리전 간 데이터 세트 복제
BigQuery 데이터 세트 복제를 사용하면 서로 다른 두 리전 또는 멀티 리전 간에 데이터 세트 자동 복제를 설정할 수 있습니다.
개요
BigQuery에서 데이터 세트를 만들 때 데이터가 저장되는 리전 또는 멀티 리전을 선택합니다. 리전은 지리적 영역 내의 데이터 센터 모음이고, 멀티 리전은 두 개 이상의 지리적 리전이 포함된 큰 지리적 영역입니다. 데이터는 포함된 리전 중 하나에 저장되며 멀티 리전 내에서 복제되지 않습니다. 리전 및 멀티 리전에 대한 자세한 내용은 BigQuery 위치를 참조하세요.
BigQuery는 항상 데이터 세트 위치 내의 서로 다른 두Google Cloud 영역에 데이터 복사본을 저장합니다. 영역은 리전 내 Google Cloud 리소스의 배포 구역입니다. 모든 리전에서 영역 간 복제에는 동기식 이중 쓰기가 사용됩니다. 멀티 리전 위치를 선택하면 리전 간 복제 또는 리전 중복성이 제공되지 않으므로 리전 서비스 중단이 발생하는 경우 데이터 세트 가용성이 증가하지 않습니다. 데이터는 지리적 위치 내의 단일 리전에 저장됩니다.
추가적인 지리적 중복성을 위해 모든 데이터 세트를 복제할 수 있습니다. BigQuery는 지정한 다른 리전에 있는 데이터 세트의 보조 복제본을 만듭니다. 그런 후 이 복제본이 다른 리전의 두 영역 사이에 비동기적으로 복제되어 총 4개의 영역별 복사본이 생성됩니다.
데이터 세트 복제
데이터 세트를 복제할 때 BigQuery는 지정된 리전에 데이터를 저장합니다.
기본 리전. 데이터 세트를 처음 만들 때는 BigQuery가 기본 리전에 데이터 세트를 배치합니다.
보조 리전. 데이터 세트 복제본을 추가할 때는 BigQuery가 보조 리전에 복제본을 배치합니다.
처음에는 기본 리전의 복제본이 기본 복제본이 되고 두 번째 리전의 복제본이 보조 복제본이 됩니다.
기본 복제본은 쓰기 가능하고 보조 복제본은 읽기 전용입니다. 기본 복제본에 쓰기는 보조 복제본에 비동기적으로 복제됩니다. 각 리전 내에서 데이터가 2개 영역에 중복해서 저장됩니다. 네트워크 트래픽은 Google Cloud 네트워크를 벗어나지 않습니다.
다음 다이어그램은 데이터 세트가 복제될 때 발생하는 복제를 보여줍니다.
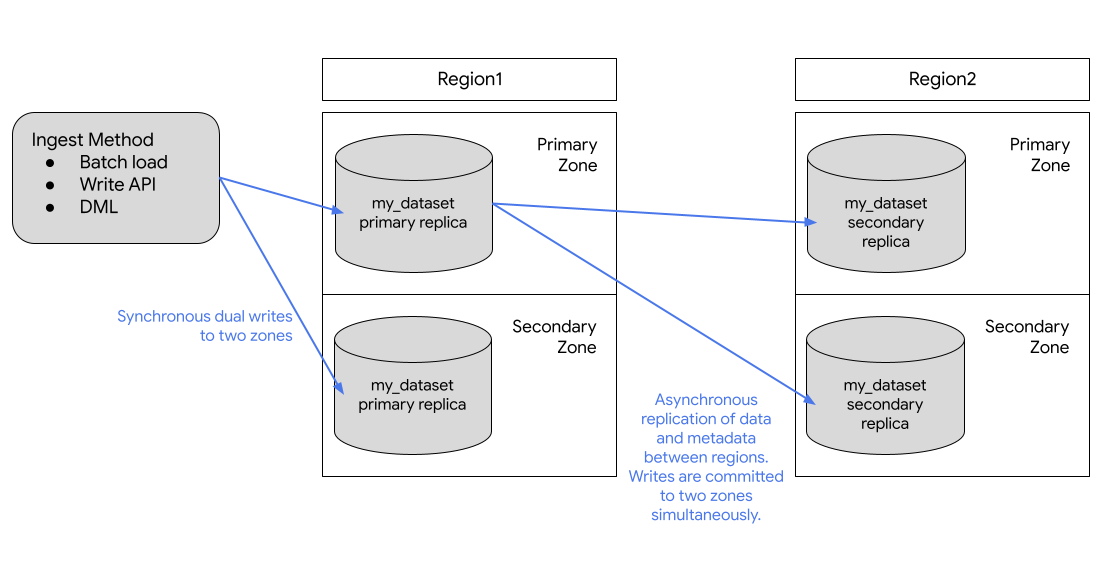
기본 리전이 온라인이면 보조 복제본으로 수동으로 전환할 수 있습니다. 자세한 내용은 보조 복제본 승격을 참조하세요.
