BigQuery 内の Apache Iceberg 用 BigLake テーブル
BigQuery 内の Apache Iceberg 用 BigLake テーブル(以下、BigQuery 内の BigLake Iceberg テーブル)は、 Google Cloudでオープン形式のレイクハウスを構築するための基盤になります。BigQuery の BigLake Iceberg テーブルは、標準の BigQuery テーブルと同じフルマネージド エクスペリエンスを提供しますが、お客様所有のストレージ バケットにデータを保存します。BigQuery の BigLake Iceberg テーブルは、オープン Iceberg テーブル形式をサポートしているため、データの単一コピーでオープンソースとサードパーティのコンピューティング エンジンとの相互運用性が向上します。
BigQuery 内の Apache Iceberg 用 BigLake テーブルは、Apache Iceberg 外部テーブルとは異なります。BigQuery の Apache Iceberg 用 BigLake テーブルは、BigQuery で直接変更可能なフルマネージド テーブルですが、Apache Iceberg 外部テーブルはユーザー管理で、BigQuery からの読み取り専用アクセスを提供します。
BigQuery の BigLake Iceberg テーブルは、次の機能をサポートしています。
- テーブル ミューテーション: GoogleSQL データ操作言語(DML)を使用します。
- 統合されたバッチ処理と高スループット ストリーミング: Spark、Dataflow、その他のエンジンなどの BigLake コネクタを介して Storage Write API を使用します。
- Iceberg V2 スナップショットのエクスポートと自動更新。オープンソースとサードパーティのクエリエンジンを使用して直接クエリにアクセスするための各テーブル ミューテーション。
- スキーマの進化: ニーズに合わせて列の追加、削除、名前の変更が可能です。この機能を使用すると、既存の列のデータ型の変更や、列モードの変更ができます。詳細については、型変換規則をご覧ください。
- ストレージの自動最適化: 適応型ファイルサイズ設定、自動クラスタリング、ガベージ コレクション、メタデータの最適化などが含まれます。
- BigQuery での過去のデータアクセス用のタイムトラベル。
- 列レベルのセキュリティとデータ マスキング。
- マルチステートメント トランザクション (プレビュー)。
アーキテクチャ
BigQuery の BigLake Iceberg テーブルを使用すると、独自のクラウド バケットに存在するテーブルで、BigQuery リソース管理の利便性を享受できます。これらのテーブルでは、管理するバケットからデータを移動することなく、BigQuery とオープンソースのコンピューティング エンジンを使用できます。Cloud Storage バケットは、BigQuery で BigLake Iceberg テーブルの使用を開始する前に構成する必要があります。
BigQuery の BigLake Iceberg テーブルは、すべての Iceberg データの統合ランタイム メタストアとして BigLake metastore を使用します。BigLake metastore は、複数のエンジンからのメタデータを管理するための信頼できる唯一の情報源を提供し、エンジンの相互運用を可能にします。
次の図は、マネージド テーブルのアーキテクチャの概要を示します。
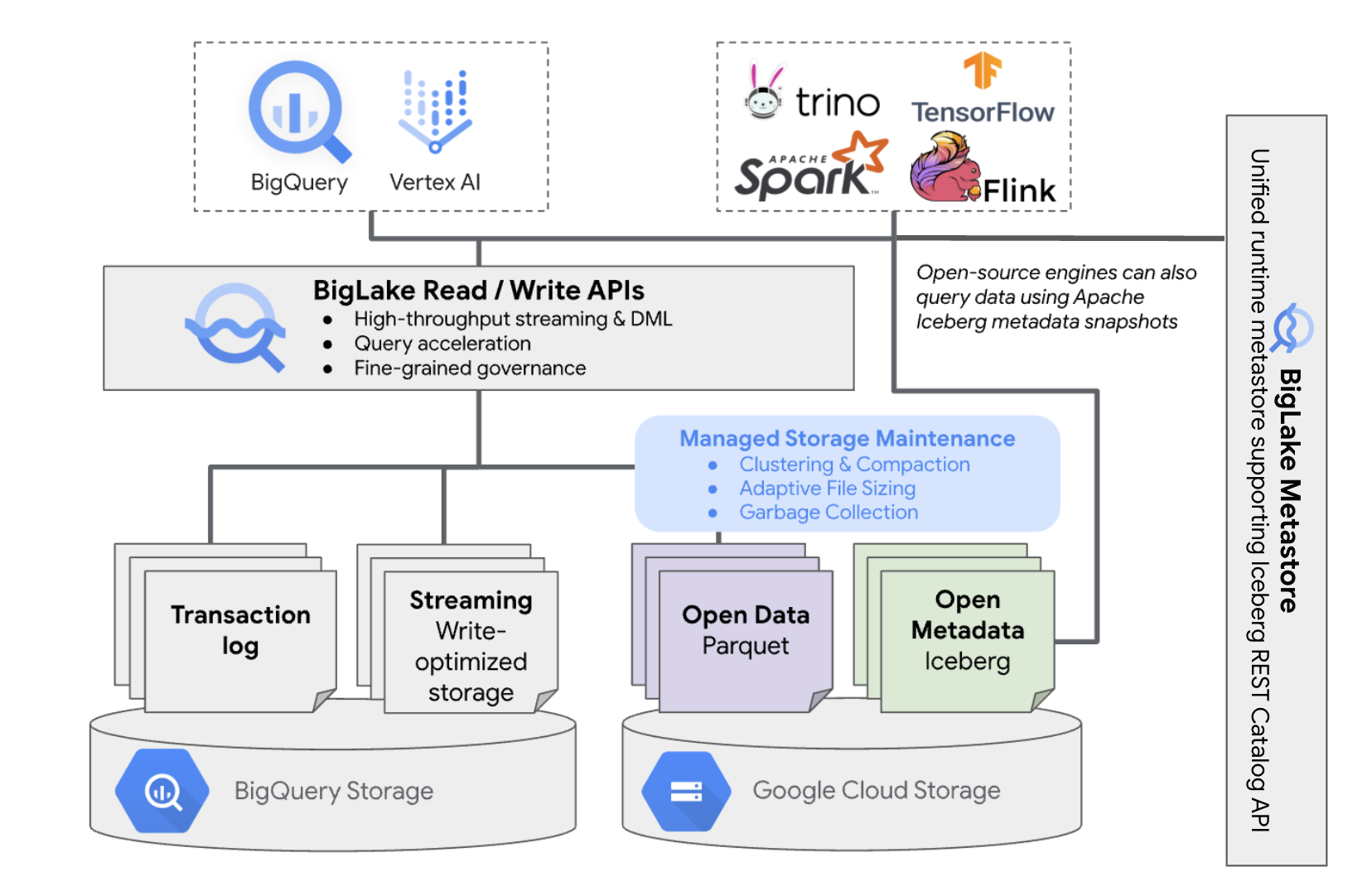
このテーブル管理は、バケットに次のような影響を与えます。
- BigQuery は、書き込みリクエストやバックグラウンドのストレージ最適化(DML ステートメントやストリーミングなど)に応じて、バケットに新しいデータファイルを作成します。
- BigQuery でマネージド テーブルを削除すると、タイムトラベル期間の終了後に、関連するデータファイルが Cloud Storage でガベージ コレクションされます。
BigQuery での BigLake Iceberg テーブルの作成は、BigQuery テーブルの作成と似ています。データをオープン形式で Cloud Storage に保存するため、次の操作を行う必要があります。
