변경 데이터 캡처로 테이블 업데이트 스트리밍
BigQuery 변경 데이터 캡처(CDC)는 스트리밍된 변경사항을 기존 데이터에 처리하고 적용하여 BigQuery 테이블을 업데이트합니다. 이 동기화는 BigQuery Storage Write API에서 실시간으로 스트리밍하는 행 upsert 및 delete 작업을 통해 수행됩니다. 참고로, 계속하기 전에 BigQuery Storage Write API에 대해서는 반드시 숙지해야 합니다.
시작하기 전에
이 문서의 각 태스크를 수행하는 데 필요한 권한을 사용자에게 제공하는 Identity and Access Management(IAM) 역할을 부여해야 하며, 워크플로가 각 기본 요건을 충족하는지 확인해야 합니다.
필수 권한
Storage Write API를 사용하는 데 필요한 권한을 얻으려면 관리자에게 BigQuery 데이터 편집자(roles/bigquery.dataEditor) IAM 역할을 부여해 달라고 요청하세요.
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
이 사전 정의된 역할에는 Storage Write API를 사용하는 데 필요한 bigquery.tables.updateData 권한이 포함됩니다.
커스텀 역할이나 다른 사전 정의된 역할을 사용하여 이 권한을 부여받을 수도 있습니다.
BigQuery에서 IAM 역할 및 권한에 대한 자세한 내용은 IAM 소개를 참조하세요.
기본 요건
BigQuery CDC를 사용하려면 워크플로가 다음 조건을 충족해야 합니다.
- 기본 스트림에서 Storage Write API를 사용해야 합니다.
- protobuf 형식을 수집 형식으로 사용해야 합니다. Apache Arrow 형식은 지원되지 않습니다.
- BigQuery의 대상 테이블에 기본 키를 선언해야 합니다. 최대 16개의 열이 포함된 복합 기본 키가 지원됩니다.
- CDC 행 작업을 실행할 수 있는 충분한 BigQuery 컴퓨팅 리소스를 사용할 수 있어야 합니다. CDC 행 수정 작업이 실패하면 삭제하려는 데이터가 의도치 않게 유지될 수 있습니다. 자세한 내용은 삭제된 데이터 고려사항을 참고하세요.
기존 레코드에 변경사항 지정
BigQuery CDC에서 유사 열 _CHANGE_TYPE은 각 행에서 처리할 변경 유형을 나타냅니다. CDC를 사용하려면 Storage Write API를 사용하여 행 수정사항을 스트리밍할 때 _CHANGE_TYPE를 설정하세요. 유사 열 _CHANGE_TYPE은 UPSERT 및 DELETE 값만 허용합니다.
Storage Write API가 이러한 방식으로 테이블에 행 수정을 스트리밍하는 동안 테이블은 CDC가 사용 설정된 것으로 간주됩니다.
UPSERT 및 DELETE 값의 예시
BigQuery의 다음 테이블을 고려해 보세요.
| ID | 이름 | 급여 |
|---|---|---|
| 100 | Charlie | 2000 |
| 101 | Tal | 3000 |
| 102 | Lee | 5000 |
다음 행 수정사항은 Storage Write API에 의해 스트리밍됩니다.
| ID | 이름 | 급여 | _CHANGE_TYPE |
|---|---|---|---|
| 100 | 삭제 | ||
| 101 | Tal | 8000 | UPSERT |
| 105 | Izumi | 6000 | UPSERT |
업데이트된 테이블은 다음과 같습니다.
| ID | 이름 | 급여 |
|---|---|---|
| 101 | Tal | 8000 |
| 102 | Lee | 5000 |
| 105 | Izumi | 6000 |
테이블 비활성 관리
기본적으로 쿼리를 실행할 때마다 BigQuery는 최신 결과를 반환합니다. CDC가 사용 설정된 테이블을 쿼리할 때 최신 결과를 제공하려면 BigQuery가 쿼리 시작 시간까지의 각 스트리밍 행 수정을 적용해야 테이블의 최신 버전이 쿼리될 수 있습니다. 쿼리 실행 시 이러한 행 수정사항을 적용하면 쿼리 지연 시간과 비용이 증가합니다. 그러나 완전히 최신 쿼리 결과가 필요하지 않으면 테이블에서 max_staleness 옵션을 설정하여 쿼리 비용 및 지연 시간을 줄일 수 있습니다. 이 옵션을 설정하면 BigQuery는 max_staleness 값으로 정의된 간격 내에 행 수정사항을 최소 한 번 적용하므로 업데이트가 적용될 때까지 기다리지 않고 약간의 데이터 비활성 비용으로 쿼리를 실행합니다.
