Pengantar BigQuery Omni
Dengan BigQuery Omni, Anda dapat menjalankan analisis BigQuery pada data yang disimpan di Amazon Simple Storage Service (Amazon S3) atau Azure Blob Storage menggunakan tabel BigLake.
Banyak organisasi yang menyimpan data di beberapa cloud publik. Data ini sering kali disimpan secara terpisah, karena sulit untuk mendapatkan insight keseluruhan dari semua data. Disarankan agar dapat menganalisis data dengan alat data multi-cloud yang murah, cepat, dan tidak menciptakan overhead tambahan untuk tata kelola data yang terdesentralisasi. Dengan menggunakan BigQuery Omni, kami mengurangi hambatan ini dengan antarmuka terpadu.
Untuk menjalankan analisis BigQuery pada data eksternal, Anda harus terhubung ke Amazon S3 atau Blob Storage terlebih dahulu. Jika ingin membuat kueri data eksternal, Anda harus membuat tabel BigLake yang mereferensikan data Amazon S3 atau Blob Storage.
Alat BigQuery Omni
Anda dapat menggunakan alat BigQuery Omni berikut untuk menjalankan analisis BigQuery pada data eksternal Anda:
- Gabungan lintas cloud: Jalankan kueri langsung dari region BigQuery yang dapat menggabungkan data dari region BigQuery Omni.
- Tampilan terwujud lintas cloud: Gunakan replika tampilan terwujud untuk mereplikasi data secara berkelanjutan dari region BigQuery Omni. Mendukung pemfilteran data.
- Transfer lintas cloud menggunakan
SELECT: Jalankan kueri menggunakan pernyataanCREATE TABLE AS SELECTatauINSERT INTO SELECTdi region BigQuery Omni dan pindahkan hasilnya ke region BigQuery. - Transfer lintas cloud menggunakan
LOAD: Gunakan pernyataanLOAD DATAuntuk memuat data secara langsung dari Amazon Simple Storage Service (Amazon S3) atau Azure Blob Storage ke BigQuery
Tabel berikut menguraikan fitur dan kemampuan utama setiap alat lintas cloud:
| Gabungan lintas cloud | Tampilan terwujud lintas cloud | Transfer lintas cloud menggunakan SELECT |
Transfer lintas cloud menggunakan LOAD |
|
|---|---|---|---|---|
| Penggunaan yang disarankan | Buat kueri data eksternal untuk penggunaan satu kali, tempat Anda dapat menggabungkan dengan tabel lokal atau menggabungkan data antara dua region BigQuery Omni yang berbeda—misalnya, antara region AWS dan Azure Blob Storage. Gunakan gabungan lintas-cloud jika data tidak besar, dan jika caching bukan persyaratan utama | Siapkan kueri berulang atau terjadwal untuk mentransfer data eksternal secara inkremental dan berkelanjutan, dengan persyaratan utama berupa penyiapan cache. Misalnya, untuk mengelola dasbor | Membuat kueri data eksternal untuk penggunaan satu kali, dari region BigQuery Omni ke region BigQuery, jika kontrol manual seperti caching dan pengoptimalan kueri adalah persyaratan utama, dan jika Anda menggunakan kueri kompleks yang tidak didukung oleh gabungan lintas cloud atau tampilan terwujud lintas cloud | Memigrasikan set data besar apa adanya tanpa perlu pemfilteran, menggunakan kueri terjadwal untuk memindahkan data mentah |
| Mendukung pemfilteran sebelum memindahkan data | Ya. Batasan berlaku pada operator kueri tertentu. Untuk mengetahui informasi selengkapnya, lihat Batasan gabungan lintas cloud | Ya. Batas berlaku pada operator kueri tertentu, seperti fungsi agregat dan operator UNION |
