Amazon Redshift to BigQuery migration: Overview
This document provides guidance on migrating from Amazon Redshift to BigQuery, focusing on the following topics:
- Strategies for migration
- Best practices for query optimization and data modeling
- Troubleshooting tips
- User adoption guidance
The objectives of this document are as follows:
- Provide high-level guidance for organizations migrating from Amazon Redshift to BigQuery, including helping you rethink your existing data pipelines to get the most out of BigQuery.
- Help you compare the architectures of BigQuery and Amazon Redshift so that you can determine how to implement existing features and capabilities during migration. The goal is to show you new capabilities available to your organization through BigQuery, not to map features one to one with Amazon Redshift.
This document is intended for enterprise architects, database administrators, application developers, and IT security specialists. It assumes you are familiar with Amazon Redshift.
You can also use batch SQL translation to migrate your SQL scripts in bulk, or interactive SQL translation to translate ad hoc queries. Amazon Redshift SQL is fully supported by both SQL translation services.
Pre-migration tasks
To help ensure a successful data warehouse migration, start planning your migration strategy early in your project timeline. This approach lets you evaluate the Google Cloud features that suit your needs.
Capacity planning
BigQuery uses slots to measure analytics throughput. A BigQuery slot is Google's proprietary unit of computational capacity required to execute SQL queries. BigQuery continuously calculates how many slots are required by queries as they execute, but it allocates slots to queries based on a fair scheduler.
You can choose between the following pricing models when capacity planning for BigQuery slots:
- On-demand pricing: With on-demand pricing, BigQuery charges for the number of bytes processed (data size), so you pay only for the queries that you run. For more information about how BigQuery determines data size, see Data size calculation. Because slots determine the underlying computational capacity, you can pay for BigQuery usage depending on the number of slots you'll need (instead of bytes processed). By default all Google Cloud projects are limited to a maximum of 2000 slots. BigQuery might burst beyond this limit to accelerate your queries, but bursting is not guaranteed.
- Capacity-based pricing: With capacity-based pricing, you purchase BigQuery slot reservations (a minimum of 100) instead of paying for the bytes processed by queries that you run. We recommend capacity-based pricing for enterprise data warehouse workloads, which commonly see many concurrent reporting and extract-load-transform (ELT) queries that have predictable consumption.
To help with slot estimation, we recommend setting up BigQuery monitoring using Cloud Monitoring and analyzing your audit logs using BigQuery. You can use Looker Studio (here's an open source example of a Looker Studio dashboard) or Looker to visualize BigQuery's audit log data, specifically for slot usage across queries and projects. You can also use BigQuery's system tables data for monitoring slot utilization across jobs and reservations (here's an open source example of a Looker Studio dashboard). Regularly monitoring and analyzing your slot utilization helps you estimate how many total slots your organization needs as you grow on Google Cloud.
For example, suppose you initially reserve 4,000 BigQuery slots to run 100 medium-complexity queries simultaneously. If you notice high wait times in your queries' execution plans, and your dashboards show high slot utilization, this could indicate that you need additional BigQuery slots to help support your workloads. If you want to purchase slots yourself through yearly or three-year commitments, you can get started with BigQuery reservations using the Google Cloud console or the bq command-line tool. For more details about workload management, query execution, and BigQuery architecture, see Migration to Google Cloud: An in-depth view.
Security in Google Cloud
The following sections describe common Amazon Redshift security controls and how you can help ensure that your data warehouse stays protected in a Google Cloud environment.
Identity and access management
Setting up access controls in Amazon Redshift involves writing Amazon Redshift API permissions policies and attaching them to Identity and Access Management (IAM) identities. The Amazon Redshift API permissions provide cluster-level access but don't provide access levels more granular than the cluster. If you want more granular access to resources like tables or views, you can use user accounts in the Amazon Redshift database.
BigQuery uses IAM to manage access to resources at a more granular level. The types of resources available in BigQuery are organizations, projects, datasets, tables, columns, and views. In the IAM policy hierarchy, datasets are child resources of projects. A table inherits permissions from the dataset that contains it.
To grant access to a resource, assign one or more IAM roles to a user, group, or service account. Organization and project roles affect the ability to run jobs or manage the project, whereas dataset roles affect the ability to access or modify the data inside a project.
IAM provides these types of roles:
- Predefined roles, which are meant to support common use cases and access control patterns.
- Custom roles, which provide granular access according to a user-specified list of permissions.
Within IAM, BigQuery provides table-level access control. Table-level permissions determine the users, groups, and service accounts that can access a table or view. You can give a user access to specific tables or views without giving the user access to the complete dataset. For more granular access, you can also look into implementing one or more of the following security mechanisms:
- Column-level access control, which provides fine-grained access to sensitive columns using policy tags, or type-based classification of data.
