Esegui codice PySpark nei notebook BigQuery Studio
Questo documento mostra come eseguire il codice PySpark in un notebook Python BigQuery.
Prima di iniziare
Se non l'hai ancora fatto, crea un progetto e un bucket Cloud Storage. Google Cloud
Configurare il progetto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Crea un bucket Cloud Storage nel tuo progetto se non ne hai uno da utilizzare.
Configurare il notebook
- Credenziali del notebook: per impostazione predefinita, la sessione del notebook utilizza le tue
credenziali utente. In alternativa, può utilizzare le credenziali dell'account di servizio della sessione.
- Credenziali utente: il tuo account utente deve avere i seguenti ruoli Identity and Access Management:
- Editor Dataproc (ruolo
roles/dataproc.editor) - Utente BigQuery Studio (ruolo
roles/bigquery.studioUser) - Ruolo Utente service account (roles/iam.serviceAccountUser)
nel service account di sessione.
Questo ruolo contiene l'autorizzazione
iam.serviceAccounts.actAsrichiesta per rappresentare l'account di servizio.
- Editor Dataproc (ruolo
- Credenziali del service account: se vuoi specificare le credenziali del account di servizio anziché le credenziali utente per la sessione del notebook, il service account per la sessione deve avere il seguente ruolo:
- Credenziali utente: il tuo account utente deve avere i seguenti ruoli Identity and Access Management:
- Runtime del notebook: il notebook utilizza un runtime Vertex AI predefinito a meno che tu non ne selezioni uno diverso. Se vuoi definire il tuo runtime, crealo dalla pagina Runtime nella console Google Cloud . Nota: quando utilizzi la libreria NumPy, utilizza la versione 1.26 di NumPy, supportata da Spark 3.5, nel runtime del notebook.
- Credenziali del notebook: per impostazione predefinita, la sessione del notebook utilizza le tue
credenziali utente. In alternativa, può utilizzare le credenziali dell'account di servizio della sessione.
Nella console Google Cloud , vai alla pagina BigQuery.
Nella barra delle schede del riquadro dei dettagli, fai clic sulla freccia accanto al segno +, quindi su Blocco note.
- Configura e crea una singola sessione nel notebook.
- Configura una sessione Spark in un modello di sessione interattiva, quindi utilizza il modello per configurare e creare una sessione nel blocco note.
BigQuery fornisce una funzionalità
Query using Sparkche ti aiuta a iniziare a codificare la sessione basata su modelli, come spiegato nella scheda Sessione Spark basata su modelli. Nella barra delle schede del riquadro dell'editor, fai clic sul menu a discesa a forma di freccia accanto al segno +, poi fai clic su Blocco note.
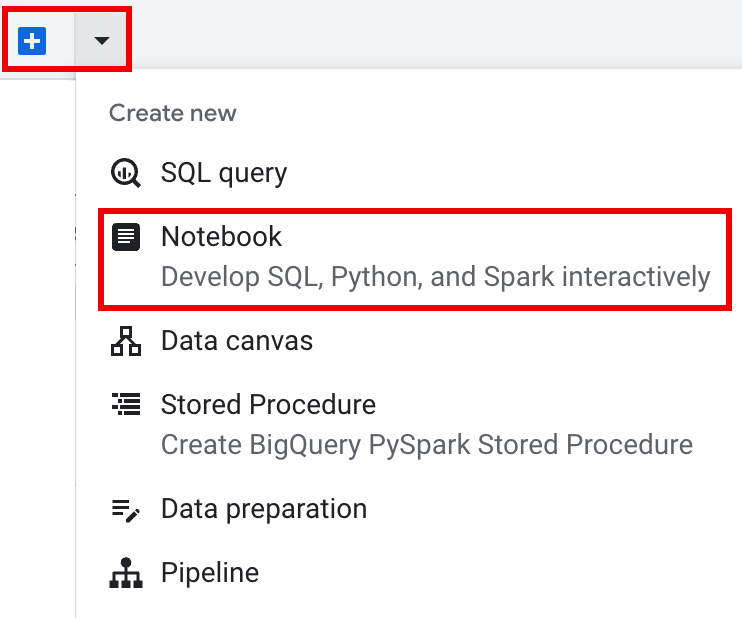
Copia ed esegui il seguente codice in una cella del notebook per configurare e creare una sessione Spark di base.
