロードをデプロイする
- Google Cloudへの移行: 手動デプロイから自動かつコンテナ化されたデプロイに移行する
- Migrate to Google Cloud: 環境を最適化する
- Google Cloudへの移行: 移行計画の検証に関するベスト プラクティス
- Google Cloudへの移行: 費用を最小限に抑える
データ転送とは
このドキュメントでのデータ移転は、ファイルをそのままオブジェクトに移動するなど、データを変換せずに移動するプロセスを指します。
データ転送の難しさ
データ移転は 1 つの巨大な FTP セッションで、片側に入れたファイルが反対側から出てくるのを待つもの、と考えがちです。しかし、ほとんどの企業環境では、移行プロセスには次のような多くの要因が関係します。
- 転送オプションの決定、承認の取得、予期しない問題への対処など、管理にかかる時間を考慮した転送計画を作成する。
- 転送を実行するチーム、ツールやアーキテクチャを承認する担当者、データの移行によるメリットや中断を懸念するビジネス関係者など、組織内のユーザーを調整する。
- リソース、費用、時間、プロジェクトにおけるその他の考慮事項に基づいて、適切な転送ツールを選択する。
- 「光の速度」の問題(帯域幅不足)、アクティブに使用されているデータセットの移動、処理中のデータの保護とモニタリング、データ移転を確実に成功させるなど、データ転送に関する課題を解決する。
このドキュメントは、移行を成功させるためのサポートを目的としています。
データ転送に関連するその他のプロジェクト
次のリストは、このドキュメントで扱っていない他のタイプのデータ転送プロジェクトのリソースです。
- データの変換(行の結合、データセットの結合、個人を特定できる情報のフィルタリングなど)が必要な場合は、データを Google Cloud データ ウェアハウスに保存できる抽出、変換、読み込み(ETL)ソリューションを検討してください。
- データベースと関連アプリを移行する必要がある場合(データベース アプリの移行など)は、データベースの移行: コンセプトと原則をご覧ください。
ステップ 1: チームを編成する
転送を計画するには、通常、次のロールと責任を持つ担当者が必要です。
- 移行に必要なリソースの有効化: ストレージ、IT、ネットワーク管理者、上層部のプロジェクト スポンサー、その他のアドバイザー(Google アカウント チームや統合パートナーなど)
- 移行決定の承認: データ所有者または管理者(誰がどのデータを移行できるかに関する内部ポリシー)、法務アドバイザー(データ関連の規制)、セキュリティ管理者(データアクセスの保護に関する内部ポリシー)
- 転送の実行: チームリーダー、プロジェクト マネージャー(プロジェクトの実行と追跡)、エンジニアリング チーム、オンサイトでの受け渡し(アプライアンス ハードウェアの受け取り)
転送プロジェクトにおける上記の責任者を特定し、必要に応じて計画や意思決定の場に参加させることが重要です。多くの場合、組織計画が不十分であることが転送イニシアチブの失敗につながります。
これらの関係者からプロジェクトの要件や意見を収集することが容易でないこともありますが、計画を立て、明確なロールと責任を確立すると、最終的には実を結びます。自分 1 人でデータの詳細をすべて把握するのは非常に困難です。チームを編成することで、ビジネスのニーズをさらに詳しく把握できます。ベスト プラクティスとして、移行の完了に時間、資金、リソースを投資する前に、潜在的な問題を特定することをおすすめします。
ステップ 2: 要件と利用可能なリソースを収集する
転送計画を設計する際は、まずデータ移転の要件を収集してから、転送オプションを決定することをおすすめします。要件を収集するには、次の手順を行います。
- 移動する必要があるデータセットを特定します。
- Data Catalog などのツールを選択して、データを論理グループにまとめて移動し、一緒に使用します。
- 組織内のチームと協力して、これらのグループを検証または更新します。
- 移動できるデータセットを特定します。
- 規制、セキュリティ、その他の要因によって、一部のデータセットの転送を禁止するかどうかを検討します。
- 移行前にデータの一部などを変換する必要がある場合(機密データの削除やデータの再編成)は、Dataflow または Cloud Data Fusion などのデータ インテグレーション サービス、あるいは Cloud Composer のようなワークフロー オーケストレーション サービスを使用することを検討してください。
- 移動可能な各データセットの転送先を決定します。
- データを保存するために選択したストレージ オプションを記録します。通常、Google Cloud のターゲット ストレージ システムは Cloud Storage です。Cloud Storage は、アプリケーションの運用開始後に複雑なソリューションが必要になった場合でも対応できる、スケーラブルで耐久性のあるストレージ オプションです。
- 移行後に維持する必要があるデータアクセス ポリシーを理解します。
- このデータを特定のリージョンに保存する必要があるかどうかを判断します。
- 転送先でどのようにこのデータを構造化するか計画します。たとえば、ソースと同じ方法で構造化するかどうかなどが考えられます。
- 継続的にデータを転送する必要があるかどうかを判断します。
- 移動可能なデータセットの場合、移動に使用できるリソースを決定します。
- 時間: いつまでに転送を完了する必要がありますか?
