Especificar columnas anidadas y repetidas en esquemas de tabla
En esta página se describe cómo definir un esquema de tabla con columnas anidadas y repetidas en BigQuery. Para ver un resumen de los esquemas de tabla, consulta Especificar un esquema.
Definir columnas anidadas y repetidas
Para crear una columna con datos anidados, define el tipo de datos de la columna como RECORD en el esquema. Se puede acceder a un RECORD como un tipo STRUCT en GoogleSQL. Un STRUCT es un contenedor de campos ordenados.
Para crear una columna con datos repetidos, defina el modo de la columna como REPEATED en el esquema.
Se puede acceder a un campo repetido como un tipo ARRAY en GoogleSQL.
Una columna RECORD puede tener el modo REPEATED, que se representa como una matriz de tipos STRUCT. Además, un campo de un registro se puede repetir, lo que se representa como un STRUCT que contiene un ARRAY. Una matriz no puede contener otra matriz directamente. Para obtener más información, consulta Declarar un tipo ARRAY.
Limitaciones
Los esquemas anidados y repetidos están sujetos a las siguientes limitaciones:
- Un esquema no puede contener más de 15 niveles de tipos
RECORDanidados.
Las columnas de tipo - pueden contener tipos
RECORDanidados, también llamados registros secundarios.RECORDEl límite máximo de profundidad de anidación es de 15 niveles. Este límite es independiente de si losRECORDson escalares o están basados en arrays (repetidos).
El tipo RECORD no es compatible con UNION, INTERSECT, EXCEPT DISTINCT ni SELECT DISTINCT.
Ejemplo de esquema
En el siguiente ejemplo se muestran datos anidados y repetidos. Esta tabla contiene información sobre personas. Consta de los siguientes campos:
idfirst_namelast_namedob(fecha de nacimiento)addresses(un campo anidado y repetido)addresses.status(actual o anterior)addresses.addressaddresses.cityaddresses.stateaddresses.zipaddresses.numberOfYears(años en la dirección)
El archivo de datos JSON tendría el siguiente aspecto. Fíjate en que la columna de direcciones contiene una matriz de valores (indicada por [ ]). Las distintas direcciones de la matriz son los datos repetidos. Los distintos campos de cada dirección son los datos anidados.
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
{"id":"2","first_name":"Jane","last_name":"Doe","dob":"1980-10-16","addresses":[{"status":"current","address":"789 Any Avenue","city":"New York","state":"NY","zip":"33333","numberOfYears":"2"},{"status":"previous","address":"321 Main Street","city":"Hoboken","state":"NJ","zip":"44444","numberOfYears":"3"}]}
El esquema de esta tabla tiene el siguiente aspecto:
[ { "name": "id", "type": "STRING", "mode": "NULLABLE" }, { "name": "first_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "last_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "dob", "type": "DATE", "mode": "NULLABLE" }, { "name": "addresses", "type": "RECORD", "mode": "REPEATED", "fields": [ { "name": "status", "type": "STRING", "mode": "NULLABLE" }, { "name": "address", "type": "STRING", "mode": "NULLABLE" }, { "name": "city", "type": "STRING", "mode": "NULLABLE" }, { "name": "state", "type": "STRING", "mode": "NULLABLE" }, { "name": "zip", "type": "STRING", "mode": "NULLABLE" }, { "name": "numberOfYears", "type": "STRING", "mode": "NULLABLE" } ] } ]
Especificar las columnas anidadas y repetidas del ejemplo
Para crear una tabla con las columnas anidadas y repetidas anteriores, selecciona una de las siguientes opciones:
Consola
Especifica la columna addresses anidada y repetida:
En la Google Cloud consola, abre la página de BigQuery.
En el panel de la izquierda, haz clic en Explorador:

Si no ves el panel de la izquierda, haz clic en Ampliar panel de la izquierda para abrirlo.
En el panel Explorador, despliega tu proyecto, haz clic en Conjuntos de datos y, a continuación, selecciona un conjunto de datos.
En el panel de detalles, haz clic en Crear tabla.
En la página Crear tabla, especifica los siguientes detalles:
- En Fuente, en el campo Crear tabla a partir de, selecciona Tabla vacía.
En la sección Destino, especifique los siguientes campos:
- En Conjunto de datos, seleccione el conjunto de datos en el que quiera crear la tabla.
- En Tabla, introduce el nombre de la tabla que quieras crear.
En Esquema, haga clic en Añadir campo e introduzca el siguiente esquema de tabla:
- En Nombre del campo, escribe
addresses. - En Type (Tipo), selecciona RECORD (REGISTRO).
- En Modo, elige REPETIDO.
