Incorporato nei job di query, BigQuery include informazioni sul piano e sulla tempistica della query diagnostica. È simile alle informazioni fornite da istruzioni come EXPLAIN in altri sistemi di database e di analisi. Queste
informazioni possono essere recuperate dalle risposte API di metodi come
jobs.get.
Per le query a esecuzione prolungata, BigQuery aggiornerà periodicamente queste statistiche. Questi aggiornamenti vengono eseguiti indipendentemente dalla frequenza con cui viene eseguito il polling dello stato del job, ma in genere non vengono eseguiti più di una volta ogni 30 secondi. Inoltre, i job di query che non utilizzano risorse di esecuzione, come richieste di prova o risultati che possono essere pubblicati dai risultati memorizzati nella cache, non includeranno le informazioni diagnostiche aggiuntive, anche se potrebbero essere presenti altre statistiche.
Sfondo
Quando BigQuery esegue un job di query, converte l'istruzione SQL dichiarativa in un grafico di esecuzione, suddiviso in una serie di fasi della query, che a loro volta sono composte da insiemi più granulari di passaggi di esecuzione. BigQuery utilizza un'architettura parallela altamente distribuita per eseguire queste query. Le fasi modellano le unità di lavoro che molti potenziali worker possono eseguire in parallelo. Le fasi comunicano tra loro utilizzando un'architettura di rimescolamento distribuito veloce.
All'interno del piano di query, i termini unità di lavoro e worker vengono utilizzati per trasmettere
informazioni specifiche sul parallelismo. In altre parti di BigQuery, potresti incontrare il termine slot, che è una rappresentazione astratta di più aspetti dell'esecuzione delle query, tra cui risorse di calcolo, memoria e I/O. Le statistiche dei job di primo livello forniscono la
stima del costo della singola query utilizzando la stima totalSlotMs della query
utilizzando questa contabilità astratta.
Un'altra proprietà importante dell'architettura di esecuzione delle query è che è dinamica, il che significa che il piano di query può essere modificato durante l'esecuzione di una query. Le fasi introdotte durante l'esecuzione di una query vengono spesso utilizzate per migliorare la distribuzione dei dati tra i worker di query. Nei piani di query in cui si verifica questa situazione, queste fasi sono in genere etichettate come fasi di ripartizione.
Oltre al piano di query, i job di query espongono anche una cronologia di esecuzione, che fornisce un conteggio delle unità di lavoro completate, in attesa e attive all'interno dei worker di query. Una query può avere più fasi con worker attivi contemporaneamente e la sequenza temporale ha lo scopo di mostrare l'avanzamento complessivo della query.
Visualizzare le informazioni con la console Google Cloud
Nella consoleGoogle Cloud , puoi visualizzare i dettagli del piano di query per una query completata facendo clic sul pulsante Dettagli esecuzione (vicino al pulsante Risultati).
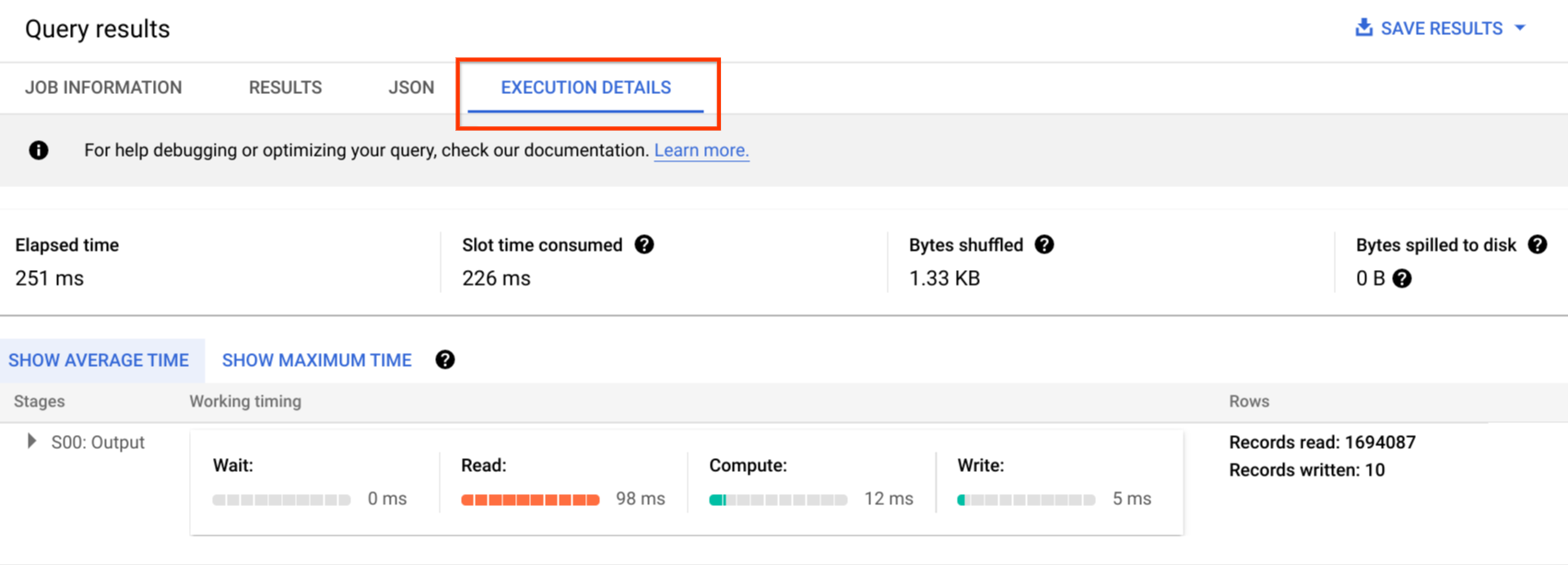
Informazioni sul piano di query
All'interno della risposta dell'API, i piani di query sono rappresentati come un elenco di fasi della query. Ogni elemento dell'elenco mostra statistiche di riepilogo per fase, informazioni dettagliate sui passaggi e classificazioni dei tempi delle fasi. Non tutti i dettagli vengono visualizzati nella console Google Cloud , ma possono essere tutti presenti nelle risposte dell'API.
