이 문서는 Google Cloud의 재해 복구 (DR)를 설명하는 시리즈 중 하나입니다. 이 파트에서는 Google Cloud 를 사용하여 워크로드를 설계하고 클라우드 인프라 서비스 중단에 대해 복원력이 우수한 구성요소를 빌드하는 방법을 설명합니다.
시리즈는 다음과 같이 구성됩니다.
- 재해 복구 계획 가이드
- 재해 복구 구성 요소
- 데이터의 재해 복구 시나리오
- 애플리케이션의 재해 복구 시나리오
- 지역별로 제한된 워크로드의 재해 복구 설계
- 재해 복구 사용 사례: 지역별로 제한된 데이터 분석 애플리케이션
- 클라우드 인프라 서비스 중단의 재해 복구 설계(이 문서)
소개
기업은 워크로드를 퍼블릭 클라우드로 이전할 때 복원력이 우수한 온프레미스 시스템의 빌드를 Google Cloud와 같은 클라우드 제공업체의 하이퍼스케일 인프라로 이해해야 합니다. 이 문서에서는 복구 시간 목표 (RTO)와 복구 지점 목표 (RPO)와 같은 재해 복구에 대한 업계 표준 개념을 Google Cloud인프라에 매핑합니다.
이 문서의 안내에서는 매우 높은 서비스 가용성을 실현하기 위한 Google의 주요 원칙 중 하나인 '장애에 대비한 계획 세우기'를 따릅니다.Google Cloud 는 매우 안정적인 서비스를 제공하지만 자연 재해, 광섬유 절단, 복잡하고 예측 불가능한 인프라 장애 등의 재해는 언제든지 발생할 수 있으며 이러한 재해는 서비스 중단을 야기합니다. 서비스 중단에 대한 계획을 수립한Google Cloud 고객은 '기본 제공' DR 메커니즘을 통해 제품을 사용하여 이러한 불가피한 이벤트가 발생한 상황에서도 예측 가능한 성능을 제공하는 애플리케이션을 빌드할 수 있습니다. Google Cloud
재해 복구에는 소프트웨어 버그나 데이터 손상과 같은 인프라 장애 이상의 광범위한 주제가 포함되므로 포괄적인 엔드 투 엔드 계획을 수립해야 합니다. 그러나 이 문서에서는 전체 DR 계획의 일부인 '클라우드 인프라 중단에 대해 복원력이 우수한 애플리케이션을 설계하는 방법'을 중점적으로 다룹니다. 특히 이 문서에서는 다음을 안내합니다.
- Google Cloud 인프라, 재해 이벤트가Google Cloud 서비스 중단으로 나타나는 방식, 서비스 중단의 빈도와 범위가 최소화되도록 Google Cloud 를 설계하는 방법
- 원하는 안정성 결과에 따라 애플리케이션을 분류하고 설계하는 프레임워크를 제공하는 아키텍처 계획 가이드
- 애플리케이션에 사용할 기본 제공 DR 기능을 제공하는 일부 Google Cloud 제품의 세부 목록
일반적인 DR 계획 및 온프레미스 DR 전략의 구성요소로 Google Cloud 를 사용하는 방법에 대한 자세한 내용은 재해 복구 계획 가이드를 참고하세요. 또한 고가용성은 재해 복구와 밀접하게 관련된 개념이지만 이 문서에서는 다루지 않습니다. 고가용성을 위한 설계에 대한 자세한 내용은 Well-Architected Framework를 참고하세요.
용어에 대한 참고사항: 이 문서에서 가용성은 시간 경과에 따라 유의미한 방식으로 액세스하고 사용할 수 있는 제품의 기능을 의미하고 안정성은 가용성뿐 아니라 내구성 및 정확성 등의 다양한 속성을 의미합니다.
복원력을 위해 설계된 Google Cloud
Google 데이터 센터
기존 데이터 센터는 개별 구성요소의 가용성을 극대화하는 데 의존합니다. Google과 같은 운영자는 클라우드에서 확장 기능을 통해 가상화 기술을 사용하여 여러 구성요소로 서비스를 분산할 수 있으므로 구성요소의 안정성을 월등히 높일 수 있습니다. 즉, 안정성 아키텍처에 대한 사고방식을 온프레미스와 관련하여 우려했던 수많은 세부정보에서 탈피할 수 있습니다. 냉각 및 전력 공급과 같은 구성요소와 관련된 여러 오류 모드에 대해 걱정할 필요 없이 Google Cloud 제품과 해당 제품의 명시된 안정성 측정항목을 중심으로 계획을 세울 수 있습니다. 이러한 측정항목은 기본 인프라 전체의 총 서비스 중단 위험을 반영합니다. 덕분에 인프라 관리보다는 애플리케이션을 설계, 배포, 운영하는 데에만 집중할 수 있습니다.
Google은 현대적인 데이터 센터를 구축하고 운영하는 광범위한 경험을 바탕으로 공격적인 가용성 목표를 충족하도록 인프라를 설계합니다. Google은 데이터 센터 설계 부문의 선두 업체입니다. 전력, 냉각, 네트워크 등 각 데이터 센터 기술에는 FMEA 계획을 비롯한 자체 중복 및 완화 조치가 있습니다. Google의 데이터 센터는 이러한 다양한 위험을 균형 있게 관리하고 고객에게 Google Cloud 제품의 일관된 예상 가용성 수준을 제공하는 방식으로 구축됩니다. Google은 자체 경험을 바탕으로 전체 물리적 및 논리적 시스템 아키텍처의 가용성을 모델링하여 데이터 센터 설계의 기대치를 충족시킵니다. Google의 엔지니어들은 이러한 기대치를 충족시키기 위해 운영 측면에서 많은 노력을 하고 있습니다. 일반적으로 실제 측정된 가용성은 여유 있게 설계 목표를 달성합니다.
Google Cloud는 이러한 모든 데이터 센터의 위험을 완화하는 기능을 사용자 대상 제품에 구현하여 Google Cloud 사용자의 설계 및 운영 책임을 덜어줍니다. 따라서Google Cloud 리전과 영역에 설계된 안정성에 집중할 수 있습니다.
리전과 영역
지역은 영역들로 구성되는 독립적인 지리적 위치입니다. 영역과 리전은 기본 물리적 리소스의 논리적 추상화입니다. 리전별 고려사항에 대한 자세한 내용은 지역 및 리전을 참조하세요.
Google Cloud 제품은 영역별 리소스, 리전별 리소스, 멀티 리전 리소스로 나뉩니다.
영역별 리소스는 단일 영역 내에서 호스팅됩니다. 특정 영역의 서비스 중단은 해당 영역의 모든 리소스에 영향을 줄 수 있습니다. 예를 들어 Compute Engine 인스턴스는 지정된 단일 영역에서 실행됩니다. 하드웨어 오류로 해당 영역의 서비스가 중단되면 중단 기간 동안에는 Compute Engine 인스턴스를 사용할 수 없습니다.
리전별 리소스는 특정 리전 내의 여러 영역에 중복해서 배포되는 리소스입니다. 이 리소스는 영역별 리소스에 비해 안정성이 더 높습니다.
멀티 리전 리소스는 리전 내 그리고 리전 간에 분산됩니다. 일반적으로 멀티 리전 리소스는 리전별 리소스보다 안정성이 더 높습니다. 그러나 이 수준의 제품은 최적화된 가용성, 성능, 리소스 효율성을 제공합니다. 따라서 사용하려는 각 멀티 리전 제품의 장단점을 이해하는 것이 중요합니다. 이러한 장단점에 대해서는 이 문서의 뒷부분에서 제품별로 설명합니다.
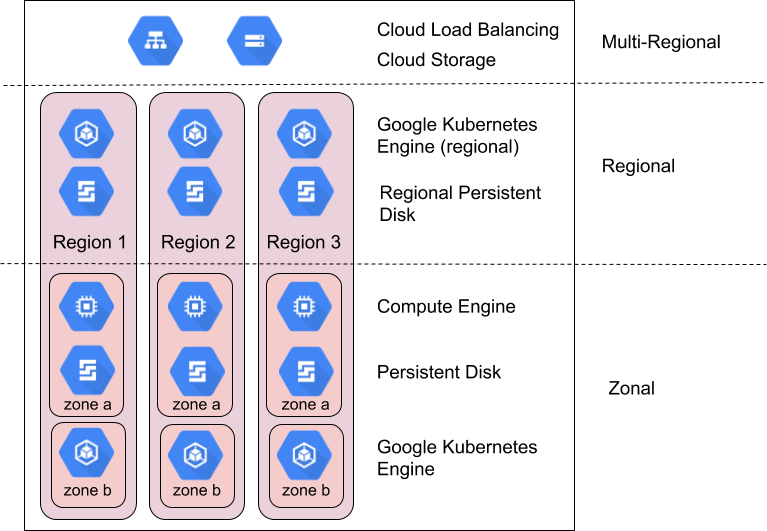
영역과 리전을 활용하여 안정성 확보
Google SRE는 전 세계 컴퓨팅 인프라를 원활하게 활용하는 다양한 기법과 기술을 통해 Gmail 및 Google 검색과 같은 매우 안정적인 글로벌 사용자 제품을 관리하고 확장합니다. 여기에는 글로벌 부하 분산을 사용하여 사용 불가능한 위치의 트래픽을 리디렉션하고 전 세계 수많은 위치에서 여러 복제본을 실행하며 여러 위치에서 데이터를 복제하는 작업이 포함됩니다. 이러한 동일한 기능은 Google Cloud 고객이 Cloud Load Balancing, Google Kubernetes Engine (GKE), Spanner와 같은 제품을 통해 사용할 수 있습니다.
Google Cloud 는 일반적으로 영역 및 리전에 다음과 같은 가용성 수준을 제공하도록 제품을 설계합니다.
| 리소스 | 예시 | 가용성 설계 목표 | 암시적 다운타임 |
|---|---|---|---|
| 영역 | Compute Engine, Persistent Disk | 99.9% | 8.75시간/년 |
| 리전 | 리전 Cloud Storage, 복제된 Persistent Disk, 리전 GKE | 99.99% | 52분/년 |
Google Cloud 가용성 설계 목표를 허용되는 수준의 다운타임과 비교하여 적절한 Google Cloud 리소스를 식별합니다. 기존 설계는 애플리케이션의 가용성을 향상시키기 위해 구성요소 수준의 가용성을 개선하는 데 초점을 맞추지만 클라우드 모델은 이 목표를 달성하는 데 필요한 구성요소의 구성에 초점을 맞춥니다.Google Cloud 에 포함된 많은 제품이 이 기법을 사용합니다. 예를 들어 Spanner는 99.999%의 가용성을 제공하기 위해 여러 리전을 구성하는 멀티 리전 데이터베이스를 제공합니다.
구성 없이는 애플리케이션 가용성이 사용 중인 Google Cloud 제품의 가용성을 능가할 수 없으므로 구성은 중요합니다. 실제로 애플리케이션이 절대 실패하지 않는다면 애플리케이션의 가용성은 기본Google Cloud 제품보다 더 낮습니다. 이 섹션의 나머지 부분에서는 일반적으로 영역 및 리전 제품의 구성을 사용하여 단일 영역 또는 리전에서 제공하는 것보다 더 높은 애플리케이션 가용성을 달성하는 방법을 설명합니다. 다음 섹션에서는 이러한 원칙을 애플리케이션에 적용하기 위한 실무 가이드를 제공합니다.
영역 서비스 중단 범위 계획
일반적으로 인프라 오류가 발생하면 단일 영역에서 실행되는 서비스가 중단될 수 있습니다. 한 리전의 영역은 다른 영역과의 연관성 장애의 위험을 최소화하도록 설계되며 한 영역의 서비스 중단은 일반적으로 동일한 리전의 다른 영역에서 실행되는 서비스에 영향을 주지 않습니다. 서비스 중단 범위가 영역으로만 지정되어 있다고 해서 전제 영역을 사용할 수 없다는 의미는 아니며 이 범위는 단순히 이슈의 경계만 정의합니다. 영역의 서비스 중단은 해당 영역의 특정 리소스에 실질적인 영향을 주지 않을 수 있습니다.
드물지만 단일 리전 내의 여러 영역에서 결국 특정 시점에 서로 상관 관계가 있는 서비스 중단이 발생하게 될 것이라는 점도 중요합니다. 2개 이상의 영역에서 서비스 중단이 발생하면 아래의 리전 서비스 중단 범위 전략이 적용됩니다.
리전별 리소스는 여러 영역의 구성에서 서비스를 제공하여 영역 서비스 중단을 방지하도록 설계되었습니다. 리전별 리소스를 지원하는 영역 중 하나가 중단되면 리소스는 자동으로 다른 영역에서 사용할 수 있게 됩니다. 자세한 내용을 알아보려면 부록의 제품 기능 설명을 주의 깊게 확인하세요.
Google Cloud 는 Compute Engine 가상 머신 (VM) 및 영구 디스크와 같은 영역별 리소스만 제공합니다. 영역별 리소스를 사용하려면 여러 영역에 있는 영역별 리소스 간에 장애 조치 및 복구를 설계, 빌드, 테스트하여 자체 리소스 구성을 수행해야 합니다. 다음은 몇 가지 전략입니다.
- 상태 확인에서 영역에 문제가 발생한 것으로 확인되면 Cloud Load Balancing을 사용하여 트래픽을 다른 영역의 가상 머신으로 빠르게 라우팅합니다.
- Compute Engine 인스턴스 템플릿 또는 관리형 인스턴스 그룹을 사용하여 여러 영역에서 동일한 VM 인스턴스를 실행하고 확장합니다.
- 리전 Persistent Disk를 사용하여 리전 내 다른 영역으로 데이터를 동기식으로 복제합니다. 자세한 내용은 리전 PD를 사용하는 고가용성 옵션을 참고하세요.
리전 서비스 중단 범위 계획
리전 서비스 중단은 단일 리전 내 여러 영역에 영향을 미칩니다. 이러한 서비스 중단은 빈도는 낮지만 대규모로 발생하며 자연 재해나 대규모 인프라 오류로 인해 발생할 수 있습니다.
99.99%의 가용성을 제공하도록 설계된 리전 제품의 경우 서비스 중단이 매년 특정 제품에서 발생하는 1시간의 다운타임으로 해석될 수 있습니다. 따라서 이 서비스 중단이 허용되지 않는 경우에는 중요한 애플리케이션에 멀티 리전 DR 계획이 필요할 수 있습니다.
멀티 리전 리소스는 여러 리전에서 서비스를 제공하여 리전 서비스 중단을 방지하도록 설계되었습니다. 위의 설명대로 멀티 리전 제품에는 지연 시간, 일관성, 비용 간 균형이 필요합니다. 일반적인 예시는 동기식 및 비동기식 데이터 복제 간의 균형입니다. 비동기식 복제는 지연 시간은 짧지만 서비스 중단 시 데이터 손실이 발생할 수 있습니다. 자세한 내용을 알아보려면 부록의 제품 기능 설명을 확인하세요.
리전별 리소스를 사용하고 리전 서비스 중단에 대한 우수한 복원력을 유지하려면 여러 리전에 있는 리전별 리소스 간에 장애 조치 및 복구를 설계, 빌드, 테스트하여 자체 리소스 구성을 수행해야 합니다. 리전에 적용할 수 있는 위의 영역 전략 외에 다음을 고려하세요.
- 리전별 리소스는 보조 리전, Cloud Storage와 같은 Multi-Regional Storage 옵션, GKE 및 Google Distributed Cloud와 같은 하이브리드 클라우드 옵션에 데이터를 복제해야 합니다.
- 리전 서비스 중단 완화 기능이 있으면 정기적으로 테스트하세요. 단일 리전 서비스 중단에 강하다고 믿고 있다가 실제 상황에서 그렇지 않다는 것을 알게 되는 것보다 나쁜 것은 거의 없습니다.
Google Cloud 복원력 및 가용성 접근 방식
Google Cloud 정기적으로 가용성 설계 목표를 초과 달성하지만 이 강력한 과거 성능이 설계 가능한 최소 가용성이라고 가정해서는 안 됩니다. 대신 애플리케이션 다운타임과 Google Cloud 다운타임이 원하는 결과를 제공하도록 고안된 설계 목표가 애플리케이션의 의도한 안정성을 초과하는 Google Cloud 종속 항목을 선택해야 합니다.
잘 설계된 시스템은 '영역 또는 리전에 1, 5, 10 또는 30분 동안 서비스 중단이 발생하면 어떻게 되나요?'라는 질문에 답변할 수 있습니다. 이 질문을 비롯한 다음 질문들은 여러 레이어에서 고려해야 하는 요소입니다.
- 서비스 중단 시 고객은 어떤 경험을 하게 되나요?
- 서비스 중단이 발생한지 어떻게 알 수 있나요?
- 서비스 중단 시 내 애플리케이션은 어떻게 되나요?
- 서비스 중단 시 내 데이터는 어떻게 되나요?
- 교차 종속 항목으로 인한 서비스 중단 시 내 애플리케이션은 어떻게 되나요?
- 서비스 중단이 해결된 후 복구하려면 누가 어떤 조치를 취해야 하나요?
- 서비스 중단 시 언제까지 누구에게 알림을 전송해야 하나요?
Google Cloud애플리케이션의 재해 복구 설계에 대한 단계별 안내
이전 섹션에서는 Google에서 클라우드 인프라를 구축하는 방법과 영역 및 리전 서비스 중단에 대처하는 여러 가지 접근 방식을 다뤘습니다.
이 섹션은 원하는 안정성 결과에 따라 구성 원칙을 애플리케이션에 적용하기 위한 프레임워크를 개발하는 데 유용합니다.
RTO 및 RPO와 같은 재해 복구 목표를 Google Cloud 타겟팅하는 고객 애플리케이션은 RTO/RPO의 적용을 받는 비즈니스에 중요한 작업이 서비스의 작업의 지속적인 처리를 담당하는 데이터 플레인 구성요소에만 종속되도록 설계해야 합니다. 즉, 이러한 고객 업무상 중요한 작업이 구성 상태를 관리하고 구성을 제어 영역과 데이터 영역으로 푸시하는 관리 영역 작업에 종속되어서는 안 됩니다.
예를 들어 Google Cloud 업무상 중요한 작업의 RTO를 달성하려는 고객은 VM 생성 API 또는 IAM 권한 업데이트에 종속되면 안 됩니다.
1단계: 기존 요구사항 수집하기
첫 번째 단계는 애플리케이션의 가용성 요구사항을 정의하는 것입니다. 대부분의 기업에는 이미 이 분야에 대한 몇 가지 수준의 설계 가이드가 있으며, 이 가이드는 내부적으로 개발되거나 규제 또는 다른 현지 법규에서 파생된 것입니다. 이 설계 가이드는 일반적으로 복구 시간 목표(RTO)와 복구 지점 목표(RPO)라는 2가지 주요 측정항목으로 작성됩니다. 비즈니스 관점에서 RTO는 '재해 발생 후 가동 및 실행까지 걸리는 시간'을 의미하고, RPO는 '재해 발생 시 감내할 수 있는 데이터 손실의 양'을 의미합니다.

지금까지 기업에서는 구성요소 오류에서 지진에 이르기까지 광범위한 재해 이벤트에 대해 RTO와 RPO 요구사항을 정의했습니다. 이 방식은 설계자가 전체 소프트웨어 및 하드웨어 스택을 통해 RTO/RPO 요구사항을 매핑해야 했던 온프레미스 환경에서는 적합했습니다. 클라우드에서는 제공업체가 세부정보를 처리하므로 더 이상 해당 세부정보를 사용하여 요구사항을 처리할 필요가 없습니다. 대신 근본적인 원인을 구체화하지 않고 손실 범위(전체 영역 또는 리전)를 기준으로 RTO 및 RPO 요구사항을 정의할 수 있습니다. 이렇게 하면 Google Cloud 영역 서비스 중단, 리전 서비스 중단, 발생 확률이 매우 낮은 멀티 리전의 서비스 중단 등 3가지 시나리오로 요구사항을 간편하게 수집할 수 있습니다.
애플리케이션별로 중요도가 서로 다를 수 있다는 점을 인식하고 있는 대부분의 고객은 구체적인 RTO/RPO 요구사항을 적용할 수 있는 중요도 계층으로 애플리케이션을 분류합니다. RTO/RPO 및 애플리케이션 중요도를 종합하여 다음 질문에 답변하는 것으로 지정된 애플리케이션의 설계 프로세스를 효율화할 수 있습니다.
- 애플리케이션을 같은 리전의 여러 영역에서 실행해야 하나요? 아니면 여러 리전의 여러 영역에서 실행해야 하나요?
- 애플리케이션에 영향을 주는 Google Cloud 제품은 무엇인가요?
다음은 요구사항 수집 실습의 출력 예시입니다.
예시 조직 Co의 애플리케이션 중요도별 RTO 및 RPO:
| 애플리케이션 중요도 | 앱 비율 | 앱 예시 | 영역 서비스 중단 | 리전 서비스 중단 |
|---|---|---|---|---|
| 등급 1
(중요도 가장 높음) |
5% | 일반적으로 실시간 결제 및 전자상거래 매장과 같은 글로벌 또는 외부 고객 대상 애플리케이션입니다. | RTO 0
RPO 0 |
RTO 0
RPO 0 |
| 등급 2 | 35% | 일반적으로 리전 애플리케이션 또는 CRM이나 ERP와 같은 중요한 내부 애플리케이션입니다. | RTO 15분
RPO 15분 |
RTO 1시간
RPO 1시간 |
| 등급 3
(중요도 가장 낮음) |
60% | 일반적으로 백오피스, 예약, 내부 출장, 회계, 인사와 같은 팀 또는 부서 애플리케이션입니다. | RTO 1시간
RPO 1시간 |
RTO 12시간
RPO 12시간 |
2단계: 사용 가능한 제품에 기능 매핑
두 번째 단계는 애플리케이션에서 사용할 Google Cloud 제품의 복원력을 이해하는 것입니다. 대부분의 기업에서는 관련 제품 정보를 검토한 후 제품 기능과 복원력 요구사항 사이의 모든 격차를 수용할 수 있도록 아키텍처를 수정하는 방법에 대한 가이드를 추가합니다. 이 섹션에서는 이 분야의 데이터 및 애플리케이션과 관련된 몇 가지 일반적인 내용과 권장사항을 설명합니다.
앞에서 설명한 것처럼 Google의 DR 지원 제품은 리전 및 영역이라는 두 가지 유형의 서비스 중단 범위를 광범위하게 충족합니다. 부분적 서비스 중단에 대한 DR은 전체 서비스 중단과 동일한 방식으로 계획되어야 합니다. 이렇게 해야 기본적으로 각 시나리오에 적합한 제품의 초기 상위 수준의 매트릭스를 확보할 수 있습니다.
Google Cloud 제품 일반 기능
(구체적인 제품 기능은 부록 참고)
| 모든 Google Cloud 제품 | 영역 간 자동 복제 기능이 있는 리전 Google Cloud 제품 | 리전 간 자동 복제 기능이 있는 멀티 리전 또는 글로벌 Google Cloud 제품 | |
|---|---|---|---|
| 영역 내 구성요소 오류 | 포함* | 포함 | 포함 |
| 영역 서비스 중단 | 포함되지 않음 | 포함 | 포함 |
| 리전 서비스 중단 | 포함되지 않음 | 포함되지 않음 | 포함 |
* 제품 문서에 구체적으로 명시된 경우를 제외하고 Google Cloud 모든 제품은 구성요소 오류에 대해 우수한 복원력을 발휘합니다. 이러한 시나리오는 제품이 메모리 또는 SSD(Solid State Disk)과 같은 특수 하드웨어에 직접 액세스하거나 정적 매핑을 제공하는 경우에 일반적입니다.
RPO가 제품 선택을 제한하는 방법
대부분의 클라우드 배포에서 데이터 무결성은 아키텍처 측면에서 서비스에 대해 고려해야 할 가장 중요한 요소입니다. 일부 애플리케이션의 RPO 요구사항은 0이므로 서비스 중단 발생 시 데이터 손실이 발생해서는 안 됩니다. 이 경우 일반적으로 데이터를 다른 영역 또는 리전으로 동기식으로 복제해야 합니다. 동기식 복제에서는 비용과 지연 시간이 서로 상쇄되므로 많은 Google Cloud 제품이 영역 간 동기식 복제를 제공하며, 단 리전 간 복제는 단 몇 가지 제품에서만 제공됩니다. 이러한 비용과 복잡성의 상쇄를 통해 애플리케이션 내 다양한 데이터 유형의 RPO 값이 서로 다른 것이 드물지 않다는 것을 알 수 있습니다.
RPO가 0보다 큰 데이터의 경우 애플리케이션은 비동기식 복제를 활용할 수 있습니다. 비동기식 복제는 손실된 데이터를 간편하게 다시 생성할 수 있거나 필요한 경우 골든 데이터 소스에서 복구할 수 있을 때 허용됩니다. 이 옵션은 소량의 데이터 손실을 영역 및 리전의 예상 서비스 중단 기간에 대한 절충으로 받아들일 수 있을 경우에도 적합합니다. 또한 일시적인 서비스 중단 시 영향을 받는 위치에 기록되지만 아직 다른 위치에 복제되지 않은 데이터는 서비스 중단이 해결된 후 일반적으로 사용할 수 있습니다. 즉, 서비스 중단 시 영구적인 데이터 손실 위험은 데이터 액세스 손실 위험보다 낮습니다.
주요 조치: RPO가 반드시 0이어야 하는지, 그리고 그럴 경우 데이터의 일부에 대해 이 조치를 수행할 수 있는지 여부를 결정합니다. 그러면 사용 가능한 DR 지원 서비스 범위가 크게 늘어납니다. Google Cloud에서 RPO 0을 달성한다는 것은 애플리케이션에 주로 리전 제품을 사용한다는 것을 의미하며, 이 경우 기본적으로 영역 범위의 서비스 중단에 대해 우수한 복원력을 발휘하지만 리전 범위의 서비스 중단에는 그렇지 못합니다.
RTO가 제품 선택을 제한하는 방법
클라우드 컴퓨팅의 주요 이점 중 하나는 온디맨드 방식으로 구현할 수 있다는 것이지만, 이는 즉각적인 배포와는 다른 개념입니다. 애플리케이션의 RTO 값은 애플리케이션에서 활용하는 Google Cloud 제품의 통합 RTO와 VM 또는 애플리케이션 구성요소를 재시작하기 위해 엔지니어 또는 SRE가 수행해야 하는 모든 조치를 수용해야 합니다. 분 단위로 측정되는 RTO는 사람의 개입 없이 재해로부터 자동으로 복구되거나 버튼을 누르는 등의 최소한의 단계로 장애 조치되는 애플리케이션을 설계할 수 있다는 것을 의미합니다. 지금까지 이러한 시스템 종류의 비용과 복잡성은 매우 높았지만 부하 분산기와 인스턴스 그룹 같은 Google Cloud 제품을 사용하면 훨씬 더 저렴하고 간편한 방식으로 애플리케이션을 설계할 수 있습니다. 따라서 대부분의 애플리케이션에 대해 자동 장애 조치 및 복구를 고려해야 합니다. 여러 리전에 걸쳐 이러한 종류의 핫(hot) 장애 조치에 사용할 시스템을 설계하는 것은 복잡하고 비용이 많이 들 수 있습니다. 극히 일부의 중요한 서비스에서만 이 기능이 보증됩니다.
