BigQuery Studio ノートブックで PySpark コードを実行する
このドキュメントでは、BigQuery Python ノートブックで PySpark コードを実行する方法について説明します。
始める前に
Google Cloud プロジェクトと Cloud Storage バケットをまだ作成していない場合は、作成します。
プロジェクトを設定する
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 使用できる Cloud Storage バケットがない場合は、プロジェクトに Cloud Storage バケットを作成します。
ノートブックを設定する
- ノートブック認証情報: デフォルトでは、ノートブック セッションでは、ユーザー認証情報を使用します。または、セッション サービス アカウントの認証情報を使用することもできます。
- ユーザー認証情報: ユーザー アカウントには、次の Identity and Access Management ロールが必要です。
- Dataproc 編集者(
roles/dataproc.editorロール) - BigQuery Studio ユーザー(
roles/bigquery.studioUserロール) - セッション サービス アカウントに対するサービス アカウント ユーザー(roles/iam.serviceAccountUser)ロール。このロールには、サービス アカウントの権限を借用するために必要な
iam.serviceAccounts.actAs権限が含まれています。
- Dataproc 編集者(
- サービス アカウントの認証情報: ノートブック セッションでユーザー認証情報の代わりにサービス アカウントの認証情報を指定する場合は、セッション サービス アカウントに次のロールが必要です。
- ユーザー認証情報: ユーザー アカウントには、次の Identity and Access Management ロールが必要です。
- ノートブックのランタイム: 別のランタイムを選択しない限り、ノートブックはデフォルトの Vertex AI ランタイムを使用します。独自のランタイムを定義する場合は、 Google Cloud コンソールの [ランタイム] ページからランタイムを作成します。注: NumPy ライブラリを使用する場合は、Spark 3.5 でサポートされている NumPy バージョン 1.26 をノートブック ランタイムで使用してください。
- ノートブック認証情報: デフォルトでは、ノートブック セッションでは、ユーザー認証情報を使用します。または、セッション サービス アカウントの認証情報を使用することもできます。
Google Cloud コンソールで、[BigQuery] ページに移動します。
詳細ペインのタブバーで、+ 記号の横にある 矢印をクリックし、[ノートブック] をクリックします。
- ノートブックで単一のセッションを構成して作成します。
- インタラクティブ セッション テンプレートで Spark セッションを構成し、テンプレートを使用してノートブックでセッションを構成して作成します。BigQuery には、[Templated Spark session] タブで説明されているように、テンプレート化されたセッションのコーディングを開始するのに役立つ
Query using Spark機能があります。 エディタペインのタブバーで、+ 記号の横にある 矢印プルダウンをクリックし、[ノートブック] をクリックします。
![新しいノートブックを作成するための [+] ボタンがある BigQuery インターフェースを示すスクリーンショット。](https://cloud-dot-devsite-v2-prod.appspot.com/static/dataproc-serverless/docs/images/plus-python-notebook.png?hl=ja)
次のコードをノートブック セルにコピーして実行し、基本的な Spark セッションを構成して作成します。
- APP_NAME: セッションのオプションの名前。
- オプションのセッション設定: Dataproc API の
Session設定を追加して、セッションをカスタマイズできます。次に例を示します。RuntimeConfig:
session.runtime_config.properties={spark.property.key1:VALUE_1,...,spark.property.keyN:VALUE_N}session.runtime_config.container_image = path/to/container/image
EnvironmentConfig: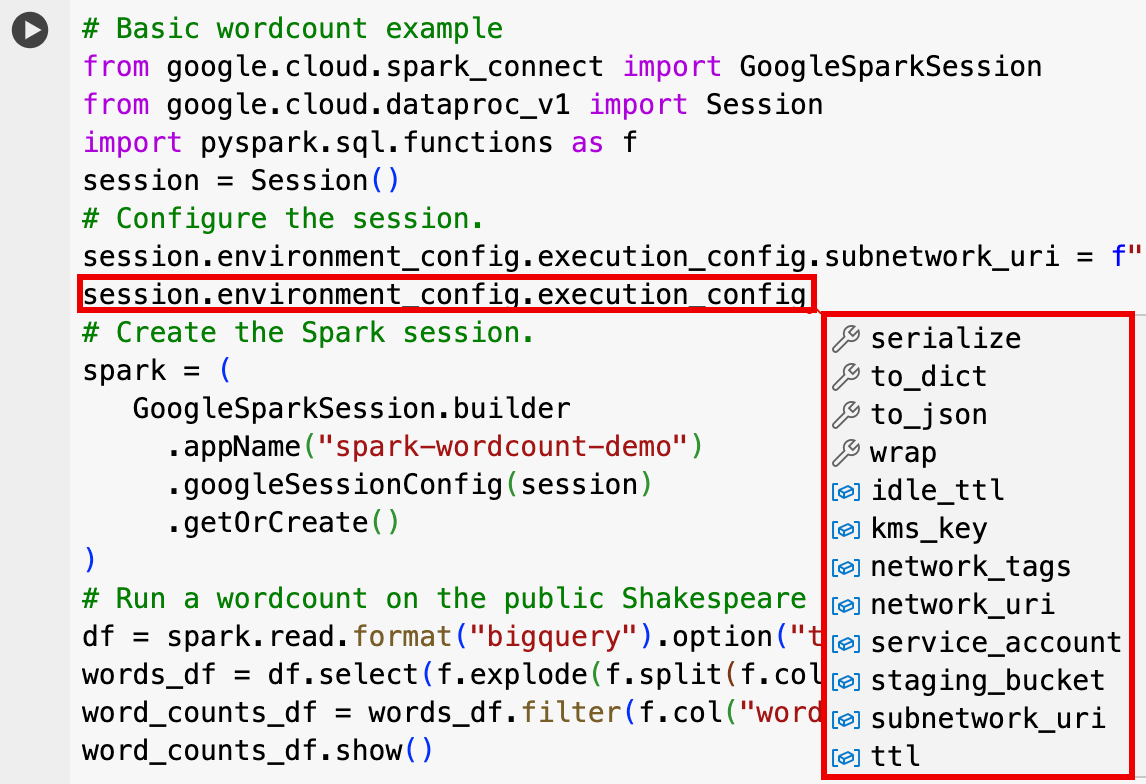
- session.environment_config.execution_config.subnetwork_uri = "SUBNET_NAME"
session.environment_config.execution_config.ttl = {"seconds": VALUE}session.environment_config.execution_config.service_account = SERVICE_ACCOUNT
- エディタペインのタブバーで、+ 記号の横にある 矢印プルダウンをクリックし、[ノートブック] をクリックします。
- [テンプレートを使って開始] で [Spark を使用したクエリ]、[テンプレートを使用] の順にクリックして、ノートブックにコードを挿入します。
