Alat analisis terprogram
Dokumen ini menjelaskan beberapa cara untuk menulis dan menjalankan kode untuk menganalisis data yang dikelola di BigQuery.
Meskipun SQL adalah bahasa kueri yang andal, bahasa pemrograman seperti Python, Java, atau R menyediakan sintaksis dan beragam fungsi statistik bawaan yang mungkin dianggap analis data lebih ekspresif dan lebih mudah dimanipulasi untuk jenis analisis data tertentu.
Demikian pula, meskipun spreadsheet digunakan secara luas, lingkungan pemrograman lain seperti notebook terkadang dapat menawarkan lingkungan yang lebih fleksibel untuk melakukan analisis dan eksplorasi data yang kompleks.
Notebook Colab Enterprise
Anda dapat menggunakan notebook Colab Enterprise di BigQuery untuk menyelesaikan alur kerja analisis dan machine learning (ML) dengan menggunakan SQL, Python, serta paket dan API umum lainnya. Notebook menawarkan kolaborasi dan pengelolaan yang lebih baik dengan opsi berikut:
- Bagikan notebook kepada pengguna dan grup tertentu dengan Identity and Access Management (IAM).
- Tinjau histori versi notebook.
- Kembalikan ke atau cabang dari versi notebook sebelumnya.
Notebook adalah aset kode BigQuery Studio yang didukung oleh Dataform, meskipun notebook tidak terlihat di Dataform. Kueri tersimpan juga merupakan aset kode. Semua aset kode disimpan di region default. Mengupdate region default akan mengubah region untuk semua aset kode yang dibuat setelah waktu tersebut.
Kemampuan notebook hanya tersedia di konsol Google Cloud .
Notebook di BigQuery menawarkan manfaat berikut:
- BigQuery DataFrames diintegrasikan dengan notebook, tanpa perlu penyiapan. BigQuery DataFrames adalah API Python yang dapat Anda gunakan untuk menganalisis data BigQuery dalam skala besar menggunakan pandas DataFrame dan API scikit-learn.
- Pengembangan kode pendukung yang didukung oleh AI generatif Gemini.
- Pelengkapan otomatis pernyataan SQL, sama seperti di editor BigQuery.
- Kemampuan untuk menyimpan, membagikan, dan mengelola versi notebook.
- Kemampuan untuk menggunakan matplotlib, seaborn, dan library populer lainnya untuk memvisualisasikan data kapan saja dalam alur kerja Anda.
- Kemampuan untuk menulis dan mengeksekusi SQL dalam sel yang dapat mereferensikan variabel Python dari notebook Anda.
- Visualisasi DataFrame interaktif yang mendukung agregasi dan penyesuaian.
Anda dapat mulai menggunakan notebook dengan menggunakan template galeri notebook. Untuk mengetahui informasi selengkapnya, lihat Membuat notebook menggunakan galeri notebook.
BigQuery DataFrames
BigQuery DataFrames adalah sekumpulan library Python open source yang memungkinkan Anda memanfaatkan pemrosesan data BigQuery menggunakan API Python yang sudah dikenal. BigQuery DataFrames menerapkan API pandas dan scikit-learn dengan mendorong pemrosesan ke BigQuery melalui konversi SQL. Desain ini memungkinkan Anda menggunakan BigQuery untuk menjelajahi dan memproses data terabyte, serta melatih model ML, semuanya dengan Python API.
BigQuery DataFrame menawarkan manfaat berikut:
- Lebih dari 750 API pandas dan scikit-learn yang diterapkan melalui konversi SQL transparan ke BigQuery dan BigQuery ML API.
- Eksekusi kueri yang ditangguhkan untuk meningkatkan performa.
- Memperluas transformasi data dengan fungsi Python yang ditentukan pengguna untuk memungkinkan Anda memproses data di cloud. Fungsi ini otomatis di-deploy sebagai fungsi jarak jauh BigQuery.
- Integrasi dengan Vertex AI memungkinkan Anda menggunakan model Gemini untuk pembuatan teks.
Solusi analisis terprogram lainnya
Solusi analisis terprogram berikut juga tersedia di BigQuery.
Notebook Jupyter
Jupyter adalah aplikasi open source berbasis web untuk memublikasikan notebook yang berisi kode aktif, deskripsi tekstual, dan visualisasi. Data scientist, spesialis machine learning, dan siswa biasanya menggunakan platform ini untuk tugas-tugas seperti pembersihan dan transformasi data, simulasi numerik, pemodelan statistik, visualisasi data, dan ML.
