Analysen mit BigQuery Data Canvas
In diesem Dokument wird beschrieben, wie Sie Data Canvas für die Datenanalyse verwenden. Sie können auch Metadaten für Daten-Canvas mit dem Dataplex Universal Catalog verwalten.
Mit dem Data Canvas von BigQuery, einem Feature von Gemini in BigQuery, können Sie Daten mithilfe natürlicher Sprach-Prompts und einer grafischen Benutzeroberfläche für Analyse-Workflows Daten transformieren, abfragen und visualisieren.
Für Analyse-Workflows wird im BigQuery-Data-Canvas ein gerichteter azyklischer Graph (Directed Acyclic Graph, DAG) verwendet, der eine grafische Ansicht Ihres Workflows bietet. Im BigQuery-Data-Canvas können Sie zentralisiert Abfrageergebnisse iterieren und mit mehreren Abfragezweigen arbeiten.
Der Daten-Canvas von BigQuery soll Analysen beschleunigen und Datenexperten wie Datenanalysten und Data Engineers dabei helfen, Daten in Einblicke zu verwandeln. Sie benötigen keine technischen Kenntnisse bestimmter Tools, sondern nur grundlegende Kenntnisse im Lesen und Schreiben von SQL. Der Daten-Canvas in BigQuery funktioniert mit Dataplex Universal Catalog-Metadaten zur Identifizierung entsprechender Tabellen auf Basis natürlicher Sprache.
BigQuery-Daten-Canvasse sind nicht für die direkte Verwendung durch Geschäftsnutzer vorgesehen.
BigQuery-Daten-Canvas verwendet Gemini in BigQuery, um Ihre Daten zu suchen, SQL zu erstellen, Diagramme zu generieren und Datenzusammenfassungen auszugeben.
Weitere Informationen dazu, wie und wann Gemini for Google Cloud Ihre Daten verwendet
Leistungsspektrum
Mit dem BigQuery-Daten-Canvas haben Sie folgende Möglichkeiten:
Verwenden Sie Suchanfragen in natürlicher Sprache oder die Syntax für die Keyword-Suche mit Dataplex Universal Catalog-Metadaten, um Assets wie Tabellen, Ansichten oder materialisierte Ansichten zu finden.
Natürliche Sprache für einfache SQL-Abfragen nutzen, zum Beispiel:
- Abfragen, die
FROM-Klauseln, mathematische Funktionen, Arrays und Strukturen enthalten. JOIN-Vorgänge für zwei Tabellen.
- Abfragen, die
Sie können benutzerdefinierte Visualisierungen erstellen, indem Sie in natürlicher Sprache beschreiben, was Sie möchten.
Datenstatistiken automatisieren.
Beschränkungen
Befehle in natürlicher Sprache funktionieren möglicherweise nicht gut mit den folgenden Elementen:
- BigQuery ML
- Apache Spark
- Objekttabellen
- BigLake
INFORMATION_SCHEMAAnsichten- JSON
- Verschachtelte und wiederkehrende Felder
- Komplexe Funktionen und Datentypen wie
DATETIMEundTIMEZONE
Datenvisualisierungen funktionieren nicht mit Geokarten.
Best Practices für die Prompt-Erstellung
Mit den richtigen Prompting-Techniken können Sie komplexe SQL-Abfragen generieren. Die folgenden Vorschläge helfen dem BigQuery-Data Canvas, Ihre Prompts in natürlicher Sprache zu optimieren, um die Genauigkeit Ihrer Abfragen zu erhöhen:
Klar schreiben. Formulieren Sie Ihre Anfrage klar und vermeiden Sie vage Formulierungen.
Direkte Fragen stellen: Für die präziseste Antwort sollten Sie jeweils nur eine Frage stellen und Ihre Prompts kurz halten. Wenn Sie ursprünglich einen Prompt mit mehr als einer Frage eingegeben haben, listen Sie die einzelnen Teile der Frage auf, damit sie für Gemini klar verständlich sind.
Geben Sie fokussierte und explizite Anweisungen. Heben Sie wichtige Begriffe in Ihren Prompts hervor.
Operatorrangfolge angeben: Geben Sie die Anweisungen klar und strukturiert an. Teilen Sie Aufgaben in kleine, fokussierte Schritte auf.
Optimieren und iterieren: Probieren Sie verschiedene Formulierungen und Ansätze aus, um die besten Ergebnisse zu erzielen.
Weitere Informationen finden Sie unter Best Practices für Prompts für BigQuery Data Canvas.
Hinweise
- Achten Sie darauf, dass Gemini in BigQuery für Ihr Google Cloud -Projekt aktiviert ist. Dieser Schritt wird in der Regel von einem Administrator ausgeführt.
- Sie benötigen die erforderliche IAM-Berechtigungen (Identity and Access Management), um den BigQuery-Daten-Canvas zu verwenden.
- Wenn Sie Metadaten für Daten-Canvas im Dataplex Universal Catalog verwalten möchten, muss die Dataplex API in Ihrem Google Cloud Projekt aktiviert sein.
Erforderliche Rollen
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen für das Projekt zuzuweisen, um die Berechtigungen zu erhalten, die Sie zur Verwendung von BigQuery-Daten-Canvas benötigen:
-
BigQuery Studio User (
roles/bigquery.studioUser) -
Gemini for Google Cloud User (
roles/cloudaicompanion.user)
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Sie können die erforderlichen Berechtigungen auch über benutzerdefinierte Rollen oder andere vordefinierte Rollen erhalten.
Weitere Informationen zu IAM-Rollen und Berechtigungen in BigQuery finden Sie unter Einführung in IAM.
Wenn Sie Metadaten für Daten-Canvas in Dataplex Universal Catalog verwalten möchten, benötigen Sie die erforderlichen Dataplex Universal Catalog-Rollen und die Berechtigung dataform.repositories.get.
Knotentypen
Eine Arbeitsfläche ist eine Sammlung von einem oder mehreren Knoten. Knoten können in beliebiger Reihenfolge verbunden werden. Für BigQuery-Daten-Canvas sind die folgenden Knotentypen verfügbar:
- Text
- Suchen
- Tabelle
- SQL
- Zielknoten
- Visualisierung
- Statistiken
Textknoten
Mit einem Textknoten in BigQuery-Daten-Canvas können Sie Rich-Text-Inhalte in Ihr Canvas einfügen. Sie können damit Erklärungen, Notizen oder Anleitungen in Ihr Arbeitsfeld einfügen, um den Kontext und Zweck Ihrer Analyse für sich und andere besser verständlich zu machen. Sie können beliebige Textinhalte in den Textknoten-Editor eingeben, einschließlich Markdown zur Formatierung. So können Sie visuell ansprechende und informative Textblöcke erstellen.
Über den Textknoten haben Sie folgende Möglichkeiten:
- Löschen Sie den Knoten.
- Fehlerbehebung für den Knoten
- Duplizieren Sie den Knoten.