Ya. Tidak ada batasan pada operator kueri | Tidak |
| Batasan ukuran transfer | 60 GB per transfer (setiap subkueri ke region jarak jauh menghasilkan satu transfer) | Tak terbatas | 60 GB per transfer (setiap subkueri ke region jarak jauh menghasilkan satu transfer) | Tak terbatas |
| Kompresi transfer data | Kompresi kabel | Kolumnar | Kompresi kabel | Kompresi Jaringan |
| Caching | Tidak didukung | Didukung dengan tabel yang mendukung cache dengan tampilan terwujud | Tidak didukung | Tidak didukung |
| Harga traffic keluar | Biaya traffic keluar dan interkontinental AWS | Biaya traffic keluar dan interkontinental AWS | Biaya traffic keluar dan interkontinental AWS | Biaya traffic keluar dan interkontinental AWS |
| Penggunaan komputasi untuk transfer data | Menggunakan slot di region AWS atau Azure Blob Storage sumber (Reservasi atau Sesuai permintaan) | Tidak digunakan | Menggunakan slot di region AWS atau Azure Blob Storage sumber (Reservasi atau Sesuai permintaan) | Tidak digunakan |
| Penggunaan komputasi untuk pemfilteran | Menggunakan slot di region AWS atau Azure Blob Storage sumber (Reservasi atau Sesuai permintaan) | Menggunakan slot di region AWS atau Azure Blob Storage sumber (Reservasi atau Sesuai permintaan) untuk menghitung tampilan terwujud dan metadata lokal | Menggunakan slot di region AWS atau Azure Blob Storage sumber (Reservasi atau Sesuai permintaan) | Tidak digunakan |
| Pentransferan inkremental | Tidak didukung | Didukung untuk tampilan terwujud non-agregat | Tidak didukung | Tidak didukung |
Anda juga dapat mempertimbangkan alternatif berikut untuk mentransfer data dari Amazon Simple Storage Service (Amazon S3) atau Azure Blob Storage ke Google Cloud:
- Storage Transfer Service: Transfer data antara penyimpanan objek dan file di Google Cloud, Amazon Simple Storage Service (Amazon S3), atau Azure Blob Storage. Google Cloud
- BigQuery Data Transfer Service: Siapkan transfer data otomatis ke BigQuery secara terjadwal dan terkelola. Mendukung berbagai sumber dan cocok untuk migrasi data. BigQuery Data Transfer Service tidak mendukung pemfilteran.
Arsitektur
Arsitektur BigQuery memisahkan komputasi dari penyimpanan, sehingga memungkinkan BigQuery melakukan penskalaan sesuai kebutuhan untuk menangani beban kerja yang sangat besar. BigQuery Omni memperluas arsitektur ini dengan menjalankan mesin kueri BigQuery di cloud lainnya. Hasilnya, Anda tidak perlu memindahkan data secara fisik ke penyimpanan BigQuery. Pemrosesan terjadi di tempat data tersebut berada.
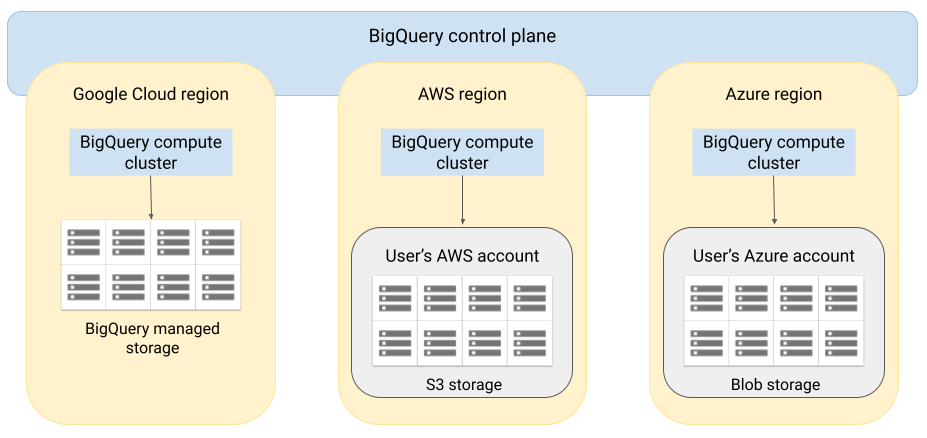
Hasil kueri dapat ditampilkan ke Google Cloud melalui koneksi yang aman, — misalnya untuk ditampilkan di konsol Google Cloud . Atau, Anda dapat menulis hasilnya langsung ke bucket Amazon S3 atau Blob Storage. Dalam kasus ini, tidak ada perpindahan lintas cloud dari hasil kueri.
BigQuery Omni menggunakan peran IAM AWS standar atau akun utama Azure Active Directory untuk mengakses data di langganan Anda. Anda mendelegasikan akses baca atau tulis ke BigQuery Omni, dan dapat mencabut akses kapan saja.
