Migración de Oracle a BigQuery
En este documento se ofrecen directrices generales sobre cómo migrar de Oracle a BigQuery. En él se describen las diferencias fundamentales de arquitectura y se sugieren formas de migrar de almacenes de datos y data marts que se ejecutan en Oracle RDBMS (incluido Exadata) a BigQuery. Este documento también proporciona detalles que se pueden aplicar a Exadata, ExaCC y Oracle Autonomous Data Warehouse, ya que utilizan software de Oracle compatible.
Este documento está dirigido a arquitectos empresariales, administradores de bases de datos, desarrolladores de aplicaciones y profesionales de seguridad de TI que quieran migrar de Oracle a BigQuery y resolver los problemas técnicos que surjan durante el proceso de migración.
También puedes usar la traducción de SQL por lotes para migrar tus secuencias de comandos SQL en bloque o la traducción de SQL interactiva para traducir consultas específicas. Oracle SQL, PL/SQL y Exadata son compatibles con ambas herramientas en vista previa.
Antes de la migración
Para que la migración del almacén de datos se lleve a cabo correctamente, empieza a planificar tu estrategia de migración al principio del proyecto. Para obtener información sobre cómo planificar sistemáticamente el trabajo de migración, consulta Qué migrar y cómo hacerlo: el marco de migración.
Planificación de la capacidad de BigQuery
En segundo plano, el rendimiento de las analíticas en BigQuery se mide en slots. Las ranuras de BigQuery son las unidades de capacidad informática propias de Google que se necesitan para ejecutar consultas de SQL.
BigQuery calcula continuamente cuántas ranuras necesitan las consultas mientras se ejecutan, pero asigna las ranuras a las consultas en función de un programador justo.
Puedes elegir entre los siguientes modelos de precios al planificar la capacidad de las ranuras de BigQuery:
Precios bajo demanda: con este modelo, BigQuery cobra por el número de bytes procesados (tamaño de los datos), por lo que solo pagas por las consultas que ejecutas. Para obtener más información sobre cómo determina BigQuery el tamaño de los datos, consulta la sección Cálculo del tamaño de los datos. Como las ranuras determinan la capacidad computacional subyacente, puedes pagar por el uso de BigQuery en función del número de ranuras que necesites (en lugar de por los bytes procesados). De forma predeterminada, los proyectos Google Cloud tienen un límite de 2000 slots.
Precios basados en la capacidad: con este modelo, compras reservas de ranuras de BigQuery (un mínimo de 100) en lugar de pagar por los bytes procesados por las consultas que ejecutas. Recomendamos la opción de precios basada en la capacidad para las cargas de trabajo de almacenes de datos empresariales, que suelen tener muchas consultas simultáneas de informes y de extracción, carga y transformación (ELT) con un consumo predecible.
Para ayudarte a estimar las ranuras, te recomendamos que configures la monitorización de BigQuery con Cloud Monitoring y que analices tus registros de auditoría con BigQuery. Muchos clientes usan Looker Studio (por ejemplo, consulta un ejemplo de software libre de un panel de control de Looker Studio), Looker o Tableau como front-ends para visualizar los datos de registro de auditoría de BigQuery, en concreto el uso de ranuras en consultas y proyectos. También puede usar los datos de las tablas de sistema de BigQuery para monitorizar la utilización de ranuras en las tareas y las reservas. Por ejemplo, consulta un ejemplo de código abierto de un panel de control de Looker Studio.
Si monitorizas y analizas periódicamente la utilización de tus espacios publicitarios, podrás estimar cuántos espacios publicitarios necesita tu organización a medida que crezca en Google Cloud.
Por ejemplo, supongamos que inicialmente reserva 4000 ranuras de BigQuery para ejecutar 100 consultas de complejidad media simultáneamente. Si observas tiempos de espera elevados en los planes de ejecución de tus consultas y tus paneles muestran una utilización de ranuras alta, puede que necesites ranuras de BigQuery adicionales para admitir tus cargas de trabajo. Si quieres comprar ranuras por tu cuenta mediante compromisos anuales o trienales, puedes empezar a usar las reservas de BigQuery con la consola de Google Cloud o la herramienta de línea de comandos bq.
Si tienes alguna pregunta relacionada con tu plan actual y las opciones anteriores, ponte en contacto con tu representante de ventas.
Seguridad en Google Cloud
En las siguientes secciones se describen los controles de seguridad habituales de Oracle y cómo puede asegurarse de que su almacén de datos esté protegido en un entorno de Google Cloud.
Gestión de identidades y accesos (IAM)
Oracle proporciona usuarios, privilegios, roles y perfiles para gestionar el acceso a los recursos.
BigQuery usa IAM para gestionar el acceso a los recursos y proporciona una gestión de acceso centralizada a los recursos y las acciones. Los tipos de recursos disponibles en BigQuery incluyen organizaciones, proyectos, conjuntos de datos, tablas y vistas. En la jerarquía de políticas de gestión de identidades y accesos, los conjuntos de datos son recursos secundarios de los proyectos. Una tabla hereda los permisos del conjunto de datos que la contiene.
Para conceder acceso a un recurso, asigna uno o varios roles a un usuario, un grupo o una cuenta de servicio. Los roles de organización y de proyecto influyen en la capacidad de ejecutar trabajos o gestionar el proyecto, mientras que los roles de conjunto de datos influyen en la capacidad de acceder a los datos de un proyecto o modificarlos.
IAM proporciona estos tipos de roles:
- Los roles predefinidos se han diseñado para admitir casos prácticos y patrones de control de acceso habituales. Los roles predefinidos proporcionan acceso granular a un servicio específico y los gestiona Google Cloud.
Los roles básicos incluyen los roles de propietario, editor y lector.
Los roles personalizados proporcionan acceso granular según una lista de permisos especificada por el usuario.
Cuando asignas roles predefinidos y básicos a un usuario, los permisos que se le conceden son la unión de los permisos de cada rol.
Seguridad a nivel de fila
Oracle Label Security (OLS) permite restringir el acceso a los datos fila por fila. Un caso de uso habitual de la seguridad a nivel de fila es restringir el acceso de un vendedor a las cuentas que gestiona. Al implementar la seguridad a nivel de fila, obtienes un control de acceso pormenorizado.
Para conseguir la seguridad a nivel de fila en BigQuery, puedes usar vistas autorizadas y políticas de acceso a nivel de fila. Para obtener más información sobre cómo diseñar e implementar estas políticas, consulta la introducción a la seguridad a nivel de fila de BigQuery.
Cifrado de disco completo
Oracle ofrece Encriptado de datos transparente (TDE) y encriptado de red para el encriptado de datos en reposo y en tránsito. TDE requiere la opción Seguridad avanzada, que se licencia por separado.
BigQuery cifra todos los datos en reposo y en tránsito de forma predeterminada, independientemente de la fuente o de cualquier otra condición, y esta opción no se puede desactivar. BigQuery también admite claves de cifrado gestionadas por el cliente (CMEK) para los usuarios que quieran controlar y gestionar las claves de cifrado de claves en Cloud Key Management Service. Para obtener más información sobre el cifrado en Google Cloud, consulta Cifrado predeterminado en reposo y Cifrado en tránsito.
Enmascaramiento y ocultación de datos
Oracle usa el enmascaramiento de datos en Real Application Testing y la ocultación de datos, que te permite enmascarar (ocultar) los datos que devuelven las consultas emitidas por las aplicaciones.
BigQuery admite el enmascaramiento dinámico de datos a nivel de columna. Puedes usar esta función para ocultar datos de las columnas a determinados grupos de usuarios, quienes podrán seguir accediendo a dichas columnas.
Puede usar Protección de Datos Sensibles para identificar y ocultar información personal identificable (IPI) sensible en BigQuery.
Comparación entre BigQuery y Oracle
En esta sección se describen las principales diferencias entre BigQuery y Oracle. Estos aspectos destacados te ayudan a identificar los obstáculos de la migración y a planificar los cambios necesarios.
Arquitectura del sistema
Una de las principales diferencias entre Oracle y BigQuery es que BigQuery es un EDW en la nube sin servidor con capas de almacenamiento y de computación independientes que se pueden escalar en función de las necesidades de la consulta. Dada la naturaleza de la oferta sin servidor de BigQuery, no estás limitado por las decisiones de hardware. En su lugar, puedes solicitar más recursos para tus consultas y usuarios mediante reservas. BigQuery tampoco requiere la configuración del software y la infraestructura subyacentes, como el sistema operativo, los sistemas de red y los sistemas de almacenamiento, incluidos el escalado y la alta disponibilidad. BigQuery se encarga de la escalabilidad, la gestión y las operaciones administrativas. En el siguiente diagrama se muestra la jerarquía de almacenamiento de BigQuery.