- 費用: チームが使用できる予算と転送費用はどのくらいありますか?
- 担当者: 転送を実行できるユーザーは誰ですか?
- 帯域幅(オンライン転送の場合): Google Cloud で使用可能な帯域幅のうち、転送に割り当てることができるのはどのくらいですか?また、割り当てられる期間はどのくらいですか?
計画の次の段階で転送オプションを評価して選択する前に、データ ガバナンス、組織、セキュリティなど、IT モデルの改善が可能な点がないかどうかを評価することをおすすめします。
セキュリティ モデル
データ転送プロジェクトの一環として、転送チームの多くのメンバーに組織の新しいロールが付与される場合があります。 Google Cloud データ転送計画は、Identity and Access Management(IAM)権限と IAM を安全に使用するためのベスト プラクティスを確認する絶好の機会です。これらの問題は、ストレージへのアクセス権の付与に影響する可能性があります。たとえば、規制上の理由でアーカイブされたデータへの書き込みアクセスを厳密に制限し、一方でテスト環境への書き込みは多くのユーザーやアプリケーションに許可することもできます。
組織 Google Cloud
Google Cloud のデータ構造は、Google Cloudの使用方法によって異なります。アプリケーションを実行するのと同じ Google Cloud プロジェクトにデータを保存しても問題なく機能する場合もありますが、管理の観点からは最適ではない場合があります。開発者によっては、本番環境データを表示する権限がない場合もあります。その場合、開発者はサンプルデータのコードを開発し、本番環境データには権限のあるサービス アカウントがアクセスすることが考えられます。そのため、本番環境のデータセット全体を別の Google Cloud プロジェクトに保存し、サービス アカウントを使用して各アプリケーション プロジェクトのデータにアクセスできるようにするとよいでしょう。
Google Cloud はプロジェクトを中心に構成されています。プロジェクトはフォルダにグループ化でき、フォルダは組織の下にグループ化できます。ロールはプロジェクト レベルで設定され、アクセス権限は Cloud Storage バケットレベルで追加されます。この構造は、他のオブジェクト ストア プロバイダの権限構造と一致します。
組織を構造化するためのベスト プラクティスについては、ランディング ゾーンのリソース階層を決定する Google Cloud をご覧ください。 Google Cloud
ステップ 3: 転送オプションを評価する
データ移転オプションを評価するには、転送チームは次のような要素を考慮する必要があります。
- 費用
- 転送時間
- オフラインとオンラインの転送オプション
- 転送ツールとテクノロジー
- セキュリティ
費用
データ転送に関連する費用の大半は、次のとおりです。
- ネットワーク費用
- Cloud Storage への上り(内向き)は無料です。ただし、パブリック クラウド プロバイダでデータをホストする場合は、データ転送の下り(外向き)料金が発生し、さらにストレージ費用(読み取りオペレーションなど)が発生する可能性があります。この料金は、Google または他のクラウド プロバイダからのデータに適用されます。
- 独自に運用しているプライベート データセンターでデータがホストされている場合は、 Google Cloudへの帯域幅を増やすための追加費用が発生する可能性があります。
- データの転送中と転送後の Cloud Storage のストレージとオペレーションの費用
- プロダクトの費用(Transfer Appliance など)
- チームの編成とサポートの取得にかかる人件費
転送時間
コンピューティングでは、大量のデータを転送するなど、ネットワークのハードウェア制限が強調されることはほとんどありません。理論上、1 Gbps のネットワークでは、1 GB を 8 秒で転送できます。これを巨大なデータセット(100 TB など)にスケールアップした場合、転送時間は 12 日間になります。巨大なデータセットを転送すると、インフラストラクチャの制限が試され、ビジネスに問題を引き起こす可能性があります。
転送にかかる時間を見積もるときは、次の要素を計算に含めます。
- 移行するデータセットのサイズ。
- 転送に使用できる帯域幅。
- 管理時間の一定の割合。
- 帯域幅の効率性。転送時間にも影響する可能性があります。
ピーク時は、大規模なデータセットを会社のネットワークから転送しない方がよい場合があります。転送によってネットワークが過負荷になると、必要な作業やミッション クリティカルな作業を完了できなくなるからです。このため、転送チームは時間の要素を考慮する必要があります。