Aliran data saat mengkueri data
Gambar berikut menjelaskan cara data berpindah antara Google Cloud dan AWS atau Azure untuk kueri berikut:
- Pernyataan
SELECT - Pernyataan
CREATE EXTERNAL TABLE

- Bidang kontrol BigQuery menerima tugas kueri dari Anda melalui Google Cloud konsol, alat command line bq, metode API, atau library klien.
- Bidang kontrol BigQuery mengirimkan tugas kueri untuk diproses ke bidang data BigQuery di AWS atau Azure.
- Bidang data BigQuery menerima kueri dari bidang kontrol melalui koneksi VPN.
- Bidang data BigQuery membaca data tabel dari bucket Amazon S3 atau Blob Storage.
- Bidang data BigQuery menjalankan tugas kueri pada data tabel. Pemrosesan data tabel terjadi di region AWS atau Azure yang ditentukan.
- Hasil kueri ditransmisikan dari bidang data ke bidang kontrol melalui koneksi VPN.
- Bidang kontrol BigQuery menerima hasil tugas kueri untuk ditampilkan kepada Anda sebagai respons terhadap tugas kueri. Data ini disimpan hingga 24 jam.
- Hasil kueri dikembalikan kepada Anda.
Untuk mengetahui informasi selengkapnya, baca Membuat kueri data Amazon S3 dan Data Azure Blob Storage.
Aliran data saat mengekspor data
Gambar berikut menjelaskan cara perpindahan data antara Google Cloud dan AWS
atau Azure selama pernyataan EXPORT DATA.

- Bidang kontrol BigQuery menerima tugas kueri ekspor dari Anda melalui Google Cloud konsol, alat command line bq, metode API, atau library klien. Kueri berisi jalur tujuan untuk hasil kueri di bucket Amazon S3 atau Blob Storage.
- Bidang kontrol BigQuery mengirimkan tugas kueri ekspor untuk diproses ke bidang data BigQuery (di AWS atau Azure).
- Bidang data BigQuery menerima kueri ekspor dari bidang kontrol melalui koneksi VPN.
- Bidang data BigQuery membaca data tabel dari bucket Amazon S3 atau Blob Storage.
- Bidang data BigQuery menjalankan tugas kueri pada data tabel. Pemrosesan data tabel terjadi di region AWS atau Azure yang ditentukan.
- BigQuery menulis hasil kueri ke jalur tujuan yang ditentukan dalam bucket Amazon S3 atau Blob Storage.
Untuk mengetahui informasi selengkapnya, baca Mengekspor hasil kueri ke Amazon S3 dan Blob Storage.
Manfaat
Performa. Anda bisa mendapatkan insight lebih cepat karena data tidak disalin di cloud, dan kueri berjalan di region yang sama dengan tempat data Anda berada.
Biaya. Anda menghemat biaya transfer data keluar karena data tidak berpindah. Tidak ada biaya tambahan untuk akun AWS atau Azure Anda terkait analisis BigQuery Omni, karena kueri berjalan pada cluster yang dikelola oleh Google. Anda hanya akan ditagih untuk menjalankan kueri, menggunakan model harga BigQuery.
Keamanan dan tata kelola data. Anda dapat mengelola data di langganan AWS atau Azure Anda sendiri. Anda tidak perlu memindahkan atau menyalin data mentah dari cloud publik. Semua komputasi terjadi di layanan multi-tenant BigQuery yang berjalan dalam region yang sama dengan data Anda.
Arsitektur serverless. Seperti BigQuery lainnya, BigQuery Omni adalah penawaran serverless. Google men-deploy dan mengelola cluster yang menjalankan BigQuery Omni. Anda tidak perlu menyediakan resource atau mengelola cluster apa pun.
Kemudahan pengelolaan. BigQuery Omni menyediakan antarmuka pengelolaan terpadu melalui Google Cloud. BigQuery Omni dapat menggunakan akun Google Cloud dan project BigQuery yang sudah ada. Anda dapat menulis kueri GoogleSQL di konsol Google Cloud untuk melakukan kueri data di AWS atau Azure, dan melihat hasil yang ditampilkan di konsol Google Cloud .
