Introducción a la optimización del rendimiento de las consultas
En este documento se ofrece una descripción general de las técnicas de optimización que pueden mejorar el rendimiento de las consultas en BigQuery. Por lo general, las consultas que requieren menos trabajo tienen un mejor rendimiento. Se ejecutan más rápido y consumen menos recursos, lo que puede reducir los costes y el número de errores.
Rendimiento de las consultas
Para evaluar el rendimiento de las consultas en BigQuery, se deben tener en cuenta varios factores:
- Datos de entrada y fuentes de datos (E/S): ¿cuántos bytes lee tu consulta?
- Comunicación entre nodos (shuffling): ¿Cuántos bytes envía tu consulta a la siguiente fase? ¿Cuántos bytes pasa tu consulta a cada ranura?
- Procesamiento: ¿Qué capacidad de CPU requiere tu consulta?
- Salidas (materialización): ¿Cuántos bytes escribe tu consulta?
- Capacidad y simultaneidad: ¿Cuántos espacios hay disponibles y cuántas consultas se están ejecutando al mismo tiempo?
- Patrones de consulta: ¿siguen tus consultas las prácticas recomendadas de SQL?
Para evaluar consultas específicas o si tienes problemas de contención de recursos, puedes usar Cloud Monitoring o los gráficos de recursos administrativos de BigQuery para monitorizar cómo consumen recursos tus trabajos de BigQuery a lo largo del tiempo. Si identificas una consulta lenta o que consume muchos recursos, puedes centrar tus optimizaciones de rendimiento en esa consulta.
Algunos patrones de consulta, especialmente los generados por herramientas de inteligencia empresarial, se pueden acelerar con BigQuery BI Engine. BI Engine es un servicio de análisis en memoria de alta velocidad que acelera muchas consultas SQL en BigQuery almacenando en caché de forma inteligente los datos que más usas. BI Engine está integrado en BigQuery, lo que significa que, a menudo, puede obtener un mejor rendimiento sin tener que modificar las consultas.
Como ocurre con todos los sistemas, la optimización del rendimiento a veces implica renunciar a otras cosas. Por ejemplo, usar una sintaxis de SQL avanzada a veces puede introducir complejidad y reducir la comprensibilidad de las consultas para las personas que no son expertas en SQL. Si dedicas tiempo a microoptimizaciones de cargas de trabajo no críticas, también podrías desviar recursos de la creación de nuevas funciones para tus aplicaciones o de la identificación de optimizaciones más importantes. Para ayudarte a conseguir el mayor retorno de la inversión posible, te recomendamos que centres tus optimizaciones en las cargas de trabajo que más importan a tus pipelines de analíticas de datos.
Optimización de la capacidad y la simultaneidad
BigQuery ofrece dos modelos de precios para las consultas: el modelo bajo demanda y el modelo basado en la capacidad. El modelo bajo demanda proporciona un grupo de capacidad compartido y los precios se basan en la cantidad de datos que procesa cada consulta que ejecutas.
El modelo basado en la capacidad se recomienda si quieres presupuestar un gasto mensual constante o si necesitas más capacidad de la que ofrece el modelo bajo demanda. Cuando usas la tarifa basada en la capacidad, asignas una capacidad de procesamiento de consultas específica que se mide en ranuras. El coste de todos los bytes procesados se incluye en el precio basado en la capacidad. Además de las reservas de ranuras fijas, puedes usar ranuras de autoescalado, que proporcionan capacidad dinámica en función de tu carga de trabajo de consultas.
El rendimiento de las consultas que se ejecutan repetidamente en los mismos datos puede variar. Por lo general, la variación es mayor en las consultas que usan ranuras bajo demanda que en las que usan reservas de ranuras.
Durante el procesamiento de las consultas de SQL, BigQuery desglosa la capacidad computacional necesaria para ejecutar cada fase de una consulta en ranuras. BigQuery determina automáticamente el número de consultas que se pueden ejecutar simultáneamente de la siguiente manera:
- Modelo bajo demanda: número de ranuras disponibles en el proyecto
- Modelo basado en la capacidad: número de espacios disponibles en la reserva
Las consultas que requieren más ranuras de las que hay disponibles se ponen en cola hasta que haya recursos de procesamiento disponibles. Una vez que se empieza a ejecutar una consulta, BigQuery calcula cuántas ranuras usa cada fase de la consulta en función del tamaño y la complejidad de la fase, así como del número de ranuras disponibles. BigQuery usa una técnica llamada programación equitativa para asegurarse de que cada consulta tenga capacidad suficiente para avanzar.
Tener acceso a más ranuras no siempre implica que una consulta se ejecute más rápido. Sin embargo, un grupo de espacios más grande puede mejorar el rendimiento de las consultas grandes o complejas, así como el de las cargas de trabajo con mucha simultaneidad. Para mejorar el rendimiento de las consultas, puede modificar sus reservas de ranuras o definir un límite superior para el escalado automático de ranuras.