Notebook Jupyter dibangun di atas kernel IPython, shell interaktif yang andal, yang dapat berinteraksi langsung dengan BigQuery menggunakan IPython Magics untuk BigQuery. Atau, Anda juga dapat mengakses BigQuery dari instance notebook Jupyter dengan menginstal library klien BigQuery yang tersedia. Anda dapat memvisualisasikan data BigQuery GIS dengan notebook Jupyter melalui ekstensi GeoJSON. Untuk mengetahui detail selengkapnya tentang integrasi BigQuery, lihat tutorial Memvisualisasikan data BigQuery di notebook Jupyter.
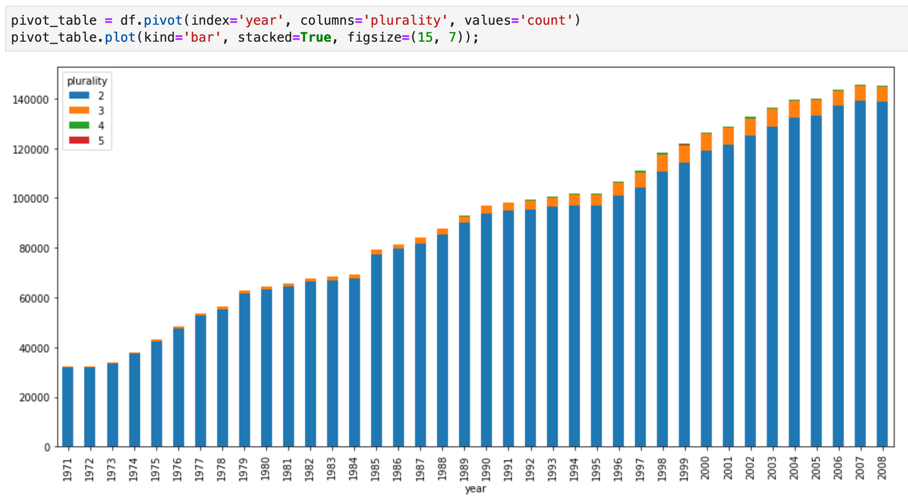
JupyterLab adalah antarmuka pengguna berbasis web untuk mengelola dokumen dan aktivitas seperti notebook Jupyter, editor teks, terminal, dan komponen kustom. Dengan JupyterLab, Anda dapat menata beberapa dokumen dan aktivitas secara berdampingan di area kerja dengan tab dan pemisah.
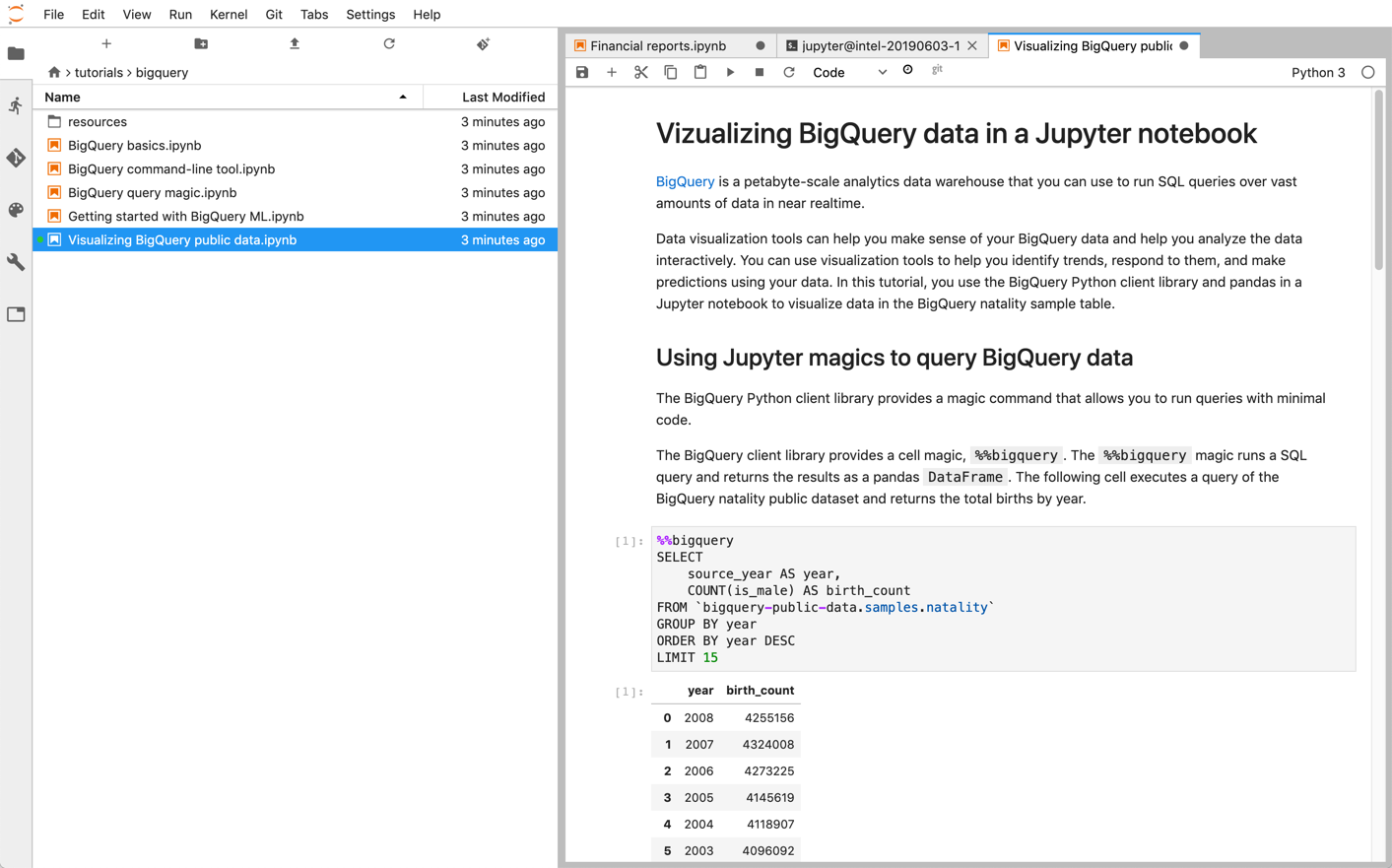
Anda dapat men-deploy notebook Jupyter dan lingkungan JupyterLab di Google Cloud menggunakan salah satu produk berikut:
- Instance Vertex AI Workbench, layanan yang menawarkan lingkungan JupyterLab terintegrasi tempat developer machine learning dan data scientist dapat menggunakan beberapa framework data science dan machine learning terbaru. Vertex AI Workbench terintegrasi dengan produk data lainnya seperti BigQuery, sehingga memudahkan peralihan dari penyerapan data ke pra-pemrosesan dan eksplorasi, serta pelatihan dan deployment model. Google Cloud Untuk mempelajari lebih lanjut, lihat Pengantar instance Vertex AI Workbench.
