In questo tutorial utilizzi un modello di regressione lineare in BigQuery ML per prevedere il peso di un pinguino in base alle informazioni demografiche del pinguino. Una regressione lineare è un tipo di modello di regressione che genera un valore continuo da una combinazione lineare di caratteristiche di input.
Questo tutorial utilizza il set di dati
bigquery-public-data.ml_datasets.penguins.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Autorizzazioni obbligatorie
Per creare il modello utilizzando BigQuery ML, devi disporre delle seguenti autorizzazioni IAM:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
Per eseguire l'inferenza, devi disporre delle seguenti autorizzazioni:
bigquery.models.getDatasul modellobigquery.jobs.create
Crea un set di dati
Crea un set di dati BigQuery per archiviare il tuo modello ML.
Console
Nella console Google Cloud , vai alla pagina BigQuery.
Nel riquadro Explorer, fai clic sul nome del progetto.
Fai clic su Visualizza azioni > Crea set di dati.
Nella pagina Crea set di dati:
In ID set di dati, inserisci
bqml_tutorial.Per Tipo di località, seleziona Multi-regione e poi Stati Uniti (più regioni negli Stati Uniti).
Lascia invariate le restanti impostazioni predefinite e fai clic su Crea set di dati.
bq
Per creare un nuovo set di dati, utilizza il
comando bq mk
con il flag --location. Per un elenco completo dei possibili parametri, consulta la
documentazione di riferimento del
comando bq mk --dataset.
Crea un set di dati denominato
bqml_tutorialcon la località dei dati impostata suUSe una descrizione diBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Anziché utilizzare il flag
--dataset, il comando utilizza la scorciatoia-d. Se ometti-de--dataset, il comando crea per impostazione predefinita un dataset.Verifica che il set di dati sia stato creato:
bq ls
API
Chiama il metodo datasets.insert con una risorsa dataset definita.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
Crea il modello
Crea un modello di regressione lineare utilizzando l'esempio di set di dati di Analytics per BigQuery.
SQL
Puoi creare un modello di regressione lineare utilizzando l'istruzione
CREATE MODEL
e specificando LINEAR_REG per il tipo di modello. La creazione del modello include
l'addestramento del modello.
Di seguito sono riportati alcuni aspetti utili da conoscere in merito alla dichiarazione CREATE MODEL:
- L'opzione
input_label_colsspecifica quale colonna dell'istruzioneSELECTutilizzare come colonna delle etichette. In questo caso, la colonna delle etichette èbody_mass_g. Per i modelli di regressione lineare, la colonna dell'etichetta deve avere valori reali, ovvero i valori della colonna devono essere numeri reali. L'istruzione
SELECTdi questa query utilizza le seguenti colonne della tabellabigquery-public-data.ml_datasets.penguinsper prevedere il peso di un pinguino:species: la specie di pinguino.island: l'isola su cui risiede il pinguino.culmen_length_mm: la lunghezza del culmen del pinguino in millimetri.culmen_depth_mm: la profondità del culmen del pinguino in millimetri.flipper_length_mm: la lunghezza delle pinne del pinguino in millimetri.sex: il sesso del pinguino.
La clausola
WHEREnell'istruzioneSELECTdi questa query,WHERE body_mass_g IS NOT NULL, esclude le righe in cui la colonnabody_mass_gèNULL.
Esegui la query che crea il modello di regressione lineare:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, esegui la query seguente:
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS (model_type='linear_reg', input_label_cols=['body_mass_g']) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
La creazione del modello
penguins_modelrichiede circa 30 secondi.Per visualizzare il modello, segui questi passaggi:
Nel riquadro a sinistra, fai clic su Explorer:

Se non vedi il riquadro a sinistra, fai clic su Espandi riquadro a sinistra per aprirlo.
Nel riquadro Explorer, espandi il progetto e fai clic su Set di dati.
Fai clic sul set di dati
bqml_tutorial.Fai clic sulla scheda Modelli.