WITH CONNECTIONを使用して Cloud リソース接続を指定し、BigLake が Cloud Storage にアクセスするための接続認証情報を構成します。file_format = PARQUETステートメントを使用して、データ ストレージのファイル形式をPARQUETとして指定します。table_format = ICEBERGステートメントを使用して、オープンソースのメタデータ テーブル形式をICEBERGとして指定します。
ベスト プラクティス
BigQuery の外部でバケットのファイルを直接変更または追加すると、データ損失や回復不能エラーが発生する可能性があります。次の表に、考えられるシナリオを示します。
| 操作 | 結果 | 予防策 |
|---|---|---|
| BigQuery の外部にあるバケットに新しいファイルを追加する。 | データ損失: BigQuery の外部で追加された新しいファイルやオブジェクトは、BigQuery によって追跡されません。追跡されないファイルは、バックグラウンドのガベージ コレクション プロセスによって削除されます。 | データの追加を常に BigQuery を介して行うと、BigQuery によってファイルが追跡され、ガベージ コレクションを防止できます。 誤って追加されることやデータが失われることがないように、BigQuery の BigLake Iceberg テーブルを含むバケットに対して、外部ツールの書き込み権限を制限することもおすすめします。 |
| 空でない接頭辞に BigQuery で新しい BigLake Iceberg テーブルを作成する。 | データ損失: 既存のデータは BigQuery によって追跡されないため、これらのファイルは追跡対象外とみなされ、バックグラウンドのガベージ コレクション プロセスによって削除されます。 | BigQuery の空の接頭辞にのみ新しい BigLake Iceberg テーブルを作成します。 |
| BigQuery の BigLake Iceberg テーブルのデータファイルを変更または置換する。 | データ損失: 外部で変更または置換を行うと、テーブルの整合性チェックが失敗して読み取り不能になり、テーブルに対するクエリが失敗します。 この状態からセルフサービスで復元する方法はありません。データ復元のサポートが必要な場合は、サポートにご連絡ください。 |
データの変更を常に BigQuery を介して行うと、BigQuery によってファイルが追跡され、ガベージ コレクションを防止できます。 誤って追加されることやデータが失われることがないように、BigQuery の BigLake Iceberg テーブルを含むバケットに対して、外部ツールの書き込み権限を制限することもおすすめします。 |
| 同じ、または重複する URI に BigQuery で BigLake Iceberg テーブルを 2 つ作成する。 | データ損失: BigQuery は、BigQuery の BigLake Iceberg テーブルの同じ URI インスタンスをブリッジしません。各テーブルのバックグラウンドのガベージ コレクション プロセスは、もう一方のテーブルにあるファイルを追跡対象外とみなして削除するため、データ損失が発生します。 | BigQuery の BigLake Iceberg テーブルごとに一意の URI を使用します。 |
Cloud Storage バケットの構成に関するベスト プラクティス
Cloud Storage バケットの構成と BigLake との接続は、BigQuery の BigLake Iceberg テーブルのパフォーマンス、費用、データの整合性、セキュリティ、ガバナンスに直接影響します。この構成に役立つベスト プラクティスは次のとおりです。
バケットが BigQuery の BigLake Iceberg テーブル専用であることを明確に示す名前を選択します。
BigQuery データセットと同じリージョンに配置されている単一リージョン Cloud Storage バケットを選択します。この調整により、データ転送料金を回避できるため、パフォーマンスが向上し、費用が削減されます。
デフォルトでは、Cloud Storage はデータを Standard ストレージ クラスに保存します。このクラスは十分なパフォーマンスを提供します。データ ストレージ費用を最適化するには、Autoclass を有効にして、ストレージ クラスの移行を自動的に管理します。Autoclass は Standard Storage クラスから始まり、アクセスされないオブジェクトをよりコールドなクラスに移動して、ストレージ費用を削減します。オブジェクトが再度読み取られると、Standard クラスに戻ります。
