Migrate schema and data from Amazon Redshift
This document describes the process of migrating data from Amazon Redshift to BigQuery using public IP addresses.
You can use the BigQuery Data Transfer Service to copy your data from an Amazon Redshift data warehouse to BigQuery. The service engages migration agents in GKE and triggers an unload operation from Amazon Redshift to a staging area in an Amazon S3 bucket. Then the BigQuery Data Transfer Service transfers your data from the Amazon S3 bucket to BigQuery.
This diagram shows the overall flow of data between an Amazon Redshift data warehouse and BigQuery during a migration.
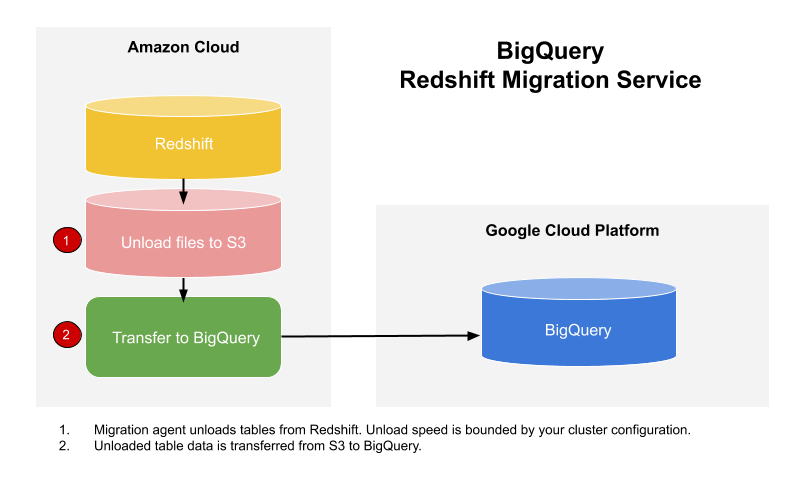
If you'd like to transfer data from your Amazon Redshift instance through a virtual private cloud (VPC) using private IP addresses, see Migrating Amazon Redshift data with VPC.
Before you begin
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and BigQuery Data Transfer Service APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and BigQuery Data Transfer Service APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Set required permissions
Before creating an Amazon Redshift transfer:
Ensure that the principal creating the transfer has the following permissions in the project containing the transfer job:
bigquery.transfers.updatepermissions to create the transfer- Both
bigquery.datasets.getandbigquery.datasets.updatepermissions on the target dataset
The
roles/bigquery.adminpredefined Identity and Access Management (IAM) role includesbigquery.transfers.update,bigquery.datasets.updateandbigquery.datasets.getpermissions. For more information on IAM roles in BigQuery Data Transfer Service, see Access control.Consult the documentation for Amazon S3 to ensure you have configured any permissions necessary to enable the transfer. At a minimum, the Amazon S3 source data must have the AWS managed policy
AmazonS3ReadOnlyAccessapplied to it.
Create a dataset
Create a BigQuery dataset to store your data. You do not need to create any tables.
Grant access to your Amazon Redshift cluster
Add the following IP ranges of your private Amazon Redshift cluster to an allowlist by configuring the security group rules. You can allowlist the IP addresses that correspond to your dataset's location, or you can allowlist all of the IP addresses in the table below. These Google-owned IP addresses are reserved for Amazon Redshift data migrations.
