本文档介绍了一个参考架构,该架构可帮助您创建可直接投入生产用途、可扩缩、具有容错能力的日志导出机制,以将日志和事件从 Google Cloud 中的资源流式传输到 Splunk。Splunk 是一种热门分析工具,提供了一个统一的安全性和可观测性平台。实际上,您可以选择将日志记录数据导出到 Splunk Enterprise 或 Splunk Cloud Platform。 如果您是管理员,还可以将此架构用于 IT 运维或安全使用场景。
此参考架构假定资源层次结构与下图类似。组织、文件夹和项目级层的所有 Google Cloud 资源日志都会收集到汇总接收器中。 然后,汇总接收器会将这些日志发送到日志导出流水线,该流水线会处理日志并将其导出到 Splunk。

架构
下图展示了部署此解决方案时使用的参考架构。下图演示了日志数据如何从Google Cloud 流向 Splunk。

此架构包括以下组件:
- Cloud Logging:为启动此过程,Cloud Logging 会将日志收集到组织级层的汇总日志接收器中,并将日志发送到 Pub/Sub。
- Pub/Sub:Pub/Sub 服务会为日志创建单个主题和订阅,并将日志转发到主 Dataflow 流水线。
- Dataflow:此参考架构中有两个 Dataflow 流水线:
- 主 Dataflow 流水线:在流程的中心,主 Dataflow 流水线是一个 Pub/Sub-to-Splunk 流式流水线,该流水线从 Pub/Sub 订阅中提取日志并将其传送至 Splunk。
- 次要 Dataflow 流水线:次要 Dataflow 流水线是与 Dataflow 主流水线并行的,它是一个 Pub/Sub 到 Pub/Sub 流式传输流水线,用于在传送失败时重放消息。
- Splunk:此过程结束时,Splunk Enterprise 或 Splunk Cloud Platform 充当 HTTP Event Collector (HEC),并接收日志以供进一步分析。您可以在本地、Google Cloud 即 SaaS 中或通过混合方法部署 Splunk。
使用场景
此参考架构使用基于推送的云方法。在这种基于推送的方法中,您可以使用 Pub/Sub to Splunk Dataflow 模板将日志流式传输到 Splunk HTTP Event Collector (HEC) 。此外,该参考架构还讨论了 Dataflow 流水线容量规划,以及如何应对遇到瞬时服务器或网络问题时可能发生的交付失败。
虽然此参考架构侧重于 Google Cloud 日志,但您可以使用同一架构来导出其他 Google Cloud 数据,例如实时资产更改和安全发现结果。从 Cloud Logging 集成日志后,您可以继续使用现有合作伙伴服务(如 Splunk)作为统一日志分析解决方案。
基于推送的方法将 Google Cloud 数据流式传输到 Splunk 具有以下优势:
- 托管式服务。作为托管式服务,Dataflow 会在 Google Cloud 中维护数据处理任务(例如日志导出)所需的资源。
- 分布式工作负载。通过此方法,您可以在多个工作器之间分配工作负载以进行并行处理,因此不存在单点故障。
- 安全。由于 Google Cloud 会将数据推送到 Splunk HEC,因此不存在任何与创建和管理服务账号密钥关联的维护和安全负担。
- 自动扩缩。Dataflow 服务会自动扩缩工作器的数量,以应对传入日志量和积压的变化。
- 容错性。如果出现暂时性服务器或网络问题,则基于推送的方法会自动尝试重新将数据发送到 Splunk HEC。该方法还支持任何无法递送的日志消息的未处理主题(也称为死信主题),以免数据丢失。
- 简单性。您无需承担管理开销以及运行 Splunk 中的一个或多个重型级转发器的费用。
此参考架构适用于许多不同行业的企业,包括制药和金融服务等受监管的行业。当您选择将 Google Cloud 数据导出到 Splunk 时,可能是出于以下原因:
- 业务分析
- IT 运营
- 应用性能监控
- 安全运维
- 合规性
设计替代方案
将日志导出到 Splunk 的另一种方法是从Google Cloud拉取日志。在这种基于拉取的方法中,您可以使用 Google Cloud API 通过 Google Cloud的 Splunk 插件提取数据。对于以下情况,您可以选择使用基于拉取的方法:
- 您的 Splunk 部署不提供 Splunk HEC 端点。
- 您的日志量较小。
- 您希望导出和分析 Cloud Monitoring 指标、Cloud Storage 对象、Cloud Resource Manager API 元数据、Cloud Billing 数据或量较小的日志。
- 您已在 Splunk 中管理一个或多个重型级转发器。
- 您在使用托管的适用于 Splunk Cloud 的输入数据管理器。
此外,使用基于拉取的方法时,还需谨记一些其他注意事项:
- 单个工作器负责处理数据注入工作负载,该工作负载不提供自动扩缩功能。
- 在 Splunk 中,使用重型级转发器拉取数据可能会导致单点故障。
- 基于拉取的方法要求您创建和管理用于 Google Cloud的 Splunk 插件的服务账号密钥。
在使用 Splunk 插件之前,必须先使用日志接收器将日志条目路由到 Pub/Sub。如需创建以 Pub/Sub 主题为目标的日志接收器,请参阅创建接收器。请务必通过该 Pub/Sub 主题目标将 Pub/Sub Publisher 角色 (roles/pubsub.publisher) 授予接收器的写入者身份。如需详细了解如何配置接收器目标位置权限,请参阅设置目标位置权限。
如需启用 Splunk 插件,请执行以下步骤:
- 在 Splunk 中,按照 Splunk 说明安装 Google Cloud的 Splunk 插件。
- 为日志路由到的 Pub/Sub 主题创建 Pub/Sub 拉取订阅(如果您还没有)。
- 创建服务账号。
- 为您刚刚创建的服务账号创建服务账号密钥。
- 向服务账号授予 Pub/Sub Viewer (
roles/pubsub.viewer) 和 Pub/Sub Subscriber (roles/pubsub.subscriber) 角色,让该账号接收来自 Pub/Sub 订阅的消息。 在 Splunk 中,按照 Splunk 说明在 Google Cloud的 Splunk 插件中配置新的 Pub/Sub 输入。
日志导出中的 Pub/Sub 消息会在 Splunk 中显示。
如需验证该插件是否正常运行,请执行以下步骤:
- 在 Cloud Monitoring 中,打开 Metrics Explorer。
- 在资源菜单中,选择
pubsub_subscription。 - 在指标类别中,选择
pubsub/subscription/pull_message_operation_count。 - 监控消息拉取操作一到两分钟。
设计考虑事项
以下指南可帮助您开发满足组织的安全性、隐私性、合规性、运维效率、可靠性、容错性、性能和费用优化要求的架构。
安全性、隐私权和合规性
以下各部分介绍了此参考架构的安全注意事项:
- 使用专用 IP 地址来保护支持 Dataflow 流水线的虚拟机
- 启用专用 Google 访问通道
- 将 Splunk HEC 入站流量限制到 Cloud NAT 使用的已知 IP 地址
- 将 Splunk HEC 令牌存储在 Secret Manager 中
- 创建自定义 Dataflow 工作器服务账号,以遵循最小权限最佳做法
- 为内部根 CA 证书配置 SSL 验证(如果您使用的是私有 CA)
使用专用 IP 地址来保护支持 Dataflow 流水线的虚拟机
您应该限制对 Dataflow 流水线中使用的工作器虚拟机的访问。如需限制访问,请使用专用 IP 地址部署这些虚拟机。但是,这些虚拟机还需要能够使用 HTTPS 将导出的日志流式传输到 Splunk,并访问互联网。如需提供此 HTTPS 访问权限,您需要一个 Cloud NAT 网关,该网关会自动将 Cloud NAT IP 地址分配给需要它们的虚拟机。确保将包含虚拟机的子网映射到 Cloud NAT 网关。
