Caricare i dati di Blob Storage in BigQuery
Puoi caricare i dati da Blob Storage a BigQuery utilizzando il connettore BigQuery Data Transfer Service per Blob Storage. Con BigQuery Data Transfer Service, puoi pianificare job di trasferimento ricorrenti che aggiungono i dati più recenti da Blob Storage a BigQuery.
Prima di iniziare
Prima di creare un trasferimento di dati Blob Storage, procedi nel seguente modo:
- Verifica di aver completato tutte le azioni necessarie per attivare BigQuery Data Transfer Service.
- Scegli un set di dati BigQuery esistente o creane uno nuovo per archiviare i dati.
- Scegli una tabella BigQuery esistente o crea una nuova tabella di destinazione per il trasferimento dei dati e specifica la definizione dello schema. La tabella di destinazione deve rispettare le regole di denominazione delle tabelle. I nomi delle tabelle di destinazione supportano anche i parametri.
- Recupera il nome dell'account di archiviazione Blob Storage, il nome del container, il percorso dei dati (facoltativo) e il token SAS. Per informazioni sulla concessione dell'accesso a Blob Storage utilizzando una firma di accesso condiviso, vedi Firma di accesso condiviso.
- Se limiti l'accesso alle tue risorse Azure utilizzando un firewall Azure Storage, aggiungi i worker di BigQuery Data Transfer Service all'elenco degli indirizzi IP consentiti.
- Se prevedi di specificare una chiave di crittografia gestita dal cliente (CMEK), assicurati che il tuo service account disponga delle autorizzazioni per criptare e decriptare e di disporre dell'ID risorsa chiave Cloud KMS necessario per utilizzare CMEK. Per informazioni su come funziona la CMEK con BigQuery Data Transfer Service, vedi Specifica la chiave di crittografia con i trasferimenti.
Autorizzazioni obbligatorie
Assicurati di aver concesso le seguenti autorizzazioni.
Ruoli BigQuery richiesti
Per ottenere le autorizzazioni
necessarie per creare un trasferimento di dati BigQuery Data Transfer Service,
chiedi all'amministratore di concederti il ruolo IAM
Amministratore BigQuery (roles/bigquery.admin)
nel tuo progetto.
Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Questo ruolo predefinito contiene le autorizzazioni necessarie per creare un trasferimento di dati BigQuery Data Transfer Service. Per vedere quali sono esattamente le autorizzazioni richieste, espandi la sezione Autorizzazioni obbligatorie:
Autorizzazioni obbligatorie
Per creare un trasferimento di dati di BigQuery Data Transfer Service sono necessarie le seguenti autorizzazioni:
-
Autorizzazioni BigQuery Data Transfer Service:
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
Autorizzazioni BigQuery:
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
Potresti anche ottenere queste autorizzazioni con ruoli personalizzati o altri ruoli predefiniti.
Per maggiori informazioni, vedi Concedere l'accesso a bigquery.admin.
Ruoli di Blob Storage obbligatori
Per informazioni sulle autorizzazioni richieste in Blob Storage per attivare il trasferimento dei dati, vedi Firma di accesso condiviso (SAS).
Limitazioni
I trasferimenti di dati di Blob Storage sono soggetti alle seguenti limitazioni:
- L'intervallo di tempo minimo tra i trasferimenti di dati ricorrenti è di 1 ora. L'intervallo predefinito è 24 ore.
- A seconda del formato dei dati di origine di Blob Storage, potrebbero essere presenti limitazioni aggiuntive:
- I trasferimenti di dati alle posizioni BigQuery Omni non sono supportati.
Configura un trasferimento di dati da Blob Storage
Seleziona una delle seguenti opzioni:
Console
Vai alla pagina Trasferimenti di dati nella console Google Cloud .
Fai clic su Crea trasferimento.
Nella pagina Crea repository, segui questi passaggi:
Nella sezione Tipo di origine, per Origine, seleziona Azure Blob Storage e ADLS:
Nella sezione Nome configurazione di trasferimento, per Nome visualizzato, inserisci un nome per il trasferimento di dati.
Nella sezione Opzioni di pianificazione:
- Seleziona una Frequenza di ripetizione. Se selezioni Ore, Giorni, Settimane o Mesi, devi anche specificare una frequenza. Puoi anche selezionare Personalizzata per specificare una frequenza di ripetizione personalizzata. Se selezioni On demand, questo trasferimento di dati viene eseguito quando attivi manualmente il trasferimento.
- Se applicabile, seleziona Inizia ora o Inizia all'ora impostata e fornisci una data di inizio e un'ora di esecuzione.
Nella sezione Impostazioni destinazione, in Set di dati, scegli il set di dati che hai creato per archiviare i dati.
Nella sezione Dettagli origine dati, segui questi passaggi:
- Per Tabella di destinazione, inserisci il nome della tabella che hai creato per archiviare i dati in BigQuery. I nomi delle tabelle di destinazione supportano i parametri.
- Per Nome account Azure Storage, inserisci il nome dell'account Blob Storage.