Regional locations
| Region description | Region name | IP addresses | |
|---|---|---|---|
| Americas | |||
| Columbus, Ohio | us-east5 |
34.162.72.184 34.162.173.185 34.162.205.205 34.162.81.45 34.162.182.149 34.162.59.92 34.162.157.190 34.162.191.145 |
|
| Dallas | us-south1 |
34.174.172.89 34.174.40.67 34.174.5.11 34.174.96.109 34.174.148.99 34.174.176.19 34.174.253.135 34.174.129.163 |
|
| Iowa | us-central1 |
34.121.70.114 34.71.81.17 34.122.223.84 34.121.145.212 35.232.1.105 35.202.145.227 35.226.82.216 35.225.241.102 |
|
| Las Vegas | us-west4 |
34.125.53.201 34.125.69.174 34.125.159.85 34.125.152.1 34.125.195.166 34.125.50.249 34.125.68.55 34.125.91.116 |
|
| Los Angeles | us-west2 |
35.236.59.167 34.94.132.139 34.94.207.21 34.94.81.187 34.94.88.122 35.235.101.187 34.94.238.66 34.94.195.77 |
|
| Mexico | northamerica-south1 |
34.51.6.35 34.51.7.113 34.51.12.83 34.51.10.94 34.51.11.219 34.51.11.52 34.51.2.114 34.51.15.251 |
|
| Montréal | northamerica-northeast1 |
34.95.20.253 35.203.31.219 34.95.22.233 34.95.27.99 35.203.12.23 35.203.39.46 35.203.116.49 35.203.104.223 |
|
| Northern Virginia | us-east4 |
35.245.95.250 35.245.126.228 35.236.225.172 35.245.86.140 35.199.31.35 35.199.19.115 35.230.167.48 35.245.128.132 35.245.111.126 35.236.209.21 |
|
| Oregon | us-west1 |
35.197.117.207 35.199.178.12 35.197.86.233 34.82.155.140 35.247.28.48 35.247.31.246 35.247.106.13 34.105.85.54 |
|
| Salt Lake City | us-west3 |
34.106.37.58 34.106.85.113 34.106.28.153 34.106.64.121 34.106.246.131 34.106.56.150 34.106.41.31 34.106.182.92 |
|
| São Paolo | southamerica-east1 |
35.199.88.228 34.95.169.140 35.198.53.30 34.95.144.215 35.247.250.120 35.247.255.158 34.95.231.121 35.198.8.157 |
|
| Santiago | southamerica-west1 |
34.176.188.48 34.176.38.192 34.176.205.134 34.176.102.161 34.176.197.198 34.176.223.236 34.176.47.188 34.176.14.80 |
|
| South Carolina | us-east1 |
35.196.207.183 35.237.231.98 104.196.102.222 35.231.13.201 34.75.129.215 34.75.127.9 35.229.36.137 35.237.91.139 |
|
| Toronto | northamerica-northeast2 |
34.124.116.108 34.124.116.107 34.124.116.102 34.124.116.80 34.124.116.72 34.124.116.85 34.124.116.20 34.124.116.68 |
|
| Europe | |||
| Belgium | europe-west1 |
35.240.36.149 35.205.171.56 34.76.234.4 35.205.38.234 34.77.237.73 35.195.107.238 35.195.52.87 34.76.102.189 |
|
| Berlin | europe-west10 |
34.32.28.80 34.32.31.206 34.32.19.49 34.32.33.71 34.32.15.174 34.32.23.7 34.32.1.208 34.32.8.3 |
|
| Finland | europe-north1 |
35.228.35.94 35.228.183.156 35.228.211.18 35.228.146.84 35.228.103.114 35.228.53.184 35.228.203.85 35.228.183.138 |
|
| Frankfurt | europe-west3 |
35.246.153.144 35.198.80.78 35.246.181.106 35.246.211.135 34.89.165.108 35.198.68.187 35.242.223.6 34.89.137.180 |
|
| London | europe-west2 |
35.189.119.113 35.189.101.107 35.189.69.131 35.197.205.93 35.189.121.178 35.189.121.41 35.189.85.30 35.197.195.192 |
|
| Madrid | europe-southwest1 |
34.175.99.115 34.175.186.237 34.175.39.130 34.175.135.49 34.175.1.49 34.175.95.94 34.175.102.118 34.175.166.114 |
|
| Milan | europe-west8 |
34.154.183.149 34.154.40.104 34.154.59.51 34.154.86.2 34.154.182.20 34.154.127.144 34.154.201.251 34.154.0.104 |
|
| Netherlands | europe-west4 |
35.204.237.173 35.204.18.163 34.91.86.224 34.90.184.136 34.91.115.67 34.90.218.6 34.91.147.143 34.91.253.1 |
|
| Paris | europe-west9 |
34.163.76.229 34.163.153.68 34.155.181.30 34.155.85.234 34.155.230.192 34.155.175.220 34.163.68.177 34.163.157.151 |