- Column-level dynamic data masking, which lets you selectively obscure column data for groups of users, while still allowing access to the column.
- Row-level security, which lets you filter data and enables access to specific rows in a table based on qualifying user conditions.
Full-disk encryption
In addition to identity and access management, data encryption adds an extra layer of defense for protecting data. In the case of data exposure, encrypted data is not readable.
On Amazon Redshift, encryption for both data at rest and data in transit is not enabled by default. Encryption for data at rest must be explicitly enabled when a cluster is launched or by modifying an existing cluster to use AWS Key Management Service encryption. Encryption for data in transit must also be explicitly enabled.
BigQuery encrypts all data at rest and in transit by default, regardless of the source or any other condition, and this cannot be turned off. BigQuery also supports customer-managed encryption keys (CMEK) if you want to control and manage key encryption keys in Cloud Key Management Service.
For more information about encryption in Google Cloud, see whitepapers about data-at-rest encryption and data-in-transit encryption.
For data in transit on Google Cloud, data is encrypted and authenticated when it moves outside of the physical boundaries controlled by Google or on behalf of Google. Inside these boundaries, data in transit is generally authenticated but not necessarily encrypted.
Data loss prevention
Compliance requirements might limit what data can be stored on Google Cloud. You can use Sensitive Data Protection to scan your BigQuery tables to detect and classify sensitive data. If sensitive data is detected, Sensitive Data Protection de-identification transformations can mask, delete, or otherwise obscure that data.
Migration to Google Cloud: The basics
Use this section to learn more about using tools and pipelines to help with migration.
Migration tools
The BigQuery Data Transfer Service provides an automated tool to migrate both schema and data from Amazon Redshift to BigQuery directly. The following table lists additional tools to assist in migrating from Amazon Redshift to BigQuery:
| Tool | Purpose |
|---|---|
| BigQuery Data Transfer Service | Perform an automated batch transfer of your Amazon Redshift data to BigQuery by using this fully managed service. |
| Storage Transfer Service | Quickly import Amazon S3 data into Cloud Storage and set up a repeating schedule for transferring data by using this fully managed service. |
gcloud |
Copy Amazon S3 files into Cloud Storage by using this command-line tool. |
| bq command-line tool | Interact with BigQuery by using this command-line tool. Common interactions include creating BigQuery table schemas, loading Cloud Storage data into tables, and executing queries. |
| Cloud Storage client libraries | Copy Amazon S3 files into Cloud Storage by using your custom tool, built on top of the Cloud Storage client library. |
| BigQuery client libraries | Interact with BigQuery by using your custom tool, built on top of the BigQuery client library. |
| BigQuery query scheduler | Schedule recurring SQL queries by using this built-in BigQuery feature. |
| Cloud Composer | Orchestrate transformations and BigQuery load jobs by using this fully managed Apache Airflow environment. |
| Apache Sqoop | Submit Hadoop jobs by using Sqoop and Amazon Redshift's JDBC driver to extract data from Amazon Redshift into either HDFS or Cloud Storage. Sqoop runs in a Dataproc environment. |
For more information on using BigQuery Data Transfer Service, see Migrate schema and data from Amazon Redshift.
Migration using pipelines
Your data migration from Amazon Redshift to BigQuery can take different paths based on the available migration tools. While the list in this section is not exhaustive, it does provide a sense of the different data pipeline patterns available when moving your data.
For more high-level information about migrating data to BigQuery by using pipelines, see Migrate data pipelines.
Extract and load (EL)
You can fully automate an EL pipeline by using BigQuery Data Transfer Service, which can automatically copy your tables' schemas and data from your Amazon Redshift cluster to BigQuery. If you want more control over your data pipeline steps, you can create a pipeline using the options described in the following sections.
Use Amazon Redshift file extracts
- Export Amazon Redshift data to Amazon S3.
Copy data from Amazon S3 to Cloud Storage by using any of the following options:
- Storage Transfer Service (recommended)
- gcloud CLI
- Cloud Storage client libraries
Load Cloud Storage data into BigQuery by using any of the following options:
Use an Amazon Redshift JDBC connection
Use any of the following Google Cloud products to export Amazon Redshift data by using the Amazon Redshift JDBC driver:
-
- Google-provided template: JDBC to BigQuery
-
Use Sqoop and the Amazon Redshift JDBC driver to extract data from Amazon Redshift into Cloud Storage
Extract, transform, and load (ETL)
If you want to transform some data before loading it into BigQuery, follow the same pipeline recommendations that are described in the Extract and Load (EL) section, adding an extra step to transform your data before loading into BigQuery.