均一なバケットレベルのアクセスと公開アクセスの防止を有効にします。
必要なロールが適切なユーザーとサービス アカウントに割り当てられていることを確認します。
Cloud Storage バケット内の Iceberg データの誤った削除や破損を防ぐには、組織内のほとんどのユーザーの書き込み権限と削除権限を制限します。これを行うには、指定したユーザーを除くすべてのユーザーに対して
PUTリクエストとDELETEリクエストを拒否する条件で、バケット権限ポリシーを設定します。運用の透明性、トラブルシューティング、データアクセスのモニタリングのために、監査ロギングを有効にします。
誤って削除された場合に備えて、デフォルトの削除(復元可能)ポリシー(7 日間の保持)を維持します。ただし、Iceberg データが削除された場合は、オブジェクトを手動で復元するのではなく、サポートにお問い合わせください。BigQuery の外部で追加または変更されたオブジェクトは、BigQuery メタデータで追跡されません。
適応型ファイルサイズ設定、自動クラスタリング、ガベージ コレクションは自動的に有効になり、ファイル パフォーマンスと費用の最適化に役立ちます。
BigQuery の BigLake Iceberg テーブルではサポートされていないため、次の Cloud Storage 機能は使用しないでください。
- 階層型名前空間
- デュアル リージョンとマルチリージョン
- オブジェクト アクセス制御リスト(ACL)
- 顧客指定の暗号鍵
- オブジェクトのバージョニング
- オブジェクト ロック
- バケットロック
- BigQuery API または bq コマンドライン ツールを使用して削除済み(復元可能)オブジェクトを復元する
これらのベスト プラクティスを実装するには、次のコマンドを使用してバケットを作成します。
gcloud storage buckets create gs://BUCKET_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --enable-autoclass \ --public-access-prevention \ --uniform-bucket-level-access
次のように置き換えます。
BUCKET_NAME: 新しいバケットの名前PROJECT_ID: オブジェクトの IDLOCATION: 新しいバケットのロケーション
BigQuery ワークフローの BigLake Iceberg テーブル
次のセクションでは、マネージド テーブルの作成、読み込み、管理、クエリの方法について説明します。
始める前に
BigQuery で BigLake Iceberg テーブルを作成して使用する前に、ストレージ バケットへの Cloud リソース接続が設定されていることを確認してください。次の必要なロール セクションで指定されているように、接続にはストレージ バケットへの書き込み権限が必要です。接続に必要なロールと権限の詳細については、接続を管理するをご覧ください。
必要なロール
プロジェクト内のテーブルを BigQuery が管理できるようにするために必要な権限を取得するには、次の IAM ロールの付与を管理者に依頼してください。
-
BigQuery で BigLake Iceberg テーブルを作成するには:
-
プロジェクトに対する BigQuery データオーナー(
roles/bigquery.dataOwner) -
プロジェクトに対する BigQuery Connection 管理者(
roles/bigquery.connectionAdmin)
-
プロジェクトに対する BigQuery データオーナー(
-
BigQuery で BigLake Iceberg テーブルに対してクエリを実行するには:
-
プロジェクトに対する BigQuery データ閲覧者(
roles/bigquery.dataViewer) -
プロジェクトに対する BigQuery ユーザー(
roles/bigquery.user)
-
プロジェクトに対する BigQuery データ閲覧者(
-
Cloud Storage でのデータの読み取りと書き込みを接続サービス アカウントで行えるように、次のロールを付与します。
-
バケットに対するストレージ オブジェクト ユーザー(
roles/storage.objectUser) -
バケットに対する Storage レガシー バケット読み取り(
roles/storage.legacyBucketReader)
-
バケットに対するストレージ オブジェクト ユーザー(
ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
これらの事前定義ロールには、プロジェクト内のテーブルの BigQuery による管理を許可するために必要な権限が含まれています。必要とされる正確な権限については、「必要な権限」セクションを開いてご確認ください。
必要な権限
プロジェクト内のテーブルの BigQuery による管理を許可するには、次の権限が必要です。
- プロジェクトに対する
bigquery.connections.delegate。 - プロジェクトに対する
bigquery.jobs.create。 - プロジェクトに対する
bigquery.readsessions.create。 - プロジェクトに対する
bigquery.tables.create。 - プロジェクトに対する
bigquery.tables.get。 - プロジェクトに対する
bigquery.tables.getData。 -
バケットに対する
storage.buckets.get -
バケットに対する
storage.objects.create -
バケットに対する
storage.objects.delete -
バケットに対する
storage.objects.get -
バケットに対する
storage.objects.list
カスタムロールや他の事前定義ロールを使用して、これらの権限を取得することもできます。
BigQuery で BigLake Iceberg テーブルを作成する
BigQuery で BigLake Iceberg テーブルを作成するには、次のいずれかの方法を選択します。
SQL
CREATE TABLE [PROJECT_ID.]DATASET_ID.TABLE_NAME ( COLUMN DATA_TYPE[, ...] ) CLUSTER BY CLUSTER_COLUMN_LIST WITH CONNECTION {CONNECTION_NAME | DEFAULT} OPTIONS ( file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'STORAGE_URI');
次のように置き換えます。
- PROJECT_ID: データセットを含むプロジェクト。未定義の場合、コマンドはデフォルトのプロジェクトを想定します。
- DATASET_ID: 既存のデータセット。
- TABLE_NAME: 作成するテーブルの名前。
- DATA_TYPE: 列に含まれる情報のデータ型。
- CLUSTER_COLUMN_LIST(省略可): 最大 4 つの列を含むカンマ区切りリスト。最上位の非繰り返し列である必要があります。
CONNECTION_NAME: 接続の名前。例:
myproject.us.myconnection。デフォルトの接続を使用するには、PROJECT_ID.REGION.CONNECTION_ID を含む接続文字列の代わりに
DEFAULTを指定します。STORAGE_URI: 完全修飾の Cloud Storage URI。例:
gs://mybucket/table。
bq
bq --project_id=PROJECT_ID mk \ --table \ --file_format=PARQUET \ --table_format=ICEBERG \ --connection_id=CONNECTION_NAME \ --storage_uri=STORAGE_URI \ --schema=COLUMN_NAME:DATA_TYPE[, ...] \ --clustering_fields=CLUSTER_COLUMN_LIST \ DATASET_ID.MANAGED_TABLE_NAME
次のように置き換えます。
- PROJECT_ID: データセットを含むプロジェクト。未定義の場合、コマンドはデフォルトのプロジェクトを想定します。
- CONNECTION_NAME: 接続の名前。例:
myproject.us.myconnection。 - STORAGE_URI: 完全修飾の Cloud Storage URI。例:
gs://mybucket/table。 - COLUMN_NAME: 列の名前。
- DATA_TYPE: 列に含まれる情報のデータ型。
- CLUSTER_COLUMN_LIST(省略可): 最大 4 つの列を含むカンマ区切りリスト。最上位の非繰り返し列である必要があります。
- DATASET_ID: 既存のデータセットの ID。
- MANAGED_TABLE_NAME: 作成するテーブルの名前。