データが Cloud Storage に転送された後、Dataflow などのさまざまなテクノロジーを使用して新しいファイルを処理できます。
ネットワーク帯域幅を増やす
ネットワーク帯域幅を増やす方法は、Google Cloudへの接続方法によって異なります。
Google Cloud と他のクラウド プロバイダの間のクラウド間転送では、Google がクラウド ベンダーのデータセンター間の接続をプロビジョニングします。セットアップは不要です。 Google Cloud
プライベート データセンターとGoogle Cloudの間でデータを転送する場合、次のような複数の方法で行えます。
- 公開 API を使用した公共のインターネット接続
- 公開 API を使用したダイレクト ピアリング
- 非公開 API を使用した Cloud Interconnect
これらのアプローチを評価する際は、長期的な接続ニーズを考慮することが重要です。転送目的でのみ帯域幅を取得するのは費用がかかりすぎると考えがちですが、Google Cloud の長期使用と組織全体のネットワーク ニーズを考慮すると、投資する価値がある場合もあります。ネットワークをGoogle Cloudに接続する方法については、Network Connectivity プロダクトを選択するをご覧ください。
公共のインターネット経由でデータを転送する方法を選択した場合は、会社のポリシーでこのような転送が禁止されているかどうかをセキュリティ管理者に確認することをおすすめします。また、本番環境のトラフィックに公共のインターネット接続が使用されているかどうかも確認してください。最後に、大規模なデータ転送は本番環境ネットワークのパフォーマンスに悪影響を与える可能性があることを考慮してください。
オンライン転送とオフライン転送
データ転送にオフライン プロセスとオンライン プロセスのどちらを使用するかは、非常に重要です。つまり、Cloud Interconnect か公共のインターネットかを問わずネットワーク経由で転送するか、ストレージ ハードウェアを使用して転送するかを選択する必要があります。
この決定を支援するために、次のグラフは、さまざまなデータセット サイズと帯域幅の転送速度も示しています。これらの計算には一定の管理オーバーヘッドが考慮されています。
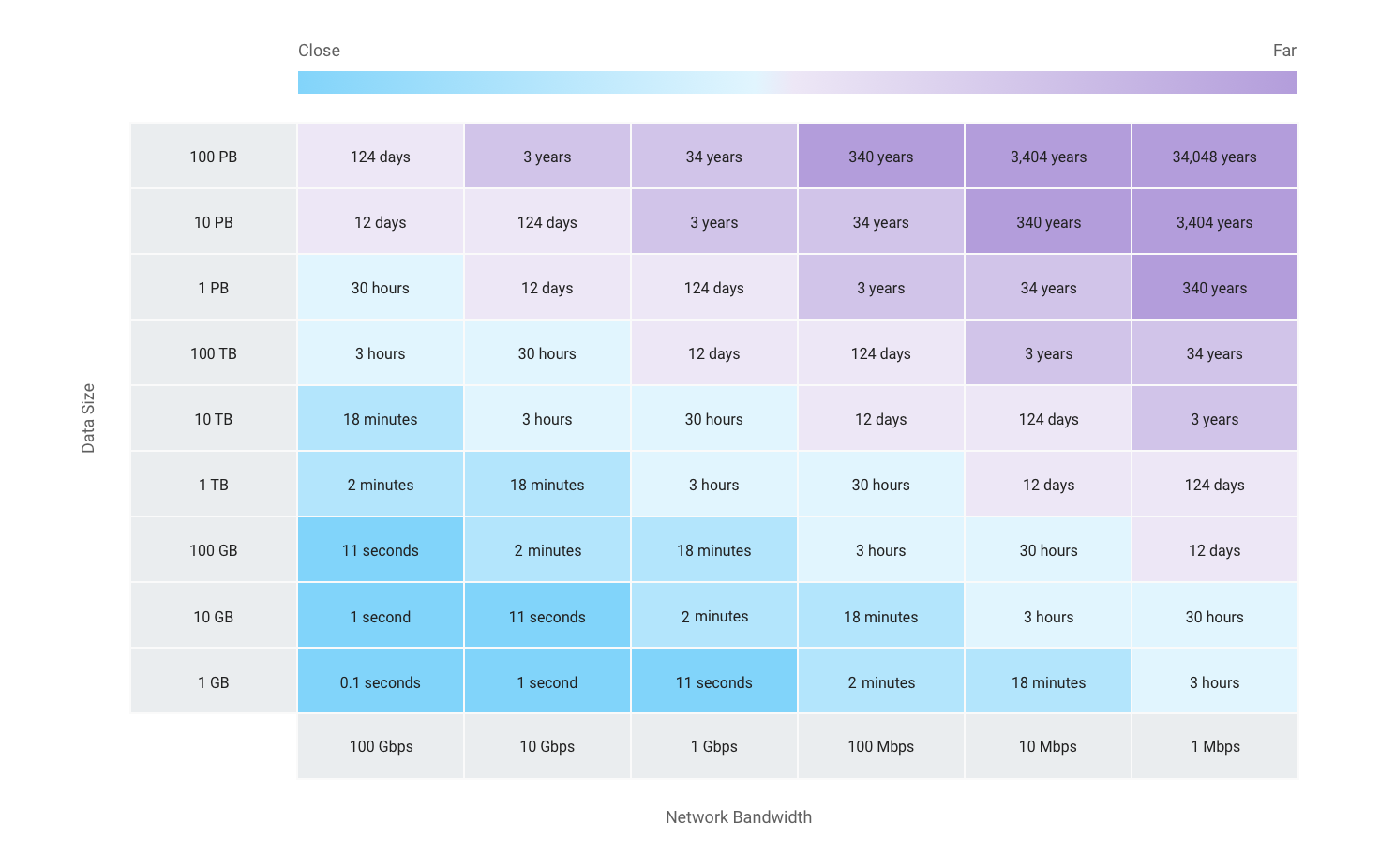
前述のように、データ移転の低レイテンシ(ネットワーク帯域幅の取得など)を実現するための費用が、組織にとっての投資価値に見合うものがどうかを検討する必要があります。
Google が提供するオプション
Google では、データ転送の実行に役立つさまざまなツールとテクノロジーを提供しています。
Google の転送オプションの選択
次の表に示すように、転送オプションの選択はユースケースによって異なります。
| データの移行元 | 事例 | おすすめのプロダクト |
|---|---|---|
| 別のクラウド プロバイダ(Amazon Web Services、Microsoft Azure など)から Google Cloud | — | Storage Transfer Service |
| Cloud Storage から Cloud Storage へ(2 つの異なるバケット間) | - | Storage Transfer Service |
| プライベート データセンターから Google Cloud | プロジェクト期限内にデータを転送できる帯域幅がある | gcloud storage コマンド |
| プライベート データセンターから Google Cloud | プロジェクト期限内にデータを転送できる帯域幅がある | オンプレミス データ用の Storage Transfer Service |
| プライベート データセンターから Google Cloud | プロジェクト期限内にデータを転送できる帯域幅がない | Transfer Appliance |
オンプレミス データの転送量を削減するための gcloud storage コマンド
gcloud storage コマンドは、一般的なエンタープライズ規模のネットワークを介してプライベート データセンターから中小規模の転送を行う場合の標準ツールです。別のクラウドプロバイダから Google Cloudへ移行できます。gcloud storage は、Cloud Storage オブジェクトの最大サイズまでのオブジェクトのアップロードをサポートしていますが、大規模なオブジェクトの転送は、短時間の転送よりもエラーが高くなる可能性があります。大規模オブジェクトを Cloud Storage に転送する方法について詳しくは、Storage Transfer Service: オンプレミス データの転送量が多い場合をご覧ください。
