本文說明使用 TensorFlow Extended (TFX) 程式庫的機器學習 (ML) 系統整體架構。本文也會說明如何使用 Cloud Build 和 Vertex AI Pipelines,為機器學習系統設定持續整合 (CI)、持續推送軟體更新 (CD) 和持續訓練 (CT)。
在本文件中,「機器學習系統」和「機器學習管道」一詞是指機器學習模型的「訓練」管道,而非模型的「評分」或「預測」管道。
本文適用對象為數據資料學家和機器學習工程師,他們希望調整 CI/CD 做法,將機器學習解決方案移至 Google Cloud的正式環境,並希望確保機器學習管道的品質、維護性和可調整性。
本文件涵蓋以下主題:
- 瞭解機器學習中的持續整合/持續推送軟體更新和自動化功能。
- 使用 TFX 設計整合式機器學習管道。
- 使用 Vertex AI Pipelines 自動化調度管理機器學習管道。
- 使用 Cloud Build 為機器學習管道設定 CI/CD 系統。
MLOps
如要在正式版環境中整合機器學習系統,您需要在機器學習管道中自動化調度管理各個步驟。此外,您還需要自動執行管道,才能持續訓練模型。如要嘗試新的構想和功能,您必須在管道的全新導入作業中採用持續整合/持續推送軟體更新 (CI/CD) 做法。以下各節將概略說明機器學習中的 CI/CD 和 CT。
機器學習管道自動化
在某些用途中,手動訓練、驗證及部署機器學習模型的程序就已足夠。如果您的團隊只管理少數幾個不會經常重新訓練或變更的機器學習模型,這項手動方法就很實用。不過,在實際情況中,模型在實際部署時經常會發生故障,因為模型無法適應環境動態變化,或描述這種動態的資料。
為了讓機器學習系統能夠適應這類變化,您必須採用下列 MLOps 技術:
- 自動執行機器學習管道,以便根據新資料重新訓練新模型,捕捉任何新興模式。本文件後續會在「使用 Vertex AI Pipeline 進行機器學習」一節中討論 CT。
- 設定持續推送系統,經常部署整個機器學習管道的全新實作項目。本文稍後將在「機器學習的 CI/CD 設定 Google Cloud」一節中討論 CI/CD。
您可以自動化機器學習正式版管道,以便使用新資料重新訓練模型。您可以根據需求、排程、新資料可用性、模型效能下降、資料統計屬性出現重大變化,或其他條件觸發管道。
CI/CD 管道與 CT 管道的比較
新資料的出現,是重新訓練機器學習模型的其中一個觸發條件。機器學習管道的全新實作項目 (包括新的模型架構、特徵工程和超參數) 也是重新執行機器學習管道的另一個重要觸發事件。這個新的機器學習管道實作項目可做為新版的模型預測服務,例如具有 REST API 的微服務,可用於線上服務。這兩種情況的差異如下:
- 如要使用新資料訓練新的機器學習模型,系統會執行先前部署的 CT 管道。不會部署新的管道或元件,只有新的預測服務或新訓練的模型會在管道結尾提供。
- 如要使用新導入項目訓練新的機器學習模型,請透過 CI/CD 管道部署新的管道。
如要快速部署新的機器學習管道,您必須設定 CI/CD 管道。當可供各種環境 (例如開發、測試、試行、前置生產和實際生產) 使用的新導入方式獲得核准後,這個管道就會負責自動部署新的機器學習管道和元件。
下圖顯示 CI/CD 管道與 ML CT 管道之間的關係。