API
次のように、定義済みのテーブル リソースを使用して tables.insert メソッドを呼び出します。
{ "tableReference": { "tableId": "TABLE_NAME" }, "biglakeConfiguration": { "connectionId": "CONNECTION_NAME", "fileFormat": "PARQUET", "tableFormat": "ICEBERG", "storageUri": "STORAGE_URI" }, "schema": { "fields": [ { "name": "COLUMN_NAME", "type": "DATA_TYPE" } [, ...] ] } }
次のように置き換えます。
- TABLE_NAME: 作成するテーブルの名前。
- CONNECTION_NAME: 接続の名前。例:
myproject.us.myconnection。 - STORAGE_URI: 完全修飾の Cloud Storage URI。ワイルドカードもサポートされます。例:
gs://mybucket/table。 - COLUMN_NAME: 列の名前。
- DATA_TYPE: 列に含まれる情報のデータ型。
BigQuery の BigLake Iceberg テーブルにデータをインポートする
次のセクションでは、さまざまなテーブル形式から BigQuery の BigLake Iceberg テーブルにデータをインポートする方法について説明します。
フラット ファイルからのデータの標準読み込み
BigQuery の BigLake Iceberg テーブルは、BigQuery 読み込みジョブを使用して外部ファイルを BigQuery の BigLake Iceberg テーブルに読み込みます。BigQuery に既存の BigLake Iceberg テーブルがある場合は、bq load CLI ガイドまたは LOAD SQL ガイドに沿って外部データを読み込みます。データの読み込み後、新しい Parquet ファイルが STORAGE_URI/data フォルダに書き込まれます。
BigQuery に既存の BigLake Iceberg テーブルがない場合に前述の手順を行うと、代わりに BigQuery テーブルが作成されます。
マネージド テーブルへのバッチ読み込みの、ツール固有の例については、以下をご覧ください。
SQL
LOAD DATA INTO MANAGED_TABLE_NAME FROM FILES ( uris=['STORAGE_URI'], format='FILE_FORMAT');
次のように置き換えます。
- MANAGED_TABLE_NAME: BigQuery の既存の BigLake Iceberg テーブルの名前。
- STORAGE_URI: 完全修飾の Cloud Storage URI または URI のカンマ区切りのリスト。ワイルドカードもサポートされます。例:
gs://mybucket/table。 - FILE_FORMAT: ソーステーブルの形式。サポートされている形式については、
load_option_listのformat行をご覧ください。
bq
bq load \ --source_format=FILE_FORMAT \ MANAGED_TABLE \ STORAGE_URI
次のように置き換えます。
- FILE_FORMAT: ソーステーブルの形式。サポートされている形式については、
load_option_listのformat行をご覧ください。 - MANAGED_TABLE_NAME: BigQuery の既存の BigLake Iceberg テーブルの名前。
- STORAGE_URI: 完全修飾の Cloud Storage URI または URI のカンマ区切りのリスト。ワイルドカードもサポートされます。例:
gs://mybucket/table。
Hive パーティション分割ファイルからの標準読み込み
BigQuery の標準読み込みジョブを使用して、Hive パーティション分割ファイルを BigQuery の BigLake Iceberg テーブルに読み込めます。詳細については、外部パーティション分割データの読み込みをご覧ください。
Pub/Sub からストリーミング データを読み込む
Pub/Sub BigQuery サブスクリプションを使用して、ストリーミング データを BigQuery の BigLake Iceberg テーブルに読み込めます。
