クエリの実行
このドキュメントでは、BigQuery でクエリを実行する方法と、ドライランを実行して、クエリの実行前に処理されるデータの量を把握する方法について説明します。
クエリの種類
次のいずれかの種類のクエリジョブを使用して、BigQuery データをクエリできます。
インタラクティブ クエリジョブ。デフォルトでは、BigQuery はクエリをインタラクティブ クエリジョブとして実行します。このジョブは、できるだけ早く実行を開始することを目的としています。
バッチ クエリジョブ。バッチクエリは、インタラクティブ クエリよりも優先度が低くなります。プロジェクトまたは予約で利用可能なコンピューティング リソースがすべて使用されている場合、バッチクエリはキューに追加され、キュー内に残る可能性が高くなります。実行の開始後は、バッチクエリとインタラクティブ クエリの動作に違いはありません。詳細については、クエリキューをご覧ください。
継続的クエリジョブ。これらのジョブでは、クエリが継続的に実行されるため、BigQuery で受信データをリアルタイムで分析し、結果を BigQuery テーブルに書き込むか、Bigtable または Pub/Sub にエクスポートできます。この機能を使用すると、分析情報の作成と即時対応、リアルタイムの ML 推論の適用、イベント ドリブン データ パイプラインの構築など、時間的制約があるタスクを実行できます。
クエリジョブは、次の方法で実行できます。
- Google Cloud コンソールでクエリを作成して実行します。
- bq コマンドライン ツールで
bq queryコマンドを実行します。 - プログラムで BigQuery REST API の
jobs.queryまたはjobs.insertメソッドを呼び出す。 - BigQuery クライアント ライブラリを使用します。
BigQuery は、クエリ結果を一時テーブル(デフォルト)または永続テーブルに保存します。結果の宛先テーブルとして永続テーブルを指定する場合は、既存のテーブルを追加または上書きするか、一意の名前で新しいテーブルを作成するかを選択できます。
必要なロール
クエリジョブを実行するために必要な権限を取得するには、管理者に次の IAM ロールを付与するよう依頼してください。
-
プロジェクトに対する BigQuery ジョブユーザー(
roles/bigquery.jobUser)。 -
クエリが参照するすべてのテーブルとビューに対する BigQuery データ閲覧者(
roles/bigquery.dataViewer)。ビューにクエリを実行するには、基になるすべてのテーブルとビューに対するこのロールも必要です。承認済みビューまたは承認済みデータセットを使用している場合は、基になるソースデータにアクセスする必要はありません。
ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
これらの事前定義ロールには、クエリジョブの実行に必要な権限が含まれています。必要とされる正確な権限については、「必要な権限」セクションを開いてご確認ください。
必要な権限
クエリジョブを実行するには、次の権限が必要です。
-
クエリを実行するプロジェクトに対する
bigquery.jobs.create。データの保存場所は関係ありません。 -
クエリが参照するすべてのテーブルとビューに対する
bigquery.tables.getData。ビューにクエリを実行するには、基になるすべてのテーブルとビューに対するこの権限も必要です。承認済みビューまたは承認済みデータセットを使用している場合は、基になるソースデータにアクセスする必要はありません。
カスタムロールや他の事前定義ロールを使用して、これらの権限を取得することもできます。
トラブルシューティング
Access Denied: Project [project_id]: User does not have bigquery.jobs.create
permission in project [project_id].
