このドキュメントでは、ML システムの継続的インテグレーション(CI)、継続的デリバリー(CD)、継続的トレーニング(CT)の実装と自動化について説明します。このドキュメントは主に予測 AI システムに適用されます。
データ サイエンスと ML は、複雑な実世界の問題を解決し、業界を変革して、すべての分野で価値を提供するコア機能になりつつあります。現在、効果的な ML を適用するための要素は次のとおりです。
- 大規模なデータセット
- 低価格のオンデマンド コンピューティング リソース
- さまざまなクラウド プラットフォームでの ML 専用のアクセラレータ
- さまざまな ML 研究分野(コンピュータ ビジョン、自然言語理解、生成 AI、Recommendations AI システムなど)における急速な進歩
そのため、多くの企業がデータ サイエンス チームと ML 機能に投資して、ユーザーにビジネス価値をもたらす予測モデルを開発しています。
このドキュメントは、DevOps の原則を ML システム(MLOps)に適用するデータ サイエンティストと ML エンジニアを対象としています。MLOps は、ML システム開発(Dev)と ML システム オペレーション(Ops)の統合を目的とする ML エンジニアリングの文化と手法です。MLOps を実践すると、統合、テスト、リリース、デプロイ、インフラストラクチャ管理など、ML システム構築のすべてのステップで自動化とモニタリングを推進できます。
データ サイエンティストは、ユースケースに関連するトレーニング データがあれば、オフラインのホールドアウト データセットの予測性能で ML モデルを実装してトレーニングできます。しかし、実際の課題は ML モデルを構築することではなく、統合された ML システムを構築し、本番環境で継続的に運用することです。Google における本番環境 ML サービスの長い歴史から、本番環境で ML ベースのシステムを運用する際には多くの問題点があることがわかっています。これらの問題点の一部については、ML: 技術的負債の高金利のクレジット カードをご覧ください。
次の図に示すように、実際の ML システムの中で ML コードで構成されているものはごく一部です。必要となる周辺要素は膨大で複雑です。
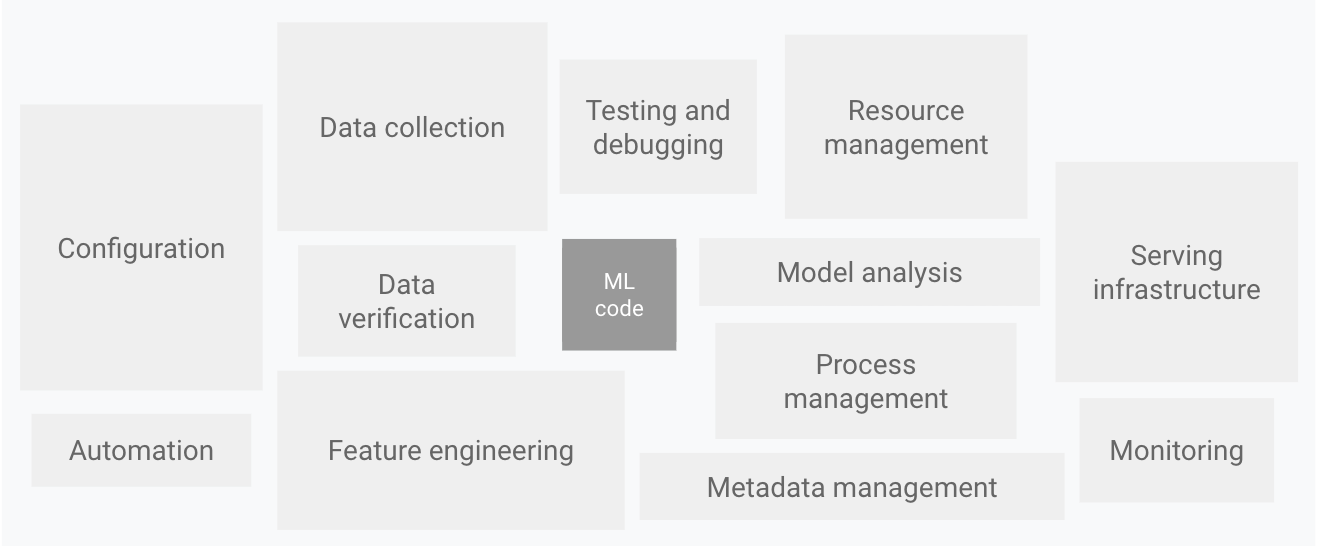
図 1:ML システムの要素。ML システムの隠れた技術的負債からの抜粋。
上の図は、次のシステム コンポーネントを示しています。
- 構成
- 自動化
- データ収集
- データの確認
- テストとデバッグ
- リソース管理
- モデル分析
- プロセスとメタデータの管理
- サービング インフラストラクチャ
- モニタリング
このような複雑なシステムを開発して運用するため、DevOps の原則を ML システム(MLOps)に適用します。このドキュメントでは、ML で CI、CD、CT など、データ サイエンスの取り組みで MLOps 環境を設定する際に考慮すべきコンセプトについて説明します。
以下のトピックについて説明します。
- DevOps と MLOps
- ML モデルの開発手順
- MLOps の成熟度
- 生成 AI のための MLOps
DevOps と MLOps
DevOps は、大規模なソフトウェア システムの開発と運用における一般的な手法です。この手法では、開発サイクルの短縮、開発の迅速化、信頼性の高いリリースが可能です。これらの利点を享受するには、ソフトウェア システム開発における 2 つのコンセプトを導入します。
ML システムはソフトウェア システムであるため、同様の手法を適用して、大規模な ML システムを確実にビルドして運用できます。
ただし、ML システムは次の点で他のソフトウェア システムと異なります。
チームのスキル: ML プロジェクトのチームには通常、探索的データ分析、モデル開発、テストに注力するデータ サイエンティストや ML 研究者が含まれます。これらのメンバーが、本番環境クラスのサービスをビルドできる経験豊富なソフトウェア エンジニアではない場合があります。
