Load Amazon S3 data into BigQuery
You can load data from Amazon S3 to BigQuery using the BigQuery Data Transfer Service for Amazon S3 connector. With the BigQuery Data Transfer Service, you can schedule recurring transfer jobs that add your latest data from Amazon S3 to BigQuery.
Before you begin
Before you create an Amazon S3 data transfer:
- Verify that you have completed all actions required to enable the BigQuery Data Transfer Service.
- Create a BigQuery dataset to store your data.
- Create the destination table for your data transfer and specify the schema definition. The destination table must follow the table naming rules. Destination table names also support parameters.
- Retrieve your Amazon S3 URI, your access key ID, and your secret access key. For information on managing your access keys, see the AWS documentation.
- If you intend to setup transfer run notifications for Pub/Sub, you
must have
pubsub.topics.setIamPolicypermissions. Pub/Sub permissions are not required if you just set up email notifications. For more information, see BigQuery Data Transfer Service run notifications.
Limitations
Amazon S3 data transfers are subject to the following limitations:
- The bucket portion of the Amazon S3 URI cannot be parameterized.
- Data transfers from Amazon S3 with the Write disposition parameter set to
WRITE_TRUNCATEwill transfer all matching files to Google Cloud during each run. This may result in additional Amazon S3 outbound data transfer costs. For more information on which files are transferred during a run, see Impact of prefix matching versus wildcard matching. - Data transfers from AWS GovCloud (
us-gov) regions are not supported. - Data transfers to BigQuery Omni locations are not supported.
Depending on the format of your Amazon S3 source data, there may be additional limitations. For more information, see:
The minimum interval time between recurring data transfers is 1 hour. The default interval for a recurring data transfer is 24 hours.
Required permissions
Ensure that you have granted the following permissions.
Required BigQuery roles
To get the permissions that
you need to create a BigQuery Data Transfer Service data transfer,
ask your administrator to grant you the
BigQuery Admin (roles/bigquery.admin)
IAM role on your project.
For more information about granting roles, see Manage access to projects, folders, and organizations.
This predefined role contains the permissions required to create a BigQuery Data Transfer Service data transfer. To see the exact permissions that are required, expand the Required permissions section:
Required permissions
The following permissions are required to create a BigQuery Data Transfer Service data transfer:
-
BigQuery Data Transfer Service permissions:
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
BigQuery permissions:
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
You might also be able to get these permissions with custom roles or other predefined roles.
For more information, see Grant bigquery.admin access.
Required Amazon S3 roles
Consult the documentation for Amazon S3 to ensure you have configured
any permissions necessary to enable the data transfer. At a minimum, the
Amazon S3 source data must have the AWS managed policy
AmazonS3ReadOnlyAccess applied to it.
Set up an Amazon S3 data transfer
To create an Amazon S3 data transfer:
Console
Go to the Data transfers page in the Google Cloud console.
Click Create transfer.
On the Create Transfer page:
In the Source type section, for Source, choose Amazon S3.

In the Transfer config name section, for Display name, enter a name for the transfer such as
My Transfer. The transfer name can be any value that lets you identify the transfer if you need to modify it later.
In the Schedule options section:
Select a Repeat frequency. If you select Hours, Days, Weeks, or Months, you must also specify a frequency. You can also select Custom to create a more specific repeat frequency. If you select On-demand, then this data transfer only runs when you manually trigger the transfer.
If applicable, select either Start now or Start at set time, and provide a start date and run time.
In the Destination settings section, for Destination dataset, choose the dataset that you created to store your data.
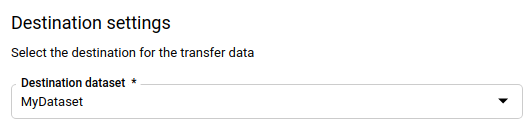
In the Data source details section:
- For Destination table, enter the name of the table that you created to store the data in BigQuery. Destination table names support parameters.
- For Amazon S3 URI, enter the URI with the format
s3://mybucket/myfolder/.... URIs also support parameters. - For Access key ID, enter your access key ID.
- For Secret access key, enter your secret access key.
- For File format choose your data format (newline delimited JSON, CSV, Avro, Parquet, or ORC).