이 동작은 데이터 최신 상태가 필요하지 않은 대시보드와 보고서에 특히 유용합니다. 또한 BigQuery가 행 수정을 적용하는 빈도를 보다 효과적으로 제어할 수 있으므로 비용 관리에 유용합니다.
max_staleness 옵션이 설정된 테이블 쿼리
max_staleness 옵션이 설정된 테이블을 쿼리하면 BigQuery는 max_staleness 값과, 테이블의 upsert_stream_apply_watermark 타임스탬프로 표시되는 마지막 적용 작업이 발생한 시간을 기준으로 결과를 반환합니다.
테이블의 max_staleness 옵션이 10분으로 설정되어 있고 가장 최근의 적용 작업이 T20에 발생한 다음 예를 살펴보세요.
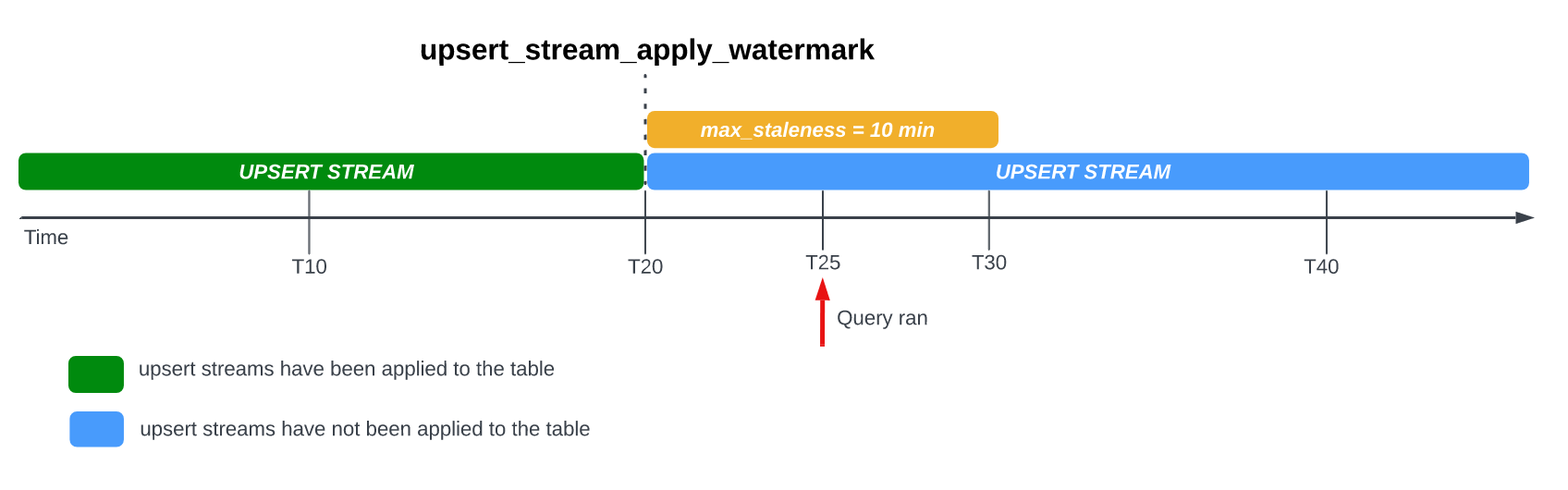
T25에서 테이블을 쿼리하면 현재 버전의 테이블은 5분 동안 비활성 상태이며, 이는 max_staleness 간격인 10분보다 작습니다. 이 경우 BigQuery는 T20의 테이블 버전을 반환하므로 반환된 데이터도 5분 지연됩니다.