開発: ML には実験的性質があります。さまざまな機能、アルゴリズム、モデリング技術、パラメータ構成を試して、問題に最適な方法をできるだけ早く見つける必要があります。何が機能し、何が機能しなかったかを追跡して、コードの再利用性を最大化しながら再現性を維持することが課題となります。
テスト: ML システムのテストは、その他のソフトウェア システムのテストよりも複雑です。一般的な単体テストと統合テストに加えて、データ検証、トレーニングされたモデル品質評価、モデル検証が必要です。
デプロイ: ML システムでのデプロイは、予測サービスとしてオフラインでトレーニングした ML モデルのデプロイのようにシンプルではありません。ML システムでは、モデルの再トレーニングとデプロイが自動で行われるように、複数のステップからなるパイプラインをデプロイしなければならない場合があります。このパイプラインにより複雑さが増し、データ サイエンティストによるデプロイの前に手動で行われる手順を自動化して、新しいモデルのトレーニングと検証をする必要があります。
本番環境: ML モデルは、最適化されていないコーディングだけでなく、絶えず変化するデータ プロファイルのためにパフォーマンスが低下する可能性があります。つまり、従来のソフトウェア システムよりも多くの方法でモデルが劣化する可能性があるため、このような性能低下を考慮する必要があります。そのため、データの概要統計を追跡し、モデルのオンライン パフォーマンスをモニタリングして、値が想定と異なる場合に通知を送信またはロールバックする必要があります。
ソース管理、単体テスト、統合テストの継続的インテグレーション(CI)、およびソフトウェア モジュールまたはパッケージの継続的デリバリー(CD)において、ML とその他のソフトウェア システムは類似しています。ただし、ML には次のような大きな違いがあります。
- CI では、コードとコンポーネントのテストと検証だけでなく、データ、データスキーマ、モデルのテストと検証も行います。
- CD は、単一のソフトウェア パッケージやサービスについではなく、別のサービス(モデル予測サービス)を自動的にデプロイするシステム(ML トレーニング パイプライン)です。
- CT は、ML システムに固有の新しいプロパティであり、自動的にモデルを再トレーニングして提供します。
次のセクションでは、予測サービスとして機能する ML モデルのトレーニングと評価の一般的な手順について説明します。
ML のデータ サイエンスの手順
ML プロジェクトでは、ビジネス ユースケースを定義して成功基準を確立した後、ML モデルを本番環境に提供するプロセスに次のステップが含まれます。これらの手順は、手動で実行することも、自動パイプラインで実行することもできます。
- データ抽出: ML タスクのさまざまなデータソースから関連データを選択して統合します。
- データ分析: 探索的データ分析(EDA)を実行して、ML モデルのビルドに使用できるデータを理解します。このプロセスは次のようになります。
- モデルで想定されるデータスキーマと特性を理解する。
- モデルに必要なデータ準備と特徴量エンジニアリングを特定する。
- データの準備: ML タスク用にデータを準備します。この準備では、データ クリーニングを行い、データをトレーニング、検証、テストセットに分割します。また、ターゲット タスクを解決するモデルにデータ変換と特徴量エンジニアリングを適用します。この手順の出力は、準備された形式のデータ分割です。
- モデルのトレーニング: データ サイエンティストは、準備したデータで異なるアルゴリズムを実装し、さまざまな ML モデルをトレーニングします。さらに、ハイパーパラメータ調整に実装されたアルゴリズムにより、最高性能の ML モデルを入手します。この手順の出力は、トレーニングされたモデルです。
- モデルの評価: モデルはホールドアウト テストセットにより品質が評価されます。この手順の出力は、モデルの品質を評価するための一連の指標です。
- モデルの検証: モデルがデプロイに適していること、つまり、予測性能が特定のベースラインより優れていることを確認します。