대부분의 애플리케이션은 1시간에서 1일 사이의 RTO를 제공합니다. 따라서 애플리케이션의 일부 구성요소는 데이터베이스와 같이 대기 모드에서도 항상 실행되는 반면 실제 재해 발생 시 웹 서버와 같은 다른 구성요소는 수평 확장되는 재해 시나리오에서 웜(warm) 장애 조치를 허용합니다. 이러한 애플리케이션의 경우 수평 확장 이벤트에 대한 자동화를 적극 고려해야 합니다. RTO가 하루 이상인 서비스는 중요도가 가장 낮으며 백업에서 복구하거나 처음부터 새로 만들 수 있습니다.
주요 조치: 리전 장애 조치의 RTO가 반드시 0이어야 하는지, 그리고 그럴 경우 데이터의 일부에 대해 이 조치를 수행할 수 있는지 여부를 결정합니다. 그러면 서비스를 실행하고 관리하는 비용이 변경됩니다.
3단계: 자체 참조 아키텍처 및 가이드 개발
마지막으로 권장되는 단계는 팀이 재해 복구 방식을 표준화하는 데 도움이 되는 기업별 아키텍처 패턴을 빌드하는 것입니다. 대부분의 Google Cloud 고객은 개발팀을 위해 Google Cloud의 두 가지 주요 서비스 중단 시나리오 카테고리에 대한 개별 비즈니스 복원력 기대치를 충족하는 가이드를 제공합니다. Google Cloud팀은 이 가이드를 활용하여 각 중요도 수준에 적합한 DR 지원 제품을 쉽게 분류할 수 있습니다.
제품 가이드라인 작성
위의 RTO/RPO 예시 표를 다시 살펴보면 기본적으로 각 중요도 등급별로 허용되는 제품을 나열하는 가설 가이드가 있습니다. 기본적으로 특정 제품이 적합하지 않은 것으로 식별된 경우에는 언제든지 영역 간 또는 리전 간 동기화를 사용 설정하기 위해 자체 복제 및 장애 조치 메커니즘을 추가할 수 있습니다. 단, 이 실습은 이 문서 범위에 포함되지 않습니다. 또한 이 표에는 각 제품에 대한 추가 정보를 볼 수 있는 링크가 제공되므로 영역 및 리전 서비스 중단 관리와 관련된 제품의 기능을 이해하는 데 유용합니다.
조직 예시 Co의 샘플 아키텍처 패턴 - 영역 서비스 중단 복원력:
| Google Cloud 제품 | 제품이 예시 조직의 영역 서비스 중단 요구사항을 충족하는지 여부(적절한 제품 구성 포함) | ||
|---|---|---|---|
| 등급 1 | 등급 2 | 등급 3 | |
| Compute Engine | 아니요 | 아니요 | 아니요 |
| Dataflow | 아니요 | 아니요 | 아니요 |
| BigQuery | 아니요 | 아니요 | 예 |
| GKE | 예 | 예 | 예 |
| Cloud Storage | 예 | 예 | 예 |
| Cloud SQL | 아니요 | 예 | 예 |
| Spanner | 예 | 예 | 예 |
| Cloud Load Balancing | 예 | 예 | 예 |
이 표는 위에 표시된 가상 등급을 기반으로 하는 예시일 뿐입니다.
조직 예시 Co의 샘플 아키텍처 패턴 - 리전 서비스 중단 복원력:
| Google Cloud 제품 | 제품이 예시 조직의 리전 서비스 중단 요구사항을 충족하는지 여부(적절한 제품 구성 포함) | ||
|---|---|---|---|
| 등급 1 | 등급 2 | 등급 3 | |
| Compute Engine | 예 | 예 | 예 |
| Dataflow | 아니요 | 아니요 | 아니요 |
| BigQuery | 아니요 | 아니요 | 예 |
| GKE | 예 | 예 | 예 |
| Cloud Storage | 아니요 | 아니요 | 아니요 |
| Cloud SQL | 아니요 | 예 | 예 |
| Spanner | 예 | 예 | 예 |
| Cloud Load Balancing | 예 | 예 | 예 |
이 표는 위에 표시된 가상 등급을 기반으로 하는 예시일 뿐입니다.
다음 섹션에서는 이러한 제품의 사용 방법을 보여주기 위해 각 가상 애플리케이션 중요도 수준에 대한 몇 가지 참조 아키텍처를 살펴봅니다. 이는 주요 아키텍처 결정을 설명하기 위해 의도적으로 개략적으로 구성한 설명이며 전체 솔루션 설계를 나타내지 않습니다.
등급 3 아키텍처 예시
| 애플리케이션 중요도 | 영역 서비스 중단 | 리전 서비스 중단 |
|---|---|---|
| 등급 3 (중요도 가장 낮음) |
RTO 12시간 RPO 24시간 |
RTO 28일 RPO 24시간 |
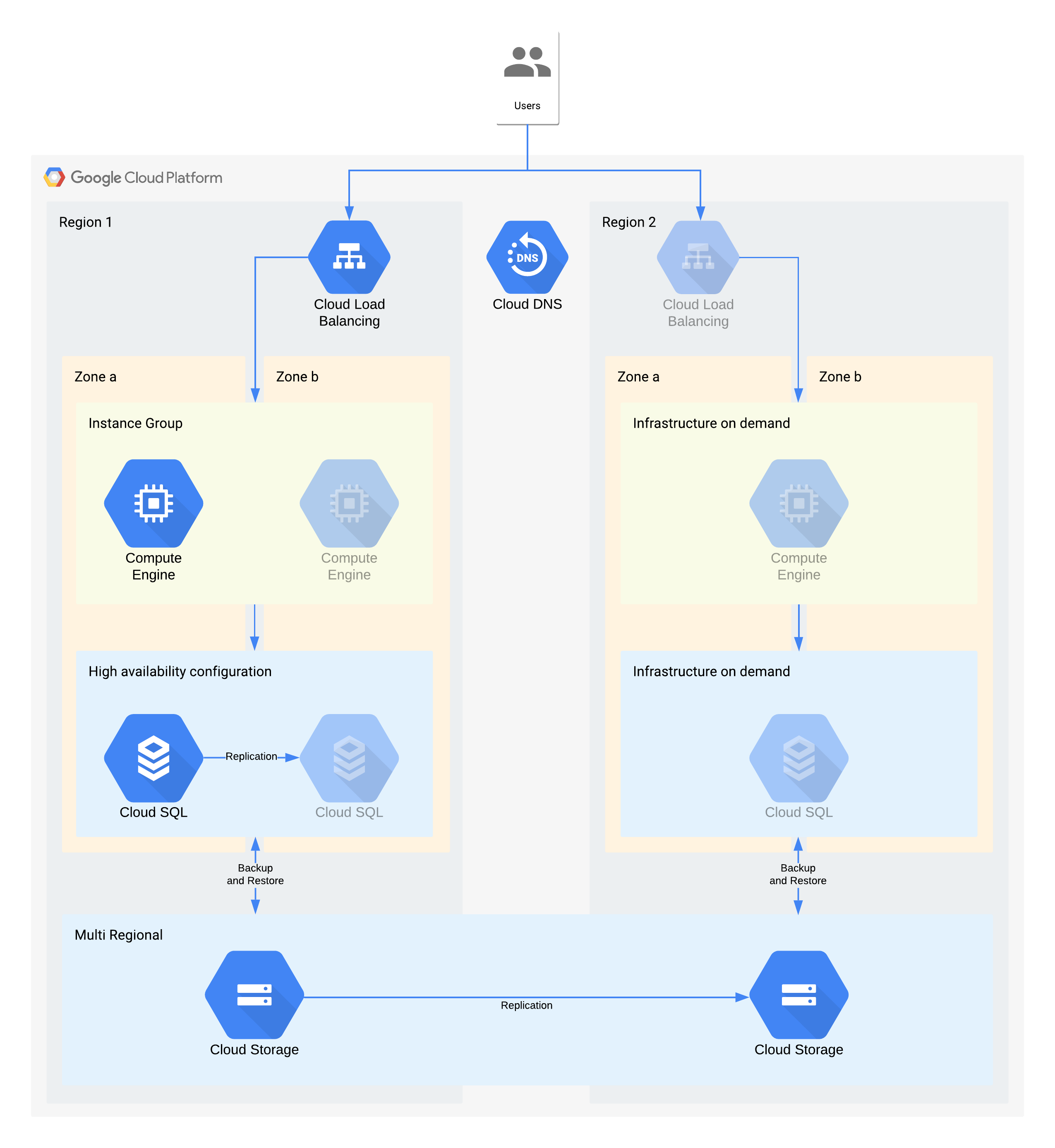
(회색으로 표시된 아이콘은 복구가 사용 설정된 인프라를 나타냅니다.)
이 아키텍처는 기존 클라이언트/서버 애플리케이션을 설명합니다. 내부 사용자는 영구 스토리지용 데이터베이스에 백업되는 컴퓨팅 인스턴스에서 실행 중인 애플리케이션에 연결됩니다.
이 아키텍처는 필요한 것보다 더 높은 RTO 및 RPO 값을 지원한다는 점에 주목해 주세요. 하지만 비용이 많이 발생하거나 신뢰할 수 없는 수동 단계는 추가하지 않는 것이 좋습니다. 예를 들어 야간 백업에서 데이터베이스를 복구하는 경우 24시간의 RPO를 지원할 수 있지만, 이 경우에는 대개 데이터베이스 관리자와 같은 숙련된 직원이 필요합니다. 단, 이러한 직원은 특히 여러 서버가 동시에 영향을 받는 경우에는 가용하지 않을 수 있습니다. Google Cloud의 온디맨드 인프라를 사용하면 큰 비용 부담 없이 이 기능을 빌드할 수 있으므로 이 아키텍처에서는 영역 서비스 중단 시 수동 백업/복원이 아닌 Cloud SQL HA를 사용합니다.
영역 서비스 중단에 대한 주요 아키텍처 결정 - RTO 12시간 및 RPO 24시간
- 내부 부하 분산기는 사용자에게 다른 영역으로의 자동 장애 조치를 허용하는 확장 가능한 액세스 포인트를 제공하는 데 사용됩니다. RTO가 12시간인 경우에도 IP 주소를 수동 변경하거나 DNS 업데이트를 처리하는 데 예상보다 시간이 오래 걸릴 수 있습니다.
- 리전 관리형 인스턴스 그룹은 여러 영역에서 최소한의 리소스로 구성됩니다. 이렇게 하면 비용에 맞게 최적화되지만 백업 영역에서 가상 머신을 빠르게 확장할 수도 있습니다.
- 고가용성 Cloud SQL 구성은 다른 영역으로의 자동 장애 조치를 기능을 제공합니다. 데이터베이스는 Compute Engine 가상 머신에 비해 재생성 및 복원이 훨씬 더 어렵습니다.
리전 서비스 중단에 대한 주요 아키텍처 결정 - RTO 28시간 및 RPO 24시간
- 부하 분산기는 리전 서비스 중단이 발생한 경우에만 리전 2에 구성됩니다. 리전 2의 인프라는 리전 서비스 중단이 발생한 경우에만 사용할 수 있으므로 Cloud DNS는 조정된 수동 리전 장애 조치를 기능을 제공하는 데 사용됩니다.
- 새로운 관리형 인스턴스 그룹은 리전 서비스 중단이 발생한 경우에만 구성됩니다. 이렇게 하면 비용에 맞게 최적화되지만 대부분의 리전 서비스 중단은 짧은 시간 동안 지속되므로 호출되지 않을 가능성이 높습니다. 편의상 다이어그램에는 재배포하는 데 필요한 관련 도구나 필요한 Compute Engine의 복사는 표시되어 있지 않습니다.
- 새 Cloud SQL 인스턴스가 재생성되고 백업에서 데이터가 복원됩니다. 한 리전에 대한 서비스 중단의 장기화 위험은 매우 낮으므로 이는 또 다른 비용 최적화 방법이 될 수 있습니다.
- 멀티 리전 Cloud Storage는 이러한 백업을 저장하는 데 사용됩니다. 이렇게 하면 RTO 및 RPO 내에 자동 영역 및 리전 복원력이 제공됩니다.
등급 2 아키텍처 예시
| 애플리케이션 중요도 | 영역 서비스 중단 | 리전 서비스 중단 |
|---|---|---|
| 등급 2 | RTO 4시간 RPO 0 |
RTO 24시간 RPO 4시간 |
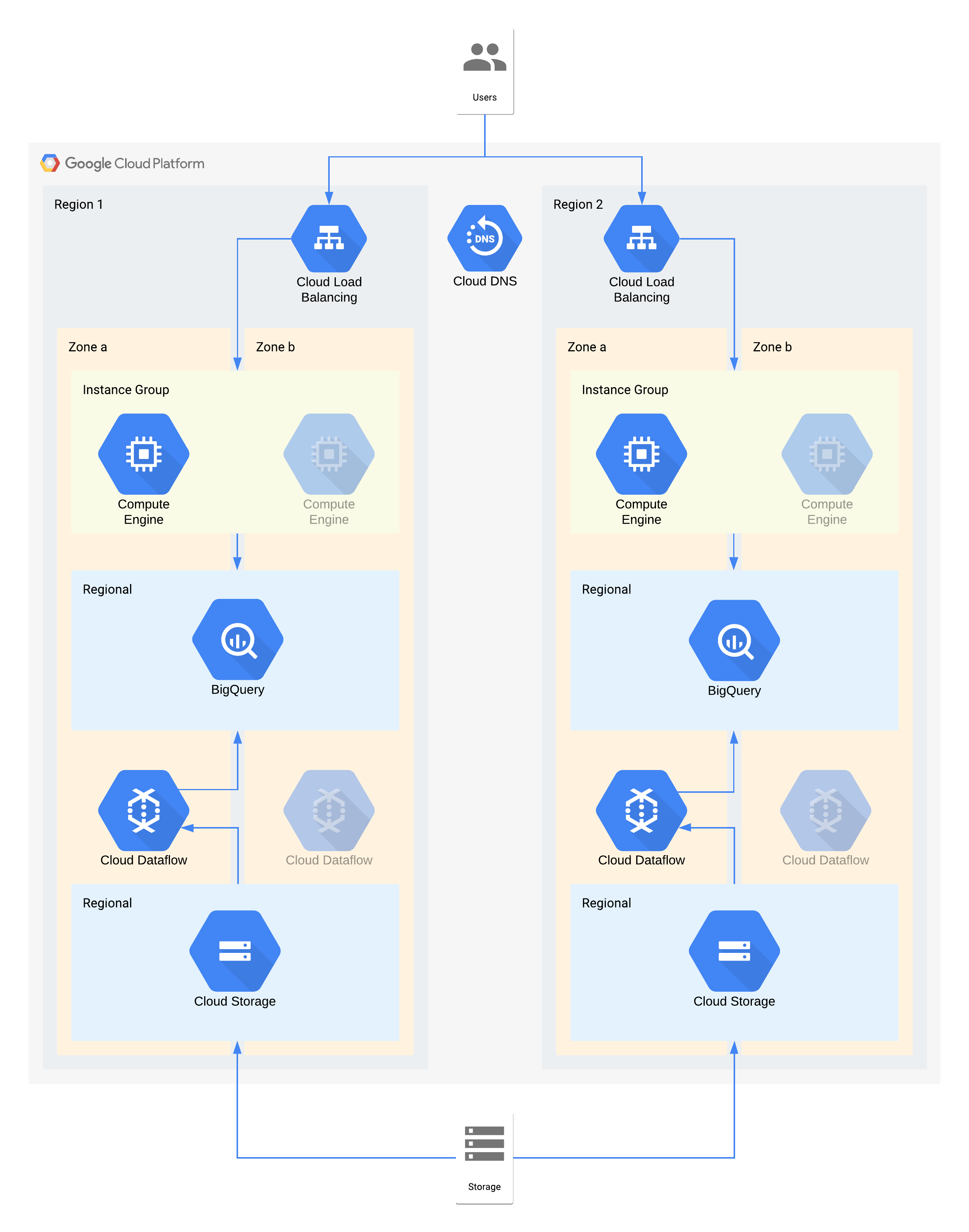
이 아키텍처는 컴퓨팅 인스턴스 시각화 레이어에 연결된 내부 사용자가 있는 데이터 웨어하우스와 백엔드 데이터 웨어하우스를 채우는 데이터 수집 및 변환 레이어를 설명합니다.
이 아키텍처의 일부 개별 구성요소는 해당 등급에 필요한 RPO를 직접 지원하지 않습니다. 하지만 함께 사용되는 방식 때문에 전체 서비스가 RPO를 충족합니다. 이 경우 Dataflow가 영역 제품이므로 서비스 중단 시 데이터 손실을 방지하기 위해 고가용성 설계 권장사항을 따르세요. 그러나 Cloud Storage 레이어는 이 데이터의 골든 소스이며 RPO 0을 지원합니다. 따라서 영역 a에서 서비스 중단이 발생하면 영역 b를 사용하여 손실된 데이터를 BigQuery로 다시 수집할 수 있습니다.
영역 서비스 중단에 대한 주요 아키텍처 결정 - RTO 4시간 및 RPO 0
- 부하 분산기는 사용자에게 다른 영역으로의 자동 장애 조치를 허용하는 확장 가능한 액세스 포인트를 제공하는 데 사용됩니다. RTO가 4시간인 경우에도 IP 주소를 수동 변경하거나 DNS 업데이트를 처리하는 데 예상보다 시간이 오래 걸릴 수 있습니다.
- 데이터 시각화 컴퓨팅 레이어의 리전 관리형 인스턴스 그룹은 여러 영역에서 최소한의 리소스로 구성됩니다. 이렇게 하면 비용에 맞게 최적화되지만 가상 머신을 빠르게 확장할 수도 있습니다.
- 리전 Cloud Storage는 데이터의 초기 수집을 위한 스테이징 레이어로 사용되며, 자동 영역 복원력을 제공합니다.
- Dataflow는 Cloud Storage에서 데이터를 추출하고 BigQuery로 로드하기 전에 변환하는 데 사용됩니다. 영역 서비스 중단이 발생하면 이 스테이트리스(Stateless) 프로세스는 다른 영역에서 다시 시작할 수 있습니다.
- BigQuery는 데이터 시각화 프런트엔드를 위한 데이터 웨어하우스 백엔드를 제공합니다. 영역 서비스 중단이 발생하면 손실된 데이터는 Cloud Storage에서 다시 수집됩니다.
리전 서비스 중단에 대한 주요 아키텍처 결정 - RTO 24시간 및 RPO 4시간
- 각 리전의 부하 분산기는 사용자에게 확장 가능한 액세스 포인트를 제공하는 데 사용됩니다. 리전 2의 인프라는 리전 서비스 중단이 발생한 경우에만 사용할 수 있으므로 Cloud DNS는 조정된 수동 리전 장애 조치를 기능을 제공하는 데 사용됩니다.
- 데이터 시각화 컴퓨팅 레이어의 리전 관리형 인스턴스 그룹은 여러 영역에서 최소한의 리소스로 구성됩니다. 부하 분산기를 다시 구성하기 전에는 이 그룹에 액세스할 수 없지만 그 외의 경우에는 수동 개입이 필요하지 않습니다.
- 리전 Cloud Storage는 데이터의 초기 수집을 위한 스테이징 레이어로 사용됩니다. 이는 RPO 요구사항을 충족하기 위해 두 리전에 동시 로드됩니다.
- Dataflow는 Cloud Storage에서 데이터를 추출하고 BigQuery로 로드하기 전에 변환하는 데 사용됩니다. 리전 서비스 중단이 발생하면 BigQuery가 Cloud Storage의 최신 데이터로 채워집니다.
- BigQuery는 데이터 웨어하우스 백엔드를 제공합니다. 정상 작동 중에는 간헐적으로 새로고침됩니다. 리전 서비스 중단이 발생하면 최신 데이터는 Dataflow를 통해 Cloud Storage에서 다시 수집됩니다.
등급 1 아키텍처 예시
| 애플리케이션 중요도 | 영역 서비스 중단 | 리전 서비스 중단 |
|---|---|---|
| 등급 1 (중요도 가장 높음) |
RTO 0 RPO 0 |
RTO 4시간 RPO 1시간 |
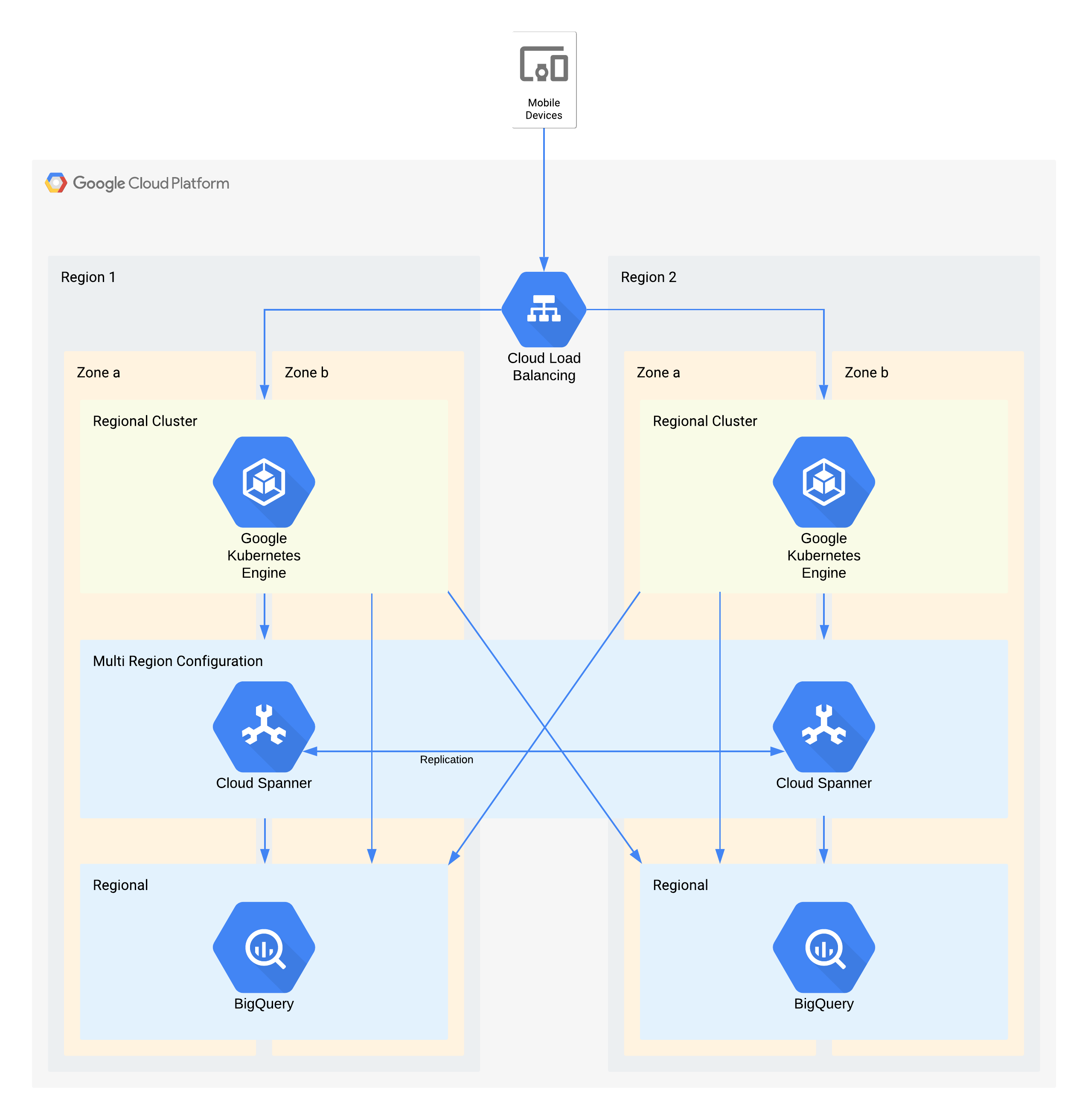
이 아키텍처는 GKE에서 실행되는 마이크로서비스 세트에 외부 사용자가 연결되는 모바일 앱 백엔드 인프라를 설명합니다. Spanner는 실시간 데이터를 위한 백엔드 데이터 스토리지 레이어를 제공하고 이전 데이터는 각 리전의 BigQuery 데이터 레이크로 스트리밍됩니다.
다시 말하자면, 이 아키텍처의 일부 개별 구성요소는 해당 등급에 필요한 RPO를 직접 지원하지 않습니다. 하지만 함께 사용되는 방식 때문에 전체 서비스가 RPO를 충족합니다. 이 경우 BigQuery는 분석 쿼리에 사용됩니다. 각 리전은 Spanner에서 동시에 공급됩니다.
영역 서비스 중단에 대한 주요 아키텍처 결정 - RTO 0 및 RPO 0
- 부하 분산기는 사용자에게 다른 영역으로의 자동 장애 조치를 허용하는 확장 가능한 액세스 포인트를 제공하는 데 사용됩니다.
- 리전 GKE 클러스터는 여러 영역으로 구성된 애플리케이션 레이어에 사용됩니다. 이렇게 하면 각 리전의 RTO가 0이 됩니다.
- 멀티 리전 Spanner는 데이터 지속성 레이어로 사용되며, 자동 영역 데이터 복원력 및 트랜잭션 일관성을 제공합니다.
- BigQuery는 애플리케이션을 위한 분석 기능을 제공합니다. 각 리전은 Spanner에서 독립적으로 제공되는 데이터로, 애플리케이션에서 독립적으로 액세스할 수 있습니다.
리전 서비스 중단에 대한 주요 아키텍처 결정 - RTO 4시간 및 RPO 1시간
- 부하 분산기는 사용자에게 다른 리전으로의 자동 장애 조치를 허용하는 확장 가능한 액세스 포인트를 제공하는 데 사용됩니다.
- 리전 GKE 클러스터는 여러 영역으로 구성된 애플리케이션 레이어에 사용됩니다. 리전 서비스 중단이 발생하면 대체 리전의 클러스터가 자동으로 확장되어 추가 처리 로드를 처리합니다.
- 멀티 리전 Spanner는 데이터 지속성 레이어로 사용되며, 자동 리전 데이터 복원력 및 트랜잭션 일관성을 제공합니다. 이는 리전 간 RPO 1시간을 달성하는 데 필요한 핵심 구성요소입니다.