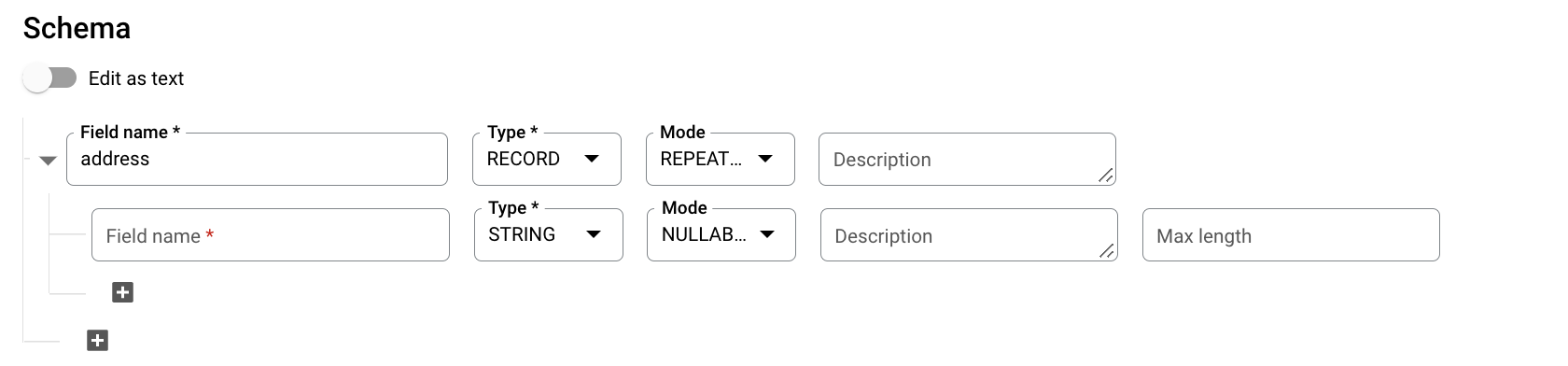
Especifique los siguientes campos de un campo anidado:
- En el campo Nombre del campo, introduce
status. - En Type (Tipo), selecciona STRING (CADENA).
- En Mode (Modo), deje el valor NULLABLE (Acepta valores nulos).
Haz clic en Añadir campo para añadir los siguientes campos:
Nombre del campo Tipo Modo addressSTRINGNULLABLEcitySTRINGNULLABLEstateSTRINGNULLABLEzipSTRINGNULLABLEnumberOfYearsSTRINGNULLABLE
También puede hacer clic en Editar como texto y especificar el esquema como una matriz JSON.
- En el campo Nombre del campo, introduce
- En Nombre del campo, escribe
SQL
Usa la instrucción CREATE TABLE.
Especifica el esquema con la opción columna:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, introduce la siguiente instrucción:
CREATE TABLE IF NOT EXISTS mydataset.mytable ( id STRING, first_name STRING, last_name STRING, dob DATE, addresses ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> ) OPTIONS ( description = 'Example name and addresses table');
Haz clic en Ejecutar.
Para obtener más información sobre cómo ejecutar consultas, consulta Ejecutar una consulta interactiva.
bq
Para especificar la columna addresses anidada y repetida en un archivo de esquema JSON, usa un editor de texto para crear un archivo. Pega la definición del esquema de ejemplo que se muestra arriba.
Una vez que hayas creado el archivo de esquema JSON, puedes proporcionarlo a través de la herramienta de línea de comandos bq. Para obtener más información, consulta el artículo sobre cómo usar un archivo de esquema JSON.
Go
Antes de probar este ejemplo, sigue las Goinstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Go de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Java
Antes de probar este ejemplo, sigue las Javainstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Java de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Node.js
Antes de probar este ejemplo, sigue las Node.jsinstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Node.js de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Python
Antes de probar este ejemplo, sigue las Pythoninstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Python de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Insertar datos en columnas anidadas en el ejemplo
Usa las siguientes consultas para insertar registros de datos anidados en tablas que tengan columnas del tipo de datos RECORD.
Ejemplo 1
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22", ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> [("current","123 First Avenue","Seattle","WA","11111","1")])
Ejemplo 2
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22",[("current","123 First Avenue","Seattle","WA","11111","1")])
Consultar columnas anidadas y repetidas
Para seleccionar el valor de un ARRAY en una posición específica, usa un operador de subíndice de matriz.
Para acceder a los elementos de un STRUCT, usa el operador de punto.
En el ejemplo siguiente se seleccionan el nombre, los apellidos y la primera dirección que se indican en el campo addresses:
SELECT first_name, last_name, addresses[offset(0)].address FROM mydataset.mytable;
El resultado es el siguiente:
+------------+-----------+------------------+ | first_name | last_name | address | +------------+-----------+------------------+ | John | Doe | 123 First Avenue | | Jane | Doe | 789 Any Avenue | +------------+-----------+------------------+
Para extraer todos los elementos de un ARRAY, usa el operador UNNEST con un CROSS JOIN.