Panoramica dello stage
I campi di riepilogo per ogni fase possono includere quanto segue:
| Campo API | Descrizione |
|---|---|
id |
ID numerico univoco per lo stage. |
name |
Nome riepilogativo semplice per la fase. Il steps all'interno della fase fornisce ulteriori dettagli sui passaggi di esecuzione. |
status |
Stato di esecuzione della fase. Gli stati possibili sono PENDING, RUNNING, COMPLETE, FAILED e CANCELLED. |
inputStages |
Un elenco degli ID che formano il grafico delle dipendenze della fase. Ad esempio, una fase JOIN spesso richiede due fasi dipendenti che preparano i dati sul lato sinistro e destro della relazione JOIN. |
startMs |
Timestamp, in millisecondi dell'epoca, che rappresenta il momento in cui è iniziata l'esecuzione del primo worker all'interno della fase. |
endMs |
Timestamp, in millisecondi dell'epoca, che rappresenta il momento in cui l'ultimo worker ha completato l'esecuzione. |
steps |
Un elenco più dettagliato dei passaggi di esecuzione all'interno della fase. Per saperne di più, consulta la sezione successiva. |
recordsRead |
Dimensione dell'input della fase come numero di record, in tutti i worker della fase. |
recordsWritten |
Dimensione dell'output dello stage come numero di record, in tutti i worker dello stage. |
parallelInputs |
Numero di unità di lavoro parallelizzabili per la fase. A seconda della fase e della query, questo valore può rappresentare il numero di segmenti colonnari all'interno di una tabella o il numero di partizioni all'interno di un rimescolamento intermedio. |
completedParallelInputs |
Numero di unità di lavoro all'interno della fase completate. Per alcune query, non è necessario completare tutti gli input all'interno di una fase per completarla. |
shuffleOutputBytes |
Rappresenta il totale dei byte scritti in tutti i worker all'interno di una fase della query. |
shuffleOutputBytesSpilled |
Le query che trasmettono una quantità significativa di dati tra le fasi potrebbero dover ricorrere alla trasmissione basata su disco. La statistica dei byte con overflow comunica la quantità di dati con overflow su disco. Dipende da un algoritmo di ottimizzazione, quindi non è deterministico per una determinata query. |
Classificazione dei tempi per fase
Le fasi della query forniscono classificazioni temporali delle fasi, in forma relativa e assoluta. Poiché ogni fase di esecuzione rappresenta il lavoro svolto da uno o più worker indipendenti, le informazioni vengono fornite sia in termini di tempi medi che di tempi nel caso peggiore. Questi tempi rappresentano le prestazioni medie di tutti i worker in una fase, nonché le prestazioni del worker più lento nella coda lunga per una determinata classificazione. I tempi medi e massimi sono ulteriormente suddivisi in rappresentazioni assolute e relative. Per le statistiche basate sul rapporto, i dati vengono forniti come frazione del tempo più lungo trascorso da qualsiasi lavoratore in qualsiasi segmento.
La console Google Cloud presenta la tempistica dello spettacolo utilizzando le rappresentazioni relative della tempistica.
Le informazioni sui tempi delle fasi vengono riportate nel seguente modo:
| Tempi relativi | Temporizzazione assoluta | Numeratore del rapporto |
|---|---|---|
waitRatioAvg |
waitMsAvg |
Tempo medio trascorso da un lavoratore in attesa di essere programmato. |
waitRatioMax |
waitMsMax |
Tempo trascorso in attesa della pianificazione dal worker più lento. |
readRatioAvg |
readMsAvg |
Tempo impiegato dal lavoratore medio per leggere i dati di input. |
readRatioMax |
readMsMax |
Tempo impiegato dal worker più lento per leggere i dati di input. |
computeRatioAvg |
computeMsAvg |
Tempo medio in cui il worker è stato vincolato alla CPU. |
computeRatioMax |
computeMsMax |
Tempo in cui il worker più lento ha utilizzato la CPU. |
writeRatioAvg |
writeMsAvg |
Tempo impiegato dal worker medio per scrivere i dati di output. |
writeRatioMax |
writeMsMax |
Tempo impiegato dal worker più lento per scrivere i dati di output. |
Panoramica del passaggio
I passaggi contengono le operazioni eseguite da ogni worker all'interno di una fase, presentate come un elenco ordinato di operazioni. Ogni operazione di passaggio ha una categoria e alcune operazioni forniscono informazioni più dettagliate. Le categorie di operazioni presenti nel piano di query includono quanto segue:
| Categoria del passaggio | Descrizione |
|---|---|
READ |
Lettura di una o più colonne da una tabella di input o da uno shuffling intermedio. Nei dettagli del passaggio vengono restituite solo le prime sedici colonne lette. |
WRITE |
Scrittura di una o più colonne in una tabella di output o in uno shuffling intermedio. Per gli output partizionati HASH di una fase, sono incluse anche le colonne utilizzate come chiave di partizione. |
COMPUTE |
Valutazione delle espressioni e funzioni SQL. |
FILTER |
Utilizzato dalle clausole WHERE, OMIT IF e HAVING. |
SORT |
ORDER BY operazione che include le chiavi di colonna e l'ordine di ordinamento. |
AGGREGATE |
Implementa le aggregazioni per clausole come GROUP BY o COUNT, tra le altre. |
LIMIT |
Implementa la clausola LIMIT. |
JOIN |
Implementa i join per clausole come JOIN, tra le altre; include il tipo di join e, possibilmente, le condizioni di join. |
ANALYTIC_FUNCTION |
Un'invocazione di una funzione finestra (nota anche come "funzione analitica"). |
USER_DEFINED_FUNCTION |
Un'invocazione a una funzione definita dall'utente'utente. |
Comprendere i dettagli del passaggio
BigQuery fornisce Dettagli passaggio che spiegano cosa ha fatto ogni passaggio all'interno di una fase. Comprendere i passaggi di una fase è necessario per identificare l'origine dei problemi di prestazioni delle query.
Per trovare i dettagli dei passaggi di una fase:
Nel riquadro Risultati delle query, fai clic su Grafico di esecuzione.

Fai clic sulla fase che ti interessa per aprire un pannello con le informazioni correlate.
