Cross-region dataset replication
With BigQuery dataset replication, you can set up automatic replication of a dataset between two different regions or multi-regions.
Overview
When you create a dataset in BigQuery, you select the region or multi-region where the data is stored. A region is a collection of data centers within a geographical area, and a multi-region is a large geographic area that contains two or more geographic regions. Your data is stored in one of the contained regions, and is not replicated within the multi-region. For more information about regions and multi-regions, see BigQuery locations.
BigQuery always stores copies of your data in two different Google Cloud zones within the dataset location. A zone is a deployment area for Google Cloud resources within a region. In all regions, replication between zones uses synchronous dual writes. Selecting a multi-region location does not provide cross-region replication or regional redundancy, so there is no increase in dataset availability in the event of a regional outage. Data is stored in a single region within the geographic location.
For additional geo-redundancy, you can replicate any dataset. BigQuery creates a secondary replica of the dataset, located in another region that you specify. This replica is then asynchronously replicated between two zones with the other region, for a total of four zonal copies.
Dataset replication
If you replicate a dataset, BigQuery stores the data in the region that you specify.
Primary region. When you first create a dataset, BigQuery places the dataset in the primary region.
Secondary region. When you add a dataset replica, BigQuery places the replica in the secondary region.
Initially, the replica in the primary region is the primary replica, and the replica in the secondary region is the secondary replica.
The primary replica is writeable, and the secondary replica is read-only. Writes to the primary replica are asynchronously replicated to the secondary replica. Within each region, the data is stored redundantly in two zones. Network traffic never leaves the Google Cloud network.
The following diagram shows the replication that occurs when a dataset is replicated:
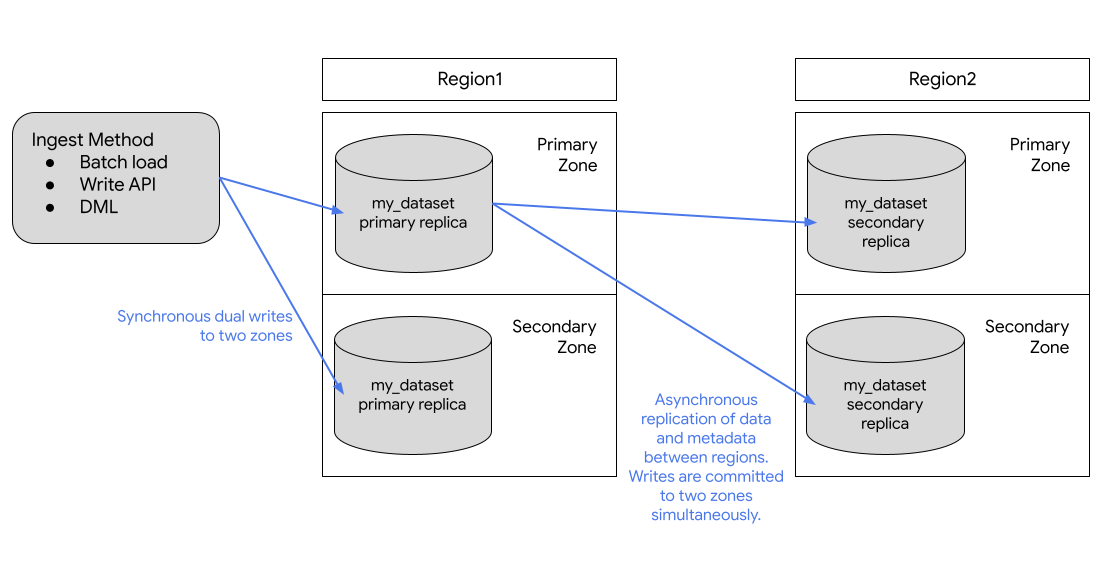
If the primary region is online, you can manually switch to the secondary replica. For more information, see Promote the secondary replica.
Pricing
You are billed for the following for replicated datasets:
- Storage. Storage bytes in the secondary region are billed as a separate copy in the secondary region. See BigQuery storage pricing.
- Data replication. For more information on how you are billed for data replication, see Data replication pricing.
Data replication is managed by BigQuery and doesn't use your slot resources. You are billed for data replication separately.
Compute capacity in the secondary region
To run jobs and queries against the replica in the secondary region, you must purchase slots within the secondary region or run an on-demand query.
You can use the slots to perform read-only queries from the secondary replica. If you promote the secondary replica to be the primary, you can also use those slots to write to the replica.