- モデルの提供: 検証済みのモデルがターゲット環境にデプロイされ、予測サービスが提供されます。このデプロイは次のいずれかになります。
- オンライン予測を提供する REST API を使用したマイクロサービス。
- エッジまたはモバイル デバイスへの組み込みモデル。
- バッチ予測システムの一部。
- モデルのモニタリング: モデルの予測性能をモニタリングし、ML プロセスで新しいイテレーションを必要に応じて呼び出します。
これらの手順の自動化レベルによって、ML プロセスの成熟度が決まります。これは、新しいデータの場合や新しい実装の場合での新しいモデルのトレーニング速度を反映します。以下のセクションでは、自動化を伴わない最も一般的なレベルから、ML と CI / CD パイプラインの自動化まで、3 つのレベルの MLOps について説明します。
MLOps レベル 0: 手動プロセス
多くの組織は、最先端のモデルをビルドできるデータ サイエンティストや ML 研究者を抱えていますが、ML モデルのビルドとデプロイのプロセスは完全に手動です。これは、基本レベルの成熟度(レベル 0)と見なされます。次の図は、このプロセスのワークフローを示しています。

図 2: 予測サービスとしてモデルを提供するための手動 ML ステップ。
特徴
図 2 に示した MLOps レベル 0 プロセスの特性は次のとおりです。
手動、スクリプト主導、インタラクティブなプロセス: データ分析、データ準備、モデル トレーニング、検証などの各手順は手動で行います。各手順を手動で実行し、手順間を手動で移行する必要があります。このプロセスは通常、実行可能なモデルが生成されるまで、データ サイエンティストがインタラクティブにノートブックに記述して実行する実験コードによって行われます。
ML とオペレーションの分離: このプロセスでは、モデルを作成するデータ サイエンティストと、予測サービスとしてモデルを提供するエンジニアを分離します。トレーニング済みのモデルは、データ サイエンティストからアーティファクトとしてエンジニアリング チームに引き渡され、API インフラストラクチャにデプロイされます。この引き渡しには、トレーニング済みモデルをストレージのロケーションに配置する、コード リポジトリに入れるモデル オブジェクトをチェックする、モデルをモデル レジストリにアップロードする、などがあります。次に、モデルをデプロイするエンジニアは、低レイテンシでのサービス提供のために必要な機能を本番環境で使用できるようにする必要があります。これにより、トレーニング サービング スキューが発生する可能性があります。
頻度の低いリリースのイテレーション: このプロセスでは、データ サイエンス チームが、変更(モデルの実装の変更や新しいデータによるモデルの再トレーニング)が頻繁に発生しない少数のモデルを管理することを前提としています。新しいモデル バージョンは年に数回しかデプロイされません。
CI なし: 実装の変更はほとんど想定されないため、CI は無視されます。通常、コードのテストは、ノートブックまたはスクリプト実行の一部です。テスト手順を実装するスクリプトとノートブックはソース管理されており、トレーニング済みモデル、評価指標、可視化などのアーティファクトが生成されます。
CD なし: モデル バージョンのデプロイは頻繁に行われないため、CD は考慮されません。
デプロイは予測サービスを意味する: このプロセスでは、ML システム全体のデプロイではなく、予測サービスとしてのトレーニング済みモデルのデプロイのみに関わります(たとえば、REST API を使用するマイクロサービス)。
アクティブなパフォーマンス モニタリングは行わない: このプロセスでは、モデルのパフォーマンス低下やその他のモデルの動作変動を検出するために必要なモデル予測とアクションを追跡または記録しません。
エンジニアリング チームは、API 構成、テスト、デプロイ(セキュリティ、リグレッション、負荷テスト、カナリアテストなど)について、独自の複雑な設定を行う場合があります。また、ML モデルの新しいバージョンの本番環境デプロイでは、通常、モデルがすべての予測リクエスト トラフィックを処理する前に、A/B テストやオンライン テストが行われます。