가격 책정
복제된 데이터 세트에 대해 다음 요금이 청구됩니다.
- 스토리지. 보조 영역의 스토리지 바이트는 보조 리전의 개별 복사본으로 청구됩니다. BigQuery 스토리지 가격 책정을 참조하세요.
- 데이터 복제. 데이터 복제 요금 청구 방식에 대한 자세한 내용은 데이터 복제 가격 책정을 참조하세요.
데이터 복제는 BigQuery에서 관리하며 슬롯 리소스를 사용하지 않습니다. 데이터 복제에 대한 요금은 별도로 청구됩니다.
보조 리전의 컴퓨팅 용량
보조 리전의 복제본에 대해 작업 및 쿼리를 실행하려면 보조 리전 내에서 슬롯을 구입하거나 주문형 쿼리를 실행해야 합니다.
슬롯을 사용하면 보조 복제본에서 읽기 전용 쿼리를 수행할 수 있습니다. 또한 보조 복제본을 기본으로 승격하면 이러한 슬롯을 사용해서 복제본에 쓰기를 수행할 수 있습니다.
기본 리전에 있는 것과 동일한 슬롯 수 또는 다른 슬롯 수를 구입할 수 있습니다. 슬롯 수를 적게 구입하면 쿼리 성능에 영향을 줄 수 있습니다.
위치 고려사항
데이터 세트 복제본을 추가하려면 먼저 BigQuery에서 복제하려는 초기 데이터 세트를 만들어야 합니다(아직 없는 경우). 추가된 복제본의 위치는 복제본을 추가할 때 지정하는 위치로 설정됩니다. 추가된 복제본의 위치는 초기 데이터 세트의 위치와 달라야 합니다. 즉, 데이터 세트의 데이터가 데이터 세트가 생성된 위치와 복제본의 위치 간에 연속적으로 복제되어야 합니다. 뷰, 구체화된 뷰 또는 BigLake 이외의 외부 테이블과 같은 코로케이션이 필요한 복제본의 경우 소스 데이터 위치와 다르거나 호환되지 않는 위치에 복제본을 추가하면 작업 오류가 발생할 수 있습니다.
고객이 여러 리전 간에 데이터 세트를 복제할 때 BigQuery는 복제본이 생성된 위치에만 데이터가 배치되도록 보장합니다.
코로케이션 요구사항
데이터 세트 복제 사용은 다음과 같은 코로케이션 요구사항에 따라 달라집니다.
Cloud Storage
Cloud Storage에서 데이터를 쿼리하려면 Cloud Storage 버킷이 복제본에 함께 배치되어야 합니다. 복제본 배치 위치를 결정할 때는 외부 테이블 위치 고려사항을 참조합니다.
제한사항
BigQuery 데이터 세트 복제에는 다음 제한사항이 적용됩니다.
- BigQuery Storage Write API 또는
tabledata.insertAll메서드에서 기본 복제본에 작성된 스트리밍 데이터는 이후 보조 복제본에 최선의 방식으로 복제되며 복제 지연이 크게 발생할 수 있습니다. - Datastream 또는 BigQuery 변경 데이터 캡처에서 기본 복제본에 작성된 스트리밍 삽입/업데이트(upsert)는 이후 보조 복제본에 최선의 방식으로 복제되며 복제 지연이 크게 발생할 수 있습니다. 복제되면 보조 복제본의 삽입/업데이트(upsert)는 테이블의 구성된
max_staleness값에 따라 보조 복제본의 테이블 기준에 병합됩니다. - 복제된 데이터 세트의 테이블에 세분화된 DML을 사용 설정할 수 없으며, 세분화된 DML이 사용 설정된 테이블이 포함된 데이터 세트를 복제할 수 없습니다.