圖 1. CI/CD 和 ML CT 管道。
這些管道的輸出內容如下:
- 如果提供新的實作項目,成功的 CI/CD 管道會部署新的機器學習持續訓練管道。
- 如果有新資料,成功的 CT 管道會訓練新模型,並將其部署為預測服務。
設計以 TFX 為基礎的機器學習系統
以下各節將說明如何使用 TensorFlow Extended (TFX) 設計整合式機器學習系統,為機器學習系統設定持續整合/持續推送軟體更新管道。雖然有幾個建構機器學習模型的架構,但 TFX 是整合式機器學習平台,可用於開發及部署實際工作環境中的機器學習系統。TFX 管線是實作機器學習系統的一系列元件。這個 TFX 管道專為可擴充的高效能機器學習工作而設計。這些工作包括建立模型、訓練、驗證、提供推論,以及管理部署作業。TFX 的主要程式庫如下:
- TensorFlow 資料驗證 (TFDV):用於偵測資料中的異常狀況。
- TensorFlow Transform (TFT):用於資料預先處理和特徵工程。
- TensorFlow Estimators 和 Keras:用於建構及訓練機器學習模型。
- TensorFlow Model Analysis (TFMA):用於評估及分析機器學習模型。
- TensorFlow Serving (TFServing):用於將 ML 模型做為 REST 和 gRPC API 提供。
TFX 機器學習系統總覽
下圖顯示如何整合各種 TFX 程式庫,以組合機器學習系統。

圖 2. 典型的以 TFX 為基礎的機器學習系統。
圖 2 為典型的 TFX 機器學習系統。您可以手動完成下列步驟,也可以透過自動化管道完成:
- 資料擷取:第一步是從資料來源擷取新的訓練資料。這個步驟的輸出內容是用於訓練及評估模型的資料檔案。
- 資料驗證:TFDV 會根據預期 (原始) 資料結構驗證資料。資料結構定義會在系統部署前,於開發階段建立及修正。資料驗證步驟會偵測資料分布和結構定義偏差的異常狀況。這個步驟的輸出內容是異常現象 (如有),以及是否要執行後續步驟的決定。
- 資料轉換:驗證資料後,系統會使用 TFT 執行資料轉換和特徵工程作業,將資料分割並準備好用於機器學習工作。這個步驟的輸出內容是用於訓練及評估模型的資料檔案,通常會轉換為
TFRecords格式。此外,產生的轉換成果有助於建構模型輸入內容,並在訓練後將轉換程序嵌入匯出的已儲存模型中。 - 模型訓練和調整:如要實作及訓練機器學習模型,請使用
tf.KerasAPI 搭配先前步驟產生的轉換資料。如要選取可產生最佳模型的參數設定,您可以使用 Keras 調節器,這是 Keras 的超參數調整程式庫。或者,您也可以使用其他服務,例如 Katib、Vertex AI Vizier 或 Vertex AI 的超參數調校器。這個步驟的輸出內容是用於評估的已儲存模型,以及用於線上提供模型以進行預測的另一個已儲存模型。 - 模型評估和驗證:在訓練步驟後匯出模型時,系統會在測試資料集上評估模型,以便使用 TFMA 評估模型品質。TFMA 會整體評估模型品質,並找出資料模型中哪個部分效能不佳。這項評估有助於確保模型只有在符合品質標準時,才會提交供放送。這些標準包括在各種資料子集 (例如客層和地點) 中獲得合理成效,以及相較於先前模型或基準模型的成效提升。這個步驟的輸出內容是一組成效指標,以及是否要將模型推送至實際工作環境的決定。