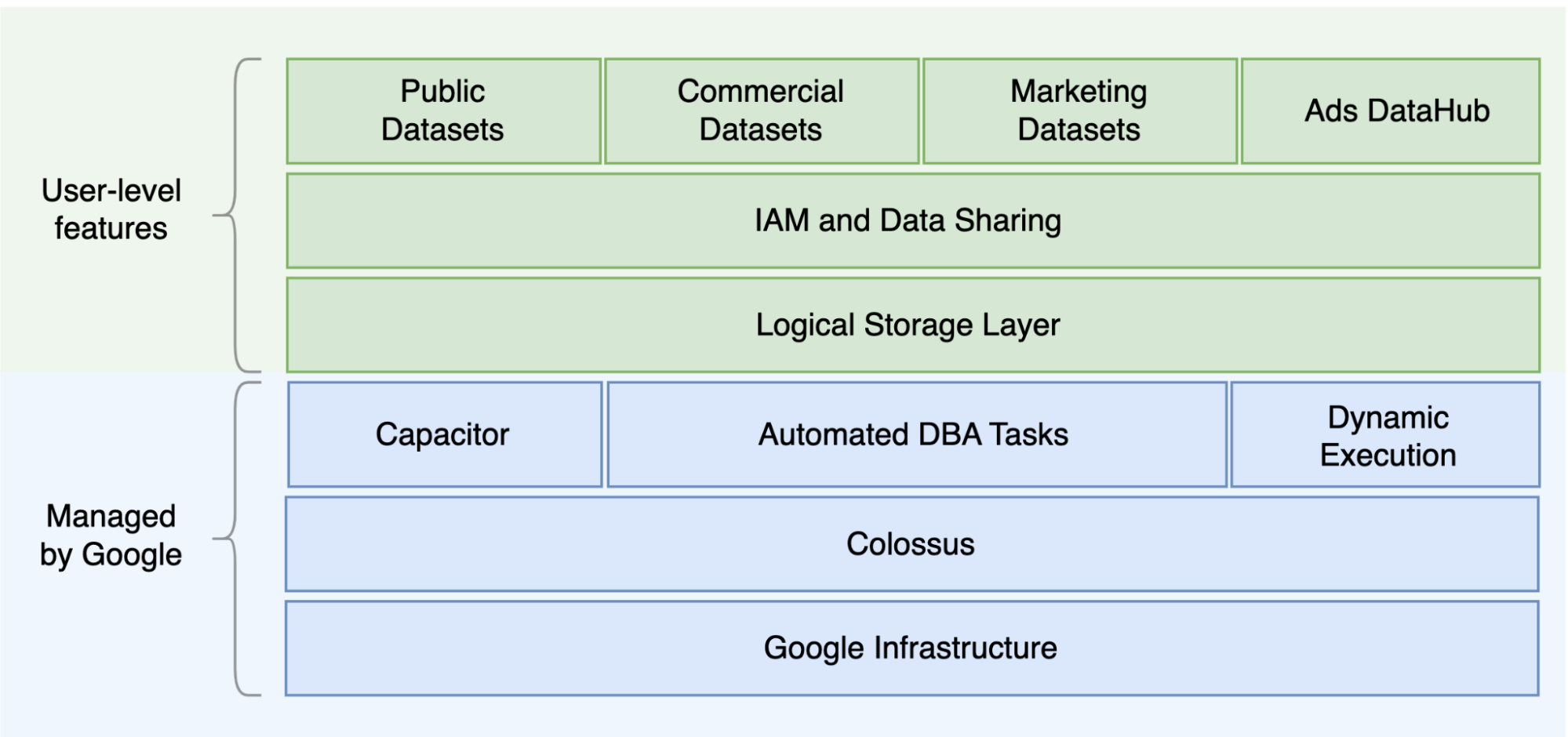
Conocer la arquitectura subyacente de almacenamiento y procesamiento de consultas, como la separación entre el almacenamiento (Colossus) y la ejecución de consultas (Dremel), y cómoGoogle Cloud asigna recursos (Borg) puede ser útil para comprender las diferencias de comportamiento y optimizar el rendimiento de las consultas y la rentabilidad. Para obtener más información, consulta las arquitecturas de sistemas de referencia de BigQuery, Oracle y Exadata.
Arquitectura de datos y almacenamiento
La estructura de los datos y el almacenamiento es una parte importante de cualquier sistema de analíticas de datos, ya que afecta al rendimiento de las consultas, al coste, a la escalabilidad y a la eficiencia.
BigQuery separa el almacenamiento de datos y el procesamiento y almacena los datos en Colossus, donde se comprimen y se guardan en un formato de columnas llamado Capacitor.
BigQuery opera directamente en datos comprimidos sin descomprimirlos mediante Capacitor. BigQuery proporciona conjuntos de datos como abstracción de nivel superior para organizar el acceso a las tablas, tal como se muestra en el diagrama anterior. Los esquemas y las etiquetas se pueden usar para organizar las tablas. BigQuery ofrece particiones para mejorar el rendimiento y los costes de las consultas, así como para gestionar el ciclo de vida de la información. Los recursos de almacenamiento se asignan a medida que los consumes y se desasignan a medida que eliminas datos o quitas tablas.
Oracle almacena los datos en formato de fila mediante el formato de bloque de Oracle, que se organiza en segmentos. Los esquemas (propiedad de los usuarios) se usan para organizar tablas y otros objetos de la base de datos. Desde Oracle 12c, se usa multitenant para crear bases de datos conectables en una instancia de base de datos para aumentar el aislamiento. Las particiones se pueden usar para mejorar el rendimiento de las consultas y las operaciones del ciclo de vida de la información. Oracle ofrece varias opciones de almacenamiento para bases de datos independientes y Real Application Clusters (RAC), como ASM, un sistema de archivos del SO y un sistema de archivos de clúster.
Exadata proporciona una infraestructura de almacenamiento optimizada en servidores de celdas de almacenamiento y permite que los servidores de Oracle accedan a estos datos de forma transparente mediante ASM. Exadata ofrece opciones de compresión columnar híbrida (HCC) para que los usuarios puedan comprimir tablas y particiones.
Oracle requiere una capacidad de almacenamiento aprovisionada previamente, un dimensionamiento cuidadoso y configuraciones de incremento automático en segmentos, archivos de datos y espacios de tabla.
Ejecución y rendimiento de las consultas
BigQuery gestiona el rendimiento y se escala a nivel de consulta para maximizar el rendimiento en función del coste. BigQuery usa muchas optimizaciones, como las siguientes:
- Ejecución de consultas en memoria
- Arquitectura de árbol multinivel basada en el motor de ejecución Dremel
- Optimización automática del almacenamiento en Capacitor
- Ancho de banda de bisección total de 1 petabit por segundo con Jupiter
- Gestión de recursos de autoescalado para ofrecer consultas rápidas a escala de petabytes
BigQuery recoge estadísticas de las columnas mientras carga los datos e incluye información de diagnóstico sobre el plan de consulta y los tiempos. Los recursos de consulta se asignan según el tipo y la complejidad de la consulta. Cada consulta usa un número determinado de ranuras, que son unidades de cálculo que incluyen una cantidad concreta de CPU y RAM.
Oracle proporciona tareas de recopilación de estadísticas de datos. El optimizador de la base de datos usa estadísticas para proporcionar planes de ejecución óptimos. Es posible que se necesiten índices para realizar búsquedas rápidas de filas y operaciones de unión. Oracle también ofrece un almacén de columnas en memoria para analíticas en memoria. Exadata ofrece varias mejoras de rendimiento, como el análisis inteligente de celdas, los índices de almacenamiento, la caché flash y las conexiones InfiniBand entre los servidores de almacenamiento y los servidores de bases de datos. Real Application Clusters (RAC) se puede usar para conseguir una alta disponibilidad de los servidores y escalar las aplicaciones que requieren un uso intensivo de la CPU de la base de datos con el mismo almacenamiento subyacente.
Para optimizar el rendimiento de las consultas con Oracle, es necesario tener en cuenta estas opciones y parámetros de la base de datos. Oracle ofrece varias herramientas, como el historial de sesiones activas (ASH), el monitor de diagnóstico automático de bases de datos (ADDM), los informes del repositorio de carga de trabajo automático (AWR), la monitorización de SQL y el asesor de optimización, así como los asesores de optimización de la memoria y de la función deshacer, para optimizar el rendimiento.
Analíticas ágiles
En BigQuery, puedes permitir que diferentes proyectos, usuarios y grupos consulten conjuntos de datos de distintos proyectos. La separación de la ejecución de consultas permite que los equipos autónomos trabajen en sus proyectos sin afectar a otros usuarios ni proyectos, ya que se separan las cuotas de ranuras y la facturación de las consultas de otros proyectos y de los proyectos que alojan los conjuntos de datos.
Alta disponibilidad, copias de seguridad y recuperación tras desastres
Oracle ofrece Data Guard como solución de recuperación tras desastres y replicación de bases de datos. Real Application Clusters (RAC) se puede configurar para la disponibilidad del servidor. Las copias de seguridad de Recovery Manager (RMAN) se pueden configurar para las copias de seguridad de bases de datos y de archivos de registro, y también se pueden usar para operaciones de restauración y recuperación. La función Flashback database (Restauración a un punto anterior de la base de datos) se puede usar para restaurar la base de datos a un momento específico. Deshacer las capturas de tablas de retenciones de espacios de tablas. Es posible consultar las capturas antiguas con las cláusulas de consulta de flashback y "as of" en función de las operaciones DML/DDL realizadas anteriormente y de los ajustes de conservación de deshacer. En Oracle, la integridad de la base de datos debe gestionarse en espacios de tabla que dependan de los metadatos del sistema, la función de deshacer y los espacios de tabla correspondientes, ya que la coherencia sólida es importante para las copias de seguridad de Oracle y los procedimientos de recuperación deben incluir todos los datos primarios. Puedes programar exportaciones a nivel de esquema de tabla si no necesitas la recuperación a un momento dado en Oracle.