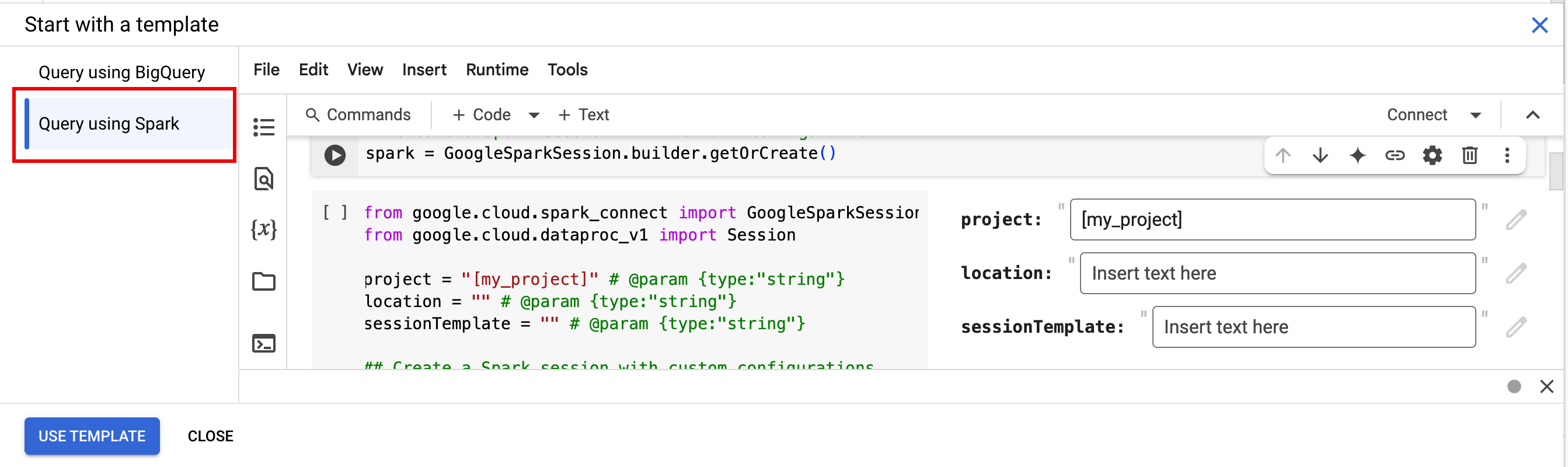
- 注に記載されているように変数を指定します。
- ノートブックに挿入された追加のサンプルコード セルは削除できます。
- PROJECT: プロジェクト ID は、Google Cloud コンソール ダッシュボードの [プロジェクト情報] セクションに表示されます。
- LOCATION: ノートブック セッションが実行される Compute Engine リージョン。指定しない場合、デフォルトのロケーションは、ノートブックを作成する VM のリージョンです。
SESSION_TEMPLATE: 既存のインタラクティブ セッション テンプレートの名前。セッション構成の設定はテンプレートから取得されます。テンプレートでは、次の設定も指定する必要があります。
- ランタイム バージョン
2.3+ ノートブック タイプ:
Spark Connect例:

- ランタイム バージョン
APP_NAME: セッションのオプションの名前。
- 一般公開の Shakespeare データセットに対して WordCount を実行します。
- BigLake metastore に保存されたメタデータを使用して Iceberg テーブルを作成します。
- APP_NAME: セッションのオプションの名前。
- PROJECT: プロジェクト ID は、Google Cloud コンソール ダッシュボードの [プロジェクト情報] セクションに表示されます。
- REGION と SUBNET_NAME: Compute Engine リージョンと、セッション リージョンのサブネットの名前を指定します。Apache Spark 向けサーバーレスは、指定されたサブネットでプライベート Google アクセス(PGA)を有効にします。
- LOCATION: デフォルトの
BigQuery_metastore_config.locationとspark.sql.catalog.{catalog}.gcp_locationはUSですが、サポートされている BigQuery のロケーションを選択できます。 - BUCKET と WAREHOUSE_DIRECTORY: Iceberg ウェアハウス ディレクトリに使用する Cloud Storage バケットとフォルダ。
- CATALOG_NAME と NAMESPACE: Iceberg テーブルを識別するための Iceberg カタログ名と名前空間の組み合わせ(
catalog.namespace.table_name)。 - APP_NAME: セッションのオプションの名前。
Google Cloud コンソールで、[BigQuery] ページに移動します。
プロジェクト リソース ペインで、プロジェクトをクリックし、名前空間をクリックして
sample_iceberg_tableテーブルを一覧表示します。[詳細] テーブルをクリックして、オープン カタログ テーブルの構成情報を表示します。入力形式と出力形式は、Iceberg が使用する標準の Hadoop
InputFormatクラス形式とOutputFormatクラス形式です。
ツールバーで [+ コード] をクリックして、新しいコードセルを挿入します。新しいコードセルに
Start coding or generate with AIが表示されます。[生成] をクリックします。生成エディタで、自然言語プロンプトを入力して
enterをクリックします。プロンプトには、キーワードsparkまたはpysparkを含めてください。プロンプトの例:
create a spark dataframe from order_items and filter to orders created in 2024
出力例:
spark.read.format("bigquery").option("table", "sqlgen-testing.pysparkeval_ecommerce.order_items").load().filter("year(created_at) = 2024").createOrReplaceTempView("order_items") df = spark.sql("SELECT * FROM order_items")Gemini Code Assist で関連するテーブルとスキーマを取得できるようにするには、Dataproc Metastore インスタンスの Data Catalog の同期を有効にします。
ユーザー アカウントに、Data Catalog のクエリテーブルへのアクセス権があることを確認します。そのためには、
DataCatalog.Viewerロールを割り当てます。- ノートブックのセルで
spark.stop()を実行します。 - ノートブックでランタイムを終了します。
- ランタイム セレクタをクリックし、[セッションの管理] をクリックします。

- [アクティブなセッション] ダイアログで、終了アイコンをクリックし、[終了] をクリックします。
![[アクティブなセッション] ダイアログでセッションの選択を終了する](https://cloud-dot-devsite-v2-prod.appspot.com/static/dataproc-serverless/docs/images/terminate-session-in-bq-notebook.png?hl=ja)
- ランタイム セレクタをクリックし、[セッションの管理] をクリックします。
