Ce document explique comment déployer un mécanisme d'exportation pour diffuser des journaux depuis les ressourcesGoogle Cloud vers Splunk. Nous partons du principe que vous avez déjà lu l'architecture de référence correspondante pour ce cas d'utilisation.
Ces instructions sont destinées aux administrateurs des opérations et de la sécurité qui souhaitent diffuser des journaux en streaming depuis Google Cloud vers Splunk. Vous devez connaître Splunk et le collecteur HEC (HTTP Event Collector) de Splunk pour suivre ces instructions pour des cas d'utilisation opérationnels ou de sécurité. Bien que cela ne soit pas obligatoire, une connaissance des pipelines Dataflow, de Pub/Sub, de Cloud Logging, de la gestion de l'authentification et des accès, et de Cloud Storage sera également utile pour ce déploiement.
Pour automatiser les étapes de déploiement de cette architecture de référence en utilisant l'infrastructure en tant que code (IaC), consultez le dépôt GitHub terraform-splunk-log-export.
Architecture
Le schéma suivant illustre l'architecture de référence et montre comment les données de journalisation circulent de Google Cloud vers Splunk.

Comme illustré dans le diagramme, Cloud Logging collecte les journaux dans un récepteur de journaux au niveau de l'organisation et les envoie à Pub/Sub. Le service Pub/Sub crée un sujet et un abonnement uniques pour les journaux, puis transfère les journaux au pipeline Dataflow principal. Le pipeline Dataflow principal est un pipeline de flux de données de Pub/Sub vers Splunk qui extrait les journaux de l'abonnement Pub/Sub et les transmet à Splunk. Parallèlement au pipeline Dataflow principal, le pipeline Dataflow secondaire est un pipeline de flux de données Pub/Sub vers Pub/Sub qui permet de relire les messages en cas d'échec d'une diffusion. À la fin du processus, Splunk Enterprise ou Splunk Cloud Platform agit en tant que point de terminaison HEC et reçoit les journaux en vue d'une analyse plus approfondie. Pour en savoir plus, consultez la section Architecture de l'architecture de référence.
Pour déployer cette architecture de référence, vous allez effectuer les tâches suivantes :
- Effectuer les tâches de configuration.
- Créer un récepteur de journaux agrégé dans un projet dédié.
- Créer un sujet de lettres mortes.
- Configurer un point de terminaison HEC Splunk.
- Configurer la capacité du pipeline Dataflow.
- Exporter les journaux vers Splunk.
- Transformer les journaux ou les événements en cours à l'aide des fonctions définies par l'utilisateur (UDF) dans le pipeline Splunk Dataflow.
- Traiter les échecs de diffusion pour éviter la perte de données due à des erreurs de configuration potentielles ou à des problèmes de réseau temporaires.
Avant de commencer
Pour configurer un environnement pour votre architecture de référenceGoogle Cloud vers Splunk, procédez comme suit:
- Lancer un projet, activer la facturation et activer les API.
- Accorder les rôles IAM.
- Configurer votre environnement.
- Configurer un réseau sécurisé.
Lancer un projet, activer la facturation et activer les API
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Monitoring API, Secret Manager, Compute Engine, Pub/Sub, and Dataflow APIs.
Accorder des rôles IAM
Dans la console Google Cloud, assurez-vous de disposer des autorisations IAM (Identity and Access Management) suivantes pour les ressources d'organisation et de projet. Pour en savoir plus, consultez la page Accorder, modifier et révoquer les accès à des ressources.
| Autorisations | Rôles prédéfinis | Ressource |
|---|---|---|
|
|
Organisation |
|
|
Projet |
|
|
Projet |
Si les rôles IAM prédéfinis n'incluent pas les autorisations suffisantes pour effectuer vos tâches, créez un rôle personnalisé. Un rôle personnalisé vous donne l'accès dont vous avez besoin, tout en vous aidant à respecter le principe du moindre privilège.
Configurer votre environnement
In the Google Cloud console, activate Cloud Shell.
Définissez le projet pour votre session Cloud Shell active :
gcloud config set project PROJECT_ID
Remplacez
PROJECT_IDpar l'ID du projet.
Configurer un réseau sécurisé
Au cours de cette étape, vous allez configurer le réseau sécurisé avant le traitement et l'exportation des journaux vers Splunk Enterprise.
Créez un réseau VPC et un sous-réseau :
gcloud compute networks create NETWORK_NAME --subnet-mode=custom gcloud compute networks subnets create SUBNET_NAME \ --network=NETWORK_NAME \ --region=REGION \ --range=192.168.1.0/24
Remplacez les éléments suivants :
NETWORK_NAME: nom de votre réseauSUBNET_NAME: nom de votre sous-réseauREGION: région que vous souhaitez utiliser pour ce réseau
Créez une règle de pare-feu pour que les machines virtuelles (VM) de nœud de calcul Dataflow communiquent entre elles :
gcloud compute firewall-rules create allow-internal-dataflow \ --network=NETWORK_NAME \ --action=allow \ --direction=ingress \ --target-tags=dataflow \ --source-tags=dataflow \ --priority=0 \ --rules=tcp:12345-12346
Cette règle autorise le trafic interne entre les VM Dataflow qui utilisent les ports TCP 12345-12346. En outre, le service Dataflow définit le tag
dataflow.Créez une passerelle Cloud NAT :
gcloud compute routers create nat-router \ --network=NETWORK_NAME \ --region=REGION gcloud compute routers nats create nat-config \ --router=nat-router \ --nat-custom-subnet-ip-ranges=SUBNET_NAME \ --auto-allocate-nat-external-ips \ --region=REGION
Activez l'accès privé à Google sur le sous-réseau :
gcloud compute networks subnets update SUBNET_NAME \ --enable-private-ip-google-access \ --region=REGION
Créer un récepteur de journaux
Dans cette section, vous allez créer le récepteur de journaux à l'échelle de l'organisation et sa destination Pub/Sub, ainsi que les autorisations nécessaires.