- BigQuery는 애플리케이션을 위한 분석 기능을 제공합니다. 각 리전은 Spanner에서 독립적으로 제공되는 데이터로, 애플리케이션에서 독립적으로 액세스할 수 있습니다. 이 아키텍처는 BigQuery 구성요소를 보완하여 전체 애플리케이션 요구사항을 충족합니다.
부록: 제품 참조
이 섹션에서는 고객 애플리케이션에서 가장 일반적으로 사용되며 DR 요구사항을 충족하는 데 쉽게 활용할 수 있는 Google Cloud 제품의 아키텍처 및 DR 기능을 설명합니다.
공통된 주제
많은 Google Cloud 제품이 리전 또는 멀티 리전 구성을 제공합니다. 리전 제품은 영역 서비스 중단에 대한 복원력이 우수하고 멀티 리전 및 글로벌 제품은 리전 서비스 중단에 대한 복원력이 우수합니다. 일반적으로 이는 서비스 중단 시 애플리케이션 중단이 최소화된다는 의미입니다. Google은 위의 아키텍처 가이드를 반영하는 몇 가지 일반적인 아키텍처 접근 방식으로 이러한 결과를 얻습니다.
중복 배포: 애플리케이션 백엔드 및 데이터 스토리지는 한 리전 내의 여러 영역과 멀티 리전 위치 내의 여러 리전에 걸쳐 배포됩니다. 지역별 고려사항에 대한 자세한 내용은 지역 및 리전을 참고하세요.
데이터 복제: 제품은 중복 위치에서 동기식 또는 비동기 복제를 사용합니다.
동기식 복제는 애플리케이션이 제품에 저장된 데이터를 생성하거나 수정하기 위해 API 호출을 수행할 때 제품이 데이터를 여러 위치에 쓴 경우에만 성공 응답을 수신한다는 것을 의미합니다. 동기식 복제를 사용하면 사용 가능한 백엔드 위치 중 하나에서 모든 데이터를 사용할 수 있기 때문에 Google Cloud 인프라 서비스가 중단된 동안에도 모든 데이터에 대한 액세스 권한이 손실되지 않습니다.
이 기법을 사용하면 최대한의 데이터가 보호되지만 지연 시간 및 성능 측면에 영향을 미칠 수 있습니다. 동기식 복제를 사용하는 멀티 리전 제품은 이러한 상충 관계의 영향을 가장 크게 받으며, 일반적으로 지연 시간이 수십 또는 수백 밀리초 단위로 증가합니다.
비동기식 복제는 애플리케이션이 제품에 저장된 데이터를 생성하거나 수정하기 위해 API 호출을 수행할 때 제품이 데이터를 단일 위치에 쓴 경우 성공 응답을 수신한다는 것을 의미합니다. 쓰기 요청 후 제품은 추가 위치에 데이터를 복제합니다.
이 기법은 동기식 복제에 비해 API에서의 지연 시간이 짧고 처리량이 높지만 데이터를 제대로 보호하지 못할 수 있습니다. 복제를 완료하기 전에 데이터를 쓴 위치에 서비스 중단이 발생하면 해당 위치의 서비스 중단이 해결될 때까지 데이터에 액세스할 수 없게 됩니다.
부하 분산으로 서비스 중단 처리: Google Cloud 소프트웨어 부하 분산을 사용하여 적절한 애플리케이션 백엔드로 요청을 라우팅합니다. DNS 부하 분산과 같은 다른 접근 방식과 달리 이 접근 방식은 시스템 응답 시간을 서비스 중단 시점까지 줄여줍니다. 위치에 Google Cloud 서비스 중단이 발생하면 부하 분산기는 해당 위치에 배포된 백엔드가 '비정상'으로 전환되었음을 감지하고 대체 위치의 백엔드로 모든 요청을 전달합니다. 그러면 제품은 특정 위치의 서비스가 중단된 동안에도 애플리케이션의 요청을 계속 처리할 수 있습니다. 위치의 서비스 중단이 해결되면 부하 분산기는 해당 위치에서 제품 백엔드의 가용성을 감지하고 이 위치로 트래픽을 다시 보내기 시작합니다.
Access Context Manager
기업은 Access Context Manager를 사용하여 요청 속성에 정의된 정책에 매핑하는 액세스 수준을 구성할 수 있습니다. 정책은 리전별로 미러링됩니다.
영역 서비스 중단이 발생하면 사용 불가능한 영역에 대한 요청이 해당 리전의 다른 사용 가능한 영역에서 자동으로 투명하게 처리됩니다.
리전 서비스 중단이 발생하면 리전이 다시 사용 가능하게 될 때까지 영향을 받는 리전에서 정책 계산을 사용할 수 없습니다.
액세스 투명성
액세스 투명성을 사용하면 Google Cloud 조직 관리자가 Google Cloud의 프로젝트 및 리소스에 대해 세분화된 속성 기반 액세스 제어를 정의할 수 있습니다. Google은 관리 목적으로 고객 데이터에 액세스해야 하는 경우가 있습니다. Google에서 고객 데이터에 액세스하면 액세스 투명성이 영향을 받는 Google Cloud 고객에게 액세스 로그를 제공합니다. 이러한 액세스 투명성 로그는 데이터 처리 시 데이터 보안 및 투명성에 대한 Google의 약속을 보장하는 데 도움이 됩니다.
액세스 투명성은 영역 및 리전 서비스 중단에 대한 복원력이 우수합니다. 영역 또는 리전 서비스 중단이 발생하면 액세스 투명성이 다른 영역 또는 리전에서 관리 액세스 로그를 계속 처리합니다.
PostgreSQL용 AlloyDB
PostgreSQL용 AlloyDB는 완전 관리형 PostgreSQL 호환 데이터베이스 서비스입니다. PostgreSQL용 AlloyDB는 리전의 두 가지 영역에 있는 기본 인스턴스의 중복 노드를 통해 한 리전에서 고가용성을 제공합니다. 기본 인스턴스는 활성 영역에 문제가 발생하면 대기 영역에 대한 자동 장애 조치를 트리거하여 리전 가용성을 유지합니다. Regional Storage는 단일 영역 손실 시 데이터 내구성을 보장합니다.
재해 복구의 추가 방법으로 PostgreSQL용 AlloyDB는 리전 간 복제를 사용하여 기본 클러스터의 데이터를 별도의 Google Cloud 리전에 있는 보조 클러스터에 비동기식으로 복제하여 재해 복구 기능을 제공합니다.
영역 서비스 중단: 정상 작동 중에 고가용성 기본 인스턴스의 두 노드 중 하나만 활성 상태이고 모든 데이터 쓰기를 제공합니다. 이 활성 노드는 클러스터의 별도 Regional Storage 레이어에 데이터를 저장합니다.
PostgreSQL용 AlloyDB는 영역 수준 장애를 자동으로 감지하고 장애 조치를 트리거하여 데이터베이스 가용성을 복원합니다. 장애 조치 중에 PostgreSQL용 AlloyDB는 이미 다른 영역에 프로비저닝된 대기 노드에서 데이터베이스를 시작합니다. 새 데이터베이스 연결이 이 영역으로 자동 라우팅됩니다.
클라이언트 애플리케이션의 관점에서 영역 서비스 중단은 일시적인 네트워크 연결 중단과 유사합니다. 장애 조치가 완료되면 클라이언트는 데이터 손실 없이 동일한 사용자 인증 정보를 사용하여 동일한 주소의 인스턴스에 다시 연결할 수 있습니다.
리전 서비스 중단: 리전 간 복제는 비동기식 복제를 사용하므로 기본 인스턴스가 복제본에서 커밋되기 전에 트랜잭션을 커밋할 수 있습니다. 트랜잭션이 기본 인스턴스에서 커밋되는 시점과 복제본에서 커밋되는 시점 간의 시간 차이를 복제 지연이라고 부릅니다. 기본 인스턴스가 미리 쓰기 로그(WAL)를 생성하는 시점과 WAL이 복제본에 도달하는 시점 간의 시간 차이를 플러시 지연이라고 합니다. 복제 지연 및 플러시 지연은 데이터베이스 인스턴스 구성과 사용자 생성 워크로드에 따라 달라집니다.
리전 서비스 중단이 발생하면 다른 리전의 보조 클러스터를 쓰기 가능한 독립형 기본 클러스터로 승격할 수 있습니다. 이 승격된 클러스터는 이전에 연결된 원래 기본 클러스터에서 더 이상 데이터를 복제하지 않습니다. 플러시 지연으로 인해 원래 기본 클러스터에 보조 클러스터로 전파되지 않은 트랜잭션이 있을 수 있으므로 일부 데이터 손실이 발생할 수 있습니다.
리전 간 복제 RPO는 기본 클러스터의 CPU 사용률과 기본 클러스터의 리전과 보조 클러스터의 리전 간의 물리적 거리의 영향을 받습니다. RPO를 최적화하려면 플러시 지연이 누적되지 않고 가장 높게 지속되는 TPS인 안전한 TPS(Transaction Per Second) 한도를 설정하기 위해 복제본이 포함된 구성으로 워크로드를 테스트하는 것이 좋습니다. 워크로드가 안전한 TPS 한도를 초과하면 플러시 지연이 누적되어 RPO에 영향을 줄 수 있습니다. 네트워크 지연을 제한하려면 동일한 지역 내 리전 쌍을 선택합니다.
네트워크 지연 및 PostgreSQL용 AlloyDB 측정항목 모니터링에 대한 자세한 내용은 인스턴스 모니터링을 참조하세요.
자금 세탁 방지 AI
자금 세탁 방지 AI(AML AI)는 전 세계 금융기관이 자금세탁을 보다 효과적이고 효율적으로 감지할 수 있도록 API를 제공합니다. 자금 세탁 방지 AI는 리전별 제품이므로 고객은 리전을 선택할 수 있지만 리전을 구성하는 영역은 선택할 수 없습니다. 데이터와 트래픽은 리전 내의 영역 간에 자동으로 분산됩니다. 작업(예: 파이프라인 만들기 또는 예측 실행)은 백그라운드에서 자동으로 확장되며 필요에 따라 영역 간에 부하가 분산됩니다.
영역 서비스 중단: AML AI는 리소스의 데이터를 리전별로 저장하고 동기식으로 복제합니다. 장기 실행 작업이 성공적으로 완료되면 영역 장애와 관계없이 리소스를 사용할 수 있습니다. 처리도 영역 간에 복제되지만 이 복제는 고가용성이 아닌 부하 분산을 목표로 하므로 작업 중 영역 오류로 인해 작업이 실패할 수 있습니다. 이 경우 작업을 재시도하면 문제가 해결될 수 있습니다. 영역 서비스 중단 시 처리 시간이 영향을 받을 수 있습니다.
리전 서비스 중단: 고객이 AML AI 리소스를 만들 Google Cloud 리전을 선택합니다. 데이터는 리전 간에 복제되지 않습니다. 고객 트래픽은 AML AI에 의해 다른 리전으로 라우팅되지 않습니다. 리전 장애의 경우 서비스 중단이 해결되는 즉시 AML AI를 다시 사용할 수 있습니다.
API 키
API 키는 프로젝트용 확장 가능한 API 키 리소스 관리를 제공합니다. API 키는 전역 서비스이므로 모든 Google Cloud 위치에서 키를 보고 액세스할 수 있습니다. 해당 데이터 및 메타데이터는 여러 영역 및 리전에 걸쳐 중복 저장됩니다.
API 키는 영역 및 리전 서비스 중단 모두에 대해 복원력이 우수합니다. 영역 서비스 중단 또는 리전 서비스 중단 시 API 키는 동일하거나 다른 리전 내 다른 영역의 요청을 계속 처리합니다.
API 키에 대한 자세한 내용은 API 키 API 개요를 참고하세요.
Apigee
Apigee는 API 개발 및 관리를 위한 보안, 확장성 및 안정성이 우수한 플랫폼을 제공합니다. Apigee는 단일 리전 및 멀티 리전 배포가 모두 가능합니다.
영역 서비스 중단: 고객 런타임 데이터가 여러 가용성 영역으로 복제됩니다. 따라서 단일 영역 서비스 중단은 Apigee에 영향을 미치지 않습니다.
리전 서비스 중단: 단일 리전 Apigee 인스턴스의 경우 리전 서비스가 중단되면 해당 리전에서 Apigee 인스턴스를 사용할 수 없으며 다른 리전으로 복원할 수 없습니다. 멀티 리전 Apigee 인스턴스의 경우 데이터가 모든 리전에 걸쳐 비동기적으로 복제됩니다. 따라서 한 리전에 장애가 발생하더라도 트래픽이 완전히 줄어들지는 않습니다. 그렇지만 장애 발생 리전에서 커밋되지 않은 데이터의 경우 액세스하지 못할 수도 있습니다. 상태가 양호하지 않은 리전을 벗어나도록 트래픽을 우회할 수 있습니다. 자동 트래픽 장애 조치가 이루어지도록 하려면 관리형 인스턴스 그룹(MIG)을 사용하여 네트워크 라우팅을 구성하면 됩니다.
AutoML Translation
AutoML Translation은 자체 데이터(문장 쌍)를 가져와서 분야별 니즈에 맞춰 커스텀 모델을 학습시킬 수 있는 기계 번역 서비스입니다.
영역 서비스 중단: AutoML Translation은 여러 영역 및 리전에 활성 컴퓨팅 서버를 갖고 있습니다. 또한 리전 내 영역 간 동기식 데이터 복제도 지원합니다. 이러한 기능을 통해 AutoML Translation은 영역 장애에 대한 데이터 손실 없이 그리고 고객 입력 또는 조정을 필요로 하지 않고 즉각적인 장애 조치를 달성할 수 있습니다.
리전 서비스 중단: 리전 장애가 발생하면 AutoML Translation을 사용할 수 없습니다.
AutoML Vision
AutoML Vision은 Vertex AI의 일부입니다. 데이터 세트를 만들고, 데이터를 가져오고, 모델을 학습시키고, 온라인 예측 및 일괄 예측을 위해 모델을 제공하는 통합 프레임워크를 제공합니다.
AutoML Vision은 리전 제품입니다. 고객은 작업을 시작할 리전을 선택할 수 있지만 해당 리전 내에서 특정 영역을 선택할 수는 없습니다. 이 서비스는 리전 내 여러 영역 간에 워크로드를 자동으로 부하 분산합니다.
영역 서비스 중단: AutoML Vision은 작업의 메타데이터를 리전별로 저장하고 리전 내 영역 간에 동기식으로 작성합니다. 작업은 Cloud Load Balancing에서 선택한 특정 영역에서 실행됩니다.
AutoML Vision 학습 작업: 영역 장애로 인해 실행 중인 작업이 실패하고 작업 상태가 실패로 업데이트됩니다. 작업이 실패하면 즉시 다시 시도하세요. 새 작업은 사용 가능한 영역으로 라우팅됩니다.
AutoML Vision 일괄 예측 작업: 일괄 예측은 Vertex AI 일괄 예측을 기반으로 빌드됩니다. 영역 서비스 중단이 발생하면 서비스가 사용 가능한 영역으로 라우팅하여 작업을 자동으로 재시도합니다. 여러 번 재시도가 실패하면 작업 상태가 실패로 업데이트됩니다. 이후에 작업을 실행하기 위한 사용자 요청은 사용 가능한 영역으로 라우팅됩니다.
리전 서비스 중단: 고객이 작업을 실행할 Google Cloud 리전을 선택합니다. 데이터는 리전 간에 복제되지 않습니다. 리전 서비스 중단이 발생하면 해당 리전에서 AutoML Vision 서비스를 사용할 수 없습니다. 서비스 중단이 해결되면 다시 사용할 수 있게 됩니다. 작업을 실행하려면 고객이 여러 리전을 사용하는 것이 좋습니다. 리전 서비스 중단이 발생하면 사용 가능한 다른 리전으로 작업을 전송합니다.
일괄
Batch는 Google Cloud에서 일괄 작업을 큐에 추가하고 예약하고 실행하는 완전 관리형 서비스입니다. Batch 설정은 리전 수준에서 정의됩니다. 고객은 리전의 영역이 아닌 리전을 선택하여 일괄 작업을 제출해야 합니다. 작업을 제출하면 Batch가 고객 데이터를 여러 영역에 동기식으로 기록합니다. 반면 고객은 Batch VM에서 작업을 실행할 영역을 지정할 수 있습니다.
영역 장애: 단일 영역에서 문제가 발생하면 해당 영역에서 실행 중인 태스크도 실패합니다. 태스크에 재시도 설정이 있으면 Batch가 자동으로 이러한 태스크를 동일한 리전의 다른 활성 영역으로 장애 조치합니다. 자동 장애 조치는 동일한 리전의 활성 영역에 있는 리소스 가용성의 영향을 받습니다. 문제가 발생한 영역에서만 사용할 수 있는 영역별 리소스(예: VM, GPU, 영역 영구 디스크)가 필요한 작업은 문제가 발생한 영역이 복구되거나 작업의 큐 제한 시간에 도달할 때까지 큐에 추가됩니다. 가능하면 Batch에서 영역별 리소스를 선택하여 작업을 실행할 수 있도록 하는 것이 좋습니다. 이를 통해 영역 서비스 중단에 대해 우수한 작업 복원력을 유지할 수 있습니다.
리전 장애: 리전 장애가 발생하면 해당 리전에서 서비스 제어 영역을 사용할 수 없습니다. 이 서비스는 리전 간에 데이터를 복제하거나 요청을 리디렉션하지 않습니다. 리전에 문제가 발생하면 여러 리전을 사용하여 작업을 실행하고 작업을 다른 리전으로 리디렉션하는 것이 좋습니다.
Chrome Enterprise Premium 위협 및 데이터 보호
Chrome Enterprise Premium 위협 및 데이터 보호는 Chrome Enterprise Premium 솔루션의 일부입니다. 멀웨어 및 피싱 방지, 데이터 손실 방지(DLP), URL 필터링 규칙, 보안 보고를 포함한 다양한 보안 기능으로 Chrome을 확장합니다.
Chrome Enterprise Premium 관리자는 향후 조사를 위해 DLP 또는 멀웨어 정책을 위반하는 고객 핵심 콘텐츠를 Google Workspace 규칙 로그 이벤트 또는 Cloud Storage에 저장하도록 선택할 수 있습니다. Google Workspace 규칙 로그 이벤트는 멀티 리전 Spanner 데이터베이스를 기반으로 합니다. Chrome Enterprise Premium이 정책 위반을 감지하는 데 최대 몇 시간이 걸릴 수 있습니다. 이 시간 동안 처리되지 않은 모든 데이터는 영역 또는 리전 서비스 중단으로 인해 손실될 수 있습니다. 위반이 감지되면 정책을 위반하는 콘텐츠가 Google Workspace 규칙 로그 이벤트 또는 Cloud Storage에 기록됩니다.
영역 및 리전 서비스 중단: Chrome Enterprise Premium 위협 방지 및 데이터 보호는 멀티 영역 및 멀티 리전에 적용되기 때문에 가용성의 손실 없이 영역 또는 리전의 완전하고 계획되지 않은 손실에도 대처할 수 있습니다. 트래픽을 다른 활성 영역 또는 리전의 서비스로 리디렉션하여 이러한 수준의 안정성을 제공합니다. 하지만 Chrome Enterprise Premium 위협 방지 및 데이터 보호가 DLP 및 멀웨어 위반을 감지하는 데 몇 시간이 걸릴 수 있기 때문에 특정 영역 또는 리전에서 처리되지 않은 모든 데이터는 영역 또는 리전 서비스 중단으로 인해 손실될 수 있습니다.
BigQuery
BigQuery는 확장성이 뛰어난 서버리스 저비용 클라우드 데이터 웨어하우스로, 비즈니스 민첩성을 제공하도록 설계되었습니다. BigQuery는 사용자 데이터 세트에 다음과 같은 위치 유형을 지원합니다.
- 리전: 아이오와(
us-central1) 또는 몬트리올(northamerica-northeast1)과 같은 특정 지리적 위치 - 멀티 리전: 미국(
US) 또는 유럽(EU)과 같이 두 개 이상의 지리적 장소를 포함하는 큰 지리적 영역
두 경우 모두 데이터가 선택한 위치의 단일 리전 내에 있는 2개 영역에 중복해서 저장됩니다. BigQuery에 기록되는 데이터는 기본 및 보조 영역에 모두 동기식으로 기록됩니다. 이렇게 하면 리전 내 단일 영역의 사용 불능 상황을 방지할 수 있지만 리전 서비스 중단은 방지하지 않습니다.
Binary Authorization
Binary Authorization은 GKE 및 Cloud Run용 소프트웨어 공급망 보안 제품입니다.
모든 Binary Authorization 정책은 모든 리전 내의 여러 영역에 복제됩니다. 복제는 Binary Authorization 정책 읽기 작업이 다른 리전의 오류를 복구하는 데 도움이 됩니다. 또한 읽기 작업이 각 리전 내에서 영역 오류를 허용하도록 합니다.
Binary Authorization 시행 작업의 복원력은 영역 서비스 중단에 대해 우수하지만 리전 서비스 중단에 대해서는 우수하지 않습니다. 시행 작업은 요청을 수행하는 GKE 클러스터 또는 Cloud Run 작업과 동일한 리전에서 실행됩니다. 따라서 리전 서비스 중단이 발생하면 Binary Authorization 시행 요청을 수행하는 작업도 없습니다.
인증서 관리자
인증서 관리자를 사용하면 다양한 유형의 Cloud Load Balancing에서 사용할 수 있는 전송 계층 보안(TLS) 인증서를 획득하고 관리할 수 있습니다.
작업과 데이터베이스가 한 리전 내의 여러 영역에 중복되므로 리전 및 전역 인증서 관리자는 영역 서비스 중단 시 영역 장애에 대한 복원력이 우수합니다. 작업과 데이터베이스가 여러 리전에 중복되므로 전역 인증서 관리자는 리전 서비스 중단 시 리전 장애에 대한 복원력이 우수합니다. 리전 인증서 관리자는 리전별 제품이므로, 리전 장애를 감당할 수 없습니다.
Cloud Intrusion Detection System
Cloud IDS(Cloud Intrusion Detection System)는 하나의 특정 영역에서 VM 트래픽을 처리하는 영역 범위의 IDS 엔드포인트를 제공하는 영역 서비스로, 영역 또는 리전 서비스 중단을 허용하지 않습니다.
영역 서비스 중단: Cloud IDS는 VM 인스턴스와 연결되어 있습니다. 고객이 여러 영역에 VM을 수동으로 또는 리전 관리형 인스턴스 그룹을 통해 배포하여 영역 서비스 중단을 완화하려는 경우 해당 영역에 Cloud IDS 엔드포인트도 배포해야 합니다.
리전 서비스 중단: Cloud IDS는 리전별 제품입니다. 리전 간 기능을 제공하지 않습니다. 특정 리전에 장애가 발생하면 해당 리전의 모든 영역에서 모든 Cloud IDS 기능이 중지됩니다.
Google Security Operations SIEM
Google Security Operations SIEM (Google Security Operations의 일부)은 보안팀이 위협을 감지, 조사, 대응하도록 도와주는 완전 관리형 서비스입니다.
Google Security Operations SIEM에는 리전 및 멀티 리전 제품이 있습니다.
리전 제품에서는 데이터와 트래픽이 선택한 리전 내의 영역 간에 자동으로 부하 분산되고 데이터는 리전 내의 가용성 영역에 중복 저장됩니다.
멀티 리전은 지리적으로 중복됩니다. 이러한 중복성은 리전별 스토리지보다 광범위한 방식으로 보호합니다. 또한 전체 리전이 손실되더라도 서비스가 계속 작동하도록 지원합니다.
대부분의 데이터 수집 경로는 여러 위치에 고객 데이터를 동기식으로 복제합니다. 데이터가 비동기식으로 복제되면 데이터가 아직 여러 위치에 복제되지 않는 기간 (복구 지점 목표 또는 RPO)이 있습니다. 멀티 리전 배포에서 피드를 사용하여 수집하는 경우에 해당합니다. RPO가 지나면 데이터를 여러 위치에서 사용할 수 있습니다.
영역 서비스 중단:
리전 배포: 요청은 리전 내의 모든 영역에서 처리됩니다. 데이터는 여러 영역에 동기식으로 복제됩니다. 전체 영역 서비스 중단이 발생해도 나머지 영역은 트래픽을 계속 처리하고 데이터를 계속 처리합니다. Google Security Operations SIEM의 중복 프로비저닝 및 자동 확장 기능은 이러한 부하 이동 중에 서비스가 나머지 영역에서 계속 작동하도록 지원합니다.
멀티 리전 배포: 영역 서비스 중단은 리전 서비스 중단과 동일합니다.
리전 서비스 중단:
리전 배포: Google Security Operations SIEM은 단일 리전 내에 모든 고객 데이터를 저장하며 트래픽은 리전 간에 라우팅되지 않습니다. 리전 서비스 중단이 발생하면 중단이 해결될 때까지 해당 리전에서 Google Security Operations SIEM을 사용할 수 없습니다.
멀티 리전 배포 (피드 없음): 요청은 멀티 리전 배포의 모든 리전에서 처리됩니다. 데이터는 여러 리전에 동기식으로 복제됩니다. 전체 리전 서비스 중단이 발생해도 나머지 리전은 트래픽을 계속 처리하고 데이터를 계속 처리합니다. Google Security Operations SIEM의 중복 프로비저닝 및 자동 확장 기능을 사용하면 이러한 부하 이동 중에 나머지 리전에서 서비스가 계속 작동하도록 할 수 있습니다.
멀티 리전 배포 (피드 포함): 요청은 멀티 리전 배포의 모든 리전에서 처리됩니다. 데이터는 제공된 RPO를 사용하여 여러 리전에 비동기적으로 복제됩니다. 전체 리전 서비스 중단의 경우 RPO 이후에 저장된 데이터만 나머지 리전에서 사용할 수 있습니다. RPO 기간 내의 데이터는 복제되지 않을 수 있습니다.
Cloud 애셋 인벤토리
Cloud 애셋 인벤토리는 Google Cloud 리소스 및 정책 메타데이터 저장소를 유지하는 복원력이 뛰어난 고성능 전역 서비스입니다. Cloud 애셋 인벤토리는 조직, 폴더 및 프로젝트에 걸쳐서 배포된 애셋을 추적할 수 있게 해주는 검색 및 분석 도구를 제공합니다.
영역 서비스 중단이 발생할 때 Cloud 애셋 인벤토리는 동일 또는 다른 리전에 있는 다른 영역의 요청을 계속 처리합니다.
리전 서비스 중단이 발생할 때 Cloud 애셋 인벤토리는 다른 리전의 요청을 계속 처리합니다.
Bigtable
Bigtable은 대규모 분석 및 운영 워크로드를 위한 완전 관리형 고성능 NoSQL 데이터베이스 서비스입니다.