Use Amazon Redshift file extracts
Copy data from Amazon S3 to Cloud Storage by using any of the following options:
- Storage Transfer Service (recommended)
- gcloud CLI
- Cloud Storage client libraries
Transform and then load your data into BigQuery by using any of the following options:
-
- Read from Cloud Storage
- Write to BigQuery
- Google-provided template: Cloud Storage Text to BigQuery
Use an Amazon Redshift JDBC connection
Use any of the products described in the Extract and Load (EL) section, adding an extra step to transform your data before loading into BigQuery. Modify your pipeline to introduce one or more steps to transform your data before writing to BigQuery.
-
- Clone the JDBC to BigQuery template code and modify the template to add Apache Beam transforms.
-
- Transform your data using any of the CDAP plugins.
Extract, load, and transform (ELT)
You can transform your data using BigQuery itself, using any of the Extract and Load (EL) options to load your data into a staging table. You then transform the data in this staging table using SQL queries that write their output into your final production table.
Change data capture (CDC)
Change data capture is one of several software design patterns used to track data changes. It's often used in data warehousing because the data warehouse is used to collate and track data and its changes from various source systems over time.
Partner tools for data migration
There are several vendors in the extract, transform, and load (ETL) space. Refer to the BigQuery partner website for a list of key partners and their provided solutions.
Migration to Google Cloud: An in-depth view
Use this section to learn more about how your data warehouse architecture, schema, and SQL dialect affects your migration.
Architecture comparison
Both BigQuery and Amazon Redshift are based on a massively parallel processing (MPP) architecture. Queries are distributed across multiple servers to accelerate their execution. With regard to system architecture, Amazon Redshift and BigQuery primarily differ in how data is stored and how queries are executed. In BigQuery, the underlying hardware and configurations are abstracted away; its storage and compute allow your data warehouse to grow without any intervention from you.
Compute, memory, and storage
In Amazon Redshift, CPU, memory, and disk storage are tied together through compute nodes, as illustrated in this diagram from the Amazon Redshift documentation. Cluster performance and storage capacity are determined by the type and the quantity of compute nodes, both of which must be configured. To change compute or storage, you need to resize your cluster through a process (over a couple of hours, or up to two days or longer) that creates a brand new cluster and copies the data over. Amazon Redshift also offers RA3 nodes with managed storage that help separate compute and storage. The largest node in the RA3 category caps at 64 TB of managed storage for each node.
From the start, BigQuery does not tie together compute, memory, and storage but instead treats each separately.
BigQuery compute is defined by slots, a unit of computational capacity required to execute queries. Google manages the entire infrastructure that a slot encapsulates, eliminating all but the task of choosing the proper slot quantity for your BigQuery workloads. Refer to the capacity planning for help deciding how many slots you'll purchase for your data warehouse. BigQuery memory is provided by a remote distributed service, connected to compute slots by Google's petabit network, all managed by Google.
BigQuery and Amazon Redshift both use columnar storage, but BigQuery uses variations and advancements on columnar storage. While columns are being encoded, various statistics about the data persisted and later are used during query execution to compile optimal plans and to choose the most efficient runtime algorithm. BigQuery stores your data in Google's distributed file system, where it's automatically compressed, encrypted, replicated, and distributed. This is all accomplished without affecting the computing power available for your queries. Separating storage from compute lets you scale up to dozens of petabytes in storage seamlessly, without requiring additional expensive compute resources. A number of other benefits of separating compute and storage exist as well.
Scaling up or down
When storage or compute become constrained, Amazon Redshift clusters must be resized by modifying the quantity or types of nodes in the cluster.
When you resize an Amazon Redshift cluster, there are two approaches:
- Classic resize: Amazon Redshift creates a cluster to which data is copied, a process that can take a couple hours or as much as two days or longer for large amounts of data.
- Elastic resize: If you change only the number of nodes, then queries are temporarily paused and connections are held open if possible. During the resize operation, the cluster is read-only. Elastic resize typically takes 10 to 15 minutes but might not be available for all configurations.
Because BigQuery is a platform as a service (PaaS), you only have to worry about the number of BigQuery slots that you want to reserve for your organization. You reserve BigQuery slots in reservations and then assign projects to these reservations. To learn how to set up these reservations, see Capacity planning.