このエラーは、プロジェクトでクエリジョブを作成する権限がプリンシパルにない場合に発生します。
解決策: 管理者が、クエリを実行するプロジェクトに対する bigquery.jobs.create 権限を付与する必要があります。クエリされたデータへのアクセスに必要な権限に加えて、この権限が必要になります。
BigQuery の権限の詳細については、IAM でのアクセス制御をご覧ください。
インタラクティブ クエリを実行する
インタラクティブ クエリを実行するには、次のいずれかのオプションを選択します。
コンソール
[BigQuery] ページに移動します。
[ SQL クエリ] をクリックします。
クエリエディタで、有効な GoogleSQL のクエリを入力します。
たとえば、BigQuery 一般公開データセット
usa_namesに対してクエリを実行し、1910 年から 2013 年の間に米国で最も多くつけられた名前を特定します。SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;または、[リファレンス] パネルを使用して新しいクエリを作成することもできます。
省略可: クエリを入力するときにコード候補を自動的に表示するには、 [その他] をクリックして、[SQL 予測入力] を選択します。予測入力の候補が必要ない場合は、[SQL 予測入力] の選択を解除します。これにより、プロジェクト名の自動入力候補もオフになります。
省略可: その他のクエリの設定を選択するには、 [その他]、[クエリの設定] の順にクリックします。
[ 実行] をクリックします。
宛先テーブルを指定しない場合、クエリジョブは出力を一時(キャッシュ)テーブルに書き込みます。
これで、[クエリ結果] ペインの [結果] タブでクエリ結果を確認できるようになりました。
省略可: クエリ結果を列で並べ替えるには、列名の横にある [並べ替えメニューを開く] をクリックし、並べ替え順を選択します。並べ替えた内容の推定バイト数が 0 より大きい場合は、メニューの一番上にバイト数が表示されます。
省略可: クエリ結果を可視化するには、[可視化] タブに移動します。グラフの拡大や縮小、PNG ファイルとしてグラフのダウンロード、凡例の表示の切り替えができます。
[可視化の構成] ペインでは、可視化タイプを変更し、可視化のメジャーとディメンションを構成できます。このペインのフィールドには、クエリの宛先テーブル スキーマから推定された初期構成が事前に入力されています。構成は、同じクエリエディタでの次のクエリ実行の間で保持されます。
可視化タイプが折れ線グラフ、棒グラフ、または散布図の場合、サポートされているディメンションは
INT64、FLOAT64、NUMERIC、BIGNUMERIC、TIMESTAMP、DATE、DATETIME、TIME、STRINGのデータ型で、サポートされているメジャーはINT64、FLOAT64、NUMERIC、BIGNUMERICのデータ型です。クエリ結果に
GEOGRAPHY型が含まれている場合、デフォルトの可視化タイプは地図になります。これにより、インタラクティブな地図で結果を可視化できます。省略可: [JSON] タブで、JSON 形式のクエリ結果を確認できます。ここで、キーは列名、値はその列の結果です。
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
bq queryコマンドを使用します。次の例では、--use_legacy_sql=falseフラグにより GoogleSQL の構文を使用できます。bq query \ --use_legacy_sql=false \ 'QUERY'
QUERY は、有効な GoogleSQL クエリに置き換えます。たとえば、BigQuery 一般公開データセット
usa_namesに対してクエリを実行し、1910 年から 2013 年の間に米国で最も多くつけられた名前を特定します。bq query \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'クエリジョブは、出力を一時(キャッシュ)テーブルに書き込みます。
必要に応じて、クエリ結果の宛先テーブルとロケーションを指定できます。結果を既存のテーブルに書き込むには、テーブルを追加(
--append_table=true)または上書き(--replace=true)する適切なフラグを指定します。bq query \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
次のように置き換えます。
LOCATION: 宛先テーブルのリージョンまたはマルチリージョン(例:
US)この例では、
usa_namesデータセットは米国のマルチリージョン ロケーションに保存されています。このクエリの宛先テーブルを指定する場合は、宛先テーブルを含むデータセットも US マルチリージョンに存在する必要があります。あるロケーションのデータセットに対するクエリを実行して、結果を別のロケーションにあるテーブルに書き込むことはできません。.bigqueryrc ファイルを使用してロケーションのデフォルト値を設定できます。
TABLE: 宛先テーブルの名前(例:
myDataset.myTable)宛先テーブルが新しいテーブルの場合、クエリを実行すると BigQuery によってテーブルが作成されます。ただし、既存のデータセットを指定する必要があります。
テーブルが現在のプロジェクトにない場合は、
