Introduzione all'ottimizzazione delle prestazioni delle query
Questo documento fornisce una panoramica delle tecniche di ottimizzazione che possono migliorare le prestazioni delle query in BigQuery. In genere le query meno complesse hanno prestazioni migliori. Eseguono più velocemente e consumano meno risorse, il che può comportare costi inferiori e meno errori.
Prestazioni delle query
La valutazione delle prestazioni delle query in BigQuery coinvolge diversi fattori:
- Dati di input e origini dati (I/O): quanti byte vengono letti dalla query?
- Comunicazione tra nodi (shuffling): quanti byte vengono passati dalla query alla fase successiva? Quanti byte vengono passati dalla query a ogni slot?
- Calcolo: quanto lavoro della CPU richiede la query?
- Output (materializzazione): quanti byte vengono scritti dalla query?
- Capacità e concorrenza: quanti slot sono disponibili e quante altre query sono in esecuzione contemporaneamente?
- Pattern di query: le query seguono le best practice relative a SQL?
Per valutare query specifiche o verificare se si verifica una contesa delle risorse, puoi utilizzare Cloud Monitoring o i grafici delle risorse amministrative di BigQuery per monitorare il consumo di risorse da parte dei job BigQuery nel tempo. Se identifichi una query lenta o che richiede molte risorse, puoi concentrarti sulle ottimizzazioni delle prestazioni per quella query.
Alcuni pattern di query, in particolare quelli generati dagli strumenti di business intelligence, possono essere accelerati utilizzando BigQuery BI Engine. BI Engine è un servizio di analisi in memoria rapido che accelera molte query SQL in BigQuery memorizzando in modo intelligente nella cache i dati che utilizzi più di frequente. BI Engine è integrato in BigQuery, il che significa che spesso puoi ottenere un rendimento migliore senza alcuna modifica alle query.
Come per qualsiasi sistema, l'ottimizzazione per il rendimento a volte comporta dei compromessi. Ad esempio, l'utilizzo di sintassi SQL avanzate a volte può introdurre complessità e ridurre la comprensibilità delle query per le persone che non sono esperte di SQL. Dedicare tempo a micro-ottimizzazioni per carichi di lavoro non critici potrebbe anche distogliere le risorse dalla creazione di nuove funzionalità per le tue applicazioni o dall'identificazione di ottimizzazioni più importanti. Per aiutarti a ottenere il più alto ritorno possibile sull'investimento, ti consigliamo di concentrare le ottimizzazioni sui carichi di lavoro più importanti per le pipeline di analisi dei dati.
Ottimizzazione per capacità e concorrenza
BigQuery offre due modelli di prezzi per le query: on demand e in base alla capacità. Il modello on demand fornisce un pool di capacità condiviso e i prezzi si basano sulla quantità di dati elaborati da ogni query eseguita.
Il modello basato sulla capacità è consigliato se vuoi pianificare una spesa mensile costante o se hai bisogno di una capacità maggiore di quella disponibile con il modello on demand. Quando utilizzi i prezzi basati sulla capacità, assegni una capacità di elaborazione delle query dedicata misurata in slot. Il costo di tutti i byte elaborati è incluso nel prezzo basato sulla capacità. Oltre agli impegni di slot fissi, puoi utilizzare gli slot a scalabilità automatica, che forniscono capacità dinamica in base al carico di lavoro delle query.
Le prestazioni delle query eseguite ripetutamente sugli stessi dati possono variare e la variazione è in genere maggiore per le query che utilizzano gli slot on demand rispetto alle query che utilizzano le prenotazioni di slot.
Durante l'elaborazione delle query SQL, BigQuery suddivide la capacità di calcolo richiesta per eseguire ogni fase di una query in slot. BigQuery determina automaticamente il numero di query che possono essere eseguite contemporaneamente come segue:
- Modello on demand: numero di slot disponibili nel progetto
- Modello basato sulla capacità: numero di slot disponibili nella prenotazione
Le query che richiedono più slot di quelli disponibili vengono messe in coda fino a quando non diventano disponibili risorse di elaborazione. Dopo l'inizio dell'esecuzione di una query, BigQuery calcola il numero di slot utilizzati da ogni fase della query in base alle dimensioni e alla complessità della fase e al numero di slot disponibili. BigQuery utilizza una tecnica chiamata pianificazione equa per garantire che a ogni query venga assegnata una capacità sufficiente per avanzare.
L'accesso a più slot non comporta sempre un aumento delle prestazioni di una query. Tuttavia, un pool di slot più grande può migliorare le prestazioni di query di grandi dimensioni o complesse e di carichi di lavoro ad alta contemporaneità. Per migliorare il rendimento delle query, puoi modificare le prenotazioni degli slot o impostare un limite più elevato per la scalabilità automatica degli slot.