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
La creazione del modello richiede circa 30 secondi. Per visualizzare il modello, segui questi passaggi:
Nel riquadro a sinistra, fai clic su Explorer:
Nel riquadro Explorer, espandi il progetto e fai clic su Set di dati.
Fai clic sul set di dati
bqml_tutorial.Fai clic sulla scheda Modelli.
Visualizzare le statistiche di allenamento
Per visualizzare i risultati dell'addestramento del modello, puoi utilizzare la
funzione ML.TRAINING_INFO
oppure visualizzare le statistiche nella console Google Cloud . In questo
tutorial utilizzi la console Google Cloud .
Un algoritmo di machine learning crea un modello esaminando molti esempi e tentando di trovare un modello che minimizzi la perdita. Questo processo è chiamato minimizzazione empirica del rischio.
La perdita è la penalità per una previsione errata. È un numero che indica quanto fosse negativa la previsione del modello su un singolo esempio. Se la previsione del modello è perfetta, la perdita è zero; in caso contrario, la perdita è maggiore. L'obiettivo dell'addestramento di un modello è trovare un insieme di ponderazioni e bias che presentino, in media, una perdita lieve in tutti gli esempi.
Visualizza le statistiche di addestramento del modello generate durante l'esecuzione della query
CREATE MODEL:
Nel riquadro a sinistra, fai clic su Explorer:
Nel riquadro Explorer, espandi il progetto e fai clic su Set di dati.
Fai clic sul set di dati
bqml_tutorial.Fai clic sulla scheda Modelli.
Per aprire il riquadro delle informazioni sul modello, fai clic su penguins_model.
Fai clic sulla scheda Addestramento e quindi su Tabella. I risultati dovrebbero essere simili ai seguenti:
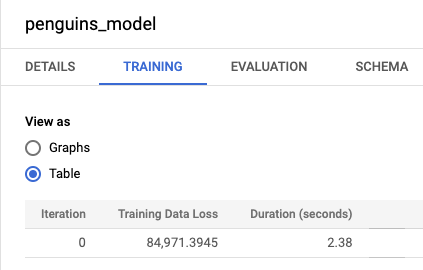
La colonna Perdita di dati di addestramento rappresenta la metrica relativa alla perdita calcolata dopo che il modello è stato addestrato sul set di dati di addestramento. Poiché hai eseguito una regressione lineare, questa colonna mostra il valore dell'errore quadratico medio. Per questo addestramento viene utilizzata automaticamente una strategia di ottimizzazione normal_equation, pertanto è necessaria una sola iterazione per convergere al modello finale. Per saperne di più sull'impostazione della strategia di ottimizzazione del modello, consulta
optimize_strategy.
Valuta il modello
Dopo aver creato il modello, valuta le sue prestazioni utilizzando la
funzione ML.EVALUATE o la funzione scoreBigQuery DataFrames per valutare i valori previsti generati dal modello rispetto ai dati effettivi.
SQL
Come input, la funzione ML.EVALUATE accetta il modello addestrato e un set di dati
che corrisponde allo schema dei dati utilizzati per addestrare il modello. In
un ambiente di produzione, devi
valutare il modello su dati diversi da quelli utilizzati per addestrarlo.
Se esegui ML.EVALUATE senza fornire dati di input, la funzione recupera
le metriche di valutazione calcolate durante l'addestramento. Queste metriche vengono calcolate
utilizzando il set di dati di valutazione riservato automaticamente:
SELECT
*
FROM
ML.EVALUATE(MODEL bqml_tutorial.penguins_model);
Esegui la query ML.EVALUATE:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, esegui la query seguente:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL));
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
I risultati dovrebbero essere simili ai seguenti:
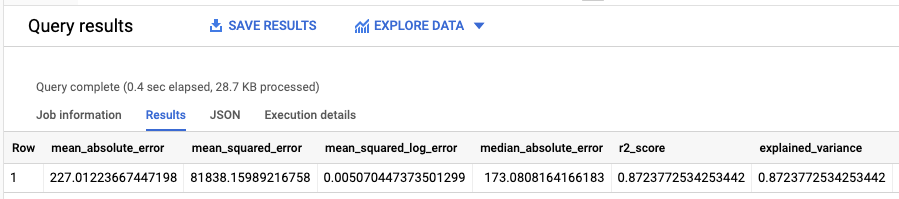
Poiché hai eseguito una regressione lineare, i risultati includono le seguenti colonne:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
Una metrica importante nei risultati della valutazione è il
coefficiente R2.