Suchknoten
Mit einem Suchknoten im BigQuery-Daten-Canvas können Sie Daten-Assets finden und in Ihren Canvas einfügen. Sie dient als Brücke zwischen Ihren Abfragen in natürlicher Sprache oder Keyword-Suchen und den tatsächlichen Daten, mit denen Sie arbeiten möchten.
Sie geben eine Suchanfrage ein, entweder in natürlicher Sprache oder mit Suchbegriffen. Der Suchknoten durchsucht Ihre Datenassets. Dabei werden Dataplex Universal Catalog-Metadaten für einen besseren Kontext verwendet. Im BigQuery-Daten-Canvas werden auch zuletzt verwendete Tabellen, Abfragen und gespeicherte Abfragen vorgeschlagen.
Der Suchknoten gibt eine Liste relevanter Daten-Assets zurück, die Ihrer Anfrage entsprechen. Dabei werden Spaltennamen und Tabellenbeschreibungen berücksichtigt. Anschließend können Sie die Assets auswählen, die Sie Ihrem Daten-Canvas als Tabellenknoten hinzufügen möchten. Dort können Sie die Daten weiter analysieren und visualisieren.
Über den Suchknoten haben Sie folgende Möglichkeiten:
- Löschen Sie den Knoten.
- Fehlerbehebung für den Knoten
- Duplizieren Sie den Knoten.
Tabellenknoten
In BigQuery-Daten-Canvas stellt ein Tabellenknoten eine bestimmte Tabelle dar, die Sie in Ihren Analyseworkflow eingebunden haben. Sie stellt die Daten dar, mit denen Sie arbeiten, und ermöglicht Ihnen, direkt mit ihnen zu interagieren.
In einem Tabellenknoten werden Informationen zur Tabelle angezeigt, z. B. Name, Schema und eine Vorschau der Daten. Sie können mit der Tabelle interagieren, indem Sie sich Details wie das Tabellenschema, die Tabellendetails und eine Tabellenvorschau ansehen.
Über den Tabellenknoten haben Sie folgende Möglichkeiten:
- Löschen Sie den Knoten.
- Fehlerbehebung für den Knoten
- Duplizieren Sie den Knoten.
- Führen Sie den Knoten aus.
- Führen Sie den Knoten und den folgenden Knoten aus.
Im Datenbereich haben Sie folgende Möglichkeiten:
- Fragen Sie die Ergebnisse in einem neuen SQL-Knoten ab.
- Führen Sie die Ergebnisse mit einer anderen Tabelle zusammen.
SQL-Knoten
Mit einem SQL-Knoten in BigQuery Data Canvas können Sie benutzerdefinierte SQL-Abfragen direkt in Ihrem Canvas ausführen. Sie können SQL-Code entweder direkt im SQL-Node-Editor schreiben oder einen Prompt in natürlicher Sprache verwenden, um den SQL-Code zu generieren.
Im SQL-Knoten wird die angegebene SQL-Abfrage für die angegebenen Datenquellen ausgeführt. Der SQL-Knoten erzeugt eine Ergebnistabelle, die dann zur weiteren Analyse oder Visualisierung mit anderen Knoten im Arbeitsbereich verbunden werden kann. Die Ausgaben aus der Ausführung eines SQL-Knotens, das sogenannte Abfrageergebnis, können auch über einen Zielknoten in einer eigenen Tabelle gespeichert werden.
Nachdem die Abfrage ausgeführt wurde, können Sie sie als geplante Abfrage exportieren, die Abfrageergebnisse exportieren oder die Arbeitsfläche freigeben, ähnlich wie beim Ausführen einer interaktiven Abfrage.
Über den SQL-Knoten haben Sie folgende Möglichkeiten:
- Exportieren Sie die SQL-Anweisung als geplante Abfrage.
- Löschen Sie den Knoten.
- Fehlerbehebung für den Knoten
- Duplizieren Sie den Knoten.
- Führen Sie den Knoten aus.
- Führen Sie den Knoten und den folgenden Knoten aus.
Im Datenbereich haben Sie folgende Möglichkeiten:
- Fragen Sie die Ergebnisse in einem neuen SQL-Knoten ab.
- Speichern Sie die Ergebnisse in einer Tabelle.
- Visualisieren Sie die Ergebnisse in einem Visualisierungsknoten.
- Statistiken zu den Ergebnissen in einem Statistikknoten generieren
- Führen Sie die Ergebnisse mit einer anderen Tabelle zusammen.
Zielknoten
In BigQuery-Daten-Canvas ist ein Zielknoten ein untergeordneter Knoten eines SQL-Knotens, in dem das Ergebnis einer SQL-Ausführung in einer dedizierten Tabelle gespeichert wird. Sie können die Tabelle in einem neuen oder vorhandenen Dataset oder als neue oder vorhandene Tabelle in einem Dataset speichern. Nachdem Sie eine Zieltabelle erstellt haben, können Sie mit der SQL-Schaltfläche dafür sorgen, dass die Tabelle in Echtzeit aktualisiert wird, wenn der übergeordnete SQL-Knoten noch einmal ausgeführt wird.
Ein Zielknoten kann zu einem Tabellenknoten werden, wenn er von seinem übergeordneten Knoten getrennt wird und der Inhalt der Tabelle nicht von Änderungen im übergeordneten SQL-Knoten beeinflusst wird.
Über den Zielknoten haben Sie folgende Möglichkeiten:
- Trennen Sie den Knoten vom übergeordneten Knoten, um ihn zu einem eigenständigen Tabellenknoten zu machen.
- Die Tabelle in einem neuen SQL-Knoten abfragen.
- Führen Sie die Ergebnisse mit einer anderen Tabelle zusammen.
Visualisierungsknoten
Mit einem Visualisierungsknoten in BigQuery Data Canvas können Sie Daten visuell darstellen, um Trends, Muster und Statistiken besser zu verstehen. Sie bietet eine Vielzahl von Diagrammtypen, aus denen Sie die beste Visualisierung für Ihre Daten auswählen und anpassen können.
Ein Visualisierungsknoten verwendet eine Tabelle als Eingabe. Diese kann das Ergebnis einer SQL-Abfrage oder eines Tabellenknotens sein. Anhand des ausgewählten Diagrammtyps und der Daten in der Eingabetabelle wird im Visualisierungsknoten ein Diagramm generiert. Sie können Auto-Chart auswählen, damit BigQuery den besten Diagrammtyp für Ihre Daten auswählt. Im Visualisierungsknoten wird dann das generierte Diagramm angezeigt.
Mit dem Visualisierungsknoten können Sie Ihr Diagramm anpassen, z. B. Farben, Labels und Datenquellen ändern. Sie können das Diagramm auch als PNG-Datei exportieren.
Sie können Daten mit den folgenden Grafiktypen visualisieren:
- Balkendiagramm
- Heatmap
- Liniendiagramm
- Kreisdiagramm
- Streudiagramm
Im Visualisierungsknoten haben Sie folgende Möglichkeiten:
- Exportieren Sie das Diagramm als PNG-Datei.