BigQuery está totalmente gestionado y se diferencia de los sistemas de bases de datos tradicionales en su funcionalidad de copia de seguridad completa. No tienes que preocuparte por los fallos de los servidores o del almacenamiento, los errores del sistema ni los daños físicos de los datos. BigQuery replica los datos en diferentes centros de datos en función de la ubicación del conjunto de datos para maximizar la fiabilidad y la disponibilidad. La función multirregional de BigQuery replica los datos en diferentes regiones y protege contra la falta de disponibilidad de una sola zona dentro de la región. La función de una sola región de BigQuery replica los datos en diferentes zonas de la misma región.
BigQuery te permite consultar las copias de las tablas de los últimos siete días y restaurar las tablas eliminadas en un plazo de dos días mediante la función de viaje en el tiempo.
Puedes copiar una tabla eliminada (para restaurarla) mediante la sintaxis de instantánea (dataset.table@timestamp).
Puedes exportar datos de tablas de BigQuery para cubrir necesidades de copia de seguridad adicionales, como la recuperación de operaciones de usuario accidentales. Se pueden usar estrategias y programaciones de copias de seguridad probadas para los sistemas de almacén de datos (DWH) actuales.
Las operaciones por lotes y la técnica de creación de copias de un momento dado permiten usar diferentes estrategias de copia de seguridad en BigQuery, por lo que no es necesario exportar con frecuencia las tablas y particiones que no han cambiado. Una copia de seguridad de exportación de la partición o la tabla es suficiente una vez que finaliza la operación de carga o ETL. Para reducir el coste de las copias de seguridad, puedes almacenar los archivos de exportación en Nearline Storage o Coldline Storage de Cloud Storage y definir una política de ciclo de vida para eliminar los archivos después de un periodo determinado, en función de los requisitos de retención de datos.
Almacenamiento en caché
BigQuery ofrece caché por usuario y, si los datos no cambian, los resultados de las consultas se almacenan en caché durante aproximadamente 24 horas. Si los resultados se obtienen de la caché, la consulta no tiene ningún coste.
Oracle ofrece varias cachés para datos y resultados de consultas, como la caché de búfer, la caché de resultados, la caché flash de Exadata y el almacén de columnas en memoria.
Conexiones
BigQuery gestiona las conexiones y no requiere que hagas ninguna configuración del lado del servidor. BigQuery proporciona controladores JDBC y ODBC. Puedes usar la consola Google Cloud o la bq command-line tool para hacer consultas interactivas. Puedes usar APIs REST y bibliotecas de cliente para interactuar con BigQuery de forma programática. También puedes conectar Hojas de cálculo de Google directamente con BigQuery y usar controladores ODBC y JDBC para conectarte a Excel. Si buscas un cliente de escritorio, hay herramientas gratuitas como DBeaver.
Oracle proporciona listeners, servicios, controladores de servicios, varios parámetros de configuración y ajuste, y servidores compartidos y dedicados para gestionar las conexiones de la base de datos. Oracle proporciona controladores JDBC, JDBC Thin y ODBC, Oracle Client y conexiones TNS. Se necesitan listeners de análisis, direcciones IP de análisis y nombres de análisis para las configuraciones de RAC.
Precios y licencias
Oracle requiere licencias y tarifas de asistencia en función del número de núcleos de las ediciones de la base de datos y de las opciones de la base de datos, como RAC, multitenant, Active Data Guard, particiones, in-memory, Real Application Testing, GoldenGate y Spatial and Graph.
BigQuery ofrece opciones de precios flexibles en función del uso del almacenamiento, las consultas y las inserciones en tiempo real. BigQuery ofrece precios basados en la capacidad a los clientes que necesitan costes y capacidad de ranuras predecibles en regiones específicas. Las ranuras que se usan para inserciones y cargas de streaming no se contabilizan en la capacidad de ranuras del proyecto. Para decidir cuántas ranuras quieres comprar para tu almacén de datos, consulta el artículo sobre la planificación de la capacidad de BigQuery.
BigQuery también reduce automáticamente a la mitad los costes de almacenamiento de los datos que no se han modificado y que se han almacenado durante más de 90 días.
Etiquetado
Los conjuntos de datos, las tablas y las vistas de BigQuery se pueden etiquetar con pares clave-valor. Las etiquetas se pueden usar para diferenciar los costes de almacenamiento y las devoluciones de cargos internas.
Monitorización y registro de auditoría
Oracle ofrece diferentes niveles y tipos de opciones de auditoría de bases de datos, así como audit vault y funciones de firewall de bases de datos, que se licencian por separado. Oracle proporciona Enterprise Manager para monitorizar bases de datos.
En BigQuery, se usan los registros de auditoría de Cloud tanto para los registros de acceso a datos como para los registros de auditoría, que están habilitados de forma predeterminada. Los registros de acceso a datos están disponibles durante 30 días, mientras que los demás registros de eventos del sistema y de actividad del administrador están disponibles durante 400 días. Si necesitas conservar los registros durante más tiempo, puedes exportarlos a BigQuery, Cloud Storage o Pub/Sub, tal como se describe en Analíticas de registros de seguridad en Google Cloud. Si se necesita una integración con una herramienta de monitorización de incidencias, se puede usar Pub/Sub para las exportaciones y se debe desarrollar una herramienta personalizada para leer los registros de Pub/Sub.
Los registros de auditoría incluyen todas las llamadas a la API, las instrucciones de consulta y los estados de los trabajos. Puedes usar Cloud Monitoring para monitorizar la asignación de ranuras, los bytes analizados en las consultas y almacenados, y otras métricas de BigQuery. El plan y la cronología de las consultas de BigQuery se pueden usar para analizar las fases y el rendimiento de las consultas.
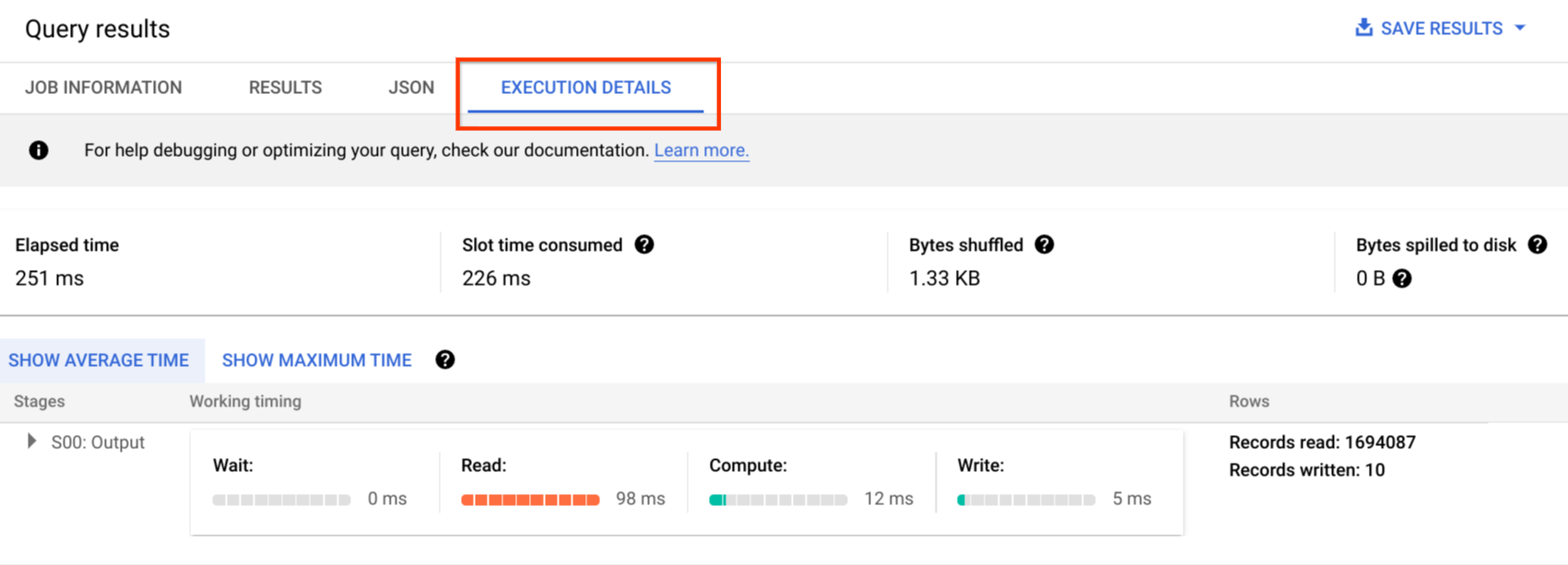
Puedes usar la tabla de mensajes de error para solucionar problemas de trabajos de consulta y errores de la API. Para distinguir las asignaciones de ranuras por consulta o trabajo, puede usar esta utilidad, que es útil para los clientes que usan precios basados en la capacidad y tienen muchos proyectos distribuidos en varios equipos.