Il coefficiente R2 è una misura statistica che determina se le previsioni della regressione lineare si avvicinano ai dati effettivi. Un valore pari a 0 indica
che il modello non spiega nessuna delle variabilità dei dati di risposta attorno alla
media. Un valore di 1 indica che il modello spiega tutta la variabilità dei dati di risposta attorno alla media.
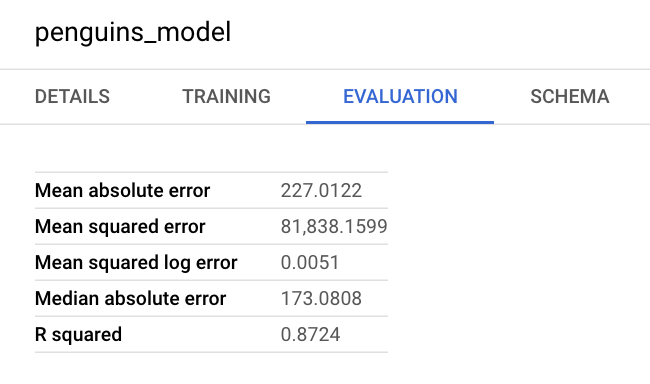
Puoi anche esaminare il riquadro delle informazioni del modello nella console Google Cloud per visualizzare le metriche di valutazione:
Utilizzare il modello per prevedere i risultati
Ora che hai valutato il modello, il passaggio successivo consiste nell'utilizzarlo per prevedere
un risultato. Puoi eseguire la
funzione ML.PREDICT o la funzione BigQuery DataFrames predict
sul modello per prevedere la massa corporea in grammi di tutti i pinguini che vivono sulle
isole Biscoe.
SQL
Per l'input, la funzione ML.PREDICT accetta il modello addestrato e un set di dati che
corrisponde allo schema dei dati utilizzati per addestrare il modello, escludendo la
colonna dell'etichetta.
Esegui la query ML.PREDICT:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, esegui la query seguente:
SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'));
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
I risultati dovrebbero essere simili ai seguenti:

Spiega i risultati della previsione
SQL
Per capire perché il modello sta generando questi risultati di previsione, puoi utilizzare
la
funzioneML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT è una versione estesa della funzione ML.PREDICT.
ML.EXPLAIN_PREDICT non solo restituisce i risultati della previsione, ma anche
colonne aggiuntive per spiegare i risultati della previsione. In pratica, puoi eseguire
ML.EXPLAIN_PREDICT anziché ML.PREDICT. Per ulteriori informazioni, vedi
Panoramica di BigQuery Explainable AI.
Esegui la query ML.EXPLAIN_PREDICT:
- Nella console Google Cloud , vai alla pagina BigQuery.