- Fehlerbehebung für den Knoten
- Duplizieren Sie den Knoten.
- Führen Sie den Knoten aus.
- Führen Sie den Knoten und den folgenden Knoten aus.
Im Datenbereich haben Sie folgende Möglichkeiten:
- Statistiken zu den Ergebnissen in einem Statistikknoten generieren
- Bearbeiten Sie die Visualisierung.
Statistikknoten
Mit einem Insights-Knoten im BigQuery-Daten-Canvas können Sie Erkenntnisse und Zusammenfassungen aus den Daten in Ihrem Daten-Canvas generieren. So können Sie Muster erkennen, die Datenqualität bewerten und statistische Analysen auf dem Arbeitsbereich ausführen. Es werden Trends, Muster, Anomalien und Korrelationen in Ihren Daten identifiziert und prägnante und übersichtliche Zusammenfassungen der Ergebnisse der Datenanalyse erstellt.
Weitere Informationen zu Data Insights finden Sie unter Data Insights in BigQuery generieren.
Über den Knoten „Statistiken“ haben Sie folgende Möglichkeiten:
- Löschen Sie den Knoten.
- Duplizieren Sie den Knoten.
- Führen Sie den Knoten aus.
BigQuery-Daten-Canvas verwenden
Sie können BigQuery Data Canvas in der Google Cloud Konsole, in einer Abfrage oder in einer Tabelle verwenden.
Rufen Sie die Seite BigQuery auf.
Klicken Sie im Abfrageeditor neben SQL-Abfrage auf Neu erstellen und dann auf Daten-Canvas.
Geben Sie im Promptfeld Natürliche Sprache einen Prompt in natürlicher Sprache ein.
Wenn Sie beispielsweise
Find me tables related to treeseingeben, gibt BigQuery-Daten-Canvas eine Liste möglicher Tabellen zurück, einschließlich öffentlicher Datasets wiebigquery-public-data.usfs_fia.plot_treeoderbigquery-public-data.new_york_trees.tree_species.Wählen Sie eine Tabelle aus.
Dem BigQuery-Daten-Canvas wird ein Tabellenknoten für die ausgewählte Tabelle hinzugefügt. Wenn Sie sich Schemainformationen, Tabellendetails oder eine Datenvorschau ansehen möchten, wählen Sie die verschiedenen Tabs im Tabellenknoten aus.
Optional: Nachdem Sie den Datenbereich gespeichert haben, können Sie mit der folgenden Symbolleiste Details zum Datenbereich oder den Versionsverlauf aufrufen, neue Kommentare hinzufügen oder auf einen vorhandenen Kommentar antworten oder einen Link dazu abrufen:
Die Symbolleistenfunktionen Details, Versionsverlauf und Kommentare sind in der Vorabversion verfügbar. Wenn Sie Feedback geben oder Support für diese Funktionen anfordern möchten, senden Sie eine E-Mail an bqui-workspace-pod@google.com.
Die folgenden Beispiele veranschaulichen verschiedene Möglichkeiten, den BigQuery-Daten-Canvas in Analyseworkflows zu verwenden.
Beispiel für einen Workflow: Daten suchen, abfragen und visualisieren
In diesem Beispiel verwenden Sie Prompts in natürlicher Sprache im BigQuery-Daten-Canvas, um Daten zu finden, eine Abfrage zu generieren und die Abfrage zu bearbeiten. Anschließend erstellen Sie ein Diagramm.
Prompt 1: Daten finden
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie im Abfrageeditor neben SQL-Abfrage auf Neu erstellen und dann auf Daten-Canvas.
Klicken Sie auf Daten suchen.
Klicken Sie auf filter_list Suchfilter bearbeiten und dann im Bereich Suche filtern auf die Ein/Aus-Schaltfläche Öffentliche BigQuery-Datasets, um sie zu aktivieren.
Geben Sie im Feld Natural Language Prompt den folgenden Natural Language Prompt ein:
Chicago taxi tripsDer BigQuery-Daten-Canvas generiert eine Liste potenzieller Tabellen anhand von Dataplex Universal Catalog-Metadaten. Sie können mehrere Tabellen auswählen.
Wählen Sie die Tabelle
bigquery-public-data.chicago_taxi_trips.taxi_tripsaus und klicken Sie dann auf Dem Arbeitsbereich hinzufügen.Dem BigQuery-Daten-Canvas wird ein Tabellenknoten für
taxi_tripshinzugefügt. Wenn Sie sich Schemainformationen, Tabellendetails oder eine Datenvorschau ansehen möchten, wählen Sie die verschiedenen Tabs im Tabellenknoten aus.
Prompt 2: SQL-Abfrage in der ausgewählten Tabelle generieren
Um eine SQL-Abfrage für den
bigquery-public-data.chicago_taxi_trips.taxi_trips zu erstellen, gehen Sie so vor:
Klicken Sie im Daten-Canvas auf Abfrage.
Geben Sie im Prompt-Feld Natürliche Sprache Folgendes ein:
Get me the 100 longest tripsDas BigQuery-Daten-Canvas generiert eine SQL-Abfrage, die etwa so aussieht:
SELECT taxi_id, trip_start_timestamp, trip_end_timestamp, trip_miles FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` ORDER BY trip_miles DESC LIMIT 100;
Prompt 3: Abfrage bearbeiten
Wenn Sie die generierte Abfrage bearbeiten möchten, können Sie sie manuell anpassen oder die Eingabeaufforderung in natürlicher Sprache ändern und die Abfrage neu generieren. In diesem Beispiel verwenden Sie einen Prompt in natürlicher Sprache, um die Abfrage so zu bearbeiten, dass nur Fahrten ausgewählt werden, bei denen der Kunde bar bezahlt hat.
Geben Sie im Prompt-Feld Natürliche Sprache Folgendes ein:
Get me the 100 longest trips where the payment type is cashDas BigQuery-Daten-Canvas generiert eine SQL-Abfrage, die etwa so aussieht:
SELECT taxi_id, trip_start_timestamp, trip_end_timestamp, trip_miles FROM `PROJECT_ID.chicago_taxi_trips_123123.taxi_trips` WHERE payment_type = 'Cash' ORDER BY trip_miles DESC LIMIT 100;
Im vorherigen Beispiel ist
PROJECT_IDdie ID Ihres Google Cloud Projekts.Klicken Sie auf Ausführen, um die Ergebnisse der Abfrage aufzurufen.
Diagramme erstellen
- Klicken Sie im Daten-Canvas auf Visualisieren.
Klicken Sie auf Balkendiagramm erstellen.
Der BigQuery-Daten-Canvas erstellt ein Balkendiagramm, das die Fahrten mit den meisten gefahrenen Kilometer nach Fahrt-ID anzeigt. Neben einem Diagramm fasst BigQuery Data Canvas einige der wichtigsten Details der Daten zusammen, die der Visualisierung zugrunde liegen.