gcloud storage コマンドは、次の場合に特に役立ちます。
- ユーザーが必要に応じて、またはコマンドライン セッション中に転送を実行する必要がある場合。
- 転送するファイルが少ないか、非常に大きい、もしくはその両方。
- プログラムの出力を使用している(Cloud Storage に出力をストリーミングしている)場合。
- 適度な数のファイルを含むディレクトリを監視し、非常に低いレイテンシで更新を同期する必要がある場合。
Storage Transfer Service: オンプレミス データの転送量が多い場合
gcloud storage コマンドと同様に、Storage Transfer Service for On Premises Data を使用すると、ネットワーク ファイル システム(NFS)ストレージから Cloud Storage への転送ができるようになります。Storage Transfer Service for On Premises Data は、大規模な転送(最大ペタバイトのデータ、数十億のファイル)用に設計されています。完全コピーまたは増分コピーが可能で、Google の転送オプションの選択で前述したすべての転送オプションで動作します。また、マネージド グラフィカル ユーザー インターフェースを備えており、IT に詳しくないユーザーであっても(セットアップ後に)データの移動に使用できます。
Storage Transfer Service for On Premises Data は、次のシナリオで特に役立ちます。
- データ ボリュームを移動するために十分な帯域幅がある場合。
- コマンドライン ツールの使用が難しいと感じる可能性のある、多数の社内ユーザーをサポートしている場合。
- 堅牢なエラー報告と、移動されたすべてのファイルとオブジェクトの記録が必要な場合。
- データセンター内の他のワークロードへ転送が与える影響を制限する必要がある場合(このプロダクトはユーザー指定の帯域幅制限内に収まります)。
- 定期的な転送を実行する場合。
Storage Transfer Service for On Premises Data を設定するには、オンプレミス ソフトウェア(エージェント)をデータセンターのコンピュータにインストールします。
Storage Transfer Service を設定したら、ソース ディレクトリ、転送先バケット、時刻またはスケジュールを指定して、Google Cloud コンソールで転送を開始できます。Storage Transfer Service は、ソース ディレクトリ内のサブディレクトリとファイルを再帰的にクロールし、対応する名前のオブジェクトを Cloud Storage に作成します(/dir/foo/file.txt オブジェクトは /dir/foo/file.txt という移行先バケットのオブジェクトになります)。Storage Transfer Service は、一時的なエラーが発生すると自動的に再試行します。転送の実行中に、移動済みのファイル数と全体の転送速度をモニタリングし、エラーサンプルを表示できます。
Storage Transfer Service が転送を完了すると、タップされたすべてのファイルと受信したエラー メッセージの全レコードを含むタブ区切りファイル(TSV)が生成されます。エージェントはフォールト トレラントであるため、エージェントがダウンしても、残りのエージェントで転送が続行されます。エージェントは自己更新と自己回復も行うため、最新バージョンのパッチを適用する必要も、予期しない問題が発生した場合にプロセスを再開する必要もありません。
Storage Transfer Service を使用するときは、以下を考慮してください。
- すべてのマシンで同一のエージェント セットアップを使用します。すべてのエージェントに同じネットワーク ファイル システム(NFS)を同じように(同じ相対パス)マウントする必要があります。このセットアップは、プロダクトが機能するための必須要件です。
- エージェントが多いほど、処理速度が向上します。転送はすべてのエージェント間で自動的に並列化されるため、多数のエージェントをデプロイして、使用可能な帯域幅を使用することをおすすめします。
- 帯域幅の上限によってワークロードを保護できます。他のワークロードがデータセンターの帯域幅を使用することもあるため、転送が SLA に影響しないように帯域幅の上限を設定します。
- エラーの確認にかかる時間を計画します。大規模な転送では、確認が必要なエラーが発生することがよくあります。Storage Transfer Service を使用すると、Google Cloud コンソールで直接発生したエラーのサンプルを確認できます。必要に応じて、すべての転送エラーの完全なレコードを BigQuery に読み込んで、ファイルのチェックや再試行後に残ったエラーの評価ができます。これらのエラーは、転送中にソースに書き込むアプリを実行している場合や、トラブルシューティングが必要な問題(権限エラーなど)があることを示している場合があります。