Query execution
BigQuery's execution engine is similar to Amazon Redshift's in that they both orchestrate your query by breaking it into steps (a query plan), executing the steps (concurrently where possible), and then reassembling the results. Amazon Redshift generates a static query plan, but BigQuery does not because it dynamically optimizes query plans as your query executes. BigQuery shuffles data using its remote memory service, whereas Amazon Redshift shuffles data using local compute node memory. For more information about BigQuery's storage of intermediate data from various stages of your query plan, see In-memory query execution in Google BigQuery.
Workload management in BigQuery
BigQuery offers the following controls for workload management (WLM):
- Interactive queries, which are executed as soon as possible (this is the default setting).
- Batch queries, which are queued on your behalf, then start as soon as idle resources are available in the BigQuery shared resource pool.
Slot reservations through capacity-based pricing. Instead of paying for queries on demand, you can dynamically create and manage buckets of slots called reservations and assign projects, folders, or organizations to these reservations. You can purchase BigQuery slot commitments (starting at a minimum of 100) in either flex, monthly, or yearly commitments to help minimize costs. By default, queries running in a reservation automatically use idle slots from other reservations.
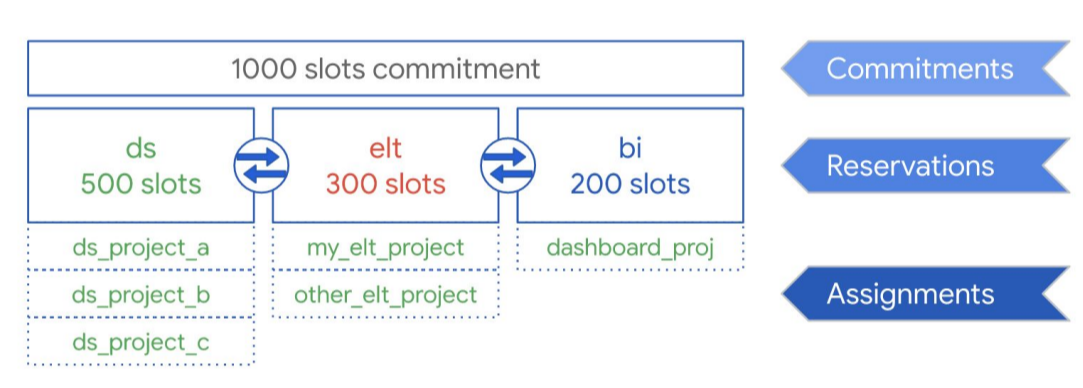
As the following diagram illustrates, suppose you purchased a total commitment capacity of 1,000 slots to share across three workload types: data science, ELT, and business intelligence (BI). To support these workloads, you could create the following reservations:
- You can create the reservation ds with 500 slots, and assign all Google Cloud data science projects to that reservation.
- You can create the reservation elt with 300 slots, and assign the projects you use for ELT workloads to that reservation.
- You can create the reservation bi with 200 slots, and assign projects connected to your BI tools to that reservation.
This setup is shown in the following graphic:
Instead of distributing reservations to your organization's workloads, for example to production and testing, you might choose to assign reservations to individual teams or departments, depending on your use case.
For more information, see Workload management using Reservations.
Workload management in Amazon Redshift
Amazon Redshift offers two types of workload management (WLM):
- Automatic: With automatic WLM, Amazon Redshift manages query concurrency and memory allocation. Up to eight queues are created with the service class identifiers 100–107. Automatic WLM determines the amount of resources that queries need and adjusts the concurrency based on the workload. For more information, see Query priority.
- Manual: In contrast, manual WLM requires you to specify values for query concurrency and memory allocation. The default for manual WLM is concurrency of five queries, and memory is divided equally between all five.
When concurrency scaling is enabled, Amazon Redshift automatically adds additional cluster capacity when you need it to process an increase in concurrent read queries. Concurrency scaling has certain regional and query considerations. For more information, see Concurrency scaling candidates.
Dataset and table configurations
BigQuery offers a number of ways to configure your data and tables such as partitioning, clustering, and data locality. These configurations can help maintain large tables and reduce the overall data load and response time for your queries, thereby increasing the operational efficiency of your data workloads.
Partitioning
A partitioned table is a table that is divided into segments, called partitions, that make it easier to manage and query your data. Users typically split large tables into many smaller partitions, where each partition contains a day's worth of data. Partition management is a key determinant of BigQuery's performance and cost when querying over a specific date range because it helps BigQuery scan less data per query.
There are three types of table partitioning in BigQuery:
- Tables partitioned by ingestion time: Tables are partitioned based on the data's ingestion time.
- Tables partitioned by column:
Tables are partitioned based on a
TIMESTAMPorDATEcolumn. - Tables partitioned by integer range: Tables are partitioned based on an integer column.