PROJECT_ID:DATASET.TABLEの形式でGoogle Cloud プロジェクト ID を追加します(例:myProject:myDataset.myTable)。--destination_tableを指定しない場合、出力を一時テーブルに書き込むクエリジョブが生成されます。
API
API を使用してクエリを実行するには、新しいジョブを挿入して query ジョブ構成プロパティに値を設定します。必要に応じて、ジョブリソースの jobReference セクションにある location プロパティでロケーションを指定します。
getQueryResults を呼び出して結果を取得します。jobComplete が true と等しくなるまで取得を続けます。エラーと警告は、errors リストで確認してください。
C#
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある C# の設定手順を完了してください。詳細については、BigQuery C# API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Go
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Go の設定手順を完了してください。詳細については、BigQuery Go API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
プロキシを使用してクエリを実行するには、プロキシの構成をご覧ください。
Node.js
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Node.js の設定手順を完了してください。詳細については、BigQuery Node.js API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
PHP
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある PHP の設定手順を完了してください。詳細については、BigQuery PHP API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Ruby
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Ruby の設定手順を完了してください。詳細については、BigQuery Ruby API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
バッチクエリを実行する
バッチクエリを実行するには、次のいずれかのオプションを選択します。
コンソール
[BigQuery] ページに移動します。
[ SQL クエリ] をクリックします。
クエリエディタで、有効な GoogleSQL のクエリを入力します。
たとえば、BigQuery 一般公開データセット
usa_namesに対してクエリを実行し、1910 年から 2013 年の間に米国で最も多くつけられた名前を特定します。SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;[ 展開] をクリックして、[クエリの設定] をクリックします。
[リソース管理] セクションで、[バッチ] を選択します。
省略可: クエリ設定を調整します。
[保存] をクリックします。
[ 実行] をクリックします。
宛先テーブルを指定しない場合、クエリジョブは出力を一時(キャッシュ)テーブルに書き込みます。
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
bq queryコマンドを使用して、--batchフラグを指定します。次の例では、--use_legacy_sql=falseフラグにより GoogleSQL の構文を使用できます。bq query \ --batch \ --use_legacy_sql=false \ 'QUERY'
QUERY は、有効な GoogleSQL クエリに置き換えます。たとえば、BigQuery 一般公開データセット
usa_namesに対してクエリを実行し、1910 年から 2013 年の間に米国で最も多くつけられた名前を特定します。bq query \ --batch \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'クエリジョブは、出力を一時(キャッシュ)テーブルに書き込みます。
必要に応じて、クエリ結果の宛先テーブルとロケーションを指定できます。結果を既存のテーブルに書き込むには、テーブルを追加(
--append_table=true)または上書き(--replace=true)する適切なフラグを指定します。bq query \ --batch \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
次のように置き換えます。
LOCATION: 宛先テーブルのリージョンまたはマルチリージョン(例:
US)この例では、
usa_namesデータセットは米国のマルチリージョン ロケーションに保存されています。このクエリの宛先テーブルを指定する場合は、宛先テーブルを含むデータセットも US マルチリージョンに存在する必要があります。あるロケーションのデータセットに対するクエリを実行して、結果を別のロケーションにあるテーブルに書き込むことはできません。.bigqueryrc ファイルを使用してロケーションのデフォルト値を設定できます。