|
| Stockholm | europe-north2 |
34.51.133.48 34.51.136.177 34.51.128.140 34.51.141.252 34.51.139.127 34.51.142.55 34.51.134.218 34.51.138.9 |
|
| Turin | europe-west12 |
34.17.15.186 34.17.44.123 34.17.41.160 34.17.47.82 34.17.43.109 34.17.38.236 34.17.34.223 34.17.16.47 |
|
| Warsaw | europe-central2 |
34.118.72.8 34.118.45.245 34.118.69.169 34.116.244.189 34.116.170.150 34.118.97.148 34.116.148.164 34.116.168.127 |
|
| Zürich | europe-west6 |
34.65.205.160 34.65.121.140 34.65.196.143 34.65.9.133 34.65.156.193 34.65.216.124 34.65.233.83 34.65.168.250 |
|
| Asia Pacific | |||
| Delhi | asia-south2 |
34.126.212.96 34.126.212.85 34.126.208.224 34.126.212.94 34.126.208.226 34.126.212.232 34.126.212.93 34.126.212.206 |
|
| Hong Kong | asia-east2 |
34.92.245.180 35.241.116.105 35.220.240.216 35.220.188.244 34.92.196.78 34.92.165.209 35.220.193.228 34.96.153.178 |
|
| Jakarta | asia-southeast2 |
34.101.79.105 34.101.129.32 34.101.244.197 34.101.100.180 34.101.109.205 34.101.185.189 34.101.179.27 34.101.197.251 |
|
| Melbourne | australia-southeast2 |
34.126.196.95 34.126.196.106 34.126.196.126 34.126.196.96 34.126.196.112 34.126.196.99 34.126.196.76 34.126.196.68 |
|
| Mumbai | asia-south1 |
34.93.67.112 35.244.0.1 35.200.245.13 35.200.203.161 34.93.209.130 34.93.120.224 35.244.10.12 35.200.186.100 |
|
| Osaka | asia-northeast2 |
34.97.94.51 34.97.118.176 34.97.63.76 34.97.159.156 34.97.113.218 34.97.4.108 34.97.119.140 34.97.30.191 |
|
| Seoul | asia-northeast3 |
34.64.152.215 34.64.140.241 34.64.133.199 34.64.174.192 34.64.145.219 34.64.136.56 34.64.247.158 34.64.135.220 |
|
| Singapore | asia-southeast1 |
34.87.12.235 34.87.63.5 34.87.91.51 35.198.197.191 35.240.253.175 35.247.165.193 35.247.181.82 35.247.189.103 |
|
| Sydney | australia-southeast1 |
35.189.33.150 35.189.38.5 35.189.29.88 35.189.22.179 35.189.20.163 35.189.29.83 35.189.31.141 35.189.14.219 |
|
| Taiwan | asia-east1 |
35.221.201.20 35.194.177.253 34.80.17.79 34.80.178.20 34.80.174.198 35.201.132.11 35.201.223.177 35.229.251.28 35.185.155.147 35.194.232.172 |
|
| Tokyo | asia-northeast1 |
34.85.11.246 34.85.30.58 34.85.8.125 34.85.38.59 34.85.31.67 34.85.36.143 34.85.32.222 34.85.18.128 34.85.23.202 34.85.35.192 |
|
| Middle East | |||
| Dammam | me-central2 |
34.166.20.177 34.166.10.104 34.166.21.128 34.166.19.184 34.166.20.83 34.166.18.138 34.166.18.48 34.166.23.171 |
|
| Doha | me-central1 |
34.18.48.121 34.18.25.208 34.18.38.183 34.18.33.25 34.18.21.203 34.18.21.80 34.18.36.126 34.18.23.252 |
|
| Tel Aviv | me-west1 |
34.165.184.115 34.165.110.74 34.165.174.16 34.165.28.235 34.165.170.172 34.165.187.98 34.165.85.64 34.165.245.97 |
|
| Africa | |||
| Johannesburg | africa-south1 |
34.35.11.24 34.35.10.66 34.35.8.32 34.35.3.248 34.35.2.113 34.35.5.61 34.35.7.53 34.35.3.17 |
|
Multi-regional locations
| Multi-region description | Multi-region name | IP addresses |
|---|---|---|
| Data centers within member states of the European Union1 | EU |
34.76.156.158 34.76.156.172 34.76.136.146 34.76.1.29 34.76.156.232 34.76.156.81 34.76.156.246 34.76.102.206 34.76.129.246 34.76.121.168 |
| Data centers in the United States | US |
35.185.196.212 35.197.102.120 35.185.224.10 35.185.228.170 35.197.5.235 35.185.206.139 35.197.67.234 35.197.38.65 35.185.202.229 35.185.200.120 |
1 Data located in the EU multi-region is not
stored in the europe-west2 (London) or europe-west6 (Zürich) data
centers.