Mantenimiento, actualizaciones y versiones
BigQuery es un servicio totalmente gestionado que no requiere que realices tareas de mantenimiento ni actualizaciones. BigQuery no ofrece diferentes versiones. Las actualizaciones son continuas y no requieren tiempo de inactividad ni afectan al rendimiento del sistema. Para obtener más información, consulta las notas de la versión.
Oracle y Exadata requieren que apliques parches, realices actualizaciones y lleves a cabo tareas de mantenimiento en la base de datos y en la infraestructura subyacente. Hay muchas versiones de Oracle y está previsto lanzar una nueva versión principal cada año. Aunque las versiones nuevas son compatibles con las anteriores, el rendimiento de las consultas, el contexto y las funciones pueden cambiar.
Puede haber aplicaciones que requieran versiones específicas, como 10g, 11g o 12c. Para llevar a cabo actualizaciones importantes de bases de datos, es necesario planificar y hacer pruebas con detenimiento. La migración de diferentes versiones puede incluir diferentes necesidades de conversión técnica en cláusulas de consulta y objetos de base de datos.
Cargas de trabajo
Oracle Exadata admite cargas de trabajo mixtas, incluidas las cargas de trabajo OLTP. BigQuery se ha diseñado para analíticas y no para gestionar cargas de trabajo de procesamiento de transacciones online (OLTP). Las cargas de trabajo de OLTP que usan el mismo Oracle deben migrarse a Cloud SQL, Spanner o Firestore enGoogle Cloud. Oracle ofrece opciones adicionales, como Advanced Analytics, Spatial y Graph. Es posible que estas cargas de trabajo deban reescribirse para migrar a BigQuery. Para obtener más información, consulta Opciones de migración de Oracle.
Parámetros y ajustes
Oracle ofrece y requiere que se configuren y ajusten muchos parámetros en los niveles de SO, base de datos, RAC, ASM y Listener para diferentes cargas de trabajo y aplicaciones. BigQuery es un servicio totalmente gestionado y no requiere que configures ningún parámetro de inicialización.
Límites y cuotas
Oracle tiene límites estrictos y flexibles en función de la infraestructura, la capacidad del hardware, los parámetros, las versiones de software y las licencias. BigQuery tiene cuotas y límites para acciones y objetos específicos.
Aprovisionamiento de BigQuery
BigQuery es una plataforma como servicio (PaaS) y un almacén de datos de procesamiento paralelo masivo en la nube. Su capacidad aumenta y disminuye sin que el usuario tenga que hacer nada, ya que Google gestiona el backend. Por lo tanto, a diferencia de muchos sistemas de gestión de bases de datos relacionales, BigQuery no requiere que aprovisiones recursos antes de usarlo. BigQuery asigna el espacio de almacenamiento y los recursos para las consultas dinámicamente en función de tus patrones de uso. Los recursos de almacenamiento se asignan a medida que los consumes y se desasignan a medida que eliminas datos o quitas tablas. Los recursos de consulta se asignan según el tipo y la complejidad de la consulta. Cada consulta usa ranuras. Se usa un programador de equidad eventual, por lo que puede haber periodos cortos en los que algunas consultas obtengan una mayor proporción de ranuras, pero el programador lo corrige con el tiempo.
En términos de máquinas virtuales tradicionales, BigQuery te ofrece el equivalente a lo siguiente:
- Facturación por segundo
- Escalado por segundo
Para llevar a cabo esta tarea, BigQuery hace lo siguiente:
- Mantiene desplegados grandes recursos para evitar tener que escalar rápidamente.
- Usa recursos multiinquilino para asignar al instante grandes fragmentos durante unos segundos.
- Asigna recursos de forma eficiente entre los usuarios con economías de escala.
- Solo se te cobra por los trabajos que ejecutas, en lugar de por los recursos implementados, por lo que pagas por los recursos que utilizas.
Para obtener más información sobre los precios, consulta el artículo Información sobre la escalabilidad rápida y los precios sencillos de BigQuery.
Migración de esquemas
Para migrar datos de Oracle a BigQuery, debes conocer los tipos de datos de Oracle y las asignaciones de BigQuery.
Tipos de datos de Oracle y asignaciones de BigQuery
Los tipos de datos de Oracle son diferentes de los tipos de datos de BigQuery. Para obtener más información sobre los tipos de datos de BigQuery, consulta la documentación oficial.
Para ver una comparación detallada entre los tipos de datos de Oracle y BigQuery, consulta la guía de traducción de SQL de Oracle.
Índices
En muchas cargas de trabajo analíticas, se usan tablas de columnas en lugar de almacenes de filas. De esta forma, se incrementan considerablemente las operaciones basadas en columnas y se elimina el uso de índices para las analíticas por lotes. BigQuery también almacena los datos en formato de columna, por lo que no se necesitan índices. Si la carga de trabajo de analíticas requiere un conjunto pequeño de acceso basado en filas, Bigtable puede ser una alternativa mejor. Si una carga de trabajo requiere procesamiento de transacciones con coherencias relacionales sólidas, Spanner o Cloud SQL pueden ser mejores alternativas.
En resumen, no se necesitan ni se ofrecen índices en BigQuery para las analíticas por lotes. Se pueden usar particiones o clústeres. Para obtener más información sobre cómo ajustar y mejorar el rendimiento de las consultas en BigQuery, consulta Introducción a la optimización del rendimiento de las consultas.
Vistas
Al igual que Oracle, BigQuery permite crear vistas personalizadas. Sin embargo, las vistas de BigQuery no admiten instrucciones DML.
Vistas materializadas
Las vistas materializadas se suelen usar para mejorar el tiempo de renderización de los informes en los tipos de informes y cargas de trabajo de escritura única y lectura múltiple.
Las vistas materializadas se ofrecen en Oracle para aumentar el rendimiento de las vistas. Para ello, solo hay que crear y mantener una tabla que contenga el conjunto de datos de resultados de la consulta. Hay dos formas de actualizar las vistas materializadas en Oracle: al confirmar y bajo demanda.
La función de vista materializada también está disponible en BigQuery. BigQuery aprovecha los resultados precalculados de las vistas materializadas y, siempre que es posible, solo lee los cambios delta de la tabla base para calcular resultados actualizados.
Las funciones de almacenamiento en caché de Looker Studio u otras herramientas de BI modernas también pueden mejorar el rendimiento y eliminar la necesidad de volver a ejecutar la misma consulta, lo que permite ahorrar costes.
Particiones de tablas
La partición de tablas se usa mucho en los almacenes de datos de Oracle. A diferencia de Oracle, BigQuery no admite la creación de particiones jerárquicas.
BigQuery implementa tres tipos de particiones de tabla que permiten que las consultas especifiquen filtros de predicado basados en la columna de partición para reducir la cantidad de datos analizados.
- Tablas con particiones por hora de ingestión: las tablas se particionan en función de la hora de ingestión de los datos.
- Tablas con particiones por columna:
las tablas se dividen en particiones en función de una columna
TIMESTAMPoDATE. - Tablas con particiones de intervalos de números enteros: las tablas se particionan en función de una columna de números enteros.
Para obtener más información sobre los límites y las cuotas aplicados a las tablas con particiones en BigQuery, consulta el artículo Introducción a las tablas con particiones.
Si las restricciones de BigQuery afectan a la funcionalidad de la base de datos migrada, plantéate usar fragmentación en lugar de particiones.
Además, BigQuery no admite EXCHANGE PARTITION,
SPLIT PARTITION ni la conversión de una tabla no particionada en una particionada.
Agrupamiento en clústeres
La agrupación en clústeres ayuda a organizar y recuperar de forma eficiente los datos almacenados en varias columnas a los que se accede con frecuencia de forma conjunta. Sin embargo, Oracle y BigQuery tienen circunstancias diferentes en las que el clustering funciona mejor. En BigQuery, si una tabla se suele filtrar y agregar con columnas específicas, usa el agrupamiento en clústeres. Puedes plantearte usar el agrupamiento en clústeres para migrar tablas con particiones de lista o organizadas por índice de Oracle.
Tablas temporales
Las tablas temporales se suelen usar en las canalizaciones de ETL de Oracle. Una tabla temporal contiene datos durante una sesión de usuario. Estos datos se eliminan automáticamente al final de la sesión.
BigQuery usa tablas temporales para almacenar en caché los resultados de las consultas que no se escriben en una tabla permanente. Una vez que finaliza una consulta, las tablas temporales permanecen durante un máximo de 24 horas. Las tablas se crean en un conjunto de datos especial y se les asigna un nombre aleatorio. También puedes crear tablas temporales para tu propio uso. Para obtener más información, consulta Tablas temporales.
Tablas externas
Al igual que Oracle, BigQuery te permite consultar fuentes de datos externas. BigQuery permite consultar datos directamente de fuentes de datos externas, como las siguientes:
- Amazon Simple Storage Service (Amazon S3)
- Azure Blob Storage
- Bigtable
- Spanner
- Cloud SQL
- Cloud Storage
- Google Drive
Modelado de datos
Los modelos de datos de estrella o copo de nieve pueden ser eficientes para el almacenamiento de analíticas y se suelen usar en almacenes de datos de Oracle Exadata.
