Introduction to BigQuery DataFrames
BigQuery DataFrames is a set of open source Python libraries that let you take advantage of BigQuery data processing by using familiar Python APIs. BigQuery DataFrames provides a Pythonic DataFrame powered by the BigQuery engine, and it implements the pandas and scikit-learn APIs by pushing the processing down to BigQuery through SQL conversion. This lets you use BigQuery to explore and process terabytes of data, and also train machine learning (ML) models, all with Python APIs.
The following diagram describes the workflow of BigQuery DataFrames:
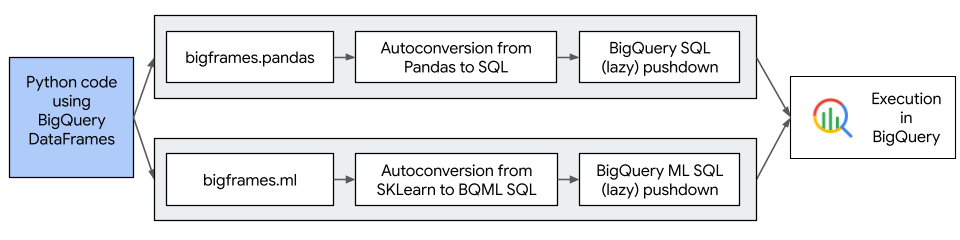
BigQuery DataFrames benefits
BigQuery DataFrames does the following:
- Offers more than 750 pandas and scikit-learn APIs implemented through transparent SQL conversion to BigQuery and BigQuery ML APIs.
- Defers the execution of queries for enhanced performance.
- Extends data transformations with user-defined Python functions to let you process data in Google Cloud. These functions are automatically deployed as BigQuery remote functions.
- Integrates with Vertex AI to let you use Gemini models for text generation.
Licensing
BigQuery DataFrames is distributed with the Apache-2.0 license.
BigQuery DataFrames also contains code derived from the following third-party packages:
For details, see the
third_party/bigframes_vendored
directory in the BigQuery DataFrames GitHub repository.
Quotas and limits
- BigQuery quotas apply to BigQuery DataFrames, including hardware, software, and network components.
- A subset of pandas and scikit-learn APIs are supported. For more information, see Supported pandas APIs.
- You must explicitly clean up any automatically created Cloud Run functions functions as part of session cleanup. For more information, see Supported pandas APIs.
Pricing
- BigQuery DataFrames is a set of open source Python libraries available for download at no extra cost.
- BigQuery DataFrames uses BigQuery, Cloud Run functions, Vertex AI, and other Google Cloud services, which incur their own costs.
- During regular usage, BigQuery DataFrames stores temporary data,
such as intermediate results, in BigQuery tables. These
tables persist for seven days by default, and you are charged for the data
stored in them. The tables are created in the
_anonymous_dataset in the Google Cloud project you specify in thebf.options.bigquery.projectoption.
What's next
- Try the BigQuery DataFrames quickstart.
- Learn how to use BigQuery DataFrames.
- Learn how to visualize graphs using BigQuery DataFrames.
- Learn how to
use the
dbt-bigqueryadapter.