- For Write Disposition, choose one of the following:
WRITE_APPENDto incrementally append new data to your existing destination table.WRITE_APPENDis the default value for Write preference.WRITE_TRUNCATEto overwrite data in the destination table during each data transfer run.
For more information about how BigQuery Data Transfer Service ingests data using either
WRITE_APPENDorWRITE_TRUNCATE, see Data ingestion for Amazon S3 transfers. For more information about thewriteDispositionfield, seeJobConfigurationLoad.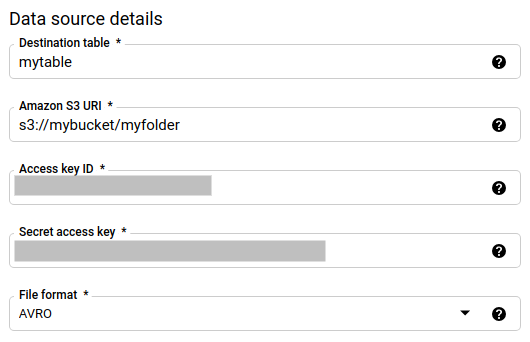
In the Transfer options - all formats section:
- For Number of errors allowed, enter an integer value for the maximum number of bad records that can be ignored.
- (Optional) For Decimal target types, enter a comma-separated
list of possible SQL data types that the source decimal values could
be converted to. Which SQL data type is selected for conversion
depends on the following conditions:
- The data type selected for conversion will be the first data type in the following list that supports the precision and scale of the source data, in this order: NUMERIC, BIGNUMERIC, and STRING.
- If none of the listed data types will support the precision and the scale, the data type supporting the widest range in the specified list is selected. If a value exceeds the supported range when reading the source data, an error will be thrown.
- The data type STRING supports all precision and scale values.
- If this field is left empty, the data type will default to "NUMERIC,STRING" for ORC, and "NUMERIC" for the other file formats.
- This field cannot contain duplicate data types.
- The order of the data types that you list in this field is ignored.

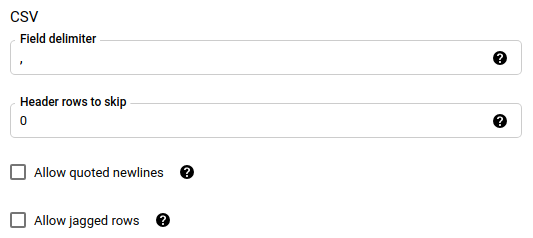
If you chose CSV or JSON as your file format, in the JSON,CSV section, check Ignore unknown values to accept rows that contain values that don't match the schema. Unknown values are ignored. For CSV files, this option ignores extra values at the end of a line.

If you chose CSV as your file format, in the CSV section enter any additional CSV options for loading data.
In the Service Account menu, select a service account from the service accounts associated with your Google Cloud project. You can associate a service account with your data transfer instead of using your user credentials. For more information about using service accounts with data transfers, see Use service accounts.
- If you signed in with a federated identity, then a service account is required to create a data transfer. If you signed in with a Google Account, then a service account for the data transfer is optional.
- The service account must have the required permissions.
(Optional) In the Notification options section:
- Click the toggle to enable email notifications. When you enable this option, the transfer administrator receives an email notification when a data transfer run fails.
- For Select a Pub/Sub topic, choose your topic name or click Create a topic to create one. This option configures Pub/Sub run notifications for your data transfer.
Click Save.
bq
Enter the bq mk command and supply the transfer creation flag —
--transfer_config.
bq mk \ --transfer_config \ --project_id=project_id \ --data_source=data_source \ --display_name=name \ --target_dataset=dataset \ --service_account_name=service_account \ --params='parameters'
Where:
- project_id: Optional. Your Google Cloud project ID.
If
--project_idisn't supplied to specify a particular project, the default project is used. - data_source: Required. The data source —
amazon_s3. - display_name: Required. The display name for the data transfer configuration. The transfer name can be any value that lets you identify the transfer if you need to modify it later.
- dataset: Required. The target dataset for the data transfer configuration.