- APP_NAME: Un nome facoltativo per la sessione.
- (Facoltativo) Impostazioni sessione:puoi aggiungere le impostazioni dell'API Dataproc
Sessionper personalizzare la sessione. Ecco alcuni esempi:RuntimeConfig:
session.runtime_config.properties={spark.property.key1:VALUE_1,...,spark.property.keyN:VALUE_N}session.runtime_config.container_image = path/to/container/image
EnvironmentConfig: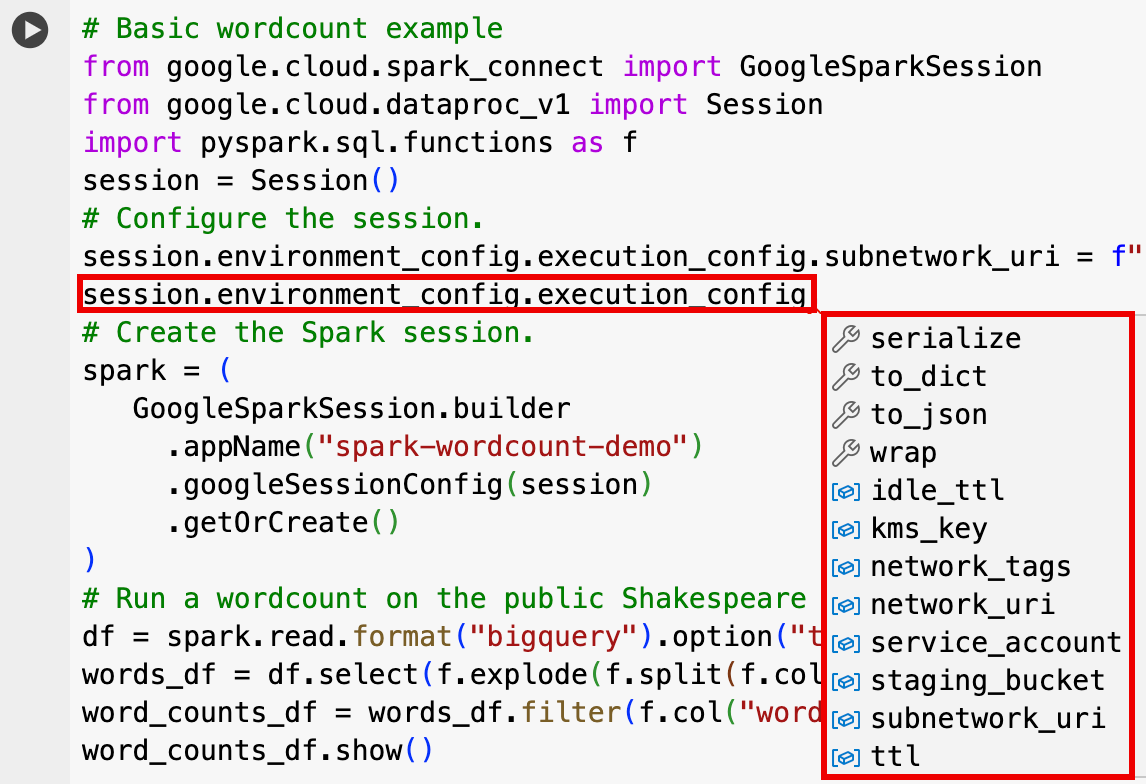
- session.environment_config.execution_config.subnetwork_uri = "SUBNET_NAME"
session.environment_config.execution_config.ttl = {"seconds": VALUE}session.environment_config.execution_config.service_account = SERVICE_ACCOUNT
- Nella barra delle schede del riquadro dell'editor, fai clic sul
menu a discesa a forma di freccia accanto al segno +, poi fai clic su
Blocco note.
- In Inizia con un modello, fai clic su Query con Spark, quindi fai clic su
Utilizza modello per inserire il codice nel notebook.