Dans Cloud Shell, créez un sujet Pub/Sub et un abonnement associé en tant que nouvelle destination du récepteur de journaux :
gcloud pubsub topics create INPUT_TOPIC_NAME gcloud pubsub subscriptions create \ --topic INPUT_TOPIC_NAME INPUT_SUBSCRIPTION_NAME
Remplacez les éléments suivants :
INPUT_TOPIC_NAME: nom du sujet Pub/Sub à utiliser comme destination du récepteur de journauxINPUT_SUBSCRIPTION_NAME: nom de l'abonnement Pub/Sub vers la destination du récepteur de journaux
Créez le récepteur de journaux de l'organisation :
gcloud logging sinks create ORGANIZATION_SINK_NAME \ pubsub.googleapis.com/projects/PROJECT_ID/topics/INPUT_TOPIC_NAME \ --organization=ORGANIZATION_ID \ --include-children \ --log-filter='NOT logName:projects/PROJECT_ID/logs/dataflow.googleapis.com'
Remplacez les éléments suivants :
ORGANIZATION_SINK_NAME: nom de votre récepteur dans l'organisationORGANIZATION_ID: ID de votre organisation.
La commande comprend les options suivantes :
- L'option
--organizationindique qu'il s'agit d'un récepteur de journaux au niveau de l'organisation. - L'option
--include-childrenest obligatoire et garantit que le récepteur de journaux au niveau de l'organisation inclut tous les journaux de tous les sous-dossiers et projets. - L'option
--log-filterspécifie les journaux à acheminer. Dans cet exemple, vous excluez les journaux des opérations Dataflow spécifiquement pour le projetPROJECT_ID. En effet, le pipeline d'exportation de journaux Dataflow génère un plus grand nombre de journaux pendant le traitement des journaux. Le filtre empêche le pipeline d'exporter ses propres journaux, évitant ainsi un cycle potentiellement exponentiel. Le résultat inclut un compte de service au formato#####-####@gcp-sa-logging.iam.gserviceaccount.com.
Attribuez le rôle IAM d'éditeur Pub/Sub sur le sujet Pub/Sub
INPUT_TOPIC_NAMEau compte de service du récepteur de journaux. Ce rôle permet au compte de service du récepteur de journaux de publier des messages sur le sujet.gcloud pubsub topics add-iam-policy-binding INPUT_TOPIC_NAME \ --member=serviceAccount:LOG_SINK_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/pubsub.publisher
Remplacez
LOG_SINK_SERVICE_ACCOUNTpar le nom du compte de service de votre récepteur de journaux.
Créer un sujet de lettres mortes
Pour éviter toute perte de données potentielle en cas d'échec de distribution d'un message, vous devez créer un sujet de lettres mortes Pub/Sub et un abonnement correspondant. Le message ayant échoué est stocké dans la file d'attente de lettres mortes jusqu'à ce qu'un opérateur ou un ingénieur en fiabilité des sites puisse examiner et corriger la défaillance. Pour en savoir plus, consultez la section Relire les messages ayant échoué de l'architecture de référence.
Dans Cloud Shell, créez un sujet Pub/Sub de lettres mortes et un abonnement pour éviter toute perte de données en stockant les messages non distribuables :
gcloud pubsub topics create DEAD_LETTER_TOPIC_NAME gcloud pubsub subscriptions create --topic DEAD_LETTER_TOPIC_NAME DEAD_LETTER_SUBSCRIPTION_NAME
Remplacez les éléments suivants :
DEAD_LETTER_TOPIC_NAME: nom du sujet Pub/Sub qui sera le sujet de lettres mortes.DEAD_LETTER_SUBSCRIPTION_NAME: nom de l'abonnement Pub/Sub pour le sujet de lettres mortes.
Configurer un point de terminaison HEC Splunk
Dans les procédures suivantes, vous allez configurer un point de terminaison HEC Splunk et stocker le jeton HEC nouvellement créé en tant que secret dans Secret Manager. Lorsque vous déployez le pipeline Dataflow de Splunk, vous devez fournir à la fois l'URL du point de terminaison et le jeton.
Configurer le collecteur HEC de Splunk
- Si vous ne disposez pas encore de point de terminaison HEC Splunk, référez-vous à la documentation Splunk pour savoir comment configurer le collecteur HEC de Splunk. La solution HEC de Splunk s'exécute sur le service Splunk Cloud Platform ou sur votre propre instance Splunk Enterprise. Laissez l'option d'acquittement de l'indexeur HEC Splunk désactivée, car elle n'est pas compatible avec Splunk Dataflow.