- service_account: The service account name used to
authenticate your data transfer. The service account should
be owned by the same
project_idused to create the data transfer and it should have all of the required permissions. parameters: Required. The parameters for the created transfer configuration in JSON format. For example:
--params='{"param":"param_value"}'. The following are the parameters for an Amazon S3 transfer:- destination_table_name_template: Required. The name of your destination table.
data_path: Required. The Amazon S3 URI, in the following format:
s3://mybucket/myfolder/...URIs also support parameters.
access_key_id: Required. Your access key ID.
secret_access_key: Required. Your secret access key.
file_format: Optional. Indicates the type of files you want to transfer:
CSV,JSON,AVRO,PARQUET, orORC. The default value isCSV.write_disposition: Optional.
WRITE_APPENDwill transfer only the files which have been modified since the previous successful run.WRITE_TRUNCATEwill transfer all matching files, including files that were transferred in a previous run. The default isWRITE_APPEND.max_bad_records: Optional. The number of allowed bad records. The default is
0.decimal_target_types: Optional. A comma-separated list of possible SQL data types that the source decimal values could be converted to. If this field is not provided, the data type defaults to "NUMERIC,STRING" for ORC, and "NUMERIC" for the other file formats.
ignore_unknown_values: Optional, and ignored if file_format is not
JSONorCSV. Whether to ignore unknown values in your data.field_delimiter: Optional, and applies only when
file_formatisCSV. The character that separates fields. The default value is a comma.skip_leading_rows: Optional, and applies only when file_format is
CSV. Indicates the number of header rows you don't want to import. The default value is0.allow_quoted_newlines: Optional, and applies only when file_format is
CSV. Indicates whether to allow newlines within quoted fields.allow_jagged_rows: Optional, and applies only when file_format is
CSV. Indicates whether to accept rows that are missing trailing optional columns. The missing values will be filled in with NULLs.
For example, the following command creates an Amazon S3 data transfer named
My Transfer using a data_path value of
s3://mybucket/myfile/*.csv, target dataset mydataset, and file_format
CSV. This example includes non-default values for the optional params
associated with the CSV file_format.
The data transfer is created in the default project:
bq mk --transfer_config \
--target_dataset=mydataset \
--display_name='My Transfer' \
--params='{"data_path":"s3://mybucket/myfile/*.csv",
"destination_table_name_template":"MyTable",
"file_format":"CSV",
"write_disposition":"WRITE_APPEND",
"max_bad_records":"1",
"ignore_unknown_values":"true",
"field_delimiter":"|",
"skip_leading_rows":"1",
"allow_quoted_newlines":"true",
"allow_jagged_rows":"false"}' \
--data_source=amazon_s3
After running the command, you receive a message like the following:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Follow the instructions and paste the authentication code on the command line.
API
Use the projects.locations.transferConfigs.create
method and supply an instance of the TransferConfig
resource.
Java
Before trying this sample, follow the Java setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery Java API reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries.
Impact of prefix matching versus wildcard matching
The Amazon S3 API supports prefix matching, but not wildcard matching. All Amazon S3 files that match a prefix will be transferred into Google Cloud. However, only those that match the Amazon S3 URI in the transfer configuration will actually get loaded into BigQuery. This could result in excess Amazon S3 outbound data transfer costs for files that are transferred but not loaded into BigQuery.
As an example, consider this data path:
s3://bucket/folder/*/subfolder/*.csv
Along with these files in the source location:
s3://bucket/folder/any/subfolder/file1.csv
s3://bucket/folder/file2.csv
This will result in all Amazon S3 files with the prefix s3://bucket/folder/
being transferred to Google Cloud. In this example, both file1.csv and
file2.csv will be transferred.
However, only files matching s3://bucket/folder/*/subfolder/*.csv will
actually load into BigQuery. In this example, only file1.csv
will be loaded into BigQuery.
Troubleshoot transfer setup
If you are having issues setting up your data transfer, see Amazon S3 transfer issues.
What's next
- For an introduction to Amazon S3 data transfers, see Overview of Amazon S3 transfers
- For an overview of BigQuery Data Transfer Service, see Introduction to BigQuery Data Transfer Service.
- For information on using data transfers including getting information about a transfer configuration, listing transfer configurations, and viewing a transfer's run history, see Working with transfers.
- Learn how to load data with cross-cloud operations.