启用专用 Google 访问通道
创建 Cloud NAT 网关时,系统会自动启用专用 Google 访问通道。但是,如需允许具有专用 IP 地址的 Dataflow 工作器访问 Google Cloud API 和服务使用的外部 IP 地址,您还必须为子网手动启用专用 Google 访问通道。
将 Splunk HEC 入站流量限制到 Cloud NAT 使用的已知 IP 地址
如果您想将进入 Splunk HEC 的流量限制到已知 IP 地址的子集,则可以预留静态 IP 地址并将其手动分配给 Cloud NAT 网关。根据您的 Splunk 部署,然后您可以使用这些静态 IP 地址配置 Splunk HEC 入站流量防火墙规则。如需详细了解 Cloud NAT,请参阅使用 Cloud NAT 设置和管理网络地址转换。
将 Splunk HEC 令牌存储在 Secret Manager 中
部署 Dataflow 流水线时,您可以通过以下任一方式传递令牌值:
- 明文
- 使用 Cloud Key Management Service 密钥加密的密文
- 由 Secret Manager 加密和管理的密文版本
在此参考架构中,您将使用 Secret Manager 选项,因为此选项提供了保护 Splunk HEC 令牌的最简单、最高效的方法。此选项还可防止 Dataflow 控制台或作业详情泄露 Splunk HEC 令牌。
Secret Manager 中的 Secret 包含一系列 Secret 版本。每个 Secret 版本都会存储实际的 Secret 数据,例如 Splunk HEC 令牌。如果您以后选择轮替 Splunk HEC 令牌作为额外的安全措施,则可以将新令牌作为新 Secret 版本添加到此密文。如需了解有关 Secret 轮替的一般信息,请参阅关于轮替时间表。
创建自定义 Dataflow 工作器服务账号,以遵循最小权限最佳做法
Dataflow 流水线中的工作器使用 Dataflow 工作器服务账号来访问资源并执行操作。默认情况下,工作器将您项目的 Compute Engine 默认服务账号用作工作器服务账号,该服务账号向其授予项目中所有资源的宽泛权限。但是,如需在生产环境中运行 Dataflow 作业,我们建议您创建具有一组最低角色和权限的自定义服务账号。然后,您可以将此自定义服务账号分配给 Dataflow 流水线工作器。
下图列出了使 Dataflow 工作人员能够成功运行 Dataflow 作业而必须分配给服务账号的所需角色。
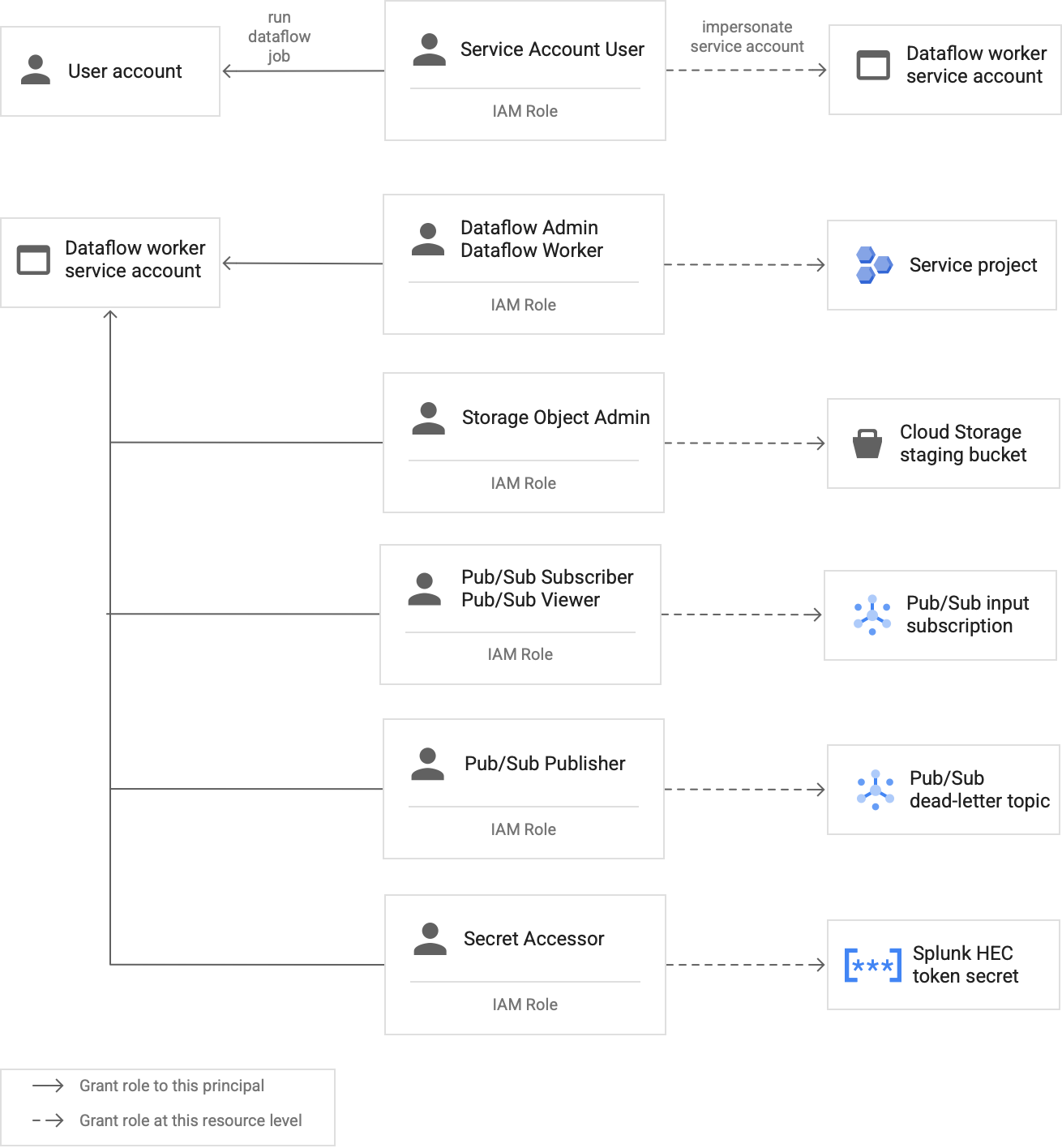
如图所示,您需要将以下角色分配给 Dataflow 工作器的服务账号:
- Dataflow Admin
- Dataflow Worker
- Storage Object Admin
- Pub/Sub Subscriber
- Pub/Sub Viewer
- Pub/Sub Publisher
- Secret Accessor
使用内部根 CA 证书配置 SSL 验证(如果您使用的是私有 CA)
默认情况下,Dataflow 流水线使用 Dataflow 工作器的默认受信任证书存储区来验证 Splunk HEC 端点的 SSL 证书。如果您使用私有证书授权机构 (CA) 为 Splunk HEC 端点使用的 SSL 证书签名,则可以将内部根 CA 证书导入受信任证书存储区。 然后,Dataflow 工作器可以使用导入的证书进行 SSL 证书验证。
对于自签名证书或私有签名证书,您可以将自己的内部根 CA 证书用于 Splunk 部署。您还可以完全停用 SSL 验证以用于内部开发和测试。此内部根 CA 方法最适合面向非互联网的内部 Splunk 部署。