Optional: Führen Sie einen oder mehrere der folgenden Schritte aus:
- Klicken Sie zum Ändern des Diagramms auf Bearbeiten und bearbeiten Sie dann das Diagramm im Bereich Visualisierung bearbeiten.
- Wenn Sie das Daten-Canvas freigeben möchten, klicken Sie auf Freigeben und dann auf Link freigeben, um den BigQuery-Daten-Canvas-Link zu kopieren.
- Wählen Sie zum Bereinigen des Daten-Canvas Weitere Aktionen und dann Canvas löschen aus. In diesem Schritt wird ein leerer Canvas erstellt.
Beispielworkflow: Tabellen zusammenführen
In diesem Beispiel verwenden Sie Prompts in natürlicher Sprache im BigQuery-Daten-Canvas, um Daten zu finden und Tabellen zu verknüpfen. Anschließend exportieren Sie eine Abfrage als Notebook.
Prompt 1: Daten finden
Geben Sie im Feld für Natural Language Prompts Natural Language den folgenden Prompt ein:
Information about treesIm BigQuery-Daten-Canvas werden mehrere Tabellen mit Informationen zu Bäumen vorgeschlagen.
Wählen Sie in diesem Beispiel die Tabelle
bigquery-public-data.new_york_trees.tree_census_1995aus und klicken Sie dann auf Dem Arbeitsbereich hinzufügen.Die Tabelle wird auf dem Canvas angezeigt.
Prompt 2: Tabellen unter ihrer Adresse zusammenführen
Klicken Sie im Daten-Canvas auf Verknüpfen.
BigQuery-Daten-Canvas schlägt Tabellen vor, die zusammengeführt werden könnten.
Wenn Sie ein neues Promptfeld für Natürliche Sprache öffnen möchten, klicken Sie auf Nach Tabellen suchen.
Geben Sie im Feld für Natural Language Prompts Natural Language den folgenden Prompt ein:
Information about treesWählen Sie die Tabelle
bigquery-public-data.new_york_trees.tree_census_2005aus und klicken Sie dann auf Auf Arbeitsbereich einfügen.Die Tabelle wird auf dem Canvas angezeigt.
Klicken Sie im Daten-Canvas auf Verknüpfen.
Wählen Sie im Bereich Auf diesem Arbeitsbereich das Kästchen Tabellenzelle aus und klicken Sie dann auf OK.
Geben Sie im Feld für Natural Language Prompts Natural Language den folgenden Prompt ein:
Join on addressBigQuery-Daten-Canvas schlägt eine SQL-Abfrage vor, um diese beiden Tabellen anhand ihrer Adresse zusammenzuführen.
SELECT * FROM `bigquery-public-data.new_york_trees.tree_census_2015` AS t2015 JOIN `bigquery-public-data.new_york_trees.tree_census_1995` AS t1995 ON t2015.address = t1995.address;
Klicken Sie auf Ausführen, um die Abfrage auszuführen und die Ergebnisse anzusehen.
Abfrage als Notebook exportieren
Mit BigQuery-Daten-Canvas können Sie Ihre Abfragen als Notebook exportieren.
- Klicken Sie im Daten-Canvas auf Als Notebook exportieren.
- Geben Sie im Bereich Notebook speichern den Namen des Notebooks und die Region ein, in der Sie es speichern möchten.
- Klicken Sie auf Speichern. Das Notebook wird erstellt.
- Optional: Klicken Sie auf Öffnen, um das erstellte Notebook aufzurufen.
Beispielworkflow: Diagramm mit einem Prompt bearbeiten
In diesem Beispiel verwenden Sie Prompts in natürlicher Sprache im BigQuery-Daten-Canvas, um Daten zu suchen, abzufragen und zu filtern und dann Visualisierungsdetails zu bearbeiten.
Prompt 1: Daten finden
Wenn Sie Daten zu US-Namen abrufen möchten, geben Sie den folgenden Prompt ein:
Find data about USA namesMit dem BigQuery-Daten-Canvas wird eine Liste von Tabellen generiert.
Wählen Sie in diesem Beispiel die Tabelle
bigquery-public-data.usa_names.usa_1910_currentaus und klicken Sie auf Dem Arbeitsbereich hinzufügen.
Prompt 2: Daten abfragen
Klicken Sie im Daten-Canvas auf Abfrage und geben Sie dann den folgenden Prompt ein, um die Daten abzufragen:
Summarize this dataDas BigQuery-Daten-Canvas generiert eine Abfrage, die etwa so aussieht:
SELECT state, gender, year, name, number FROM `bigquery-public-data.usa_names.usa_1910_current`
Klicken Sie auf Ausführen. Die Abfrageergebnisse werden angezeigt.
Prompt 3: Daten filtern
- Klicken Sie im Daten-Canvas auf Diese Ergebnisse abfragen.
Geben Sie zum Filtern der Daten im Promptfeld SQL den folgenden Prompt ein:
Get me the top 10 most popular names in 1980Das BigQuery-Daten-Canvas generiert eine Abfrage, die etwa so aussieht:
SELECT name, SUM(number) AS total_count FROM `bigquery-public-data`.usa_names.usa_1910_current WHERE year = 1980 GROUP BY name ORDER BY total_count DESC LIMIT 10;
Wenn Sie die Abfrage ausführen, erhalten Sie eine Tabelle mit den zehn häufigsten Namen von Kindern, die 1980 geboren wurden.
Diagramm erstellen und bearbeiten
Klicken Sie im Daten-Canvas auf Visualisieren.
Im BigQuery-Daten-Canvas werden verschiedene Visualisierungsoptionen vorgeschlagen (Balkendiagramm, Kreisdiagramm, Liniendiagramm, benutzerdefinierte Visualisierung usw.).
Klicken Sie in diesem Beispiel auf Balkendiagramm erstellen.