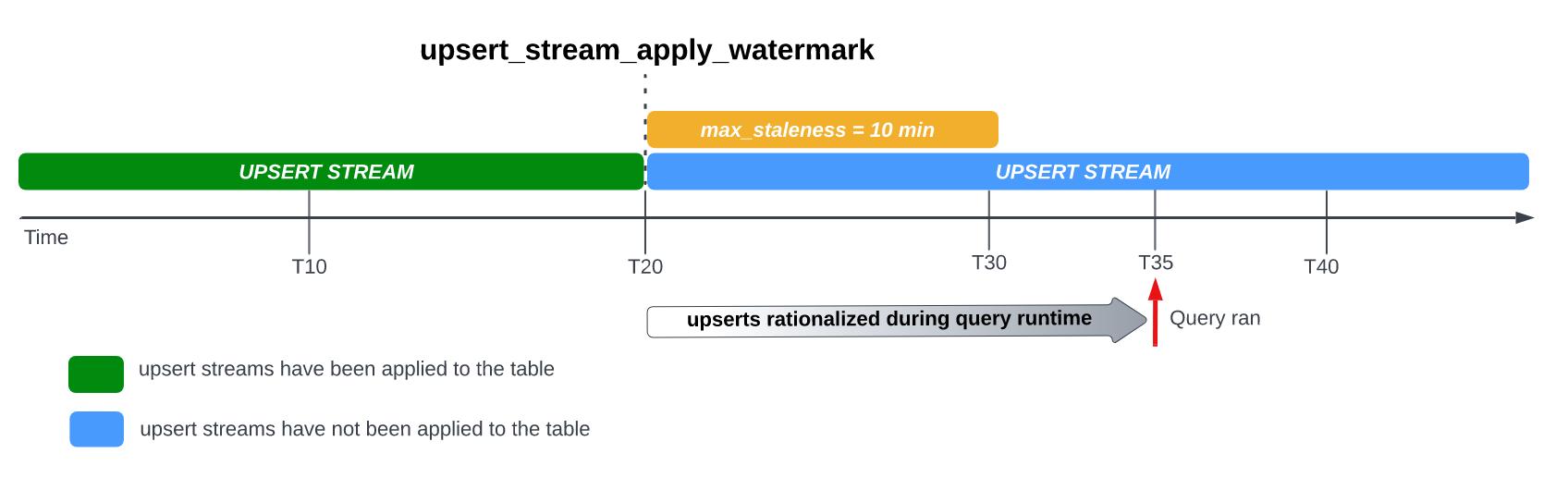
테이블에서 max_staleness 옵션을 설정하면 BigQuery는 max_staleness 간격 내에 대기 중인 행 수정사항을 최소 한 번 적용합니다. 하지만 BigQuery가 이 간격 내에 보류 중인 행 수정사항을 적용하는 프로세스를 완료하지 못할 수도 있습니다.
예를 들어 T35에서 테이블을 쿼리하고 보류 중인 행 수정 적용 프로세스가 완료되지 않으면 현재 버전의 테이블은 15분 동안 비활성 상태이며, 이는 max_staleness 간격인 10분보다 큽니다.
이 경우 쿼리 실행 시 BigQuery는 현재 쿼리에 대해 T20과 T35 사이의 모든 행 수정 사항을 적용합니다. 즉, 쿼리 지연 시간이 추가로 발생하지만 쿼리된 데이터는 완전히 최신 상태입니다.
이는 런타임 병합 작업으로 간주됩니다.
권장 테이블 max_staleness 값
테이블의 max_staleness 값은 일반적으로 다음 두 값 중 더 큰 값이어야 합니다.
- 워크플로에 허용되는 최대 데이터 비활성
- upsert된 변경사항을 테이블에 적용하는 데 걸리는 최대 시간의 두 배와 추가 버퍼 시간
upsert된 변경사항을 기존 테이블에 적용하는 데 걸리는 시간을 계산하려면 다음 SQL 쿼리를 사용하여 백그라운드 적용 작업의 95번째 백분위수 기간과 BigQuery 쓰기 최적화 스토리지(스트리밍 버퍼) 변환을 허용하는 7분 버퍼를 확인합니다.
SELECT project_id, destination_table.dataset_id, destination_table.table_id, APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)] AS p95_background_apply_duration_in_seconds, CEILING(APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)]*2/60)+7 AS recommended_max_staleness_with_buffer_in_minutes FROM `region-REGION`.INFORMATION_SCHEMA.JOBS AS job WHERE project_id = 'PROJECT_ID' AND DATE(creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE "%cdc_background%" GROUP BY 1,2,3;
다음을 바꿉니다.