Bigtable 복제 개요
Bigtable이 제공하는 유연하고 완전히 구성 가능한 복제 기능을 사용하면 데이터를 여러 리전 또는 단일 리전의 여러 영역에 있는 클러스터에 복사하여 데이터의 가용성과 내구성을 높일 수 있습니다. 또한 Bigtable은 복제를 사용할 때 요청에 대한 자동 장애 조치를 제공할 수 있습니다.
멀티 클러스터 라우팅과 함께 멀티 영역 또는 멀티 리전 구성을 사용하는 경우 영역 또는 리전 서비스 중단이 발생하면 Bigtable이 자동으로 트래픽을 다시 라우팅하여 사용 가능한 가장 가까운 클러스터에서 요청을 처리합니다. Bigtable 복제는 비동기식이고 eventual consistency를 가지므로, 서비스 중단이 발생한 위치에 있는 데이터의 최근 변경사항이 다른 위치에 아직 복제되지 않은 경우 해당 변경사항이 적용되지 않을 수 있습니다.
성능에 대한 고려사항
CPU 리소스 수요가 사용 가능한 노드 용량을 초과하면 Bigtable은 항상 복제 트래픽보다 먼저 수신하는 요청을 처리하는 데 우선순위를 둡니다.
워크로드에 Bigtable 복제를 사용하는 방법에 대한 자세한 내용은 Cloud Bigtable 복제 개요 및 복제 설정 예시를 참조하세요.
Bigtable 노드는 들어오는 요청을 처리하고 다른 클러스터에서 데이터를 복제하는 데 사용됩니다. 클러스터당 충분한 노드 수를 유지하는 것 외에도 과도하거나 불균형한 CPU 사용량과 복제 지연 시간 증가를 유발할 수 있는 핫스팟을 방지하려면 애플리케이션에서 적절한 스키마 설계를 사용해야 합니다.
Bigtable 성능 및 효율성을 극대화하도록 애플리케이션 스키마를 설계하는 방법에 대한 자세한 내용은 스키마 설계 권장사항을 참조하세요.
모니터링
Bigtable은 Google Cloud console에서 제공되는 복제 차트를 사용하여 인스턴스와 클러스터의 복제 지연 시간을 시각적으로 모니터링하는 여러 방법을 제공합니다.
Cloud Monitoring API를 사용하여 Bigtable 복제 측정항목을 프로그래매틱 방식으로 모니터링할 수도 있습니다.
Certificate Authority Service
Certificate Authority Service(CA 서비스)를 사용하면 고객이 비공개 인증 기관(CA)의 배포, 관리, 보안을 간소화, 자동화, 맞춤설정하고 규모에 맞게 복원력 있는 방식으로 인증서를 발급할 수 있습니다.
영역 서비스 중단: CA 서비스는 해당 제어 영역이 리전 내 여러 영역에 중복되어 있기 때문에 영역 오류에 대해 복원력을 갖습니다. 영역 서비스 중단이 발생하면 CA 서비스가 중단 없이 동일 리전의 다른 영역에서 요청을 계속 처리할 수 있습니다. 데이터는 동기식으로 복제되기 때문에 데이터가 손실되거나 손상되지 않습니다.
리전 서비스 중단: CA 서비스는 리전별 제품이므로, 리전 장애를 견딜 수 없습니다. 리전 장애에 대한 복원력이 필요하면 서로 다른 두 리전에 발급 CA를 만듭니다. 인증서가 필요한 리전에 기본 발급 CA를 만듭니다. 다른 리전에는 대체 CA를 만듭니다. 기본 종속 CA 리전에 중단이 발생하면 대체 CA를 사용합니다. 필요한 경우 두 CA가 동일한 루트 CA에 연결될 수 있습니다.
Cloud Billing
Cloud Billing API를 사용하면 개발자가Google Cloud 프로젝트의 결제를 프로그래매틱 방식으로 관리할 수 있습니다. Cloud Billing API는 여러 영역과 리전에 동기식으로 업데이트가 작성되는 전역 시스템으로 설계되었습니다.
영역 또는 리전 장애: Cloud Billing API가 자동으로 다른 영역 또는 리전으로 장애 조치됩니다. 개별 요청은 실패할 수 있지만 재시도 정책을 사용하면 후속 시도가 성공할 수 있습니다.
Cloud Build
Cloud Build는 Google Cloud에서 빌드를 실행하는 서비스입니다.
Cloud Build는 리전 내에서 여러 영역 간에 데이터를 동기식으로 복제하는 리전별로 격리된 인스턴스로 구성되어 있습니다. 전역 리전 대신 특정 Google Cloud 리전을 사용하고, 빌드에 사용되는 리소스 (로그 버킷, Artifact Registry 저장소 등)가 빌드 실행 리전에 맞게 조정되었는지 확인하는 것이 좋습니다.
영역 서비스 중단이 발생할 때 제어 영역 작업은 영향을 받지 않습니다. 그러나 현재 장애가 발생한 영역 내에서 빌드를 실행하면 지연되거나 영구적으로 손실됩니다. 새로 트리거된 빌드는 남은 작동 영역으로 자동으로 배포됩니다.
리전 장애가 발생하면 제어 영역이 오프라인이 되고 현재 실행 중인 빌드가 지연되거나 영구적으로 삭제됩니다. 트리거, 작업자 풀, 빌드 데이터는 리전 간에 복제되지 않습니다. 중단을 더 쉽게 완화할 수 있도록 여러 리전에 트리거 및 작업자 풀을 준비하는 것이 좋습니다.
Cloud CDN
Cloud CDN은 클라이언트에 대한 처리 지연 시간을 줄이기 위해 Google 네트워크의 여러 위치 간에 콘텐츠를 배포하고 캐시합니다. 캐시된 콘텐츠는 최선의 노력을 다하는 기준(best-effort basis)에 따라 제공됩니다. Cloud CDN 캐시가 요청을 처리할 수 없으면 백엔드 VM 또는 Cloud Storage 버킷과 같이 원본 콘텐츠가 저장된 원본 서버로 요청이 전달됩니다.
영역 또는 리전이 실패하면 영향을 받는 위치의 캐시가 사용 불가능합니다. 인바운드 요청은 사용 가능한 Google 에지 위치 및 캐시로 라우팅됩니다. 이러한 대체 캐시가 요청을 처리할 수 없으면 요청을 사용 가능한 원본 서버로 전달합니다. 서버가 최신 데이터로 요청을 처리할 수 있으면 콘텐츠 손실이 발생하지 않습니다. 캐시 부적중 비율이 증가하면 캐시가 채워짐에 따라 원본 서버에서 정상보다 높은 트래픽 볼륨이 발생합니다. 후속 요청은 영역 또는 리전 서비스 중단의 영향을 받지 않는 캐시에서 처리됩니다.
Cloud CDN 및 캐시 동작에 대한 자세한 내용은 Cloud CDN 문서를 참조하세요.
Cloud Composer
Cloud Composer는 클라우드 및 온프레미스 데이터 센터 전체의 워크플로를 생성, 예약, 모니터링, 관리할 수 있는 관리형 워크플로 조정 서비스입니다. Cloud Composer 환경은 Apache Airflow 오픈소스 프로젝트를 기반으로 구축되었습니다.
Cloud Composer API 가용성은 영역 비가용성의 영향을 받지 않습니다. 영역 서비스 중단이 발생해도 새 Cloud Composer 환경을 만드는 기능을 포함하여 Cloud Composer API에 대한 액세스 권한은 유지됩니다.
Cloud Composer 환경에는 아키텍처의 일부로 GKE 클러스터가 있습니다. 영역 서비스 중단 시 클러스터 워크플로가 중단될 수 있습니다.
- Cloud Composer 1에서 환경의 클러스터는 영역별 리소스이므로 영역 서비스 중단 발생 시 클러스터를 사용하지 못할 수 있습니다. 서비스 중단 시점에 실행 중인 Workflows는 완료 전에 중지될 수 있습니다.
- Cloud Composer 2에서 환경 클러스터는 리전별 리소스입니다. 하지만 영역 서비스 중단의 영향을 받는 영역의 노드에서 실행되는 워크플로는 완료되기 전에 중지될 수 있습니다.
두 버전의 Cloud Composer에서 영역 서비스 중단으로 인해 워크플로가 수행하도록 구성된 외부 작업을 포함하여 부분적으로 실행된 워크플로의 실행이 중단될 수 있습니다. 워크플로에 따라 외부 데이터 스토어를 수정하는 다단계의 실행 과정 도중에 워크플로가 중지되는 경우와 같이 외부적으로 불일치가 발생할 수 있습니다. 따라서 부분적으로 실행되지 않은 워크플로 상태를 감지하고 부분적 데이터 변경사항을 복구하는 방법을 포함하여 Airflow 워크플로를 설계할 때 복구 프로세스를 고려해야 합니다.
Cloud Composer 1에서는 영역 서비스 중단 시 다른 영역에서 새 Cloud Composer 환경을 시작할 수 있습니다. Airflow는 메타데이터 데이터베이스에서 워크플로 상태를 유지하므로 이 정보를 새 Cloud Composer 환경으로 전송하면 추가 단계 및 준비가 수행될 수 있습니다.
Cloud Composer 2에서는 환경 스냅샷으로 재해 복구를 미리 설정하여 영역 서비스 중단을 해결할 수 있습니다. 영역 서비스 중단 시 환경 스냅샷으로 워크플로 상태를 전송하여 다른 환경으로 전환할 수 있습니다. Cloud Composer 2만 환경 스냅샷을 사용한 재해 복구를 지원합니다.
Cloud Data Fusion
Cloud Data Fusion은 데이터 파이프라인을 신속하게 빌드하고 관리하기 위한 완전 관리형 기업 데이터 통합 서비스입니다. 이 제품은 세 가지 버전으로 제공됩니다.
영역 서비스 중단은 개발자 버전 인스턴스에 영향을 줍니다.
리전 서비스 중단은 기본 및 엔터프라이즈 버전 인스턴스에 영향을 줍니다.
리소스 액세스를 제어하려면 개별 환경에서 파이프라인을 설계 및 실행할 수 있습니다. 이러한 구분을 통해 파이프라인을 한 번만 설계하여 여러 환경에서 실행할 수 있습니다. 두 환경 모두에서 파이프라인을 복구할 수 있습니다. 자세한 내용은 인스턴스 데이터 백업 및 복원을 참조하세요.
다음 권장사항은 리전 및 영역 서비스 중단에 모두 적용됩니다.
파이프라인 설계 환경의 서비스 중단
설계 환경에서 서비스 중단 시 파이프라인 초안을 저장합니다. 특정 RTO 및 RPO 요구사항에 따라 저장된 초안을 사용하여 서비스 중단 시 다른 Cloud Data Fusion 인스턴스에서 파이프라인을 복원할 수 있습니다.
파이프라인 실행 환경의 서비스 중단
실행 환경에서는 Cloud Data Fusion 트리거 또는 일정에 따라 내부적으로 또는 Cloud Composer와 같은 조정 도구를 사용하여 외부적으로 파이프라인을 시작합니다. 파이프라인의 런타임 구성을 복구하려면 플러그인 및 일정과 같은 파이프라인 및 구성을 백업합니다. 서비스 중단 시에는 백업을 사용하여 영향을 받지 않은 리전 또는 영역의 인스턴스를 복제할 수 있습니다.
서비스 중단을 준비하는 또 다른 방법은 동일한 구성 및 파이프라인 설정으로 리전 간에 여러 인스턴스를 배치하는 것입니다. 외부 조정을 사용할 경우 실행 중인 파이프라인이 인스턴스 간에 자동으로 부하 분산됩니다. 서비스 중단 시 핵심 오류 지점이 될 수 있으므로, 단일 리전에 연결되어 있고 모든 인스턴스에 사용되는 리소스(예: 데이터 소스 또는 조정 도구)가 없는지 특별히 주의하세요. 예를 들어 서로 다른 리전에 여러 인스턴스를 배치하고 Cloud Load Balancing 및 Cloud DNS를 사용하여 서비스 중단의 영향을 받지 않는 인스턴스로 파이프라인 실행 요청을 전달할 수 있습니다(등급 1 및 등급 3 아키텍처 예시 참조).
파이프라인 내 다른 Google Cloud 데이터 서비스의 서비스 중단
인스턴스는 Dataproc, Cloud Storage, BigQuery와 같이 다른 Google Cloud 서비스를 데이터 소스 또는 파이프라인 실행 환경으로 사용할 수 있습니다. 이러한 서비스는 서로 다른 리전에 있을 수 있습니다. 리전 간 실행이 필요하면 어느 한 리전의 오류가 서비스 중단으로 이어집니다. 이 시나리오에서는 서로 다른 리전에 중요 서비스가 배치된 리전 간 설정의 복원력이 더 적다는 것을 염두에 두고 표준 재해 복구 단계를 수행합니다.
Cloud Deploy
Cloud Deploy는 GKE 및 Cloud Run과 같은 런타임 서비스로 워크로드를 지속적으로 배포합니다. 이 서비스는 리전 내의 영역 간에 데이터를 동기식으로 복제하는 리전 인스턴스로 구성됩니다.
영역 서비스 중단: 컨트롤 플레인 작업은 영향을 받지 않습니다. 그러나 영역 장애가 발생할 때 실행되는 Cloud Build 빌드(예: 렌더링 또는 배포 작업)는 지연되거나 영구적으로 손실됩니다. 서비스 중단 중에 빌드를 트리거한 Cloud Deploy 리소스(출시 버전 또는 출시)는 기본 작업이 실패했음을 나타내는 실패 상태를 표시합니다. 나머지 작동하는 영역에서 새 빌드를 시작하려면 리소스를 다시 만들면 됩니다. 예를 들어 출시 버전을 대상에 다시 배포하여 새 출시를 만듭니다.
리전 서비스 중단: 리전이 복원될 때까지 컨트롤 플레인 작업을 사용할 수 없으며 Cloud Deploy의 데이터도 사용할 수 없습니다. 리전 서비스 중단 발생 시 서비스를 더 쉽게 복원할 수 있도록 소스 제어에 배포 파이프라인과 대상 정의를 저장하는 것이 좋습니다. 이러한 구성 파일을 사용하여 작동하는 리전에서 Cloud Deploy 파이프라인을 다시 만들 수 있습니다. 서비스 중단 중에는 기존 버전의 데이터가 손실됩니다. 대상에 소프트웨어를 계속 배포하려면 새 출시 버전을 만드세요.
Cloud DNS
Cloud DNS는 비용 효율적인 방식으로 도메인 이름을 전역 DNS에 게시하는 복원력이 우수한 고성능 전역 DNS(도메인 이름 시스템) 서비스입니다.
영역 서비스 중단 시 Cloud DNS는 동일 또는 다른 리전에 있는 다른 영역의 요청을 중단 없이 계속 처리합니다. Cloud DNS 레코드 업데이트는 수신된 위치의 리전 내에서 영역 간에 동기적으로 복제됩니다. 따라서 데이터 손실이 발생하지 않습니다.
리전 서비스 중단의 경우 Cloud DNS는 다른 리전에서 요청을 계속 처리합니다. 업데이트가 단일 리전에서 먼저 처리된 후 다른 리전에 비동기적으로 복제되기 때문에 Cloud DNS 레코드에 대한 가장 최근의 업데이트는 제공되지 않을 수 있습니다.
Cloud Healthcare API
의료 데이터 저장 및 관리를 위한 서비스인 Cloud Healthcare API는 고가용성을 제공하도록 구축되었으며, 선택한 구성에 따라 영역 및 리전 장애 시 보호 기능을 제공합니다.
리전 구성: 해당 기본 구성에서 Cloud Healthcare API가 영영 장애에 대한 보호 기능을 제공합니다. 서비스는 한 리전의 3개 영역에 배포되고, 데이터도 리전 내 서로 다른 영역에 세 번씩 배포됩니다. 서비스 영역 또는 데이터 영역에 영향을 주는 영역 장애가 발생하면 남은 영역이 중단 없이 작업을 이어서 처리합니다. 리전 구성에서는 서비스가 있는 전체 리전에 중단이 발생할 경우 리전이 온라인으로 전환될 때까지 서비스를 사용할 수 없습니다. 전체 리전이 물리적으로 파괴되는 예측할 수 없는 상황이 발생하면 해당 리전에 저장된 데이터가 손실됩니다.
멀티 리전 구성: 멀티 리전 구성에서 Cloud Healthcare API는 3개의 서로 다른 리전에 속하는 3개 영역에 배포됩니다. 데이터도 3개 리전에 복제됩니다. 이렇게 하면 전체 리전이 중단되어도 남은 리전이 자동으로 서비스를 이어가므로 서비스가 중단되지 않습니다. FHIR과 같은 구조화된 데이터가 여러 리전에 동기적으로 복제되므로 전체 리전이 중단되어도 데이터가 손실되지 않습니다. DICOM 및 음성기록 또는 대형 HL7v2/FHIR 객체와 같이 Cloud Storage 버킷에 저장된 데이터는 여러 리전 간에 비동기식으로 복제됩니다.
Cloud ID
Cloud ID 서비스는 여러 리전에 배포되며 동적 부하 분산을 사용합니다. Cloud ID에서는 사용자가 리소스 범위를 선택할 수 없습니다. 특정 영역 또는 리전에서 서비스 중단이 발생하면 트래픽은 다른 영역 또는 리전으로 자동 배포됩니다.
대부분의 경우 영구 데이터는 동기식 복제를 사용하여 여러 리전에서 미러링됩니다. 캐시 또는 수많은 항목에 영향을 미치는 변경사항 등 성능상의 이유로 일부 시스템은 여러 리전에 걸쳐 비동기식으로 복제됩니다. 최신 데이터가 저장되는 기본 리전에 서비스 중단이 발생하면 Cloud ID는 기본 리전을 사용할 수 있을 때까지 다른 위치에서 비활성 데이터를 제공합니다.
Cloud Interconnect
Cloud Interconnect는 Google 피어링 에지에 연결된 물리적 케이블을 통해 온프레미스 데이터 센터에서 Google Cloud 네트워크에 대한 RFC 1918 액세스를 고객에게 제공합니다.
Cloud Interconnect는 대도시 지역에서 2개의 EAD(에지 가용성 도메인)에 대해 연결을 프로비저닝할 경우 99.9% SLA를 고객들에게 제공합니다. 99.99% SLA는 전역 라우팅과 함께 고객이 2개 대도시 지역에서 2개 EAD의 연결을 2개 리전에 프로비저닝할 때 가능합니다. 자세한 내용은 비핵심 애플리케이션용 토폴로지 개요 및 프로덕션 수준 애플리케이션용 토폴로지 개요를 참고하세요.
Cloud Interconnect는 컴퓨팅 영역에 독립적이고 EAD 형식으로 고가용성을 제공합니다. EAD 장애 시에는 해당 EAD에 대한 BGP 세션이 중단되고 트래픽이 다른 EAD로 장애 조치됩니다.
리전별 장애가 발생하면 해당 리전에 대한 BGP 세션이 중단되고 트래픽이 정상 리전의 리소스로 장애 조치됩니다. 전역 라우팅이 사용 설정된 경우에 적용됩니다.
Cloud Key Management Service
Cloud Key Management Service(Cloud KMS)는 확장 가능하고 견고한 암호화 키 리소스 관리를 제공합니다. Cloud KMS는 동기식 복제를 통해 높은 데이터 내구성과 가용성을 제공하는 Spanner 데이터베이스에 모든 데이터와 메타데이터를 저장합니다.
Cloud KMS 리소스는 단일 리전, 여러 리전 또는 전역에서 만들 수 있습니다.
영역 서비스 중단 발생 시 Cloud KMS는 같은 리전의 다른 영역 또는 다른 리전의 요청을 중단 없이 계속 처리합니다. 데이터는 동기식으로 복제되기 때문에 데이터가 손실되거나 손상되지 않습니다. 영역 서비스 중단이 해결되면 전체 중복성이 복원됩니다.
리전 서비스 중단이 발생한 경우 해당 리전을 다시 사용할 수 있을 때까지 해당 리전의 리전별 리소스는 오프라인 상태가 됩니다. 리전 내에서도 3개 이상의 복제본은 별도의 영역에서 유지관리됩니다. 높은 가용성이 필요한 경우 리소스를 멀티 리전 또는 전역 구성에 저장해야 합니다. 멀티 리전 및 전역 구성은 둘 이상의 리전에 데이터를 지리적으로 중복해 저장하고 제공하여 리전 서비스 중단에도 계속 사용할 수 있도록 설계되었습니다.
Cloud 외부 키 관리자(Cloud EKM)
Cloud 외부 키 관리자는 Cloud Key Management Service와 통합되어 지원되는 서드 파티 파트너를 통해 외부 키를 제어하고 액세스할 수 있습니다. 이러한 외부 키를 사용하여 고객 관리 암호화 키 (CMEK) 통합을 지원하는 다른 Google Cloud 서비스에 사용할 저장 데이터를 암호화할 수 있습니다.
영역 서비스 중단: Cloud 외부 키 관리자는 한 리전의 여러 영역에서 제공하는 중복성으로 인해 영역 서비스 중단에 대한 복원력이 우수합니다. 영역 서비스 중단이 발생하면 트래픽은 리전 내의 다른 영역으로 다시 라우팅됩니다. 트래픽이 리라우팅되는 동안 오류가 증가할 수 있지만 서비스는 계속 사용할 수 있습니다.
리전 서비스 중단: 영향을 받는 리전의 리전 서비스 중단 중에는 Cloud 외부 키 관리자를 사용할 수 없습니다. 리전 간에 요청을 리디렉션하는 장애 조치 메커니즘이 없습니다. 고객이 여러 리전을 사용하여 작업을 실행하는 것이 좋습니다.
Cloud External Key Manager는 고객 데이터를 영구적으로 저장하지 않습니다. 따라서 Cloud 외부 키 관리자 시스템 내에서는 리전 서비스 중단 시 데이터 손실은 발생하지 않습니다. 하지만 Cloud 외부 키 관리자는 Cloud Key Management Service 및 외부 서드 파티 공급업체와 같은 다른 서비스의 가용성에 따라 달라집니다. 리전 서비스 중단 시 해당 시스템이 실패하면 데이터가 손실될 수 있습니다. 이러한 시스템의 RPO/RTO는 Cloud 외부 키 관리자 약정 범위에 포함되지 않습니다.
Cloud Load Balancing
Cloud Load Balancing은 완전히 배포되는 소프트웨어 정의 관리형 서비스입니다. Cloud Load Balancing을 통해 단일 Anycast IP 주소가 전 세계 리전의 백엔드용 프런트엔드로 작동할 수 있습니다. 하드웨어 기반이 아니므로 물리적인 부하 분산 인프라를 관리할 필요가 없습니다. 부하 분산기는 가장 가용성이 높은 애플리케이션의 핵심 구성요소입니다.
Cloud Load Balancing은 리전 및 전역 부하 분산기를 모두 제공합니다. 또한 기본 백엔드가 양호하지 않을 경우 트래픽을 장애 조치 백엔드로 이동시키는 자동 멀티 리전 장애 조치 등 리전 간 부하 분산을 제공합니다.
전역 부하 분산기는 영역 및 리전 서비스 중단에 대해 복원력이 있습니다. 리전 부하 분산기는 영역 서비스 중단에 대해 복원력이 있지만 해당 리전에서의 서비스 중단의 영향을 받습니다. 그러나 어느 경우든 전체 애플리케이션의 복원력은 단지 배포하는 부하 분산기의 유형뿐만 아니라 백엔드의 중복성에 의해서도 달라진다는 것을 이해해야 합니다.
Cloud Load Balancing 및 해당 기능에 대한 자세한 내용은 Cloud Load Balancing 개요를 참조하세요.
Cloud Logging
Cloud Logging은 로그 라우터와 Cloud Logging 스토리지라는 두 가지 주요 부분으로 구성됩니다.
로그 라우터는 스트리밍 로그 이벤트를 처리하고 로그를 Cloud Storage, Pub/Sub, BigQuery 또는 Cloud Logging 스토리지로 전달합니다.
Cloud Logging 스토리지는 로그를 저장 및 쿼리하고 로그의 규정 준수를 관리하는 서비스로, 개발, 규정 준수, 문제 해결, 사전 알림을 포함하여 많은 사용자와 워크플로를 지원합니다.
로그 라우터 및 수신 로그: 영역 서비스 중단 시 Cloud Logging API가 리전의 다른 영역으로 로그를 라우팅합니다. 일반적으로 로그 라우터에서 Cloud Logging, BigQuery 또는 Pub/Sub으로 라우팅하는 로그는 최대한 빠르게 최종 대상에 기록되지만 Cloud Storage로 전송되는 로그는 매시간 버퍼링되고 일괄 기록됩니다.
로그 항목: 영역 또는 리전 서비스 중단 발생 시 영향을 받는 영역 또는 리전에서 버퍼링되었지만 내보내기 대상에 기록되지 않은 로그 항목에는 액세스할 수 없습니다. 로그 기반 측정항목은 로그 라우터에서 계산되며 동일한 제약조건이 적용됩니다. 선택된 로그 내보내기 위치로 전달된 로그는 대상 서비스에 따라 복제됩니다. Cloud Logging 스토리지로 내보낸 로그는 리전의 두 영역에 동기식으로 복제됩니다. 다른 대상 유형의 복제 동작은 이 문서의 관련 섹션을 참조하세요. Cloud Storage로 내보낸 로그는 매시간 일괄 처리되고 작성됩니다. 따라서 Cloud Logging 스토리지, BigQuery 또는 Pub/Sub를 사용하여 서비스 중단의 영향을 받는 데이터 양을 최소화하는 것이 좋습니다.
로그 메타데이터: 싱크 및 제외 구성과 같은 메타데이터는 전역적으로 저장되지만 리전별로 캐시되므로 서비스 중단 발생 시 리전 로그 라우터 인스턴스가 작동합니다. 단일 리전 서비스 중단은 리전 외부에는 영향을 미치지 않습니다.
Cloud Monitoring
Cloud Monitoring은 대시보드(기본 제공 및 사용자 정의), 알림, 업타임 모니터링 등 상호 연결된 다양한 기능으로 구성됩니다.
대시보드, 업타임 체크, 알림 정책을 비롯한 모든 Cloud Monitoring 구성은 전역으로 정의됩니다. 이러한 데이터에 대한 모든 변경사항은 여러 리전에 동기적으로 복제됩니다. 따라서 영역 및 리전 서비스 중단 중에 성공적인 구성 변경사항은 지속 가능합니다. 또한 영역 또는 리전이 처음 실패할 때 일시적인 읽기 및 쓰기 실패가 발생할 수 있지만 Cloud Monitoring은 사용 가능한 영역 및 리전으로 요청을 리라우팅합니다. 이 경우 지수 백오프로 구성 변경을 다시 시도할 수 있습니다.