- Dans Splunk, après avoir créé un jeton HEC Splunk, copiez la valeur du jeton.
- Dans Cloud Shell, enregistrez la valeur du jeton HEC Splunk dans un fichier temporaire nommé
splunk-hec-token-plaintext.txt.
Stocker le jeton HEC de Splunk dans Secret Manager
Dans cette étape, vous allez créer un secret et une seule version de secret sous-jacente dans laquelle stocker la valeur du jeton HEC de Splunk.
Dans Cloud Shell, créez un secret contenant votre jeton HEC de Splunk :
gcloud secrets create hec-token \ --replication-policy="automatic"
Pour en savoir plus sur les règles de réplication des secrets, consultez la section Choisir une règle de réplication.
Ajoutez le jeton en tant que version secrète en utilisant le contenu du fichier
splunk-hec-token-plaintext.txt:gcloud secrets versions add hec-token \ --data-file="./splunk-hec-token-plaintext.txt"
Supprimez le fichier
splunk-hec-token-plaintext.txt, car il n'est plus nécessaire.
Configurer la capacité du pipeline Dataflow
Le tableau suivant récapitule les bonnes pratiques générales recommandées pour configurer les paramètres de capacité du pipeline Dataflow :
| Paramètre | Bonnes pratiques générales |
|---|---|
Option |
Définir la taille de la machine de référence sur |
Option |
Définir le nombre maximal de nœuds de calcul nécessaires pour gérer le pic d'EPS attendu selon vos calculs |
Paramètre |
Définir sur (2 x processeurs virtuels par nœud de calcul x le nombre maximal de nœuds de calcul) pour optimiser le nombre de connexions HEC Splunk parallèles |
|
Définir sur 10 à 50 événements/requête pour les journaux, à condition que le délai maximal de mise en mémoire tampon de deux secondes soit acceptable. |
N'oubliez pas d'utiliser vos propres valeurs et calculs uniques lorsque vous déployez cette architecture de référence dans votre environnement.
Définissez les valeurs de type de machine et de nombre de machines. Pour calculer les valeurs appropriées pour votre environnement cloud, consultez les sections Type de machine et Nombre de machines de l'architecture de référence.
DATAFLOW_MACHINE_TYPE DATAFLOW_MACHINE_COUNT
Définissez les valeurs de parallélisme Dataflow et de nombre de lots. Pour calculer les valeurs appropriées pour votre environnement cloud, consultez les sections Parallélisme et Nombre de lots de l'architecture de référence.
JOB_PARALLELISM JOB_BATCH_COUNT
Pour savoir comment calculer les paramètres de capacité du pipeline Dataflow, consultez la section Considérations de conception liées à l'optimisation des performances et des coûts de l'architecture de référence.
Exporter des journaux à l'aide du pipeline Dataflow
Dans cette section, vous allez déployer le pipeline Dataflow en procédant comme suit :
- Créer un bucket Cloud Storage et un compte de service de nœud de calcul Dataflow.
- Accorder des rôles et accéder au compte de service de nœud de calcul Dataflow.
- Déployer le pipeline Dataflow.
- Afficher les journaux dans Splunk.
Le pipeline envoie des messages de journal Google Cloud au collecteur HEC de Splunk.
Créer un bucket Cloud Storage et un compte de service de nœud de calcul Dataflow
Dans Cloud Shell, créez un bucket Cloud Storage avec un paramètre d'accès uniforme au niveau du bucket :
gcloud storage buckets create gs://PROJECT_ID-dataflow/ --uniform-bucket-level-access
Le bucket Cloud Storage que vous venez de créer correspond à l'emplacement où la tâche Dataflow prépare les fichiers temporaires.
Dans Cloud Shell, créez un compte de service pour vos nœuds de calcul Dataflow :
gcloud iam service-accounts create WORKER_SERVICE_ACCOUNT \ --description="Worker service account to run Splunk Dataflow jobs" \ --display-name="Splunk Dataflow Worker SA"
Remplacez
WORKER_SERVICE_ACCOUNTpar le nom que vous souhaitez utiliser pour le compte de service de nœud de calcul Dataflow.
Attribuer des rôles et accéder au compte de service de nœud de calcul Dataflow
Dans cette section, attribuez les rôles requis au compte de service du nœud de calcul Dataflow, comme indiqué dans le tableau suivant.