- Dataproc, layanan cepat, mudah digunakan, dan terkelola sepenuhnya untuk menjalankan cluster Apache Spark dan Apache Hadoop dengan cara yang sederhana dan hemat biaya. Anda dapat menginstal notebook Jupyter dan JupyterLab pada cluster Dataproc dengan komponen opsional Jupyter. Komponen ini menyediakan kernel Python untuk menjalankan kode PySpark. Secara default, Dataproc mengonfigurasi notebook agar disimpan di Cloud Storage secara otomatis sehingga file notebook yang sama dapat diakses cluster lain. Saat memigrasikan notebook yang ada ke Dataproc, periksa apakah dependensi notebook Anda tercakup dalam versi Dataproc yang didukung. Jika Anda perlu menginstal software kustom, pertimbangkan untuk membuat image Dataproc Anda sendiri, menulis tindakan inisialisasi Anda sendiri, atau menyebutkan persyaratan paket Python kustom. Untuk memulai, lihat tutorial tentang Menginstal dan menjalankan notebook Jupyter pada cluster Dataproc.
Apache Zeppelin
Apache Zeppelin
adalah project open source yang menawarkan notebook berbasis web untuk analisis data.
Anda dapat men-deploy instance Apache Zeppelin di
Dataproc
dengan menginstal
komponen opsional Zeppelin.
Secara default, notebook disimpan di Cloud Storage di
bucket staging Dataproc, yang ditentukan oleh pengguna atau
dibuat otomatis saat cluster dibuat. Anda dapat mengubah lokasi notebook
dengan menambahkan properti zeppelin:zeppelin.notebook.gcs.dir saat membuat
cluster. Untuk informasi selengkapnya tentang cara menginstal dan mengonfigurasi Apache Zeppelin,
lihat
Panduan komponen Zeppelin.