Transfer lintas cloud. Anda dapat memuat data ke tabel BigQuery standar dari bucket S3 dan Blob Storage. Untuk mengetahui informasi selengkapnya, baca artikel Mentransfer data Amazon S3 dan Memindahkan data Blob Storage ke BigQuery.
Penyimpanan cache metadata untuk peningkatan performa
Anda dapat menggunakan metadata yang di-cache untuk meningkatkan performa kueri pada tabel BigLake yang mereferensikan data Amazon S3. Hal ini sangat membantu terutama jika Anda mengerjakan sejumlah besar file atau jika data dipartisi oleh Apache Hive.
BigQuery menggunakan CMETA sebagai sistem metadata terdistribusi untuk menangani tabel besar secara efisien. CMETA menyediakan metadata terperinci di tingkat kolom dan blok, yang dapat diakses melalui tabel sistem. Sistem ini membantu meningkatkan performa kueri dengan mengoptimalkan akses dan pemrosesan data. Untuk lebih mempercepat performa kueri pada tabel besar, BigQuery mempertahankan cache metadata. Tugas pembaruan CMETA membuat cache ini tetap terbaru.Metadata tersebut mencakup nama file, informasi partisi, dan metadata fisik dari file seperti jumlah baris. Anda dapat memilih apakah akan mengaktifkan caching metadata di tabel atau tidak. Kueri dengan jumlah file yang besar dan filter partisi Apache Hive akan mendapatkan manfaat terbesar dari caching metadata.
Jika Anda tidak mengaktifkan caching metadata, kueri pada tabel harus membaca sumber data eksternal untuk mendapatkan metadata objek. Membaca data ini akan meningkatkan latensi kueri; membuat daftar jutaan file dari sumber data eksternal dapat memakan waktu beberapa menit. Jika Anda mengaktifkan caching metadata, kueri dapat menghindari pencantuman file dari sumber data eksternal serta dapat mempartisi dan memangkas file dengan lebih cepat.
Caching metadata juga terintegrasi dengan pembuatan versi objek Cloud Storage. Saat diisi atau diperbarui, cache akan mengambil metadata berdasarkan versi aktif objek Cloud Storage pada saat itu. Akibatnya, kueri yang mengaktifkan penayangan cache metadata membaca data yang sesuai dengan versi objek yang di-cache tertentu, meskipun versi yang lebih baru menjadi aktif di Cloud Storage. Mengakses data dari versi objek yang diperbarui berikutnya di Cloud Storage memerlukan refresh cache metadata.
Ada dua properti yang mengontrol fitur ini:
- Keusangan maksimum menentukan kapan kueri menggunakan metadata yang disimpan dalam cache.
- Mode cache metadata menentukan cara metadata dikumpulkan.
Saat mengaktifkan caching metadata, Anda dapat menentukan interval maksimum keusangan metadata yang dapat diterima untuk operasi terhadap tabel. Misalnya, jika Anda menentukan interval 1 jam, operasi terhadap tabel akan menggunakan metadata yang disimpan dalam cache jika telah diperbarui dalam satu jam terakhir. Jika metadata yang di-cache lebih lama dari itu, operasi akan kembali untuk mengambil metadata dari Amazon S3. Anda dapat menentukan interval keusangan antara 30 menit dan 7 hari.
Saat Anda mengaktifkan caching metadata untuk tabel BigLake atau tabel objek, BigQuery akan memicu tugas refresh pembuatan metadata. Anda dapat memilih untuk memuat ulang cache secara otomatis atau manual:
- Untuk pemuatan ulang otomatis, cache dimuat ulang pada interval yang ditentukan sistem, biasanya antara 30 dan 60 menit. Memperbarui cache secara otomatis merupakan pendekatan yang baik jika file di Amazon S3 ditambahkan, dihapus, atau diubah secara acak. Jika Anda perlu mengontrol waktu pemuatan ulang, misalnya untuk memicu pemuatan ulang di akhir tugas pemuatan transformasi ekstrak, gunakan pemuatan ulang manual.