Grant access to your Amazon S3 bucket
You must have an Amazon S3 bucket to use as a staging area to transfer the Amazon Redshift data to BigQuery. For detailed instructions, see the Amazon documentation.
We recommended that you create a dedicated Amazon IAM user, and grant that user only Read access to Amazon Redshift and Read and Write access to Amazon S3. To achieve this step, you can apply the following policies:

Create an Amazon IAM user access key pair.
Configure workload control with a separate migration queue
Optionally, you can define an Amazon Redshift queue for migration purposes to limit and separate the resources used for migration. You can configure this migration queue with a maximum concurrency query count. You can then associate a certain migration user group with the queue and use those credentials when setting up the migration to transfer data to BigQuery. The transfer service only has access to the migration queue.
Gather transfer information
Gather the information that you need to set up the migration with the BigQuery Data Transfer Service:
- Follow these instructions to get the JDBC URL.
- Get the username and password of a user with appropriate permissions to your Amazon Redshift database.
- Follow the instructions at Grant access to your Amazon S3 bucket to get an AWS access key pair.
- Get the URI of the Amazon S3 bucket you want to use for the transfer. We recommend that you set up a Lifecycle policy for this bucket to avoid unnecessary charges. The recommended expiration time is 24 hours to allow sufficient time to transfer all data to BigQuery.
Assess your data
As part of the data transfer, BigQuery Data Transfer Service writes data from Amazon Redshift to Cloud Storage as CSV files. If these files contain the ASCII 0 character, they can't be loaded into BigQuery. We suggest you assess your data to determine if this could be an issue for you. If it is, you can work around this by exporting your data to Amazon S3 as Parquet files, and then importing those files by using BigQuery Data Transfer Service. For more information, see Overview of Amazon S3 transfers.
Set up an Amazon Redshift transfer
Select one of the following options:
Console
In the Google Cloud console, go to the BigQuery page.
Click Data transfers.
Click Create transfer.
In the Source type section, select Migration: Amazon Redshift from the Source list.
In the Transfer config name section, enter a name for the transfer, such as
My migration, in the Display name field. The display name can be any value that allows you to easily identify the transfer if you need to modify it later.In the Destination settings section, choose the dataset you created from the Dataset list.
In the Data source details section, do the following:
- For JDBC connection url for Amazon Redshift, provide the JDBC URL to access your Amazon Redshift cluster.
- For Username of your database, enter the username for the Amazon Redshift database that you want to migrate.
For Password of your database, enter the database password.
For Access key ID and Secret access key, enter the access key pair you obtained from Grant access to your S3 bucket.
For Amazon S3 URI, enter the URI of the S3 bucket you'll use as a staging area.
For Amazon Redshift Schema, enter the Amazon Redshift schema you're migrating.
For Table name patterns, specify a name or a pattern for matching the table names in the schema. You can use regular expressions to specify the pattern in the form:
<table1Regex>;<table2Regex>. The pattern should follow Java regular expression syntax. For example:lineitem;ordertbmatches tables that are namedlineitemandordertb..*matches all tables.