Nel riquadro con le informazioni sulla fase, vai alla sezione Dettagli del passaggio.
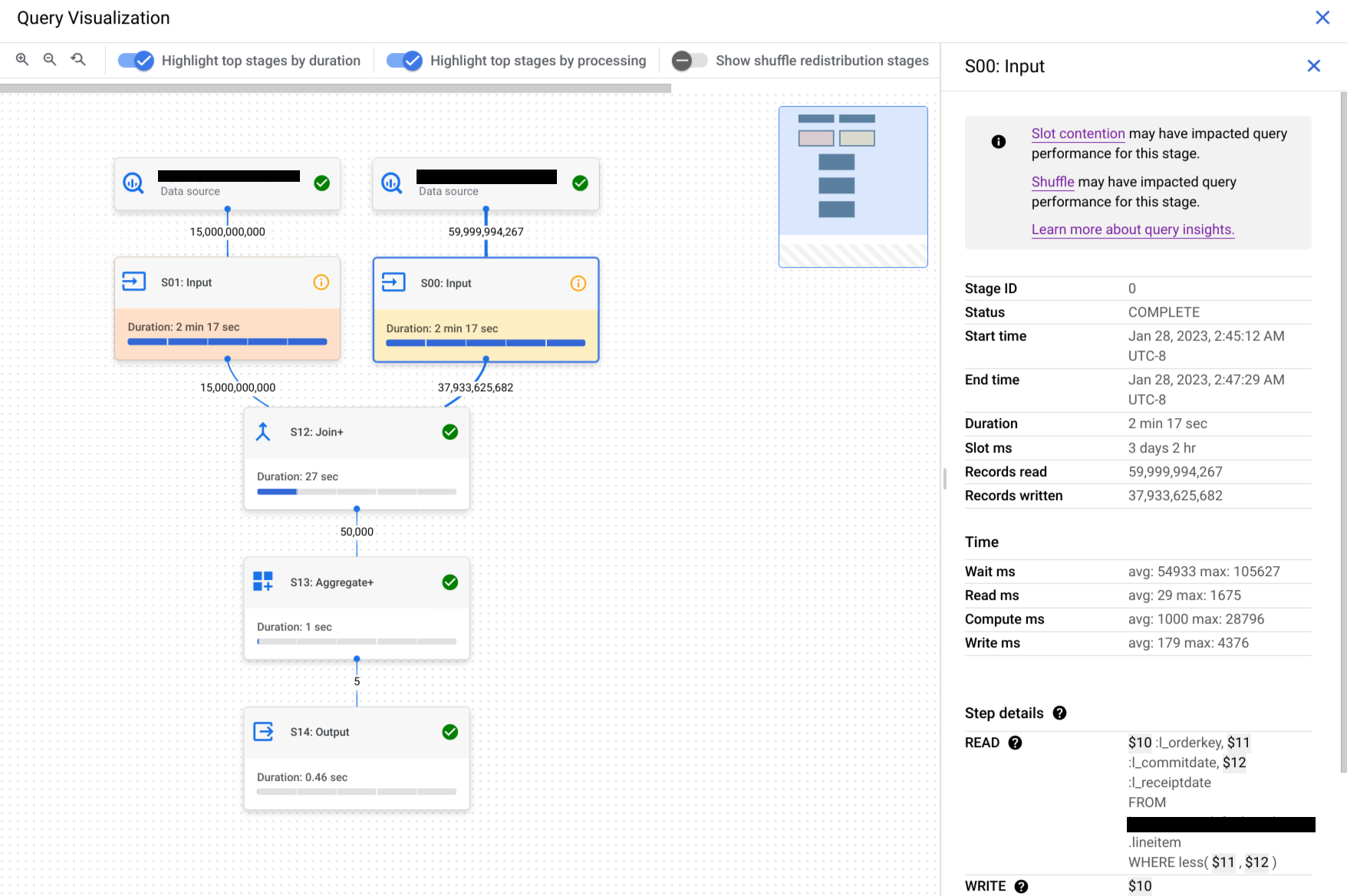
Ogni passaggio è costituito da sottopassaggi che descrivono l'operazione eseguita. I passaggi secondari utilizzano variabili per descrivere le relazioni tra i passaggi. Le variabili iniziano con un segno di dollaro seguito da un numero univoco.
Ecco un esempio dei dettagli del passaggio di una fase con variabili condivise tra i passaggi:
READ $30:l_orderkey, $31:l_quantity FROM lineitem AGGREGATE GROUP BY $100 := $30 $70 := SUM($31) WRITE $100, $70 TO __stage00_output BY HASH($100)
I dettagli del passaggio dell'esempio eseguono le seguenti operazioni:
Lo stage ha letto le colonne
l_orderkeyel_quantitydalla tabellalineitemutilizzando rispettivamente le variabili$30e$31.La fase aggregata sulle variabili
$30e$31, memorizzando le aggregazioni nelle variabili$100e$70, rispettivamente.Lo stage ha scritto i risultati delle variabili
$100e$70da rimescolare. La fase utilizzata$100per ordinare i risultati della fase in modo casuale.
BigQuery potrebbe troncare i dettagli del passaggio quando il grafico di esecuzione della query era sufficientemente complesso da causare problemi di dimensioni del payload durante il recupero delle informazioni sulla query se fossero stati forniti dettagli completi del passaggio della fase.
Comprendere i passaggi con il testo della query
Per assistenza durante l'anteprima, invia un'email all'indirizzo bq-query-inspector-feedback@google.com.
Comprendere la relazione tra i passaggi della fase e la query può essere difficile. La sezione Testo della query mostra la relazione tra alcuni passaggi e il testo della query originale.
La sezione Testo della query evidenzia diverse parti del testo della query originale e mostra i passaggi che rimandano al testo della query immediatamente precedente al testo della query originale evidenziato. Solo i passaggi immediatamente sopra una parte evidenziata del testo della query originale si applicano al testo della query evidenziata.

L'esempio di screenshot mostra questi mapping:
Il passaggio
AGGREGATE: GROUP BY $100 := $30corrisponde al testo della queryselect l_orderkey.Il passaggio
READ: FROM lineitemcorrisponde al testo della queryselect ... from lineitem.Il passaggio
AGGREGATE: $70 := SUM($31)corrisponde al testo della querysum(l_quantity).