- Per Nome container, inserisci il nome del container Blob Storage.
- Per Percorso dati, inserisci il percorso per filtrare i file da trasferire. Guarda gli esempi.
- Per Token SAS, inserisci il token SAS di Azure.
- Per Formato file, scegli il formato dei dati di origine.
- Per Disposizione scrittura, seleziona
WRITE_APPENDper aggiungere in modo incrementale i nuovi dati alla tabella di destinazione oWRITE_TRUNCATEper sovrascrivere i dati nella tabella di destinazione durante ogni esecuzione del trasferimento.WRITE_APPENDè il valore predefinito per Disposizione scrittura.
Per saperne di più su come BigQuery Data Transfer Service importa i dati utilizzando
WRITE_APPENDoWRITE_TRUNCATE, consulta Importazione dei dati per i trasferimenti Azure Blob. Per ulteriori informazioni sul campowriteDisposition, vediJobConfigurationLoad.
Nella sezione Opzioni di trasferimento, segui questi passaggi:
- Per Numero di errori consentiti, inserisci un valore intero per il numero massimo di record non validi che possono essere ignorati. Il valore predefinito è 0.
- (Facoltativo) Per Tipi di target decimali, inserisci un elenco separato da virgole dei possibili tipi di dati SQL in cui vengono convertiti i valori decimali nei dati di origine. Il tipo di dati SQL selezionato per la conversione dipende dalle seguenti condizioni:
- Nell'ordine di
NUMERIC,BIGNUMERICeSTRING, un tipo viene scelto se è nell'elenco specificato e se supporta la precisione e la scalabilità. - Se nessuno dei tipi di dati elencati supporta la precisione e la scalabilità, viene selezionato il tipo di dati che supporta l'intervallo più ampio nell'elenco specificato. Se un valore supera l'intervallo supportato durante la lettura dei dati di origine, viene generato un errore.
- Il tipo di dati
STRINGsupporta tutti i valori di precisione e scalabilità. - Se questo campo viene lasciato vuoto, il tipo di dato predefinito sarà
NUMERIC,STRINGper ORC eNUMERICper gli altri formati file. - Questo campo non può contenere tipi di dati duplicati.
- L'ordine dei tipi di dati elencati in questo campo viene ignorato.
- Nell'ordine di
Se hai scelto CSV o JSON come formato file, nella sezione JSON, CSV, seleziona Ignora valori sconosciuti per accettare le righe contenenti valori che non corrispondono allo schema.
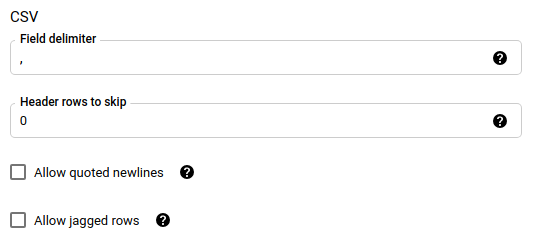
Se hai scelto CSV come formato file, nella sezione CSV inserisci eventuali opzioni CSV aggiuntive per il caricamento dei dati.
Nella sezione Opzioni di notifica, puoi scegliere di abilitare le notifiche via email e le notifiche Pub/Sub.
- Quando abiliti le notifiche via email, l'amministratore del trasferimento riceve una notifica via email quando l'esecuzione di un trasferimento non riesce.
- Quando attivi le notifiche Pub/Sub, scegli un nome per l'argomento in cui pubblicare o fai clic su Crea un argomento per crearne uno.
Se utilizzi le CMEK, nella sezione Opzioni avanzate, seleziona Chiave gestita dal cliente. Viene visualizzato un elenco di CMEK disponibili tra cui scegliere. Per informazioni su come funzionano le CMEK con BigQuery Data Transfer Service, vedi Specificare la chiave di crittografia con i trasferimenti.
Fai clic su Salva.