如需了解详情,请参阅 Pub/Sub to Splunk Dataflow 模板参数 rootCaCertificatePath 和 disableCertificateValidation。
运营效率
以下部分介绍了此参考架构的运营效率注意事项:
使用 UDF 转换运行中的日志或事件
Pub/Sub to Splunk Dataflow 模板支持将用户定义的函数 (UDF) 用于自定义事件转换。示例应用场景包括通过其他字段丰富记录、隐去一些敏感字段或过滤掉不需要的记录。借助 UDF,您可以更改 Dataflow 流水线的输出格式,而无需重新编译或维护模板代码本身。此参考架构使用 UDF 处理流水线无法传送到 Splunk 的消息。
重放未处理的消息
有时,流水线会收到传送错误,并且不会再次尝试传送消息。在这种情况下,Dataflow 会将这些未处理的消息发送到未处理的主题,如下图所示。修复传送失败的根本原因后,您可以重放未处理的消息。
以下步骤概述了上图中显示的过程:
- 从 Pub/Sub 到 Splunk 的主传送流水线会自动将无法传送的消息转发到未处理的主题以供用户调查。
运营商或站点可靠性工程师 (SRE) 会调查未处理订阅中的失败消息。运营商会排查并解决传送失败的根本原因。例如,修复 HEC 令牌配置错误可能会导致消息传送。
运算符触发重放失败的消息流水线。此 Pub/Sub to Pub/Sub 流水线(在上图的虚线部分突出显示)是一个临时流水线,用于将失败消息从未处理订阅中的消息移回原始日志接收器主题。
主传送流水线重新处理先前失败的消息。此步骤要求流水线使用 UDF 来正确检测和解码失败的消息载荷。以下代码是一个示例函数,用于实现此条件解码逻辑,其中包括用于跟踪的传送尝试数:
// If the message has already been converted to a Splunk HEC object // with a stringified obj.event JSON payload, then it's a replay of // a previously failed delivery. // Unnest and parse the obj.event. Drop the previously injected // obj.attributes such as errorMessage and timestamp if (obj.event) { try { event = JSON.parse(obj.event); redelivery = true; } catch(e) { event = obj; } } else { event = obj; } // Keep a tally of delivery attempts event.delivery_attempt = event.delivery_attempt || 1; if (redelivery) { event.delivery_attempt += 1; }
可靠性和容错能力
就可靠性和容错性而言,下表(表 1)列出了一些可能的 Splunk 传送错误。在将消息转发到未处理的主题之前,该表还列出了每个消息记录相应的 errorMessage 属性。
表 1:Splunk 传送错误类型
| 递送错误类型 | 是否由流水线自动重试? | 属性 errorMessage 示例 |
|---|---|---|
暂时性网络连接错误 |
是 |
或
|
Splunk Server 5xx 错误 |
是 |
|
Splunk 服务器 4xx 错误 |
否 |
|
Splunk 服务器关闭 |
否 |
|
Splunk SSL 证书无效 |
否 |
|
用户定义的函数 (UDF) 中的 JavaScript 语法错误 |
否 |
|
在某些情况下,流水线会应用指数退避算法,并自动尝试重新传送消息。例如,当 Splunk 服务器生成 5xx 错误代码时,流水线需要重新传送消息。当 Splunk HEC 端点过载时,会出现这些错误代码。