Non tutti i passaggi possono essere mappati nuovamente al testo della query.
Se una query utilizza viste e se i passaggi della fase hanno mappature al testo della query di una vista, la sezione Testo della query mostra il nome della vista e il testo della query della vista con le relative mappature. Tuttavia, se la visualizzazione viene eliminata o se
perdi l'bigquery.tables.get autorizzazione IAM
per la visualizzazione, la sezione Testo della query non mostra le mappature
delle fasi dello stage per la visualizzazione.
Interpretare e ottimizzare i passaggi
Le sezioni seguenti spiegano come interpretare i passaggi di un piano di query e forniscono modi per ottimizzare le query.
READ passaggio
Il passaggio READ indica che una fase sta accedendo ai dati per l'elaborazione. I dati possono essere
letti direttamente dalle tabelle a cui viene fatto riferimento in una query o dalla memoria di shuffling.
Quando vengono letti i dati di una fase precedente, BigQuery legge i dati dalla
memoria di shuffling. La quantità di dati scansionati influisce sui costi quando utilizzi slot on demand e sulle prestazioni quando utilizzi le prenotazioni.
Potenziali problemi di rendimento
- Scansione di grandi dimensioni di una tabella non partizionata: se la query richiede solo una piccola porzione dei dati, ciò potrebbe indicare che una scansione della tabella è inefficiente. Il partizionamento potrebbe essere una buona strategia di ottimizzazione.
- Scansione di una tabella di grandi dimensioni con un piccolo rapporto di filtro:ciò suggerisce che il filtro non riduce in modo efficace i dati scansionati. Valuta la possibilità di rivedere le condizioni del filtro.
- Byte di shuffling riversati su disco:questo suggerisce che i dati non sono memorizzati in modo efficace utilizzando tecniche di ottimizzazione come il clustering, che potrebbe mantenere dati simili nei cluster.
Ottimizza
- Filtro mirato:utilizza le clausole
WHEREin modo strategico per filtrare i dati irrilevanti il prima possibile nella query. In questo modo si riduce la quantità di dati che devono essere elaborati dalla query. - Partizionamento e clustering:BigQuery utilizza il partizionamento e il clustering delle tabelle per individuare in modo efficiente segmenti di dati specifici.
Assicurati che le tabelle siano partizionate e raggruppate in cluster in base ai pattern di query tipici per ridurre al minimo i dati scansionati durante i passaggi
READ. - Seleziona le colonne pertinenti:evita di utilizzare le istruzioni
SELECT *. Seleziona invece colonne specifiche o utilizzaSELECT * EXCEPTper evitare di leggere dati non necessari. - Viste materializzate:le viste materializzate possono precalcolare e archiviare
aggregazioni utilizzate di frequente, riducendo potenzialmente la necessità di leggere le tabelle
di base durante i passaggi
READper le query che utilizzano queste viste.
COMPUTE passaggio
Nel passaggio COMPUTE, BigQuery esegue le seguenti azioni sui
tuoi dati:
- Valuta le espressioni nelle clausole
SELECT,WHERE,HAVINGe altre della query, incluse operazioni logiche, confronti e calcoli. - Esegue funzioni SQL integrate e funzioni definite dall'utente.
- Filtra le righe di dati in base alle condizioni della query.
Ottimizza
Il piano di query può rivelare i colli di bottiglia nel passaggio COMPUTE. Cerca le fasi
con calcoli estesi o un numero elevato di righe elaborate.
- Correlare il passaggio
COMPUTEal volume di dati:se una fase mostra un calcolo significativo ed elabora un grande volume di dati, potrebbe essere un buon candidato per l'ottimizzazione. - Dati distorti: per le fasi in cui il massimo di calcolo è significativamente superiore alla media di calcolo, ciò indica che la fase ha trascorso una quantità di tempo sproporzionata a elaborare alcune sezioni di dati. Valuta la distribuzione dei dati per verificare se sono disallineati.
- Considera i tipi di dati:utilizza i tipi di dati appropriati per le colonne. Ad esempio, l'utilizzo di numeri interi, date e ore e timestamp anziché stringhe può migliorare le prestazioni.
WRITE passaggio
WRITE passaggi vengono eseguiti per i dati intermedi e l'output finale.
- Scrittura nella memoria di shuffling:in una query in più fasi, il passaggio
WRITEspesso comporta l'invio dei dati elaborati a un'altra fase per un'ulteriore elaborazione. Ciò è tipico della memoria di shuffling, che combina o aggrega i dati provenienti da più origini. I dati scritti durante questa fase sono in genere un risultato intermedio, non l'output finale. - Output finale:il risultato della query viene scritto nella destinazione o in una tabella temporanea.
Partizionamento hash
Quando una fase del piano di query scrive dati in un output partizionato con hash, BigQuery scrive le colonne incluse nell'output e la colonna scelta come chiave di partizionamento.
Ottimizza
Anche se il passaggio WRITE potrebbe non essere ottimizzato direttamente, comprenderne il ruolo può aiutarti a identificare potenziali colli di bottiglia nelle fasi precedenti:
- Ridurre al minimo i dati scritti:concentrati sull'ottimizzazione delle fasi precedenti con il filtraggio e l'aggregazione per ridurre la quantità di dati scritti durante questo passaggio.
Partizionamento:la scrittura trae grande vantaggio dal partizionamento delle tabelle. Se i dati che scrivi sono limitati a partizioni specifiche, BigQuery può eseguire scritture più veloci.
Se l'istruzione DML ha una clausola
WHEREcon una condizione statica rispetto a una colonna di partizione della tabella, BigQuery modifica solo le partizioni della tabella pertinenti.Compromessi della denormalizzazione:la denormalizzazione a volte può portare a set di risultati più piccoli nel passaggio intermedio
WRITE. Tuttavia, ci sono svantaggi come un maggiore utilizzo dello spazio di archiviazione e problemi di coerenza dei dati.
JOIN passaggio
Nel passaggio JOIN, BigQuery combina i dati di due origini dati.