| Rôle | Chemin | Objectif |
|---|---|---|
| Administrateur Dataflow |
|
Autorise le compte de service à agir en tant qu'administrateur Dataflow. |
| Nœud de calcul Dataflow |
|
Autorise le compte de service à agir en tant que nœud de calcul Dataflow. |
| Administrateur des objets Storage |
|
Autorise le compte de service à accéder au bucket Cloud Storage utilisé par Dataflow pour les fichiers de préproduction. |
| Diffuseur Pub/Sub |
|
Autorise le compte de service à publier des messages ayant échoué sur le sujet de lettres mortes Pub/Sub. |
| Abonné Pub/Sub |
|
Autorise le compte de service à accéder à l'abonnement d'entrée. |
| Lecteur Pub/Sub |
|
Autorise le compte de service pour afficher l'abonnement. |
| Accesseur de secrets Secret Manager |
|
Autorise le compte de service à accéder au secret contenant le jeton HEC de Splunk. |
Dans Cloud Shell, accordez au compte de service de nœud de calcul Dataflow les rôles d'administrateur Dataflow et de nœud de calcul Dataflow dont ce compte a besoin pour exécuter les opérations de job et les tâches d'administration de la tâche Dataflow :
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/dataflow.worker"
Accordez au compte de service de nœud de calcul Dataflow l'accès permettant d'afficher et consulter les messages de l'abonnement d'entrée Pub/Sub :
gcloud pubsub subscriptions add-iam-policy-binding INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.subscriber"
gcloud pubsub subscriptions add-iam-policy-binding INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.viewer"
Accordez au compte de service de nœud de calcul Dataflow l'accès permettant de publier tous les messages ayant échoué dans le sujet Pub/Sub non traité :
gcloud pubsub topics add-iam-policy-binding DEAD_LETTER_TOPIC_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.publisher"
Accordez au compte de service de nœud de calcul Dataflow l'accès au secret du jeton HEC Splunk dans Secret Manager :
gcloud secrets add-iam-policy-binding hec-token \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/secretmanager.secretAccessor"
Accordez au compte de service de nœud de calcul Dataflow un accès en lecture et en écriture au bucket Cloud Storage qui sera utilisé par le job Dataflow pour les fichiers de préproduction :
gcloud storage buckets add-iam-policy-binding gs://PROJECT_ID-dataflow/ \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" --role=”roles/storage.objectAdmin”
Déployer le pipeline Dataflow
Dans Cloud Shell, définissez la variable d'environnement suivante pour votre URL HEC Splunk :
export SPLUNK_HEC_URL=SPLUNK_HEC_URL
Remplacez la variable
SPLUNK_HEC_URLau formatprotocol://host[:port], où :protocolcorrespond àhttpouhttps.hostest le nom de domaine complet ou l'adresse IP de votre instance HEC Splunk ou, si vous avez plusieurs instances HEC, l'équilibreur de charge HTTP(S) associé (ou basé sur le DNS).portcorrespond au numéro de port HEC. Cette option est facultative et dépend de la configuration de votre point de terminaison HEC Splunk.
Voici un exemple d'entrée d'URL HEC Splunk valide :
https://splunk-hec.example.com:8088. Si vous envoyez des données à HEC sur Splunk Cloud Platform, consultez la section Envoyer des données à HEC sur Splunk Cloud pour déterminer les partieshostetportci-dessus de votre URL HEC Splunk.L'URL HEC Splunk ne doit pas inclure le chemin d'accès au point de terminaison HEC (par exemple,
/services/collector). Le modèle Dataflow Pub/Sub vers Splunk n'est actuellement compatible qu'avec le point de terminaison/services/collectorpour les événements au format JSON. Il ajoute automatiquement ce chemin à votre entrée d'URL HEC Splunk. Pour en savoir plus sur ce point de terminaison HEC, consultez la documentation Splunk pour les services/point de terminaison du collecteur.Déployez le pipeline Dataflow à l'aide du modèle Dataflow Pub/Sub vers Splunk :
gcloud beta dataflow jobs run JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --staging-location=gs://PROJECT_ID-dataflow/temp/ \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION/subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/INPUT_SUBSCRIPTION_NAME,\ outputDeadletterTopic=projects/PROJECT_ID/topics/DEAD_LETTER_TOPIC_NAME,\ url=SPLUNK_HEC_URL,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID/secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT,\ parallelism=JOB_PARALLELISM,\ javascriptTextTransformGcsPath=gs://splk-public/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=process
Remplacez
JOB_NAMEpar le format de nompubsub-to-splunk-date+"%Y%m%d-%H%M%S".Les paramètres facultatifs
javascriptTextTransformGcsPathetjavascriptTextTransformFunctionNamespécifient un exemple de fonction définie par l'utilisateur accessible au public :gs://splk-public/js/dataflow_udf_messages_replay.js. L'exemple de fonction définie par l'utilisateur inclut des exemples de code pour la transformation d'événements et la logique de décodage que vous utilisez pour relire les diffusions ayant échoué. Pour en savoir plus sur la fonction définie par l'utilisateur, consultez la page Transformer des événements en cours avec les UDF.Une fois la tâche de pipeline terminée, recherchez le nouvel ID de tâche dans le résultat, copiez l'ID de tâche et enregistrez-le. Vous devrez saisir cet ID de tâche lors d'une prochaine étape.
Afficher les journaux dans Splunk
Le provisionnement des nœuds de calcul du pipeline Dataflow et la préparation de journaux à envoyer au collecteur HEC de Splunk prennent quelques minutes. Vous pouvez confirmer que les journaux ont bien été reçus et indexés dans l'interface de recherche de Splunk Enterprise ou Splunk Cloud Platform. Pour afficher le nombre de journaux par type de ressource surveillée, procédez comme suit :
Dans Splunk, ouvrez Splunk Search & Reporting (Recherche et création de rapports Splunk).