- 預測模型服務:經過驗證的新訓練模型會以微服務的形式部署,以便使用 TensorFlow Serving 提供線上預測服務。這個步驟的輸出內容是已訓練的機器學習模型所部署的預測服務。您可以將訓練好的模型儲存在模型登錄檔中,取代這個步驟。接著,系統會啟動另一個提供 CI/CD 程序的模型。
如需 TFX 程式庫的使用範例,請參閱官方的 TFX Keras 元件教學課程。
Google Cloud上的 TFX ML 系統
在實際工作環境中,系統元件必須在可靠的平台上大規模執行。下圖顯示 TFX ML 管道各個步驟如何在 Google Cloud上使用受管理的服務執行,確保敏捷性、可靠性和大規模效能。

圖 3. 以 Google Cloud為基礎的 TFX 機器學習系統。
下表說明圖 3 中顯示的主要Google Cloud 服務:
| 步驟 | TFX 程式庫 | Google Cloud service |
|---|---|---|
| 資料擷取和驗證 | TensorFlow Data Validation | Dataflow |
| 資料轉換 | TensorFlow Transform | Dataflow |
| 模型訓練和調整 | TensorFlow | Vertex AI 訓練 |
| 模型評估和驗證 | TensorFlow Model Analysis | Dataflow |
| 提供預測模型 | TensorFlow Serving | Vertex AI 預測 |
| 模型儲存空間 | 不適用 | Vertex AI Model Registry |
- Dataflow 是一項可靠的無伺服器全代管服務,可用於在 Google Cloud上大規模執行 Apache Beam 管道。Dataflow 可用於擴大下列程序:
- 計算統計資料,驗證傳入的資料。
- 執行資料準備和轉換作業。
- 在大型資料集上評估模型。
- 根據評估資料集的不同面向計算指標。
- Cloud Storage 是具有高可用性和耐用性的儲存空間,適用於二進位大型物件。Cloud Storage 會代管 ML 管道執行期間產生的構件,包括:
- 資料異常 (如有)
- 轉換後的資料和構件
- 匯出的 (經過訓練的) 模型
- 模型評估指標
- Vertex AI Training 是一種代管服務,可大規模訓練機器學習模型。您可以使用 TensorFlow、Scikit learn、XGBoost 和 PyTorch 的預先建構容器執行模型訓練工作。您也可以使用自己的自訂容器執行任何架構。針對訓練基礎架構,您可以使用加速器和多個節點進行分散式訓練。此外,我們也提供可用於超參數調整的貝式最佳化方法服務,可讓您進行可擴充的最佳化作業
- Vertex AI Prediction 是一項代管服務,可透過 REST API 將模型部署為微服務,藉此執行批次預測和線上預測,這項服務也與 Vertex Explainable AI 和 Vertex AI Model Monitoring 整合,可瞭解您的模型,並在出現特徵或特徵歸因偏差和偏移時收到警示。