I join possono includere condizioni di join. I join richiedono molte risorse. Quando esegui il join di grandi quantità di dati in BigQuery, le chiavi di join vengono rimescolate in modo indipendente per allinearsi allo stesso slot, in modo che il join venga eseguito localmente su ogni slot.
Il piano di query per il passaggio JOIN in genere rivela i seguenti dettagli:
- Pattern di join: indica il tipo di join utilizzato. Ogni tipo definisce il numero di righe delle tabelle unite incluse nel set di risultati.
- Colonne di unione:le colonne utilizzate per trovare corrispondenze tra le righe delle origini dati. La scelta delle colonne è fondamentale per le prestazioni del join.
Pattern di unione
- Broadcast join:quando una tabella, in genere quella più piccola, può essere inserita nella memoria di un singolo nodo o slot worker, BigQuery può trasmetterla a tutti gli altri nodi per eseguire il join in modo efficiente. Cerca
JOIN EACH WITH ALLnei dettagli del passaggio. - Unione hash:quando le tabelle sono grandi o un'unione broadcast non è adatta, potrebbe essere utilizzata un'unione hash. BigQuery utilizza operazioni di hashing e rimescolamento per rimescolare le tabelle sinistra e destra in modo che le chiavi corrispondenti finiscano nello stesso slot per eseguire un join locale. I join hash sono un'operazione costosa
poiché i dati devono essere spostati, ma consentono una corrispondenza
efficiente delle righe tra gli hash. Cerca
JOIN EACH WITH EACHnei dettagli del passaggio. - Self-join:un anti-pattern SQL in cui una tabella viene unita a se stessa.
- Cross join:un antipattern SQL che può causare problemi di prestazioni significativi perché genera dati di output più grandi rispetto agli input.
- Join asimmetrico: la distribuzione dei dati nella chiave di join di una tabella è molto asimmetrica e può causare problemi di prestazioni. Cerca i casi in cui il tempo di calcolo massimo è molto maggiore del tempo di calcolo medio nel piano di query. Per ulteriori informazioni, consulta Join ad alta cardinalità e Skew della partizione.
Debug
- Volume elevato di dati:se il piano di query mostra una quantità significativa di dati
elaborati durante il passaggio
JOIN, esamina la condizione di join e le chiavi di join. Valuta la possibilità di filtrare o utilizzare chiavi di unione più selettive. - Distribuzione dei dati asimmetrica:analizza la distribuzione dei dati delle chiavi di unione. Se una tabella è molto distorta, esplora strategie come la suddivisione della query o il prefiltraggio.
- Join con cardinalità elevata:i join che producono molte più righe rispetto al numero di righe di input a sinistra e a destra possono ridurre drasticamente le prestazioni delle query. Evita i join che producono un numero molto elevato di righe.
- Ordine errato della tabella:assicurati di aver scelto il tipo di join appropriato, ad esempio
INNERoLEFT, e di aver ordinato le tabelle dalla più grande alla più piccola in base ai requisiti della query.
Ottimizza
- Chiavi di join selettive:per le chiavi di join, utilizza
INT64anzichéSTRINGquando possibile. I confrontiSTRINGsono più lenti dei confrontiINT64perché confrontano ogni carattere di una stringa. I numeri interi richiedono un solo confronto. - Filtra prima dell'unione:applica i filtri della clausola
WHEREalle singole tabelle prima dell'unione. In questo modo, la quantità di dati coinvolti nell'operazione di join viene ridotta. - Evita le funzioni nelle colonne di unione:evita di chiamare le funzioni nelle colonne di unione. Standardizza invece i dati delle tabelle durante la procedura di importazione o post-importazione utilizzando le pipeline SQL ELT. Questo approccio elimina la necessità di modificare dinamicamente le colonne di unione, il che consente unioni più efficienti senza compromettere l'integrità dei dati.
- Evita i self-join: i self-join vengono comunemente utilizzati per calcolare le relazioni dipendenti dalle righe. Tuttavia, i self-join possono potenzialmente quadruplicare il numero di righe di output, causando problemi di prestazioni. Anziché fare affidamento sui self-join, valuta la possibilità di utilizzare le funzioni finestra (analitiche).
- Prima le tabelle di grandi dimensioni:anche se l'ottimizzatore di query SQL può determinare quale tabella deve trovarsi su quale lato del join, ordina le tabelle unite in modo appropriato. La best practice consiste nell'inserire prima la tabella più grande, poi quella più piccola e poi quelle di dimensioni decrescenti.
- Denormalizzazione:in alcuni casi, la denormalizzazione strategica delle tabelle (aggiunta di dati ridondanti) può eliminare completamente i join. Tuttavia, questo approccio comporta compromessi in termini di archiviazione e coerenza dei dati.
- Partizionamento e clustering: il partizionamento delle tabelle in base alle chiavi di join e il clustering dei dati collocati possono velocizzare notevolmente i join consentendo a BigQuery di scegliere come target le partizioni di dati pertinenti.
- Ottimizzazione dei join asimmetrici: per evitare problemi di prestazioni associati ai join asimmetrici, prefiltra i dati della tabella il prima possibile o suddividi la query in due o più query.
AGGREGATE passaggio
Nel passaggio AGGREGATE, BigQuery aggrega e raggruppa i dati.
Debug
- Dettagli fase:controlla il numero di righe di input e di output dell'aggregazione e la dimensione del rimescolamento per determinare la riduzione dei dati ottenuta dal passaggio di aggregazione e se è stato coinvolto il data shuffling.
- Dimensione shuffle:una dimensione shuffle elevata potrebbe indicare che una quantità significativa di dati è stata spostata tra i nodi worker durante l'aggregazione.
- Controlla la distribuzione dei dati:assicurati che i dati siano distribuiti in modo uniforme tra le partizioni. La distribuzione distorta dei dati può comportare carichi di lavoro sbilanciati nel passaggio di aggregazione.
- Rivedi le aggregazioni: analizza le clausole di aggregazione per verificare che siano necessarie ed efficienti.
Ottimizza
- Clustering:raggruppa le tabelle in cluster in base alle colonne utilizzate di frequente in
GROUP BY,COUNTo altre clausole di aggregazione. - Partizionamento:scegli una strategia di partizionamento in linea con i tuoi pattern di query. Valuta la possibilità di utilizzare tabelle partizionate per data di importazione per ridurre la quantità di dati scansionati durante l'aggregazione.