특정 리소스용 측정항목 작성 시 Cloud Monitoring은 먼저 리소스가 있는 리전을 식별합니다. 그런 후 리전 내에서 독자적으로 세 개의 측정항목 데이터 복제본을 작성합니다. 세 개 중 한 개 쓰기가 성공하면 전체 리전의 측정항목 쓰기가 성공 반환됩니다. 세 복제본이 리전 내 서로 다른 영역에 있으리라는 보장은 없습니다.
영역: 영역 서비스 중단 시 영향을 받는 영역의 리소스에 대한 측정항목 쓰기 및 읽기를 완전히 사용할 수 없는 것은 아닙니다. 실제로 Cloud Monitoring은 영향을 받는 영역이 없는 것처럼 작동합니다.
리전: 리전 서비스 중단 시 영향을 받는 리전의 리소스에 대한 측정항목 쓰기 및 읽기를 완전히 사용할 수 없는 것은 아닙니다. 실제로 Cloud Monitoring은 영향을 받는 리전이 없는 것처럼 작동합니다.
Cloud NAT
Cloud NAT(네트워크 주소 변환)는 외부 IP 주소가 없는 특정 리소스에서 인터넷에 대한 아웃바운드 연결을 만들 수 있게 해주는 분산 소프트웨어 정의 관리형 서비스입니다. 프록시 VM 또는 어플라이언스를 기반으로 하지 않습니다. Cloud NAT는 Virtual Private Cloud(VPC) 네트워크를 지원하는 Andromeda 소프트웨어를 구성하여 외부 IP 주소가 없는 VM에 소스 네트워크 주소 변환(소스 NAT 또는 SNAT)이 제공되도록 합니다. Cloud NAT는 또한 설정된 인바운드 응답 패킷에만 목적지 네트워크 주소 변환(대상 NAT 또는 DNAT)을 제공합니다.
Cloud NAT의 기능에 대한 자세한 내용은 문서를 참조하세요.
영역 서비스 중단: 제어 영역과 네트워크 데이터 영역이 한 리전 내의 여러 영역에 중복되므로 Cloud NAT는 영역 장애에 대한 복원력이 우수합니다.
리전 서비스 중단: Cloud NAT는 리전 제품이므로 리전 장애를 견딜 수 없습니다.
Cloud Router
Cloud Router는 경계 게이트웨이 프로토콜 (BGP)을 사용하여 IP 주소 범위를 공지하는 완전 분산형 및 관리형 Google Cloud 서비스입니다. Cloud Router는 피어에서 수신하는 BGP 공지를 기반으로 동적 경로를 프로그래밍합니다. 각 Cloud Router는 실제 기기나 어플라이언스 대신 BGP 스피커와 반응자 역할을 하는 소프트웨어 태스크로 구성됩니다.
영역 서비스 중단이 발생한 경우 고가용성(HA) 구성을 사용하는 Cloud Router는 영역 장애에 대해 복원력이 있습니다. 이 경우 한 인터페이스에서 연결이 손실될 수 있지만 BGP를 사용하는 동적 라우팅을 통해 트래픽이 다른 인터페이스로 리디렉션됩니다.
리전 서비스 중단이 발생한 경우 Cloud Router는 리전별 제품이므로, 리전 장애를 견딜 수 없습니다. 고객이 전역 라우팅 모드를 사용 설정했으면 장애가 발생한 리전과 다른 리전 간의 라우팅에 영향을 줄 수 있습니다.
Cloud Run
Cloud Run은 고객이 Google 인프라에서 컨테이너화된 코드를 실행할 수 있는 스테이트리스(Stateless) 컴퓨팅 환경입니다. Cloud Run은 리전별 제품이므로 고객은 리전을 선택할 수 있지만 리전을 구성하는 영역은 선택할 수 없습니다. 데이터와 트래픽은 리전 내의 영역 간에 자동으로 분산됩니다. 컨테이너 인스턴스는 수신 트래픽을 충족하도록 자동으로 확장되며 필요에 따라 영역 간에 부하가 분산됩니다. 각 영역은 이 영역당 자동 확장을 제공하는 스케줄러를 유지합니다. 또한 다른 영역이 수신하는 부하를 인식하고 영역 내에서 추가 용량을 프로비저닝하여 영역 장애를 허용합니다.
Cloud Run GPU를 사용하는 경우 서비스의 영역 중복을 사용 중지하고 영역 중단 시 더 저렴한 비용으로 최선의 안정성을 대신 사용할 수 있습니다. 자세한 내용은 GPU 영역 중복 옵션을 참고하세요.
영역 서비스 중단: Cloud Run은 배포된 컨테이너와 메타데이터를 저장합니다. 이 데이터는 리전별로 저장되며 동기식으로 작성됩니다. Cloud Run Admin API는 데이터가 리전 내의 쿼럼에 커밋된 후에만 API 호출을 반환합니다. 데이터는 리전별로 저장되므로 데이터 영역 작업도 영역 장애의 영향을 받지 않습니다. 영역 장애가 발생하면 트래픽이 다른 영역으로 라우팅됩니다.
리전 서비스 중단: 고객이 Cloud Run 서비스를 만들 Google Cloud 리전을 선택합니다. 데이터는 리전 간에 복제되지 않습니다. 고객 트래픽은 Cloud Run에 의해 다른 리전으로 라우팅되지 않습니다. 리전 장애가 발생한 경우 서비스 중단이 해결되는 즉시 Cloud Run을 다시 사용할 수 있습니다. 고객은 원하는 경우 여러 리전에 배포하고 Cloud Load Balancing을 사용하여 가용성을 높이는 것이 좋습니다.
Cloud Shell
Cloud Shell은 Google Cloud 사용자에게 온보딩, 교육, 개발, 운영자 작업을 위해 사전 구성된 단일 사용자 Compute Engine 인스턴스에 대한 액세스 권한을 제공합니다.
Cloud Shell은 애플리케이션 워크로드를 실행하는 데 적합하지 않으며, 대신 대화형 개발 및 교육용 사용 사례에 적합합니다. 사용자별 런타임 할당량 제한이 있고, 짧은 시간 동안 비활성화되면 자동으로 종료되고, 할당된 사용자만 인스턴스에 액세스할 수 있습니다.
서비스를 지원하는 Compute Engine 인스턴스는 영역별 리소스이므로, 영역 서비스 중단이 발생했을 때 사용자의 Cloud Shell을 사용할 수 없습니다.
Cloud Source Repositories
Cloud Source Repositories를 사용하면 비공개 소스 코드 저장소를 만들고 관리할 수 있습니다. 이 제품은 전역 모델로 설계되었으므로 리전 및 영역 복원력을 구성할 필요가 없습니다.
대신 Cloud Source Repositories에 대한 git push 작업은 소스 저장소 업데이트를 여러 리전 간의 여러 영역에 동기식으로 복제합니다. 즉, 서비스가 한 리전의 중단에 대해 복원력을 갖습니다.
특정 영역 또는 리전에서 서비스 중단이 발생하면 트래픽은 다른 영역 또는 리전으로 자동 배포됩니다.
GitHub 또는 Bitbucket에서 저장소를 자동으로 미러링하는 기능은 이러한 제품의 문제에 영향을 받을 수 있습니다. 예를 들어 GitHub 또는 Bitbucket이 Cloud Source Repositories에 새 커밋을 알릴 수 없거나 Cloud Source Repositories가 업데이트된 저장소에서 콘텐츠를 검색할 수 없으면 미러링에 영향을 줍니다.
Spanner
Spanner는 관계형 시맨틱스를 사용해 확장 가능하고 가용성이 높은 다중 버전이며 동기식으로 복제된 strong consistency를 갖춘 데이터베이스입니다.
리전 Spanner 인스턴스는 단일 리전의 세 개 영역에 데이터를 동기식으로 복제합니다. 리전 Spanner 인스턴스에 대한 쓰기는 3개의 모든 복제본에 동기식으로 전송되고 복제본이 2개 이상(2/3의 다수 쿼럼) 쓰기를 커밋한 후 클라이언트에 확인됩니다. 이렇게 하면 최신 쓰기가 유지되고 복제본 2개로 쓰기의 다수 쿼럼을 계속 달성할 수 있으므로 Spanner가 모든 데이터에 대한 액세스를 제공하여 영역 장애에 대해 복원력이 우수하게 됩니다.
Spanner 멀티 리전 인스턴스에는 3개 리전에 있는 5개의 영역에 데이터를 동기식으로 복제하는 쓰기 쿼럼이 포함되어 있습니다(기본 최적 리전과 다른 리전 각각에 읽기-쓰기 복제본 2개, 감시 리전에 복제본 1개). 멀티 리전 Spanner 인스턴스에 대한 쓰기는 복제본이 3개 이상(3/5의 다수 쿼럼) 쓰기를 커밋한 후에 확인됩니다. 영역 또는 리전 장애가 발생하는 경우 쓰기가 클라이언트에 확인될 때 리전 2개의 3개 이상의 영역에서 데이터가 유지되므로 Spanner는 모든 데이터(최신 쓰기 포함)에 액세스할 수 있고 읽기/쓰기 요청을 처리합니다.
이러한 구성에 대한 자세한 내용은 Spanner 인스턴스 문서를 참고하고 Spanner 복제 방식에 대한 자세한 내용은 복제 문서를 참고하세요.
Cloud SQL
Cloud SQL은 MySQL, PostgreSQL, SQL Server를 위한 완전 관리형 관계형 데이터베이스 서비스입니다. Cloud SQL은 관리형 Compute Engine 가상 머신을 사용하여 데이터베이스 소프트웨어를 실행합니다. 또한 리전 중복을 위해 고가용성 구성을 제공하므로 영역 서비스 중단으로부터 데이터베이스를 보호합니다. 리전 간 복제본을 프로비저닝하여 리전 서비스 중단으로부터 데이터베이스를 보호할 수 있습니다. 이 제품은 영역 또는 리전 서비스 중단에 대한 복원력이 낮은 영역 옵션도 제공하므로 고가용성 구성, 리전 간 복제본, 또는 둘 다 선택할 때는 주의해야 합니다.
영역 서비스 중단: 고가용성 옵션은 한 리전 내 2개의 별도 영역에 기본 및 대기 VM 인스턴스를 만듭니다. 정상 작동 중에 기본 VM 인스턴스는 모든 요청을 처리하여 기본 및 대기 영역에 동기식으로 복제되는 리전 Persistent Disk에 데이터베이스 파일을 씁니다. 영역 서비스 중단이 기본 인스턴스에 영향을 미치는 경우 Cloud SQL은 Persistent Disk가 대기 VM에 연결되고 트래픽이 다시 라우팅되는 동안 장애 조치를 시작합니다.
이 프로세스 도중 데이터베이스를 초기화해야 하며, 여기에는 트랜잭션 로그에 기록되지만 데이터베이스에는 적용되지 않는 모든 트랜잭션 처리가 포함됩니다. 처리되지 않은 트랜잭션의 수와 유형에 따라 RTO 시간이 늘어날 수 있습니다. 최근 쓰기가 많으면 처리되지 않은 트랜잭션의 백로그가 발생할 수 있습니다. (a) 최근 쓰기 활동이 많거나 (b) 데이터베이스 스키마를 최근 변경한 경우 RTO 시간에 가장 큰 영향을 미칩니다.
마지막으로 영역 서비스 중단이 해결되었으면 수동으로 장애 복구 작업을 트리거하여 기본 영역에서 서비스 제공을 재개할 수 있습니다.
고가용성 옵션에 대한 자세한 내용은 Cloud SQL 고가용성 문서를 참조하세요.
리전 서비스 중단: 리전 간 복제본 옵션은 다른 리전에 있는 기본 인스턴스의 읽기 복제본을 만들어 리전 서비스 중단으로부터 데이터베이스를 보호합니다. 리전 간 복제는 비동기식 복제를 사용하므로 기본 인스턴스가 복제본에서 커밋되기 전에 트랜잭션을 커밋할 수 있습니다. 트랜잭션이 기본 인스턴스에서 커밋되는 시점과 복제본에서 커밋되는 시점 간의 시간 차이를 '복제 지연'이라고 부르며, 이는 모니터링할 수 있습니다. 이 측정항목은 기본 인스턴스에서 복제본으로 전송되지 않은 트랜잭션과 복제본에서 수신했지만 처리되지 않은 트랜잭션을 모두 반영합니다. 리전 서비스 중단 시 복제본으로 전송되지 않은 트랜잭션을 사용할 수 없게 됩니다. 복제본에서 수신했지만 처리하지 않은 트랜잭션은 아래의 설명대로 복구 시간에 영향을 미칩니다.
Cloud SQL은 복제 지연이 누적되지 않으며 가장 높게 지속되는 TPS인 '안전한 TPS(Transaction Per Second)' 한도를 설정하기 위해 복제본이 포함된 구성으로 워크로드를 테스트할 것을 권장합니다. 워크로드가 안전한 TPS 한도를 초과하면 복제 지연이 누적되어 RPO 및 RTO 값에 부정적인 영향을 미칩니다. 일반적으로 복제 지연에 민감한 소규모 인스턴스 구성(vCPU 코어 2개 미만, 디스크 100GB 미만, PD-HDD)은 사용하지 않는 것이 좋습니다.
리전 서비스 중단이 발생하면 읽기 복제본을 수동으로 승격할지 여부를 결정해야 합니다. 승격은 수동 작업인데, 승격 시점에 기본 인스턴스가 지연되어도 승격된 복제본이 새로운 트랜잭션을 허용하는 분할 브레인 시나리오가 발생할 수 있기 때문입니다. 이로 인해 리전 서비스 중단이 해결될 때 문제가 발생할 수 있으며 기본 인스턴스에서 복제본 인스턴스로 절대 전파되지 않는 트랜잭션을 조정해야 합니다. 이 경우 사용자의 요구를 충족하는 데 문제가 되면 Spanner와 같은 리전 간 동기식 복제 데이터베이스 제품 사용을 고려할 수 있습니다.
사용자가 트리거한 승격 프로세스는 고가용성 구성에서 대기 인스턴스를 활성화하는 것과 유사한 단계를 따릅니다. 이 과정에서 읽기 복제본은 트랜잭션 로그를 처리해야 하며, 이는 총 복구 시간을 늘립니다. 복제본 승격에는 내장 부하 분산기가 포함되지 않으므로 승격된 기본 노드로 애플리케이션을 수동으로 리디렉션하세요.
리전 간 복제본 옵션에 대한 자세한 내용은 Cloud SQL 리전 간 복제본 문서를 참조하세요.
Cloud SQL DR에 대한 자세한 내용은 다음을 참고하세요.
Cloud Storage
Cloud Storage는 확장성과 내구성이 우수하며 전 세계적으로 통합된 객체 스토리지입니다. Cloud Storage 버킷은 하나의 대륙 내에서 단일 리전, 이중 리전, 멀티 리전의 세 가지 유형 중 하나의 위치에 만들 수 있습니다. 리전별 버킷을 사용하면 단일 리전의 가용성 영역 간에 객체가 중복되어 저장됩니다. 반면에 이중 리전 및 멀티 리전 버킷은 지리적으로 중복됩니다. 즉, 새로 작성된 데이터가 하나 이상의 원격 리전에 복제된 후 객체가 여러 리전에 중복되어 저장됩니다. 이러한 접근 방법은 리전별 스토리지로 얻을 수 있는 것보다 더 광범위한 방식으로 이중 리전 및 멀티 리전 버킷의 데이터를 보호합니다.
리전별 버킷은 단일 가용성 영역에 중단이 발생하더라도 복원력을 갖도록 설계되었습니다. 영역에 서비스 중단이 발생하면 사용 불가능한 영역의 객체가 해당 리전의 다른 위치에서 자동으로 투명하게 제공됩니다. 데이터와 메타데이터는 초기 쓰기부터 여러 영역에 중복으로 저장됩니다. 영역을 사용할 수 없게 되어도 기록된 데이터가 손실되지 않습니다. 리전 서비스 중단이 발생한 경우 해당 리전을 다시 사용할 수 있을 때까지 해당 리전의 리전 버킷은 오프라인 상태가 됩니다.
더 높은 가용성이 필요하면 이중 리전 또는 멀티 리전 구성에 데이터를 저장할 수 있습니다. 이중 리전 및 멀티 리전 버킷은 단일 버킷(별도의 기본 및 보조 위치가 없음)이지만 리전 간에 데이터 및 메타데이터를 중복하여 저장합니다. 리전 서비스 중단이 발생해도 서비스가 중단되지 않습니다. 이중 리전 및 멀티 리전 버킷은 버킷이 strong consistency를 유지하면서 둘 이상 리전에서 워크로드를 동시에 읽고 쓸 수 있다는 점에서 활성-활성으로 간주될 수 있습니다. 이는 재해 복구 아키텍처의 일부로 두 리전 간에 워크로드를 분할하려는 고객에게 특히 매력적일 수 있습니다.
이중 리전 및 멀티 리전은 메타데이터가 항상 여러 리전 간에 동기적으로 기록되기 때문에 strong consistency를 갖습니다. 이러한 접근 방법을 따르면 항상 객체의 최신 버전과 원격 리전을 포함한 서비스 제공 가능 위치를 확인할 수 있습니다.
데이터는 비동기적으로 복제됩니다. 즉, 일정 RPO 기간 동안 단일 리전 내 가용성 영역에 걸쳐 중복성이 지원되고 새로 작성된 객체가 리전별 객체로 보호됩니다. 그런 다음 이 RPO 기간 내에 서비스가 하나 이상의 원격 리전에 객체를 복제하고 지리적 중복성을 만듭니다. 복제가 완료되면 리전별 서비스 중단이 발생할 경우 다른 리전에서 자동으로 그리고 투명하게 데이터를 제공할 수 있습니다. 터보 복제는 새로 작성된 객체를 100% 복제하고 15분 내에 지리적 중복성을 갖는 것을 목표로 해서 더 작은 RPO 기간을 얻기 위해 이중 리전 버킷에서 제공되는 프리미엄 기능입니다.
RPO는 중요한 고려 사항입니다. 리전 서비스 중단 기간 중에 RPO 기간 내에서 최근에 해당 리전에 기록된 데이터가 아직 다른 리전에 복제되지 않을 수 있기 때문입니다. 따라서 서비스 중단 중 데이터에 액세스하지 못할 수 있고, 영향을 받는 리전에서 데이터를 물리적으로 삭제하는 경우 손실될 수 있습니다.
Cloud Translation
Cloud Translation은 여러 영역 및 리전에 활성 컴퓨팅 서버를 갖고 있습니다. 또한 리전 내 영역 간 동기식 데이터 복제도 지원합니다. 이러한 기능을 통해 Translation은 영역 장애에 대한 데이터 손실 없이 그리고 고객 입력 또는 조정을 필요로 하지 않고 즉각적인 장애 조치를 달성할 수 있습니다. 리전 장애가 발생하면 Cloud Translation을 사용할 수 없습니다.
Compute Engine
Compute Engine은 Google Cloud의 Infrastructure as a Service 옵션 중 하나입니다. Google의 글로벌 인프라를 사용하여 가상 머신과 관련 서비스를 고객에게 제공합니다.
Compute Engine 인스턴스는 영역별 리소스이므로 영역 서비스 중단 발생 시 인스턴스가 기본으로 제공되지 않습니다. Compute Engine은 단일 영역 내 및 단일 리전 내 여러 영역에서 사전 구성된 인스턴스 템플릿의 추가 VM을 자동으로 확장할 수 있는 관리형 인스턴스 그룹(MIG)입니다. MIG는 영역 손실에 대해 복원력이 우수하고 스테이트리스(Stateless)이지만 구성 및 리소스 계획이 필요한 애플리케이션에 적합합니다. 스테이트리스(Stateless) 애플리케이션의 리전 서비스 중단을 복원하는 데 여러 리전 MIG를 사용할 수 있습니다.
스테이트풀(Stateful) 워크로드가 있는 애플리케이션도 스테이트풀(Stateful) MIG를 사용할 수 있지만 수평으로 확장되지 않기 때문에 용량 계획 시 특히 주의해야 합니다. 어느 시나리오에서든 Compute Engine 인스턴스 템플릿과 MIG를 올바르게 구성하고 테스트하여 다른 영역으로의 장애 조치가 제대로 작동하는지 사전에 확인하는 것이 중요합니다. 자세한 내용은 위 자체 참조 아키텍처 및 가이드 개발 섹션을 참조하세요.
단독 테넌시
단독 테넌시를 사용하면 프로젝트의 VM만 호스팅하는 물리적 Compute Engine 서버인 단독 테넌트 노드에 독점적으로 액세스할 수 있습니다.
Compute Engine 인스턴스와 같은 단독 테넌트 노드는 영역별 리소스입니다. 드물지만 영역 서비스 중단이 발생하면 사용할 수 없습니다. 영역 장애를 완화하려면 다른 영역에 단독 테넌트 노드를 만들면 됩니다. 특정 워크로드에서 라이선스 또는 CAPEX 회계 목적으로 단독 테넌트 노드의 이점을 활용할 수 있으므로 개발자는 사전에 장애 조치 전략을 계획해야 합니다.
이러한 리소스를 다른 위치에 다시 만들면 추가 라이선스 비용이 발생하거나 CAPEX 회계 요구사항을 위반할 수 있습니다. 일반적인 안내는 자체 참조 아키텍처 및 가이드 개발을 참고하세요.
단독 테넌트 노드는 영역별 리소스이며 리전 장애를 감당할 수 없습니다. 영역 간에 확장하려면 리전 MIG를 사용하세요.
Compute Engine용 네트워킹
Interconnect 연결을 위한 고가용성 설정에 대한 자세한 내용은 다음 문서를 참조하세요.
전역 또는 리전 모드에서 외부 IP 주소를 프로비저닝할 수 있으며, 이렇게 하면 리전 장애가 발생할 경우 가용성에 영향을 미칩니다.
Cloud Load Balancing 복원력
부하 분산기는 가장 가용성이 높은 애플리케이션의 핵심 구성요소입니다. 전체 애플리케이션의 복원력은 선택한 부하 분산기 범위(전역 또는 리전)뿐만 아니라 백엔드 서비스의 중복성에 따라 달라진다는 점을 이해해야 합니다.
다음 표에는 부하 분산기의 분산 또는 범위에 따른 부하 분산기 복원력이 요약되어 있습니다.
| 부하 분산기 범위 | 아키텍처 | 영역 서비스 중단에 대한 복원력 | 리전 서비스 중단에 대한 복원력 |
|---|---|---|---|
| 전역 | 각 부하 분산기가 모든 리전에 분산됩니다. | ||
| 리전 간 | 각 부하 분산기가 여러 리전에 분산됩니다. | ||
| 리전 | 각 부하 분산기가 해당 리전의 여러 영역에 분산됩니다. | 지정된 리전에서의 중단은 해당 리전의 리전 부하 분산기에 영향을 줍니다. |
부하 분산기 선택에 대한 자세한 내용은 Cloud Load Balancing 문서를 참조하세요.
연결 테스트
연결 테스트는 네트워크 엔드포인트 간 연결을 확인할 수 있게 해주는 진단 도구입니다. 구성을 분석하고 경우에 따라 엔드포인트 간에 실시간 데이터 영역 분석을 수행합니다. 엔드포인트란 VM, Google Kubernetes Engine(GKE) 클러스터, 부하 분산기 전달 규칙 또는 인터넷 IP 주소와 같은 네트워크 트래픽의 소스나 대상을 의미합니다. 연결 테스트는 데이터 영역 구성요소가 없는 진단 도구입니다. 사용자 트래픽을 처리하거나 생성하지 않습니다.
영역 서비스 중단: 연결 테스트 리소스는 전역입니다. 영역 서비스 중단이 발생하면 이를 관리하고 볼 수 있습니다. 연결 테스트 리소스는 구성 테스트 결과입니다. 이러한 결과에는 영향을 받는 영역에 있는 영역별 리소스(예: VM 인스턴스)의 구성 데이터가 포함될 수 있습니다. 분석은 서비스 중단 이전의 비활성 데이터를 기반으로 수행되므로 서비스 중단이 발생한 경우 분석 결과가 정확하지 않습니다. 분석 결과에 의존하지 마세요.
리전 서비스 중단: 리전 서비스 중단에서도 연결 테스트 리소스를 관리하고 볼 수 있습니다. 연결 테스트 리소스에는 영향을 받는 리전에 있는 리전별 리소스(예: 서브네트워크)의 구성 데이터가 포함될 수 있습니다. 분석은 서비스 중단 이전의 비활성 데이터를 기반으로 수행되므로 서비스 중단이 발생한 경우 분석 결과가 정확하지 않습니다. 분석 결과에 의존하지 마세요.
Container Registry
Container Registry는 안전한 비공개 방식으로 Docker 컨테이너 이미지를 저장하는 확장 가능한 호스팅된 Docker 레지스트리를 구현합니다. Container Registry는 HTTP Docker Registry API를 구현합니다.
Container Registry는 기본적으로 이미지 메타데이터를 여러 영역 및 리전에 중복 저장하는 전역 서비스입니다. 컨테이너 이미지는 Cloud Storage 멀티 리전 버킷에 저장됩니다. 이 스토리지 전략을 통해 Container Registry는 모든 경우에 대해 영역 서비스 중단 복원력을 제공하고, Cloud Storage에서 여러 리전에 비동기적으로 복제한 모든 데이터에 대해서는 리전 서비스 중단 복원력을 제공합니다.
Database Migration Service
Database Migration Service는 다른 클라우드 제공업체의 데이터베이스 또는 온프레미스 데이터 센터의 데이터베이스를 Google Cloud로 마이그레이션하는 완전 관리형 Google Cloud 서비스입니다.
Database Migration Service는 리전 제어 영역으로 설계되었습니다. 제어 영역은 지정된 리전의 개별 영역과 관계없습니다. 영역 서비스 중단이 발생해도 마이그레이션 작업을 만들고 관리하는 기능을 포함하여 Database Migration Service API에 대한 액세스 권한은 유지됩니다. 리전 서비스 중단 시 서비스 중단이 해결될 때까지 해당 리전에 속하는 Database Migration Service 리소스에 액세스할 수 없습니다.
Database Migration Service는 마이그레이션 프로세스에 사용되는 소스 및 대상 데이터베이스의 가용성에 따라 다릅니다. Database Migration Service 소스 또는 대상 데이터베이스를 사용할 수 없으면 마이그레이션이 진행되지 않지만 고객 핵심 데이터 또는 작업 데이터가 손실되지 않습니다. 소스 및 대상 데이터베이스를 다시 사용할 수 있게 되면 마이그레이션 작업이 다시 시작됩니다.
예를 들어 고가용성(HA)이 사용 설정된 대상 Cloud SQL 데이터베이스를 구성하여 영역 서비스 중단에 대한 복원력이 우수한 대상 데이터베이스를 가져올 수 있습니다.
Database Migration Service 마이그레이션은 두 단계를 거칩니다.