- 복제 및 전환은 SQL 데이터 정의 언어(DDL) 문을 통해 관리됩니다.
- 각 리전 또는 멀티 리전에서 각 데이터 세트의 복제본은 1개로 제한됩니다. 동일한 대상 리전에서 동일한 데이터 세트에 대해 2개의 보조 복제본을 만들 수 없습니다.
- 복제본 내의 리소스에는 리소스 동작에 설명된 제한사항이 적용됩니다.
- 정책 태그 및 연결된 데이터 정책은 보조 복제본에 복제되지 않습니다. 원래 리전 이외의 리전에 있는 정책 태그가 포함된 열을 참조하는 쿼리는 해당 복제본이 승격된 경우에도 실패합니다.
- 시간 이동은 보조 복제본 만들기가 완료된 후에만 보조 복제본에서 사용 가능합니다.
- 데이터 세트에서 리전 간 복제를 사용 설정하기 위한 대상 리전 크기 한도는 기본적으로
us및eu멀티 리전의 경우 10PB, 기타 리전의 경우 500TB입니다. 이러한 한도는 구성 가능합니다. 자세한 내용은 Google Cloud 지원팀에 문의하세요. - 할당량은 논리 리소스에 적용됩니다.
- 테이블 수가 100,000개 미만인 데이터 세트만 복제할 수 있습니다.
- 동일한 리전에 데이터 세트당 하루에 최대 4개의 복제본이 추가(이후 삭제)될 수 있습니다.
- 대역폭에 제한됩니다.
- 고객 관리 암호화 키(CMEK)가 적용된 테이블은
replica_kms_key값이 구성되지 않은 경우 보조 리전에서 쿼리할 수 없습니다. - BigLake 테이블은 지원되지 않습니다.
- 외부 또는 제휴 데이터 세트는 복제할 수 없습니다.
- BigQuery Omni 위치는 지원되지 않습니다.
- 재해 복구를 위해 데이터 복제를 구성하는 경우 다음 리전 쌍은 구성할 수 없습니다.
us-central1-us멀티 리전us-west1-us멀티 리전eu-west1-eu멀티 리전eu-west4-eu멀티 리전
- 루틴 수준 액세스 제어는 복제할 수 없지만 루틴의 데이터 세트 수준 액세스 제어는 복제할 수 있습니다.
리소스 동작
다음 작업은 보조 복제본 내 리소스에서 지원되지 않습니다.
보조 복제본은 읽기 전용입니다. 보조 복제본에 리소스 복사본을 만들어야 하는 경우 리소스를 복사하거나 리소스를 먼저 쿼리한 다음 보조 복제본 외부에서 결과를 구체화해야 합니다. 예를 들어 보조 복제본 리소스에서 새 리소스를 만들려면 CREATE TABLE AS SELECT를 사용합니다.
기본 및 보조 복제본에는 다음과 같은 차이가 있습니다.
| 리전 1 기본 복제본 | 리전 2 보조 복제본 | 참고 |
|---|---|---|
| BigLake 테이블 | BigLake 테이블 | 지원되지 않음 |
| 외부 테이블 | 외부 테이블 | 외부 테이블 정의만 복제됩니다. Cloud Storage 버킷이 복제본과 동일한 위치에 함께 배치되지 않으면 쿼리가 실패합니다. |
| 논리적 뷰 | 논리적 뷰 | 논리적 뷰와 동일한 위치에 배치되지 않은 데이터 세트 또는 리소스를 참조하는 논리적 뷰는 쿼리 시에 실패합니다. |
| 관리형 테이블 | 관리형 테이블 | 차이가 없습니다. |
| 구체화된 뷰 | 구체화된 뷰 | 참조된 테이블이 구체화된 뷰와 동일한 리전에 없으면 쿼리가 실패합니다. 복제된 구체화된 뷰는 뷰의 최대 비활성보다 높은 비활성 수준을 경험할 수 있습니다. |
| 모델 | 모델 | 관리형 테이블로 저장됩니다. |
| 원격 함수 | 원격 함수 | 연결이 리전별로 수행됩니다. 원격 함수와 동일한 위치에 배치되지 않은 데이터 세트 또는 리소스(연결)를 참조하는 원격 함수는 실행 시 실패합니다. |
| 루틴 | 사용자 정의 함수(UDF) 또는 저장 프로시저 | 루틴과 동일한 위치에 배치되지 않은 데이터 세트 또는 리소스를 참조하는 루틴은 실행 시 실패합니다. 원격 함수와 같이 연결을 참조하는 모든 루틴은 소스 리전 외부에서 작동하지 않습니다. |