課題
MLOps レベル 0 は、ML をユースケースに適用しようとしている多くの企業において一般的です。モデルの変更やトレーニングがほとんど行われない場合、このマニュアル、データ サイエンティスト主導のプロセスで十分です。事実、モデルは、実際にデプロイされるとしばしば失敗します。モデルは、環境のダイナミクスの変化や環境を記述するデータの変更への適応に失敗します。詳しくは、本番環境において機械学習モデルが失敗する原因をご覧ください。
これらの課題に対処し、本番環境でモデルの精度を維持するには、次の操作を行う必要があります。
本番環境でモデルの品質を積極的にモニタリングする: モニタリングを使用すると、パフォーマンスの低下とモデルの古さを検出できます。これは、新たなテストのイテレーションと新しいデータに対するモデルの(手動)再トレーニングの手がかりとして機能します。
本番環境モデルを頻繁に再トレーニングする: 変化するパターンと新しいパターンをキャプチャするには、最新のデータでモデルを再トレーニングする必要があります。たとえば、アプリが ML を使用してファッション関連商品をおすすめしている場合は、最新のトレンドや商品に合わせておすすめ商品を表示させる必要があります。
新しい実装を継続的にテストして、モデルを生成する: 技術における最新のアイデアと進歩を取り入れるため、特徴量エンジニアリング、モデル アーキテクチャ、ハイパーパラメータなどの新しい実装を試行する必要があります。たとえば、顔検出においてコンピュータ ビジョンを使用する場合、顔のパターンは固定されますが、より良い新しい技術を使用すると検出精度を向上させることができます。
この手動プロセスの課題に対処するには、CI / CD と CT 向けの MLOps 手法が役立ちます。ML トレーニング パイプラインをデプロイすると、CT を有効にし、CI / CD システムを設定して、ML パイプラインの新しい実装を迅速にテスト、ビルド、デプロイできます。これらの機能については、次のセクションで詳しく説明します。
MLOps レベル 1: ML パイプラインの自動化
レベル 1 の目標は、ML パイプラインを自動化することにより、モデルの継続的トレーニングを実行することです。これにより、モデル予測サービスの継続的デリバリーを実現できます。新しいデータを使用して本番環境においてモデルを再トレーニングするプロセスを自動化するには、自動化されたデータとモデル検証の手順、およびパイプライン トリガーとメタデータ管理をパイプラインに導入する必要があります。
以下の図は、CT 用の自動化された ML パイプラインの概略的な表現です。

図 3: CT 用 ML パイプラインの自動化。
特徴
図 3 に示された MLOps レベル 1 の設定の特徴は次のとおりです。
迅速なテスト: ML テストの手順は統合されています。手順間の移動が自動化されることで、テストのイテレーションが迅速になり、パイプライン全体を本番環境に移行する準備が改善されます。
本番環境でのモデルの CT: 次のセクションで説明するライブ パイプライン トリガーに基づいて、新しいデータを使用して本番環境でモデルが自動的にトレーニングされます。
テストと運用の対称性: 開発環境またはテスト環境で使用されるパイプライン実装は、本番前環境と本番環境で使用されます。これは、DevOps を統合する MLOps 手法の重要な側面です。
コンポーネントとパイプライン用のモジュール化されたコード: ML パイプラインを構築するには、コンポーネントを再利用可能、構成可能で、場合によっては ML パイプライン間で共有できる必要があります。したがって、EDA コードはノートブック内に存在できますが、コンポーネントのソースコードはモジュール化する必要があります。また、コンポーネントは次の操作のためにコンテナ化するのが理想的です。
- 実行環境とカスタムコード ランタイムを分離する。
- 開発環境と本番環境の間でコードを再現可能にする。
- パイプライン内で各コンポーネントを分離する。各コンポーネントは、独自のバージョンのランタイム環境、異なる言語とライブラリを持つことができます。