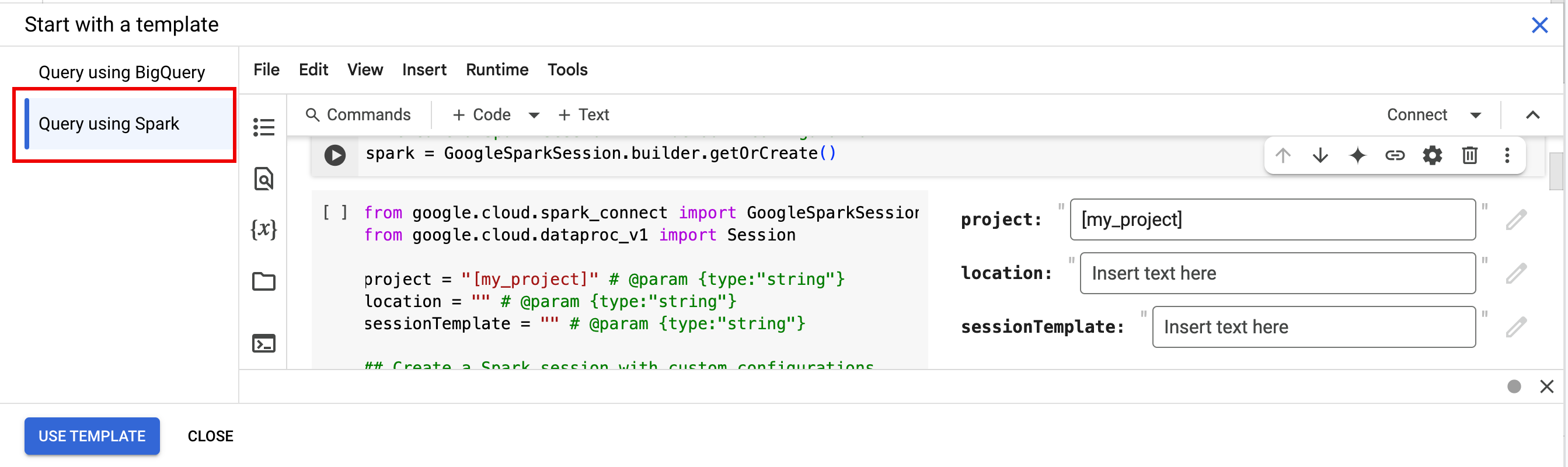
- Specifica le variabili come spiegato nelle Note.
- Puoi eliminare tutte le celle di codice campione aggiuntive inserite nel blocco note.
- PROJECT: l'ID progetto, elencato nella sezione Informazioni progetto della dashboard della consoleGoogle Cloud .
- LOCATION: la regione di Compute Engine in cui verrà eseguita la sessione del notebook. Se non viene fornita, la località predefinita è la regione della VM che crea il notebook.
SESSION_TEMPLATE: il nome di un template di sessione interattiva esistente. Le impostazioni di configurazione della sessione vengono ottenute dal modello. Il modello deve specificare anche le seguenti impostazioni:
- Versione runtime
2.3+ Tipo di notebook:
Spark ConnectEsempio:

- Versione runtime
APP_NAME: Un nome facoltativo per la sessione.
- Esegui un conteggio parole su un set di dati pubblico di Shakespeare.
- Crea una tabella Iceberg con i metadati salvati in BigLake Metastore.
- APP_NAME: Un nome facoltativo per la sessione.
- PROJECT: l'ID progetto, elencato nella sezione Informazioni progetto della dashboard della consoleGoogle Cloud .
- REGION e SUBNET_NAME: specifica la regione Compute Engine e il nome di una subnet nella regione della sessione. Serverless per Apache Spark abilita l'accesso privato Google (PGA) sulla subnet specificata.
- LOCATION: il valore predefinito
BigQuery_metastore_config.locationespark.sql.catalog.{catalog}.gcp_locationèUS, ma puoi scegliere qualsiasi località BigQuery supportata. - BUCKET e WAREHOUSE_DIRECTORY: il bucket Cloud Storage e la cartella utilizzati per la directory del warehouse Iceberg.
- CATALOG_NAME e NAMESPACE: il nome e lo spazio dei nomi del catalogo Iceberg si combinano per identificare la tabella Iceberg (
catalog.namespace.table_name). - APP_NAME: Un nome facoltativo per la sessione.
Nella console Google Cloud , vai alla pagina BigQuery.