| 행 액세스 정책 | 행 액세스 정책 | 차이가 없습니다. |
| 검색 색인 | 검색 색인 | 복제되지 않습니다. |
| 저장 프로시져 | 저장 프로시져 | 저장 프로시저와 동일한 위치에 배치되지 않은 데이터 세트 또는 리소스를 참조하는 저장 프로시저는 실행 시 실패합니다. |
| 테이블 클론 | 관리형 테이블 | 보조 복제본에서 딥 복사본으로 청구됩니다. |
| 테이블 스냅샷 | 테이블 스냅샷 | 보조 복제본에서 딥 복사본으로 청구됩니다. |
| 테이블 값 함수(TVF) | TVF | TVF와 동일한 위치에 배치되지 않은 데이터 세트 또는 리소스를 참조하는 TVF는 실행 시 실패합니다. |
| UDF | UDF | UDF와 동일한 위치에 배치되지 않은 데이터 세트 또는 리소스를 참조하는 UDF는 실행 시 실패합니다. |
중단 시나리오
리전 간 복제는 전체 리전 중단 중 재해 복구 계획용으로 의도되지 않았습니다. 기본 복제본 리전에서 전체 리전 중단이 발생하면 보조 복제본을 승격할 수 없습니다. 보조 복제본이 읽기 전용이기 때문에 보조 복제본에서 쓰기 작업을 실행할 수 없고 기본 복제본의 리전이 복원될 때까지 보조 리전을 승격할 수 없습니다. 재해 복구 준비에 대한 자세한 내용은 관리형 재해 복구를 참조하세요.
다음 표에서는 복제된 데이터에서 전체 리전 중단의 영향에 대해 설명합니다.
| 리전 1 | 리전 2 | 중단 리전 | 영향 |
|---|---|---|---|
| 기본 복제본 | 보조 복제본 | 리전 2 | 보조 복제본에 대해 리전 2에서 실행 중인 읽기 전용 작업이 실패합니다. |
| 기본 복제본 | 보조 복제본 | 리전 1 | 리전1에서 실행 중인 모든 작업이 실패합니다. 읽기 전용 작업이 보조 복제본이 배치된 리전 2에서 계속 실행됩니다. 리전 2의 콘텐츠는 리전 1과 성공적으로 동기화될 때까지 비활성 상태입니다. |
데이터 세트 복제 사용
이 섹션에서는 데이터 세트를 복제하고, 보조 복제본을 승격하고, 보조 리전에서 BigQuery 읽기 작업을 실행하는 방법을 설명합니다.
필수 권한
복제본을 관리하는 데 필요한 권한을 얻으려면 관리자에게 bigquery.datasets.update 권한을 부여해 달라고 요청하세요.
데이터 세트 복제
데이터 세트를 복제하려면 ALTER SCHEMA ADD REPLICA DDL 문을 사용합니다.
리전 또는 멀티 리전에 아직 복제되지 않은 복제본을 해당 리전 또는 멀티 리전에 배치된 모든 데이터 세트에 추가할 수 있습니다. 복제본을 추가한 후에는 처음 복사 작업이 완료되는 데 시간이 걸립니다. 쿼리 처리 용량의 감소 없이 데이터를 복제하는 동안 기본 복제본을 참조하는 쿼리를 계속 실행할 수 있습니다. 멀티 리전 내의 지리적 위치 내에서는 데이터를 복제할 수 없습니다.
다음 예시에서는 us-central1 리전에 my_dataset라는 데이터 세트를 만든 후 us-east4 리전에 복제본을 추가합니다.
-- Create the primary replica in the us-central1 region. CREATE SCHEMA my_dataset OPTIONS(location='us-central1'); -- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `my_replica` OPTIONS(location='us-east4');
보조 복제본이 성공적으로 생성되었는지 확인하려면 INFORMATION_SCHEMA.SCHEMATA_REPLICAS 뷰에서 creation_complete 열을 쿼리할 수 있습니다.
보조 복제본이 생성된 후 쿼리의 위치 설정을 보조 리전으로 명시적으로 설정하여 쿼리할 수 있습니다. 위치가 명시적으로 설정되지 않은 경우 BigQuery는 데이터 세트의 기본 복제본의 리전을 사용합니다.