- Aggrega prima:se possibile, esegui le aggregazioni prima nella pipeline di query. In questo modo è possibile ridurre la quantità di dati da elaborare durante l'aggregazione.
- Ottimizzazione del rimescolamento: se il rimescolamento è un collo di bottiglia, esplora i modi per ridurlo al minimo. Ad esempio, denormalizza le tabelle o utilizza il clustering per collocare vicini i dati pertinenti.
Casi limite
- Aggregazioni DISTINCT:le query con aggregazioni
DISTINCTpossono essere costose dal punto di vista computazionale, soprattutto su set di dati di grandi dimensioni. Prendi in considerazione alternative comeAPPROX_COUNT_DISTINCTper risultati approssimativi. - Numero elevato di gruppi:se la query produce un numero elevato di gruppi, potrebbe consumare una quantità significativa di memoria. In questi casi, valuta la possibilità di limitare il numero di gruppi o di utilizzare una strategia di aggregazione diversa.
REPARTITION passaggio
REPARTITION e COALESCE sono tecniche di ottimizzazione che BigQuery applica direttamente ai dati rimescolati nella query.
REPARTITION: questa operazione ha lo scopo di ribilanciare la distribuzione dei dati tra i nodi worker. Supponiamo che, dopo il rimescolamento, un nodo worker finisca per avere una quantità di dati sproporzionatamente grande. Il passaggioREPARTITIONridistribuisce i dati in modo più uniforme, impedendo a un singolo worker di diventare un collo di bottiglia. Ciò è particolarmente importante per le operazioni a elevato consumo di risorse di calcolo come i join.COALESCE: questo passaggio si verifica quando hai molti piccoli bucket di dati dopo il rimescolamento. Il passaggioCOALESCEcombina questi bucket in bucket più grandi, riducendo l'overhead associato alla gestione di numerosi piccoli pezzi di dati. Ciò può essere particolarmente utile quando si ha a che fare con set di risultati intermedi molto piccoli.
Se nel piano di query vengono visualizzati i passaggi REPARTITION o COALESCE, non
significa necessariamente che ci sia un problema con la query. Spesso è un segnale che
BigQuery sta ottimizzando in modo proattivo la distribuzione dei dati per migliorare
le prestazioni. Tuttavia, se visualizzi queste operazioni ripetutamente, potrebbe indicare
che i tuoi dati sono intrinsecamente distorti o che la tua query sta causando un rimescolamento eccessivo dei dati.
Ottimizza
Per ridurre il numero di passaggi di REPARTITION, prova a:
- Distribuzione dei dati:assicurati che le tabelle siano partizionate e raggruppate in modo efficace. I dati ben distribuiti riducono la probabilità di squilibri significativi dopo il rimescolamento.
- Struttura della query:analizza la query per individuare potenziali fonti di distorsione dei dati. Ad esempio, esistono filtri o join altamente selettivi che comportano l'elaborazione di un piccolo sottoinsieme di dati su un singolo worker?
- Strategie di unione:prova diverse strategie di unione per vedere se portano a una distribuzione dei dati più equilibrata.
Per ridurre il numero di passaggi di COALESCE, prova a:
- Strategie di aggregazione:valuta la possibilità di eseguire le aggregazioni prima nella pipeline di query. Ciò può contribuire a ridurre il numero di piccoli set di risultati intermedi
che potrebbero causare passaggi
COALESCE. - Volume di dati:se hai a che fare con set di dati molto piccoli,
COALESCEpotrebbe non essere un problema significativo.
Non ottimizzare eccessivamente. L'ottimizzazione prematura potrebbe rendere le query più complesse senza produrre vantaggi significativi.
Spiegazione delle query federate
Le query federate ti consentono di inviare un'istruzione di query a un'origine dati esterna utilizzando la funzione EXTERNAL_QUERY.
Le query federate sono soggette alla tecnica di ottimizzazione nota come pushdown SQL e il piano di query mostra le operazioni eseguite nell'origine dati esterna, se presente. Ad esempio, se esegui la query seguente:
SELECT id, name
FROM EXTERNAL_QUERY("<connection>", "SELECT * FROM company")
WHERE country_code IN ('ee', 'hu') AND name like '%TV%'
Il piano di query mostrerà i seguenti passaggi della fase:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, country_code
FROM (
/*native_query*/
SELECT * FROM company
)
WHERE in(country_code, 'ee', 'hu')
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
In questo piano, table_for_external_query_$_0(...) rappresenta la funzione
EXTERNAL_QUERY. Tra parentesi puoi vedere la query eseguita dall'origine dati esterna. In base a questo, puoi notare che:
- Un'origine dati esterna restituisce solo tre colonne selezionate.
- Un'origine dati esterna restituisce solo le righe per le quali
country_codeè'ee'o'hu'. - L'operatore
LIKEnon viene eseguito il push verso il basso e viene valutato da BigQuery.
A titolo di confronto, se non sono presenti pushdown, il piano di query mostrerà i seguenti passaggi della fase:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, description, country_code, primary_address, secondary address
FROM (
/*native_query*/
SELECT * FROM company
)
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Questa volta un'origine dati esterna restituisce tutte le colonne e tutte le righe della
tabella company e BigQuery esegue il filtraggio.