Las tablas desnormalizadas eliminan las operaciones de unión costosas y, en la mayoría de los casos, ofrecen un mejor rendimiento para las analíticas en BigQuery. BigQuery también admite modelos de datos de estrella y copo de nieve. Para obtener más información sobre el diseño de almacenes de datos en BigQuery, consulta Diseñar un esquema.
Formato de filas frente a formato de columnas y límites de servidor frente a sin servidor
Oracle usa un formato de fila en el que la fila de la tabla se almacena en bloques de datos, por lo que las columnas innecesarias se obtienen en el bloque de las consultas analíticas, en función del filtrado y la agregación de columnas específicas.
Oracle tiene una arquitectura de todo compartido, con dependencias de recursos de hardware fijos, como la memoria y el almacenamiento, asignadas al servidor. Estas son las dos fuerzas principales que subyacen a muchas técnicas de modelado de datos que han evolucionado para mejorar la eficiencia del almacenamiento y el rendimiento de las consultas analíticas. Los esquemas de estrella y copo de nieve, así como el modelado de almacén de datos, son algunos de ellos.
BigQuery usa un formato de columnas para almacenar datos y no tiene límites fijos de almacenamiento ni de memoria. Esta arquitectura te permite desnormalizar aún más y diseñar esquemas basados en lecturas y necesidades empresariales, lo que reduce la complejidad y mejora la flexibilidad, la escalabilidad y el rendimiento.
Desnormalización
Uno de los principales objetivos de la normalización de bases de datos relacionales es reducir la redundancia de datos. Aunque este modelo es el más adecuado para una base de datos relacional que usa un formato de fila, la desnormalización de datos es preferible para las bases de datos de columnas. Para obtener más información sobre las ventajas de desnormalizar datos y otras estrategias de optimización de consultas en BigQuery, consulta el artículo sobre desnormalización.
Técnicas para aplanar tu esquema
La tecnología de BigQuery aprovecha una combinación de acceso y procesamiento de datos en columnas, almacenamiento en memoria y procesamiento distribuido para ofrecer un rendimiento de consultas de calidad.
Al diseñar un esquema de almacén de datos de BigQuery, es mejor crear una tabla de hechos en una estructura de tabla plana (consolidando todas las tablas de dimensiones en un único registro de la tabla de hechos) para el uso del almacenamiento que usar varias tablas de dimensiones del almacén de datos. Además de ocupar menos espacio de almacenamiento, tener una tabla plana en BigQuery conlleva un menor uso de JOIN. En el siguiente diagrama se muestra un ejemplo de cómo acoplar un esquema.
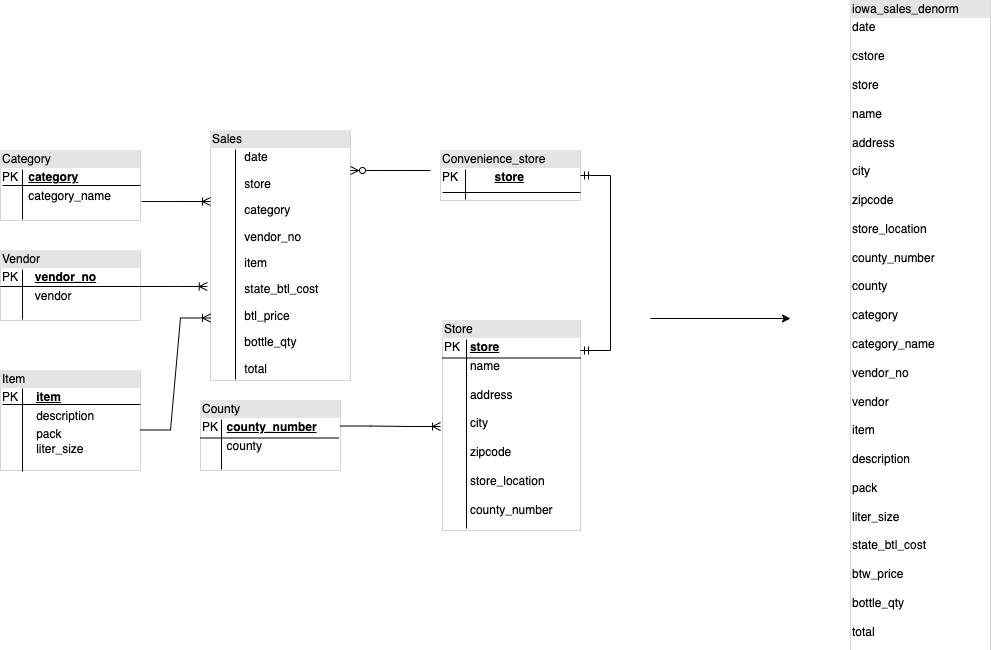
Ejemplo de aplanamiento de un esquema de estrella
En la figura 1 se muestra una base de datos de gestión de ventas ficticia que incluye cuatro tablas:
- Tabla de pedidos o ventas (tabla de hechos)
- Tabla de empleados
- Tabla de ubicaciones
- Tabla de clientes
La clave principal de la tabla de ventas es OrderNum, que también contiene claves externas de las otras tres tablas.
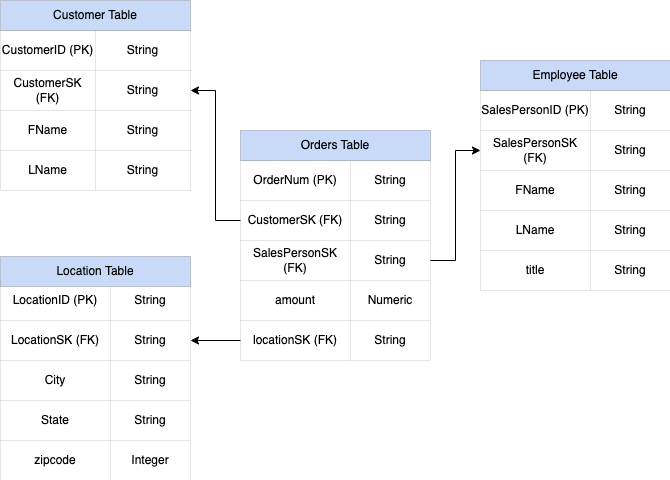
Figura 1: Datos de ventas de ejemplo en un esquema de estrella
Datos de ejemplo
Contenido de la tabla de hechos de pedidos
| OrderNum | CustomerID | SalesPersonID | amount | Ubicación |
| O-1 | 1234 | 12 | 234.22 | 18 |
| O-2 | 4567 | 1 | 192,10 | 27 |
| O-3 | 12 | 14,66 | 18 | |
| O-4 | 4567 | 4 | 182,00 | 26 |
Contenido de la tabla de empleados
| SalesPersonID | FName | LName | title |
| 1 | Alex | Smith | Comercial |
| 4 | Lisa | Pérez | Comercial |
| 12 | Juan | Pérez | Comercial |
Contenido de la tabla de clientes
| CustomerID | FName | LName |
| 1234 | Amanda | Lee |
| 4567 | Matt | Ryan |
Contenido de la tabla de ubicaciones
| Ubicación | ciudad | ciudad | ciudad |
| 18 | Bronx | NY | 10452 |
| 26 | Mountain View | CA | 90210 |
| 27 | Chicago | IL | 60613 |
Consulta para acoplar los datos mediante LEFT OUTER JOIN
#standardSQL INSERT INTO flattened SELECT orders.ordernum, orders.customerID, customer.fname, customer.lname, orders.salespersonID, employee.fname, employee.lname, employee.title, orders.amount, orders.location, location.city, location.state, location.zipcode FROM orders LEFT OUTER JOIN customer ON customer.customerID = orders.customerID LEFT OUTER JOIN employee ON employee.salespersonID = orders.salespersonID LEFT OUTER JOIN location ON location.locationID = orders.locationID
Salida de los datos acoplados
| OrderNum | CustomerID | FName | LName | SalesPersonID | FName | LName | amount | Ubicación | ciudad | estado | código postal |
| O-1 | 1234 | Amanda | Lee | 12 | Juan | Pérez | 234.22 | 18 | Bronx | NY | 10452 |
| O-2 | 4567 | Matt | Ryan | 1 | Alex | Smith | 192,10 | 27 | Chicago | IL | 60613 |
| O-3 | 12 | Juan | Pérez | 14,66 | 18 | Bronx | NY | 10452 | |||
| O-4 | 4567 | Matt | Ryan | 4 | Lisa | Pérez | 182,00 | 26 | Montaña
Ver |
CA | 90210 |
Campos anidados y repetidos
Para diseñar y crear un esquema de DWH a partir de un esquema relacional (por ejemplo, esquemas de estrella y de copo de nieve que contengan tablas de dimensiones y de hechos), BigQuery ofrece la función de campos anidados y repetidos. Por lo tanto, las relaciones se pueden conservar de forma similar a un esquema de DWH relacional normalizado (o parcialmente normalizado) sin que afecte al rendimiento. Para obtener más información, consulta las prácticas recomendadas para mejorar el rendimiento.