Google Cloud コンソールからノートブック コードをスケジュールします(ノートブックの料金が適用されます)。
ノートブック コードをバッチ ワークロードとして実行します(Apache Spark 向け Serverless の料金が適用されます)。
- ノートブックのスケジュールを設定します。
- ノートブックのコード実行がワークフローの一部である場合は、パイプラインの一部としてノートブックのスケジュールを設定します。
ノートブック コードをローカル ターミナルまたは Cloud Shell のファイルにダウンロードします。
Google Cloud コンソールの BigQuery Studio ページで、[エクスプローラ] ペインでノートブックを開きます。
メニューバーを展開するには、keyboard_arrow_down(ヘッダーの表示 / 非表示を切り替える)をクリックします。
[File] > [Download] をクリックし、[Download.py] をクリックします。
![[エクスプローラ] ページの [ファイル] > [ダウンロード] メニュー。](/static/dataproc-serverless/docs/images/download-pyspark-notebook.png)
requirements.txtを生成します。.pyファイルを保存したディレクトリにpipreqsをインストールします。pip install pipreqs
pipreqsを実行してrequirements.txtを生成します。pipreqs filename.py
Google Cloud CLI を使用して、ローカルの
requirements.txtファイルを Cloud Storage のバケットにコピーします。gcloud storage cp requirements.txt gs://BUCKET/
ダウンロードした
.pyファイルを編集して、Spark セッション コードを更新します。シェル スクリプト コマンドを削除するか、コメントアウトします。
Spark セッションを構成するコードを削除し、構成パラメータをバッチ ワークロード送信パラメータとして指定します。(Spark バッチ ワークロードを送信するをご覧ください)。
例:
コードから次のセッション サブネット構成行を削除します。
session.environment_config.execution_config.subnetwork_uri = "{subnet_name}"バッチ ワークロードを実行する場合は、
--subnetフラグを使用してサブネットを指定します。gcloud dataproc batches submit pyspark \ --subnet=SUBNET_NAME
単純なセッション作成コード スニペットを使用する。
簡素化前のダウンロードされたノートブック コードのサンプル。
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session
session = Session() spark = DataprocSparkSession \ .builder \ .appName("CustomSparkSession") .dataprocSessionConfig(session) \ .getOrCreate()
簡素化後のバッチ ワークロード コード。
from pyspark.sql import SparkSession
spark = SparkSession \ .builder \ .getOrCreate()
-
手順については、Spark バッチ ワークロードを送信するをご覧ください。
--deps-bucket フラグを含めて、
requirements.txtファイルを含む Cloud Storage バケットを指定してください。例:
gcloud dataproc batches submit pyspark FILENAME.py \ --region=REGION \ --deps-bucket=BUCKET \ --version=2.3
注:
- FILENAME: ダウンロードして編集したノートブック コード ファイルの名前。
- REGION: クラスタが配置されている Compute Engine リージョン。
- BUCKET:
requirements.txtファイルを含む Cloud Storage バケットの名前。 --version: バッチ ワークロードを実行するために Spark ランタイム バージョン 2.3 が選択されています。
コードを commit します。
- バッチ ワークロード コードをテストしたら、CI/CD パイプラインの一部として、GitHub、GitLab、Bitbucket などの
gitクライアントを使用して、.ipynbファイルまたは.pyファイルをリポジトリに commit できます。
- バッチ ワークロード コードをテストしたら、CI/CD パイプラインの一部として、GitHub、GitLab、Bitbucket などの
Cloud Composer でバッチ ワークロードのスケジュールを設定します。
- 手順については、Cloud Composer で Apache Spark 用 Serverless ワークロードを実行するをご覧ください。
- YouTube 動画デモ: BigQuery と統合された Apache Spark のパワーを解き放つ。
- Dataproc で BigLake metastore を使用する
- Apache Spark 用サーバーレスで BigLake metastore を使用する