REGION: 프로젝트가 있는 리전 이름(예:us).PROJECT_ID: BigQuery CDC에서 수정 중인 BigQuery 테이블이 포함된 프로젝트의 ID.
백그라운드 적용 작업 기간은 비활성 간격 내에서 실행되는 CDC 작업의 수와 복잡성, 테이블 크기, BigQuery 리소스 가용성을 포함하여 여러 요인의 영향을 받습니다. 리소스 가용성에 대한 자세한 내용은 백그라운드 예약의 크기 및 모니터링을 참조하세요.
max_staleness 옵션을 사용하여 테이블 만들기
max_staleness 옵션을 사용하여 테이블을 만들려면 CREATE TABLE 문을 사용하세요.
다음 예시에서는 max_staleness 제한 시간이 10분인 employees 테이블을 만듭니다.
CREATE TABLE employees ( id INT64 PRIMARY KEY NOT ENFORCED, name STRING) CLUSTER BY id OPTIONS ( max_staleness = INTERVAL 10 MINUTE);
기존 테이블의 max_staleness 옵션 수정
기존 테이블에서 max_staleness 한도를 추가하거나 수정하려면 ALTER TABLE 문을 사용합니다.
다음 예시에서는 employees 테이블의 max_staleness 한도를 15분으로 변경합니다.
ALTER TABLE employees SET OPTIONS ( max_staleness = INTERVAL 15 MINUTE);
테이블의 현재 max_staleness 값 확인
테이블의 현재 max_staleness 값을 확인하려면 INFORMATION_SCHEMA.TABLE_OPTIONS 뷰를 쿼리합니다.
다음 예시에서는 mytable 테이블의 현재 max_staleness 값을 확인합니다.
SELECT option_name, option_value FROM DATASET_NAME.INFORMATION_SCHEMA.TABLE_OPTIONS WHERE option_name = 'max_staleness' AND table_name = 'TABLE_NAME';
다음을 바꿉니다.
DATASET_NAME: CDC가 사용 설정된 테이블이 있는 데이터 세트의 이름입니다.TABLE_NAME: CDC가 사용 설정된 테이블의 이름입니다.
결과는 max_staleness 값이 10분인 것으로 표시됩니다.
+---------------------+--------------+ | Row | option_name | option_value | +---------------------+--------------+ | 1 | max_staleness | 0-0 0 0:10:0 | +---------------------+--------------+
테이블 삽입/업데이트(upsert) 작업 진행 상황 모니터링
테이블의 상태를 모니터링하고 행 수정사항이 마지막으로 적용된 시점을 확인하려면 INFORMATION_SCHEMA.TABLES 뷰를 쿼리하여 upsert_stream_apply_watermark 타임스탬프를 가져옵니다.
다음 예시에서는 mytable 테이블의 upsert_stream_apply_watermark 값을 확인합니다.
SELECT upsert_stream_apply_watermark FROM DATASET_NAME.INFORMATION_SCHEMA.TABLES WHERE table_name = 'TABLE_NAME';
다음을 바꿉니다.
DATASET_NAME: CDC가 사용 설정된 테이블이 있는 데이터 세트의 이름입니다.TABLE_NAME: CDC가 사용 설정된 테이블의 이름입니다.
결과는 다음과 비슷합니다.
[{
"upsert_stream_apply_watermark": "2022-09-15T04:17:19.909Z"
}]
upsert 작업은 bigquery-adminbot@system.gserviceaccount.com 서비스 계정으로 수행되며 CDC가 사용 설정된 테이블이 포함된 프로젝트의 작업 기록에 표시됩니다.
커스텀 순서 지정 관리
BigQuery로 삽입/업데이트(upsert)를 스트리밍할 때 기본 키가 동일한 레코드를 정렬하는 기본 동작은 레코드가 BigQuery로 수집된 BigQuery 시스템 시간에 따라 결정됩니다. 즉, 최신 타임스탬프로 가장 최근에 수집된 레코드가 오래된 타임스탬프로 이전에 수집된 레코드보다 우선합니다. 단기간 동안 동일한 기본 키에 삽입/업데이트(upsert)가 자주 발생할 수 있거나 삽입/업데이트(upsert) 순서가 보장되지 않는 경우와 같은 특정 사용 사례에서는 이것으로 충분하지 않을 수 있습니다. 이러한 경우 사용자 제공 순서 키가 필요할 수 있습니다.
