Herramientas de análisis programático
En este documento se describen varias formas de escribir y ejecutar código para analizar los datos gestionados en BigQuery.
Aunque SQL es un lenguaje de consulta potente, los lenguajes de programación como Python, Java o R proporcionan sintaxis y una gran variedad de funciones estadísticas integradas que los analistas de datos pueden considerar más expresivas y fáciles de manipular para determinados tipos de análisis de datos.
Del mismo modo, aunque las hojas de cálculo se usan mucho, otros entornos de programación, como los cuadernos, a veces pueden proporcionar un entorno más flexible para realizar análisis y exploraciones de datos complejos.
Cuadernos de Colab Enterprise
Puedes usar cuadernos de Colab Enterprise en BigQuery para completar análisis y flujos de trabajo de aprendizaje automático (ML) con SQL, Python y otros paquetes y APIs habituales. Los cuadernos ofrecen una mejor colaboración y gestión con las siguientes opciones:
- Comparte cuadernos con usuarios y grupos específicos mediante Gestión de Identidades y Accesos (IAM).
- Revisa el historial de versiones del cuaderno.
- Volver a versiones anteriores del cuaderno o crear una rama a partir de ellas.
Los cuadernos son recursos de código de BigQuery Studio que se basan en Dataform, aunque no se pueden ver en Dataform. Las consultas guardadas también son recursos de código. Todos los recursos de código se almacenan en una región predeterminada. Si actualiza la región predeterminada, cambiará la región de todos los recursos de código que se creen a partir de ese momento.
Las funciones de cuaderno solo están disponibles en la Google Cloud consola.
Los cuadernos de BigQuery ofrecen las siguientes ventajas:
- BigQuery DataFrames está integrado en los cuadernos y no requiere configuración. BigQuery DataFrames es una API de Python que puedes usar para analizar datos de BigQuery a gran escala mediante las APIs DataFrame de pandas y scikit-learn.
- Desarrollo de código asistido por la IA generativa de Gemini.
- Autocompletado de instrucciones SQL, igual que en el editor de BigQuery.
- Posibilidad de guardar, compartir y gestionar versiones de cuadernos.
- La posibilidad de usar matplotlib, seaborn y otras bibliotecas populares para visualizar datos en cualquier punto de tu flujo de trabajo.
- La posibilidad de escribir y ejecutar SQL en una celda que pueda hacer referencia a variables de Python de tu cuaderno.
- Visualización de DataFrame interactiva que admite la agregación y la personalización.
Puedes empezar a usar cuadernos con las plantillas de la galería de cuadernos. Para obtener más información, consulta el artículo Crear un cuaderno con la galería de cuadernos.
BigQuery DataFrames
BigQuery DataFrames es un conjunto de bibliotecas de Python de código abierto que te permiten aprovechar el procesamiento de datos de BigQuery mediante APIs de Python que ya conoces. BigQuery DataFrames implementa las APIs de pandas y scikit-learn transfiriendo el procesamiento a BigQuery mediante la conversión a SQL. Este diseño te permite usar BigQuery para explorar y procesar terabytes de datos, así como entrenar modelos de aprendizaje automático, todo ello con APIs de Python.
BigQuery DataFrames ofrece las siguientes ventajas:
- Más de 750 APIs de pandas y scikit-learn implementadas mediante la conversión transparente de SQL a las APIs de BigQuery y BigQuery ML.
- Ejecución diferida de consultas para mejorar el rendimiento.
- Amplía las transformaciones de datos con funciones de Python definidas por el usuario para que puedas procesar datos en la nube. Estas funciones se implementan automáticamente como funciones remotas de BigQuery.
- Integración con Vertex AI para que puedas usar modelos de Gemini para generar texto.
Otras soluciones de análisis programático
Las siguientes soluciones de análisis programático también están disponibles en BigQuery.