You can purchase the same number of slots as you have in the primary region, or a different number of slots. If you purchase fewer slots, it might affect query performance.
Location considerations
Before adding a dataset replica, you need to create the initial dataset you want to replicate in BigQuery if it doesn't exist already. The location of the added replica is set to the location that you specify when adding the replica. The location of the added replica must be different from the location of the initial dataset. This means that the data in your dataset is continually replicated between the location the dataset was created in and the location of the replica. For replicas that require colocation, such as views, materialized views, or non-BigLake external tables, adding a replica in a location that is different from, or not compatible with, your source data's location could result in job errors.
When customers replicate a dataset across regions, BigQuery ensures data is located only in the locations where the replicas were created.
Colocation requirements
Using dataset replication is dependent on the following colocation requirements.
Cloud Storage
Querying data on Cloud Storage requires that the Cloud Storage bucket is colocated with the replica. Use the external tables location considerations when deciding where to place your replica.
Limitations
BigQuery dataset replication is subject to the following limitations:
- Streaming data written to the primary replica from the
BigQuery Storage Write API or the
tabledata.insertAllmethod, which is then replicated into the secondary replica, is best-effort and may see high replication delay. - Streaming upserts written to the primary replica from
Datastream or
BigQuery change data capture,
which is then replicated into the secondary replica, is best-effort and may
see high replication delay. Once replicated, the upserts in the secondary
replica are merged into the secondary replica's table baseline as per the
table's configured
max_stalenessvalue. - You can't enable fine-grained DML on a table in a replicated dataset, and you can't replicate a dataset that contains a table with fine-grained DML enabled.
- Replication and switchover are managed through SQL data definition language (DDL) statements.
- You are limited to one replica of each dataset for each region or multi-region. You cannot create two secondary replicas of the same dataset in the same destination region.
- Resources within replicas are subject to the limitations as described in Resource behavior.
- Policy tags and associated data policies are not replicated to the secondary replica. Any queries that reference columns with policy tags in regions other than the original region fail, even if that replica is promoted.
- Time travel is only available in the secondary replica after the creation of the secondary replica is completed.
- The destination region size limit for enabling cross-region replication
on a dataset is 10 PB for
usandeumulti-regions and 500 TB for other regions by default. These limits are configurable. For more information, reach out to Google Cloud Support. - The quota applies to logical resources.
- You can only replicate a dataset with fewer than 100,000 tables.
- You are limited to a maximum of 4 replicas added (then dropped) to the same region per dataset per day.
- You are limited by bandwidth.
- Tables with Customer-managed encryption
keys (CMEK) applied are not
queryable in the secondary region if the
replica_kms_keyvalue is not configured. - BigLake tables are not supported.
- You can't replicate external or federated datasets.
- BigQuery Omni locations aren't supported.
- You can't configure the following region pairs if you are configuring data replication for disaster recovery:
us-central1-usmulti-regionus-west1-usmulti-regioneu-west1-eumulti-regioneu-west4-eumulti-region
- Routine-level access controls can't be replicated, but you can replicate dataset-level access controls for routines.
- The following behavior applies to search indexes:
- Only the search index metadata is replicated to the secondary region, not index data itself.
- If you switch over to the replica, then your index is deleted from the previous primary region and regenerated in the promoted region.
- If you switch back and forth within 8 hours, then your index generation is delayed by 8 hours.
Resource behavior
The following operations are not supported on resources within the secondary replica:
The secondary replica is read-only. If you need to create a copy of a resource in a secondary replica, you must either copy the resource or query the resource first, and then materialize the results outside of the secondary replica. For example, use CREATE TABLE AS SELECT to create a new resource from the secondary replica resource.