- 전체 덤프: 마이그레이션 작업 사양에 따라 소스에서 대상으로 전체 데이터 복사를 수행합니다.
- 변경 데이터 캡처(CDC): 소스에서 대상으로의 증분 변경사항을 복제합니다.
영역 서비스 중단: 이러한 단계 중 하나에서 영역 장애가 발생해도 Database Migration Service에서 리소스에 계속 액세스하고 관리할 수 있습니다. 데이터 마이그레이션은 다음과 같이 영향을 받습니다.
- 전체 덤프: 데이터 마이그레이션이 실패할 시 대상 데이터베이스가 장애 조치 작업을 완료하면 마이그레이션 작업을 다시 시작해야 합니다.
- CDC: 데이터 마이그레이션이 일시중지됩니다. 대상 데이터베이스가 장애 조치 작업을 완료하면 마이그레이션 작업이 자동으로 다시 시작됩니다.
리전 서비스 중단: Database Migration Service는 리전 간 리소스를 지원하지 않으므로 리전 장애에 대한 복원력이 우수하지 않습니다.
Dataflow
Dataflow는 스트리밍 및 일괄 파이프라인을 위한 Google Cloud의 완전 관리형 서버리스 데이터 처리 서비스입니다. 기본적으로 리전 엔드포인트는 리전 내에서 사용 가능한 모든 영역을 사용하도록 Dataflow 작업자 풀을 구성합니다. 영역 선택은 작업자가 생성될 때 각 작업자에 대해 계산되어 리소스 획득 및 미사용 예약 사용에 최적화됩니다. Dataflow 작업의 기본 구성에서 중간 데이터는 Dataflow 서비스에 의해 저장되고 작업 상태는 백엔드에 저장됩니다. 다른 영역에서 작업자가 다시 생성되므로 영역에 장애가 발생해도 Dataflow 작업이 계속 실행될 수 있습니다.
다음과 같은 제한사항이 적용됩니다.
- 리전 배치는 Streaming Engine 또는 Dataflow Shuffle을 사용하는 작업에만 지원됩니다. Streaming Engine 또는 Dataflow Shuffle을 선택 해제한 작업은 리전 배치를 사용할 수 없습니다.
- 리전 배치는 VM에만 적용됩니다. Streaming Engine 및 Dataflow Shuffle 관련 리소스에는 적용되지 않습니다.
- VM은 여러 영역 간에 복제되지 않습니다. VM을 사용할 수 없게 되면 작업 항목이 손실된 것으로 간주되어 다른 VM에서 다시 처리됩니다.
- 리전 전체에서 소진이 발생하면 Dataflow 서비스는 더 이상 VM을 만들 수 없습니다.
고가용성을 위한 Dataflow 파이프라인 설계
고가용성 데이터 처리를 위해 여러 스트리밍 파이프라인을 동시에 실행할 수 있습니다. 예를 들어 서로 다른 리전에서 두 개의 병렬 스트리밍 작업을 실행할 수 있습니다. 병렬 파이프라인은 데이터 처리를 위한 지리적 중복성과 내결함성을 제공합니다. 데이터 소스 및 싱크의 지리적 가용성을 고려하여 가용성이 높은 멀티 리전 구성에서 엔드 투 엔드 파이프라인을 운영할 수 있습니다. 자세한 내용은 'Dataflow 파이프라인 워크플로 설계'의 고가용성 및 지리적 중복성을 참조하세요.
영역 또는 리전 서비스 중단 발생 시 동일한 Pub/Sub 주제 구독을 재사용하여 데이터 손실을 방지할 수 있습니다. 셔플 중에 레코드가 손실되지 않도록 Dataflow는 업스트림 백업을 사용합니다. 즉, 레코드를 전송하는 작업자가 레코드 수신에 대한 긍정 확인을 받을 때까지 RPC를 재시도하고, 레코드 처리에 따른 부작용이 영구 스토리지 다운스트림에 커밋됩니다. 또한 Dataflow는 레코드를 전송하는 작업자가 사용 불가능한 상태가 될 때까지 RPC를 계속 재시도합니다. RPC를 재시도하면 모든 레코드가 단 한 번만 전송됩니다. Dataflow의 정확히 한 번 처리 보장에 대한 자세한 내용은 Dataflow에서 단 한 번 처리을 참조하세요.
파이프라인에서 그룹화 또는 기간 설정을 사용하는 경우 영역 또는 리전 서비스 중단 후 Pub/Sub의 탐색 기능 또는 Kafka의 재생 기능을 사용하여 데이터 요소가 동일한 계산 결과에 도달하도록 재처리할 수 있습니다. 파이프라인에 사용된 비즈니스 로직이 서비스 중단 전의 데이터와 관계없다면 파이프라인 출력의 데이터 손실을 0개 요소까지 최소화할 수 있습니다. 예를 들어 긴 슬라이드 기간을 사용하거나 전역 기간에 계속 증가하는 카운터가 저장되는 경우와 같이 파이프라인 비즈니스 로직이 서비스 중단 전에 처리된 데이터와 관계있는 경우 Dataflow 스냅샷을 사용하여 스트리밍 파이프라인의 상태를 저장하고 상태 손실 없이 새 버전의 작업을 시작합니다.
Dataproc
Dataproc은 스트리밍 및 일괄 데이터 처리 기능을 제공합니다. Dataproc은 사용자가 Dataproc 클러스터를 관리할 수 있게 해주는 리전 제어 영역으로 설계되었습니다. 제어 영역은 지정된 리전의 개별 영역과 관계없습니다. 따라서 영역 서비스 중단이 발생해도 새 클러스터 생성 기능을 포함하여 Dataproc API에 대한 액세스 권한은 유지됩니다.
다음에서 Dataproc 클러스터를 만들 수 있습니다.
Compute Engine용 Dataproc 클러스터
Compute Engine의 Dataproc 클러스터는 영역별 리소스이므로 영역 서비스 중단 발생 시 클러스터를 사용할 수 없게 되거나 클러스터가 삭제됩니다. Dataproc은 클러스터 상태에 대한 스냅샷을 자동으로 만들지 않으므로 영역 서비스 중단으로 인해 데이터가 손실될 수 있습니다. Dataproc은 서비스 내에 사용자 데이터를 유지하지 않습니다. 사용자는 여러 데이터 스토어에 결과를 기록하도록 파이프라인을 구성할 수 있습니다. 단, 데이터 스토어의 아키텍처를 고려하고 필요한 재해 복원력을 갖춘 제품을 선택해야 합니다.
영역에 서비스 중단이 발생하면 다른 영역을 선택하거나 사용 가능한 영역을 자동으로 선택하는 Dataproc의 자동 배치 기능을 사용하여 다른 영역에서 클러스터의 새 인스턴스를 다시 만들 수 있습니다. 클러스터를 사용할 수 있게 되면 데이터 처리가 다시 시작됩니다. 고가용성 모드가 사용 설정된 클러스터를 실행하면 부분 영역 서비스 중단이 마스터 노드와 전체 클러스터에 영향을 줄 가능성이 줄어듭니다.
GKE용 Dataproc 클러스터
GKE용 Dataproc 클러스터는 영역별 또는 리전별 리소스일 수 있습니다.
영역 및 리전 GKE 클러스터의 아키텍처와 DR 기능에 대한 자세한 내용은 이 문서 뒷부분의 Google Kubernetes Engine 섹션을 참조하세요.
Datastream
Datastream은 최소한의 지연 시간으로 데이터를 안정적으로 동기화할 수 있게 해주는 서버리스 변경 데이터 캡처 (CDC) 및 복제 서비스입니다. Datastream은 운영 데이터베이스에서 BigQuery 및 Cloud Storage로의 데이터 복제를 지원합니다. 또한 Dataflow 템플릿과의 간소화된 통합을 제공해 Cloud SQL 및 Spanner와 같은 다양한 대상에 데이터를 로드하는 커스텀 워크플로를 빌드할 수 있습니다.
영역 서비스 중단: Datastream은 멀티 영역 서비스입니다. 데이터 또는 가용성 손실 없이 완전하고 계획되지 않은 영역 서비스 중단에 대처할 수 있습니다. 영역 장애가 발생해도 Datastream에서 리소스에 계속 액세스하고 관리할 수 있습니다.
리전 서비스 중단: 리전 서비스 중단이 발생한 경우 서비스 중단이 해결되는 즉시 Datastream을 다시 사용할 수 있습니다.
Document AI
Document AI는 문서 이해 플랫폼으로, 문서에서 비정형 데이터를 추출하여 정형 데이터로 변환함으로써 사용자가 보다 쉽게 이해하고 분석하고 사용할 수 있도록 도와줍니다. Document AI는 리전별 제품입니다. 고객은 리전을 선택할 수 있지만 해당 리전 내의 영역은 선택할 수 없습니다. 데이터와 트래픽은 리전 내의 영역 간에 자동으로 분산됩니다. 서버는 수신 트래픽을 충족하도록 자동으로 확장되며 필요에 따라 영역 간에 부하가 분산됩니다. 각 영역은 이 영역당 자동 확장을 제공하는 스케줄러를 유지합니다. 스케줄러는 다른 영역이 수신하는 부하를 인식하고 영역 내에서 추가 용량을 프로비저닝하여 영역 장애를 허용합니다.
영역 서비스 중단: Document AI는 사용자 문서와 프로세서 버전 데이터를 저장합니다. 이 데이터는 리전별로 저장되고 동기식으로 기록됩니다. 데이터는 리전별로 저장되므로 데이터 영역 작업은 영역 장애의 영향을 받지 않습니다. 영역 장애가 발생하면 트래픽은 Vertex AI와 같은 종속 서비스가 복구하는 데 걸리는 시간에 따라 지연이 발생하는 다른 영역으로 자동 라우팅됩니다.
리전 서비스 중단: 데이터는 리전 간에 복제되지 않습니다. 리전 서비스 중단 시 Document AI는 장애 조치되지 않습니다. 고객이 Document AI를 사용할 Google Cloud 리전을 선택합니다. 그러나 해당 고객 트래픽은 다른 리전으로 라우팅되지 않습니다.
엔드포인트 확인
관리자 및 보안 운영 전문가는 엔드포인트 확인을 통해 조직 데이터에 액세스하는 기기 인벤토리를 빌드할 수 있습니다. 엔드포인트 확인은 Chrome Enterprise Premium 솔루션의 일부로 중요한 기기 신뢰와 보안 기반 액세스 제어를 제공합니다.
조직의 노트북 및 데스크톱 기기의 보안 상태 개요를 확인하려면 엔드포인트 확인을 사용합니다. 엔드포인트 확인을 Chrome Enterprise Premium 제품과 페어링한 경우 엔드포인트 확인을 사용하면 Google Cloud 리소스에 대한 세분화된 액세스 제어를 적용할 수 있습니다.
엔드포인트 확인은 Google Cloud, Cloud ID, Google Workspace Business, Google Workspace Enterprise에서 사용할 수 있습니다.
Eventarc
Eventarc는 상태 변경에 반응하는 느슨하게 결합된 서비스를 사용하여 Google 제공업체(자사), 사용자 앱(세컨드파티), Software as a Service(서드파티)에서 비동기적으로 제공되는 이벤트를 제공합니다. 이를 통해 고객은 이벤트 제공업체 서비스 또는 고객 코드에서 이벤트가 발생할 때 트리거되도록 대상 (예: Cloud Run 인스턴스 또는 2세대 Cloud Run 함수)을 구성할 수 있습니다.
영역 서비스 중단: Eventarc는 트리거와 관련된 메타데이터를 저장합니다. 이 데이터는 리전별로 저장되고 동기식으로 기록됩니다. 트리거와 채널을 만들고 관리하는 Eventarc API는 데이터가 리전 내의 쿼럼에 커밋된 후에만 API 호출을 반환합니다. 데이터는 리전별로 저장되므로 데이터 영역 작업은 영역 장애의 영향을 받지 않습니다. 영역 장애가 발생하면 트래픽은 자동으로 다른 영역으로 라우팅됩니다. 세컨드파티 및 서드파티 이벤트를 수신 및 제공하는 Eventarc 서비스는 영역 간에 복제됩니다. 이러한 서비스는 지역별로 분산되어 있습니다. 사용 불가능한 영역에 대한 요청은 해당 리전의 사용 가능한 영역에서 자동으로 처리됩니다.
리전 서비스 중단: 고객이 Eventarc 트리거를 만들 Google Cloud 리전을 선택합니다. 데이터는 리전 간에 복제되지 않습니다. 고객 트래픽은 Eventarc에 의해 다른 리전으로 라우팅되지 않습니다. 리전 장애가 발생한 경우 서비스 중단이 해결되는 즉시 Eventarc를 다시 사용할 수 있습니다. 가용성을 높이려면 원하는 경우 여러 리전에 트리거를 배포하는 것이 좋습니다.
다음에 유의하세요.
- 서드 파티 이벤트를 수신 및 제공하는 Eventarc 서비스는 최선의 방식으로 제공되며 RTO/RPO가 적용되지 않습니다.
- Google Kubernetes Engine 서비스의 Eventarc 이벤트 전송은 최선을 다해 제공되며 RTO/RPO가 적용되지 않습니다.
Filestore
기본 및 영역 등급은 영역별 리소스입니다. 이는 배포된 영역 또는 리전의 장애를 허용하지 않습니다.
리전 등급 Filestore 인스턴스는 리전별 리소스입니다. Filestore는 NFS에 필요한 엄격한 일관성 정책을 적용합니다. 클라이언트가 데이터를 쓸 경우, Filestore는 후속 읽기에서 올바른 데이터를 반환하도록 변경사항이 지속되고 두 영역에 복제될 때까지 확인을 반환하지 않습니다.
영역 오류가 발생할 경우 리전 등급 인스턴스는 계속해서 다른 영역의 데이터를 제공하고, 그동안 새 쓰기를 허용합니다. 읽기 작업과 쓰기 작업 모두 성능이 저하될 수 있으며, 쓰기 작업은 복제되지 않을 수 있습니다. 키는 다른 영역에서 제공되므로 암호화가 손상되지 않습니다.
동일한 리전의 다른 영역에서 추가 서비스 중단이 발생할 경우 클라이언트가 외부 백업을 만드는 것이 좋습니다. 백업을 사용하여 인스턴스를 다른 리전으로 복원할 수 있습니다.
Firestore
Firestore는 Firebase 및 Google Cloud의 모바일, 웹, 서버 개발에 사용되는 유연하고 확장 가능한 데이터베이스입니다. Firestore는 자동 멀티 리전 데이터 복제, 강력한 일관성 보장, 원자적 일괄 작업, ACID 트랜잭션을 제공합니다.
Firestore는 고객에게 단일 리전 및 멀티 리전 위치를 모두 제공합니다. 트래픽은 리전의 영역 간에 자동으로 부하 분산됩니다.
리전 Firestore 인스턴스는 3개 이상의 영역에 데이터를 동기식으로 복제합니다. 영역 장애의 경우 나머지 두 개 이상의 복제본에서 쓰기를 커밋할 수 있으며 커밋된 데이터는 유지됩니다. 트래픽은 자동으로 다른 영역으로 라우팅됩니다. 리전 위치는 비용을 절감하고 쓰기 지연 시간을 단축하며 다른 Google Cloud리소스와의 코로케이션을 제공합니다.
Firestore 멀티 리전 인스턴스는 3개 리전(2개의 제공 리전과 1개의 감시 리전)에서 5개의 영역에 데이터를 동기식으로 복제하며, 영역 및 리전 장애에 대비합니다. 영역 또는 리전 장애가 발생해도 커밋된 데이터는 유지됩니다. 트래픽은 자동으로 서비스 영역/리전으로 라우팅되며, 커밋은 남아 있는 두 리전의 영역 3개 이상에서 계속 제공됩니다. 멀티 리전은 데이터베이스 가용성과 내구성을 극대화합니다.
방화벽 통계
방화벽 통계는 방화벽 규칙을 이해하고 최적화하는 데 도움이 됩니다. 방화벽 규칙 사용 방법에 대한 통계, 권장사항 및 측정항목을 제공합니다. 또한 방화벽 통계는 머신러닝을 사용하여 이후의 방화벽 규칙 사용을 예측합니다. 방화벽 통계를 사용하면 방화벽 규칙을 최적화하는 동안 더 나은 결정을 내릴 수 있습니다. 예를 들어 방화벽 통계는 과도한 권한이 부여된 것으로 분류되는 규칙을 식별합니다. 이 정보를 사용하여 방화벽 구성을 더 엄격하게 만들 수 있습니다.
영역 서비스 중단: 방화벽 통계 데이터가 영역 간에 복제되므로 영역 서비스 중단의 영향을 받지 않으며 고객 트래픽은 자동으로 다른 영역으로 라우팅됩니다.
리전 서비스 중단: 방화벽 통계 데이터가 리전 간에 복제되므로 리전 서비스 중단의 영향을 받지 않으며 고객 트래픽은 자동으로 다른 리전으로 라우팅됩니다.
Fleet
Fleet을 사용하면 고객이 여러 Kubernetes 클러스터를 그룹으로 관리하고 플랫폼 관리자가 멀티 클러스터 서비스를 사용할 수 있습니다. 예를 들어 Fleet를 사용하면 관리자가 모든 클러스터에 균일한 정책을 적용하거나 멀티 클러스터 인그레스를 설정할 수 있습니다.
GKE 클러스터를 Fleet에 등록하면 기본적으로 클러스터는 동일 리전에 리전 멤버십이 있습니다.Google Cloud 이 아닌 클러스터를 Fleet에 등록할 때는 리전이나 전역 위치를 선택할 수 있습니다. 클러스터의 물리적 위치와 가까운 리전을 선택하는 것이 좋습니다. 이렇게 하면 Connect 게이트웨이를 사용하여 클러스터에 액세스할 때 최적의 지연 시간이 제공됩니다.
영역 서비스 중단이 발생해도 기본 클러스터가 영역 클러스터이며 사용할 수 없게 되지 않는 한 Fleet 기능은 영향을 받지 않습니다.
리전 서비스 중단의 경우 리전 내 멤버십 클러스터의 Fleet 기능이 정적으로 실패합니다. 리전 서비스 중단을 완화하려면 클라우드 인프라 서비스 중단의 재해 복구 설계에 설명된 대로 여러 리전에 배포해야 합니다.
Google Cloud Armor
Cloud Armor를 사용하면 대규모 DDoS 공격과 교차 사이트 스크립팅 및 SQL 삽입과 같은 애플리케이션 공격을 포함한 여러 유형의 위협으로부터 배포와 애플리케이션을 보호할 수 있습니다. Cloud Armor는 Google Cloud 부하 분산기에서 원치 않는 트래픽을 필터링하고 이러한 트래픽이 VPC로 들어와서 리소스를 소비하지 못하도록 합니다. 이러한 보호 조치 중 일부는 자동으로 적용됩니다. 일부의 경우 보안 정책을 구성하고 이를 백엔드 서비스 또는 리전에 연결해야 합니다. 전역 범위의 Cloud Armor 보안 정책은 전역 부하 분산기에 적용됩니다. 리전 범위의 보안 정책은 리전 부하 분산기에 적용됩니다.
영역 서비스 중단: 영역 서비스 중단이 발생하면 Google Cloud 부하 분산기가 정상 백엔드 인스턴스를 사용할 수 있는 다른 영역으로 트래픽을 리디렉션합니다. Cloud Armor 보안 정책이 리전의 모든 영역에 동기식으로 복제되기 때문에 트래픽 장애 조치 후 즉시 Cloud Armor 보호를 사용할 수 있습니다.
리전 서비스 중단: 리전 서비스 중단이 발생하면 전역 Google Cloud 부하 분산기가 정상 백엔드 인스턴스를 사용할 수 있는 다른 리전으로 트래픽을 리디렉션합니다. 전역 Cloud Armor 보안 정책이 모든 리전에 동기적으로 복제되기 때문에 트래픽 장애 조치 후 즉시 Cloud Armor 보호를 사용할 수 있습니다. 리전 장애에 대한 복원력을 갖추려면 모든 리전에 Cloud Armor 리전 보안 정책을 구성해야 합니다.
Google Kubernetes Engine
Google Kubernetes Engine (GKE)은 Google Cloud에서 컨테이너화된 애플리케이션의 배포 과정을 간소화하여 관리형 Kubernetes 서비스를 제공합니다. 리전 또는 영역 클러스터 토폴로지 중에서 선택할 수 있습니다.
- 영역 클러스터를 만들 때 GKE는 선택된 영역에 1개의 제어 영역 머신과 동일한 영역 내에 작업자 머신(노드)을 프로비저닝합니다.
- 리전 클러스터의 경우 GKE는 선택된 리전 내 3개 영역에서 3개의 제어 영역 머신을 프로비저닝합니다. 기본적으로 노드는 3개 영역에 걸쳐 있지만 한 영역에서만 프로비저닝된 노드를 사용하여 리전 클러스터를 만들 수 있습니다.
- 멀티 영역 클러스터는 하나의 마스터 머신을 포함하고 있다는 점에서 영역 클러스터와 비슷하지만 여러 영역에 걸쳐 있는 노드를 포괄하는 기능을 추가로 제공합니다.
영역 서비스 중단: 영역 서비스 중단을 방지하려면 리전 클러스터를 사용하세요. 제어 영역과 노드는 한 리전에 있는 3개 영역에 배포됩니다. 영역 서비스 중단은 다른 두 영역에 배포된 제어 영역과 워커 노드에는 영향을 미치지 않습니다.
리전 서비스 중단: 리전 서비스 중단을 완화하려면 여러 리전에 배포해야 합니다. 현재 기본 제공 제품 기능으로 제공되지는 않지만 여러 GKE 고객이 멀티 리전 토폴로지를 채택하고 있으며 이 접근 방식은 수동으로 구현할 수 있습니다. 여러 리전 클러스터를 생성하여 여러 리전에 걸쳐 워크로드를 복제하고 멀티 클러스터 인그레스를 사용하여 이러한 클러스터에 대한 트래픽을 제어할 수 있습니다.
HA VPN
HA VPN(고가용성)은 온프레미스 프라이빗 클라우드, 기타 Virtual Private Cloud, 기타 클라우드 서비스 제공업체 네트워크에서 Google Cloud Virtual Private Cloud(VPC)로 트래픽을 안전하게 암호화하는 복원력이 우수한 Cloud VPN 제품입니다.
HA VPN의 게이트웨이에는 최적의 중복성을 보장하기 위해 서로 다른 PoP 및 클러스터에 논리적이고 물리적으로 분할된 별도의 IP 주소 풀에서 각각의 IP 주소가 있는 두 개의 인터페이스가 있습니다.
영역 서비스 중단: 영역 서비스 중단 시 한 인터페이스의 연결이 끊어질 수 있지만, 트래픽은 BGP(Border Gateway Protocol)를 사용하여 동적 라우팅을 통해 다른 인터페이스로 리디렉션됩니다.
리전 서비스 중단: 리전 서비스 중단 시 두 인터페이스 모두 잠시 동안 연결이 끊어질 수 있습니다.
Identity and Access Management
Identity and Access Management(IAM)는 클라우드 리소스의 작업에 대한 모든 승인 결정을 담당합니다. IAM은 정책이 각 작업(데이터 영역)에 대해 권한을 부여하는지 확인하고 SetPolicy 호출(제어 영역)을 통해 이러한 정책에 대한 업데이트를 처리합니다.
모든 IAM 정책이 모든 리전 내의 여러 영역에 걸쳐서 복제되므로, IAM 데이터 영역 작업이 다른 리전의 장애로부터 복구되고 각 리전 내에 영역 장애가 있어도 이를 견딜 수 있습니다. 영역 장애 및 리전 장애에 대한 IAM 데이터 영역의 복원력에 따라 고가용성을 위한 멀티 리전 및 다중 영역 아키텍처가 지원됩니다.
IAM 제어 영역 작업은 교차 리전 복제에 따라 달라질 수 있습니다. SetPolicy 호출이 성공하면 데이터가 멀티 리전에 기록되지만 다른 리전에 대한 전파가 eventual consistency를 갖습니다.
IAM 제어 영역은 단일 리전 장애에 대해 복원력이 있습니다.
IAP(Identity-Aware Proxy)
Identity-Aware Proxy는 Google Cloud, 다른 클라우드 및 온프레미스에서 호스팅되는 애플리케이션에 대한 액세스 권한을 제공합니다. IAP는 리전별로 배포되며, 사용 불가능한 영역에 대한 요청이 해당 리전의 다른 사용 가능한 영역에서 자동으로 처리됩니다.
IAP에서 리전 서비스 중단이 발생하면 해당 리전에서 호스팅되는 애플리케이션에 대한 액세스에 영향을 줍니다. 리전 중단에 대해 더 높은 가용성과 복원력을 얻기 위해서는 여러 리전에 배포하고 Cloud Load Balancing을 사용하는 것이 좋습니다.
Identity Platform
Identity Platform을 사용하면 고객이 맞춤설정 가능한 Google 수준의 ID 및 액세스 관리를 앱에 추가할 수 있습니다. Identity Platform은 전 세계에서 제공됩니다. 고객은 데이터가 저장되는 리전이나 영역을 선택할 수 없습니다.
영역 서비스 중단: 영역 서비스 중단 시 Identity Platform은 요청을 다음으로 가까운 셀로 장애 조치합니다. 모든 데이터는 전역 규모로 저장되므로 데이터 손실이 없습니다.
리전 서비스 중단: 리전 서비스 중단 시 Identity Platform이 영향을 받는 리전에서 트래픽을 삭제하는 동안 사용할 수 없는 리전에 대한 Identity Platform 요청이 일시적으로 실패합니다. 영향을 받는 리전으로 더 이상 트래픽이 전송되지 않으면 전역 서버 부하 분산 서비스가 요청을 사용 가능한 가장 가까운 정상 리전으로 라우팅합니다. 모든 데이터가 전역적으로 저장되므로 데이터 손실이 발생하지 않습니다.
Knative serving
Knative serving은 고객이 고객 클러스터에서 서버리스 워크로드를 실행할 수 있게 해주는 전역 서비스입니다. 목적은 Knative serving 워크로드가 고객 클러스터에 올바르게 배포되고 Knative serving의 설치 상태가 GKE Fleet API 기능 리소스에 반영되도록 하는 것입니다. 이 서비스는 고객 클러스터에 Knative serving 리소스를 설치하거나 업그레이드할 때만 참여합니다. 클러스터 워크로드 실행에는 관여하지 않습니다. Knative 서비스가 사용 설정된 프로젝트에 속하는 고객 클러스터는 여러 리전과 영역의 복제본 사이에 분산되며 각 클러스터는 하나의 복제본에 의해 모니터링됩니다.