- 長時間実行される転送向けに Cloud Monitoring をセットアップします。Storage Transfer Service を使用すると Monitoring でエージェントの健全性とスループットをモニタリングできるため、エージェントが停止した場合や注意が必要な場合にアラートが通知されます。転送に数日から数週間かかる場合のエージェント障害の対処は重要です。プロジェクト タイムラインの遅れにつながりかねない大幅な速度低下や中断を避けることができます。
Transfer Appliance: 大規模な転送の場合
大規模な転送(特にネットワーク帯域幅が限られている転送)で、とりわけ高速ネットワーク接続が利用できず、帯域幅を増やす費用が高すぎる場合、Transfer Appliance が最適なオプションです。
Transfer Appliance は、次のシナリオで特に役立ちます。
- データセンターが離れた場所にあり、帯域幅へのアクセスが限られているかまったくアクセスできない場合。
- 帯域幅があっても、プロジェクトの期限までに取得することができない場合。
- アプライアンスを受け取りネットワークに接続するための、物流リソースへのアクセスがある場合。
このオプションでは、次の点を考慮します。
- Transfer Appliance を活用するには、Google が所有するハードウェアを受け取って返送できる必要があります。
- インターネット接続によって異なりますが、 Google Cloud へのデータ転送のレイテンシはオンラインよりも Transfer Appliance の方が通常長くなります。
- Transfer Appliance は一部の国でのみご利用いただけます。
Transfer Appliance で考慮すべき 2 つの主な基準は、費用と速度です。一般的なネットワーク接続(1 Gbps など)では、100 TB のデータをオンラインで転送するのに 10 日以上かかります。この速度が許容範囲であれば、オンライン転送がニーズに適したソリューションということになります。100 Mbps の接続しか使用していない場合(または遠隔地から接続している場合)、同じ転送に 100 日以上かかります。この時点で、Transfer Appliance などのオフライン転送オプションを検討する価値があります。
Transfer Appliance の利用方法は簡単です。Google Cloud コンソールで、保有しているデータ量を指定して Transfer Appliance をリクエストすると、リクエストした場所に Google からアプライアンスが 1 つまたは複数届きます。数日以内に、データをアプライアンスに転送して(データ キャプチャ)Google に返送します。
Storage Transfer Service: クラウド間転送の場合
Storage Transfer Service は、スケーラビリティに優れたフルマネージド サービスで、他のパブリック クラウドから Cloud Storage への転送を自動化します。たとえば、Storage Transfer Service を使用して Amazon S3 から Cloud Storage にデータを転送できます。
HTTP の場合、Storage Transfer Service に決まったフォーマットでパブリック URL を指定します。このアプローチでは、スクリプトを記述する際に各ファイルのサイズ(バイト)およびファイル コンテンツの Base64 でエンコードされた MD5 ハッシュを指定する必要があります。ファイルサイズとハッシュは、ソースのウェブサイトから利用できる場合もあります。そうでなければ、ファイルへのローカル アクセスが必要となり、前述のとおり gcloud storage コマンドを使用する方が簡単です。
転送の準備ができているなら、Storage Transfer Service はとりわけ別のパブリック クラウドから転送する場合に、データを取得して保持するための優れた方法です。
Storage Transfer Service でサポートされていない別のクラウドからデータを移動する場合は、クラウドでホストされている仮想マシン インスタンスから gcloud storage コマンドを使用します。
セキュリティ
多くの Google Cloud ユーザーにとって、セキュリティは最優先事項であり、さまざまなレベルのセキュリティをご利用いただけます。セキュリティに関する考慮事項として、保存データの保護(送信元と宛先のストレージ システムへの承認とアクセス)、転送中のデータの保護、転送プロダクトへのアクセスの保護などがあります。次の表に、これらのセキュリティの側面をサービス別に示します。