Untuk pemuatan ulang manual, Anda akan menjalankan prosedur sistem
BQ.REFRESH_EXTERNAL_METADATA_CACHEuntuk memuat ulang cache metadata sesuai jadwal yang memenuhi persyaratan Anda. Memperbarui cache secara manual adalah pendekatan yang baik jika file di Amazon S3 ditambahkan, dihapus, atau diubah pada interval yang diketahui, misalnya sebagai output pipeline.Jika Anda melakukan beberapa pemuatan ulang manual secara serentak, hanya satu yang akan berhasil.
Cache metadata akan habis masa berlakunya setelah 7 hari jika tidak diperbarui.
Pembaruan cache manual dan otomatis dijalankan dengan
prioritas kueri INTERACTIVE.
Menggunakan reservasi BACKGROUND
Jika Anda memilih untuk menggunakan pembaruan otomatis, sebaiknya buat
pemesanan, lalu buat
tugas dengan jenis tugas BACKGROUND
untuk project yang menjalankan tugas pembaruan cache metadata. Dengan BACKGROUND pemesanan, tugas pembaruan menggunakan kumpulan resource khusus yang mencegah tugas pembaruan bersaing dengan kueri pengguna, dan mencegah tugas berpotensi gagal jika tidak tersedia resource yang memadai.
Meskipun penggunaan kumpulan slot bersama tidak menimbulkan biaya tambahan, penggunaan reservasi BACKGROUND memberikan performa yang lebih konsisten dengan mengalokasikan kumpulan resource khusus, serta meningkatkan keandalan tugas pemuatan ulang dan efisiensi kueri secara keseluruhan di BigQuery.
Anda harus mempertimbangkan bagaimana nilai interval keusangan dan mode caching metadata akan berinteraksi sebelum menetapkannya. Perhatikan contoh berikut:
- Jika Anda memuat ulang cache metadata secara manual untuk sebuah tabel, dan menetapkan
interval usang menjadi 2 hari, Anda harus menjalankan
prosedur sistem
BQ.REFRESH_EXTERNAL_METADATA_CACHEsetiap 2 hari atau kurang jika menginginkan operasi terhadap tabel agar menggunakan metadata yang disimpan dalam cache. - Jika Anda otomatis memuat ulang cache metadata untuk sebuah tabel, dan menetapkan interval usang menjadi 30 menit, beberapa operasi terhadap tabel kemungkinan akan dibaca dari Amazon S3 jika pemuatan ulang cache metadata memerlukan waktu yang lebih lama daripada periode 30 hingga 60 menit seperti biasanya.
Untuk menemukan informasi tentang tugas pemuatan ulang metadata, buat kueri
tampilan INFORMATION_SCHEMA.JOBS,
seperti yang ditunjukkan dalam contoh berikut:
SELECT * FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` WHERE job_id LIKE '%metadata_cache_refresh%' AND creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 6 HOUR) ORDER BY start_time DESC LIMIT 10;
Untuk mengetahui informasi selengkapnya, lihat Caching metadata.
Tabel yang mendukung cache dengan tampilan terwujud
Anda dapat menggunakan tampilan terwujud melalui tabel yang mendukung cache metadata Amazon Simple Storage Service (Amazon S3) untuk meningkatkan performa dan efisiensi saat membuat kueri data terstruktur yang disimpan di Amazon S3. Tampilan terwujud ini berfungsi seperti tampilan terwujud melalui tabel penyimpanan yang dikelola BigQuery, termasuk manfaat pemuatan ulang otomatis dan smart tuning.
Untuk membuat data Amazon S3 dalam tampilan terwujud tersedia di region BigQuery yang didukung untuk gabungan, buat replika tampilan terwujud. Anda hanya dapat membuat replika tampilan terwujud melalui tampilan terwujud yang diotorisasi.
Batasan
Selain batasan untuk tabel BigLake, batasan berikut berlaku untuk BigQuery Omni, yang mencakup tabel BigLake berdasarkan data Amazon S3 dan Blob Storage:
- Penanganan data di salah satu region BigQuery Omni tidak didukung oleh edisi Standard dan Enterprise Plus. Untuk mengetahui informasi selengkapnya tentang edisi, lihat Pengantar edisi BigQuery.
- Tampilan
INFORMATION_SCHEMA,OBJECT_PRIVILEGES,STREAMING_TIMELINE_BY_*,TABLE_SNAPSHOTS,TABLE_STORAGE,TABLE_CONSTRAINTS,KEY_COLUMN_USAGE,CONSTRAINT_COLUMN_USAGE, danPARTITIONStidak tersedia untuk tabel BigLake berdasarkan data Amazon S3 dan Blob Storage. - Tampilan terwujud tidak didukung untuk Blob Storage.