En el siguiente ejemplo se seleccionan el nombre, los apellidos, la dirección y el estado de todas las direcciones que no se encuentran en Nueva York:
SELECT first_name, last_name, a.address, a.state FROM mydataset.mytable CROSS JOIN UNNEST(addresses) AS a WHERE a.state != 'NY';
El resultado es el siguiente:
+------------+-----------+------------------+-------+ | first_name | last_name | address | state | +------------+-----------+------------------+-------+ | John | Doe | 123 First Avenue | WA | | John | Doe | 456 Main Street | OR | | Jane | Doe | 321 Main Street | NJ | +------------+-----------+------------------+-------+
Modificar columnas anidadas y repetidas
Después de añadir una columna anidada o una columna anidada y repetida a la definición del esquema de una tabla, puedes modificar la columna como harías con cualquier otro tipo de columna. BigQuery admite de forma nativa varios cambios de esquema, como añadir un nuevo campo anidado a un registro o flexibilizar el modo de un campo anidado. Para obtener más información, consulta Modificar los esquemas de tabla.
Cuándo usar columnas anidadas y repetidas
BigQuery funciona mejor cuando los datos están desnormalizados. En lugar de conservar un esquema relacional, como un esquema de estrella o de copo de nieve, desnormaliza los datos y aprovecha las columnas anidadas y repetidas. Las columnas anidadas y repetidas pueden mantener relaciones sin que esto afecte al rendimiento, como sí ocurre al conservar un esquema relacional (normalizado).
Por ejemplo, una base de datos relacional que se use para hacer un seguimiento de los libros de una biblioteca probablemente mantendrá toda la información de los autores en una tabla independiente. Se usaría una clave como author_id para vincular el libro con los autores.
En BigQuery, puedes conservar la relación entre el libro y el autor sin crear una tabla de autores independiente. En su lugar, crea una columna de autor y anida campos en ella, como el nombre, los apellidos y la fecha de nacimiento del autor, entre otros. Si un libro tiene varios autores, puedes repetir la columna de autor anidada.
Supongamos que tienes la siguiente tabla mydataset.books:
+------------------+------------+-----------+ | title | author_ids | num_pages | +------------------+------------+-----------+ | Example Book One | [123, 789] | 487 | | Example Book Two | [456] | 89 | +------------------+------------+-----------+
También tienes la siguiente tabla, mydataset.authors, con información completa de cada ID de autor:
+-----------+-------------+---------------+ | author_id | author_name | date_of_birth | +-----------+-------------+---------------+ | 123 | Alex | 01-01-1960 | | 456 | Rosario | 01-01-1970 | | 789 | Kim | 01-01-1980 | +-----------+-------------+---------------+
Si las tablas son grandes, puede que se necesiten muchos recursos para combinarlas con regularidad. En función de tu situación, puede ser útil crear una sola tabla que contenga toda la información:
CREATE TABLE mydataset.denormalized_books( title STRING, authors ARRAY<STRUCT<id INT64, name STRING, date_of_birth STRING>>, num_pages INT64) AS ( SELECT title, ARRAY_AGG(STRUCT(author_id, author_name, date_of_birth)) AS authors, ANY_VALUE(num_pages) FROM mydataset.books, UNNEST(author_ids) id JOIN mydataset.authors ON id = author_id GROUP BY title );
La tabla resultante tendrá este aspecto:
+------------------+-------------------------------+-----------+
| title | authors | num_pages |
+------------------+-------------------------------+-----------+
| Example Book One | [{123, Alex, 01-01-1960}, | 487 |
| | {789, Kim, 01-01-1980}] | |
| Example Book Two | [{456, Rosario, 01-01-1970}] | 89 |
+------------------+-------------------------------+-----------+
BigQuery admite la carga de datos anidados y repetidos de formatos de origen que admiten esquemas basados en objetos, como archivos JSON, archivos Avro, archivos de exportación de Firestore y archivos de exportación de Datastore.
Eliminar registros duplicados en una tabla
La siguiente consulta usa la función row_number()
para identificar registros duplicados que tienen los mismos valores para
last_name y first_name en los ejemplos utilizados y los ordena por dob:
CREATE OR REPLACE TABLE mydataset.mytable AS ( SELECT * except(row_num) FROM ( SELECT *, row_number() over (partition by last_name, first_name order by dob) row_num FROM mydataset.mytable) temp_table WHERE row_num=1 )
Seguridad de las tablas
Para controlar el acceso a las tablas de BigQuery, consulta el artículo sobre cómo controlar el acceso a los recursos con la gestión de identidades y accesos.
Siguientes pasos
- Para insertar y actualizar filas con columnas anidadas y repetidas, consulta la sintaxis del lenguaje de manipulación de datos.