Das BigQuery-Daten-Canvas erstellt ein Balkendiagramm, das etwa so aussieht:
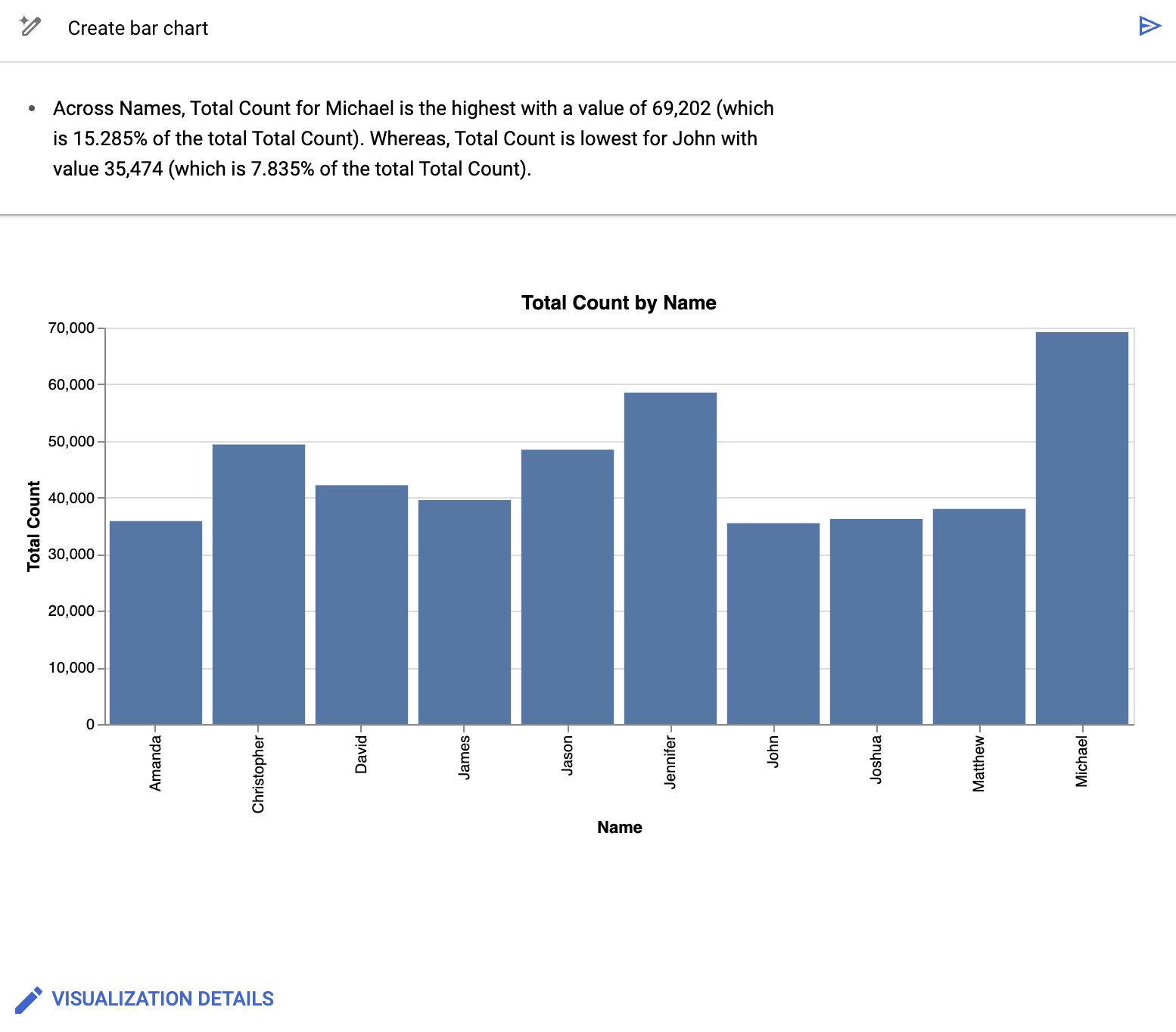
Neben einem Diagramm fasst der Daten-Canvas von BigQuery einige der wichtigsten Details der Daten zusammen, die der Visualisierung zugrunde liegen. Um das Diagramm anzupassen, klicken Sie auf Visualisierungsdetails und bearbeiten das Diagramm in der Seitenleiste.
Prompt 4: Visualisierungsdetails bearbeiten
Geben Sie im Prompt-Feld Visualisierung Folgendes ein:
Create a bar chart sorted high to low, with a gradientDas BigQuery-Daten-Canvas erstellt ein Balkendiagramm, das etwa so aussieht:
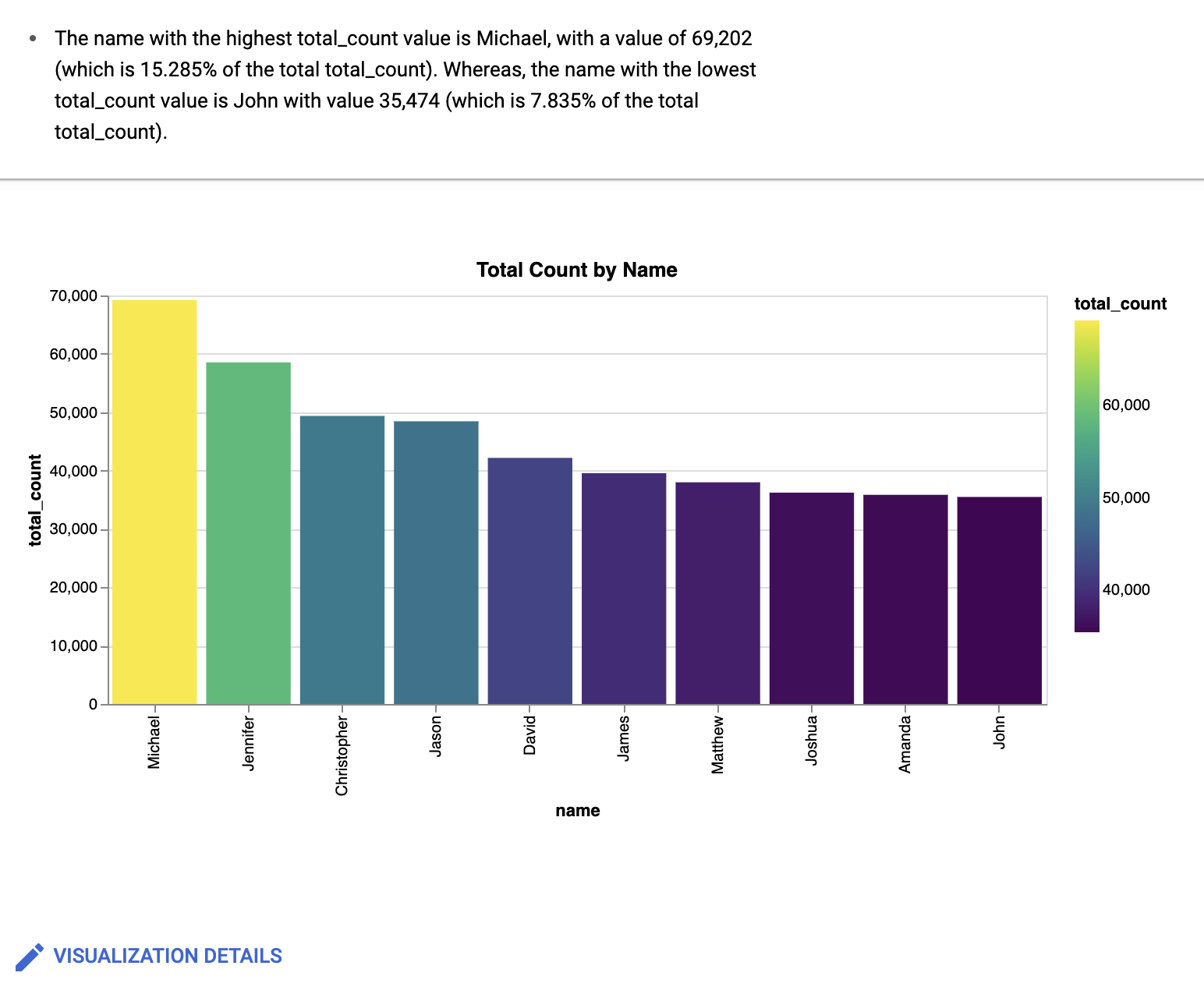
Optional: Wenn Sie weitere Änderungen vornehmen möchten, klicken Sie auf Bearbeiten.