料金
料金については、BigQuery のノートブック ランタイムの料金をご覧ください。
BigQuery Studio Python ノートブックを開く
BigQuery Studio ノートブックで Spark セッションを作成する
BigQuery Studio Python ノートブックを使用して、Spark Connect インタラクティブ セッションを作成できます。各 BigQuery Studio ノートブックには、アクティブな Spark セッションを 1 つだけ関連付けることができます。
BigQuery Studio Python ノートブックで Spark セッションを作成するには、次の方法があります。
1 回のみ
新しいノートブックで Spark セッションを作成するには、次の操作を行います。
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )次のように置き換えます。
テンプレート化された Spark セッション
ノートブック セルにコードを入力して実行し、既存のセッション テンプレートに基づいて Spark セッションを作成できます。ノートブック コードで指定した
session構成設定は、セッション テンプレートで設定されている同じ設定をオーバーライドします。すぐに始めるには、
Query using Sparkテンプレートを使用して、Spark セッション テンプレート コードでノートブックを事前入力します。from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Configure the session with an existing session template. session_template = "SESSION_TEMPLATE" session.session_template = f"projects/{project}/locations/{location}/sessionTemplates/{session_template}" # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )BigQuery Studio ノートブックで PySpark コードを記述して実行する
ノートブックで Spark セッションを作成したら、そのセッションを使用してノートブックで Spark ノートブック コードを実行します。
Spark Connect PySpark API のサポート: Spark Connect ノートブック セッションは、DataFrame、Functions、Column など、ほとんどの PySpark API をサポートしていますが、SparkContext、RDD、その他の PySpark API はサポートしていません。詳細については、Spark 3.5 でサポートされている内容をご覧ください。
Spark Connect ノートブックの直接書き込み: BigQuery Studio ノートブックの Spark セッションでは、Spark BigQuery コネクタが事前に構成され、データを直接書き込めるようになっています。DIRECT 書き込みメソッドは BigQuery Storage Write API を使用して、データを BigQuery に直接書き込みます。INDIRECT 書き込みメソッド(Apache Spark バッチのサーバーレスのデフォルト)は、データを中間 Cloud Storage バケットに書き込んでから、BigQuery に書き込みます(INDIRECT 書き込みの詳細については、BigQuery との間でデータを読み書きするをご覧ください)。
Dataproc 固有の API: Dataproc は、
addArtifactsメソッドを拡張することで、PyPIパッケージを Spark セッションに動的に追加する処理を簡素化します。このリストは、version-scheme形式(pip installに似ている)で指定できます。これにより、Spark Connect サーバーに、すべてのクラスタノードにパッケージとその依存関係をインストールするよう指示し、UDF のワーカーで使用できるようにします。指定された
textdistanceバージョンと、互換性のある最新のrandom2ライブラリをクラスタにインストールして、textdistanceとrandom2を使用する UDF がワーカーノードで実行できるようにする例。spark.addArtifacts("textdistance==4.6.1", "random2", pypi=True)ノートブックのコードヘルプ: BigQuery Studio ノートブックでは、クラス名またはメソッド名にポインタを合わせるとコードヘルプが表示され、コードを入力するときにコード補完ヘルプが表示されます。
次の例では、
DataprocSparkSessionを入力しています。このクラス名にポインタを合わせると、コード補完とドキュメントのヘルプが表示されます。
BigQuery Studio ノートブックの PySpark の例
このセクションでは、次のタスクを実行する PySpark コードを含む BigQuery Studio Python ノートブックの例を示します。
ワード数
次の Pyspark の例では、Spark セッションを作成し、一般公開の