| サービス | 保存データ | 転送中のデータ | 転送プロダクトへのアクセス |
|---|---|---|---|
| Transfer Appliance | すべてのデータは保存時に暗号化されます。 | データはお客様が管理する鍵で保護されます。 | アプライアンスは誰でも注文できますが、使用するにはデータソースへのアクセスが必要です。 |
gcloud storage コマンド |
保管時に暗号化される Cloud Storage にアクセスするために必要なアクセスキー。 | データは HTTPS 経由で送信され、転送中に暗号化されます。 | 誰でも Google Cloud CLI をダウンロードして実行できます。データを移行するには、バケットとローカル ファイルに対する権限が必要です。 |
| オンプレミス データ用の Storage Transfer Service | 保管時に暗号化される Cloud Storage にアクセスするために必要なアクセスキー。エージェント プロセスは、OS の権限で許可されているローカル ファイルにアクセスできます。 | データは HTTPS 経由で送信され、転送中に暗号化されます。 | Cloud Storage バケットにアクセスするには、オブジェクトの編集権限が必要です。 |
| Storage Transfer Service | Google Cloud リソース以外(Amazon S3 など)に必要なアクセスキー。保管時に暗号化される Cloud Storage にアクセスするには、アクセスキーが必要です。 | データは HTTPS 経由で送信され、転送中に暗号化されます。 | ソースにアクセスするためのサービス アカウントと Cloud Storage バケットのオブジェクト編集者権限の IAM 権限が必要です。 |
ベースライン セキュリティ強化のため、gcloud storage コマンドを使用したGoogle Cloud へのオンライン転送は HTTPS で行われます。転送中のデータは暗号化され、保存中の Cloud Storage のデータもすべてデフォルトで暗号化されます。Transfer Appliance を使用する場合は、管理するセキュリティ キーを使用してデータを保護できます。通常は、転送計画が会社と規制の要件を満たしていることを確認するために、セキュリティ チームと連携することをおすすめします。
サードパーティの転送プロダクト
高度なネットワークレベルの最適化や継続的なデータ転送ワークフローが必要な場合、より高度なツールを使用できます。より高度なツールの詳細については、Google Cloud パートナーをご覧ください。
ステップ 4: データ移行方法を評価する
データを移行する際は、次の一般的な手順を行います。
- 前のサイトから新しいサイトにデータを転送する。
- 複数のソースから同じデータを同期する場合など、データ インテグレーションで発生した問題を解決する。
- データの移行を検証します。
- 新しいサイトをプライマリ コピーに昇格する。
- フォールバックの必要がなくなったら、前のサイトを廃止する。
データの移行戦略を決める場合、次のことを検討します。
- 移行が必要なデータの量はどれくらいか
- このデータはどのくらいの頻度で変更されるのか
- カットオーバーまでのダウンタイムを許容できるか
- 現在のデータ整合性モデルは何か
最善の方法はありません。どれを選択するかは環境と要件によって異なります。
以下では、次の 4 つのアプローチについて説明します。
- 定期メンテナンス
- 継続的なレプリケーション
- Y(書き込み / 読み取り)
- データアクセス マイクロサービス
どのアプローチにも課題はあります。問題点は、データ移行の規模や要件によって異なります。
マイクロサービス アーキテクチャの場合、データアクセス マイクロサービスが最も望ましい選択肢ですが、データ移行という点では他のアプローチも有効です。データアクセス マイクロサービスを使用するためにインフラストラクチャの最新化が必要な場合は、他のアプローチのほうがよい場合もあります。
次のグラフは、それぞれのアプローチのカットオーバーまでの期間、リファクタリングの作業量、柔軟性を比較しています。

これらのアプローチを実施する前に、新しい環境に必要なインフラストラクチャが準備されていることを確認してください。
定期メンテナンス
ワークロードのカットオーバーに余裕がある場合は、定期メンテナンス(1 回限りの移行、ビッグバン移行)が理想的な選択肢です。カットオーバーの時期を計画できるため。
このアプローチでは、次の手順で移行を行います。