Der Bereich Visualisierung bearbeiten wird angezeigt. Sie können Details wie den Diagrammtitel, den Namen der X-Achse und den Namen der Y-Achse bearbeiten. Wenn Sie auf den Tab JSON-Editor klicken, können Sie das Diagramm außerdem basierend auf den JSON-Werten direkt bearbeiten.
Mit einem Gemini-Assistenten arbeiten
Sie können mit einem auf Gemini basierenden Chat Daten-Canvas in BigQuery verwenden. Der Chat-Assistent kann Knoten basierend auf Ihren Anfragen erstellen, Abfragen ausführen und Visualisierungen erstellen. Sie können Tabellen auswählen, mit denen der Assistent arbeiten soll, und Anweisungen hinzufügen, um sein Verhalten zu steuern. Der Assistent funktioniert mit neuen oder vorhandenen Daten-Canvas.
So arbeiten Sie mit dem Gemini-Assistenten:
- Klicken Sie zum Öffnen des Assistenten im Daten-Canvas auf spark Data Canvas-Assistenten öffnen.
Geben Sie im Feld Frage zu Daten stellen einen Prompt in natürlicher Sprache ein, z. B. einen der folgenden:
Show me interesting statistics of my data.Make a chart based on my data, sorted high to low.I want to see sample data from my table.
Die Antwort enthält einen oder mehrere Knoten, die auf der Anfrage basieren. Wenn Sie den Assistenten beispielsweise bitten, ein Diagramm Ihrer Daten zu erstellen, wird ein Visualisierungsknoten auf dem Daten-Canvas erstellt.
Wenn Sie auf das Feld Eine Frage zu Daten stellen klicken, haben Sie auch folgende Möglichkeiten:
- Klicken Sie auf Einstellungen, um Daten hinzuzufügen.
- Klicken Sie auf Einstellungen, um Anweisungen hinzuzufügen.
Wenn Sie weiter mit dem Assistenten arbeiten möchten, fügen Sie zusätzliche Prompts in natürlicher Sprache hinzu.
Sie können weiterhin Prompts in natürlicher Sprache eingeben, während Sie mit dem Daten-Canvas arbeiten.
Daten hinzufügen
Wenn Sie mit der Gemini-Chatoberfläche arbeiten, können Sie Daten hinzufügen, damit der Assistent weiß, auf welches Dataset er sich beziehen soll. Der Assistent fordert Sie auf, eine Tabelle auszuwählen, bevor Sie Prompts ausführen. Wenn Sie im Assistenten nach Daten suchen, können Sie den Umfang der durchsuchbaren Daten auf alle Projekte, markierte Projekte oder Ihr aktuelles Projekt beschränken. Sie können auch festlegen, ob öffentliche Datasets in Ihre Suche einbezogen werden sollen.
So fügen Sie dem Gemini-Assistenten Daten hinzu:
- Klicken Sie zum Öffnen des Assistenten im Daten-Canvas auf spark Data Canvas-Assistenten öffnen.
- Klicken Sie auf Einstellungen und dann auf Daten hinzufügen.
- Optional: Wenn Sie die Suchergebnisse auf öffentliche Datasets ausweiten möchten, klicken Sie auf die Ein/Aus-Schaltfläche Öffentliche Datasets, um sie zu aktivieren.
- Optional: Wenn Sie den Bereich der Suchergebnisse auf andere Projekte ändern möchten, wählen Sie im Menü Bereich die entsprechende Projektoption aus.
- Klicken Sie das Kästchen für jede Tabelle an, die Sie dem Assistenten hinzufügen möchten.
- Wenn Sie nach Tabellen suchen möchten, die nicht vom Assistenten vorgeschlagen werden, klicken Sie auf Nach Tabellen suchen.
- Geben Sie im Prompt-Feld Natürliche Sprache einen Prompt ein, der die gesuchte Tabelle beschreibt, und drücken Sie dann die Eingabetaste.
- Klicken Sie das Kästchen für jede Tabelle an, die Sie dem Assistenten hinzufügen möchten, und klicken Sie dann auf Ok.
- Schließen Sie den Bereich Einstellungen für Canvas-Assistenten.
Der Assistent stützt seine Analyse auf die von Ihnen ausgewählten Daten.
Anleitung hinzufügen
Wenn Sie mit der Gemini-Chat-Oberfläche arbeiten, können Sie Anweisungen hinzufügen, damit der Assistent weiß, wie er sich verhalten soll. Diese Anweisungen werden auf alle Prompts im Datenbereich angewendet. Beispiele für mögliche Anweisungen:
Visualize trends over time.Chart colors: Red (negative), Green (positive)Domain: USA
So fügen Sie dem Assistenten Anweisungen hinzu:
- Klicken Sie zum Öffnen des Assistenten im Daten-Canvas auf spark Data Canvas-Assistenten öffnen.
- Klicken Sie auf Einstellungen.
- Fügen Sie im Feld Anleitung eine Liste mit Anweisungen für den Assistenten hinzu und schließen Sie dann den Bereich Canvas-Assistenteneinstellungen.
Der Assistent merkt sich die Anweisungen und wendet sie auf zukünftige Prompts an.
Best Practices für Gemini Assistant
Wenn Sie mit dem Assistenten für den BigQuery-Daten-Canvas arbeiten, sollten Sie die folgenden Best Practices beachten, um optimale Ergebnisse zu erzielen:
Seien Sie spezifisch und eindeutig. Geben Sie klar an, was Sie berechnen, analysieren oder visualisieren möchten. Sagen Sie beispielsweise
Calculate the average trip duration for trips starting in council district eightanstelle vonAnalyze trip data.Für einen genauen Datenkontext sorgen: Der Assistent kann nur mit den Daten arbeiten, die Sie bereitstellen. Achten Sie darauf, dass alle relevanten Tabellen und Spalten dem Arbeitsbereich hinzugefügt wurden.