Metadati Timeline
La cronologia delle query mostra i progressi in momenti specifici, fornendo istantanee dei progressi complessivi delle query. La cronologia è rappresentata come una serie di campioni che riportano i seguenti dettagli:
| Campo | Descrizione |
|---|---|
elapsedMs |
Millisecondi trascorsi dall'inizio dell'esecuzione della query. |
totalSlotMs |
Una rappresentazione cumulativa dei millisecondi di slot utilizzati dalla query. |
pendingUnits |
Unità di lavoro totali pianificate e in attesa di esecuzione. |
activeUnits |
Il numero totale di unità di lavoro attive in fase di elaborazione da parte dei worker. |
completedUnits |
Il numero totale di unità di lavoro completate durante l'esecuzione di questa query. |
Query di esempio
La seguente query conta il numero di righe nel set di dati pubblico di Shakespeare e ha un secondo conteggio condizionale che limita i risultati alle righe che fanno riferimento ad "Amleto":
SELECT
COUNT(1) as rowcount,
COUNTIF(corpus = 'hamlet') as rowcount_hamlet
FROM `publicdata.samples.shakespeare`
Fai clic su Dettagli esecuzione per visualizzare il piano di query:
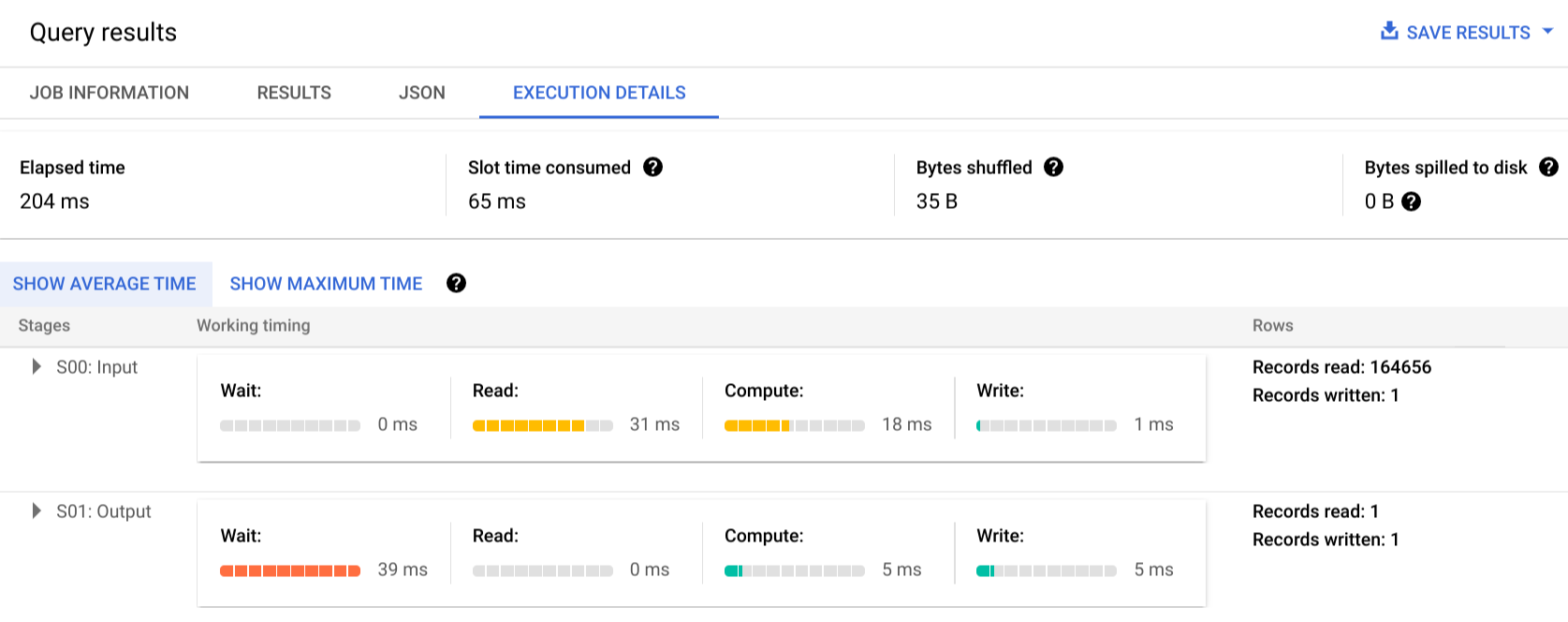
Gli indicatori di colore mostrano le tempistiche relative per tutti i passaggi in tutte le fasi.
Per saperne di più sui passaggi delle fasi di esecuzione, fai clic su per espandere i dettagli della fase:
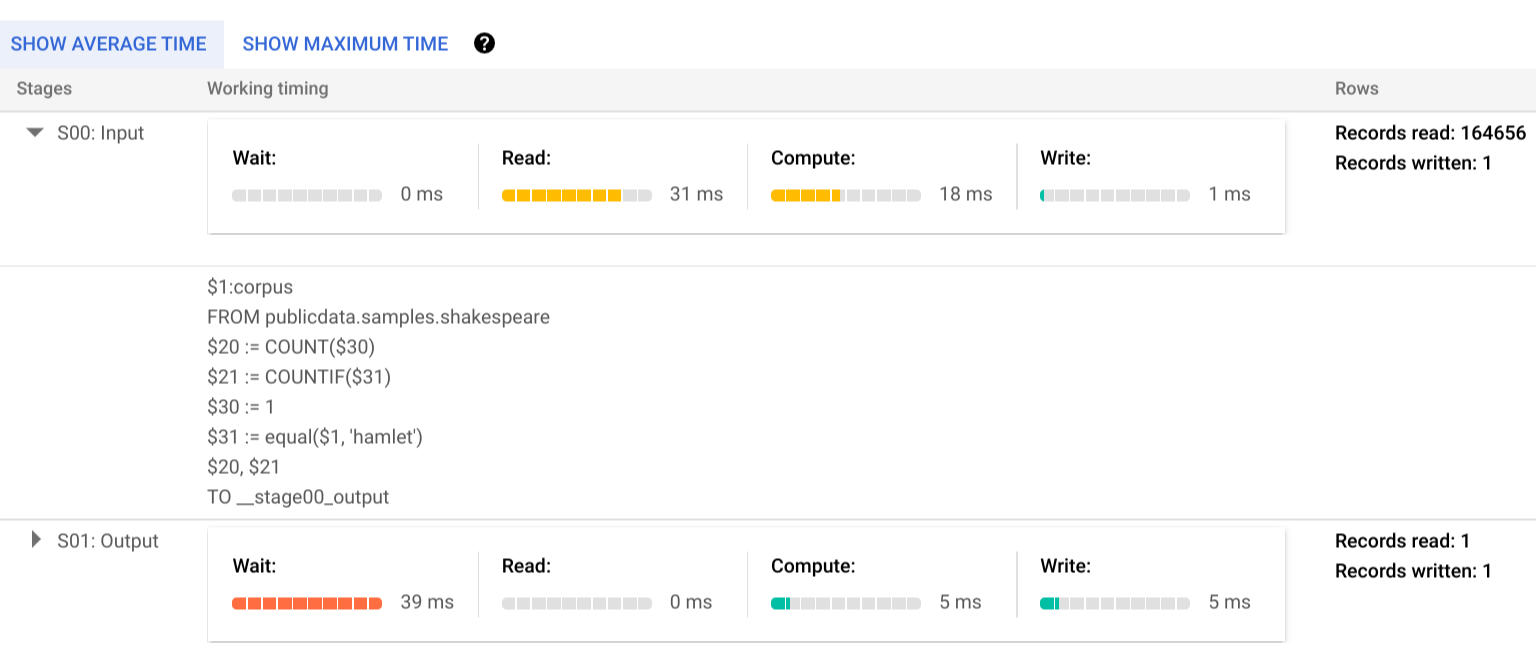
In questo esempio, il tempo più lungo in qualsiasi segmento è stato il tempo trascorso dal singolo worker nella fase 01 in attesa del completamento della fase 00. Questo perché la fase 01 dipendeva dall'input della fase 00 e non poteva iniziare finché la prima fase non scriveva il suo output nel shuffle intermedio.