Primary and secondary replicas are subject to the following differences:
| Region 1 primary replica | Region 2 secondary replica | Notes |
|---|---|---|
| BigLake table | BigLake table | Not supported. |
| External table | External table | Only the external table definition is replicated. The query fails when the Cloud Storage bucket is not co-located in the same location as a replica. |
| Logical view | Logical view | Logical views that reference a dataset or resource that is not located in the same location as the logical view fail when queried. |
| Managed table | Managed table | No difference. |
| Materialized view | Materialized view | If a referenced table is not in the same region as the materialized view, the query fails. Replicated materialized views may see staleness above the view's max staleness. |
| Model | Model | Stored as managed tables. |
| Remote function | Remote function | Connections are regional. Remote functions that reference a dataset or resource (connection) that is not located in the same location as the remote function fail when run. |
| Routines | User-defined function (UDF) or stored procedure | Routines that reference a dataset or resource that is not located in the same location as the routine fail when run. Any routine that references a connection, such as remote functions, does not work outside the source region. |
| Row Access Policy | Row Access Policy | No difference. |
| Search index | Search index | Only index metadata is replicated. Index data only exists in primary region. |
| Stored procedure | Stored procedure | Stored procedures that reference a dataset or resource that is not located in the same location as the stored procedure fail when run. |
| Table clone | Managed table | Billed as a deep copy in secondary replica. |
| Table snapshot | Table snapshot | Billed as a deep copy in secondary replica. |
| Table-valued function (TVF) | TVF | TVFs that reference a dataset or resource that is not located in the same location as the TVF fail when run. |
| UDF | UDF | UDFs that reference a dataset or resource that is not located in the same location as the UDF fail when run. |
Outage scenarios
Cross-region replication is not intended for use as a disaster recovery plan during a total-region outage. In the case of a total region outage in the primary replica's region, you cannot promote the secondary replica. Because secondary replicas are read-only, you can't run any write jobs on the secondary replica and can't promote the secondary region until the primary replica's region is restored. For more information about preparing for disaster recovery, see Managed disaster recovery.
The following table explains the impact of total-region outages on your replicated data:
| Region 1 | Region 2 | Outage region | Impact |
|---|---|---|---|
| Primary replica | Secondary replica | Region 2 | Read-only jobs running in region 2 against the secondary replica fail. |
| Primary replica | Secondary replica | Region 1 | All jobs running in region 1 fail. Read-only jobs continue to run in region 2 where the secondary replica is located. The contents of region 2 are stale until it is successfully synced with region 1. |
Use dataset replication
This section describes how to replicate a dataset, promote the secondary replica, and run BigQuery read jobs in the secondary region.
Required permissions
To get the permissions that you need to manage replicas, ask your administrator
to grant you bigquery.datasets.update permission.
Replicate a dataset
To replicate a dataset, use the
ALTER SCHEMA ADD REPLICA DDL statement.
You can add a replica to any dataset that's located in a region or multi-region that is not already replicated in that region or multi-region. After you add a replica, it takes time for the initial copy operation to complete. You can still run queries referencing the primary replica while the data is being replicated, with no reduction in query processing capacity. You can't replicate data within the geo-locations within a multi-region.
The following example creates a dataset named my_dataset in the us-central1
region and then adds a replica in the us-east4 region:
-- Create the primary replica in the us-central1 region. CREATE SCHEMA my_dataset OPTIONS(location='us-central1'); -- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `my_replica` OPTIONS(location='us-east4');
To confirm when the secondary replica has successfully been created, you can
query the creation_complete column in the
INFORMATION_SCHEMA.SCHEMATA_REPLICAS
view.
After the secondary replica has been created, you can query it by explicitly setting the location of the query to the secondary region. If a location is not explicitly set, BigQuery uses the region of the primary replica of the dataset.
Promote the secondary replica
If the primary region is online, you can promote the secondary replica. Promotion switches the secondary replica to be the writeable primary. This operation completes within a few seconds if the secondary replica is caught up with the primary replica. If the secondary replica is not caught up, the promotion can't complete until it is caught up. The secondary replica can't be promoted to the primary if the region containing the primary has an outage.
Note the following:
- All writes to tables return errors while promotion is in process. The old primary replica becomes non-writable immediately when the promotion begins.
- Tables that aren't fully replicated at the time the promotion is initiated return stale reads.
To promote a replica to be the primary replica, use the ALTER SCHEMA SET
OPTIONS DDL
statement
and set the primary_replica option.
Note the following: - You must explicitly set the job location to the secondary region in query settings. See BigQuery specify locations.
The following example promotes the us-east4 replica to be the primary:
ALTER SCHEMA my_dataset SET OPTIONS(primary_replica = 'us-east4')
To confirm when the secondary replica has successfully been promoted, you can
query the replica_primary_assignment_complete column in the
INFORMATION_SCHEMA.SCHEMATA_REPLICAS
view.
Remove a dataset replica
To remove a replica and stop replicating the dataset, use the
ALTER SCHEMA DROP REPLICA DDL statement.