Leave this field empty to migrate all tables from the specified schema.
For VPC and the reserved IP range, leave the field blank.
In the Service Account menu, select a service account from the service accounts associated with your Google Cloud project. You can associate a service account with your transfer instead of using your user credentials. For more information about using service accounts with data transfers, see Use service accounts.
- If you signed in with a federated identity, then a service account is required to create a transfer. If you signed in with a Google Account, then a service account for the transfer is optional.
- The service account must have the required permissions.
Optional: In the Notification options section, do the following:
- Click the toggle to enable email notifications. When you enable this option, the transfer administrator receives an email notification when a transfer run fails.
- For Select a Pub/Sub topic, choose your topic name or click Create a topic. This option configures Pub/Sub run notifications for your transfer.
Click Save.
The Google Cloud console displays all the transfer setup details, including a Resource name for this transfer.
bq
Enter the bq mk command and supply the transfer creation flag
--transfer_config. The following flags are also required:
--project_id--data_source--target_dataset--display_name--params
bq mk \ --transfer_config \ --project_id=project_id \ --data_source=data_source \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters'
Where:
- project_id is your Google Cloud project ID. If
--project_idisn't specified, the default project is used. - data_source is the data source:
redshift. - dataset is the BigQuery target dataset for the transfer configuration.
- name is the display name for the transfer configuration. The transfer name can be any value that lets you identify the transfer if you need to modify it later.
- service_account: is the service account name used to
authenticate your transfer. The service account should
be owned by the same
project_idused to create the transfer and it should have all of the required permissions. - parameters contains the parameters for the created transfer
configuration in JSON format. For example:
--params='{"param":"param_value"}'.
Parameters required for an Amazon Redshift transfer configuration are:
jdbc_url: The JDBC connection URL is used to locate the Amazon Redshift cluster.database_username: The username to access your database to unload specified tables.database_password: The password used with the username to access your database to unload specified tables.access_key_id: The access key ID to sign requests made to AWS.secret_access_key: The secret access key used with the access key ID to sign requests made to AWS.s3_bucket: The Amazon S3 URI beginning with "s3://" and specifying a prefix for temporary files to be used.redshift_schema: The Amazon Redshift schema that contains all the tables to be migrated.table_name_patterns: Table name patterns separated by a semicolon (;). The table pattern is a regular expression for table(s) to migrate. If not provided, all tables under the database schema are migrated.
For example, the following command creates an Amazon Redshift transfer
named My Transfer with a target dataset named mydataset and a project
with the ID of google.com:myproject.
bq mk \
--transfer_config \
--project_id=myproject \
--data_source=redshift \
--target_dataset=mydataset \
--display_name='My Transfer' \
--params='{"jdbc_url":"jdbc:postgresql://test-example-instance.sample.us-west-1.redshift.amazonaws.com:5439/dbname","database_username":"my_username","database_password":"1234567890","access_key_id":"A1B2C3D4E5F6G7H8I9J0","secret_access_key":"1234567890123456789012345678901234567890","s3_bucket":"s3://bucket/prefix","redshift_schema":"public","table_name_patterns":"table_name"}'
API
Use the projects.locations.transferConfigs.create
method and supply an instance of the TransferConfig
resource.
Java
Before trying this sample, follow the Java setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery Java API reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries.
Quotas and limits
BigQuery has a load quota of 15 TB for each load job for each table. Internally, Amazon Redshift compresses the table data, so the exported table size will be larger than the table size reported by Amazon Redshift. If you plan to migrate a table larger than 15 TB, please contact Cloud Customer Care first.
Costs can be incurred outside of Google by using this service. Review the Amazon Redshift and Amazon S3 pricing pages for details.
Because of Amazon S3's consistency model, it's possible that some files will not be included in the transfer to BigQuery.
What's next
- Learn about Migrating Amazon Redshift private instances with VPC.
- Learn more about the BigQuery Data Transfer Service.
- Migrate SQL code with the Batch SQL translation.