- Nell'editor di query, esegui la query seguente:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'), STRUCT(3 as top_k_features));
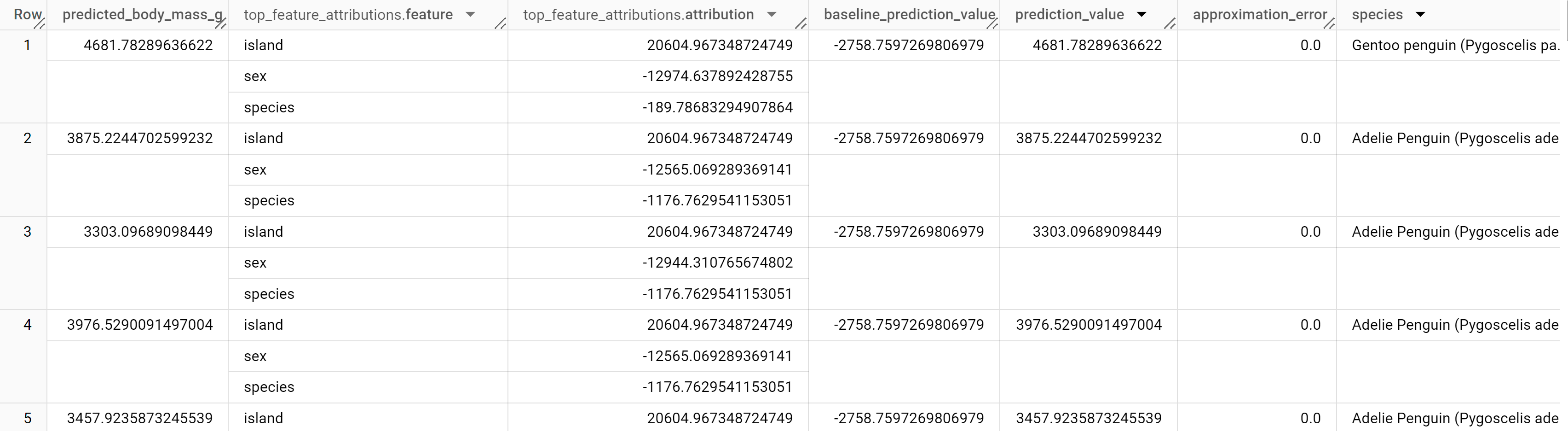
I risultati dovrebbero essere simili ai seguenti:
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
Per i modelli di regressione lineare, vengono utilizzati i valori di Shapley per generare valori di attribuzione delle caratteristiche per ogni caratteristica nel modello. L'output include
le prime tre attribuzioni di caratteristiche per riga della tabella penguins perché
top_k_features è stato impostato su 3. Queste attribuzioni sono ordinate in base al
valore assoluto dell'attribuzione in ordine decrescente. In tutti gli esempi, la caratteristica sex ha contribuito maggiormente alla previsione complessiva.
Spiega il modello a livello globale
SQL
Per sapere quali caratteristiche sono generalmente le più importanti per determinare il peso dei pinguini, puoi utilizzare la funzione ML.GLOBAL_EXPLAIN.
Per utilizzare ML.GLOBAL_EXPLAIN, devi riaddestrare il modello con l'opzione
ENABLE_GLOBAL_EXPLAIN impostata su TRUE.
Esegui il retrain e ottieni le spiegazioni globali per il modello:
- Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, esegui la seguente query per eseguire di nuovo l'addestramento del modello:
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS ( model_type = 'linear_reg', input_label_cols = ['body_mass_g'], enable_global_explain = TRUE) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
Nell'editor di query, esegui la seguente query per ottenere le spiegazioni globali:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
I risultati dovrebbero essere simili ai seguenti:
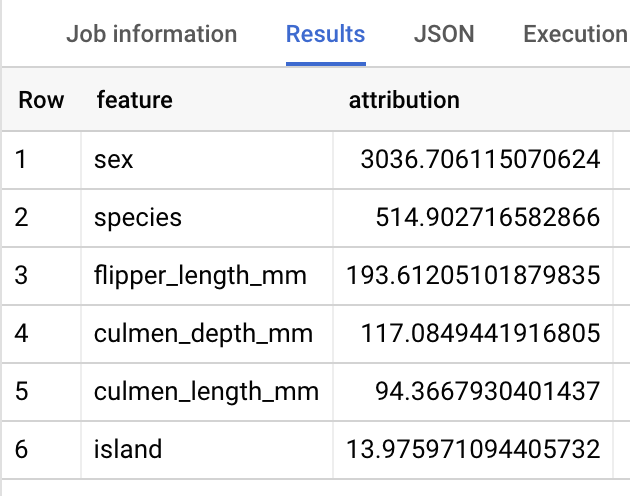
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.