Exécutez la recherche
index=[MY_INDEX] | stats count by resource.typeoù l'indexMY_INDEXest configuré pour votre jeton HEC Splunk.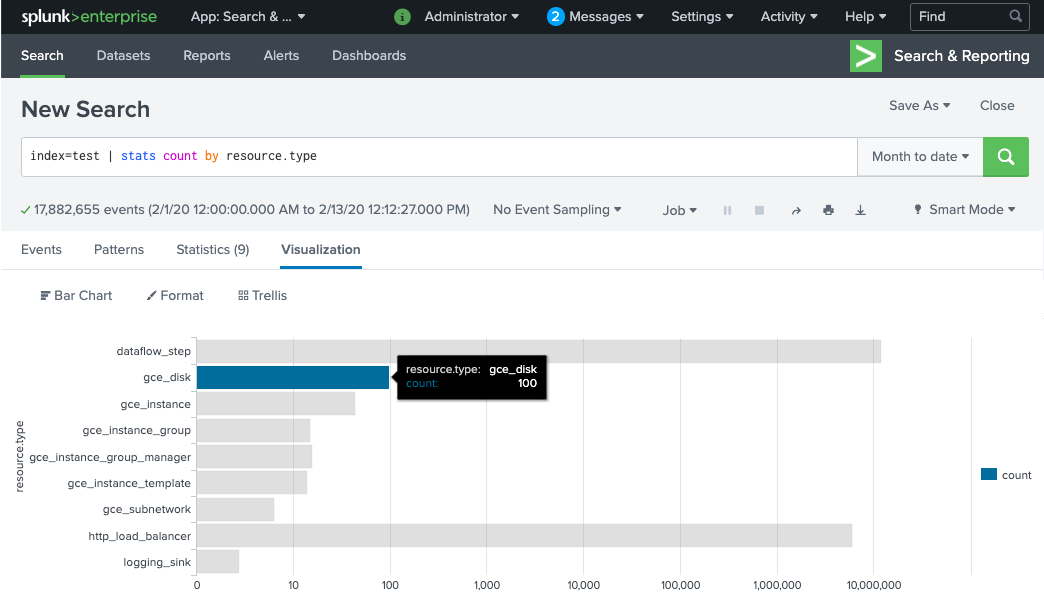
Si vous ne voyez aucun événement, consultez la section Gérer les échecs de diffusion.
Transformer des événements en cours avec les UDF
Le modèle Dataflow Pub/Sub vers Splunk est compatible avec une fonction JavaScript définie par l'utilisateur pour la transformation d'événements personnalisés, comme l'ajout de champs ou la définition de métadonnées HEC Splunk sur une base événementielle. Le pipeline que vous avez déployé utilise cet exemple de fonction définie par l'utilisateur.
Dans cette section, vous commencez par modifier l'exemple de fonction définie par l'utilisateur pour ajouter un nouveau champ d'événement. Ce nouveau champ indique la valeur de l'abonnement Pub/Sub d'origine sous forme d'informations contextuelles supplémentaires. Vous mettez ensuite à jour le pipeline Dataflow avec la fonction modifiée définie par l'utilisateur.
Modifier l'exemple de fonction définie par l'utilisateur
Dans Cloud Shell, téléchargez le fichier JavaScript contenant l'exemple de fonction définie par l'utilisateur :
wget https://storage.googleapis.com/splk-public/js/dataflow_udf_messages_replay.js
Dans l'éditeur de texte de votre choix, ouvrez le fichier JavaScript, recherchez le champ
event.inputSubscription, annulez la mise en commentaire de cette ligne et remplacezsplunk-dataflow-pipelineparINPUT_SUBSCRIPTION_NAME:event.inputSubscription = "INPUT_SUBSCRIPTION_NAME";
Enregistrez le fichier.
Importez le fichier dans le bucket Cloud Storage :
gcloud storage cp ./dataflow_udf_messages_replay.js gs://PROJECT_ID-dataflow/js/
Mettre à jour le pipeline Dataflow à l'aide de la nouvelle fonction définie par l'utilisateur
Dans Cloud Shell, arrêtez le pipeline à l'aide de l'option Drainer pour vous assurer que les journaux déjà extraits depuis Pub/Sub ne sont pas perdus :
gcloud dataflow jobs drain JOB_ID --region=REGION
Exécutez le job de pipeline Dataflow avec la fonction définie par l'utilisateur mise à jour.
gcloud beta dataflow jobs run JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION/subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/INPUT_SUBSCRIPTION_NAME,\ outputDeadletterTopic=projects/PROJECT_ID/topics/DEAD_LETTER_TOPIC_NAME,\ url=SPLUNK_HEC_URL,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID/secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT,\ parallelism=JOB_PARALLELISM,\ javascriptTextTransformGcsPath=gs://PROJECT_ID-dataflow/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=process
Remplacez
JOB_NAMEpar le format de nompubsub-to-splunk-date+"%Y%m%d-%H%M%S".