モデルの継続的デリバリー: 本番環境の ML パイプラインは、新しいデータでトレーニングされた新しいモデルに予測サービスを継続的に提供します。オンライン予測用の予測サービスとしてトレーニング済みで検証済みのモデルを提供するモデルのデプロイ手順が自動化されます。
パイプラインのデプロイ: レベル 0 では、トレーニング済みモデルを予測サービスとして本番環境にデプロイします。レベル 1 の場合、トレーニング済みのモデルを予測サービスとして提供するために自動的に繰り返し実行されるトレーニング パイプライン全体をデプロイします。
追加コンポーネント
このセクションでは、ML の継続的トレーニングを有効にするためにアーキテクチャに追加する必要があるコンポーネントについて説明します。
データとモデルの検証
ML パイプラインを本番環境にデプロイすると、ML パイプライン トリガーのセクションで説明した 1 つ以上のトリガーによって自動的にパイプラインが実行されます。パイプラインは、新しいライブデータによって、新しいデータでトレーニングされる新しいモデル バージョンを生成することを想定しています(図 3 を参照)。そのため、本番環境のパイプラインでは、次の想定される動作を保証するために、データ検証とモデル検証の自動化手順を実行する必要があります。
データの検証: この手順はモデル トレーニングの前に必要です。モデルを再トレーニングするか、パイプラインの実行を停止するかを決定します。この決定は、パイプラインによって以下が識別された場合に自動的に行われます。
- データスキーマ スキュー: これらのスキューは入力データにおける異常値とみなされます。そのため、データ処理やモデル トレーニングなどのダウンストリーム パイプライン手順において、想定されるスキーマに準拠しない入力データが受信されます。この場合、パイプラインを停止して、データ サイエンス チームが調査する必要があります。チームは、パイプラインに修正やアップロードをリリースし、スキーマにおけるこれらの変更を処理する場合があります。スキーマのスキューには、予期されない特徴を受信すること、すべての予期される特徴を受信しないこと、予期されない値の特徴を受信することなどがあります。
- データ値のスキュー: これらのスキューは、データの統計的プロパティの重要な変化です。つまり、データパターンが変化しており、モデルの再トレーニングをトリガーして変化をキャプチャする必要があることを意味します。
モデルの検証: これは、新しいデータでのモデルのトレーニングが正常に終了した後の手順です。モデルを本番環境に進める前に評価と検証を行います。このオフライン モデル検証の手順は以下の通りです。
- トレーニング済みモデルをテスト データセットで使用して、評価指標値を生成し、モデルの予測品質を評価します。
- 新しいトレーニング済みのモデルにより生成された評価指標値を、現在のモデル(本番環境モデル、ベースライン モデル、その他のビジネス要件のモデルなど)と比較します。新しいモデルを本番環境に進める前に、現在のモデルよりもパフォーマンスが優れていることを確認します。
- モデルのパフォーマンスがデータのさまざまなセグメントで一貫していることを確認します。たとえば、新しくトレーニングされた顧客チャーンモデルの全体的な予測精度が、前のモデルと比較して向上している場合でも、顧客リージョンごとの精度値に大きな差異が出ることがあります。
- インフラストラクチャの互換性や予測サービス API との整合性など、デプロイするモデルを確実にテストします。
オフライン モデル検証に加えて、新しくデプロイされたモデルは、オンライン トラフィックの予測を提供する前に、オンライン モデル検証(カナリア デプロイや A/B テスト設定で)を受けます。
Feature Store
レベル 1 の ML パイプライン自動化用のオプションの追加コンポーネントは、Feature Store の 1 つです。Feature Store は、一元化されたリポジトリで、トレーニングと提供のために特徴の定義、保存、アクセスを標準化できます。Feature Store では、特徴値の高スループットのバッチでの提供と低レイテンシのリアルタイムでの提供の両方の API を指定し、トレーニングとサービス提供のワークロードの両方をサポートする必要があります。