Nel riquadro delle risorse del progetto, fai clic sul progetto, quindi fai clic sullo spazio dei nomi per elencare la tabella
sample_iceberg_table. Fai clic sulla tabella Dettagli per visualizzare le informazioni relative alla configurazione della tabella del catalogo aperto.I formati di input e output sono i formati standard delle classi Hadoop
InputFormateOutputFormatutilizzati da Iceberg.
Inserisci una nuova cella di codice facendo clic su + Codice nella barra degli strumenti. Nella nuova cella di codice viene visualizzato
Start coding or generate with AI. Fai clic su Genera.Nell'editor Genera, inserisci un prompt in linguaggio naturale e poi fai clic su
enter. Assicurati di includere la parola chiavesparkopysparknel prompt.Prompt di esempio:
create a spark dataframe from order_items and filter to orders created in 2024
Esempio di output:
spark.read.format("bigquery").option("table", "sqlgen-testing.pysparkeval_ecommerce.order_items").load().filter("year(created_at) = 2024").createOrReplaceTempView("order_items") df = spark.sql("SELECT * FROM order_items")Per consentire a Gemini Code Assist di recuperare tabelle e schemi pertinenti, attiva la sincronizzazione di Data Catalog per le istanze Dataproc Metastore.
Assicurati che il tuo account utente abbia accesso a Data Catalog, alle tabelle di query. Per farlo, assegna il ruolo
DataCatalog.Viewer.- Esegui
spark.stop()in una cella del notebook. - Termina il runtime nel notebook:
- Fai clic sul selettore del runtime e poi su Gestisci sessioni.

- Nella finestra di dialogo Sessioni attive, fai clic sull'icona di chiusura, quindi su Termina.

- Fai clic sul selettore del runtime e poi su Gestisci sessioni.
Pianifica il codice del notebook dalla console Google Cloud (si applicano i prezzi dei notebook).
Esegui il codice del notebook come workload batch (si applicano i prezzi di Serverless per Apache Spark).
- Pianifica il notebook.
- Se l'esecuzione del codice del notebook fa parte di un flusso di lavoro, pianifica il notebook nell'ambito di una pipeline.
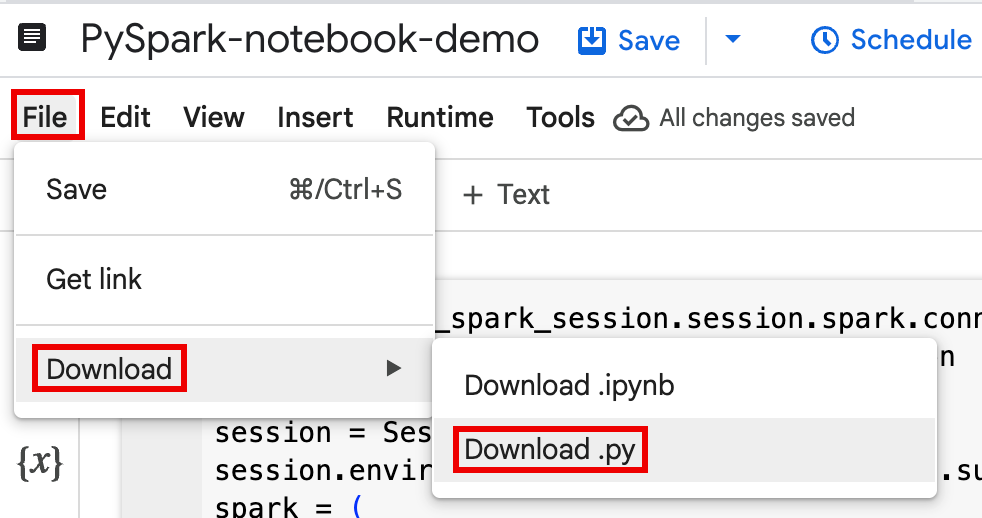
Scarica il codice del blocco note in un file in un terminale locale o in Cloud Shell.
Nella console Google Cloud , nella pagina BigQuery Studio, apri il blocco note nel riquadro Explorer.
Per espandere la barra dei menu, fai clic su keyboard_arrow_down Attiva/disattiva visualizzazione intestazione.
Fai clic su File > Scarica, quindi fai clic su Download.py.