Para entender mejor la implementación de los campos anidados y repetidos, consulta un esquema relacional sencillo de una tabla CUSTOMERS y una tabla ORDER/SALES. Se trata de dos tablas diferentes, una por cada entidad, y las relaciones se definen mediante una clave, como una clave principal y una clave externa, como enlace entre las tablas al hacer consultas con JOIN. Los campos anidados y repetidos de BigQuery te permiten mantener la misma relación entre las entidades en una sola tabla. Para ello, se pueden tener todos los datos de los clientes, mientras que los datos de los pedidos se anidan para cada uno de los clientes. Para obtener más información, consulta Especificar columnas anidadas y repetidas.
Para convertir la estructura plana en un esquema anidado o repetido, anida los campos de la siguiente manera:
CustomerID,FNameyLNameanidados en un nuevo campo llamadoCustomer.SalesPersonID,FNameyLNameanidados en un nuevo campo llamadoSalesperson.LocationID,city,stateyzip codeanidados en un nuevo campo llamadoLocation.
Los campos OrderNum y amount no están anidados, ya que representan elementos únicos.
Quieres que tu esquema sea lo suficientemente flexible como para que cada pedido tenga más de un cliente: uno principal y otro secundario. El campo de cliente se marca como repetido. El esquema resultante se muestra en la figura 2, que ilustra los campos anidados y repetidos.
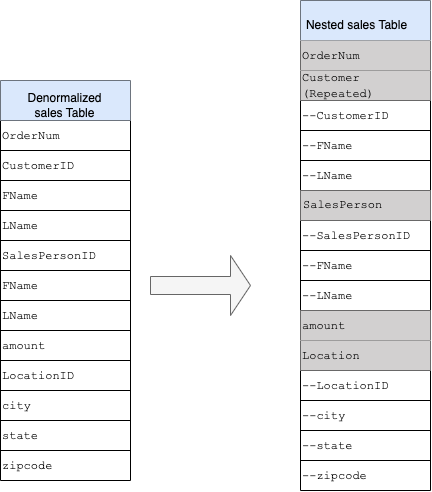
Figura 2: Representación lógica de una estructura anidada
En algunos casos, la desnormalización mediante campos anidados y repetidos no conlleva mejoras en el rendimiento. Para obtener más información sobre las limitaciones y restricciones, consulta Especificar columnas anidadas y repetidas en esquemas de tablas.
Claves subrogadas
Es habitual identificar las filas con claves únicas en las tablas. Las secuencias se suelen usar en Oracle para crear estas claves. En BigQuery, puedes crear claves subrogadas con las funciones row_number y partition by. Para obtener más información, consulta Claves subrogadas en BigQuery: un enfoque práctico.
Hacer un seguimiento de los cambios y del historial
Cuando planifiques una migración de DWH de BigQuery, ten en cuenta el concepto de dimensiones que cambian lentamente (SCD). En general, el término "SCD" describe el proceso de hacer cambios (operaciones DML) en las tablas de dimensiones.
Por varios motivos, los almacenes de datos tradicionales usan diferentes tipos para gestionar los cambios en los datos y conservar el historial de datos en dimensiones que cambian lentamente. Estos usos de tipos son necesarios debido a las limitaciones de hardware y a los requisitos de eficiencia que hemos comentado anteriormente. Como el almacenamiento es mucho más barato que los recursos de computación y se puede escalar infinitamente, se recomienda la redundancia y la duplicación de datos si esto permite que las consultas en BigQuery sean más rápidas. Puede usar técnicas de creación de instantáneas de datos en las que se cargan todos los datos en nuevas particiones diarias.
Vistas específicas de roles y usuarios
Usa vistas específicas de roles y usuarios cuando los usuarios pertenezcan a diferentes equipos y solo deban ver los registros y resultados que necesiten.
BigQuery admite la column- y a nivel de fila. La seguridad a nivel de columna proporciona acceso pormenorizado a columnas sensibles mediante etiquetas de política o con una clasificación basada en tipos de datos. Seguridad a nivel de fila, que le permite filtrar datos y acceder a filas específicas de una tabla en función de las condiciones de usuario que cumplan los requisitos.
Migración de datos
En esta sección se proporciona información sobre la migración de datos de Oracle a BigQuery, incluida la carga inicial, la captura de datos de cambios (CDC) y las herramientas y los enfoques de ETL/ELT.
Actividades de migración
Se recomienda realizar la migración por fases identificando los casos de uso adecuados para la migración. Hay varias herramientas y servicios disponibles para migrar datos de Oracle a Google Cloud. Aunque esta lista no es exhaustiva, sí da una idea del tamaño y el alcance del esfuerzo de migración.
Exportar datos de Oracle: para obtener más información, consulta Carga inicial y Ingestión de CDC y streaming de Oracle a BigQuery. Las herramientas de ETL se pueden usar para la carga inicial.
Preparación de datos (en Cloud Storage): Cloud Storage es el lugar de destino (área de preparación) recomendado para los datos exportados de Oracle. Cloud Storage se ha diseñado para ingerir datos estructurados o sin estructurar de forma rápida y flexible.
Proceso de extracción, transformación y carga (ETL): para obtener más información, consulta Migración de ETL/ELT.
Cargar datos directamente en BigQuery: puedes cargar datos en BigQuery directamente desde Cloud Storage, a través de Dataflow o mediante streaming en tiempo real. Usa Dataflow cuando sea necesario transformar datos.
Carga inicial
La migración de los datos iniciales del almacén de datos de Oracle a BigQuery puede ser diferente de las canalizaciones incrementales de ETL o ELT en función del tamaño de los datos y del ancho de banda de la red. Se pueden usar las mismas canalizaciones de ETL o ELT si el tamaño de los datos es de un par de terabytes.
Si los datos ocupan unos pocos terabytes, volcar los datos y usar gcloud storage
para la transferencia puede ser mucho más eficiente que usar una metodología de extracción de bases de datos programática similar a JdbcIO, ya que los enfoques programáticos pueden necesitar un ajuste del rendimiento mucho más granular. Si el tamaño de los datos es de varios terabytes y están almacenados en la nube o en un almacenamiento online (como Amazon Simple Storage Service [Amazon S3]), considera la posibilidad de usar BigQuery Data Transfer Service. Para las transferencias a gran escala (especialmente las que tienen un ancho de banda de red limitado), Transfer Appliance es una opción útil.
Restricciones de la carga inicial
Cuando planifiques la migración de datos, ten en cuenta lo siguiente:
- Tamaño de los datos del DWH de Oracle: el tamaño de origen de tu esquema tiene un peso significativo en el método de transferencia de datos elegido, sobre todo cuando el tamaño de los datos es grande (terabytes o más). Si el tamaño de los datos es relativamente pequeño, el proceso de transferencia de datos se puede completar en menos pasos. Gestionar grandes cantidades de datos hace que el proceso sea más complejo.
Tiempo de inactividad: es importante decidir si el tiempo de inactividad es una opción para tu migración a BigQuery. Para reducir el tiempo de inactividad, puede cargar de forma masiva el historial de datos estable y tener una solución de CDC para ponerse al día con los cambios que se produzcan durante el proceso de transferencia.
Precios: en algunos casos, es posible que necesites herramientas de integración de terceros (por ejemplo, herramientas de ETL o de replicación) que requieran licencias adicionales.
Transferencia de datos inicial (por lotes)
La transferencia de datos mediante un método por lotes indica que los datos se exportarán de forma coherente en un solo proceso (por ejemplo, exportar los datos del esquema de DWH de Oracle a archivos CSV, Avro o Parquet, o importarlos a Cloud Storage para crear conjuntos de datos en BigQuery). Todas las herramientas y los conceptos de ETL que se explican en el artículo sobre la migración de ETL/ELT se pueden usar para la carga inicial.
Si no quieres usar una herramienta de ETL o ELT para la carga inicial, puedes escribir secuencias de comandos personalizadas para exportar datos a archivos (CSV, Avro o Parquet) y subir esos datos a Cloud Storage mediante gcloud storage, BigQuery Data Transfer Service o Transfer Appliance. Para obtener más información sobre cómo optimizar el rendimiento de las transferencias de grandes cantidades de datos y sobre las opciones de transferencia, consulta el artículo Transferir grandes conjuntos de datos. A continuación, cargue los datos de Cloud Storage en BigQuery.
Cloud Storage es ideal para gestionar la recepción inicial de los datos. Cloud Storage es un servicio de almacenamiento de objetos de alta disponibilidad y duradero que no tiene limitaciones en el número de archivos y en el que solo pagas por el almacenamiento que utilizas. El servicio está optimizado para funcionar con otros Google Cloud servicios, como BigQuery y Dataflow.
CDC e ingestión de datos en tiempo real de Oracle a BigQuery
Hay varias formas de capturar los datos modificados de Oracle. Cada opción tiene sus pros y sus contras, principalmente en lo que respecta al impacto en el rendimiento del sistema de origen, los requisitos de desarrollo y configuración, y los precios y las licencias.
CDC basada en registros
Oracle GoldenGate es la herramienta recomendada de Oracle para extraer registros de rehacer. Puedes usar GoldenGate for Big Data para transmitir registros a BigQuery. GoldenGate requiere licencias por CPU. Para obtener información sobre el precio, consulta la lista de precios global de tecnología de Oracle. Si Oracle GoldenGate for Big Data está disponible (en caso de que ya se hayan adquirido licencias), usar GoldenGate puede ser una buena opción para crear flujos de datos para transferir datos (carga inicial) y, a continuación, sincronizar todas las modificaciones de datos.