사용자 제공 순서 키를 구성하려면 유사 열 _CHANGE_SEQUENCE_NUMBER를 사용하여 기본 키가 같은 일치 레코드 2개 간에 더 큰 _CHANGE_SEQUENCE_NUMBER를 기준으로 BigQuery에서 레코드를 적용해야 하는 순서를 나타냅니다. 유사 열 _CHANGE_SEQUENCE_NUMBER는 선택적인 열이며 고정된 형식으로 된 STRING 값만 허용합니다.
_CHANGE_SEQUENCE_NUMBER 형식
유사 열 _CHANGE_SEQUENCE_NUMBER는 고정된 형식으로 작성된 STRING 값만 허용합니다. 이 고정된 형식은 섹션을 슬래시 /로 구분하여 16진수로 작성된 STRING 값을 사용합니다. 각 섹션은 최대 16개의 16진수 문자로 표현할 수 있으며 _CHANGE_SEQUENCE_NUMBER당 최대 4개의 섹션이 허용됩니다. _CHANGE_SEQUENCE_NUMBER의 허용 범위는 0/0/0/0~FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF 사이의 값을 지원합니다.
_CHANGE_SEQUENCE_NUMBER 값은 대문자와 소문자를 모두 지원합니다.
기본 순서 키는 단일 섹션을 사용하여 표현할 수 있습니다. 예를 들어 애플리케이션 서버의 레코드 처리 타임스탬프만을 기준으로 키를 정렬하려면 타임스탬프를 에포크(이 경우 '18F2EBB6480')에서 밀리초로 변환하여 16진수로 표현되는 '2024-04-30 11:19:44 UTC' 섹션 하나를 사용할 수 있습니다. 데이터를 16진수로 변환하는 로직은 Storage Write API를 사용하여 BigQuery에 쓰기를 실행하는 클라이언트의 책임입니다.
여러 섹션을 지원하면 보다 복잡한 사용 사례를 위해 여러 처리 로직 값을 하나의 키로 결합할 수 있습니다. 예를 들어 애플리케이션 서버의 레코드 처리 타임스탬프, 로그 시퀀스 번호, 레코드 상태를 기준으로 키를 정렬하려면 각각 16진수로 표현되는 '2024-04-30 11:19:44 UTC' / '123' / 'complete'라는 세 가지 섹션을 사용할 수 있습니다.
섹션 순서는 처리 로직의 순위를 결정하는 데 중요한 고려사항입니다. BigQuery는 첫 번째 섹션을 비교한 후 이전 섹션이 동일한 경우에만 다음 섹션을 비교하여 _CHANGE_SEQUENCE_NUMBER 값을 비교합니다.
BigQuery는 _CHANGE_SEQUENCE_NUMBER를 사용하여 2개 이상의 _CHANGE_SEQUENCE_NUMBER 필드를 부호 없는 숫자 값으로 비교하여 순서 지정을 수행합니다.
다음 _CHANGE_SEQUENCE_NUMBER 비교 예시와 우선 적용 결과를 고려하세요.
예시 1:
- 레코드 #1:
_CHANGE_SEQUENCE_NUMBER= '77' - 레코드 #2:
_CHANGE_SEQUENCE_NUMBER= '7B'
결과: '7B' > '77'(즉, '123' > '119')이므로 레코드 #2가 최신 레코드로 간주됩니다.
- 레코드 #1:
예시 2:
- 레코드 #1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/B' - 레코드 #2:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC'
결과: 'FFF/ABC' > 'FFF/B'(즉, '4095/2748' > '4095/11')이므로 레코드 #2가 최신 레코드로 간주됩니다.
- 레코드 #1:
예시 3:
- 레코드 #1:
_CHANGE_SEQUENCE_NUMBER= 'BA/FFFFFFFF' - 레코드 #2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
결과: 'ABC' > 'BA/FFFFFFFF'(즉, '2748' > '186/4294967295')이므로 레코드 #2가 최신 레코드로 간주됩니다.