Genera
requirements.txt.- Installa
pipreqsnella directory in cui hai salvato il file.py.pip install pipreqs
Esegui
pipreqsper generarerequirements.txt.pipreqs filename.py
Utilizza Google Cloud CLI per copiare il file
requirements.txtlocale in un bucket in Cloud Storage.gcloud storage cp requirements.txt gs://BUCKET/
- Installa
Aggiorna il codice della sessione Spark modificando il file
.pyscaricato.Rimuovi o commenta tutti i comandi dello script shell.
Rimuovi il codice che configura la sessione Spark, quindi specifica i parametri di configurazione come parametri di invio del carico di lavoro batch. (vedi Inviare un carico di lavoro batch Spark).
Esempio:
Rimuovi la seguente riga di configurazione della subnet di sessione dal codice:
session.environment_config.execution_config.subnetwork_uri = "{subnet_name}"Quando esegui il carico di lavoro batch, utilizza il flag
--subnetper specificare la subnet.gcloud dataproc batches submit pyspark \ --subnet=SUBNET_NAME
Utilizza un semplice snippet di codice per la creazione della sessione.
Codice del blocco note campione scaricato prima della semplificazione.
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session
session = Session() spark = DataprocSparkSession \ .builder \ .appName("CustomSparkSession") .dataprocSessionConfig(session) \ .getOrCreate()
Codice del carico di lavoro batch dopo la semplificazione.
from pyspark.sql import SparkSession
spark = SparkSession \ .builder \ .getOrCreate()
Esegui il carico di lavoro batch.
Per istruzioni, consulta la sezione Inviare il carico di lavoro batch Spark.
Assicurati di includere il flag --deps-bucket per indicare il bucket Cloud Storage che contiene il file
requirements.txt.Esempio:
gcloud dataproc batches submit pyspark FILENAME.py \ --region=REGION \ --deps-bucket=BUCKET \ --version=2.3
Note:
- FILENAME: il nome del file di codice del notebook scaricato e modificato.
- REGION: la regione di Compute Engine in cui si trova il cluster.
- BUCKET Il nome del bucket Cloud Storage
che contiene il file
requirements.txt. --version: è selezionata la versione 2.3 di Spark Runtime per eseguire il carico di lavoro batch.
Esegui il commit del codice.
- Dopo aver testato il codice del batch, puoi eseguire il commit del file
.ipynbo.pynel repository utilizzando il clientgit, ad esempio GitHub, GitLab o Bitbucket, nell'ambito della pipeline CI/CD.
- Dopo aver testato il codice del batch, puoi eseguire il commit del file
Pianifica il tuo workload batch con Cloud Composer.
- Per istruzioni, consulta Esegui workload Serverless per Apache Spark con Cloud Composer.
- Video dimostrativo di YouTube: Unleashing the power of Apache Spark integrated with BigQuery.
- Utilizzare BigLake Metastore con Dataproc
- Utilizzare BigLake Metastore con Serverless per Apache Spark
Prezzi
Per informazioni sui prezzi, consulta la sezione Prezzi del runtime dei notebook di BigQuery.
Apri un notebook Python di BigQuery Studio
Crea una sessione Spark in un notebook BigQuery Studio
Puoi utilizzare un notebook Python di BigQuery Studio per creare una sessione interattiva Spark Connect. A ogni notebook BigQuery Studio può essere associata una sola sessione Spark attiva.
Puoi creare una sessione Spark in un notebook Python di BigQuery Studio nei seguenti modi:
Singola sessione
Per creare una sessione Spark in un nuovo notebook:
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )Sostituisci quanto segue:
Sessione Spark basata su un modello
Puoi inserire ed eseguire il codice in una cella del notebook per creare una sessione Spark basata su un template di sessione esistente. Qualsiasi impostazione di configurazione
sessionfornita nel codice del notebook sostituirà qualsiasi impostazione uguale impostata nel modello di sessione.Per iniziare rapidamente, utilizza il modello
Query using Sparkper precompilare il notebook con il codice del modello di sessione Spark:from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Configure the session with an existing session template. session_template = "SESSION_TEMPLATE" session.session_template = f"projects/{project}/locations/{location}/sessionTemplates/{session_template}" # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )Scrivere ed eseguire codice PySpark nel notebook BigQuery Studio
Dopo aver creato una sessione Spark nel notebook, utilizzala per eseguire il codice del notebook Spark nel notebook.