Gérer les échecs de diffusion
Les échecs de diffusion peuvent être dus à des erreurs liées au traitement des événements ou à la connexion au collecteur HEC Splunk. Dans cette section, vous allez créer un échec de diffusion pour illustrer le processus de traitement des erreurs. Vous apprendrez également à afficher et à déclencher la redistribution des messages ayant échoué vers Splunk.
Déclencher des échecs de diffusion
Pour introduire manuellement un échec de diffusion dans Splunk, effectuez l'une des opérations suivantes :
- Si vous exécutez une seule instance, arrêtez le serveur Splunk pour provoquer des erreurs de connexion.
- Désactivez le jeton HEC pertinent de votre configuration d'entrée Splunk.
Résoudre les problèmes liés aux messages ayant échoué
Pour examiner un message ayant échoué, vous pouvez utiliser la console Google Cloud :
Dans la console Google Cloud, accédez à la page Abonnements Pub/Sub.
Cliquez sur l'abonnement non traité que vous avez créé. Si vous avez utilisé l'exemple précédent, le nom de l'abonnement est
projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME.Pour ouvrir le lecteur de messages, cliquez sur Afficher les messages.
Pour afficher les messages, cliquez sur Extraire et assurez-vous de laisser l'option Activer la confirmation de messages désactivée.
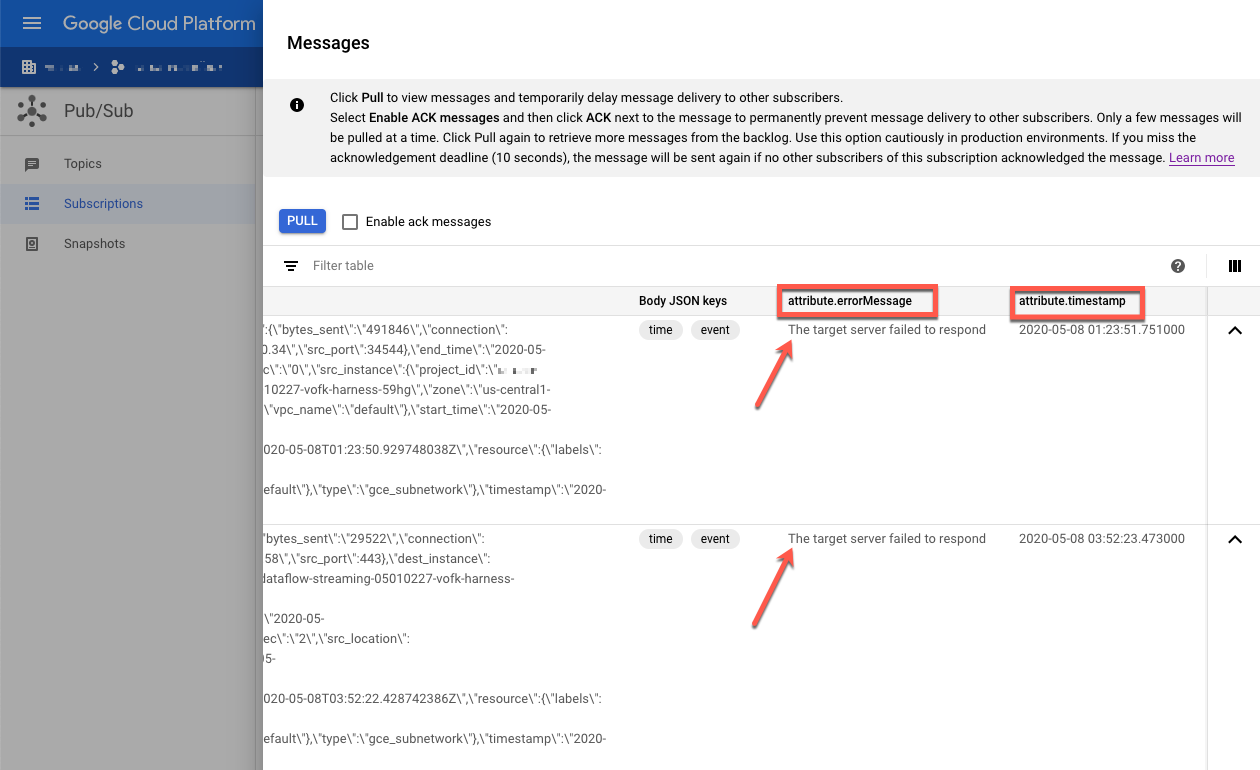
Inspectez les messages ayant échoué. Tenez compte des points suivants :
- Charge utile de l'événement Splunk dans la colonne
Message body. - Message d'erreur dans la colonne
attribute.errorMessage. - Horodatage des erreurs dans la colonne
attribute.timestamp.
- Charge utile de l'événement Splunk dans la colonne
La capture d'écran suivante montre un exemple de message d'échec que vous recevez si le point de terminaison HEC Splunk est temporairement indisponible ou inaccessible. Notez que le texte de l'attribut errorMessage indique The target server failed to respond.
Le message affiche également l'horodatage associé à chaque échec. Vous pouvez utiliser cet horodatage pour résoudre la cause première de l'échec.