Segnalazione degli errori
È possibile che i job di query non vengano eseguiti correttamente. Poiché le informazioni sul piano vengono aggiornate periodicamente, puoi osservare in quale punto del grafico di esecuzione si è verificato l'errore. Nella console Google Cloud , le fasi riuscite o non riuscite sono contrassegnate da un segno di spunta o un punto esclamativo accanto al nome della fase.
Per ulteriori informazioni sull'interpretazione e la risoluzione degli errori, consulta la guida alla risoluzione dei problemi.
Rappresentazione di esempio dell'API
Le informazioni sul piano di query sono incorporate nelle informazioni di risposta del job e puoi recuperarle chiamando jobs.get.
Ad esempio, il seguente estratto di una risposta JSON per un job che restituisce la query hamlet di esempio mostra sia il piano di query sia le informazioni sulla cronologia.
"statistics": {
"creationTime": "1576544129234",
"startTime": "1576544129348",
"endTime": "1576544129681",
"totalBytesProcessed": "2464625",
"query": {
"queryPlan": [
{
"name": "S00: Input",
"id": "0",
"startMs": "1576544129436",
"endMs": "1576544129465",
"waitRatioAvg": 0.04,
"waitMsAvg": "1",
"waitRatioMax": 0.04,
"waitMsMax": "1",
"readRatioAvg": 0.32,
"readMsAvg": "8",
"readRatioMax": 0.32,
"readMsMax": "8",
"computeRatioAvg": 1,
"computeMsAvg": "25",
"computeRatioMax": 1,
"computeMsMax": "25",
"writeRatioAvg": 0.08,
"writeMsAvg": "2",
"writeRatioMax": 0.08,
"writeMsMax": "2",
"shuffleOutputBytes": "18",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "164656",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$1:corpus",
"FROM publicdata.samples.shakespeare"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$20 := COUNT($30)",
"$21 := COUNTIF($31)"
]
},
{
"kind": "COMPUTE",
"substeps": [
"$30 := 1",
"$31 := equal($1, 'hamlet')"
]
},
{
"kind": "WRITE",
"substeps": [
"$20, $21",
"TO __stage00_output"
]
}
]
},
{
"name": "S01: Output",
"id": "1",
"startMs": "1576544129465",
"endMs": "1576544129480",
"inputStages": [
"0"
],
"waitRatioAvg": 0.44,
"waitMsAvg": "11",
"waitRatioMax": 0.44,
"waitMsMax": "11",
"readRatioAvg": 0,
"readMsAvg": "0",
"readRatioMax": 0,
"readMsMax": "0",
"computeRatioAvg": 0.2,
"computeMsAvg": "5",
"computeRatioMax": 0.2,
"computeMsMax": "5",
"writeRatioAvg": 0.16,
"writeMsAvg": "4",
"writeRatioMax": 0.16,
"writeMsMax": "4",
"shuffleOutputBytes": "17",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "1",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$20, $21",
"FROM __stage00_output"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$10 := SUM_OF_COUNTS($20)",
"$11 := SUM_OF_COUNTS($21)"
]
},
{
"kind": "WRITE",
"substeps": [
"$10, $11",
"TO __stage01_output"
]
}
]
}
],
"estimatedBytesProcessed": "2464625",
"timeline": [
{
"elapsedMs": "304",
"totalSlotMs": "50",
"pendingUnits": "0",
"completedUnits": "2"
}
],
"totalPartitionsProcessed": "0",
"totalBytesProcessed": "2464625",
"totalBytesBilled": "10485760",
"billingTier": 1,
"totalSlotMs": "50",
"cacheHit": false,
"referencedTables": [
{
"projectId": "publicdata",
"datasetId": "samples",
"tableId": "shakespeare"
}
],
"statementType": "SELECT"
},
"totalSlotMs": "50"
},
Utilizzo delle informazioni sull'esecuzione
I piani di query BigQuery forniscono informazioni su come il servizio esegue le query, ma la natura gestita del servizio limita l'azione diretta su alcuni dettagli. Molte ottimizzazioni vengono eseguite automaticamente utilizzando il servizio, il che può differire da altri ambienti in cui la messa a punto, il provisioning e il monitoraggio possono richiedere personale dedicato e competente.
Per tecniche specifiche che possono migliorare l'esecuzione e il rendimento delle query, consulta la documentazione sulle best practice. Le statistiche del piano e della cronologia delle query possono aiutarti a capire se determinate fasi dominano l'utilizzo delle risorse. Ad esempio, una fase JOIN che genera molte più righe di output rispetto alle righe di input può indicare l'opportunità di filtrare in precedenza nella query.
Inoltre, le informazioni sulla cronologia possono aiutare a determinare se una determinata query è lenta in isolamento o a causa degli effetti di altre query che competono per le stesse risorse. Se noti che il numero di unità attive rimane limitato per tutta la durata della query, ma la quantità di unità di lavoro in coda rimane elevata, ciò può rappresentare casi in cui la riduzione del numero di query simultanee può migliorare significativamente il tempo di esecuzione complessivo per determinate query.