Sebagai contoh, lihat
Menganalisis set data BigQuery menggunakan Interpreter BigQuery untuk Apache Zeppelin.
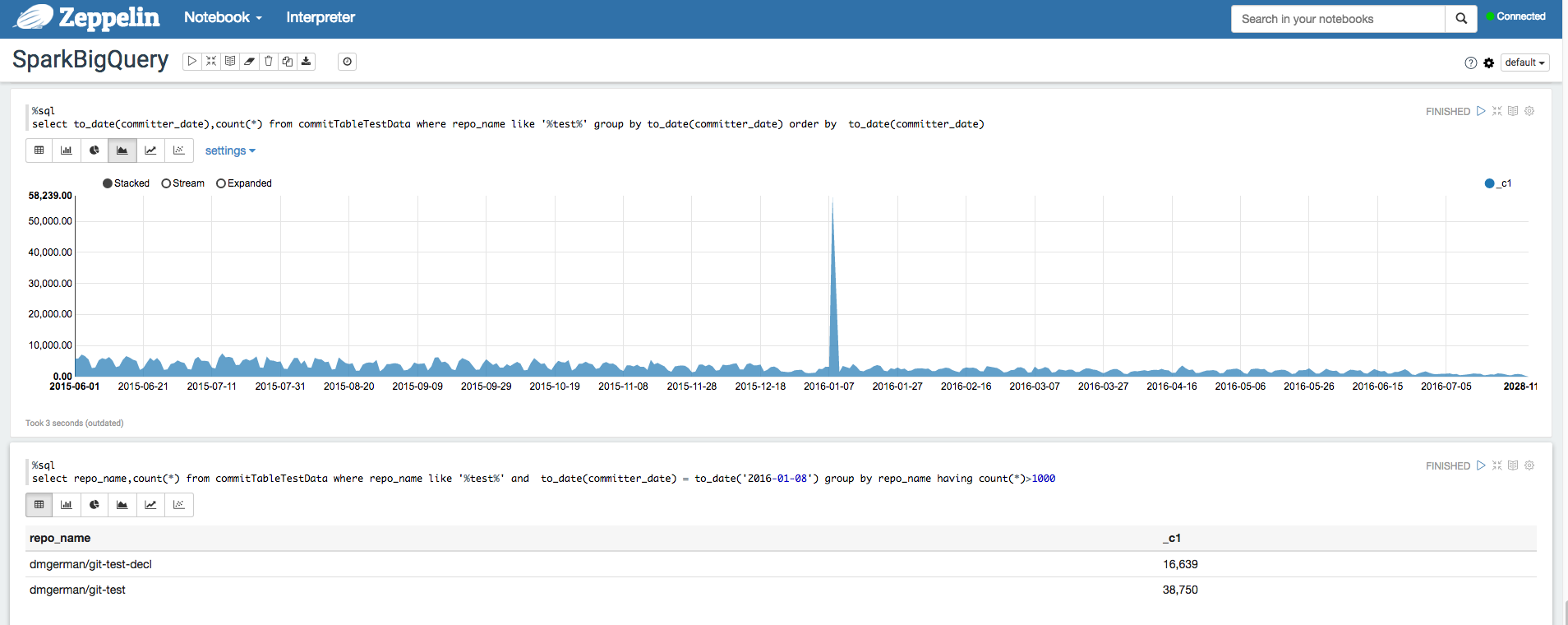
Apache Hadoop, Apache Spark, dan Apache Hive
Sebagai bagian dari migrasi pipeline analisis data, Anda mungkin ingin memigrasikan beberapa pekerjaan Apache Hadoop, Apache Spark, atau Apache Hive lama yang perlu memproses data secara langsung dari data warehouse Anda. Misalnya, Anda dapat mengekstrak fitur untuk workload machine learning Anda.
Dataproc memungkinkan Anda men-deploy cluster Hadoop dan Spark yang terkelola sepenuhnya secara efisien dan hemat biaya. Dataproc terintegrasi dengan konektor BigQuery open source. Konektor ini menggunakan BigQuery Storage API, yang mengalirkan data secara paralel langsung dari BigQuery melalui gRPC.