The following example removes the us replica:
ALTER SCHEMA my_dataset DROP REPLICA IF EXISTS `us`;
You must first drop any secondary replicas to delete the entire dataset. If you
delete the entire dataset—for example, by using the DROP
SCHEMAstatement—without
dropping all secondary replicas, you receive the following error:
The dataset replica of the cross region dataset 'project_id:dataset_id' in region 'REGION' is not yet writable because the primary assignment is not yet complete.
For more information, see Promote the secondary replica.
List dataset replicas
To list the dataset replicas in a project, query the
INFORMATION_SCHEMA.SCHEMATA_REPLICAS
view.
Migrate datasets
You can use cross-region dataset replication to migrate your datasets from one
region to another. The following example demonstrates the process of migrating
the existing my_migration dataset from the US multi-region to the EU
multi-region using cross-region replication.
Replicate the dataset
To begin the migration process, first replicate the dataset in the region that you
want to migrate the data to. In this scenario, you are migrating the
my_migration dataset to the EU multi-region.
-- Create a replica in the secondary region. ALTER SCHEMA my_migration ADD REPLICA `eu` OPTIONS(location='eu');
This creates a secondary replica named eu in the EU multi-region.
The primary replica is the my_migration dataset in the US multi-region.
Promote the secondary replica
To continue migrating the dataset to the EU multi-region, promote the
secondary replica:
ALTER SCHEMA my_migration SET OPTIONS(primary_replica = 'eu')
After the promotion is complete, eu is the primary replica. It is a writable
replica.
Complete the migration
To complete the migration from the US multi-region to the EU multi-region,
delete the us replica. This step is not required but is useful if you don't
need a dataset replica beyond your migration needs.
ALTER SCHEMA my_migration DROP REPLICA IF EXISTS us;
Your dataset is located in the EU multi-region and there are no replicas of
the my_migration dataset. You have successfully migrated your dataset to the
EU multi-region. The complete list of resources that are migrated can be found
in Resource behavior.
Customer-managed encryption keys (CMEK)
Customer-managed Cloud Key Management Service keys
are not automatically replicated when you create a secondary replica. In order
to maintain the encryption on your replicated dataset, you must set the
replica_kms_key for the location of the added replica. You can set the
replica_kms_key using the ALTER SCHEMA ADD REPLICA DDL
statement.
Replicating datasets with CMEK behaves as described in the following scenarios:
If the source dataset has a
default_kms_key, you must provide areplica_kms_keythat was created in the replica dataset's region when using theALTER SCHEMA ADD REPLICADDL statement.If the source dataset doesn't have a value set for
default_kms_key, you can't set thereplica_kms_key.If you are using Cloud KMS key rotation on either (or both) of the
default_kms_keyor thereplica_kms_keythe replicated dataset is still queryable after the key rotation.- Key rotation in the primary region updates the key version only in tables created after the rotation, tables that existed prior to the key rotation still use the key version that was set prior to the rotation.
- Key rotation in the secondary region updates all tables in the secondary replica to the new key version.
- Switching the primary replica to secondary replica updates all tables in the secondary replica (formerly the primary replica) to the new key version.
- If the key version set on tables in the primary replica prior to key rotation is deleted, any tables still using the key version set prior to key rotation cannot be queried until the key version is updated. In order to update the key version, the old key version must be active (not disabled or deleted).
If the source dataset doesn't have a value set for
default_kms_key, but there are individual tables in the source dataset with CMEK applied, those tables aren't queryable in the replicated dataset. To query the tables, do the following:- Add a
default_kms_keyvalue for the source dataset. - When you create a
new replica using the
ALTER SCHEMA ADD REPLICADDL statement, set a value for thereplica_kms_keyoption. The CMEK tables are queryable in the destination region.
All the CMEK tables in the destination region use the same
replica_kms_key, regardless of the key used in the source region.- Add a
Create a replica with CMEK
The following example creates a replica in the us-west1 region with a
replica_kms_key value set. For CMEK key, grant the
BigQuery service account permission
to encrypt and decrypt.
-- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `us-west1` OPTIONS(location='us-west1', replica_kms_key='my_us_west1_kms_key_name');
CMEK limitations
Replicating datasets with CMEK applied are subject to the following limitations:
You can't update the replicated Cloud KMS key after the replica is created.
You can't update the
default_kms_keyvalue on the source dataset after the dataset replicas have been created.If the provided
replica_kms_keyis not valid in the destination region, the dataset won't be replicated.
What's next
- Learn how to work with BigQuery reservations.
- Learn about BigQuery reliability features.