Relire les messages ayant échoué
Dans cette section, vous devez redémarrer le serveur Splunk ou activer le point de terminaison HEC Splunk pour corriger l'erreur de diffusion. Vous pouvez ensuite relire les messages non traités.
Dans Splunk, utilisez l'une des méthodes suivantes pour restaurer la connexion àGoogle Cloud:
- Si vous avez arrêté le serveur Splunk, redémarrez-le.
- Si vous avez désactivé le point de terminaison HEC Splunk dans la section Déclencher des échecs de diffusion, vérifiez que celui-ci est désormais opérationnel.
Dans Cloud Shell, prenez un instantané de l'abonnement non traité avant de retraiter les messages de cet abonnement. L'instantané évite la perte de messages en cas d'erreur de configuration inattendue.
gcloud pubsub snapshots create SNAPSHOT_NAME \ --subscription=DEAD_LETTER_SUBSCRIPTION_NAME
Remplacez
SNAPSHOT_NAMEpar un nom qui vous aide à identifier l'instantané, tel quedead-letter-snapshot-date+"%Y%m%d-%H%M%S.Utiliser le modèle Dataflow Pub/Sub vers Splunk pour créer un pipeline Pub/Sub vers Pub/Sub. Le pipeline utilise un autre job Dataflow pour retourner les messages de l'abonnement non traité vers le sujet d'entrée.
DATAFLOW_INPUT_TOPIC="INPUT_TOPIC_NAME" DATAFLOW_DEADLETTER_SUB="DEAD_LETTER_SUBSCRIPTION_NAME" JOB_NAME=splunk-dataflow-replay-date +"%Y%m%d-%H%M%S" gcloud dataflow jobs run JOB_NAME \ --gcs-location= gs://dataflow-templates/latest/Cloud_PubSub_to_Cloud_PubSub \ --worker-machine-type=n2-standard-2 \ --max-workers=1 \ --region=REGION \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME,\ outputTopic=projects/PROJECT_ID/topics/INPUT_TOPIC_NAME
Copiez l'ID de job Dataflow à partir du résultat de la commande et enregistrez-le pour une utilisation ultérieure. Vous devez saisir cet ID de job sous la forme
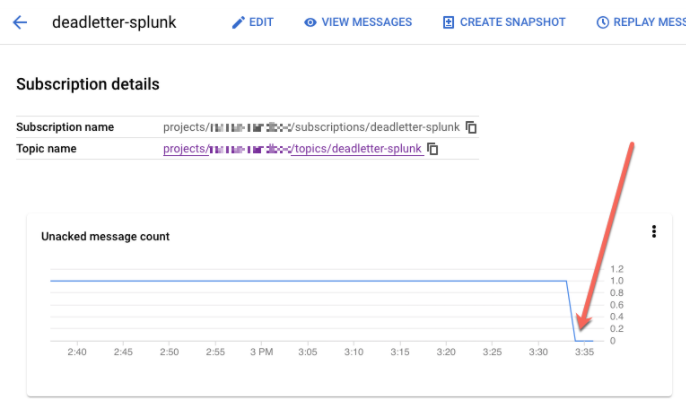
REPLAY_JOB_IDlorsque vous drainez votre job Dataflow.Dans la console Google Cloud, accédez à la page Abonnements Pub/Sub.
Sélectionnez l'abonnement non traité. Vérifiez que le graphique Nombre de messages qui n'ont pas fait l'objet d'un accusé de réception est égal à 0, comme illustré dans la capture d'écran suivante.
Dans Cloud Shell, drainez le job Dataflow que vous avez créé :
gcloud dataflow jobs drain REPLAY_JOB_ID --region=REGION
Remplacez
REPLAY_JOB_IDpar l'ID de job Dataflow que vous avez enregistré précédemment.
Lorsque les messages sont retournés vers le sujet d'entrée d'origine, le pipeline Dataflow principal récupère automatiquement les messages ayant échoué et les renvoie à Splunk.
Confirmer les messages dans Splunk
Pour confirmer que les messages ont été renvoyés, accédez à Splunk, puis ouvrez Splunk Search & Reporting (Recherche et création de rapports Splunk).
Effectuez une recherche pour
delivery_attempts > 1. Il s'agit d'un champ spécial que l'exemple de fonction définie par l'utilisateur ajoute à chaque événement pour suivre le nombre de tentatives d'envoi. Veillez à étendre la période de recherche afin d'inclure les événements ayant pu survenir par le passé, car l'horodatage de l'événement correspond à l'heure d'origine de la création, et non à l'heure de l'indexation.
Dans la capture d'écran qui suit, les deux messages ayant initialement échoué ont été distribués puis indexés dans Splunk avec l'horodatage approprié.