BigQuery の BigLake Iceberg テーブルからデータをエクスポートする
次のセクションでは、BigQuery の BigLake Iceberg テーブルからさまざまなテーブル形式にデータをエクスポートする方法について説明します。
データをフラット形式にエクスポートする
BigQuery の BigLake Iceberg テーブルをフラット形式にエクスポートするには、EXPORT DATA ステートメントを使用してエクスポート先の形式を選択します。詳細については、データのエクスポートをご覧ください。
BigQuery メタデータ スナップショットに BigLake Iceberg テーブルを作成する
BigQuery メタデータ スナップショットに BigLake Iceberg テーブルを作成する手順は次のとおりです。
EXPORT TABLE METADATASQL ステートメントを使用して、メタデータを Iceberg V2 形式にエクスポートします。省略可: Iceberg メタデータ スナップショットの更新をスケジュールします。設定された時間間隔で Iceberg メタデータ スナップショットを更新するには、スケジュールされたクエリを使用します。
省略可: プロジェクトのメタデータの自動更新を有効にして、テーブル ミューテーションごとに Iceberg テーブルのメタデータ スナップショットを自動的に更新します。メタデータの自動更新を有効にするには、bigquery-tables-for-apache-iceberg-help@google.com にお問い合わせください。更新オペレーションごとに
EXPORT METADATA費用が適用されます。
次の例では、DDL ステートメント EXPORT TABLE METADATA FROM mydataset.test を使用して、My Scheduled Snapshot Refresh Query という名前のスケジュールされたクエリを作成します。DDL ステートメントは 24 時間ごとに実行されます。
bq query \ --use_legacy_sql=false \ --display_name='My Scheduled Snapshot Refresh Query' \ --schedule='every 24 hours' \ 'EXPORT TABLE METADATA FROM mydataset.test'
BigQuery メタデータ スナップショットで BigLake Iceberg テーブルを表示する
BigQuery の BigLake Iceberg テーブルのメタデータ スナップショットを更新すると、BigQuery の BigLake Iceberg テーブルが最初に作成された Cloud Storage URI でスナップショットを確認できます。/data フォルダには Parquet ファイルのデータシャードが含まれ、/metadata フォルダには BigQuery メタデータ スナップショットの BigLake Iceberg テーブルが含まれます。
SELECT table_name, REGEXP_EXTRACT(ddl, r"storage_uri\s*=\s*\"([^\"]+)\"") AS storage_uri FROM `mydataset`.INFORMATION_SCHEMA.TABLES;
mydataset と table_name は、実際のデータセットとテーブルのプレースホルダです。
Apache Spark で BigQuery の BigLake Iceberg テーブルを読み取る
次の例では、Apache Iceberg で Spark SQL を使用するように環境をセットアップしてから、クエリを実行して、BigQuery の指定された BigLake Iceberg テーブルからデータを取得します。
spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-ICEBERG_VERSION_NUMBER \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.type=hadoop \ --conf spark.sql.catalog.CATALOG_NAME.warehouse='BUCKET_PATH' \ # Query the table SELECT * FROM CATALOG_NAME.FOLDER_NAME;
次のように置き換えます。
- ICEBERG_VERSION_NUMBER: Apache Spark Iceberg ランタイムの現在のバージョン。Spark のリリースから最新バージョンをダウンロードしてください。