Cuadernos de Jupyter
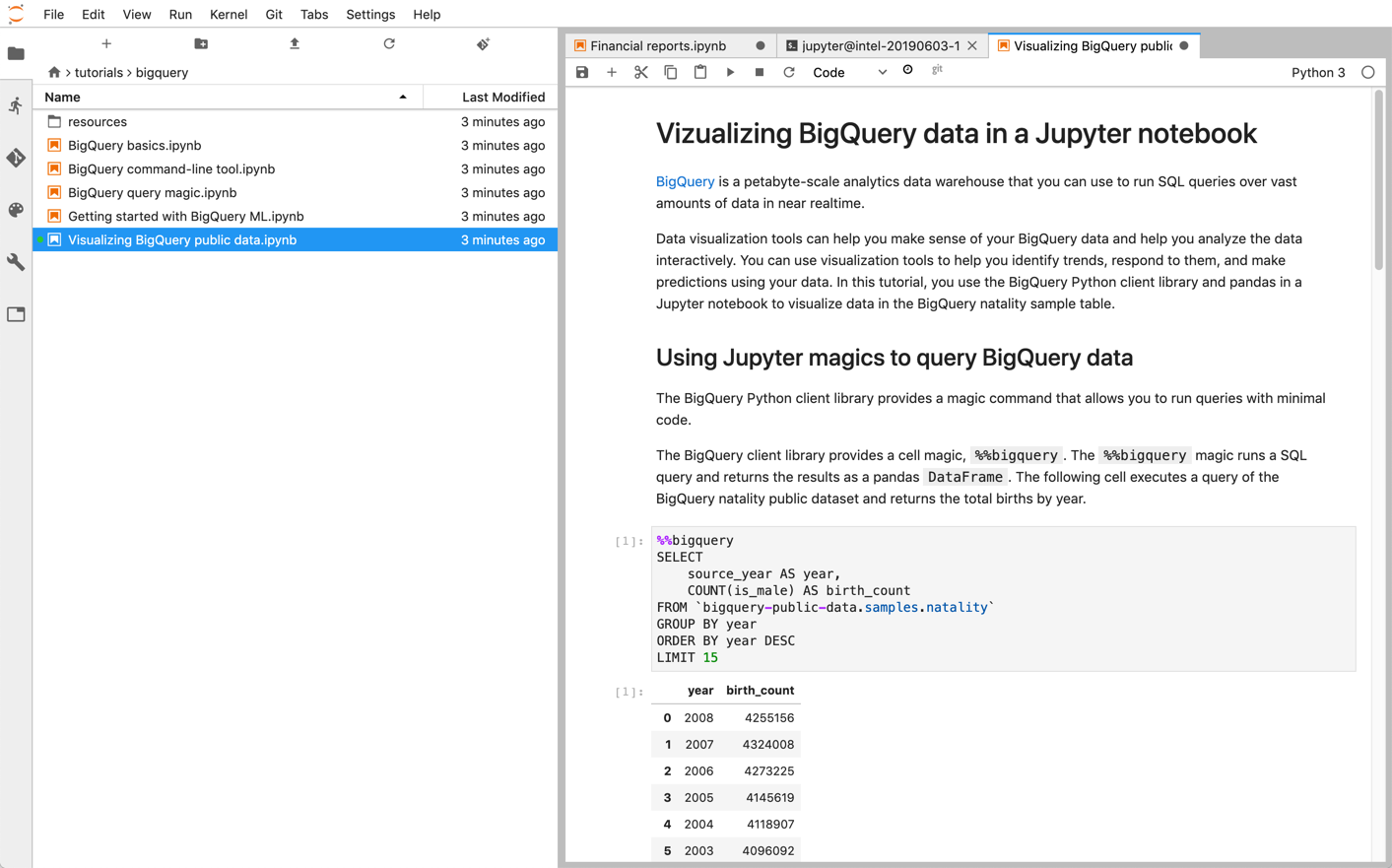
Jupyter es una aplicación web de código abierto para publicar cuadernos que contienen código en ejecución, descripciones textuales y visualizaciones. Los científicos de datos, los especialistas en aprendizaje automático y los estudiantes suelen usar esta plataforma para tareas como la limpieza y la transformación de datos, la simulación numérica, el modelado estadístico, la visualización de datos y el aprendizaje automático.
Los cuadernos de Jupyter se basan en el kernel IPython, un shell interactivo potente que puede interactuar directamente con BigQuery mediante IPython Magics para BigQuery. También puedes acceder a BigQuery desde tus instancias de cuadernos Jupyter instalando cualquiera de las bibliotecas de cliente de BigQuery disponibles. Puedes visualizar datos de BigQuery GIS con cuadernos de Jupyter mediante la extensión GeoJSON. Para obtener más información sobre la integración de BigQuery, consulta el tutorial Visualizar datos de BigQuery en un cuaderno de Jupyter.