Oracle XStream
Oracle almacena cada confirmación en archivos de registro de rehacer y estos archivos se pueden usar para CDC. Oracle XStream Out se basa en LogMiner y lo proporcionan herramientas de terceros, como Debezium (a partir de la versión 0.8) o herramientas comerciales, como Striim. Para usar las APIs de XStream, es necesario comprar una licencia de Oracle GoldenGate, aunque GoldenGate no esté instalado ni se use. XStream le permite propagar mensajes de Streams entre Oracle y otro software de forma eficiente.
Oracle LogMiner
No se necesita ninguna licencia especial para LogMiner. Puedes usar la opción LogMiner en el conector de la comunidad de Debezium. También está disponible comercialmente mediante herramientas como Attunity, Striim o StreamSets. LogMiner puede afectar al rendimiento de una base de datos de origen muy activa y debe usarse con cuidado en los casos en los que el volumen de cambios (el tamaño de la rehacer) sea superior a 10 GB por hora, en función de la capacidad y la utilización de la CPU, la memoria y las E/S del servidor.
CDC basada en SQL
Se trata de un enfoque de ETL incremental en el que las consultas de SQL sondean continuamente las tablas de origen para detectar cambios en función de una clave que aumenta de forma monótona y una columna de marca de tiempo que contiene la fecha de la última modificación o inserción. Si no hay ninguna clave que aumente de forma monótona, usar la columna de marca de tiempo (fecha de modificación) con una precisión pequeña (segundos) puede provocar que se dupliquen los registros o que se pierdan datos en función del volumen y del operador de comparación, como > o >=.
Para solucionar estos problemas, puede usar una mayor precisión en las columnas de marca de tiempo, como seis dígitos decimales (microsegundos, que es la precisión máxima admitida en BigQuery), o bien añadir tareas de desduplicación en su canalización de ETL o ELT, en función de las claves empresariales y las características de los datos.
Debe haber un índice en la columna de clave o de marca de tiempo para mejorar el rendimiento de la extracción y reducir el impacto en la base de datos de origen. Las operaciones de eliminación son un reto para esta metodología, ya que deben gestionarse en la aplicación de origen de forma que se eliminen de forma lógica, como asignando una marca de eliminación y actualizando last_modified_date. Otra solución es registrar estas operaciones en otra tabla mediante un activador.
Activadores
Los activadores de bases de datos se pueden crear en tablas de origen para registrar los cambios en tablas de registro de cambios. Las tablas de registro pueden contener filas completas para hacer un seguimiento de cada cambio de columna o solo pueden conservar la clave principal con el tipo de operación (insertar, actualizar o eliminar). Después, los datos modificados se pueden capturar con un enfoque basado en SQL, tal como se describe en CDC basado en SQL. El uso de activadores puede afectar al rendimiento de las transacciones y duplicar la latencia de la operación DML de una sola fila si se almacena una fila completa. Si solo se almacena la clave principal, se puede reducir esta sobrecarga, pero en ese caso, se requiere una operación JOIN con la tabla original en la extracción basada en SQL, que no tiene en cuenta el cambio intermedio.
Migración de ETL/ELT
Hay muchas posibilidades para gestionar ETL/ELT en Google Cloud. En este documento no se ofrece asistencia técnica sobre conversiones de cargas de trabajo de ETL específicas. Puedes plantearte una estrategia de lift and shift o rediseñar tu plataforma de integración de datos en función de las limitaciones, como el coste y el tiempo. Para obtener más información sobre cómo migrar tus flujos de procesamiento de datos a Google Cloud y sobre otros muchos conceptos de migración, consulta el artículo Migrar flujos de procesamiento de datos.
Estrategia de migración mediante lift-and-shift
Si tu plataforma admite BigQuery y quieres seguir usando tu herramienta de integración de datos:
- Puedes mantener la plataforma ETL/ELT tal cual y cambiar las fases de almacenamiento necesarias por BigQuery en tus tareas ETL/ELT.
- Si también quieres migrar la plataforma ETL/ELT a Google Cloud , puedes preguntar a tu proveedor si su herramienta tiene licencia en Google Cloudy, si es así, puedes instalarla en Compute Engine o consultar Google Cloud Marketplace.
Para obtener información sobre los proveedores de soluciones de integración de datos, consulta los partners de BigQuery.
Rediseño de la plataforma ETL/ELT
Si quieres rediseñar tus pipelines de datos, te recomendamos que te plantees seriamente usar los servicios de Google Cloud .
Cloud Data Fusion
Cloud Data Fusion es una oferta gestionada de CDAP on Google Cloud que proporciona una interfaz visual con muchos complementos para tareas como arrastrar y soltar, y desarrollo de flujos de procesamiento. Cloud Data Fusion se puede usar para capturar datos de muchos tipos de sistemas de origen diferentes y ofrece funciones de replicación por lotes y de streaming. Se pueden usar complementos de Cloud Data Fusion u Oracle para obtener datos de Oracle. Se puede usar un complemento de BigQuery para cargar los datos en BigQuery y gestionar las actualizaciones del esquema.
No se ha definido ningún esquema de salida en los complementos de origen y de destino, y se usa select * from en el complemento de origen para replicar también las columnas nuevas.
Puedes usar la función Wrangle de Cloud Data Fusion para limpiar y preparar los datos.
Dataflow
Dataflow es una plataforma de procesamiento de datos sin servidor que puede autoescalarse, así como procesar datos por lotes y en streaming. Dataflow puede ser una buena opción para los desarrolladores de Python y Java que quieran codificar sus canalizaciones de datos y usar el mismo código para cargas de trabajo de streaming y por lotes. Usa la plantilla JDBC a BigQuery para extraer datos de tus bases de datos relacionales de Oracle u otras y cargarlos en BigQuery.
Cloud Composer
Cloud Composer es un servicio totalmente gestionado de orquestación de flujos de trabajo integrado en Apache Airflow. Google Cloud Te permite crear, programar y monitorizar flujos de procesamiento que abarcan entornos de nube y centros de datos on-premise. Cloud Composer proporciona operadores y contribuciones que pueden ejecutar tecnologías multicloud para casos prácticos como extracciones y cargas, transformaciones de ELT y llamadas a APIs REST.
Cloud Composer usa grafos acíclicos dirigidos (DAGs) para programar y orquestar flujos de trabajo. Para entender los conceptos generales de Airflow, consulta Conceptos de Apache Airflow. Para obtener más información sobre los DAGs, consulta el artículo Escribir DAGs (flujos de trabajo). Para ver ejemplos de prácticas recomendadas de ETL con Apache Airflow, consulta el sitio de documentación sobre prácticas recomendadas de ETL con Airflow¶. Puedes sustituir el operador de Hive de ese ejemplo por el operador de BigQuery y se aplicarían los mismos conceptos.