bq
Utilizza il
comando bq mk --transfer_config
per creare un trasferimento da Blob Storage:
bq mk \ --transfer_config \ --project_id=PROJECT_ID \ --data_source=DATA_SOURCE \ --display_name=DISPLAY_NAME \ --target_dataset=DATASET \ --destination_kms_key=DESTINATION_KEY \ --params=PARAMETERS
Sostituisci quanto segue:
PROJECT_ID: (facoltativo) l'ID progetto contenente il set di dati di destinazione. Se non specificato, viene utilizzato il progetto predefinito.DATA_SOURCE:azure_blob_storage.DISPLAY_NAME: il nome visualizzato per la configurazione del trasferimento dei dati. Il nome del trasferimento può essere qualsiasi valore che ti consenta di identificare il trasferimento se devi modificarlo in un secondo momento.DATASET: il set di dati di destinazione per la configurazione del trasferimento dei dati.DESTINATION_KEY: (facoltativo) l'ID risorsa della chiave Cloud KMS, ad esempioprojects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name.PARAMETERS: i parametri per la configurazione del trasferimento dei dati, elencati in formato JSON. Ad esempio,--params={"param1":"value1", "param2":"value2"}. Di seguito sono riportati i parametri per un trasferimento di dati Blob Storage:destination_table_name_template: obbligatorio. Il nome della tabella di destinazione.storage_account: obbligatorio. Il nome dell'account Blob Storage.container: obbligatorio. Il nome del container Blob Storage.data_path: (Facoltativo) Il percorso per filtrare i file da trasferire. Vedi esempi.sas_token: obbligatorio. Il token SAS di Azure.file_format: (Facoltativo) Il tipo di file che vuoi trasferire:CSV,JSON,AVRO,PARQUEToORC. Il valore predefinito èCSV.write_disposition: (Facoltativo) SelezionaWRITE_APPENDper aggiungere i dati alla tabella di destinazione oWRITE_TRUNCATEper sovrascrivere i dati nella tabella di destinazione. Il valore predefinito èWRITE_APPEND.max_bad_records: (Facoltativo) Il numero di record non validi consentiti. Il valore predefinito è 0.decimal_target_types: (Facoltativo) Un elenco separato da virgole dei possibili tipi di dati SQL in cui vengono convertiti i valori decimali nei dati di origine. Se questo campo non viene fornito, il tipo di dato predefinito saràNUMERIC,STRINGper ORC eNUMERICper gli altri formati file.ignore_unknown_values: (facoltativo) viene ignorato sefile_formatnon èJSONoCSV. Impostatrueper accettare le righe che contengono valori che non corrispondono allo schema.field_delimiter: facoltativo e si applica solo quandofile_formatèCSV. Il carattere che separa i campi. Il valore predefinito è,.skip_leading_rows: facoltativo e si applica solo quandofile_formatèCSV. Indica il numero di righe di intestazione che non vuoi importare. Il valore predefinito è 0.allow_quoted_newlines: facoltativo e si applica solo quandofile_formatèCSV. Indica se consentire i caratteri di fine riga all'interno dei campi tra virgolette.allow_jagged_rows: facoltativo e si applica solo quandofile_formatèCSV. Indica se accettare le righe che non hanno le colonne finali facoltative. I valori mancanti vengono compilati conNULL.
Ad esempio, il seguente comando crea un trasferimento di dati di Blob Storage
denominato mytransfer:
bq mk \ --transfer_config \ --data_source=azure_blob_storage \ --display_name=mytransfer \ --target_dataset=mydataset \ --destination_kms_key=projects/myproject/locations/us/keyRings/mykeyring/cryptoKeys/key1 --params={"destination_table_name_template":"mytable", "storage_account":"myaccount", "container":"mycontainer", "data_path":"myfolder/*.csv", "sas_token":"my_sas_token_value", "file_format":"CSV", "max_bad_records":"1", "ignore_unknown_values":"true", "field_delimiter":"|", "skip_leading_rows":"1", "allow_quoted_newlines":"true", "allow_jagged_rows":"false"}
API
Utilizza il metodo projects.locations.transferConfigs.create e fornisci un'istanza della risorsa TransferConfig.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Specifica la chiave di crittografia con i trasferimenti
Puoi specificare le chiavi di crittografia gestite dal cliente (CMEK) per criptare i dati per un'esecuzione del trasferimento. Puoi utilizzare una chiave CMEK per supportare i trasferimenti da Azure Blob Storage.Quando specifichi una CMEK con un trasferimento, BigQuery Data Transfer Service la applica a qualsiasi cache su disco intermedia dei dati importati, in modo che l'intero flusso di lavoro di trasferimento dei dati sia conforme alla CMEK.
Non puoi aggiornare un trasferimento esistente per aggiungere una chiave CMEK se il trasferimento non è stato originariamente creato con una chiave CMEK. Ad esempio, non puoi modificare una tabella di destinazione che originariamente era criptata per impostazione predefinita in modo che ora sia criptata con CMEK. Al contrario, non puoi modificare una tabella di destinazione criptata con CMEK in modo che abbia un tipo di crittografia diverso.
Puoi aggiornare una CMEK per un trasferimento se la configurazione del trasferimento è stata originariamente creata con una crittografia CMEK. Quando aggiorni una CMEK per una configurazione di trasferimento, BigQuery Data Transfer Service la propaga alle tabelle di destinazione alla successiva esecuzione del trasferimento, durante la quale BigQuery Data Transfer Service sostituisce le CMEK obsolete con la nuova CMEK. Per saperne di più, vedi Aggiornare un trasferimento.
Puoi anche utilizzare le chiavi predefinite del progetto. Quando specifichi una chiave predefinita del progetto con un trasferimento, BigQuery Data Transfer Service utilizza la chiave predefinita del progetto come chiave predefinita per qualsiasi nuova configurazione di trasferimento.
Risolvere i problemi di configurazione del trasferimento
Se riscontri problemi durante la configurazione del trasferimento dei dati, consulta Problemi di trasferimento di Blob Storage.
Passaggi successivi
- Scopri di più sui parametri di runtime nei trasferimenti.
- Scopri di più su BigQuery Data Transfer Service.
- Scopri come caricare i dati con operazioni cross-cloud.