Feature Store は、データ サイエンティストが以下を行うのをサポートします。
- (同じ特徴や類似の特徴の再作成ではなく)エンティティ用に使用可能な特徴を見つけ出し、再利用する。
- 特徴とそれに関連するメタデータを維持することで、定義が異なる類似した特徴の使用を避ける。
- Feature Store から最新の特徴値を提供する。
Feature Store を、テスト、継続的トレーニング、オンライン サービス提供のためのデータソースとして使用して、トレーニング サービング スキューを防ぐ。このアプローチにより、トレーニングで使用される特徴が、サービス提供時に使用される特徴と同じになります。
- データ サイエンティストは Feature Store からオフライン抽出を取得して、テストを実行できます。
- 継続的なトレーニングの場合、自動 ML トレーニング パイプラインは、トレーニング タスクに使用されるデータセットの最新の特徴値のバッチをフェッチできます。
- オンライン予測の場合、予測サービスは、リクエストされたエンティティに関連する特徴値(顧客の属性特徴、プロダクト特徴、現在のセッション集計特徴など)をバッチでフェッチできます。
- オンライン予測と特徴取得の場合、予測サービスはエンティティに関連する特徴を特定します。たとえば、エンティティが顧客の場合、関連する特徴には年齢、購入履歴、閲覧行動などがあります。サービスはこれらの特徴値をバッチ処理し、エンティティに必要なすべての特徴を個別ではなく、一度に取得します。この取得方法は、特に複数のエンティティを管理する必要がある場合に効率的です。
メタデータ管理
ML パイプラインの各実行についての情報は、データとアーティファクトのリネージ、再現、比較のために保存されます。また、エラーと異常値のデバッグにも役立ちます。パイプラインの実行のたびに、ML メタデータ ストアは次のメタデータを保存します。
- 実行されたパイプラインとコンポーネントのバージョン。
- パイプラインの各ステップの開始日時と終了日時、完了までかかった時間。
- パイプラインのエグゼキュータ。
- パイプラインに渡されたパラメータの引数。
- パイプラインの各手順で生成されたアーティファクトのポインタ(準備したデータのロケーション、検証での異常値、計算された統計値、カテゴリ特徴から抽出された語彙など)失敗した手順によりパイプラインが停止した場合、これらの中間出力を追跡することで、すでに終了した手順を再度実行することなく、直近の手順からパイプラインを再開できます。
- 以前のモデル バージョンにロールバックする必要がある場合や、モデル検証の手順でパイプラインに新しいテストデータが提供されたときに以前のモデル バージョンに評価指標を生成する必要がある場合、以前のトレーニング済みモデルへのポインタ。
- トレーニング セットとテストセットの両方のモデル評価の手順で生成されたモデル評価指標。これらの指標は、新しくトレーニングされたモデルのパフォーマンスを、モデル検証の手順で以前のモデルの記録されたパフォーマンスと比較するのに役立ちます。
ML パイプライン トリガー
ユースケースに応じて、ML の本番環境のパイプラインを自動化して、新しいデータでモデルを再トレーニングできます。
- オンデマンド: パイプラインのアドホック手動実行。
- スケジュールに従う: ラベル付きの新しいデータは、ML システムで毎日、毎週、または毎月利用できます。再トレーニングの頻度は、データパターンの変更頻度、およびモデルの再トレーニングの費用によっても異なります。
- 新しいトレーニング データが利用可能になったとき: ML システムでは、新しいデータは体系的に利用できるのではなく、新しいデータが収集されてソース データベースで利用可能になった時点でアドホック ベースで利用できるようになります。
- モデルのパフォーマンスが低下したとき: モデルは、パフォーマンスの低下が目立つようになったときに再トレーニングされます。