TABLE: 宛先テーブルの名前(例:
myDataset.myTable)宛先テーブルが新しいテーブルの場合、クエリを実行すると BigQuery によってテーブルが作成されます。ただし、既存のデータセットを指定する必要があります。
テーブルが現在のプロジェクトにない場合は、
PROJECT_ID:DATASET.TABLEの形式でGoogle Cloud プロジェクト ID を追加します(例:myProject:myDataset.myTable)。--destination_tableを指定しない場合、出力を一時テーブルに書き込むクエリジョブが生成されます。
API
API を使用してクエリを実行するには、新しいジョブを挿入して query ジョブ構成プロパティに値を設定します。必要に応じて、ジョブリソースの jobReference セクションにある location プロパティでロケーションを指定します。
クエリジョブのプロパティにデータを入力する場合、configuration.query.priority プロパティを含めて、値を BATCH に設定します。
getQueryResults を呼び出して結果を取得します。jobComplete が true と等しくなるまで取得を続けます。エラーと警告は、errors リストで確認してください。
Go
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Go の設定手順を完了してください。詳細については、BigQuery Go API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Java
バッチクエリを実行するには、QueryJobConfiguration の作成時に、クエリの優先度の設定を QueryJobConfiguration.Priority.BATCH にします。
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Node.js
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Node.js の設定手順を完了してください。詳細については、BigQuery Node.js API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
継続的クエリを実行する
連継続的クエリジョブを実行するには、追加の構成が必要です。詳細については、継続的クエリを作成するをご覧ください。
[リファレンス] パネルを使用する
クエリエディタの [リファレンス] パネルには、テーブル、スナップショット、ビュー、マテリアライズド ビューに関するコンテキストに応じた情報が動的に表示されます。このパネルで、これらのリソースのスキーマの詳細をプレビューし、リソースを新しいタブで開くことができます。また、[リファレンス] パネルを使用して、クエリ スニペットやフィールド名を挿入して新しいクエリを作成または既存のクエリを編集することもできます。
[リファレンス] パネルを使用して新しいクエリを作成する手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[ SQL クエリ] をクリックします。
[quick_reference_all リファレンス] をクリックします。
最近使用した、またはスター付きのテーブルまたはビューをクリックします。検索バーを使用してテーブルとビューを検索することもできます。
[ アクションを表示] をクリックし、[クエリ スニペットを挿入] をクリックします。
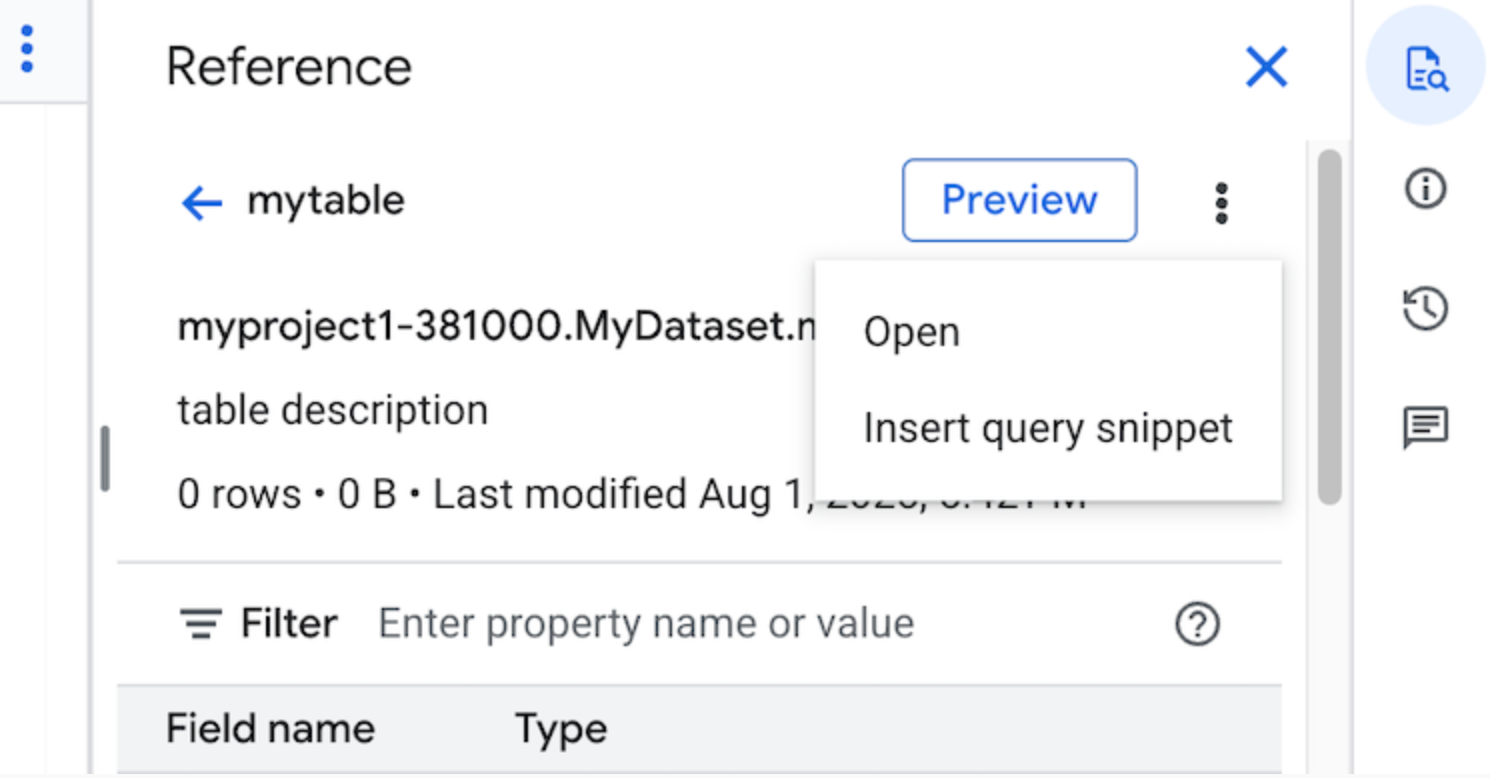
省略可: テーブルまたはビューのスキーマの詳細をプレビューするか、それらを新しいタブで開くことができます。
クエリを手動で編集するか、フィールド名をクエリに直接挿入できるようになりました。フィールド名を挿入するには、クエリエディタでフィールド名を挿入する場所をポイントしてクリックしてから、[リファレンス] パネルでフィールド名をクリックします。
クエリの設定
クエリを実行するときに、次の設定を指定できます。
クエリ結果の宛先テーブル。
ジョブの優先度。
キャッシュに保存されたクエリ結果を使用するかどうか。
ジョブのタイムアウト(ミリ秒)。
セッション モードを使用するかどうか。
使用する暗号化のタイプ。
クエリに対して課金される最大バイト数。
使用する SQL 言語。
クエリを実行するロケーション。クエリは、クエリで参照されるテーブルと同じロケーションで実行する必要があります。
オプション ジョブ作成モード
オプション ジョブ作成モードを使用すると、ダッシュボードやデータ探索ワークロードなどの実行時間の短いクエリの全体的なレイテンシを改善できます。このモードでは、クエリを実行して SELECT ステートメントの結果をインラインで返します。結果を取得するために jobs.getQueryResults を使用する必要はありません。オプション ジョブ作成モードを使用するクエリは、BigQuery がクエリを完了するためにジョブの作成が必要と判断しない限り、実行時にジョブを作成しません。
オプション ジョブ作成モードを有効にするには、jobs.query リクエスト本文で QueryRequest インスタンスの jobCreationMode フィールドを JOB_CREATION_OPTIONAL に設定します。