- CATALOG_NAME: BigQuery で BigLake Iceberg テーブルを参照するカタログ。
- BUCKET_PATH: テーブル ファイルを含むバケットへのパス。例:
gs://mybucket/。 - FOLDER_NAME: テーブル ファイルを含むフォルダ。例:
myfolder
BigQuery で BigLake Iceberg テーブルを変更する
BigQuery で BigLake Iceberg テーブルを変更するには、テーブル スキーマの変更の手順に沿って操作します。
マルチステートメント トランザクションを使用する
BigQuery の BigLake Iceberg テーブルのマルチステートメント トランザクションを利用するには、登録フォームに必要事項を記入してお申し込みください。
料金
BigQuery の BigLake Iceberg テーブルの料金は、ストレージ、ストレージ最適化、クエリとジョブで構成されます。
ストレージ
BigQuery の BigLake Iceberg テーブルは、すべてのデータを Cloud Storage に保存します。保存されたすべてのデータ(過去のテーブルデータを含む)に対して課金されます。Cloud Storage のデータ処理と転送料金も適用される場合があります。BigQuery または BigQuery Storage API を介して処理されるオペレーションについては、一部の Cloud Storage オペレーション料金が免除される場合があります。BigQuery 固有のストレージ料金はありません。詳細については、Cloud Storage の料金をご覧ください。
ストレージ最適化
BigQuery の BigLake Iceberg テーブルは、クエリ パフォーマンスを最適化し、ストレージ費用を削減するために、圧縮、クラスタリング、ガベージ コレクション、BigQuery メタデータの生成/更新などのテーブルの自動管理を行います。BigLake テーブル管理のコンピューティング リソースの使用量は、秒単位で、Data Compute Unit(DCU)で課金されます。詳細については、BigQuery の BigLake Iceberg テーブルの料金をご覧ください。
BigQuery Storage Write API を介してストリーミング中に実行されるデータ エクスポート オペレーションは、Storage Write API の料金に含まれており、バックグラウンド メンテナンスとしては課金されません。詳細については、データの取り込みの料金をご覧ください。
[ストレージ最適化] と EXPORT TABLE METADATA の使用状況は、INFORMATION_SCHEMA.JOBS ビューに表示されます。
クエリとジョブ
BigQuery テーブルと同様に、BigQuery オンデマンド料金を使用する場合はクエリと読み取りバイト数(TiB 単位)、BigQuery 容量コンピューティングの料金を使用する場合はスロットの使用量(スロット時間単位)に基づいて課金されます。
BigQuery の料金は、BigQuery Storage Read API と BigQuery Storage Write API にも適用されます。
読み込みオペレーションとエクスポート オペレーション(EXPORT METADATA など)は、Enterprise エディションの従量課金制スロットを使用します。これは、これらのオペレーションに対して料金が発生しない BigQuery テーブルと異なる点です。Enterprise または Enterprise Plus のスロットによる PIPELINE 予約が使用可能な場合、読み込みオペレーションとエクスポート オペレーションでは、代わりにこれらの予約スロットが優先的に使用されます。
制限事項
BigQuery の BigLake Iceberg テーブルには次の制限があります。
- BigQuery の BigLake Iceberg テーブルは、名前変更オペレーションや
ALTER TABLE RENAME TOステートメントをサポートしていません。 - BigQuery の BigLake Iceberg テーブルは、テーブルのコピーや
CREATE TABLE COPYステートメントをサポートしていません。 - BigQuery の BigLake Iceberg テーブルは、テーブル クローンや