영역 및 리전 서비스 중단: 서비스 중단이 발생한 위치에서 호스팅된 복제본에 의해 모니터링되는 클러스터는 다른 영역 및 리전의 정상 복제본 간에 자동으로 재분배됩니다. 이 재할당이 진행되는 동안 일부 클러스터가 Knative serving에 의해 모니터링되지 않는 짧은 시간이 있을 수 있습니다. 이 기간 동안 사용자가 클러스터에서 Knative serving 기능을 사용 설정하기로 결정한 경우, 클러스터가 정상 Knative serving 서비스 복제본에 다시 연결되면 클러스터에 Knative serving 리소스 설치가 시작됩니다.
Looker(Google Cloud 핵심 서비스)
Looker (Google Cloud 핵심 서비스)은 Google Cloud 콘솔에서 Looker 인스턴스의 단순화되고 간소화된 프로비저닝, 구성, 관리를 제공하는 비즈니스 인텔리전스 플랫폼입니다. Looker(Google Cloud 핵심 서비스)를 사용하면 사용자가 데이터를 탐색하고, 대시보드를 만들고, 알림을 설정하고, 보고서를 공유할 수 있습니다. 또한 Looker(Google Cloud 핵심 서비스)는 데이터 모델러를 위한 IDE와 개발자를 위한 다양한 임베딩 및 API 기능을 제공합니다.
Looker(Google Cloud 핵심 서비스)는 리전 내의 영역 간에 데이터를 동기식으로 복제하는 리전별로 격리된 인스턴스로 구성됩니다. Looker(Google Cloud 핵심 서비스)가 연결된 데이터 소스 등 인스턴스가 사용하는 리소스가 인스턴스가 실행되는 위치와 동일한 리전에 있는지 확인하세요.
영역 서비스 중단: Looker(Google Cloud 핵심 서비스) 인스턴스는 메타데이터 및 자체 배포된 컨테이너를 저장합니다. 데이터는 복제된 인스턴스 간에 동기식으로 기록됩니다. 영역 서비스 중단 시 Looker(Google Cloud 핵심 서비스) 인스턴스는 동일한 리전의 다른 사용 가능한 영역에서 계속 제공됩니다. 데이터가 리전 내의 쿼럼에 커밋된 후에 트랜잭션 또는 API 호출이 반환됩니다. 복제가 실패하면 트랜잭션이 커밋되지 않고 사용자에게 실패에 관한 알림이 전송됩니다. 두 개 이상의 영역에서 장애가 발생하면 트랜잭션도 실패하고 사용자에게 알림이 전송됩니다. Looker(Google Cloud 핵심 서비스)는 현재 실행 중인 일정 또는 쿼리를 중지합니다. 실패를 해결한 후 다시 예약하거나 대기열에 추가해야 합니다.
리전 서비스 중단: 영향을 받는 리전 내의 Looker(Google Cloud 핵심 서비스) 인스턴스는 사용할 수 없습니다. Looker(Google Cloud 핵심 서비스)는 현재 실행 중인 일정 또는 쿼리를 중지합니다. 실패를 해결한 후 쿼리를 다시 예약하거나 대기열에 추가해야 합니다. 다른 리전에서 새 인스턴스를 수동으로 만들 수 있습니다. Looker(Google Cloud 핵심 서비스) 인스턴스에서 데이터 가져오기 또는 내보내기에 정의된 프로세스를 사용하여 인스턴스를 복구할 수도 있습니다. 지역 중단이 발생할 가능성이 낮은 경우에 대비하여 사전에 애셋을 복사할 수 있도록 주기적인 데이터 내보내기 프로세스를 설정하는 것이 좋습니다.
Looker Studio
Looker Studio는 데이터 시각화 및 비즈니스 인텔리전스 제품입니다. 고객은 이를 사용해서 다른 시스템에 저장된 데이터에 연결하고, 이 데이터를 사용해서 보고서 및 대시보드를 만들고, 조직 전반에 걸쳐 보고서 및 대시보드를 공유할 수 있습니다. Looker Studio는 전역 서비스이며 사용자가 리소스 범위를 선택할 수 없습니다.
영역 서비스 중단이 발생한 경우에도 Looker Studio는 동일 리전 또는 다른 리전의 다른 영역에서 발행하는 요청을 중단 없이 계속 처리할 수 있습니다. 사용자 애셋은 리전 간에 동기식으로 복제됩니다. 따라서 데이터 손실이 발생하지 않습니다.
리전 서비스 중단이 발생해도 Looker Studio는 중단 없이 다른 리전의 요청을 계속 처리할 수 있습니다. 사용자 애셋은 리전 간에 동기식으로 복제됩니다. 따라서 데이터 손실이 발생하지 않습니다.
Memorystore for Memcached
Memorystore for Memcached는 Google Cloud's 관리형 Memcached 제품입니다. Memorystore for Memcached를 사용하면 고객이 애플리케이션에 대한 고처리량 키-값 데이터베이스로 사용할 수 있는 Memcached 클러스터를 만들 수 있습니다.
Memcached 클러스터는 모든 고객 지정 영역에 노드가 분산되는 리전별 구성입니다. 하지만 Memcached는 노드 간에 데이터를 복제하지 않습니다. 따라서 부분 캐시 플러시의 설명과 같이 영역 장애로 인해 데이터 손실이 발생할 수 있습니다. Memcached 인스턴스는 계속 작동하지만 노드 수가 줄어들고 영역 장애 발생 시 서비스가 새 노드를 시작하지 않습니다. 영역 장애로 인해 영역이 복구될 때까지 캐시 적중률이 감소하더라도 영향을 받지 않는 영역의 Memcached 노드는 계속 트래픽을 처리합니다.
리전 장애가 발생하면 Memcached 노드가 트래픽을 제공하지 않습니다. 이 경우 데이터가 손실되어 전체 캐시 플러시가 수행됩니다. 리전 서비스 중단을 완화하려면 여러 리전에 걸쳐서 애플리케이션 및 Memorystore for Memcached를 배포하는 아키텍처를 구현할 수 있습니다.
Memorystore for Redis
Memorystore for Redis는 복잡한 Redis 배포 관리의 부담을 줄여주는 Google Cloud의 완전 관리형 Redis 서비스입니다. 현재 기본 등급과 표준 등급이라는 2가지 등급이 있습니다. 기본 등급의 경우 영역 또는 리전 서비스 중단으로 인해 데이터 손실이 발생하며, 전체 캐시 플러시라고도 합니다. 표준 등급의 경우 리전 서비스 중단으로 인해 데이터 손실이 발생합니다. 영역 서비스 중단은 비동기 복제로 인해 표준 등급 인스턴스에서 부분 데이터 손실이 발생할 수 있습니다.
영역 서비스 중단: 표준 등급 인스턴스는 기본 노드의 데이터 세트에서 복제본 노드로 데이터 세트 작업을 비동기식으로 복제합니다. 기본 노드의 영역 내에서 중단이 발생하면 복제본 노드가 기본 노드로 승격됩니다. 승격 중에 장애 조치가 발생하고 Redis 클라이언트가 인스턴스에 다시 연결해야 합니다. 다시 연결한 후에는 작업이 다시 시작됩니다. 표준 등급의 Memorystore for Redis 인스턴스의 고가용성에 대한 자세한 내용은 Memorystore for Redis 고가용성을 참조하세요.
표준 등급 인스턴스에서 읽기 복제본을 사용 설정하고 복제본이 하나만 있는 경우 영역 서비스 중단 기간 동안 읽기 엔드포인트를 사용할 수 없습니다. 읽기 복제본의 재해 복구에 대한 자세한 내용은 읽기 복제본의 장애 모드를 참조하세요.
리전 서비스 중단: Memorystore for Redis는 리전 제품이므로 단일 인스턴스가 리전 장애를 견딜 수 없습니다. 주기적인 작업을 예약하여 Redis 인스턴스를 다른 리전의 Cloud Storage 버킷으로 내보낼 수 있습니다. 리전 서비스 중단이 발생하면 내보낸 데이터 세트를 통해 다른 리전에서 Redis 인스턴스를 복원할 수 있습니다.
멀티 클러스터 서비스 검색 및 멀티 클러스터 인그레스
GKE 멀티 클러스터 서비스(MCS)는 여러 구성요소로 이루어집니다. 구성요소에는 Google Kubernetes Engine 허브(멤버십을 사용하여 여러 Google Kubernetes Engine 클러스터 조정), 클러스터 자체, GKE 허브 컨트롤러(멀티 클러스터 인그레스, 멀티 클러스터 서비스 검색)가 포함됩니다. 허브 컨트롤러는 여러 클러스터의 백엔드를 사용하여 Compute Engine 부하 분산기 구성을 오케스트레이션합니다.
영역 서비스 중단이 발생해도 멀티 클러스터 서비스 검색이 계속 다른 영역 또는 리전에서 요청을 처리합니다. 리전 서비스 중단이 발생해도 멀티 클러스터 서비스 검색은 장애 조치를 수행하지 않습니다.
멀티 클러스터 인그레스에 대해 영역 서비스 중단이 발생하면 구성 클러스터가 영역 클러스터이고 오류 범위 내에 있는 경우 사용자가 수동으로 장애 조치를 해야 합니다. 데이터 영역은 잠시 동작하며 사용자가 장애 조치를 할 때까지 트래픽을 계속 제공합니다. 수동 장애 조치가 필요하지 않도록 하려면 구성 클러스터에 리전 클러스터를 사용하세요.
리전 서비스 중단이 발생해도 멀티 클러스터 인그레스는 장애 조치를 수행하지 않습니다. 사용자는 구성 클러스터를 수동으로 장애 조치하기 위한 DR 계획이 있어야 합니다. 자세한 내용은 멀티 클러스터 인그레스 설정 및 멀티 클러스터 서비스 구성을 참고하세요.
GKE에 대한 자세한 내용은 클라우드 인프라 서비스 중단의 재해 복구 설계의 'Google Kubernetes Engine' 섹션을 참조하세요.
네트워크 분석기
네트워크 분석기는 VPC 네트워크 구성을 자동으로 모니터링하고 잘못된 구성과 최적화되지 않은 구성을 탐지합니다. 네트워크 토폴로지, 방화벽 규칙, 경로, 구성 종속 항목, 서비스와 애플리케이션 연결에 대한 유용한 정보를 제공합니다. 네트워크 장애를 식별하고 근본 원인 정보를 제공하며 가능한 해결 방법을 제안합니다.
네트워크 분석기는 지속적으로 실행되며 네트워크의 구성 업데이트에 따라 거의 실시간으로 관련 분석을 트리거합니다. 네트워크 분석기에서 네트워크 오류를 감지하면 근본 원인을 파악하기 위해 오류와 최근 구성 변경사항과의 상관관계를 파악하려고 합니다. 가능한 경우 추천을 제공하여 문제 해결 방법에 대한 세부정보를 제안합니다.
네트워크 분석기는 데이터 영역 구성요소가 없는 진단 도구입니다. 사용자 트래픽을 처리하거나 생성하지 않습니다.
영역 서비스 중단: 네트워크 분석기 서비스는 전역적으로 복제되며 가용성은 영역 서비스 중단의 영향을 받지 않습니다.
네트워크 분석기의 통계에 서비스 중단이 발생한 영역의 구성이 포함된 경우 데이터 품질이 영향을 받습니다. 해당 영역의 구성을 참조하는 네트워크 통계가 비활성화됩니다. 서비스 중단 시 네트워크 분석기에서 제공하는 통계에 의존하지 마세요.
리전 서비스 중단: 네트워크 분석기 서비스는 전역적으로 복제되며 가용성은 리전 서비스 중단의 영향을 받지 않습니다.
네트워크 분석기의 통계에 서비스 중단이 발생한 리전의 구성이 포함된 경우 데이터 품질이 영향을 받습니다. 해당 리전의 구성을 참조하는 네트워크 통계가 비활성화됩니다. 서비스 중단 시 네트워크 분석기에서 제공하는 통계에 의존하지 마세요.
네트워크 토폴로지
네트워크 토폴로지는 네트워크 인프라의 토폴로지를 보여주는 시각화 도구입니다. 인프라 뷰에서 가상 프라이빗 클라우드(VPC) 네트워크, 온프레미스 네트워크와의 하이브리드 연결, Google 관리 서비스에 대한 연결, 관련 측정항목을 보여줍니다.
영역 서비스 중단: 영역 서비스 중단이 발생하면 해당 영역의 데이터가 네트워크 토폴로지에 표시되지 않습니다. 다른 영역의 데이터는 영향을 받지 않습니다.
리전 서비스 중단:리전 서비스 중단이 발생하면 해당 리전의 데이터가 네트워크 토폴로지에 표시되지 않습니다. 다른 지역의 데이터는 영향을 받지 않습니다.
성능 대시보드
성능 대시보드를 사용하면 전체 Google Cloud 네트워크 성능과 프로젝트 리소스 성능을 확인할 수 있습니다.
이러한 성능 모니터링 기능을 사용하면 애플리케이션의 문제와 기본 Google Cloud 네트워크의 문제를 구분할 수 있습니다. 이전 네트워크 성능 문제를 조사할 수도 있습니다. 또한 성능 대시보드는 데이터를 Cloud Monitoring으로 내보냅니다. Monitoring을 사용하여 데이터를 쿼리하고 추가 정보에 액세스할 수 있습니다.
영역 서비스 중단:
영역 서비스 중단의 경우 영향을 받는 영역의 트래픽에 대한 지연 시간 및 패킷 손실 데이터가 성능 대시보드에 표시되지 않습니다. 다른 영역의 트래픽에 대한 지연 시간 및 패킷 손실 데이터는 영향을 받지 않습니다. 서비스 중단이 종료되면 지연 시간 및 패킷 손실 데이터의 표시가 재개됩니다.
리전 서비스 중단:
리전 서비스 중단의 경우 영향을 받는 리전의 트래픽에 대한 지연 시간 및 패킷 손실 데이터가 성능 대시보드에 표시되지 않습니다. 다른 리전의 트래픽에 대한 지연 시간 및 패킷 손실 데이터는 영향을 받지 않습니다. 서비스 중단이 종료되면 지연 시간 및 패킷 손실 데이터의 표시가 재개됩니다.
Network Connectivity Center
Network Connectivity Center는 허브 및 스포크 아키텍처를 사용하는 네트워크 연결 관리 제품입니다. 이 아키텍처에서는 중앙 관리 리소스가 허브 역할을 하고 각 연결 리소스가 스포크 역할을 합니다. 하이브리드 스포크는 현재 주요 타사 공급업체의 HA VPN, Dedicated Interconnect 및 Partner Interconnect, SD-WAN 라우터 어플라이언스를 지원합니다. 기업은 네트워크 연결 센터 하이브리드 스포크를 사용하여 Google Cloud 워크로드와 서비스를 Google Cloud 네트워크의 글로벌 도달 범위를 통해 온프레미스 데이터 센터, 다른 클라우드, 지사에 연결할 수 있습니다.
영역 서비스 중단: HA 구성이 있는 Network Connectivity Center 하이브리드 스포크는 제어 영역과 네트워크 데이터 영역이 한 리전 내의 여러 영역에 중복되므로 영역 장애에 대한 복원력이 우수합니다.
리전 서비스 중단: Network Connectivity Center 하이브리드 스포크는 리전별 리소스이므로 리전 장애를 견딜 수 없습니다.
네트워크 서비스 등급
네트워크 서비스 등급을 사용하면 인터넷에 있는 시스템과 Google Cloud 인스턴스 사이의 연결을 최적화할 수 있습니다. 네트워크 서비스 등급에는 프리미엄 등급과 표준 등급이라는 두 가지 서비스 등급이 있습니다. 프리미엄 등급을 사용하면 전역으로 공지되는 애니캐스트 프리미엄 등급 IP 주소가 리전 또는 전역 백엔드의 프런트엔드 역할을 할 수 있습니다. 표준 등급을 사용하면 리전별로 공지되는 표준 등급 IP 주소가 리전 백엔드의 프런트엔드 역할을 할 수 있습니다. 애플리케이션의 전반적인 복원력은 네트워크 서비스 등급과 연결된 백엔드의 중복성에 의해 영향을 받습니다.
영역 서비스 중단: 프리미엄 등급과 표준 등급은 모두 리전 중복 백엔드와 연결될 때 영역 서비스 중단에 대한 복원력을 제공합니다. 영역 서비스 중단이 발생하는 경우 리전 중복 백엔드를 사용하는 경우의 장애 조치 동작은 연결된 백엔드 자체에 의해 결정됩니다. 영역 백엔드와 연결된 경우 서비스 중단이 해결되는 즉시 서비스를 다시 사용할 수 있게 됩니다.
리전 서비스 중단: 프리미엄 등급은 전역 중복 백엔드와 연결될 때 리전 서비스 중단에 대한 복원력을 제공합니다. 표준 등급에서는 영향을 받는 리전에 대한 모든 트래픽이 실패합니다. 다른 모든 리전에 대한 트래픽은 영향을 받지 않습니다. 리전 서비스 중단이 발생하는 경우 전역 중복 백엔드와 함께 프리미엄 등급을 사용하는 경우의 장애 조치 동작은 연결된 백엔드 자체에 의해 결정됩니다. 리전 백엔드와 함께 프리미엄 등급을 사용하거나 표준 등급을 사용하는 경우 서비스 중단이 해결되는 즉시 서비스를 다시 사용할 수 있게 됩니다.
조직 정책 서비스
조직 정책 서비스는 조직의 Google Cloud 리소스를 중앙에서 프로그래매틱 방식으로 제어할 수 있는 기능을 제공합니다. 조직 정책 관리자는 전체 리소스 계층 구조에 걸쳐 제약 조건을 구성할 수 있습니다.
영역 서비스 중단: 조직 정책 서비스에서 생성된 모든 조직 정책은 모든 리전 내의 여러 영역에 비동기식으로 복제됩니다. 조직 정책 데이터와 컨트롤 플레인 작업은 각 리전 내에서 영역 오류를 허용합니다.
리전 서비스 중단: 조직 정책 서비스에서 생성된 모든 조직 정책은 여러 리전에 비동기식으로 복제됩니다. 조직 정책 컨트롤 플레인 작업은 여러 리전에 작성되며 다른 리전으로의 전파는 몇 분 이내에 일관됩니다. 조직 정책 컨트롤 플레인은 단일 리전 장애에 대해 복원력이 있습니다. 조직 정책 데이터 영역 작업은 다른 리전의 장애로부터 복구할 수 있으며 영역 장애 및 리전 장애에 대한 조직 정책 데이터 영역의 복원력에 따라 고가용성을 위한 멀티 리전 및 다중 영역 아키텍처가 지원됩니다.
패킷 미러링
패킷 미러링은 Virtual Private Cloud(VPC) 네트워크에서 지정된 인스턴스의 트래픽을 클론하여 검사를 위해 클론된 데이터를 리전 내부 부하 분산기 뒤에 있는 인스턴스로 전달합니다. 패킷 미러링은 페이로드와 헤더를 포함한 모든 트래픽과 패킷 데이터를 캡처합니다.
패킷 미러링 기능에 대한 자세한 내용은 패킷 미러링 개요 페이지를 참고하세요.
영역 서비스 중단: 여러 영역에 인스턴스가 있도록 내부 부하 분산기를 구성합니다. 영역 서비스 중단이 발생하면 패킷 미러링이 복제된 패킷을 정상 영역으로 전환합니다.
리전 서비스 중단: 패킷 미러링은 리전별 제품입니다. 리전 중단이 발생하면 영향을 받는 리전의 패킷이 클론되지 않습니다.
Persistent Disk
Persistent Disk는 영역 및 리전 구성에서 사용할 수 있습니다.
영역 Persistent Disk는 단일 영역에서 호스팅됩니다. 디스크의 영역을 사용할 수 없는 경우 영역 서비스 중단이 해결될 때까지 Persistent Disk를 사용할 수 없습니다.
리전 Persistent Disk는 리전의 두 영역 간에 데이터를 동기식으로 복제합니다. 가상 머신의 영역에 서비스 중단이 발생하면 디스크의 보조 영역에 있는 VM 인스턴스에 리전 Persistent Disk를 강제 연결할 수 있습니다. 이 작업을 수행하려면 해당 영역에서 다른 VM 인스턴스를 시작하거나 해당 영역에서 상시 대기 VM 인스턴스를 유지해야 합니다.
리전 간 영구 디스크에서 데이터를 비동기식으로 복제하려면 영구 디스크 비동기 복제 (PD 비동기 복제)를 사용하면 됩니다. 이 기능은 리전 간 활성-수동 DR을 위해 낮은 RTO 및 RPO 블록 스토리지 복제를 제공합니다. 드물게 발생하는 리전 중단의 경우에도 PD 비동기 복제를 사용하면 데이터를 보조 리전으로 장애 조치하고 이 리전에서 워크로드를 다시 시작할 수 있습니다.
Personalized Service Health
Personalized Service Health는 Google Cloud 프로젝트와 관련된 서비스 중단을 전달합니다. 다음을 포함하여 여러 채널과 프로세스를 제공하여 중단을 유발하는 이벤트(이슈, 계획된 유지보수)를 보거나 이슈 대응 프로세스에 통합합니다.
- Google Cloud 콘솔의 대시보드
- 서비스 API
- 맞춤 알림
- 생성되어 Cloud Logging으로 전송된 로그
영역 서비스 중단: 특정 위치에서 데이터가 종속 항목 없이 전역 데이터베이스에서 제공됩니다. 영역 서비스 중단이 발생하면 Service Health가 요청을 처리하고 자동으로 트래픽을 계속 작동하는 같은 리전의 영역으로 다시 라우팅할 수 있습니다. Service Health는 Service Health 데이터베이스에서 이벤트 데이터를 검색할 수 있으면 API 호출을 성공적으로 반환할 수 있습니다.
리전 서비스 중단: 특정 위치에서 데이터가 종속 항목 없이 전역 데이터베이스에서 제공됩니다. 리전 서비스 중단이 발생해도 Service Health는 요청을 계속 처리할 수 있지만 감소된 용량으로 수행할 수 있습니다. Logging 위치에서 리전 오류가 발생하면 로그나 Cloud Alerting 알림을 사용하는 Service Health 사용자가 영향을 받을 수 있습니다.
Private Service Connect
Private Service Connect는 소비자가 VPC 네트워크 내부에서 비공개로 관리형 서비스에 액세스할 수 있도록 허용하는 Google Cloud네트워킹 기능입니다. 마찬가지로 이를 이용해 관리형 서비스 프로듀서는 이러한 서비스를 별도의 개별 VPC 네트워크에서 호스팅하고 소비자에게 비공개 연결을 제공할 수 있습니다.
게시된 서비스용 Private Service Connect 엔드포인트
Private Service Connect 엔드포인트는 Private Service Connect 전달 규칙을 사용하여 서비스 프로듀서 VPC 네트워크의 서비스에 연결됩니다. 서비스 프로듀서는 단일 서비스 연결을 노출하여 서비스 소비자에게 비공개 연결을 사용하는 서비스를 제공합니다. 그러면 서비스 소비자가 해당 서비스에 대해 VPC의 가상 IP 주소를 할당할 수 있습니다.
영역 서비스 중단: 소비자 VPC 클라이언트 엔드포인트에서 생성된 VM 트래픽에서 발생하는 Private Service Connect 트래픽은 서비스 프로듀서의 내부 VPC 네트워크에서 노출된 관리형 서비스에 계속 액세스할 수 있습니다. Private Service Connect 트래픽이 다른 영역에 있는 정상 서비스 백엔드로 장애 조치되기 때문에 이 액세스가 가능합니다.
리전 서비스 중단: Private Service Connect는 리전별 제품입니다. 리전 서비스 중단에 대한 복원력이 우수하지 않습니다. 멀티 리전 관리형 서비스는 여러 리전에 Private Service Connect 엔드포인트를 구성하여 리전 서비스 중단 시 고가용성을 달성할 수 있습니다.
Google API용 Private Service Connect 엔드포인트
Private Service Connect 엔드포인트는 Private Service Connect 전달 규칙을 사용하여 Google API에 연결합니다. 이 전달 규칙을 사용하면 고객이 내부 IP 주소와 함께 맞춤 엔드포인트 이름을 사용할 수 있습니다.
영역 서비스 중단: VM과 엔드포인트 간의 연결이 자동으로 동일한 리전의 다른 기능 영역으로 장애 조치되기 때문에 소비자 VPC 클라이언트 엔드포인트의 Private Service Connect 트래픽은 Google API에 계속 액세스할 수 있습니다. 서비스 중단이 시작될 때 이미 진행 중인 요청은 복구를 위해 클라이언트의 TCP 제한 시간 및 재시도 동작에 따라 달라집니다.
자세한 내용은 Compute Engine 복구를 참고하세요.
리전 서비스 중단: Private Service Connect는 리전별 제품입니다. 리전 서비스 중단에 대한 복원력이 우수하지 않습니다. 멀티 리전 관리형 서비스는 여러 리전에 Private Service Connect 엔드포인트를 구성하여 리전 서비스 중단 시 고가용성을 달성할 수 있습니다.
Private Service Connect에 대한 자세한 내용은 Private Service Connect 유형의 '엔드포인트' 섹션을 참고하세요.
Pub/Sub
Pub/Sub는 애플리케이션 통합 및 스트림 분석을 위한 메시징 서비스입니다. Pub/Sub 주제는 전역 리소스이므로 모든 Google Cloud 위치에서 해당 주제를 보고 액세스할 수 있습니다. 그러나 특정 메시지는 리소스 위치 정책에 따라 게시자와 가장 가까운 단일 Google Cloud 리전에 저장됩니다. 따라서 하나의 주제에는 Google Cloud전반의 여러 리전에 저장된 메시지가 있을 수 있습니다. Pub/Sub 메시지 스토리지 정책은 메시지가 저장되는 리전을 제한할 수 있습니다.
영역 서비스 중단: Pub/Sub 메시지가 게시되면 이 메시지는 리전 내의 2개 이상의 영역에 있는 스토리지에 동기식으로 기록됩니다. 따라서 단일 영역을 사용할 수 없게 되어도 고객은 영향을 받지 않습니다.
리전 서비스 중단: 리전 서비스 중단 시 영향을 받는 리전 내에 저장된 메시지에는 액세스할 수 없습니다. 리전 엔드포인트 또는 전역 엔드포인트를 통해 영향을 받는 리전에 연결하는 게시자와 구독자는 연결할 수 없습니다. 다른 리전에 연결하는 게시자와 구독자는 계속 연결할 수 있으며, 다른 리전에서 사용 가능한 메시지는 네트워크에서 가장 가까우며 용량이 있는 구독자에게 전송됩니다.
애플리케이션에 메시지 순서 지정이 사용되는 경우 Pub/Sub 팀의 세부 권장사항을 참조하세요. 메시지 순서 지정 보장은 리전별 기준에 따라 제공되며, 전역 엔드포인트를 사용할 경우에는 중단될 수 있습니다.
reCAPTCHA
reCAPTCHA는 허위 행위, 스팸, 악용을 감지하는 전역 서비스입니다. 리전 또는 영역 복원력을 위한 구성이 필요하지 않거나 허용하지 않습니다. 구성 메타데이터 업데이트는 reCAPTCHA가 실행되는 각 리전에 비동기식으로 복제됩니다.