Einfach anfangen und dann iterieren: Beginnen Sie mit einer einfachen Frage, damit der Assistent die grundlegende Struktur und die Daten versteht. Sagen Sie zum Beispiel zuerst
Show total trips byund dannsubscriber_typeShow total trips by.subscriber_typeand break down the result bycouncil_districtKomplexe Fragen aufschlüsseln: Bei mehrstufigen Prozessen sollten Sie Ihren Prompt klar und in einzelne Abschnitte unterteilt formulieren oder für jeden wichtigen Schritt einen separaten Prompt verwenden. Geben Sie beispielsweise
First, find the top five busiest stations by trip count. Second, calculate the average trip duration for trips starting from only those top five stationsein.Berechnungen deutlich angeben: Geben Sie die ausgewählte Berechnung an, z. B.
SUM,MAXoderAVERAGE. Geben Sie beispielsweiseFind theein.MAXtrip duration perbike_idSystemanweisungen für persistenten Kontext und Einstellungen verwenden Verwenden Sie Systemanweisungen, um Informationsregeln und Einstellungen anzugeben, die für alle Prompts gelten.
Canvas ansehen Überprüfen Sie immer die generierten Knoten, um sicherzustellen, dass die Logik mit Ihrer Anfrage übereinstimmt und die Ergebnisse korrekt sind.
Test Probieren Sie verschiedene Formulierungen, Detaillierungsgrade und Prompt-Strukturen aus, um zu sehen, wie der Assistent auf Ihre spezifischen Daten und Analyseanforderungen reagiert.
Auf Spaltennamen verweisen: Verwenden Sie nach Möglichkeit die tatsächlichen Spaltennamen aus den ausgewählten Daten. Sagen Sie beispielsweise
Show the count of trips grouped byanstelle vonsubscriber_typeandstart_station_nameShow trips by subscriber type.
Beispielworkflow: Mit einem Gemini-Assistenten arbeiten
In diesem Beispiel verwenden Sie Prompts in natürlicher Sprache mit dem Gemini-Assistenten, um Daten zu finden, abzufragen und zu visualisieren.
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie im Abfrageeditor neben SQL-Abfrage auf Neu erstellen und dann auf Daten-Canvas.
Klicken Sie auf Daten suchen.
Klicken Sie auf filter_list Suchfilter bearbeiten und dann im Bereich Suche filtern auf die Ein/Aus-Schaltfläche Öffentliche BigQuery-Datasets, um sie zu aktivieren.
Geben Sie im Feld Natural Language Prompt den folgenden Natural Language Prompt ein:
bikeshareDer BigQuery-Daten-Canvas generiert eine Liste potenzieller Tabellen anhand von Dataplex Universal Catalog-Metadaten. Sie können mehrere Tabellen auswählen.
Wählen Sie die Tabelle
bigquery-public-data.austin_bikeshare.bikeshare_stationsundbigquery-public-data.austin_bikeshare.bikeshare_tripsaus und klicken Sie dann auf Dem Arbeitsbereich hinzufügen.Für jede der ausgewählten Tabellen wird dem BigQuery-Daten-Canvas ein Tabellenknoten hinzugefügt. Wenn Sie sich Schemainformationen, Tabellendetails oder eine Datenvorschau ansehen möchten, wählen Sie die verschiedenen Tabs im Tabellenknoten aus.
Klicken Sie zum Öffnen des Assistenten im Daten-Canvas auf spark Data Canvas-Assistenten öffnen.
Klicken Sie auf Einstellungen.
Fügen Sie dem Feld Anleitung die folgenden Anweisungen für den Assistenten hinzu:
Tasks: - Visualize findings with charts - Show many charts per question - Make sure to cover each part via a separate line of reasoningSchließen Sie den Bereich Einstellungen für Canvas-Assistenten.
Geben Sie im Feld Frage zu Daten stellen den folgenden Prompt in natürlicher Sprache ein:
Show the number of trips by council district and subscriber typeSie können weiterhin Prompts in das Feld Eine Frage zu Daten stellen eingeben. Geben Sie den folgenden Natural Language Prompt ein:
What are most popular stations among the top 5 subscriber typesGeben Sie den endgültigen Prompt ein:
What station is least used to start and end a tripNachdem Sie alle relevanten Prompts eingegeben haben, wird der Arbeitsbereich mit den entsprechenden Knoten für Abfragen und Visualisierungen gefüllt, die auf den Prompts und Anweisungen basieren, die Sie dem Assistenten gegeben haben. Geben Sie weitere Prompts ein oder ändern Sie vorhandene Prompts, um die gewünschten Ergebnisse zu erhalten.
Alle Data Canvases ansehen
So rufen Sie eine Liste aller Daten-Canvas in Ihrem Projekt auf:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie im Bereich Explorer neben Daten-Canvasse auf Aktionen ansehen und führen Sie einen der folgenden Schritte aus:
- Wenn Sie die Liste im aktuellen Tab öffnen möchten, klicken Sie auf Alle anzeigen.
- Wenn Sie die Liste in einem neuen Tab öffnen möchten, klicken Sie auf Alle anzeigen in > Neuer Tab.
- Wenn Sie die Liste in einem geteilten Tab öffnen möchten, klicken Sie auf Alle anzeigen in > Tab aufteilen.
Metadaten von Data Canvas ansehen
So rufen Sie die Metadaten des Datenbereichs auf:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Maximieren Sie im Bereich Explorer Ihr Projekt und den Ordner Data Canvas und gegebenenfalls den Ordner Freigegebene Data Canvas. Klicken Sie auf den Namen des Daten-Canvas, für den Sie Metadaten aufrufen möchten.
Im Bereich Zusammenfassung finden Sie Informationen zum Daten-Canvas, z. B. die verwendete Region und das Datum der letzten Änderung.
Mit Data Canvas-Versionen arbeiten
Sie können einen Data Canvas entweder innerhalb oder außerhalb eines Repositorys erstellen. Die Versionsverwaltung von Data Canvas wird je nach Speicherort des Data Canvas unterschiedlich gehandhabt.
Versionsverwaltung von Data Canvas in Repositories
Repositories sind Git-Repositories, die sich entweder in BigQuery oder bei einem Drittanbieter befinden. Sie können Arbeitsbereiche in Repositorys verwenden, um die Versionskontrolle für Daten-Canvas durchzuführen. Weitere Informationen finden Sie unter Versionsverwaltung für eine Datei verwenden.
Versionsverwaltung von Data Canvas außerhalb von Repositories
Sie können Versionen eines Daten-Canvas aufrufen, vergleichen und wiederherstellen.
Daten-Canvas-Versionen ansehen und vergleichen
So rufen Sie verschiedene Versionen eines Daten-Canvas auf und vergleichen sie mit der aktuellen Version:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Maximieren Sie im Bereich Explorer Ihr Projekt und den Ordner Data Canvas und gegebenenfalls den Ordner Freigegebene Data Canvas. Klicken Sie auf den Namen des Daten-Canvas, für den Sie Aktivitäten aufrufen möchten.
Klicken Sie auf Versionsverlauf, um eine Liste der Data Canvas-Versionen in absteigender Reihenfolge nach Datum aufzurufen.