- 以前のサイトにあるデータを新しいサイトにコピーします。このコピーを行うことで、カットオーバーまでの時間を短縮できます。この後は、移行期間中に変更されたデータだけをコピーします。
- データの検証と整合性のチェックを行い、前のサイトのデータと新しいサイトにコピーしたデータを比較します。
- コピーしたデータがこれ以上変更されないように、これらのデータに書き込み権限のあるワークロードとサービスを停止します。
- 最初のコピーの後に発生した変更を同期します。
- 新しいサイトを使用するように、ワークロードとサービスをリファクタリングします。
- ワークロードとサービスを開始します。
- フォールバックの必要がなくなったら、前のサイトを廃止します。
このアプローチでは、ワークロードとサービスのリファクタリングは最小限になるため、ほとんどの作業が運用側で行われます。
継続的なレプリケーション
カットオーバーまでに余裕のないワークロードがある場合は、最初のコピーと検証の後にレプリケーションを継続的に行うようにスケジューリングできます。このとき、データが変更される頻度も考慮する必要があります。2 つのシステムが同期された状態を維持するのが難しい場合もあります。
継続的なレプリケーション アプローチ(オンライン移行またはトリクル移行とも呼ばれます)は、定期メンテナンス アプローチよりも複雑です。同期に必要なデータ量が最小限になるため、カットオーバーまでの時間は短くなります。継続的なレプリケーションによる移行の順序は次のとおりです。
- 以前のサイトにあるデータを新しいサイトにコピーします。このコピーを行うことで、カットオーバーまでの時間を短縮できます。この後は、移行期間中に変更されたデータだけをコピーします。
- データの検証と整合性のチェックを行い、前のサイトのデータと新しいサイトにコピーしたデータを比較します。
- 前のサイトから新しいサイトへの継続的なレプリケーションを設定します。
- 移行するデータ(つまり、前の手順に含まれるデータ)にアクセスできるワークロードとサービスを停止します。
- 新しいサイトを使用するように、ワークロードとサービスをリファクタリングします。
- レプリケーションによって新しいサイトがレガシーサイトに完全に同期されるまで待ちます。
- ワークロードとサービスを開始します。
- フォールバックの必要がなくなったら、前のサイトを廃止します。
このアプローチでは、定期メンテナンスの場合と同様に、大半の作業は運用側で行います。
Y(書き込み / 読み取り)
ワークロードに高い可用性が必要で、カットオーバーまでのダウンタイムを許容できない場合は、別のアプローチが必要になります。この場合、このドキュメントで Y(書き込み / 読み取り)と呼んでいるアプローチを使用できます。これは一種の並行移行です。移行が終わるまで前のサイトと新しいサイトの両方でデータの書き込みと読み取りを行います。この Y の文字は、移行期間中のデータフローの形を記号として表したものす。
このアプローチの場合、移行手順は次のようになります。
- データを前のサイトから読み取り、前のサイトと新しいサイトの両方に書き込むように、ワークロードとサービスをリファクタリングします。
- 新しいサイトへの書き込みを有効にする前に書き込まれたデータを識別し、そのデータを以前のサイトから新しいサイトにコピーします。前述のリファクタリングとともにこれを行うことで、データストアの整合性が確保されます。
- データの検証と整合性のチェックを行い、以前のサイトのデータと新しいサイトのデータを比較します。
- 読み取りオペレーションを前のサイトから新しいサイトに切り替えます。
- データの検証と整合性のチェックを再度行い、前のサイトのデータと新しいサイトのデータを比較します。
- 前のサイトへの書き込みを無効にします。
- フォールバックの必要がなくなったら、前のサイトを廃止します。
定期メンテナンスや継続的なレプリケーションとは異なり、このアプローチでは複数のリファクタリングが必要になるため、ほとんどの作業を開発側が行うことになります。
データアクセス マイクロサービス
Y(書き込み / 読み取り)アプローチで必要なリファクタリングを少なくしたい場合は、データアクセス マイクロサービスを使用するようにワークロードとサービスをリファクタリングします。これにより、データの読み取り / 書き込みオペレーションが一元化されます。このスケーラブルなマイクロサービスがデータ ストレージ レイヤへの唯一のエントリ ポイントとなり、レイヤのプロキシとして機能します。アーキテクチャの他のコンポーネントに影響を与えず、カットオーバーまでの期間を考慮せずにコンポーネントをリファクタリングできるため、ここで説明しているアプローチの中では最も柔軟な方法となります。