或者,可能出现持续阻止向 HEC 端点提交消息的问题。对于此类持续问题,流水线不会再次尝试传送消息。持续性问题的示例如下:
- UDF 函数中的语法错误。
- 无效的 HEC 令牌,可导致 Splunk 服务器生成
4xx“禁止访问”服务器响应。
性能和费用优化
在性能和费用优化方面,您需要确定 Dataflow 流水线的大小和吞吐量上限。您必须计算正确的大小和吞吐量值,以便流水线可以处理来自上游 Pub/Sub 订阅的每日最大日志量 (GB/天) 和日志消息率(每秒事件数,也称 EPS)。
您必须选择大小和吞吐量值,以免系统出现以下任一问题:
- 由消息积压或邮件节流造成的延迟。
- 超额预配流水线需额外付费。
执行大小和吞吐量计算后,您可以使用结果来配置最佳流水线,以平衡性能和费用。如需配置流水线容量,请使用以下设置:
- 机器类型和机器数量标志属于部署 Dataflow 作业的 gcloud 命令的一部分。通过这些标志,您可以定义要使用的虚拟机的类型和数量。
- Parallelism 和 Batch count 参数属于 Pub/Sub to Splunk Dataflow 模板的一部分。这些参数有助于提高 EPS,同时避免过载 Splunk HEC 端点。
以下部分介绍这些设置。如果适用,这些部分还提供了使用每个公式的公式和示例计算。这些示例计算和生成的值假设组织具有以下特征:
- 每天生成 1 TB 的日志。
- 平均邮件大小为 1 KB。
- 持续峰值消息率为平均速率的两倍。
由于您的 Dataflow 环境是唯一的,因此您必须在完成这些步骤时将示例值替换为您自己的组织中的值。
机器类型
最佳做法:将 --worker-machine-type 标志设置为 n2-standard-4 以选择具有最佳性能成本比的机器大小。
由于 n2-standard-4 机器类型可以处理 12k EPS,我们建议您将此机器类型用作所有 Dataflow 工作器的基准。
对于此参考架构,请将 --worker-machine-type 标志设置为 n2-standard-4 值。
机器数量
最佳做法:设置 --max-workers 标志以控制处理预期峰值 EPS 所需的工作器数量上限。
Dataflow 自动扩缩功能可让服务在资源使用情况和负载发生变化时,以自适应方式更改用于执行流处理流水线的工作器数量。为避免自动扩缩时过度配置,我们建议您始终定义用作 Dataflow 工作器的虚拟机数量上限。您可以在部署 Dataflow 流水线时使用 --max-workers 标志定义虚拟机数量上限。
Dataflow 通过静态方式预配存储组件,如下所示:
自动扩缩流水线会为每个潜在流处理工作器部署一个数据永久性磁盘。默认永久性磁盘大小为 400 GB,您可以使用
--max-workers标志设置工作器数量上限。磁盘可以随时装载到正在运行的工作器,包括启动。由于每个工作器实例仅限于 15 个永久性磁盘,因此启动工作器的最小数量为
⌈--max-workers/15⌉。因此,如果默认值为--max-workers=20,则流水线使用情况(和费用)如下:- 存储:静态存储 20 个永久性磁盘。
- 计算:至少具有 2 个工作器实例 (⌈20/15⌉ = 2),且最多为 20 个。
此值相当于 8 TB 的永久性磁盘。如果永久性磁盘未完全使用,则此大小的永久性磁盘可能会产生不必要的费用,尤其是当只有一个或两个工作器在大多数时间运行时。
如需确定流水线所需的工作器数量上限,请按顺序使用以下公式:
使用以下公式确定每秒平均事件数 (EPS):
\( {AverageEventsPerSecond}\simeq\frac{TotalDailyLogsInTB}{AverageMessageSizeInKB}\times\frac{10^9}{24\times3600} \)计算示例:假设每天有 1 TB 日志的示例值,平均消息大小为 1 KB,则此公式的平均 EPS 值为 11500 EPS。