- 레코드 #1:
예시 4:
- 레코드 #1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC' - 레코드 #2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
결과: 'FFF/ABC' > 'ABC'(즉, '4095/2748' > '2748')이므로 레코드 #1이 최신 레코드로 간주됩니다.
- 레코드 #1:
두 _CHANGE_SEQUENCE_NUMBER 값이 동일하면 최신 BigQuery 시스템 수집 시간이 있는 레코드가 이전에 수집된 레코드보다 우선 적용됩니다.
테이블에 맞춤 순서를 사용하는 경우 항상 _CHANGE_SEQUENCE_NUMBER 값을 제공해야 합니다. _CHANGE_SEQUENCE_NUMBER 값을 지정하지 않아 _CHANGE_SEQUENCE_NUMBER 값이 있는 행과 없는 행이 혼합되는 쓰기 요청은 순서를 예측할 수 없습니다.
CDC에 사용할 BigQuery 예약 구성
BigQuery 예약을 사용하여 CDC 행 수정 작업을 위한 전용 BigQuery 컴퓨팅 리소스를 할당할 수 있습니다. 예약을 사용하면 이러한 작업 수행에 드는 비용의 한도를 설정할 수 있습니다. 이 접근 방식은 큰 테이블에 대해 CDC 작업이 자주 수행되는 워크플로와 같이 각 작업을 수행할 때 처리되는 바이트 수가 많아서 주문형 비용이 높아질 수 있는 경우에 특히 유용합니다.
max_staleness 간격 내에 보류 중인 행 수정을 적용하는 BigQuery CDC 작업은 백그라운드 작업으로 간주되고 QUERY 할당 유형 대신 BACKGROUND 할당 유형을 활용합니다.
반면에 쿼리 실행 시 행 수정을 적용해야 하는 max_staleness 간격 외부의 쿼리는 QUERY 할당 유형을 사용합니다. max_staleness 설정이 없는 테이블 또는 max_staleness가 0으로 설정된 테이블도 QUERY 할당 유형을 사용합니다.
BACKGROUND 할당 없이 수행되는 BigQuery CDC 백그라운드 작업은 주문형 가격 책정을 사용합니다.
이러한 고려 사항은 BigQuery CDC에 대해 워크로드 관리 전략을 설계할 때 중요합니다.
CDC에 사용하도록 BigQuery 예약을 구성하려면 먼저 BigQuery 테이블이 있는 리전에 예약을 구성합니다. 예약 크기에 대한 안내는 BACKGROUND 예약 크기 조정 및 모니터링을 참조하세요.
예약을 만든 후에는 BigQuery 프로젝트를 예약에 할당하고, 다음 CREATE ASSIGNMENT 문을 실행하여 job_type 옵션을 BACKGROUND에 설정하세요.
CREATE ASSIGNMENT `ADMIN_PROJECT_ID.region-REGION.RESERVATION_NAME.ASSIGNMENT_ID` OPTIONS ( assignee = 'projects/PROJECT_ID', job_type = 'BACKGROUND');
다음을 바꿉니다.
ADMIN_PROJECT_ID: 예약을 소유한 관리 프로젝트의 IDREGION: 프로젝트가 있는 리전 이름(예:us).RESERVATION_NAME: 예약 이름.ASSIGNMENT_ID: 할당 ID. ID는 프로젝트 및 위치에 고유해야 하고, 소문자 또는 숫자로 시작하고 끝나야 하고, 소문자, 숫자, 대시만 포함해야 합니다.PROJECT_ID: BigQuery CDC에서 수정 중인 BigQuery 테이블이 포함된 프로젝트의 ID. 이 프로젝트가 예약에 할당됩니다.
BACKGROUND 예약 크기 조정 및 모니터링
예약은 BigQuery 컴퓨팅 작업을 실행하는 데 사용할 수 있는 컴퓨팅 리소스의 양을 결정합니다. 예약 크기를 너무 작게 설정하면 CDC 행 수정 작업의 처리 시간이 늘어날 수 있습니다. 예약을 정확하게 크기 조정하려면 CDC 작업을 실행하는 프로젝트의 이전 슬롯 소비를 모니터링하세요. INFORMATION_SCHEMA.JOBS_TIMELINE 뷰를 쿼리하면 됩니다.