Saat memigrasikan workload Hadoop dan Spark yang ada ke Dataproc, Anda dapat melihat apakah dependensi workload Anda tercakup dalam versi Dataproc yang didukung. Jika perlu menginstal software kustom, Anda dapat mempertimbangkan untuk membuat image Dataproc Anda sendiri, menulis tindakan inisialisasi Anda sendiri, atau menyebutkan persyaratan paket Python kustom.
Untuk memulai, lihat panduan memulai Dataproc dan contoh kode konektor BigQuery.
Apache Beam
Apache Beam adalah framework open source yang kaya dengan rangkaian dasar windowing dan analisis sesi, serta ekosistem konektor sumber dan sink, termasuk konektor untuk BigQuery. Apache Beam memungkinkan Anda untuk mengubah dan memperkaya data baik secara streaming (real time) maupun batch (historis) dengan keandalan dan ekspresif yang sama.
Dataflow adalah layanan terkelola sepenuhnya untuk menjalankan tugas Apache Beam dalam skala besar. Pendekatan serverless Dataflow memangkas beban operasional dengan performa, penskalaan, ketersediaan, keamanan, dan kepatuhan yang ditangani secara otomatis sehingga Anda dapat fokus pada pemrograman, bukan pengelolaan cluster server.
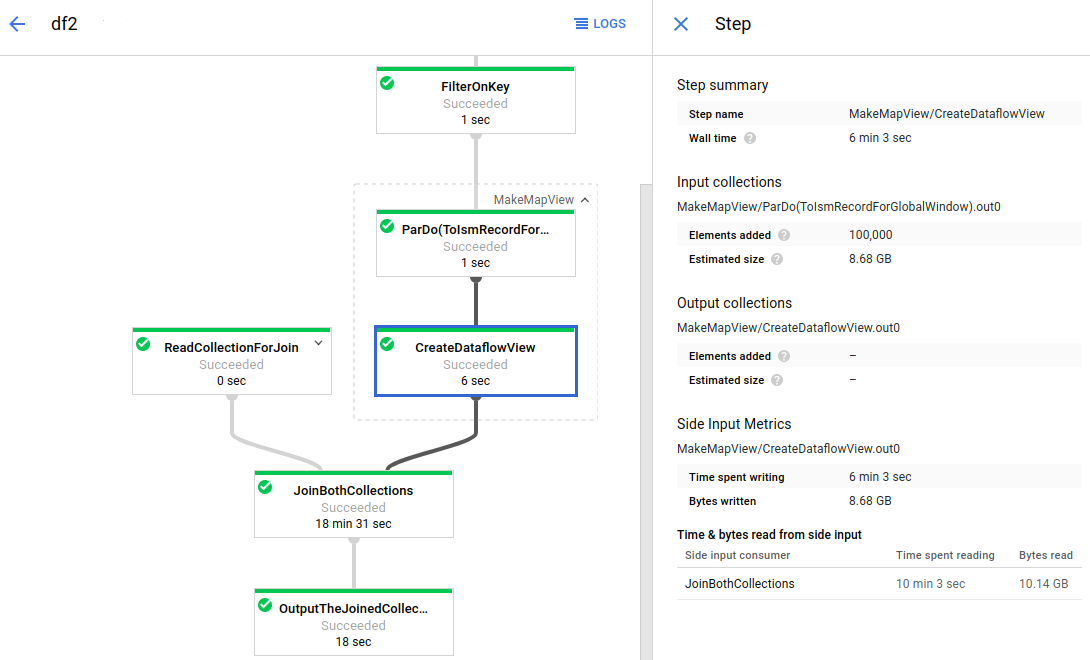
Anda dapat mengirimkan tugas Dataflow dengan berbagai cara, baik melalui antarmuka command line, Java SDK, atau Python SDK.
Jika Anda ingin memigrasikan kueri dan pipeline data dari framework lain ke Apache Beam dan Dataflow, baca tentang Model pemrograman Apache Beam dan jelajahi Dokumentasi Dataflow resmi.
Resource lainnya
BigQuery menawarkan beragam library klien dalam berbagai bahasa pemrograman seperti Java, Go, Python, JavaScript, PHP, dan Ruby. Beberapa framework analisis data seperti pandas menyediakan plugin yang berinteraksi langsung dengan BigQuery. Untuk beberapa contoh praktis, lihat tutorial Memvisualisasikan data BigQuery di notebook Jupyter.
Terakhir, jika Anda lebih memilih untuk menulis program di lingkungan shell, Anda dapat menggunakan alat command line bq.