A column-based, time-partitioned table obviates the need to maintain partition awareness independent from the existing data filtering on the bound column. Data written to a column-based, time-partitioned table is automatically delivered to, the appropriate partition based on the value of the data. Similarly, queries that express filters on the partitioning column can reduce the overall data scanned, which can yield improved performance and reduced query cost for on-demand queries.
BigQuery column-based partitioning is similar to Amazon Redshift's column-based partitioning, with a slightly different motivation. Amazon Redshift uses column-based key distribution to try to keep related data stored together within the same compute node, ultimately minimizing data shuffling that occurs during joins and aggregations. BigQuery separates storage from compute, so it leverages column-based partitioning to minimize the amount of data that slots read from disk.
Once slot workers read their data from disk, BigQuery can automatically determine more optimal data sharding and quickly repartition data using BigQuery's in-memory shuffle service.
For more information, see Introduction to partitioned tables.
Clustering and sort keys
Amazon Redshift supports specifying table columns as either compound or interleaved sort keys. In BigQuery, you can specify compound sort keys by clustering your table. BigQuery clustered tables improve query performance because the table data is automatically sorted based on the contents of up to four columns specified in the table's schema. These columns are used to colocate related data. The order of the clustering columns you specify is important because it determines the sort order of the data.
Clustering can improve the performance of certain types of queries, such as queries that use filter clauses and queries that aggregate data. When data is written to a clustered table by a query job or a load job, BigQuery automatically sorts the data using the values in the clustering columns. These values are used to organize the data into multiple blocks in BigQuery storage. When you submit a query containing a clause that filters data based on the clustering columns, BigQuery uses the sorted blocks to eliminate scans of unnecessary data.
Similarly, when you submit a query that aggregates data based on the values in the clustering columns, performance is improved because the sorted blocks colocate rows with similar values.
Use clustering in the following circumstances:
- Compound sort keys are configured in your Amazon Redshift tables.
- Filtering or aggregation is configured against particular columns in your queries.
When you use clustering and partitioning together, your data can be partitioned by a date, timestamp, or integer column and then clustered on a different set of columns (up to four total clustered columns). In this case, data in each partition is clustered based on the values of the clustering columns.
When you specify sort keys in tables in Amazon Redshift, depending on the load
on the system, Amazon Redshift automatically initiates the sort using your own
cluster's compute capacity. You may even need to manually run the
VACUUM
command if you want to fully sort your table data as soon as possible, for
example, after a large data load. BigQuery
automatically handles
this sorting for you and does not use your allocated BigQuery
slots, therefore not affecting the performance of any of your queries.
For more information about working with clustered tables, see the Introduction to clustered tables.
Distribution keys
Amazon Redshift uses distribution keys to optimize the location of data blocks to execute its queries. BigQuery does not use distribution keys because it automatically determines and adds stages in a query plan (while the query is running) to improve data distribution throughout query workers.
External sources
If you use Amazon Redshift Spectrum to query data on Amazon S3, you can similarly use BigQuery's external data source feature to query data directly from files on Cloud Storage.
In addition to querying data in Cloud Storage, BigQuery offers federated query functions for querying directly from the following products:
- Cloud SQL (fully managed MySQL or PostgreSQL)
- Bigtable (fully managed NoSQL)
- Google Drive (CSV, JSON, Avro, Sheets)
Data locality
You can create your BigQuery datasets in both regional and multi-regional locations, whereas Amazon Redshift only offers regional locations. BigQuery determines the location to run your load, query, or extract jobs based on the datasets referenced in the request. Refer to the BigQuery location considerations for tips on working with regional and multi-regional datasets.
Data type mapping in BigQuery
Amazon Redshift data types differ from BigQuery data types. For more details on BigQuery data types, refer to the official documentation.
BigQuery also supports the following data types, which don't have a direct Amazon Redshift analog:
SQL comparison
GoogleSQL supports compliance with the SQL 2011 standard and has extensions that support querying nested and repeated data. Amazon Redshift SQL is based on PostgreSQL but has several differences which are detailed in the Amazon Redshift documentation. For a detailed comparison between Amazon Redshift and GoogleSQL syntax and functions, see the Amazon Redshift SQL translation guide.
You can use the batch SQL translator to convert scripts and other SQL code from your current platform to BigQuery.
Post-migration
Since you've migrated scripts that weren't designed with BigQuery in mind, you can opt to implement techniques for optimizing query performance in BigQuery. For more information, see Introduction to optimizing query performance.
What's next
- Get step-by-step instructions to migrate schema and data from Amazon Redshift.
- Get step-by-step instructions to migrate Amazon Redshift to BigQuery with VPC.