- UDF JavaScript tidak didukung.
Pernyataan SQL berikut tidak didukung:
- Pernyataan BigQuery ML.
- Pernyataan bahasa definisi data (DDL)
yang memerlukan data yang dikelola di BigQuery. Misalnya,
CREATE EXTERNAL TABLE,CREATE SCHEMA, atauCREATE RESERVATIONdidukung, tetapiCREATE TABLEtidak. - Pernyataan bahasa manipulasi data (DML).
Batasan berikut berlaku pada proses kueri dan pembacaan tabel sementara tujuan:
- Membuat kueri tabel sementara tujuan dengan pernyataan
SELECTtidak didukung.
- Membuat kueri tabel sementara tujuan dengan pernyataan
Kueri terjadwal hanya didukung melalui metode API atau CLI. Opsi tabel tujuan dinonaktifkan untuk kueri. Hanya kueri
EXPORT DATAyang diizinkan.BigQuery Storage API tidak tersedia di region BigQuery Omni.
Jika kueri Anda menggunakan klausa
ORDER BYdan memiliki ukuran hasil lebih besar dari 256 MB, kueri Anda akan gagal. Untuk mengatasi hal ini, perkecil ukuran hasil atau hapus klausaORDER BYdari kueri. Untuk mengetahui informasi selengkapnya tentang kuota BigQuery Omni, lihat Kuota dan batas.Penggunaan kunci enkripsi yang dikelola pelanggan (CMEK) dengan set data dan tabel eksternal tidak didukung.
Harga
Untuk mengetahui informasi tentang harga dan penawaran berbatas waktu di BigQuery Omni, lihat harga BigQuery Omni.
Kuota dan batas
Untuk mengetahui informasi tentang kuota BigQuery Omni, lihat Kuota dan batas.
Jika hasil kueri Anda lebih dari 20 GiB, sebaiknya ekspor hasilnya ke Amazon S3 atau Blob Storage. Untuk mempelajari kuota untuk BigQuery Connection API, lihat BigQuery Connection API.
Lokasi
BigQuery Omni memproses kueri di lokasi yang sama dengan set data yang berisi tabel yang Anda kuerikan. Setelah Anda membuat set data, lokasi tidak dapat diubah. Data Anda berada dalam akun AWS atau Azure Anda. Region BigQuery Omni mendukung pemesanan edisi Enterprise dan harga compute (analisis) on demand. Untuk informasi selengkapnya tentang edisi, lihat Pengantar edisi BigQuery.
| Deskripsi region | Nama region | Region BigQuery yang digabungkan | |
|---|---|---|---|
| AWS | |||
| AWS - AS Timur (N. Utara) | aws-us-east-1 |
us-east4 |
|
| AWS - AS Barat (Oregon) | aws-us-west-2 |
us-west1 |
|
| AWS - Asia Pasifik (Seoul) | aws-ap-northeast-2 |
asia-northeast3 |
|
| AWS - Asia Pasifik (Sydney) | aws-ap-southeast-2 |
australia-southeast1 |
|
| AWS - Eropa (Irlandia) | aws-eu-west-1 |
europe-west1 |
|
| AWS - Eropa (Frankfurt) | aws-eu-central-1 |
europe-west3 |
|
| Azure | |||
| Azure - East US 2 | azure-eastus2 |
us-east4 |
|
Langkah berikutnya
- Pelajari cara terhubung ke Amazon S3 dan Blob Storage.
- Pelajari cara membuat tabel BigLake Amazon S3 dan Blob Storage.
- Pelajari cara membuat kueri tabel BigLake Amazon S3 dan Blob Storage.
- Pelajari cara menggabungkan tabel BigLake Amazon S3 dan Blob Storage dengan tabel Google Cloud menggunakan gabungan lintas cloud.
- Pelajari cara mengekspor hasil kueri ke Amazon S3 dan Blob Storage.
- Pelajari cara mentransfer data dari Amazon S3 dan Blob Storage ke BigQuery.
- Pelajari cara menyiapkan perimeter Kontrol Layanan VPC.
- Pelajari cara menentukan lokasi