Supporto dell'API Spark Connect PySpark:la sessione del notebook Spark Connect supporta la maggior parte delle API PySpark, incluse DataFrame, Functions, e Column, ma non supporta SparkContext e RDD e altre API PySpark. Per ulteriori informazioni, vedi Che cosa è supportato in Spark 3.5.
Scritture dirette del notebook Spark Connect: le sessioni Spark in un notebook BigQuery Studio preconfigurano il connettore Spark BigQuery per eseguire scritture DIRETTE dei dati. Il metodo di scrittura DIRECT utilizza l'API BigQuery Storage Write, che scrive i dati direttamente in BigQuery; il metodo di scrittura INDIRECT, che è il valore predefinito per i batch Serverless per Apache Spark, scrive i dati in un bucket Cloud Storage intermedio, quindi li scrive in BigQuery (per ulteriori informazioni sulle scritture INDIRECT, consulta Leggere e scrivere dati da e in BigQuery).
API specifiche di Dataproc: Dataproc semplifica l'aggiunta dinamica di pacchetti
PyPIalla sessione Spark estendendo il metodoaddArtifacts. Puoi specificare l'elenco nel formatoversion-scheme, (simile apip install). In questo modo, il server Spark Connect installa i pacchetti e le relative dipendenze su tutti i nodi del cluster, rendendoli disponibili ai worker per le tue UDF.Esempio che installa la versione
textdistancespecificata e le librerierandom2compatibili più recenti sul cluster per consentire l'esecuzione di UDF che utilizzanotextdistanceerandom2sui nodi worker.spark.addArtifacts("textdistance==4.6.1", "random2", pypi=True)Guida al codice del blocco note: il blocco note BigQuery Studio fornisce assistenza per il codice quando tieni il puntatore sopra il nome di una classe o di un metodo e fornisce assistenza per il completamento del codice durante l'inserimento.
Nel seguente esempio, inserisci
DataprocSparkSession. e se tieni il puntatore sopra il nome della classe, vengono visualizzati il completamento del codice e la guida alla documentazione.
Esempi di PySpark per i notebook BigQuery Studio
Questa sezione fornisce esempi di notebook Python di BigQuery Studio con codice PySpark per eseguire le seguenti attività:
Wordcount
L'esempio Pyspark seguente crea una sessione Spark, quindi conta le occorrenze delle parole in un set di dati pubblico
bigquery-public-data.samples.shakespeare.# Basic wordcount example from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Run a wordcount on the public Shakespeare dataset. df = spark.read.format("bigquery").option("table", "bigquery-public-data.samples.shakespeare").load() words_df = df.select(f.explode(f.split(f.col("word"), " ")).alias("word")) word_counts_df = words_df.filter(f.col("word") != "").groupBy("word").agg(f.count("*").alias("count")).orderBy("word") word_counts_df.show()Sostituisci quanto segue:
Output:
L'output della cella elenca un campione dell'output del conteggio parole. Per visualizzare i dettagli della sessione nella console Google Cloud , fai clic sul link Visualizzazione dettagli sessione interattiva. Per monitorare la sessione Spark, fai clic su Visualizza UI di Spark nella pagina dei dettagli della sessione.