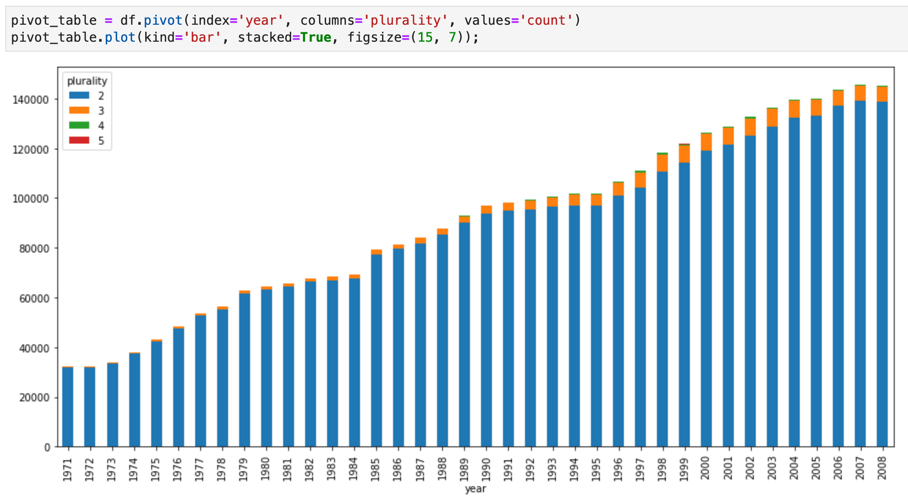
JupyterLab es una interfaz de usuario basada en web para gestionar documentos y actividades, como cuadernos de Jupyter, editores de texto, terminales y componentes personalizados. Con JupyterLab, puedes organizar varios documentos y actividades en paralelo en el área de trabajo mediante pestañas y divisores.
Puedes desplegar cuadernos de Jupyter y entornos de JupyterLab enGoogle Cloud con uno de los siguientes productos:
- Instancias de Vertex AI Workbench, un servicio que ofrece un entorno de JupyterLab integrado en el que los desarrolladores de aprendizaje automático y los científicos de datos pueden usar algunos de los frameworks más recientes de aprendizaje automático y ciencia de datos. Vertex AI Workbench está integrado con otros productos de datos, como BigQuery, lo que permite pasar fácilmente de la ingestión de datos al preprocesamiento y la exploración, y, finalmente, al entrenamiento y al despliegue de modelos. Google Cloud Para obtener más información, consulta la introducción a las instancias de Vertex AI Workbench.
- Dataproc, un servicio rápido, fácil de usar y totalmente gestionado para ejecutar clústeres de Apache Spark y Apache Hadoop de una manera sencilla y rentable. Puedes instalar cuadernos de Jupyter y JupyterLab en un clúster de Dataproc mediante el componente opcional Jupyter. El componente proporciona un kernel de Python para ejecutar código PySpark. De forma predeterminada, Dataproc configura automáticamente los cuadernos para que se guarden en Cloud Storage, lo que permite que otros clústeres accedan a los mismos archivos de cuaderno. Cuando migres tus cuadernos a Dataproc, comprueba que las dependencias de tus cuadernos estén cubiertas por las versiones de Dataproc compatibles. Si necesitas instalar software personalizado, te recomendamos que crees tu propia imagen de Dataproc, escribas tus propias acciones de inicialización o especifiques requisitos de paquetes de Python personalizados. Para empezar, consulta el tutorial sobre cómo instalar y ejecutar un cuaderno de Jupyter en un clúster de Dataproc.