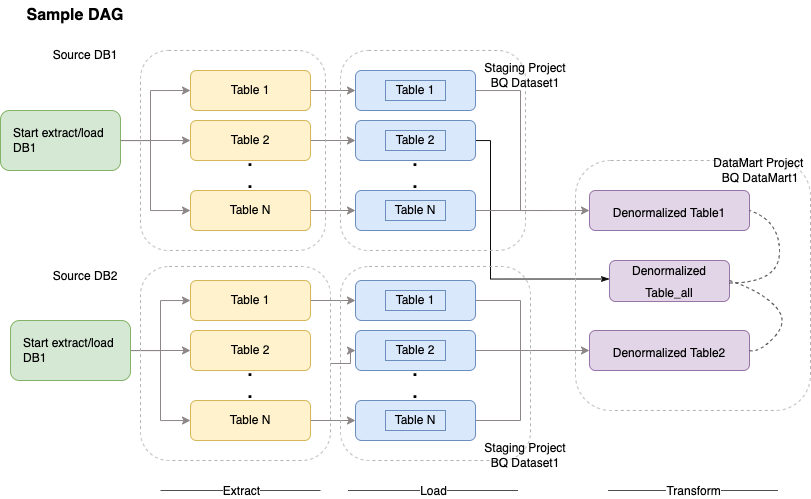
El siguiente código de muestra es una parte de alto nivel de un DAG de ejemplo del diagrama anterior:
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=10),
}
schedule_interval = "00 01 * * *"
dag = DAG('load_db1_db2',catchup=False, default_args=default_args,
schedule_interval=schedule_interval)
tables = {
'DB1_TABLE1': {'database':'DB1', 'table_name':'TABLE1'},
'DB1_TABLE2': {'database':'DB1', 'table_name':'TABLE2'},
'DB1_TABLEN': {'database':'DB1', 'table_name':'TABLEN'},
'DB2_TABLE1': {'database':'DB2', 'table_name':'TABLE1'},
'DB2_TABLE2': {'database':'DB2', 'table_name':'TABLE2'},
'DB2_TABLEN': {'database':'DB2', 'table_name':'TABLEN'},
}
start_db1_daily_incremental_load = DummyOperator(
task_id='start_db1_daily_incremental_load', dag=dag)
start_db2_daily_incremental_load = DummyOperator(
task_id='start_db2_daily_incremental_load', dag=dag)
load_denormalized_table1 = BigQueryOperator(
task_id='load_denormalized_table1',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db1.TABLEN` as tN on t1.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt1', dag=dag)
load_denormalized_table2 = BigQueryOperator(
task_id='load_denormalized_table2',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db2.TABLE2` as t2 on t1.ID = t2.ID
left join `ingest-project.ingest_db2.TABLEN` as tN on t2.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt2', dag=dag)
load_denormalized_table_all = BigQueryOperator(
task_id='load_denormalized_table_all',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),t3.* except (ID)
from `datamart-project.dm1.dt1` as t1
left join `ingest-project.ingest_db1.TABLE2` as t2 on t1.ID = t2.ID
left join `datamart-project.dm1.dt2` as t3 on t2.ID = t3.ID
''', destination_dataset_table='datamart-project.dm1.dt_all', dag=dag)
def start_pipeline(database,table,...):
#start initial or incremental load job here
#you can write your custom operator to integrate ingestion tool
#or you can use operators available in composer instead
for table,table_attr in tables.items():
tbl=table_attr['table_name']
db=table_attr['database'])
load_start = PythonOperator(
task_id='start_load_{db}_{tbl}'.format(tbl=tbl,db=db),
python_callable=start_pipeline,
op_kwargs={'database': db,
'table':tbl},
dag=dag
)
load_monitor = HttpSensor(
task_id='load_monitor_{db}_{tbl}'.format(tbl=tbl,db=db),
http_conn_id='ingestion-tool',
endpoint='restapi-endpoint/',
request_params={},
response_check=lambda response: """{"status":"STOPPED"}""" in
response.text,
poke_interval=1,
dag=dag,
)
load_start.set_downstream(load_monitor)
if table_attr['database']=='db1':
load_start.set_upstream(start_db1_daily_incremental_load)
else:
load_start.set_upstream(start_db2_daily_incremental_load)
if table_attr['database']=='db1':
load_monitor.set_downstream(load_denormalized_table1)
else:
load_monitor.set_downstream(load_denormalized_table2)
load_denormalized_table1.set_downstream(load_denormalized_table_all)
load_denormalized_table2.set_downstream(load_denormalized_table_all)
El código anterior se proporciona con fines de demostración y no se puede usar tal cual.
Dataprep de Trifacta
Dataprep es un servicio de datos que permite examinar, limpiar y preparar datos estructurados y no estructurados de forma visual para procesos de análisis, creación de informes y aprendizaje automático. Exporta los datos de origen a archivos JSON o CSV, transforma los datos con Dataprep y cárgalos con Dataflow. Por ejemplo, consulta Datos de Oracle (ETL) a BigQuery con Dataflow y Dataprep.
Dataproc
Dataproc es un servicio de Hadoop gestionado por Google. Puedes usar Sqoop para exportar datos de Oracle y de muchas bases de datos relacionales a Cloud Storage como archivos Avro. Después, puedes cargar archivos Avro en BigQuery mediante la bq tool. Es muy habitual instalar herramientas de ETL como CDAP en Hadoop, que usan JDBC para extraer datos y Apache Spark o MapReduce para transformar los datos.
Herramientas de partners para la migración de datos
Hay varios proveedores en el espacio de extracción, transformación y carga (ETL). Los líderes del mercado de ETL, como Informatica, Talend, Matillion, Infoworks, Stitch, Fivetran y Striim, se han integrado profundamente con BigQuery y Oracle, y pueden ayudar a extraer, transformar y cargar datos, así como a gestionar flujos de trabajo de procesamiento.
Las herramientas de ETL llevan muchos años en el mercado. Algunas organizaciones pueden aprovechar las inversiones que ya han hecho en scripts de ETL de confianza. Algunas de nuestras soluciones de partners clave se incluyen en el sitio web de partners de BigQuery. Saber cuándo elegir herramientas de partners en lugar de las utilidades integradas depende de tu infraestructura actual y de la familiaridad de tu equipo de TI con el desarrollo de pipelines de datos en código Java o Python.Google Cloud
Migración de herramientas de inteligencia empresarial (BI)
BigQuery admite un conjunto flexible de soluciones de inteligencia empresarial (BI) para informes y análisis que puedes aprovechar. Para obtener más información sobre la migración de herramientas de BI y la integración de BigQuery, consulta Descripción general de las analíticas de BigQuery.
Traducción de consultas (SQL)
El GoogleSQL de BigQuery cumple el estándar SQL 2011 y tiene extensiones que permiten consultar datos anidados y repetidos. Todas las funciones y los operadores de SQL que cumplen el estándar ANSI se pueden usar con modificaciones mínimas. Para ver una comparación detallada entre la sintaxis y las funciones de SQL de Oracle y BigQuery, consulta la referencia de traducción de SQL de Oracle a BigQuery.
Usa la traducción de SQL por lotes para migrar tu código SQL en bloque o la traducción de SQL interactiva para traducir consultas puntuales.
Opciones de migración de Oracle
En esta sección se ofrecen recomendaciones y referencias de arquitectura para convertir aplicaciones que usan las funciones de minería de datos, R, y espaciales y de grafos de Oracle.
Opción Oracle Advanced Analytics
Oracle ofrece opciones de analíticas avanzadas para la minería de datos, algoritmos fundamentales de aprendizaje automático y uso de R. La opción de analíticas avanzadas requiere una licencia. Puedes elegir entre una lista completa de productos de IA/ML de Google en función de tus necesidades, desde el desarrollo hasta la producción a gran escala.
Oracle R Enterprise
Oracle R Enterprise (ORE), un componente de la opción Oracle Advanced Analytics, permite que el lenguaje de programación estadística R de código abierto se integre con Oracle Database. En las implementaciones estándar de ORE, R se instala en un servidor Oracle.
Si se trata de grandes cantidades de datos o de enfoques de almacenamiento, integrar R con BigQuery es una opción ideal. Puedes usar la biblioteca de código abierto bigrquery de R para integrar R con BigQuery.
Google se ha asociado con RStudio para ofrecer a los usuarios las herramientas más avanzadas del sector. RStudio se puede usar para acceder a terabytes de datos en BigQuery, ajustar modelos en TensorFlow y ejecutar modelos de aprendizaje automático a gran escala con AI Platform. En Google Cloud, R se puede instalar en Compute Engine a gran escala.
Oracle Data Mining
Oracle Data Mining (ODM), un componente de la opción Oracle Advanced Analytics, permite a los desarrolladores crear modelos de aprendizaje automático con Oracle PL/SQL Developer en Oracle.
BigQuery ML permite a los desarrolladores ejecutar muchos tipos de modelos, como regresión lineal, regresión logística binaria, regresión logística multiclase, clústeres de k-medias e importaciones de modelos de TensorFlow. Para obtener más información, consulta la introducción a BigQuery ML.
Para convertir trabajos de ODM, puede que tengas que volver a escribir el código. Puedes elegir entre las ofertas de productos de IA de Google, como BigQuery ML, las APIs de IA (Speech-to-Text, Text-to-Speech, Dialogflow, Cloud Translation, Cloud Natural Language API, Cloud Vision y Timeseries Insights API, entre otras) o Vertex AI.
Vertex AI Workbench se puede usar como entorno de desarrollo para científicos de datos, y Vertex AI Training se puede usar para ejecutar cargas de trabajo de entrenamiento y puntuación a gran escala.
Opción Espacial y Gráfico
Oracle ofrece la opción Espacial y de gráficos para consultar geometrías y gráficos, y requiere una licencia para esta opción. Puedes usar las funciones de geometría en BigQuery sin costes ni licencias adicionales, así como otras bases de datos de grafos en Google Cloud.
Espacial
BigQuery ofrece funciones y tipos de datos de analíticas geoespaciales. Para obtener más información, consulta Trabajar con datos de analíticas geoespaciales. Los tipos de datos y las funciones espaciales de Oracle se pueden convertir en funciones geográficas de SQL estándar de BigQuery. Las funciones de geografía no suponen un coste adicional a los precios estándar de BigQuery.
Gráfico
JanusGraph es una solución de base de datos de gráficos de código abierto que puede usar Bigtable como backend de almacenamiento. Para obtener más información, consulta Ejecutar JanusGraph en GKE con Bigtable.
Neo4j es otra solución de base de datos de grafos que se ofrece como un Google Cloud servicio que se ejecuta en Google Kubernetes Engine (GKE).
Oracle Application Express
Las aplicaciones de Oracle Application Express (APEX) son exclusivas de Oracle y deben reescribirse. Las funciones de informes y visualización de datos se pueden desarrollar con Looker Studio o BI Engine, mientras que las funciones a nivel de aplicación, como la creación y edición de filas, se pueden desarrollar sin necesidad de escribir código en AppSheet mediante Cloud SQL.
Siguientes pasos
- Consulta cómo optimizar las cargas de trabajo para mejorar el rendimiento general y reducir los costes.
- Consulta cómo optimizar el almacenamiento en BigQuery.
- Para ver las novedades de BigQuery, consulta las notas de la versión.
- Consulta la guía de traducción de SQL de Oracle.