SELECT period_start, SUM(period_slot_ms) / (1000 * 60) AS slots_used FROM region-REGION.INFORMATION_SCHEMA.JOBS_TIMELINE_BY_PROJECT WHERE DATE(job_creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE '%cdc_background%' GROUP BY period_start ORDER BY period_start DESC;
REGION을 프로젝트가 있는 리전 이름으로 바꿉니다. 예를 들면 us입니다.
삭제된 데이터 고려사항
- BigQuery CDC 작업은 BigQuery 컴퓨팅 리소스를 사용합니다. CDC 작업이 주문형 결제를 사용하도록 구성된 경우 CDC 작업은 내부 BigQuery 리소스를 사용하여 정기적으로 실행됩니다. CDC 작업이
BACKGROUND예약으로 구성된 경우 CDC 작업은 대신 구성된 예약의 리소스 가용성에 영향을 받습니다. 구성된 예약 내에서 사용할 수 있는 리소스가 충분하지 않으면 삭제를 비롯한 CDC 작업 처리에 예상보다 오래 걸릴 수 있습니다. - CDC
DELETE작업은upsert_stream_apply_watermark타임스탬프가 Storage Write API가 작업을 스트리밍한 타임스탬프를 통과한 경우에만 적용되는 것으로 간주됩니다.upsert_stream_apply_watermark타임스탬프에 대한 자세한 내용은 테이블 삽입/업데이트(upsert) 작업 진행 상황 모니터링을 참조하세요. - 순서가 잘못된 CDC
DELETE작업을 적용하기 위해 BigQuery는 삭제 보관 기간을 2일로 유지합니다. 테이블DELETE작업은 표준 Google Cloud 데이터 삭제 프로세스가 시작되기 전에 이 기간 동안 저장됩니다. 삭제 보관 기간 내의DELETE작업에는 표준 BigQuery 스토리지 가격 책정이 사용됩니다.
제한사항
- BigQuery CDC는 키 강제 적용을 실행하지 않으므로 기본 키가 고유해야 합니다.
- 기본 키는 16개의 열을 초과할 수 없습니다.
- CDC 지원 테이블에는 테이블의 스키마에서 정의된 최고 수준 열을 2,000개 넘게 포함할 수 없습니다.
- CDC가 사용 설정된 테이블은 다음을 지원하지 않습니다.
DELETE,UPDATE,MERGE등의 데이터 조작 언어(DML) 문 변형- 와일드 카드 테이블 쿼리
- 검색 색인
- 테이블의
max_staleness값이 너무 낮기 때문에 런타임 병합 작업을 수행하는 CDC 지원 테이블은 다음을 지원할 수 없습니다. - CDC가 사용 설정된 테이블의 BigQuery 내보내기 작업은 아직 백그라운드 작업에 적용되지 않은 최근에 스트리밍된 행 수정사항을 내보내지 않습니다. 전체 테이블을 내보내려면
EXPORT DATA문을 사용합니다. - 쿼리가 파티션을 나눈 테이블에서 런타임 병합을 트리거하면 쿼리가 파티션의 하위 집합으로 제한되는지 여부에 관계없이 전체 테이블이 스캔됩니다.
- Standard 버전을 사용하는 경우
BACKGROUND예약을 사용할 수 없으므로 대기 중인 행 수정을 적용할 때 주문형 가격 책정 모델을 사용합니다. 하지만 버전에 관계없이 CDC가 사용 설정된 테이블을 쿼리할 수 있습니다. - 유사 열
_CHANGE_TYPE및_CHANGE_SEQUENCE_NUMBER는 테이블 읽기를 수행할 때 쿼리할 수 있는 열이 아닙니다. _CHANGE_TYPE에 대해UPSERT또는DELETE값이 있는 행을 동일한 연결에서_CHANGE_TYPE에 대해INSERT또는 지정되지 않은 값이 있는 행과 혼합하는 것은 지원되지 않으며The given value is not a valid CHANGE_TYPE라는 유효성 검사 오류가 발생합니다.