보조 복제본 승격
기본 리전이 온라인이면 보조 복제본을 승격할 수 있습니다. 승격 시 보조 복제본이 쓰기 가능한 기본 복제본으로 전환됩니다. 보조 복제본이 기본 복제본과 동기화되었으면 이 작업이 몇 초 내에 완료됩니다. 보조 복제본이 동기화되지 않았으면 동기화될 때까지 승격이 완료되지 않습니다. 기본 복제본이 포함된 리전에 중단이 발생하면 보조 복제본을 기본 복제본으로 승격할 수 없습니다.
다음에 유의하세요.
- 승격이 진행되는 동안 테이블에 쓰기를 수행하면 오류가 반환됩니다. 승격이 시작되는 즉시 이전 기본 복제본이 쓰기 불가능 상태로 됩니다.
- 승격이 시작되는 시점에 완전히 복제되지 않은 테이블은 비활성 읽기를 반환합니다.
복제본을 기본 복제본으로 승격하려면 ALTER SCHEMA SET
OPTIONS DDL 문을 사용하고 primary_replica 옵션을 설정합니다.
다음 사항에 유의하세요. -쿼리 설정에서 작업 위치를 보조 리전으로 명시적으로 설정해야 합니다. BigQuery 위치 지정을 참조하세요.
다음 예시는 us-east4 복제본을 기본 복제본으로 승격합니다.
ALTER SCHEMA my_dataset SET OPTIONS(primary_replica = 'us-east4')
보조 복제본이 성공적으로 승격되었는지 확인하려면 INFORMATION_SCHEMA.SCHEMATA_REPLICAS 뷰에서 replica_primary_assignment_complete 열을 쿼리할 수 있습니다.
데이터 세트 복제본 삭제
복제본을 삭제하고 데이터 세트 복제를 중지하려면 ALTER SCHEMA DROP REPLICA DDL 문을 사용합니다.
다음 예시에서는 us 복제본을 삭제합니다.
ALTER SCHEMA my_dataset DROP REPLICA IF EXISTS `us`;
전체 데이터 세트를 삭제하려면 먼저 보조 복제본을 삭제해야 합니다. 모든 보조 복제본을 삭제하지 않고 DROP
SCHEMA 문을 사용해서 전체 데이터 세트를 삭제하면 다음 오류가 반환됩니다.
The dataset replica of the cross region dataset 'project_id:dataset_id' in region 'REGION' is not yet writable because the primary assignment is not yet complete.
자세한 내용은 보조 복제본 승격을 참조하세요.
데이터 세트 복제본 나열
프로젝트의 데이터 세트 복제본을 나열하려면 INFORMATION_SCHEMA.SCHEMATA_REPLICAS 뷰를 쿼리합니다.
데이터 세트 마이그레이션
하나의 리전에서 다른 리전으로 데이터 세트를 마이그레이션하려면 리전 간 데이터 세트 복제를 사용하면 됩니다. 다음 예시에서는 리전 간 복제를 사용해서 US 멀티 리전에서 EU 멀티 리전으로 기존 my_migration 데이터 세트를 마이그레이션하는 프로세스를 설명합니다.
데이터 세트 복제
마이그레이션 프로세스를 시작하려면 먼저 데이터를 마이그레이션하려는 리전에서 데이터 세트를 복제합니다. 이 시나리오에서는 my_migration 데이터 세트를 EU 멀티 리전에 마이그레이션합니다.
-- Create a replica in the secondary region. ALTER SCHEMA my_migration ADD REPLICA `eu` OPTIONS(location='eu');
그러면 EU 멀티 리전에 eu라는 보조 복제본이 생성됩니다.
기본 복제본은 US 멀티 리전에 있는 my_migration 데이터 세트입니다.
보조 복제본 승격
데이터 세트를 EU 멀티 리전으로 계속 마이그레이션하려면 보조 복제본을 승격시킵니다.
ALTER SCHEMA my_migration SET OPTIONS(primary_replica = 'eu')
승격이 완료되면 eu가 기본 복제본이 됩니다. 이 복제본은 쓰기 가능한 복제본입니다.
마이그레이션 완료
US 멀티 리전에서 EU 멀티 리전으로 마이그레이션을 완료하기 위해 us 복제본을 삭제합니다. 이 단계는 필수가 아니지만 마이그레이션 요구를 넘어서 데이터 세트 복제본이 필요하지 않은 경우에 유용합니다.