영역 서비스 중단 시 reCAPTCHA는 동일 또는 다른 리전에 있는 다른 영역의 요청을 중단 없이 계속 처리합니다.
리전 서비스 중단 시 reCAPTCHA는 중단 없이 다른 리전의 요청을 계속 처리합니다.
Secret Manager
Secret Manager는Google Cloud를 위한 보안 비밀 및 사용자 인증 정보 관리 제품입니다. Secret Manager를 사용하면 보안 비밀을 쉽게 감사하고, 보안 비밀에 대한 액세스를 제한하고, 저장 중인 보안 비밀을 암호화하고, 민감한 정보가 Google Cloud에서 보호되도록 보장할 수 있습니다.
Secret Manager 리소스는 일반적으로 전역 복제를 가능하게 해주는 자동 복제 정책(권장)과 함께 생성됩니다. 조직에 보안 비밀 데이터에 대해 전역 복제를 허용하지 않는 정책이 있으면 Secret Manager 리소스를 사용자 관리 복제 정책으로 만들 수 있습니다. 이렇게 하면 보안 비밀을 복제할 리전이 하나 이상 선택됩니다.
영역 서비스 중단: 영역 서비스 중단이 발생한 경우에는 Secret Manager가 중단 없이 동일한 리전 또는 다른 리전의 다른 영역에서 요청을 계속 처리합니다. 각 리전 내에서 Secret Manager는 항상 2개 이상의 복제본을 별개 영역에 유지합니다(대부분의 경우 3개 복제본). 영역 서비스 중단이 해결되면 전체 중복성이 복원됩니다.
리전 서비스 중단: 리전 서비스 중단이 발생한 경우 자동 복제를 통해 또는 2개 이상의 리전에 대한 사용자 관리형 복제를 통해 데이터가 2개 이상의 리전에 복제되어 있으면 Secret Manager는 중단 없이 다른 리전에서 요청을 계속 처리합니다. 리전 서비스 중단이 해결되면 전체 중복성이 복원됩니다.
Security Command Center
Security Command Center는 Google Cloud의 글로벌 실시간 위험 관리 플랫폼입니다. 감지기와 결과라는 두 가지 주요 구성요소로 구성됩니다.
감지기는 리전 서비스 중단과 영역 장애의 다른 방식으로 영향을 받습니다. 리전 서비스 중단이 발생하면 감지기는 검사해야 하는 리소스를 사용할 수 없으므로 리전 리소스에 대한 새로운 발견 항목을 생성할 수 없습니다.
영역 장애가 발생하면 감지기가 정상 작동을 재개하는 데 몇 분에서 몇 시간까지 걸릴 수 있습니다. Security Command Center에서 발견 항목 데이터가 손실되지 않습니다. 또한 사용할 수 없는 리소스에 대한 새로운 발견 데이터도 생성되지 않습니다. 최악의 경우 Container Threat Detection 에이전트가 정상 셀에 연결하는 동안 버퍼 공간이 부족해 감지가 손실될 수 있습니다.
발견 항목은 리전 간에 동기식으로 복제되기 때문에 리전 및 영역 서비스 중단에 대한 복원력이 우수합니다.
Sensitive Data Protection(DLP API 포함)
Sensitive Data Protection에서는 민감한 정보 분류, 프로파일링, 익명화, 토큰화, 개인 정보 보호 위험 분석 서비스를 제공합니다. 요청 본문으로 전송되는 데이터에 대해서는 동기식으로 또는 이미 클라우드 스토리지 시스템에 있는 데이터에 대해서는 비동기적으로 작동합니다. Sensitive Data Protection은 전역 또는 리전별 엔드포인트를 통해 호출될 수 있습니다.
전역 엔드포인트: 리전 장애와 영역 장애 모두에 대한 복원력이 우수하도록 설계된 서비스입니다. 장애 발생 시 서비스가 과부하되면 서비스의 hybridInspect 메서드로 전송된 데이터가 손실될 수 있습니다.
장애 방지 아키텍처를 만들려면 hybridInspect 메서드로 생성된 최근의 장애 전 발견 항목을 검사하는 로직을 포함합니다. 서비스 중단이 발생하면 메서드로 전송된 데이터가 손실될 수 있지만 장애 이벤트 전 마지막 10분 이내의 값이 손실될 수 있습니다. 서비스 중단이 시작되기 10분 전에 발견 항목이 있는 경우 이는 해당 발견 항목으로 인해 데이터가 손실되지 않았다는 의미입니다. 이 경우 10분 간격 내에 있더라도 발견 항목 타임스탬프 이전에 제공된 데이터를 다시 재생할 필요가 없습니다.
리전 엔드포인트: 리전 엔드포인트는 리전 장애에 대한 복원력이 우수하지 않습니다. 리전 장애에 대한 복원력이 필요한 경우 다른 리전으로 장애 조치를 고려합니다. 영역 장애 특성은 위와 동일합니다.
서비스 사용량
Service Usage API는 Google Cloud 프로젝트에서 API 및 서비스를 나열하고 관리할 수 있게 해주는 Google Cloud 의 인프라 서비스입니다. Google, Google Cloud, 서드 파티 제작자에서 제공하는 API 및 서비스를 나열하고 관리할 수 있습니다. Service Usage API는 영역 및 리전 서비스 중단에 대한 복원력이 우수한 전역 서비스입니다. 영역 서비스 중단 또는 리전 서비스 중단 시 Service Usage API는 다른 리전의 다른 영역에서 요청을 계속 처리합니다.
서비스 사용량에 대한 자세한 내용은 서비스 사용량 문서를 참조하세요.
Speech-to-Text
Speech-to-Text를 사용하면 신경망 모델과 같은 머신러닝 기술을 사용하여 음성 오디오를 텍스트로 변환할 수 있습니다. 오디오는 애플리케이션의 마이크로부터 실시간 전송되거나 오디오 파일 배치로 처리됩니다.
영역 서비스 중단:
Speech-to-Text API v1: 영역 서비스 중단 시 Speech-to-Text API 버전 1은 중단 없이 같은 리전의 다른 영역에서 들어오는 요청을 계속 처리합니다. 그러나 현재 장애가 발생한 영역 내에서 실행 중인 모든 작업이 손실됩니다. 사용자는 실패한 작업을 다시 시도해야 하며 이 작업은 사용 가능한 영역으로 자동 라우팅됩니다.
Speech-to-Text API v2: 영역 서비스 중단 시 Speech-to-Text API 버전 2는 같은 리전의 다른 영역에서 들어오는 요청을 계속 처리합니다. 그러나 현재 장애가 발생한 영역 내에서 실행 중인 모든 작업이 손실됩니다. 사용자는 실패한 작업을 다시 시도해야 하며 이 작업은 사용 가능한 영역으로 자동 라우팅됩니다. Speech-to-Text API는 데이터가 리전 내의 쿼럼에 커밋된 후에만 API 호출을 반환합니다. 일부 리전에서는 AI 가속기(TPU)를 한 영역에서만 사용할 수 있습니다. 이 경우 해당 영역에서 서비스 중단이 발생하면 음성 인식이 실패하지만 데이터는 손실되지 않습니다.
리전 서비스 중단:
Speech-to-Text API v1: Speech-to-Text API 버전 1은 전역 멀티 리전 서비스이므로 리전 장애의 영향을 받지 않습니다. 이 서비스는 중단 없이 다른 리전의 요청을 계속 처리합니다. 그러나 현재 장애가 발생한 리전 내에서 실행 중인 작업은 손실됩니다. 사용자는 실패한 작업을 다시 시도해야 하며 이 작업은 사용 가능한 리전으로 자동 라우팅됩니다.
Speech-to-Text API v2:
멀티 리전 Speech-to-Text API 버전 2 서비스는 중단 없이 같은 리전의 다른 영역에서 들어오는 요청을 계속 처리할 수 있습니다.
단일 리전 Speech-to-Text API 버전 2 서비스는 작업 실행 범위를 요청된 리전으로 지정합니다. Speech-to-Text API 버전 2는 트래픽을 다른 리전으로 라우팅하지 않으며 데이터는 다른 리전으로 복제되지 않습니다. 리전 장애가 발생하면 해당 리전에서 Speech-to-Text API 버전 2를 사용할 수 없습니다. 하지만 서비스 중단이 해결되면 다시 사용할 수 있게 됩니다.
Storage Transfer Service
Storage Transfer Service는 파일 시스템에 대한 데이터 전송 및 파일 시스템 간의 데이터 전송뿐만 아니라 여러 클라우드 서비스에서 Cloud Storage로의 데이터 전송을 관리합니다.
Storage Transfer Service API는 전역 리소스입니다.
Storage Transfer Service는 전송 소스 및 대상의 가용성에 따라 달라집니다. 전송 소스 또는 대상을 사용할 수 없으면 전송 진행이 중지합니다. 그러나 고객 핵심 데이터 또는 작업 데이터가 손실되지 않습니다. 소스와 대상을 다시 사용할 수 있게 되면 전송이 다시 시작됩니다.
다음과 같이 에이전트 여부에 관계없이 Storage Transfer Service를 사용할 수 있습니다.
에이전트리스 전송은 리전별 작업자를 사용하여 전송 작업을 조정합니다.
에이전트 기반 전송은 인프라에 설치된 소프트웨어 에이전트를 사용합니다. 에이전트 기반 전송은 전송 에이전트의 가용성 및 파일 시스템에 연결할 수 있는 에이전트 기능에 따라 달라집니다. 전송 에이전트 설치 위치를 결정할 때는 파일 시스템의 가용성을 고려해야 합니다. 예를 들어 여러 Compute Engine VM에서 엔터프라이즈급 Filestore 인스턴스(리전별 리소스)에 데이터를 전송하기 위해 전송 에이전트를 실행하는 경우 Filestore 인스턴스 리전 내에서 여러 영역에 VM을 배치하는 것이 좋습니다.
에이전트를 사용할 수 없거나 파일 시스템 연결이 중단되면 전송 진행이 중지되지만 데이터가 손실되지 않습니다. 모든 에이전트 프로세스가 종료되면 새 에이전트가 전송 에이전트 풀에 추가될 때까지 전송 작업이 일시 중지됩니다.
중단 중 Storage Transfer Service 동작은 다음과 같습니다.
영역 서비스 중단: 영역 서비스 중단 중에는 Storage Transfer Service API가 사용 가능한 상태로 유지되고 계속 전송 작업을 만들 수 있습니다. 데이터는 계속 전송됩니다.
리전 서비스 중단: 리전 서비스 중단 중에는 Storage Transfer Service API가 사용 가능한 상태로 유지되고 전송 작업을 계속 만들 수 있습니다. 전송 작업자가 영향을 받는 리전에 있으면 리전을 다시 사용할 수 있을 때까지 데이터 전송이 중지되고 이후에 전송이 자동으로 재개됩니다.
Vertex ML Metadata
Vertex ML Metadata를 사용하면 ML 시스템에서 생성된 메타데이터와 아티팩트를 기록하고 ML 메타데이터를 쿼리하여 ML 시스템 또는 ML 시스템에서 생성하는 아티팩트의 성능을 분석, 디버깅, 감사할 수 있습니다.
영역 서비스 중단: 기본 구성에서 Vertex ML Metadata는 영역 장애에 대한 보호 기능을 제공합니다. 이 서비스는 각 리전의 여러 영역에 배포되고, 데이터는 각 리전 내의 서로 다른 영역에 동기식으로 복제됩니다. 영역 장애가 발생하면 남은 영역이 최소한의 중단으로 작업을 이어서 처리합니다.
리전 서비스 중단: Vertex ML Metadata는 리전화된 서비스입니다. 리전 서비스 중단 발생 시 Vertex ML Metadata는 다른 리전으로 장애 조치되지 않습니다.
Vertex AI 일괄 예측
배치 예측을 사용하면 사용자가 Google 인프라에서 AI/ML 모델에 대해 배치 예측을 실행할 수 있습니다. 일괄 예측은 지역별 제품입니다. 고객은 작업을 실행할 리전을 선택할 수 있지만 해당 리전 내의 특정 영역은 선택할 수 없습니다. 일괄 예측 서비스는 선택한 리전 내 여러 영역 간에 작업을 자동으로 부하 분산합니다.
영역 서비스 중단: 일괄 예측은 리전 내 일괄 예측 작업의 메타데이터를 저장합니다. 데이터는 해당 리전 내 여러 영역에 동기식으로 기록됩니다. 영역 서비스 중단 시 일괄 예측은 작업을 실행하는 작업자를 부분적으로 잃지만 사용 가능한 다른 영역에 작업자를 자동으로 다시 추가합니다. 일괄 예측 재시도가 여러 번 실패하면 UI와 API 호출 요청에 작업 상태가 실패로 표시됩니다. 이후에 작업을 실행하기 위한 사용자 요청은 사용 가능한 영역으로 라우팅됩니다.
리전 서비스 중단: 고객이 Google Cloud 일괄 예측 작업을 실행하려는 리전을 선택합니다. 데이터는 리전 간에 복제되지 않습니다. 일괄 예측은 요청된 리전으로 작업 실행 범위를 지정하고 예측 요청을 다른 리전으로 라우팅하지 않습니다. 리전 장애가 발생하면 해당 리전에서 일괄 예측을 사용할 수 없습니다. 서비스 중단이 해결되면 다시 사용할 수 있게 됩니다. 고객이 여러 리전을 사용하여 작업을 실행하는 것이 좋습니다. 리전 서비스 중단이 발생하면 사용 가능한 다른 리전으로 작업을 전송합니다.
Vertex AI Model Registry
Vertex AI Model Registry를 사용하면 중앙 저장소에서 모델 관리, 거버넌스, ML 모델 배포를 간소화할 수 있습니다. Vertex AI Model Registry는 고가용성을 갖춘 리전 제품이며 영역 서비스 중단에 대한 보호 기능을 제공합니다.
영역 서비스 중단: Vertex AI Model Registry는 영역 서비스 중단에 대한 보호 기능을 제공합니다. 이 서비스는 각 리전의 3개 영역에 배포되고, 데이터는 리전 내의 서로 다른 영역에 동기식으로 복제됩니다. 영역에 장애가 발생하면 데이터 손실 및 최소 서비스 중단 없이 나머지 영역으로 인계됩니다.
리전 서비스 중단: Vertex AI Model Registry는 리전화된 서비스입니다. 리전이 실패하면 Model Registry가 장애 조치되지 않습니다.
Vertex AI 온라인 예측
온라인 예측을 사용하면 Google Cloud에 AI/ML 모델을 배포할 수 있습니다. 온라인 예측은 리전별 제품입니다. 고객은 모델을 배포할 리전을 선택할 수 있지만 해당 리전 내에서 특정 영역을 선택할 수는 없습니다. 예측 서비스는 선택한 리전 내의 여러 영역 간에 워크로드를 자동으로 부하 분산합니다.
영역별 서비스 중단: 온라인 예측은 고객 콘텐츠를 저장하지 않습니다. 영역 장애가 발생하면 현재 예측 요청 실행이 실패합니다. 사용되는 엔드포인트 유형에 따라 온라인 예측이 예측 요청을 자동으로 재시도할 수도 있고 그렇지 않을 수도 있습니다. 특히 공개 엔드포인트는 자동으로 재시도하지만 비공개 엔드포인트는 재시도하지 않습니다. 실패를 처리하고 복원력을 개선하려면 코드에 지수 백오프를 사용하는 재시도 로직을 통합하세요.
리전 서비스 중단: 고객이 AI/ML 모델 및 온라인 예측 서비스를 실행할 Google Cloud 리전을 선택합니다. 데이터는 리전 간에 복제되지 않습니다. 온라인 예측은 AI/ML 모델 실행 범위를 요청된 리전으로 지정하고 예측 요청을 다른 리전으로 라우팅하지 않습니다. 리전 장애가 발생하면 해당 리전에서 온라인 예측 서비스를 사용할 수 없습니다. 서비스 중단이 해결되면 다시 사용할 수 있게 됩니다. 고객이 여러 리전을 사용하여 AI/ML 모델을 실행하는 것이 좋습니다. 리전 서비스 중단이 발생하면 사용 가능한 다른 리전으로 트래픽을 전송합니다.
Vertex AI Pipelines
Vertex AI Pipelines는 서버리스 방식으로 머신러닝(ML) 워크플로를 자동화, 모니터링, 제어할 수 있게 해주는 Vertex AI 서비스입니다. Vertex AI Pipelines는 고가용성을 제공하도록 구축되었으며 영역 장애에 대한 보호 기능을 제공합니다.
영역 서비스 중단: 기본 구성에서 Vertex AI Pipelines는 영역 장애에 대한 보호 기능을 제공합니다. 이 서비스는 각 리전의 여러 영역에 배포되고, 데이터는 리전 내의 서로 다른 영역에 동기식으로 복제됩니다. 영역 장애가 발생하면 남은 영역이 최소한의 중단으로 작업을 이어서 처리합니다.
리전 서비스 중단: Vertex AI Pipelines는 리전화된 서비스입니다. 리전 서비스 중단 발생 시 Vertex AI Pipelines는 다른 리전으로 장애 조치되지 않습니다. 리전 서비스 중단이 발생하면 백업 리전에서 파이프라인 작업을 실행하는 것이 좋습니다.
Vertex AI Search
Vertex AI Search는 생성형 AI 기능과 기본 기업 규정 준수가 포함된 맞춤설정 가능한 검색 솔루션입니다. Vertex AI Search는 Google Cloud내의 여러 리전에 자동으로 배포 및 복제됩니다. 지원되는 멀티 리전(예: 전역, 미국 또는 EU)을 선택하여 데이터 저장 위치를 구성할 수 있습니다.
영역 및 리전 서비스 중단: 비동기 복제 지연으로 인해 Vertex AI Search에 업로드된 UserEvents를 복구하지 못할 수 있습니다. 자동 장애 조치와 동기식 데이터 복제로 인해 Vertex AI Search에서 제공하는 다른 데이터와 서비스를 계속 사용할 수 있습니다.
Vertex AI Training
Vertex AI Training은 사용자에게 Google 인프라에서 커스텀 학습 작업을 실행할 수 있는 기능을 제공합니다. Vertex AI Training은 리전별 제품입니다. 즉, 고객이 학습 작업을 실행할 리전을 선택할 수 있습니다. 그러나 고객은 해당 리전 내에서 특정 영역을 선택할 수 없습니다. 학습 서비스는 리전 내 여러 영역 간에 작업 실행을 자동으로 부하 분산할 수 있습니다.
영역 서비스 중단: Vertex AI Training은 커스텀 학습 작업에 대한 메타데이터를 저장합니다. 이 데이터는 리전별로 저장되고 동기식으로 기록됩니다. Vertex AI Training API 호출은 이 메타데이터가 리전 내 쿼럼에 커밋된 후에만 반환됩니다. 학습 작업은 특정 영역에서 실행될 수 있습니다. 영역 장애가 발생하면 현재 작업 실행이 실패합니다. 이 경우 서비스가 이를 다른 영역으로 라우팅하여 작업을 자동으로 재시도합니다. 여러 번 재시도가 실패하면 작업 상태가 실패로 업데이트됩니다. 이후에 작업을 실행하기 위한 사용자 요청은 사용 가능한 영역으로 라우팅됩니다.
리전 서비스 중단: 고객이 학습 작업을 실행하려는 Google Cloud 리전을 선택합니다. 데이터는 리전 간에 복제되지 않습니다. Vertex AI Training은 요청된 리전으로 작업 실행 범위를 지정하고 학습 작업을 다른 리전으로 라우팅하지 않습니다. 리전 서비스 중단이 발생하면 해당 리전에서 Vertex AI Training 서비스를 사용할 수 없고 중단이 해결되었을 때 다시 사용할 수 있습니다. 고객이 여러 리전을 사용해서 작업을 실행하고, 리전 서비스 중단이 발생하면 사용 가능한 다른 리전으로 작업을 전송하는 것이 좋습니다.
Virtual Private Cloud(VPC)
VPC는 리소스에 대한 네트워크 연결(예: VM)을 제공하는 전역 서비스입니다. 하지만 장애는 영역 단위입니다. 영역 장애가 발생하면 해당 영역의 리소스를 사용할 수 없습니다. 마찬가지로 리전이 실패하면 실패한 리전과 주고받는 트래픽만 영향을 받습니다. 정상 리전의 연결은 영향을 받지 않습니다.
영역 서비스 중단: VPC 네트워크에 영역이 여러 개 있고 영역 하나가 실패해도 VPC 네트워크는 정상 영역에서 계속 정상입니다. 정상 영역의 리소스 간 네트워크 트래픽은 장애 중에도 계속 정상적으로 작동합니다. 영역 장애는 장애가 발생한 영역의 리소스와 주고받는 네트워크 트래픽에만 영향을 미칩니다. 영역 장애의 영향을 완화하려면 단일 영역에 모든 리소스를 만들지 않는 것이 좋습니다. 대신 리소스를 만들 때 여러 영역에 분산합니다.
리전 서비스 중단: VPC 네트워크에 리전이 여러 개 있고 리전 하나가 실패해도 VPC 네트워크는 정상 리전에서 계속 정상입니다. 정상 리전의 리소스 간 네트워크 트래픽은 장애 중에도 계속 정상적으로 작동합니다. 리전 장애는 장애가 발생한 리전의 리소스와 주고받는 네트워크 트래픽에만 영향을 미칩니다. 리전 장애의 영향을 완화하려면 리소스를 여러 리전에 분산하는 것이 좋습니다.
VPC 서비스 제어
VPC 서비스 제어는 리전 서비스입니다. 기업 보안팀은 VPC 서비스 제어를 이용하여 세밀한 경계 제어를 정의하고 수많은 Google Cloud 서비스와 프로젝트에 보안 상태를 적용할 수 있습니다. 고객 정책은 리전별로 미러링됩니다.
영역 서비스 중단: VPC 서비스 제어는 중단 없이 동일 리전의 다른 영역에서 요청을 계속 처리합니다.
리전 서비스 중단: 영향을 받는 리전에서 VPC 서비스 제어 정책 적용을 위해 구성된 API는 리전이 다시 사용 가능해질 때까지 사용할 수 없습니다. 고객은 높은 가용성을 원하는 경우 VPC 서비스 제어 시행 서비스를 여러 리전에 배포하는 것이 좋습니다.
워크플로
Workflows는 고객이 다음 작업을 할 수 있도록 지원하는 오케스트레이션 제품입니다. Google Cloud
- HTTP를 사용하여 다른 기존 서비스를 연결하는 워크플로를 배포하고 실행합니다.
- 최대 1년 동안 자동 재시도를 사용하여 HTTP 응답을 기다리는 것을 포함하여 프로세스 자동화
- 지연 시간이 짧은 이벤트 기반 실행을 통해 실시간 처리 구현
Workflows 고객은 수행하려는 비즈니스 논리를 설명하는 워크플로를 배포한 후 API로 직접 또는 이벤트 기반 트리거(현재 Pub/Sub 또는 Eventarc로 제한)를 사용하여 워크플로를 실행할 수 있습니다. 실행 중인 워크플로는 변수를 조작하고, HTTP 호출을 수행하고, 결과를 저장하거나 콜백을 정의하고 다른 서비스에서 재개될 때까지 기다릴 수 있습니다.
영역 서비스 중단: 워크플로 소스 코드는 영역 서비스 중단의 영향을 받지 않습니다. Workflows는 실행 중인 워크플로가 수신한 변수 값 및 HTTP 응답과 함께 워크플로의 소스 코드를 저장합니다. 소스 코드는 리전별로 저장되고 동기식으로 작성됩니다. 제어 플레인 API는 이 메타데이터가 리전 내 쿼럼에 커밋된 후에만 반환됩니다. 변수 및 HTTP 결과도 리전별로 저장되고 최소 5초 간격으로 동기식으로 작성됩니다.
영역에 장애가 발생하면 마지막으로 저장된 데이터를 기반으로 워크플로가 자동으로 재개됩니다. 하지만 아직 응답을 받지 못한 HTTP 요청은 자동으로 재시도되지 않습니다. 문서에 설명된 대로 안전하게 재시도할 수 있는 요청에는 재시도 정책을 사용하세요.
리전 서비스 중단: 워크플로는 리전화된 서비스입니다. 리전 서비스 중단이 발생해도 워크플로는 장애 조치되지 않습니다. 고객은 더 높은 가용성을 원하는 경우 여러 리전에 Workflows를 배포하는 것이 좋습니다.
Cloud Service Mesh
Cloud Service Mesh를 사용하면 여러 GKE 클러스터에 걸쳐 있는 관리형 서비스 메시를 구성할 수 있습니다. 이 문서에서는 관리형 Cloud Service Mesh만 다룹니다. 클러스터 내 변형은 자체 호스팅되며 일반 플랫폼 가이드라인을 따라야 합니다.
영역 서비스 중단: 메시 구성은 GKE 클러스터에 저장되므로 클러스터가 리전 클러스터라면 영역 서비스 중단에 대한 복원력이 우수합니다. 제품에서 내부 회계에 사용하는 데이터는 리전별 또는 전역으로 저장되며 단일 영역이 서비스 중단되더라도 영향을 받지 않습니다. 제어 영역은 지원되는 GKE 클러스터와 동일한 리전에서 실행되며(영역 클러스터의 경우 포함된 리전에서 실행) 단일 영역 내 서비스 중단의 영향을 받지 않습니다.
리전 서비스 중단: Cloud Service Mesh는 리전 또는 영역 GKE 클러스터에 서비스를 제공합니다. 리전 서비스 중단이 발생하면 Cloud Service Mesh가 장애 조치되지 않습니다. GKE도 마찬가지입니다. 고객은 여러 리전에 걸쳐 있는 GKE 클러스터를 구성하는 메시를 배포하는 것이 좋습니다.
서비스 디렉터리
서비스 디렉터리는 서비스 검색, 게시, 연결을 위한 플랫폼입니다. 모든 서비스에 관한 실시간 정보를 한곳에서 제공합니다. 서비스 디렉터리를 사용하면 서비스 엔드포인트가 많든 적든 상관없이 서비스 인벤토리 관리를 규모에 맞춰 실행할 수 있습니다.
서비스 디렉터리 리소스는 리전별로 생성되고 이는 사용자가 지정한 위치 매개변수와 일치합니다.
영역 서비스 중단: 영역 서비스 중단 시 서비스 디렉터리는 중단 없이 동일하거나 다른 리전 내 다른 영역의 요청을 계속 처리합니다. 서비스 디렉터리는 항상 각 리전 내에 여러 개의 복제본을 유지합니다. 영역 서비스 중단이 해결되면 전체 중복성이 복원됩니다.
리전 서비스 중단: 서비스 디렉터리는 리전 서비스 중단에 대해 복원력이 우수하지 않습니다.