CREATE TABLE CLONEステートメントをサポートしていません。 - BigQuery の BigLake Iceberg テーブルは、テーブル スナップショットや
CREATE SNAPSHOT TABLEステートメントをサポートしていません。 - BigQuery の BigLake Iceberg テーブルは、次のテーブル スキーマをサポートしていません。
- 空のスキーマ
BIGNUMERIC、INTERVAL、JSON、RANGE、GEOGRAPHYのデータ型のスキーマ。- フィールドの照合順序を含むスキーマ。
- デフォルト値の式を含むスキーマ。
- BigQuery の BigLake Iceberg テーブルは、次のスキーマ進化のケースをサポートしていません。
NUMERICからFLOATへの型強制変換INTからFLOATへの型強制変換- SQL DDL ステートメントを使用した、新しいネストされたフィールドの既存の
RECORD列への追加
- BigQuery の BigLake Iceberg テーブルでは、コンソールまたは API でクエリが実行されると、ストレージ サイズが 0 バイトと表示されます。
- BigQuery の BigLake Iceberg テーブルは、マテリアライズド ビューをサポートしていません。
- BigQuery の BigLake Iceberg テーブルは承認済みビューをサポートしていませんが、列レベルのアクセス制御はサポートしています。
- BigQuery の BigLake Iceberg テーブルは、変更データ キャプチャ(CDC)の更新をサポートしていません。
- BigQuery の BigLake Iceberg テーブルは、マネージド障害復旧をサポートしていません
- BigQuery の BigLake Iceberg テーブルはパーティショニングをサポートしていません。代わりにクラスタリングを検討してください。
- BigQuery の BigLake Iceberg テーブルは、行レベルのセキュリティをサポートしていません。
- BigQuery の BigLake Iceberg テーブルは、フェイルセーフ期間をサポートしていません。
- BigQuery の BigLake Iceberg テーブルは抽出ジョブをサポートしていません。
INFORMATION_SCHEMA.TABLE_STORAGEビューには、BigQuery の BigLake Iceberg テーブルは含まれません。- BigQuery の BigLake Iceberg テーブルは、クエリ結果の宛先としてサポートされていません。代わりに、
CREATE TABLEステートメントを使用し、AS query_statement引数を指定して、クエリ結果の宛先としてテーブルを作成できます。 CREATE OR REPLACEは、BigQuery の標準テーブルの BigLake Iceberg テーブルへの置き換えや、BigQuery の BigLake Iceberg テーブルの標準テーブルへの置き換えをサポートしていません。- バッチ読み込みと
LOAD DATAステートメントは、BigQuery の既存の BigLake Iceberg テーブルへのデータの追加のみをサポートしています。 - バッチ読み込みと
LOAD DATAステートメントは、スキーマの更新をサポートしていません。 TRUNCATE TABLEは、BigQuery の BigLake Iceberg テーブルをサポートしていません。これに代わる方法が 2 つあります。CREATE OR REPLACE TABLE(同じテーブル作成オプションを使用)。WHERE句 true でのDELETE FROMテーブル
APPENDSテーブル値関数(TVF)は、BigQuery の BigLake Iceberg テーブルをサポートしていません。- Iceberg メタデータには、過去 90 分以内に Storage Write API によって BigQuery にストリーミングされたデータは含まれない場合があります。
tabledata.listを使用したレコードベースのページ分割アクセスは、BigQuery の BigLake Iceberg テーブルをサポートしていません。- BigQuery の BigLake Iceberg テーブルは、リンクされたデータセットをサポートしていません。
- BigQuery では、BigLake Iceberg テーブルごとに 1 つの同時変更 DML ステートメント(
UPDATE、DELETE、MERGE)のみが実行されます。追加の変更 DML ステートメントはキューに入ります。