ALTER SCHEMA my_migration DROP REPLICA IF EXISTS us;
데이터 세트가 EU 멀티 리전에 배치되고 my_migration 데이터 세트의 복제본이 없습니다. 데이터 세트가 EU 멀티 리전에 성공적으로 마이그레이션되었습니다. 마이그레이션된 리소스의 전체 목록은 리소스 동작에서 찾을 수 있습니다.
고객 관리 암호화 키(CMEK)
고객 관리 Cloud Key Management Service 키는 보조 복제본을 만들 때 자동으로 복제되지 않습니다. 복제된 데이터 세트에서 암호화를 유지하기 위해서는 추가한 복제본의 위치에 replica_kms_key를 설정해야 합니다. ALTER SCHEMA ADD REPLICA DDL 문을 사용하여 replica_kms_key를 설정할 수 있습니다.
CMEK로 데이터 세트 복제는 다음 시나리오에 설명된 것과 같이 작동합니다.
소스 데이터 세트에
default_kms_key가 있으면ALTER SCHEMA ADD REPLICADDL 문을 사용할 때 복제본 데이터 세트의 리전에 생성된replica_kms_key를 제공해야 합니다.소스 데이터 세트에
default_kms_key에 대해 설정된 값이 없으면replica_kms_key를 설정할 수 없습니다.default_kms_key또는replica_kms_key중 하나(또는 둘 다)에서 Cloud KMS 키 순환을 사용하는 경우 키 순환 후에도 복제된 데이터 세트를 계속 쿼리할 수 있습니다.- 기본 리전의 키 순환은 순환 이후에 생성된 테이블에서만 키 버전을 업데이트하며, 키 순환 이전에 존재했던 테이블은 순환 이전에 설정된 키 버전을 계속 사용합니다.
- 보조 리전의 키 순환은 보조 복제본의 모든 테이블을 새 키 버전으로 업데이트합니다.
- 기본 복제본을 보조 복제본으로 전환하면 보조 복제본(이전의 기본 복제본)의 모든 테이블이 새 키 버전으로 업데이트됩니다.
- 키 순환 전에 기본 복제본의 테이블에 설정된 키 버전이 삭제되면 키 순환 이전에 설정된 키 버전을 계속 사용하는 모든 테이블은 키 버전이 업데이트될 때까지 쿼리할 수 없습니다. 키 버전을 업데이트하려면 이전 키 버전이 사용 중지 또는 삭제된 상태가 아니라 활성 상태여야 합니다.
소스 데이터 세트에
default_kms_key에 대해 설정된 값이 없지만 소스 데이터 세트에 CMEK가 적용된 개별 테이블이 있으면 해당 테이블이 복제된 데이터 세트에서 쿼리할 수 없는 상태가 됩니다. 이 테이블을 쿼리하려면 다음을 수행합니다.- 소스 데이터 세트에 대해
default_kms_key값을 추가합니다. ALTER SCHEMA ADD REPLICADDL 문을 사용하여 새 복제본을 만들 때replica_kms_key옵션의 값을 설정합니다. CMEK 테이블이 대상 리전에서 쿼리 가능해집니다.
대상 리전의 모든 CMEK 테이블은 소스 리전에 사용된 키에 관계없이 동일한
replica_kms_key를 사용합니다.- 소스 데이터 세트에 대해
CMEK로 복제본 만들기
다음 예시에서는 replica_kms_key 값이 설정된 us-west1 리전에서 복제본을 만듭니다. CMEK 키의 경우 암호화 및 복호화할 수 있는 BigQuery 서비스 계정 권한을 부여합니다.
-- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `us-west1` OPTIONS(location='us-west1', replica_kms_key='my_us_west1_kms_key_name');
CMEK 제한사항
CMEK를 적용하여 데이터 세트를 복제할 때는 다음과 같은 제한사항이 적용됩니다.
복제본이 생성된 후 복제된 Cloud KMS 키를 업데이트할 수 없습니다.
데이터 세트 복제본이 생성된 후 소스 데이터 세트에서
default_kms_key값을 업데이트할 수 없습니다.제공된
replica_kms_key가 대상 리전에서 유효하지 않으면 데이터 세트가 복제되지 않습니다.
다음 단계
- BigQuery 예약 작업 방법 알아보기
- BigQuery 신뢰성 기능 알아보기