Klicken Sie neben einer Version des Daten-Canvas auf Aktionen ansehen und dann auf Vergleichen. Der Vergleichsbereich wird geöffnet und die ausgewählte Daten-Canvas-Version wird mit der aktuellen Daten-Canvas-Version verglichen.
Optional: Wenn Sie die Versionen inline und nicht in separaten Bereichen vergleichen möchten, klicken Sie auf Vergleichen und dann auf Inline.
Daten-Canvas-Version wiederherstellen
Wenn Sie über den Vergleichsbereich wiederherstellen, können Sie die vorherige Version des Daten-Canvas mit der aktuellen Version vergleichen, bevor Sie die Wiederherstellung bestätigen.
- Maximieren Sie im Bereich Explorer Ihr Projekt und den Ordner Data Canvas und gegebenenfalls den Ordner Freigegebene Data Canvas. Klicken Sie auf den Namen des Daten-Canvas, von dem Sie eine vorherige Version wiederherstellen möchten.
- Klicken Sie auf Versionsverlauf.
Klicken Sie neben der Version des Daten-Canvas, die Sie wiederherstellen möchten, auf Aktionen ansehen und dann auf Vergleichen.
Der Vergleichsbereich wird geöffnet und die ausgewählte Version des Datenbereichs wird mit der neuesten Version des Datenbereichs verglichen.
Wenn Sie nach dem Vergleich die vorherige Version des Datenbereichs wiederherstellen möchten, klicken Sie auf Wiederherstellen.
Klicken Sie auf Bestätigen.
Metadaten in Dataplex Universal Catalog verwalten
Mit Dataplex Universal Catalog können Sie Metadaten für Datenbereiche ansehen und verwalten. Data Canvas sind standardmäßig in Dataplex Universal Catalog verfügbar, ohne dass eine zusätzliche Konfiguration erforderlich ist.
Mit Dataplex Universal Catalog können Sie Daten-Canvas an allen BigQuery-Standorten verwalten. Die Verwaltung von Daten-Canvas in Dataplex Universal Catalog unterliegt den Kontingenten und Limits für Dataplex Universal Catalog und der Preisgestaltung für Dataplex Universal Catalog.
Dataplex Universal Catalog ruft automatisch die folgenden Metadaten aus Datenbereichen ab:
- Name des Datenassets
- Übergeordnetes Data Asset
- Speicherort des Daten-Assets
- Datentyp-Asset
- Entsprechendes Google Cloud Projekt
Im Dataplex Universal Catalog werden Daten-Canvas als Einträge mit den folgenden Eintragswerten protokolliert:
- Systemeintragsgruppe
- Die Systemeintragsgruppe für Daten-Canvas ist
@dataform. Wenn Sie Details zu Data Canvas-Einträgen im Dataplex Universal Catalog aufrufen möchten, müssen Sie die System-Eintragsgruppedataformaufrufen. Eine Anleitung dazu, wie Sie eine Liste aller Einträge in einer Eintragsgruppe aufrufen, finden Sie in der Dataplex Universal Catalog-Dokumentation unter Details einer Eintragsgruppe ansehen. - Systemeintragstyp
- Der Systemeintragstyp für Daten-Canvas ist
dataform-code-asset. Wenn Sie Details zu Daten-Canvas aufrufen möchten, müssen Sie den System-Eintragstypdataform-code-assetaufrufen, die Ergebnisse mit einem aspektbasierten Filter filtern und das Feldtypeim Aspektdataform-code-assetaufDATA_CANVASfestlegen. Wählen Sie dann einen Eintrag des ausgewählten Datenbereichs aus. Eine Anleitung dazu, wie Sie Details zu einem ausgewählten Eintragstyp aufrufen, finden Sie in der Dataplex Universal Catalog-Dokumentation unter Details zu einem Eintragstyp ansehen. Eine Anleitung dazu, wie Sie die Details eines ausgewählten Eintrags aufrufen, finden Sie in der Dataplex Universal Catalog-Dokumentation unter Details eines Eintrags ansehen. - Systemaspekttyp
- Der Systemaspekttyp für Daten-Canvas ist
dataform-code-asset. Wenn Sie Daten-Canvas in Dataplex Universal Catalog zusätzlichen Kontext hinzufügen möchten, indem Sie Daten-Canvas-Einträge mit Aspekten annotieren, rufen Sie den Aspekttypdataform-code-assetauf, filtern Sie die Ergebnisse mit einem aspektbasierten Filter und legen Sie das Feldtypeim Aspektdataform-code-assetaufDATA_CANVASfest. Eine Anleitung zum Annotieren von Einträgen mit Aspekten finden Sie in der Dataplex Universal Catalog-Dokumentation unter Aspekte verwalten und Metadaten anreichern. - Typ
- Der Typ für Daten-Canvas ist
DATA_CANVAS. Mit diesem Typ können Sie Daten-Canvas im Systemeingabetypdataform-code-assetund im Aspekttypdataform-code-assetfiltern, indem Sie die Abfrageaspect:dataplex-types.global.dataform-code-asset.type=DATA_CANVASin einem aspektbasierten Filter verwenden.
Eine Anleitung zum Suchen nach Assets in Dataplex Universal Catalog finden Sie in der Dataplex Universal Catalog-Dokumentation unter Nach Daten-Assets in Dataplex Universal Catalog suchen.
Preise
Weitere Informationen zu den Preisen für diese Funktion finden Sie unter Preisübersicht für Gemini in BigQuery.
Kontingente und Limits
Informationen zu Kontingenten und Limits für diese Funktion finden Sie unter Kontingente für Gemini in BigQuery.
Standorte
Sie können BigQuery Data Canvas an allen BigQuery-Standorten verwenden. Gemini in BigQuery ist global verfügbar. Sie können die Datenverarbeitung daher nicht auf eine bestimmte Region beschränken. Weitere Informationen zu den Standorten, an denen Gemini in BigQuery Daten verarbeitet, finden Sie unter Gemini-Bereitstellungsorte.
Feedback geben
Um dazu beitragen, die Vorschläge im BigQuery-Data Canvas zu verbessern, senden Sie Ihr Feedback an Google. So geben Sie Feedback:
Klicken Sie in der Symbolleiste der Google Cloud Console auf Feedback geben.
Optional: Wenn Sie die DAG-JSON-Informationen kopieren möchten, um Ihrem Feedback zusätzlichen Kontext zu geben, klicken Sie auf Kopieren.
Klicken Sie auf das Formular, um es auszufüllen und Feedback zu geben.
Datenfreigabeeinstellungen gelten für das gesamte Projekt und können nur von einem Projektadministrator mit den IAM-Berechtigungen serviceusage.services.enable und serviceusage.services.list festgelegt werden. Weitere Informationen zur Datennutzung im Trusted Tester-Programm finden Sie unter Gemini im Google Cloud Trusted Tester-Programm.
Wenn Sie direktes Feedback zu diesem Feature geben möchten, können Sie sich auch an datacanvas-feedback@google.com wenden.