- Vertex AI Model Registry 可讓您管理機器學習模型的生命週期。您可以為匯入的模型建立版本,並查看其成效指標。接著,您可以使用模型進行批次預測,或部署模型以便透過 Vertex AI 預測功能進行線上服務
使用 Vertex AI Pipelines 自動化調度管理機器學習系統
本文件說明如何設計以 TFX 為基礎的機器學習系統,以及如何在 Google Cloud上大規模執行系統的每個元件。不過,您需要使用指揮器才能將系統的這些不同元件連結在一起。指揮器會依序執行管道,並根據定義的條件自動從一個步驟移動到另一個步驟。舉例來說,如果評估指標符合預先定義的門檻,定義的條件可能會在模型評估步驟後執行模型服務步驟。您也可以並行執行步驟,以節省時間,例如驗證部署基礎架構和評估模型。無論是在開發階段還是實際工作環境階段,自動調度管理機器學習管線都很實用:
- 在開發階段,自動化調度功能可協助數據資料學家執行機器學習實驗,而非手動執行每個步驟。
- 在實際執行階段,自動化調度管理可協助您根據排程或特定觸發條件,自動執行機器學習管道。
搭配使用 Vertex AI Pipelines 的機器學習
Vertex AI Pipelines 是 Google Cloud 代管服務,可讓您自動調度及自動執行機器學習管道,其中管道中的每個元件都能在Google Cloud 或其他雲端平台上執行容器。產生的管道參數和構件會自動儲存在 Vertex 機器學習中繼資料中,方便追蹤歷程和執行作業。Vertex AI Pipelines 服務包含以下項目:
- 可用於管理及追蹤實驗、工作和執行作業的使用者介面。
- 用於排定多步驟機器學習工作流程的引擎。
- 用於定義及操作管道和元件的 Python SDK。
- 整合 Vertex ML 中繼資料,儲存執行作業、模型、資料集和其他構件的相關資訊。
以下是 Vertex AI Pipelines 執行管道的組成要素:
- 一組容器化機器學習任務或元件。管道元件是獨立的程式碼,可封裝為 Docker 映像檔。元件會執行管道中的一個步驟。它會接收輸入引數並產生構件。
- 機器學習工作順序的規格,透過 Python 特定領域語言 (DSL) 定義。工作流程的拓撲會透過將上游步驟的輸出內容連結至下游步驟的輸入內容,間接定義。管道定義中的步驟會叫用管道中的元件。在複雜的管道中,元件可以在迴圈中執行多次,也可以依條件執行。
- 一組管道輸入參數,其值會傳遞至管道的元件,包括篩選資料的條件,以及管道產生的構件儲存位置。
下圖顯示 Vertex AI 管道的範例圖表。
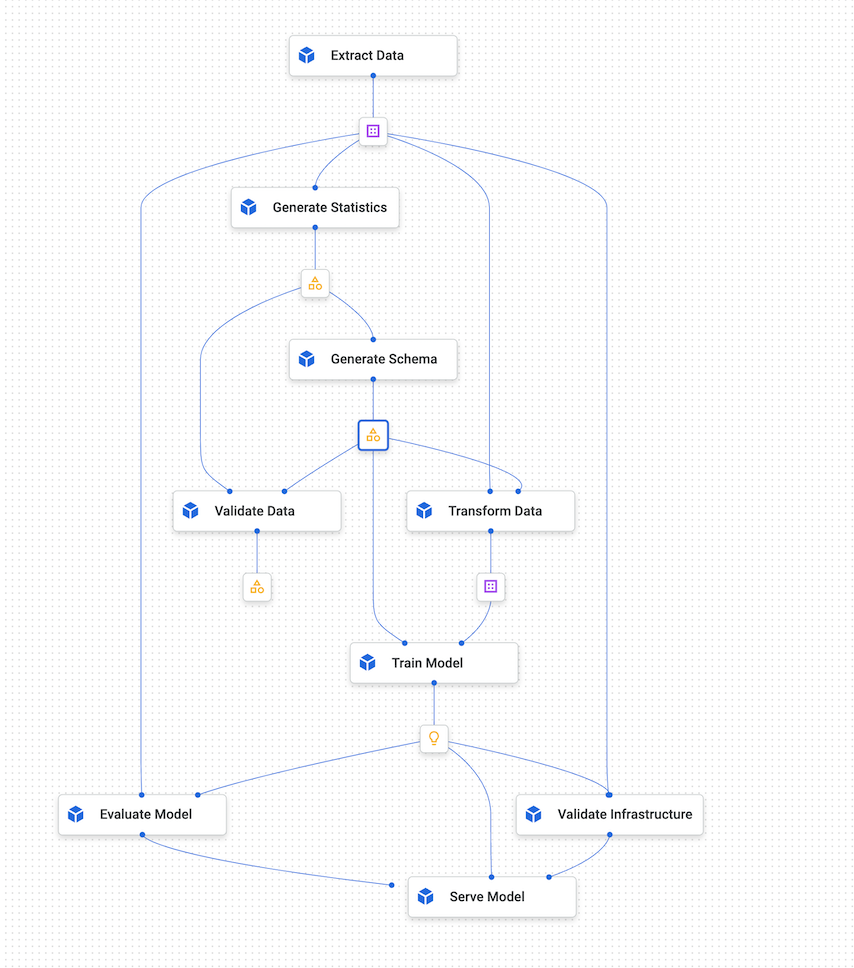
圖 4. Vertex AI Pipelines 的示範圖表。
Kubeflow Pipelines SDK
Kubeflow Pipelines SDK 可讓您建立元件、定義其調度,並將其做為管道執行。如要進一步瞭解 Kubeflow Pipelines 元件,請參閱 Kubeflow 說明文件中的「建立元件」。
您也可以使用 TFX 管道 DSL 和 TFX 元件。TFX 元件會封裝中繼資料功能。驅動程式會透過查詢中繼資料儲存庫,將中繼資料提供給執行程式。發布程式會接收執行程式的結果,並將結果儲存至中繼資料。您也可以實作自訂元件,這類元件與中繼資料的整合方式相同。您可以使用 tfx.orchestration.experimental.KubeflowV2DagRunner,將 TFX 管道編譯為 Vertex AI Pipelines 相容的 YAML。接著,您可以將檔案提交至 Vertex AI Pipelines 執行。