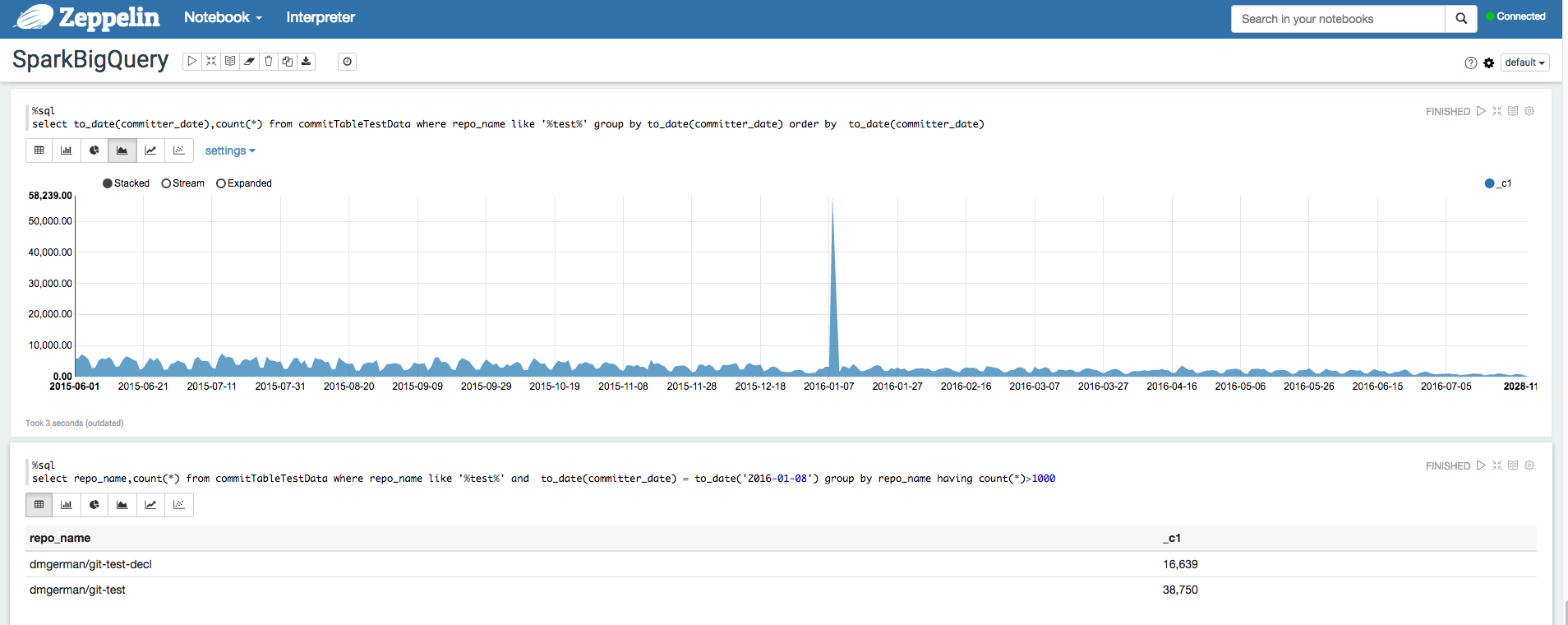
Apache Zeppelin
Apache Zeppelin
es un proyecto de código abierto que ofrece cuadernos basados en web para el análisis de datos.
Puedes desplegar una instancia de Apache Zeppelin en Dataproc
instalando el componente opcional Zeppelin.
De forma predeterminada, los cuadernos se guardan en Cloud Storage en el segmento de desarrollo por fases de Dataproc, que especifica el usuario o se crea automáticamente al crear el clúster. Puedes cambiar la ubicación del cuaderno
añadiendo la propiedad zeppelin:zeppelin.notebook.gcs.dir al crear el
clúster. Para obtener más información sobre cómo instalar y configurar Apache Zeppelin, consulta la guía de componentes de Zeppelin.
Por ejemplo, consulta Analizar conjuntos de datos de BigQuery con el intérprete de BigQuery para Apache Zeppelin.
Apache Hadoop, Apache Spark y Apache Hive
Como parte de la migración de tu canalización de analíticas de datos, puede que quieras migrar algunas tareas antiguas de Apache Hadoop, Apache Spark o Apache Hive que necesiten procesar directamente datos de tu almacén de datos. Por ejemplo, puedes extraer características para tus cargas de trabajo de aprendizaje automático.
Dataproc te permite desplegar clústeres de Hadoop y Spark totalmente gestionados de forma eficiente y rentable. Dataproc se integra con conectores de BigQuery de código abierto. Estos conectores usan la API Storage de BigQuery, que transmite datos en paralelo directamente desde BigQuery a través de gRPC.