- データ分布の大幅な変化(コンセプトの変動)。オンライン モデルの全体的なパフォーマンスを評価することは困難ですが、予測を行うために使用される特徴のデータ分布の大きな変化は検知できます。このような変化は、モデルが古くなっていて、新しいデータで再トレーニングする必要があることを示しています。
課題
パイプラインの新しい実装が頻繁にはデプロイされず、少数のパイプラインのみを管理しているとします。このような場合は通常、パイプラインとそのコンポーネントを手動でテストします。また、新しいパイプライン実装を手動でデプロイします。また、パイプラインのテスト済ソースコードを IT チームに提出し、ターゲット環境へのデプロイも行います。新しい ML アイデアによるものではなく、新しいデータに基づく新しいモデルをデプロイするときに、この設定が適切です。
ただし、新しい ML アイデアを試し、ML コンポーネントの新しい実装を迅速にデプロイする必要があります。本番環境で多数の ML パイプラインを管理する場合は、ML パイプラインのビルド、テスト、デプロイを自動化する CI / CD 設定が必要です。
MLOps レベル 2: CI / CD パイプラインの自動化
本番環境でパイプラインを迅速かつ確実に更新するには、堅牢な自動 CI / CD システムが必要です。この自動化された CI / CD システムにより、データ サイエンティストは特徴量エンジニアリング、モデル アーキテクチャ、ハイパーパラメータに関する新しいアイデアを迅速に探索できます。これらのアイデアを実装し、新しいパイプライン コンポーネントをターゲット環境に自動的にビルド、テスト、デプロイできます。
次の図は、自動 ML パイプラインの設定と自動 CI / CD ルーチンの特性を備えた CI / CD を使用した ML パイプラインの実装を示しています。

図 4: CI / CD と自動 ML パイプライン。
この MLOps 設定には次のコンポーネントが含まれます。
- ソース管理
- サービスのテストとビルド
- デプロイ サービス
- モデル レジストリ
- Feature Store
- ML メタデータ ストア
- ML パイプライン オーケストレーター
特徴
次の図は、ML CI / CD 自動化パイプラインのステージを示しています。

図 5CI / CD 自動 ML パイプラインのステージ。
パイプラインは次のステージで構成されています。
開発とテスト: テスト手順が統合されている新しい ML アルゴリズムと新しいモデリングを繰り返し試行します。このステージの出力は、ML パイプライン手順のソースコードで、ソース リポジトリに push されます。
パイプラインの継続的インテグレーション: ソースコードをビルドし、さまざまなテストを実行します。このステージの出力は、後のステージでデプロイされるパイプライン コンポーネント(パッケージ、実行可能ファイル、アーティファクト)です。
パイプライン継続的デリバリー: CI ステージで生成されたアーティファクトをターゲット環境にデプロイします。このステージの出力は、モデルの新しい実装を含むデプロイされたパイプラインです。
自動トリガー: スケジュールに基づいて、またはトリガーに応じて、本番環境でパイプラインが自動的に実行されます。 このステージの出力は、モデル レジストリに push されるトレーニング済みモデルです。
モデルの継続的デリバリー: 予測のためにトレーニング済みモデルを予測サービスとして提供します。このステージの出力は、デプロイされたモデル予測サービスです。
モニタリング: ライブデータに基づいてモデルのパフォーマンスに関する統計情報を収集します。このステージの出力は、パイプラインを実行するトリガー、または新しいテストサイクルを実行するトリガーです。
データ分析の手順は、パイプラインがテストの新しいイテレーションを開始する前に、データ サイエンティストがなお手動で行うプロセスです。モデル分析の手順も手動で行います。
継続的インテグレーション
この設定では、新しいコードがソースコード リポジトリに commit または push されると、パイプラインとそのコンポーネントがビルド、テスト、パッケージ化されます。パッケージ、コンテナ イメージ、実行可能ファイルのビルドに加えて、CI プロセスには次のテストを含めることができます。