下圖顯示在 Vertex AI Pipelines 中,容器化工作如何叫用其他服務,例如 BigQuery 工作、Vertex AI (分散式) 訓練工作和 Dataflow 工作。

圖 5:Vertex AI Pipelines 會叫用Google Cloud 代管服務。
Vertex AI Pipelines 可讓您執行必要的 Google Cloud 服務,藉此調度管理及自動化生產機器學習管道。在圖 5 中,Vertex ML 中繼資料是 Vertex AI Pipelines 的機器學習中繼資料儲存庫。
管線元件不限於在Google Cloud上執行 TFX 相關服務。這些元件可執行任何與資料和運算相關的服務,包括用於 SparkML 工作的 Dataproc、AutoML 和其他運算工作負載。
在 Vertex AI Pipelines 中將工作容器化,可享有下列優勢:
- 將執行環境與程式碼執行階段分開。
- 在開發環境和實際工作環境之間提供程式碼的可重現性,因為您測試的內容與實際工作環境相同。
- 隔離管道中的每個元件,每個元件可使用不同的執行階段版本、語言和程式庫。
- 協助組合複雜的管道。
- 整合 Vertex 機器學習中繼資料,以便追蹤及重現管道執行作業和構件。
如要全面瞭解 Vertex AI Pipelines,請參閱可用的筆記本範例清單。
觸發及排定 Vertex AI 管道
將管道部署至正式版環境時,您需要視機器學習管道自動化一節所述情境自動執行管道。
Vertex AI SDK 可讓您以程式設計方式操作管道。google.cloud.aiplatform.PipelineJob 類別包含用於建立實驗,以及部署及執行管道的 API。因此,您可以使用 SDK 從其他服務叫用 Vertex AI Pipelines,以便啟用排程器或事件觸發條件。

圖 6. 流程圖,說明使用 Pub/Sub 和 Cloud Run 函式為 Vertex AI 管道建立多個觸發事件。
在圖 6 中,您可以看到如何觸發 Vertex AI Pipelines 服務來執行管道的範例。這個管道會透過 Cloud Run 函式中的 Vertex AI SDK 觸發。Cloud Run 函式本身是 Pub/Sub 的訂閱者,會根據新訊息觸發。任何想要觸發管道執行作業的服務,都可以在對應的 Pub/Sub 主題上發布。上述範例有三項發布服務:
- Cloud Scheduler 會依排程發布訊息,進而觸發管道。
- Cloud Composer 會在更大型的工作流程中發布訊息,例如在 BigQuery 擷取新資料後,觸發訓練管道的資料擷取工作流程。
- Cloud Logging 會根據符合某些篩選條件的記錄發布訊息。您可以設定篩選器,偵測新資料的到達情形,甚至是 Vertex AI Model Monitoring 服務產生的偏差和偏移警示。
在 Google Cloud上設定機器學習 CI/CD