このフィールドの値が JOB_CREATION_OPTIONAL に設定されている場合、BigQuery はクエリでオプション ジョブ作成モードを使用できるかどうかを判断します。使用できる場合、BigQuery はクエリを実行し、レスポンスの rows フィールドにすべての結果を返します。このクエリ用にジョブが作成されていないため、BigQuery はレスポンス本文に jobReference を返しません。代わりに、queryId フィールドが返されます。このフィールドでは、INFORMATION_SCHEMA.JOBS ビューを使用してクエリに関する分析情報を取得できます。ジョブは作成されないため、これらのクエリを検索するために jobs.get API と jobs.getQueryResults API に渡す jobReference はありません。
BigQuery がクエリを完了するためにジョブが必要であると判断した場合は、jobReference が返されます。INFORMATION_SCHEMA.JOBS ビューの job_creation_reason フィールドを調べると、クエリに対してジョブが作成された理由を確認できます。この場合は、クエリが完了したときに jobs.getQueryResults を使用して結果を取得する必要があります。
JOB_CREATION_OPTIONAL 値を使用する場合、jobReference フィールドがレスポンスに存在しないことがあります。フィールドにアクセスする前に、フィールドが存在するかどうかを確認してください。
複数ステートメント クエリ(スクリプト)に JOB_CREATION_OPTIONAL が指定されている場合、BigQuery は実行プロセスを最適化することがあります。この最適化の一環として、BigQuery は、個々のステートメントの数よりも少ない数のジョブリソースを作成してスクリプトを完了できると判断するか、ジョブを作成せずにスクリプト全体を実行する場合があります。この最適化は、BigQuery によるスクリプトの評価に依存し、すべてのケースで適用されるとは限りません。最適化はシステムによって完全に自動化されています。ユーザーによる制御やアクションは必要ありません。
オプション ジョブ作成モードを使用してクエリを実行するには、次のいずれかのオプションを選択します。
コンソール
[BigQuery] ページに移動します。
[ SQL クエリ] をクリックします。
クエリエディタで、有効な GoogleSQL のクエリを入力します。
たとえば、BigQuery 一般公開データセット
usa_namesに対してクエリを実行し、1910 年から 2013 年の間に米国で最も多くつけられた名前を特定します。SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;[ その他] をクリックし、[オプション ジョブ作成] クエリモードを選択します。[確認] をクリックして選択内容を確定します。
[ 実行] をクリックします。
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
bq queryコマンドを使用して、--job_creation_mode=JOB_CREATION_OPTIONALフラグを指定します。次の例では、--use_legacy_sql=falseフラグにより GoogleSQL の構文を使用できます。bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=LOCATION \ 'QUERY'
QUERY は有効な GoogleSQL クエリに置き換え、LOCATION はデータセットが配置されている有効なリージョンに置き換えます。たとえば、BigQuery 一般公開データセット
usa_namesに対してクエリを実行し、1910 年から 2013 年の間に米国で最も多くつけられた名前を特定します。bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=us \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'クエリジョブは、レスポンスで出力をインラインで返します。
API
API を使用してオプション ジョブ作成モードでクエリを実行するには、クエリを同期的に実行し、QueryRequest プロパティに値を設定します。jobCreationMode プロパティを指定して、値を JOB_CREATION_OPTIONAL に設定します。
レスポンスを確認します。jobComplete が true と等しく、jobReference が空の場合は、rows フィールドから結果を読み取ります。レスポンスから queryId を取得することもできます。
jobReference が存在する場合は、jobCreationReason で BigQuery によってジョブが作成された理由を確認できます。getQueryResults を呼び出して結果をポーリングします。jobComplete が true と等しくなるまで取得を続けます。エラーと警告は、errors リストで確認してください。
Java
利用可能なバージョン: 2.51.0 以降
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
プロキシを使用してクエリを実行するには、プロキシの構成をご覧ください。