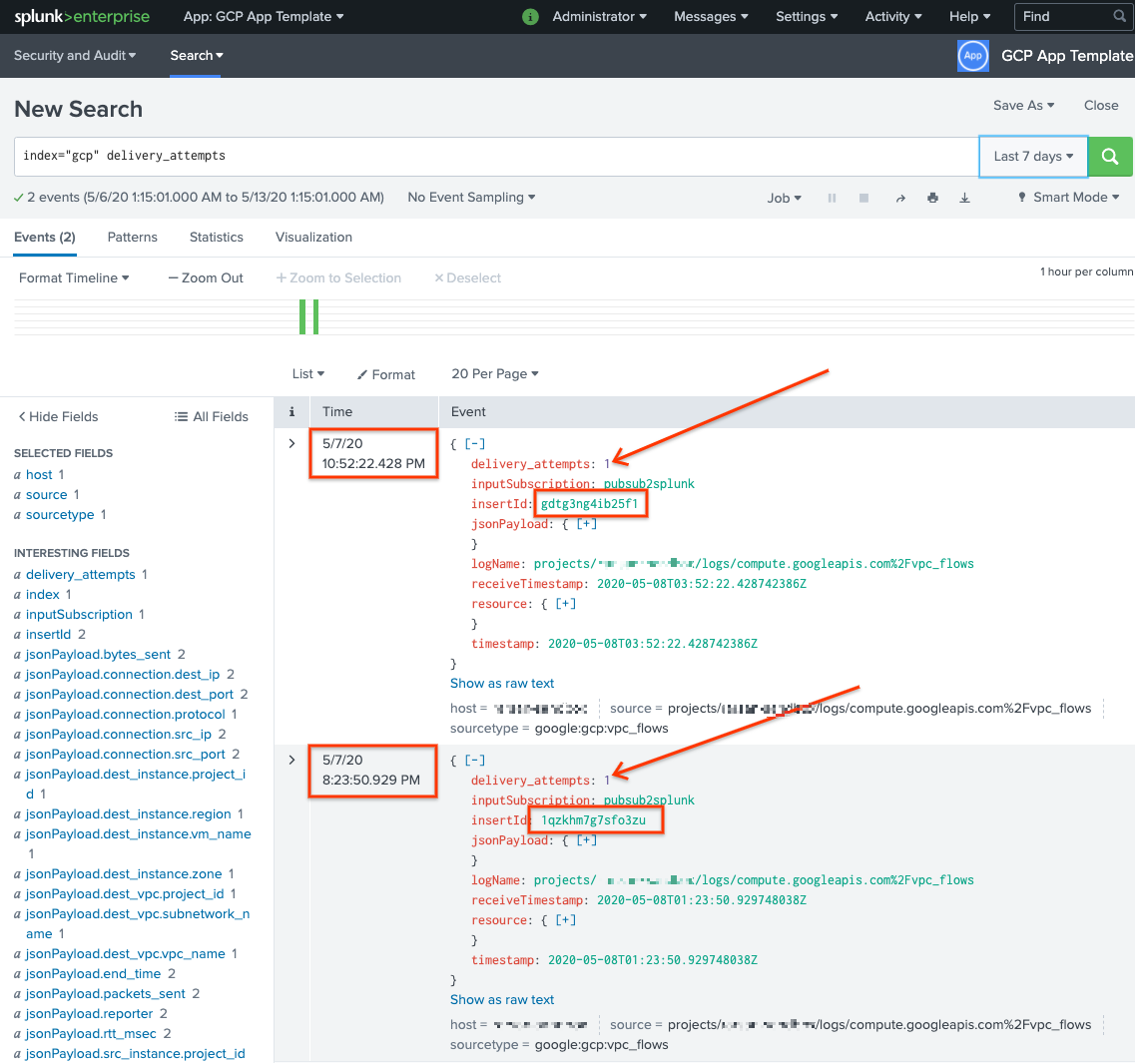
Notez que la valeur du champ insertId est identique à la valeur qui apparaît dans les messages ayant échoué lorsque vous consultez l'abonnement non traité.
Le champ insertId est un identifiant unique que Cloud Logging attribue à l'entrée de journal d'origine. Le insertId s'affiche également dans le corps du message Pub/Sub.
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cette architecture de référence ne soient facturées sur votre compte Google Cloud , supprimez le projet contenant les ressources, ou conservez le projet et supprimez chaque ressource individuellement.
Supprimer le récepteur au niveau de l'organisation
- Exécutez la commande suivante pour supprimer le récepteur de journaux au niveau de l'organisation :
gcloud logging sinks delete ORGANIZATION_SINK_NAME --organization=ORGANIZATION_ID
Supprimer le projet
Une fois le récepteur de journaux supprimé, vous pouvez supprimer les ressources créées pour recevoir et exporter des journaux. Le moyen le plus simple consiste à supprimer le projet que vous avez créé pour l'architecture de référence.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Étapes suivantes
- Pour obtenir la liste complète des paramètres du modèle Dataflow Pub/Sub vers Splunk, consultez la documentation Dataflow Pub/Sub vers Splunk.
- Pour obtenir les modèles Terraform correspondants pour vous aider à déployer cette architecture de référence, consultez le dépôt GitHub
terraform-splunk-log-export. Il inclut un tableau de bord Cloud Monitoring prédéfini pour surveiller votre pipeline Dataflow Splunk. - Pour en savoir plus sur les métriques et la journalisation personnalisées Dataflow avec Splunk, afin de vous aider à surveiller vos pipelines Dataflow Splunk et à résoudre les problèmes associés, consultez l'article de blog Nouvelles fonctionnalités d'observabilité pour vos pipelines de streaming Dataflow Splunk.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.