データアクセス マイクロサービスを使用するアプローチは Y(書き込み / 読み取り)とよく似ています。違うのは、データ ストレージ レイヤにアクセスするすべてのワークロードとサービスをリファクタリングするのではなく、データアクセス マイクロサービスをリファクタリングする点です。このアプローチの場合、移行手順は次のようになります。
- 前のサイトと新しいサイトの両方にデータを書き込むように、データアクセス マイクロサービスをリファクタリングします。読み取りは前のサイトに対して行われます。
- 新しいサイトへの書き込みを有効にする前に書き込まれたデータを識別し、そのデータを以前のサイトから新しいサイトにコピーします。前述のリファクタリングとともにこれを行うことで、データストアの整合性が確保されます。
- データの検証と整合性のチェックを行い、以前のサイトのデータと新しいサイトのデータを比較します。
- 新しいサイトからデータを読み取るようにデータアクセス マイクロサービスをリファクタリングします。
- データの検証と整合性のチェックを再度行い、前のサイトのデータと新しいサイトのデータを比較します。
- 新しいサイトにのみ書き込むように、データアクセス マイクロサービスをリファクタリングします。
- フォールバックの必要がなくなったら、前のサイトを廃止します。
このアプローチでは、Y(書き込み / 読み取り)と同様に、作業の大半を開発側で行います。ただし、リファクタリングはデータアクセス マイクロサービスにのみ行うため、Y(書き込み / 読み取り)よりも負担はかなり軽減されます。
ステップ 5: 転送を準備する
大規模な転送の場合、もしくは依存関係が大きい転送の場合、移行サービスをどのように運用するか理解することが重要です。通常は次のステップを行います。
- 料金と ROI の見積もりこのステップでは、意思決定に役立つさまざまなオプションを提供します。
機能テストこのステップでは、プロダクトが正常にセットアップされていること、ネットワーク接続(該当する場合)が動作することを確認します。また、データの代表的なサンプルを宛先に移動できるかどうかテストします(VM インスタンスの移動などの転送以外のステップを含む)。
通常、このステップは転送マシンや帯域幅などのすべてのリソースを割り当てる前に行うことができます。このステップの目標は次のとおりです。
- 転送をインストールして操作できることを確認する。
- データ移動(ネットワーク ルートなど)やオペレーション(転送以外のステップで必要なトレーニングなど)を妨げる、潜在的なプロジェクト停止の問題を明らかにする。
パフォーマンス テストこのステップでは、本番環境リソースが次の目的で割り当てられた後に、実際のデータの大型のサンプル(通常は 3~5%)で転送を実行します。
- 割り当てられたすべてのリソースを使用でき、期待する速度を達成できることを確認する。
- ボトルネックを明らかにし、解決する(低速なソース ストレージ システムなど)。
ステップ 6: 転送の整合性を確保する
転送中のデータの整合性を確保するため、次の点に注意することをおすすめします。
- 転送先でバージョニングとバックアップを有効にして、誤って削除した場合の被害を抑える。
- ソースデータを削除する前にデータを検証する。
大規模なデータ転送(数ペタバイトのデータと数十億のファイル)の場合、基盤となるソース ストレージ システムのベースラインの潜在エラー率が 0.0001% と低くても、数千ものファイルとギガバイトの損失が生じてしまいます。通常、ソースで実行されているアプリケーションはこれらのエラーに対応しているため、追加の検証は必要ありません。例外的なシナリオ(長期間のアーカイブなど)では、ソースから安全にデータを削除する前に追加の検証を行う必要があります。
アプリケーションの要件によっては、転送の完了後にデータの整合性テストを実行して、アプリケーションが意図したとおりに動作するかどうか確認することをおすすめします。多くの転送プロダクトには、データの整合性チェックが組み込まれています。ただし、リスク プロファイルによっては、ソースからデータを削除する前に、データとそのデータを読み取るアプリに対して追加のチェックを行うことをおすすめします。たとえば、記録して計算したチェックサムが宛先に書き込まれたデータと一致するか、アプリケーションで使用されたデータセットが正常に転送されたかを確認してください。
次のステップ
- 移行に関するヘルプを確認するタイミングを確認する。
- Cloud Architecture Center で、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。
寄稿者
著者:
- Marco Ferrari | クラウド ソリューション アーキテクト
- Ross Thomson | クラウド ソリューション アーキテクト