Vertex AI Pipelines 可協調涉及多個步驟的機器學習系統,包括資料預先處理、模型訓練和評估,以及模型部署。在數據科學探索階段,Vertex AI Pipelines 可協助快速實驗整個系統。在實際工作環境階段,Vertex AI Pipelines 可讓您根據新資料自動執行管道,以便訓練或重新訓練機器學習模型。
CI/CD 架構
下圖概略說明使用 Vertex AI Pipelines 進行機器學習的 CI/CD 流程。
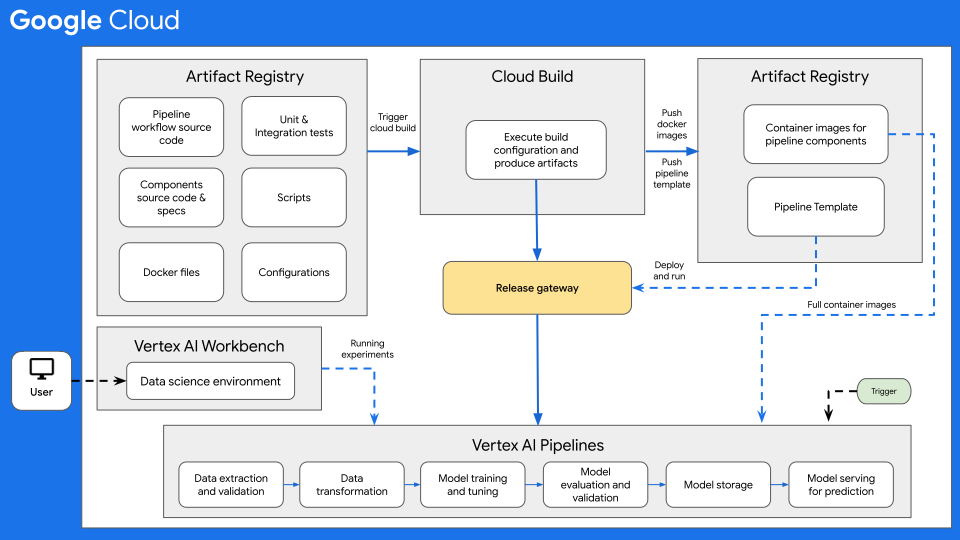
圖 7:使用 Vertex AI Pipelines 進行 CI/CD 的概略說明。
此架構的核心是 Cloud Build。Cloud Build 可從 Artifact Registry、GitHub 或 Bitbucket 匯入原始碼,然後依據您的規格執行建構作業,並產生 Docker 容器或 Python tar 檔案等成果。
Cloud Build 會以一系列建構步驟執行建構作業,這些步驟是在建構設定檔 (cloudbuild.yaml) 中定義。每個建構步驟都會在 Docker 容器中執行。您可以使用 Cloud Build 提供的支援建構步驟,也可以自行撰寫建構步驟。
您可以手動或透過自動化建構觸發條件執行 Cloud Build 程序,為機器學習系統執行必要的 CI/CD。每當變更推送至建構原始碼時,觸發條件都會執行您設定的建構步驟。您可以設定建構觸發條件,在原始碼存放區發生變更時執行建構例行程序,或是只在變更符合特定條件時執行建構例行程序。
此外,您可以讓建構例行作業 (Cloud Build 設定檔) 根據不同的觸發事件執行。舉例來說,您可以設定建構例行作業,在開發分支或主分支中進行提交時觸發。
您可以使用設定變數替代字元來定義建構時間的環境變數。這些替代項目會從觸發的版本擷取。這些變數包括 $COMMIT_SHA、$REPO_NAME、$BRANCH_NAME、$TAG_NAME 和 $REVISION_ID。其他非觸發條件變數為 $PROJECT_ID 和 $BUILD_ID。對於值在建構之前仍未知的變數,或者以不同變數值重複使用現有建構要求而言,substitutions 很實用。
CI/CD 工作流程用途
原始碼存放區通常包含下列項目:
- 定義管道工作流程的 Python 管道工作流程原始碼
- Python 管道元件來源程式碼和對應的元件規格檔案,適用於不同的管道元件,例如資料驗證、資料轉換、模型訓練、模型評估和模型服務。
- 建立 Docker 容器映像檔所需的 Dockerfile,每個管道元件各一個。
- Python 單元和整合測試,用於測試元件和整體管道中實作的各項方法。
- 其他指令碼,包括
cloudbuild.yaml檔案、測試觸發事件和管道部署作業。 - 設定檔 (例如
settings.yaml檔案),包括管道輸入參數的設定。 - 用於探索性資料分析、模型分析和模型互動實驗的筆記本。
在下列範例中,當開發人員從數據科學環境將原始碼推送至開發分支時,系統會觸發建構例行作業。
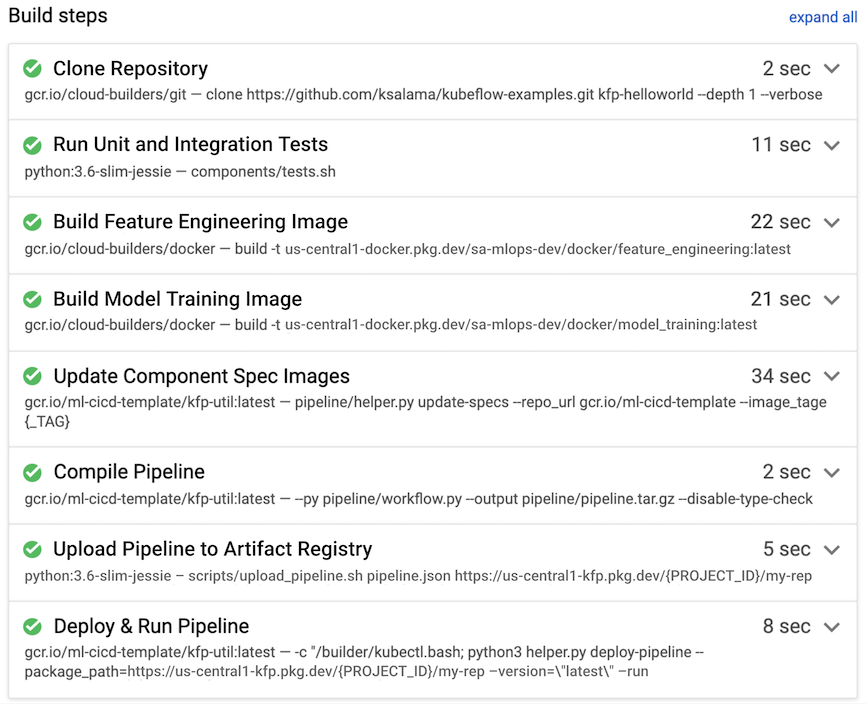
圖 8:Cloud Build 執行的建構步驟範例。
Cloud Build 通常會執行下列建構步驟,如圖 7 所示:
- 原始碼存放區會複製到 Cloud Build 執行階段環境,位於
/workspace目錄下。 - 執行單元和整合測試。
- 選用:使用 Pylint 等分析工具執行靜態程式碼分析。
- 如果測試通過,系統就會建構 Docker 容器映像檔,每個管道元件一個。圖片會加上
$COMMIT_SHA參數。 - Docker 容器映像檔會上傳至 Artifact Registry (如圖 7 所示)。
- 在每個
component.yaml檔案中,映像檔網址會更新為已建立且標記的 Docker 容器映像檔。 - 管道工作流程會編譯,產生
pipeline.json檔案。 pipeline.json檔案會上傳至 Artifact Registry。- 選用:在整合測試或正式執行作業中,使用參數值執行管道。執行的管道會產生新模型,並可將模型部署為 Vertex AI Prediction 上的 API。
如需實際可用於生產環境的端對端機器學習作業範例,包括使用 Cloud Build 的持續整合/持續推送軟體更新管道,請參閱 GitHub 上的 Vertex 管道端對端範例。
其他事項
在 Google Cloud上設定機器學習 CI/CD 架構時,請考量以下事項:
- 在數據資料學環境中,您可以使用本機電腦或 Vertex AI Workbench。
- 您可以設定自動 Cloud Build 管道,略過觸發事件,例如只編輯說明文件檔案,或修改實驗筆記本。
- 您可以將整合和回歸測試的管道,當做為建構測試執行。在管道部署至目標環境之前,您可以使用
wait()方法,等待提交的管道執行作業完成。 - 除了使用 Cloud Build 之外,您也可以使用其他建構系統,例如 Jenkins。您可以在 Google Cloud Marketplace 中找到 Jenkins 的即用部署作業。
- 您可以設定管道,讓管道根據不同的觸發事件自動部署至不同的環境,包括開發、測試和預備環境。此外,您也可以手動部署至特定環境 (例如預先發布或正式發布),通常是在取得發布核准後進行。您可以為不同的觸發事件或目標環境建立多個建構例程。
- 您可以使用 Apache Airflow 這項熱門的自動化調度管理和排程架構,執行通用工作流程,並透過全代管 Cloud Composer 服務執行工作流程。
- 將新版模型部署至實際工作環境時,請以初期測試版本部署,瞭解模型的效能 (CPU、記憶體和磁碟使用量)。在設定新模型以處理所有即時流量之前,您也可以執行 A/B 測試。設定新模型,以便為 10% 至 20% 的即時流量提供服務。如果新模型的成效優於目前的模型,您可以將新模型設為處理所有流量。否則,服務系統會回復至目前的模型。
後續步驟
- 進一步瞭解如何使用 Cloud Build 以 Git 運作方式持續推送軟體更新。
- 如要概略瞭解 Google Cloud中 AI 和機器學習工作負載的架構原則和建議,請參閱「良好架構」架構的AI 和機器學習觀點。
- 如需更多參考架構、圖表和最佳做法,請瀏覽 雲端架構中心。
貢獻者
作者:
- Ross Thomson | 雲端解決方案架構師
- Khalid Salama | 機器學習軟體工程師
其他貢獻者:Wyatt Gorman | HPC 對外產品經理