bigquery-public-data.samples.shakespeareデータセット内の単語の出現回数をカウントします。# Basic wordcount example from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Run a wordcount on the public Shakespeare dataset. df = spark.read.format("bigquery").option("table", "bigquery-public-data.samples.shakespeare").load() words_df = df.select(f.explode(f.split(f.col("word"), " ")).alias("word")) word_counts_df = words_df.filter(f.col("word") != "").groupBy("word").agg(f.count("*").alias("count")).orderBy("word") word_counts_df.show()次のように置き換えます。
出力:
セル出力には、ワードカウント出力のサンプルが一覧表示されます。 Google Cloud コンソールでセッションの詳細を表示するには、[Interactive Session Detail View] リンクをクリックします。Spark セッションをモニタリングするには、セッションの詳細ページで [Spark UI を表示] をクリックします。
![コンソールのセッションの詳細ページにある [Spark UI を表示] ボタン](https://cloud-dot-devsite-v2-prod.appspot.com/static/dataproc-serverless/docs/images/view-spark-ui.png?hl=ja)
Interactive Session Detail View: LINK +------------+-----+ | word|count| +------------+-----+ | '| 42| | ''All| 1| | ''Among| 1| | ''And| 1| | ''But| 1| | ''Gamut'| 1| | ''How| 1| | ''Lo| 1| | ''Look| 1| | ''My| 1| | ''Now| 1| | ''O| 1| | ''Od's| 1| | ''The| 1| | ''Tis| 4| | ''When| 1| | ''tis| 1| | ''twas| 1| | 'A| 10| |'ARTEMIDORUS| 1| +------------+-----+ only showing top 20 rows
Iceberg テーブル
PySpark コードを実行して、BigLake metastore メタデータを含む Iceberg テーブルを作成する
次のサンプルコードでは、BigLake metastore にテーブル メタデータを保存する
sample_iceberg_tableを作成し、テーブルをクエリします。from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f # Create the Dataproc Serverless session. session = Session() # Set the session configuration for BigLake Metastore with the Iceberg environment. project_id = "PROJECT" region = "REGION" subnet_name = "SUBNET_NAME" location = "LOCATION" session.environment_config.execution_config.subnetwork_uri = f"{subnet_name}" warehouse_dir = "gs://BUCKET/WAREHOUSE_DIRECTORY" catalog = "CATALOG_NAME" namespace = "NAMESPACE" session.runtime_config.properties[f"spark.sql.catalog.{catalog}"] = "org.apache.iceberg.spark.SparkCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.catalog-impl"] = "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_project"] = f"{project_id}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_location"] = f"{location}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.warehouse"] = f"{warehouse_dir}" # Create the Spark Connect session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Create the namespace in BigQuery. spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;") # Create the Iceberg table. spark.sql("DROP TABLE IF EXISTS `sample_iceberg_table`"); spark.sql("CREATE TABLE sample_iceberg_table (id int, data string) USING ICEBERG;") spark.sql("DESCRIBE sample_iceberg_table;") # Insert table data and query the table. spark.sql("INSERT INTO sample_iceberg_table VALUES (1, \"first row\");") # Alter table, then query and display table data and schema. spark.sql("ALTER TABLE sample_iceberg_table ADD COLUMNS (newDoubleCol double);") spark.sql("DESCRIBE sample_iceberg_table;") df = spark.sql("SELECT * FROM sample_iceberg_table") df.show() df.printSchema()注:
セルの出力には、追加された列を含む
sample_iceberg_tableが一覧表示され、 Google Cloud コンソールの [インタラクティブ セッションの詳細] ページへのリンクが表示されます。セッションの詳細ページで [Spark UI を表示] をクリックすると、Spark セッションをモニタリングできます。
Interactive Session Detail View: LINK +---+---------+------------+ | id| data|newDoubleCol| +---+---------+------------+ | 1|first row| NULL| +---+---------+------------+ root |-- id: integer (nullable = true) |-- data: string (nullable = true) |-- newDoubleCol: double (nullable = true)
BigQuery でテーブルの詳細を表示する
BigQuery で Iceberg テーブルの詳細を確認する手順は次のとおりです。
その他の例
Pandas DataFrame(
df)から SparkDataFrame(sdf)を作成します。sdf = spark.createDataFrame(df) sdf.show()Spark
DataFramesで集計を実行します。from pyspark.sql import functions as F sdf.groupby("segment").agg( F.mean("total_spend_per_user").alias("avg_order_value"), F.approx_count_distinct("user_id").alias("unique_customers") ).show()Spark-BigQuery コネクタを使用して BigQuery から読み取ります。
spark.conf.set("viewsEnabled","true") spark.conf.set("materializationDataset","my-bigquery-dataset") sdf = spark.read.format('bigquery') \ .load(query)Gemini Code Assist を使用して Spark コードを記述する
Gemini Code Assist に、ノートブックで PySpark コードを生成するよう依頼できます。Gemini Code Assist は、関連する BigQuery テーブルと Dataproc Metastore テーブルとそのスキーマを取得して使用し、コード レスポンスを生成します。
ノートブックで Gemini Code Assist コードを生成する手順は次のとおりです。
Gemini Code Assist のコード生成に関するヒント
Spark セッションを終了する
BigQuery Studio ノートブックで Spark Connect セッションを停止するには、次のいずれかを行います。
BigQuery Studio ノートブック コードをオーケストレートする
BigQuery Studio ノートブック コードをオーケストレートするには、次の方法があります。
Google Cloud コンソールからノートブック コードのスケジュールを設定する
ノートブック コードは次の方法でスケジュールできます。
ノートブック コードをバッチ ワークロードとして実行する
BigQuery Studio ノートブック コードをバッチ ワークロードとして実行するには、次の操作を行います。
ノートブック エラーのトラブルシューティング
Spark コードを含むセルでエラーが発生した場合は、セル出力の [Interactive Session Detail View] リンクをクリックして、エラーのトラブルシューティングを行えます(Wordcount と Iceberg テーブルの例をご覧ください)。
既知の問題と解決策
エラー: Python バージョン
3.10で作成されたノートブック ランタイムが Spark セッションに接続しようとすると、PYTHON_VERSION_MISMATCHエラーを引き起こすことがあります。解決策: Python バージョン
3.11でランタイムを再作成します。次のステップ