BigQuery CDC 가격 책정
BigQuery CDC는 데이터 수집용 Storage Write API, 데이터 스토리지용 BigQuery 스토리지, 행 수정 작업에 BigQuery 컴퓨팅을 사용하며, 이러한 모든 작업에는 비용이 발생합니다. 가격 정보는 BigQuery 가격 책정을 참고하세요.
BigQuery CDC 비용 추정
일반적인 BigQuery 비용 예상 권장사항 외에도, 대량의 데이터, 낮은 max_staleness 구성 또는 자주 변경되는 데이터를 가진 워크플로의 경우 BigQuery CDC 비용 예측은 중요할 수 있습니다.
BigQuery 데이터 수집 가격 책정 및 BigQuery 스토리지 가격 책정은 유사 열을 포함하여 수집하고 저장하는 데이터 양으로 직접 계산됩니다. 하지만 BigQuery 컴퓨팅 가격 책정은 BigQuery CDC 작업을 실행하는 데 사용되는 컴퓨팅 리소스 소비와 관련이 있으므로 예상하기 어려울 수 있습니다.
BigQuery CDC 작업은 다음 세 가지 카테고리로 나뉩니다.
- 백그라운드 적용 작업: 테이블의
max_staleness값에 의해 정의된 일정한 간격으로 백그라운드에서 실행되는 작업입니다. 이 작업은 최근에 스트리밍된 행 수정사항을 CDC가 사용 설정된 테이블에 적용합니다. - 쿼리 작업:
max_staleness창 내에서 실행되고 CDC 기준 테이블에서만 읽을 수 있는 GoogleSQL 쿼리입니다. - 런타임 병합 작업:
max_staleness창 외부에서 실행되는 임시 GoogleSQL 쿼리에 의해 트리거되는 작업입니다. 이러한 작업은 CDC 기준 테이블과 최근에 스트리밍된 행 수정을 쿼리 런타임에서 즉석에서 병합해야 합니다.
쿼리 작업만 BigQuery 파티셔닝을 활용합니다. 최근에 스트리밍된 행 수정사항을 적용할 때는 최근에 스트리밍된 upsert가 적용되는 테이블 파티션에 대해 보장되지 않기 때문에 백그라운드 적용 작업과 런타임 병합 작업은 파티션닝을 사용할 수 없습니다. 즉, 백그라운드 적용 작업과 런타임 병합 작업 중에 전체 기준 테이블이 읽힙니다. 같은 이유로 쿼리 작업만 BigQuery 클러스터링 열의 필터를 활용할 수 있습니다. CDC 작업을 실행하기 위해 읽어오는 데이터의 양을 파악하면 총비용을 추정하는 데 도움이 됩니다.
테이블 기준에서 읽어오는 데이터 양이 많은 경우 처리된 데이터 양을 기반으로 하지 않는 BigQuery 용량 가격 모델을 사용하는 것이 좋습니다.
BigQuery CDC 비용 권장사항
일반적인 BigQuery 비용 권장사항 외에도 다음 기법을 사용하여 BigQuery CDC 작업의 비용을 최적화하세요.
- 필요하지 않은 경우 테이블의
max_staleness옵션을 매우 낮은 값으로 구성하지 마세요.max_staleness값은 쿼리 작업보다 비용이 많이 들고 속도가 느린 백그라운드 적용 작업 및 런타임 병합 작업의 발생을 늘릴 수 있습니다. 자세한 안내는 권장되는 테이블max_staleness값을 참고하세요. - CDC 테이블에서 사용할 BigQuery 예약 구성을 고려해 보세요.
그렇지 않으면 백그라운드 적용 작업 및 런타임 병합 작업에서 주문형 가격 책정을 사용하므로 데이터 처리가 많아 비용이 더 많이 들 수 있습니다. 자세한 내용은 BigQuery 예약을 알아보고 BigQuery CDC 사용 시
BACKGROUND예약 크기를 조정하고 모니터링하는 방법에 대한 안내를 따르세요.
다음 단계
- Storage Write API 기본 스트림을 구현하는 방법을 알아봅니다.
- Storage Write API 권장사항에 대해 알아봅니다.
- BigQuery CDC를 사용하여 Datastream으로 트랜잭션 데이터베이스를 BigQuery에 복제하는 방법을 알아봅니다.