特徴量エンジニアリング ロジックの単体テスト。
モデルに実装されているさまざまなメソッドの単体テスト。たとえば、カテゴリデータ列を受け入れる関数があり、その関数をワンホット特徴としてエンコードします。
モデル トレーニングが収束することのテスト(つまり、モデルの損失がイテレーションによって減少し、いくつかのサンプル レコードを過学習します)。
ゼロ除算または大小の値を操作することにより、モデルのトレーニングで NaN 値が生成されないことのテスト。
パイプライン内の各コンポーネントが求められるアーティファクトを生成することのテスト。
パイプライン コンポーネント間の統合のテスト。
継続的デリバリー
このレベルでは、システムは新しいパイプライン実装をターゲット環境に継続的に提供し、ターゲット環境は新しくトレーニングされたモデルの予測サービスを提供します。パイプラインとモデルを迅速かつ信頼性の高い方法で継続的に配信するには、次の点を考慮してください。
モデルをデプロイする前に、モデルとターゲット インフラストラクチャの互換性を確認する。たとえば、モデルに必要なパッケージがサービス環境にインストールされていること、必要なメモリ、コンピューティング、アクセラレータのリソースが使用可能であることを確認する必要があります。
必要な入力でサービス API を呼び出して予測サービスをテストし、求めるレスポンスが得られることを確認する。このテストは通常、モデル バージョンの更新で異なった入力が必要な場合に発生する可能性のある問題をキャプチャします。
予測サービスのパフォーマンスをテストする。これには、秒間クエリ数(QPS)やモデル レイテンシなどの指標をキャプチャするサービスの負荷テストが含まれます。
再トレーニングまたはバッチ予測のためにデータを検証する。
モデルがデプロイされる前に、予測性能目標を満たしていることを確認する。
テスト環境への自動デプロイ。たとえば、コードを開発ブランチに push することによりトリガーされるデプロイ。
本番前環境への半自動デプロイ。たとえば、レビュー担当者が変更を承認した後にメインブランチにコードを結合することによってトリガーされるデプロイ。
本番前環境でパイプラインを数回正常に実行した後、本番環境に手動でデプロイする。
まとめると、本番環境に ML を実装することは、モデルを予測用の API としてデプロイすることを意味するだけではありません。これは、新しいモデルの再トレーニングとデプロイを自動化できる ML パイプラインをデプロイすることを意味します。CI / CD システムを設定すると、新しいパイプライン実装を自動的にテストしてデプロイできます。このシステムにより、データやビジネス環境の急速な変化に対応できます。すべてのプロセスをあるレベルから別のレベルにすぐに移行する必要はありません。これらの手法を段階的に実装して、ML システムの開発と本番環境の自動化を改善できます。
次のステップ
- TensorFlow Extended、Vertex AI Pipelines、Cloud Build を使用した MLOps のアーキテクチャの詳細を確認する。
- ML オペレーション(MLOps)の実践的な運用ガイドについて確認する。
- YouTube で Google Cloud の MLOps ベスト プラクティス(Cloud Next '19)を視聴する。
- Google Cloudの AI ワークロードと ML ワークロードに固有のアーキテクチャ原則と推奨事項の概要について、Well-Architected Framework の AI と ML の視点を確認する。
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。
寄稿者
著者:
- Jarek Kazmierczak | ソリューション アーキテクト
- Khalid Salama | スタッフ ソフトウェア エンジニア、ML
- Valentin Huerta | AI エンジニア
その他の寄稿者: Sunil Kumar Jang Bahadur | カスタマー エンジニア