Manage clustered tables
This document describes how to get information about and control access to clustered tables in BigQuery.
For more information, see the following:
- To learn about clustered table support in BigQuery, see Introduction to clustered tables.
- To learn how to create clustered tables, see Create clustered tables.
Before you begin
To get information about tables, you must have the
bigquery.tables.get permission. The following predefined IAM
roles include bigquery.tables.get permissions:
roles/bigquery.metadataViewerroles/bigquery.dataViewerroles/bigquery.dataOwnerroles/bigquery.dataEditorroles/bigquery.admin
In addition, if a user has the bigquery.datasets.create permission, when that
user creates a dataset, they are granted bigquery.dataOwner access to it.
bigquery.dataOwner access gives the user the ability to get information about
tables in a dataset.
For more information about IAM roles and permissions in BigQuery, see Predefined roles and permissions.
Control access to clustered tables
To configure access to tables and views, you can grant an IAM role to an entity at the following levels, listed in order of range of resources allowed (largest to smallest):
- a high level in the Google Cloud resource hierarchy such as the project, folder, or organization level
- the dataset level
- the table or view level
You can also restrict data access within tables, by using the following methods:
Access with any resource protected by IAM is additive. For example, if an entity does not have access at the high level such as a project, you could grant the entity access at the dataset level, and then the entity will have access to the tables and views in the dataset. Similarly, if the entity does not have access at the high level or the dataset level, you could grant the entity access at the table or view level.
Granting IAM roles at a higher level in the Google Cloud resource hierarchy such as the project, folder, or organization level gives the entity access to a broad set of resources. For example, granting a role to an entity at the project level gives that entity permissions that apply to all datasets throughout the project.
Granting a role at the dataset level specifies the operations an entity is allowed to perform on tables and views in that specific dataset, even if the entity does not have access at a higher level. For information on configuring dataset-level access controls, see Controlling access to datasets.
Granting a role at the table or view level specifies the operations an entity is allowed to perform on specific tables and views, even if the entity does not have access at a higher level. For information on configuring table-level access controls, see Controlling access to tables and views.
You can also create IAM custom roles. If you create a custom role, the permissions you grant depend on the specific operations you want the entity to be able to perform.
You can't set a "deny" permission on any resource protected by IAM.
For more information about roles and permissions, see Understanding roles in the IAM documentation and the BigQuery IAM roles and permissions.
Get information about clustered tables
Select one of the following options:
Console
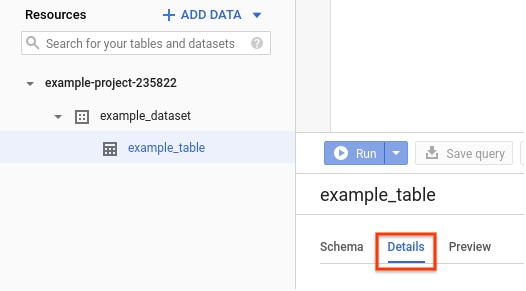
In the Google Cloud console, go to the Resources pane.
Click your dataset name to expand it, and then click the table name that you want to view.
Click Details.
The table's details are displayed, including the clustering columns.
SQL
For clustered tables, you can query the CLUSTERING_ORDINAL_POSITION column
in the INFORMATION_SCHEMA.COLUMNS view
to find the 1-indexed offset of the column within the table's clustering
columns:
In the Google Cloud console, go to the BigQuery page.
In the query editor, enter the following statement:
CREATE TABLE mydataset.data (column1 INT64, column2 INT64) CLUSTER BY column1, column2; SELECT column_name, clustering_ordinal_position FROM mydataset.INFORMATION_SCHEMA.COLUMNS;
Click Run.
For more information about how to run queries, see Run an interactive query.
The clustering ordinal position is 1 for column1 and 2 for column2.
More table metadata is available through the TABLES, TABLE_OPTIONS,
COLUMNS, and COLUMN_FIELD_PATH views in INFORMATION_SCHEMA.
bq
Issue the bq show command to display all table information. Use the
--schema flag to display only table schema information. The --format
flag can be used to control the output.
If you are getting information about a table in a project other than
your default project, add the project ID to the dataset in the following
format: project_id:dataset.
bq show \ --schema \ --format=prettyjson \ PROJECT_ID:DATASET.TABLE
Replace the following:
PROJECT_ID: your project IDDATASET: the name of the datasetTABLE: the name of the table
Examples:
Enter the following command to display all information about
myclusteredtable in mydataset. mydataset in your default project.
bq show --format=prettyjson mydataset.myclusteredtable
The output should look like the following:
{
"clustering": {
"fields": [
"customer_id"
]
},
...
}
API
Call the bigquery.tables.get
method and provide any relevant parameters.
List clustered tables in a dataset
The permissions required to list clustered tables and the steps to list them are the same as for standard tables. For more information, see Listing tables in a dataset.
Modify the clustering specification
You can change or remove a table's clustering specifications, or change the set of clustered columns in a clustered table. This method of updating the clustering column set is useful for tables that use continuous streaming inserts because those tables cannot be easily swapped by other methods.
Follow these steps to apply a new clustering specification to unpartitioned or partitioned tables.
In the bq tool, update the clustering specification of your table to match the new clustering:
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
Replace the following:
CLUSTER_COLUMN: the column you are clustering on—for example,mycolumnDATASET: the name of the dataset containing the table—for example,mydatasetORIGINAL_TABLE: the name of your original table—for example,mytable
You can also call the
tables.updateortables.patchAPI method to modify the clustering specification.To cluster all rows according to the new clustering specification, run the following
UPDATEstatement:UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
What's next
- For information about querying clustered tables, see Query clustered tables.
- For an overview of partitioned table support in BigQuery, see Introduction to partitioned tables.
- To learn how to create partitioned tables, see Create partitioned tables.