使用以下公式确定持续峰值 EPS,其中乘数 N 表示日志记录的突发性质:
\( {PeakEventsPerSecond = N \times\ AverageEventsPerSecond} \)计算示例:如果示例值 N=2 且您在上一步中计算的平均 EPS 值为 11500,则此公式会生成持续峰值 EPS 值为 23000 EPS。
使用以下公式确定所需的 vCPU 数量上限:
\( {maxCPUs = ⌈PeakEventsPerSecond / 3k ⌉} \)计算示例:根据在上一步中计算的持续峰值 23000 EPS,此公式最多生成 23 个 vCPU/3⌉ = 8 个 vCPU 核心。
使用以下公式确定 Dataflow 工作器数量上限:
\( maxNumWorkers = ⌈maxCPUs / 4 ⌉ \)计算示例:使用在上一步中计算的 vCPU 最大值 8 这一示例,以下公式 [8/4] 可为
n2-standard-4机器类型生成最大值 2。
在此示例中,您需要根据前面的一组示例计算将 --max-workers 标志设置为 2 值。但在环境中部署此参考架构时,请务必使用您自己的唯一值和计算。
最大并行数量
最佳做法:将 Pub/Sub to Splunk Dataflow 模板中的 parallelism 参数设置为 Dataflow 工作器最大数量使用的 vCPU 数量的两倍。
parallelism 参数有助于最大限度地提高并行 Splunk HEC 连接数,从而最大限度地提高流水线的 EPS 速率。
默认的 parallelism 值 1 会停用并行并限制输出速率。您需要替换此默认设置,以为每个 vCPU 考虑 2 到 4 个并行连接,并部署最大工作器数量。通常,您可以通过以下方式计算此设置的替换值:将 Dataflow 工作器数量上限乘以每个工作器的 vCPU 数量,然后将此值翻倍。
如需确定所有 Dataflow 工作器与 Splunk HEC 的并行连接总数,请使用以下公式:
计算示例:使用先前针对机器计数计算的 8 个 vCPU 这一示例,此公式生成的并行连接数为 8 x 2 = 16。
在此示例中,您需要根据前面的示例计算将 parallelism 参数设置为 16 值。但在环境中部署此参考架构时,请务必使用您自己的唯一值和计算。
批次数量
最佳做法:如需允许 Splunk HEC 批量处理事件,而不是一次处理一个事件,请将 batchCount 参数设置为一个 10 到 50 个日志事件/请求之间的值。
配置批次数量有助于增加 EPS 并减少 Splunk HEC 端点上的负载。该设置会将多个事件合并为一个批次,以提高处理效率。我们建议您将 batchCount 参数的值设置为 10 到 50 个日志事件/请求,前提是可接受的最大缓冲延迟时间为 2 秒。
在此示例中,平均日志消息大小为 1 KB,因此我们建议您为每个请求至少批处理 10 个事件。在此示例中,您需要将 batchCount 参数设置为 10 值。但在环境中部署此参考架构时,请务必使用您自己的唯一值和计算。
如需详细了解这些性能和费用优化建议,请参阅规划 Dataflow 流水线。
后续步骤
- 如需查看 Pub/Sub to Splunk Dataflow 模板参数的完整列表,请参阅 Pub/Sub to Splunk Dataflow 文档。
- 如需了解可帮助您部署此参考架构的相应 Terraform 模板,请参阅
terraform-splunk-log-exportGitHub 代码库。它包含一个预建的 Cloud Monitoring 信息中心,用于监控 Splunk Dataflow 流水线。 - 如需详细了解 Splunk Dataflow 自定义指标和日志记录(以帮助您监控和排查 Splunk Dataflow 流水线并排查问题),请参阅此博客 Splunk Dataflow 流处理流水线的新可观测性功能。
- 如需查看更多参考架构、图表和最佳实践,请浏览 Cloud 架构中心。