Piano di query e cronologia
BigQuery genera un piano di query ogni volta che esegui una query. Comprendere questo piano è fondamentale per un'ottimizzazione efficace delle query. Il piano di query include statistiche di esecuzione come i byte letti e il tempo di slot consumato. Il piano di query include anche i dettagli sulle diverse fasi di esecuzione, che possono aiutarti a diagnosticare e migliorare le prestazioni delle query. Il grafico di esecuzione delle query fornisce un'interfaccia grafica per visualizzare il piano di query e diagnosticare i problemi di prestazioni delle query.
Puoi anche utilizzare il metodo dell'API jobs.get o la visualizzazione INFORMATION_SCHEMA.JOBS per recuperare il piano di query e le informazioni sulle tempistiche. Queste informazioni vengono utilizzate da
BigQuery Visualizer,
uno strumento open source che rappresenta visivamente il flusso delle fasi di esecuzione in un
job BigQuery.
Quando BigQuery esegue un job di query, converte l'istruzione SQL declarative in un grafo di esecuzione. Questo grafico è suddiviso in una serie di fasi di query, che a loro volta sono composte da insiemi più granulari di passaggi di esecuzione. BigQuery utilizza un'architettura parallela fortemente distribuita per eseguire queste query. Le fasi BigQuery modellano le unità di lavoro che molti potenziali worker potrebbero eseguire in parallelo. Le fasi comunicano tra loro tramite un'architettura di ordinamento rapida e distribuita.
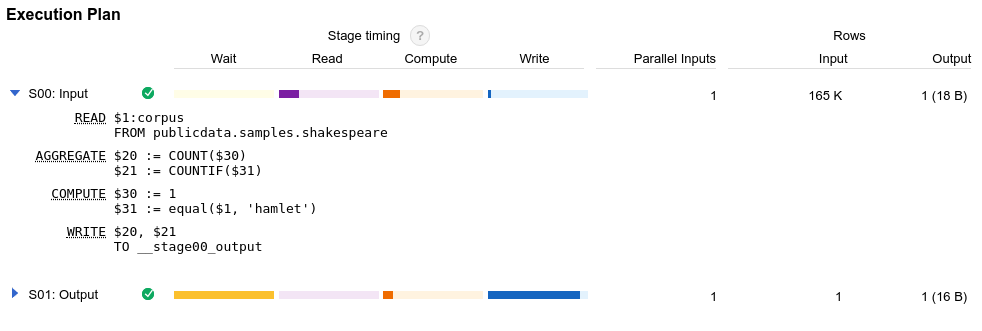
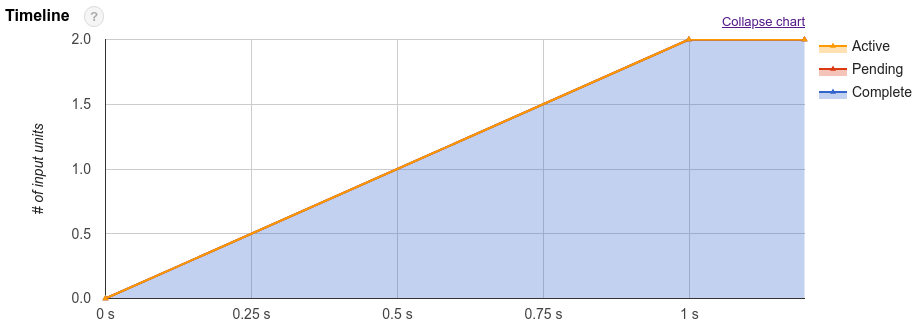
Oltre al piano di query, i job di query mostrano anche una sequenza temporale dell'esecuzione. Questa sequenza temporale fornisce un conteggio delle unità di lavoro completate, in attesa e attive all'interno dei worker di query. Una query potrebbe avere più fasi con attività contemporaneamente, pertanto la sequenza temporale è progettata per mostrare l'avanzamento complessivo della query.
Per stimare il costo computazionale di una query, puoi esaminare il numero totale di secondi di slot consumati dalla query. Più basso è il numero di secondi di slot, meglio è, perché significa che più risorse sono disponibili per altre query in esecuzione contemporaneamente nello stesso progetto.
Le statistiche del piano di query e della sequenza temporale possono aiutarti a capire come
BigQuery esegue le query e se determinate fasi dominano l'utilizzo delle risorse. Ad esempio, una fase JOIN che genera molte più righe di output rispetto alle righe di input potrebbe indicare un'opportunità di applicare un filtro all'inizio della query.
Tuttavia, la natura gestita del servizio limita la possibilità di intervenire direttamente su alcuni dettagli. Per le best practice e le tecniche per migliorare l'esecuzione e il rendimento delle query, consulta Ottimizzare il calcolo delle query.
Passaggi successivi
- Scopri come risolvere i problemi di esecuzione delle query utilizzando i log di controllo di BigQuery.
- Scopri altre tecniche di controllo dei costi per BigQuery.
- Visualizza i metadati quasi in tempo reale sui job BigQuery utilizzando la visualizzazione
INFORMATION_SHEMA.JOBS. - Scopri come monitorare l'utilizzo di BigQuery utilizzando i report sulle tabelle di sistema BigQuery.