Plan y cronología de la consulta
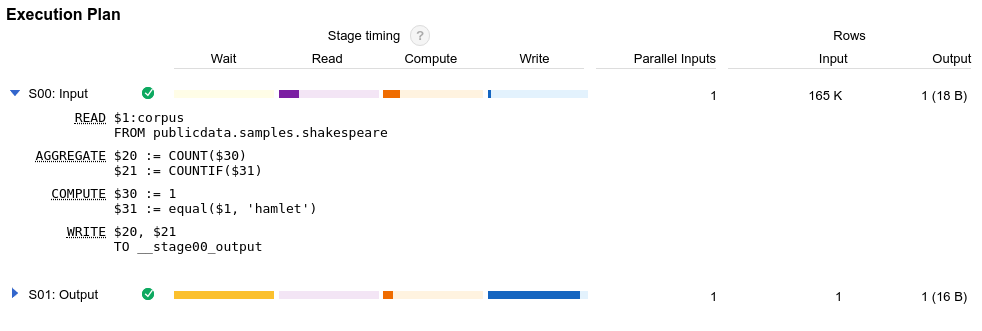
BigQuery genera un plan de consulta cada vez que ejecutas una consulta. Comprender este plan es fundamental para optimizar las consultas de forma eficaz. El plan de consulta incluye estadísticas de ejecución, como los bytes leídos y el tiempo de ranura consumido. El plan de consultas también incluye detalles sobre las diferentes fases de ejecución, lo que puede ayudarte a diagnosticar y mejorar el rendimiento de las consultas. El gráfico de ejecución de consultas proporciona una interfaz gráfica para ver el plan de consulta y diagnosticar problemas de rendimiento de las consultas.
También puedes usar el método de la API jobs.get o la vista INFORMATION_SCHEMA.JOBS para obtener el plan de consulta y la información de la cronología. BigQuery Visualiser, una herramienta de código abierto que representa visualmente el flujo de las fases de ejecución de un trabajo de BigQuery, usa esta información.
Cuando BigQuery ejecuta una tarea de consulta, convierte la instrucción SQL declarativa en un gráfico de ejecución. Este gráfico se divide en una serie de fases de consulta, que a su vez se componen de conjuntos más granulares de pasos de ejecución. BigQuery usa una arquitectura paralela muy distribuida para ejecutar estas consultas. Las fases de BigQuery modelan las unidades de trabajo que muchos trabajadores potenciales pueden ejecutar en paralelo. Las fases se comunican entre sí mediante una arquitectura de barajado rápida y distribuida.
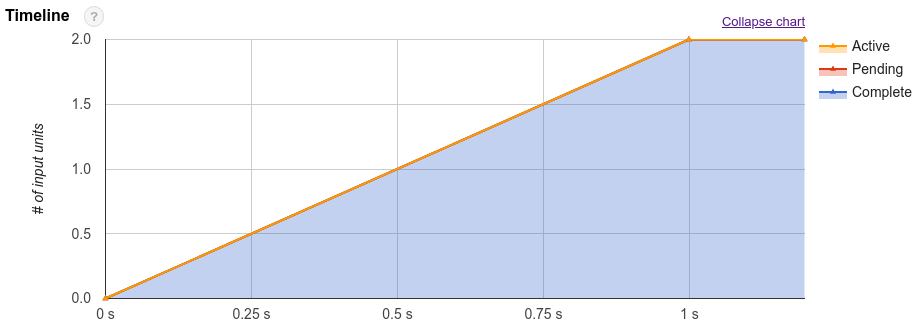
Además del plan de consultas, los trabajos de consulta también muestran una cronología de la ejecución. Esta cronología proporciona un recuento de las unidades de trabajo completadas, pendientes y activas en los trabajadores de consultas. Una consulta puede tener varias fases con trabajadores activos simultáneamente, por lo que la cronología tiene como objetivo mostrar el progreso general de la consulta.
Para estimar el coste computacional de una consulta, puedes consultar el número total de segundos de ranura que consume. Cuanto menor sea el número de segundos de ranura, mejor, ya que significa que hay más recursos disponibles para otras consultas que se ejecutan en el mismo proyecto al mismo tiempo.
Las estadísticas del plan de consulta y de la cronología pueden ayudarte a entender cómo ejecuta BigQuery las consultas y si determinadas fases predominan en el uso de recursos. Por ejemplo, una fase JOIN que genera muchas más filas de salida que de entrada puede indicar una oportunidad para filtrar antes en la consulta.
Sin embargo, la naturaleza gestionada del servicio limita si algunos detalles se pueden aplicar directamente. Para consultar las prácticas recomendadas y las técnicas para mejorar la ejecución y el rendimiento de las consultas, consulta Optimizar las operaciones de computación de las consultas.
Siguientes pasos
- Consulta cómo solucionar problemas de ejecución de consultas con los registros de auditoría de BigQuery.
- Consulta otras técnicas para controlar los costes de BigQuery.
- Consulta metadatos casi en tiempo real sobre los trabajos de BigQuery con la vista
INFORMATION_SHEMA.JOBS. - Consulta cómo monitorizar el uso de BigQuery con los informes de tablas del sistema de BigQuery.