Python
利用可能なバージョン: 3.34.0 以降
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Node.js
利用可能なバージョン: 8.1.0 以降
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Node.js の設定手順を完了してください。詳細については、BigQuery Node.js API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Go
利用可能なバージョン: 1.69.0 以降
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Go の設定手順を完了してください。詳細については、BigQuery Go API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
JDBC ドライバ
利用可能なバージョン: JDBC v1.6.1 以降
接続文字列に JobCreationMode=2 を設定する必要があります。
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;JobCreationMode=2;Location=US;
ODBC ドライバ
利用可能なバージョン: ODBC v3.0.7.1016 以降
.ini ファイルに JobCreationMode=2 を設定する必要があります。
[ODBC Data Sources] Sample DSN=Simba Google BigQuery ODBC Connector 64-bit [Sample DSN] JobCreationMode=2
割り当て
インタラクティブ クエリとバッチクエリの割り当てについては、クエリジョブをご覧ください。
クエリのモニタリング
実行中のクエリに関する情報は、ジョブ エクスプローラを使用するか、INFORMATION_SCHEMA.JOBS_BY_PROJECT ビューをクエリすることで取得できます。
ドライラン
BigQuery のドライランでは、次の情報が提供されます。
- オンデマンド モードでの料金の見積もり
- クエリの検証
- キャパシティ モードでクエリによって処理されたおおよそのバイト数
ドライランはクエリスロットを使用しないため、ドライランの実行に対しては課金されません。ドライランによって返された見積もりを料金計算ツールで使用すると、クエリの費用を計算できます。
ドライランの実行
ドライランを実行するには、次の操作を行います。
コンソール
BigQuery ページに移動します。
クエリエディタにクエリを入力します。
クエリが有効な場合、クエリで処理されるデータの量とともにチェックマークが自動的に表示されます。クエリが無効な場合は、感嘆符がエラー メッセージとともに表示されます。
bq
--dry_run フラグを使用して次のようなクエリを入力します。
bq query \ --use_legacy_sql=false \ --dry_run \ 'SELECT COUNTRY, AIRPORT, IATA FROM `project_id`.dataset.airports LIMIT 1000'
有効なクエリの場合、このコマンドによって次のレスポンスが生成されます。
Query successfully validated. Assuming the tables are not modified, running this query will process 10918 bytes of data.
API
API を使用してドライランを実行するには、JobConfiguration タイプで dryRun を true に設定してクエリジョブを送信します。
Go
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Go の設定手順を完了してください。詳細については、BigQuery Go API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Node.js
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Node.js の設定手順を完了してください。詳細については、BigQuery Node.js API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
PHP
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある PHP の設定手順を完了してください。詳細については、BigQuery PHP API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Python
QueryJobConfig.dry_run プロパティを True に設定します。ドライランのクエリ構成が渡されると、Client.query() は常に完了した QueryJob を返します。
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
次のステップ
- クエリジョブを管理する方法を学習する。
- クエリ履歴を表示する方法を学習する。
- クエリの保存と共有の方法を学習する。
- クエリキューについて学習する。
- クエリ結果を書き込む方法を学習する。