Cuando migres tus cargas de trabajo de Hadoop y Spark a Dataproc, puedes comprobar que las dependencias de tus cargas de trabajo se cubren con las versiones de Dataproc compatibles. Si necesitas instalar software personalizado, puedes crear tu propia imagen de Dataproc, escribir tus propias acciones de inicialización o especificar requisitos de paquetes de Python personalizados.
Para empezar, consulta las guías de inicio rápido de Dataproc y los códigos de ejemplo del conector de BigQuery.
Apache Beam
Apache Beam es un framework de código abierto que proporciona un amplio conjunto de primitivas de análisis de ventanas y sesiones, así como un ecosistema de conectores de origen y receptor, incluido un conector para BigQuery. Apache Beam te permite transformar y enriquecer datos tanto en streaming (en tiempo real) como por lotes (histórico) con la misma fiabilidad y expresividad.
Dataflow es un servicio totalmente gestionado para ejecutar trabajos de Apache Beam a gran escala. Al no necesitar servidor en Dataflow, puedes olvidarte de la sobrecarga operativa y centrarte en la programación. La gestión del rendimiento, el escalado, la disponibilidad, la seguridad y el cumplimiento normativo de los clústeres de servidores se hace de forma automática.
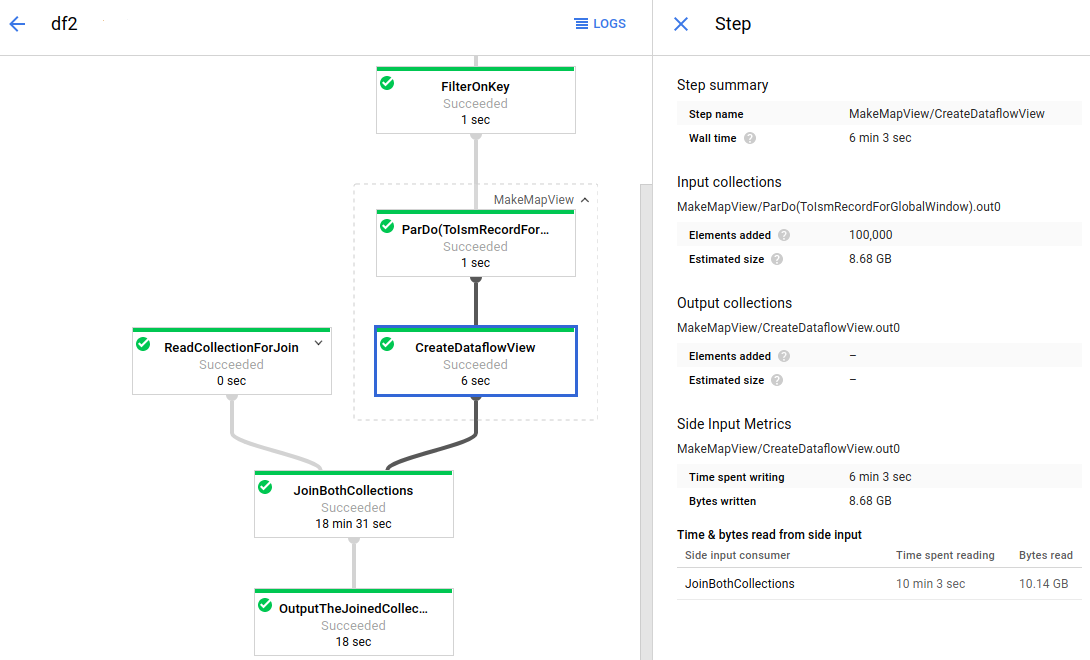
Puedes enviar tareas de Dataflow de diferentes formas: mediante la interfaz de línea de comandos, el SDK de Java o el SDK de Python.
Si quieres migrar tus consultas de datos y tus flujos de procesamiento de otros frameworks a Apache Beam y Dataflow, consulta el modelo de programación de Apache Beam y la documentación oficial de Dataflow.
Otros recursos
BigQuery ofrece una gran variedad de bibliotecas de cliente en varios lenguajes de programación, como Java, Go, Python, JavaScript, PHP y Ruby. Algunos frameworks de análisis de datos, como pandas, proporcionan complementos que interactúan directamente con BigQuery. Para ver algunos ejemplos prácticos, consulta el tutorial Visualizar datos de BigQuery en un cuaderno de Jupyter.
Por último, si prefieres escribir programas en un entorno de shell, puedes usar la herramienta de línea de comandos bq.