Interactive Session Detail View: LINK +------------+-----+ | word|count| +------------+-----+ | '| 42| | ''All| 1| | ''Among| 1| | ''And| 1| | ''But| 1| | ''Gamut'| 1| | ''How| 1| | ''Lo| 1| | ''Look| 1| | ''My| 1| | ''Now| 1| | ''O| 1| | ''Od's| 1| | ''The| 1| | ''Tis| 4| | ''When| 1| | ''tis| 1| | ''twas| 1| | 'A| 10| |'ARTEMIDORUS| 1| +------------+-----+ only showing top 20 rows
Tavolo Iceberg
Esegui il codice PySpark per creare una tabella Iceberg con i metadati di BigLake Metastore
Il seguente codice di esempio crea un
sample_iceberg_tablecon metadati della tabella archiviati in BigLake Metastore, quindi esegue query sulla tabella.from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f # Create the Dataproc Serverless session. session = Session() # Set the session configuration for BigLake Metastore with the Iceberg environment. project_id = "PROJECT" region = "REGION" subnet_name = "SUBNET_NAME" location = "LOCATION" session.environment_config.execution_config.subnetwork_uri = f"{subnet_name}" warehouse_dir = "gs://BUCKET/WAREHOUSE_DIRECTORY" catalog = "CATALOG_NAME" namespace = "NAMESPACE" session.runtime_config.properties[f"spark.sql.catalog.{catalog}"] = "org.apache.iceberg.spark.SparkCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.catalog-impl"] = "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_project"] = f"{project_id}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_location"] = f"{location}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.warehouse"] = f"{warehouse_dir}" # Create the Spark Connect session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Create the namespace in BigQuery. spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;") # Create the Iceberg table. spark.sql("DROP TABLE IF EXISTS `sample_iceberg_table`"); spark.sql("CREATE TABLE sample_iceberg_table (id int, data string) USING ICEBERG;") spark.sql("DESCRIBE sample_iceberg_table;") # Insert table data and query the table. spark.sql("INSERT INTO sample_iceberg_table VALUES (1, \"first row\");") # Alter table, then query and display table data and schema. spark.sql("ALTER TABLE sample_iceberg_table ADD COLUMNS (newDoubleCol double);") spark.sql("DESCRIBE sample_iceberg_table;") df = spark.sql("SELECT * FROM sample_iceberg_table") df.show() df.printSchema()Note:
L'output della cella elenca
sample_iceberg_tablecon la colonna aggiunta e mostra un link alla pagina Dettagli sessione interattiva nella console Google Cloud . Puoi fare clic su Visualizza UI di Spark nella pagina dei dettagli della sessione per monitorare la tua sessione Spark.
Interactive Session Detail View: LINK +---+---------+------------+ | id| data|newDoubleCol| +---+---------+------------+ | 1|first row| NULL| +---+---------+------------+ root |-- id: integer (nullable = true) |-- data: string (nullable = true) |-- newDoubleCol: double (nullable = true)
Visualizzare i dettagli della tabella in BigQuery
Per controllare i dettagli della tabella Iceberg in BigQuery:
Altri esempi
Crea uno Spark
DataFrame(sdf) da un DataFrame Pandas (df).sdf = spark.createDataFrame(df) sdf.show()Esegui aggregazioni su Spark
DataFrames.from pyspark.sql import functions as F sdf.groupby("segment").agg( F.mean("total_spend_per_user").alias("avg_order_value"), F.approx_count_distinct("user_id").alias("unique_customers") ).show()Leggi da BigQuery utilizzando il connettore Spark-BigQuery.
spark.conf.set("viewsEnabled","true") spark.conf.set("materializationDataset","my-bigquery-dataset") sdf = spark.read.format('bigquery') \ .load(query)Scrivere codice Spark con Gemini Code Assist
Puoi chiedere a Gemini Code Assist di generare codice PySpark nel tuo notebook. Gemini Code Assist recupera e utilizza tabelle BigQuery e Dataproc Metastore pertinenti e i relativi schemi per generare una risposta di codice.
Per generare codice Gemini Code Assist nel tuo notebook:
Suggerimenti per la generazione di codice con Gemini Code Assist
Terminare la sessione Spark
Puoi eseguire una delle seguenti azioni per interrompere la sessione Spark Connect nel notebook BigQuery Studio:
Orchestrare il codice del notebook BigQuery Studio
Puoi orchestrare il codice del notebook BigQuery Studio nei seguenti modi:
Pianificare il codice del notebook dalla console Google Cloud
Puoi programmare il codice del notebook nei seguenti modi:
Esegui il codice del notebook come carico di lavoro batch
Completa i seguenti passaggi per eseguire il codice del notebook BigQuery Studio come carico di lavoro batch.
Risolvere gli errori del notebook
Se si verifica un errore in una cella contenente codice Spark, puoi risolvere il problema facendo clic sul link Visualizzazione dettagli sessione interattiva nell'output della cella (vedi gli esempi di tabella Wordcount e Iceberg).
Problemi noti e soluzioni
Errore: un runtime del notebook creato con la versione Python
3.10può causare un errorePYTHON_VERSION_MISMATCHquando tenta di connettersi alla sessione Spark.Soluzione: ricrea il runtime con Python versione
3.11.Passaggi successivi