このデプロイのドキュメントでは、Cloud Vision API を使用して画像ファイルを大規模に処理するために Dataflow パイプラインをデプロイする方法について説明します。このパイプラインは、処理されたファイルの結果を BigQuery に保存します。これらのファイルは分析目的で、または BigQuery ML モデルのトレーニングに使用できます。
このデプロイで作成する Dataflow パイプラインは、1 日に数百万の画像を処理できます。唯一の制限は Vision API の割り当てです。スケーリング要件に基づいて Vision API の割り当てを増やすことができます。
この手順は、データ エンジニアとデータ サイエンティストを対象としています。このドキュメントは、Apache Beam の Java SDK、GoogleSQL for BigQuery、基本的なシェル スクリプトを使用して Dataflow パイプラインを構築する方法について基本的な知識があることを前提としています。また、Vision API に精通していることも前提としています。
アーキテクチャ
次の図は、ML ビジョン分析ソリューションを構築するためのシステムフローを説明しています。

上記の図では、アーキテクチャ内の情報フローは次のようになっています。
- クライアントが Cloud Storage バケットに画像ファイルをアップロードします。
- Cloud Storage がデータ アップロードに関するメッセージを Pub/Sub に送信します。
- Pub/Sub がアップロードについて Dataflow に通知します。
- Dataflow パイプラインが画像を Vision API に送信します。
- Vision API が画像を処理し、アノテーションを返します。
- パイプラインは、アノテーションを付けたファイルを分析用に BigQuery に送信します。
目標
- Cloud Storage に読み込まれた画像の画像分析を行う Apache Beam パイプラインを作成します。
- Dataflow Runner v2 を使用して Apache Beam パイプラインをストリーミング モードで実行し、画像がアップロードされるとすぐに分析します。
- Vision API を使用して、複数の機能タイプで画像を分析します。
- BigQuery でアノテーションを分析します。
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
サンプル アプリケーションの構築の完了後は、作成したリソースを削除すれば、それ以上の請求は発生しません。詳細については、クリーンアップをご覧ください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
- Dataflow パイプラインのソースコードを含む GitHub リポジトリのクローンを作成します。
git clone https://github.com/GoogleCloudPlatform/dataflow-vision-analytics.git - リポジトリのルートフォルダに移動します。
cd dataflow-vision-analytics - GitHub の dataflow-vision-analytics リポジトリのスタートガイド セクションに記載されている手順に沿って、次のタスクを完了します。
- 複数の API を有効にします。
- Cloud Storage バケットを作成します。
- Pub/Sub トピックとサブスクリプションを作成します。
- BigQuery データセットを作成します。
- このデプロイ用にいくつかの環境変数を設定します。
Cloud Shell で次のコマンドを実行して、Dataflow パイプラインでサポートされているすべての機能タイプで画像を処理します。
./gradlew run --args=" \ --jobName=test-vision-analytics \ --streaming \ --runner=DataflowRunner \ --enableStreamingEngine \ --diskSizeGb=30 \ --project=${PROJECT} \ --datasetName=${BIGQUERY_DATASET} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=IMAGE_PROPERTIES,LABEL_DETECTION,LANDMARK_DETECTION,LOGO_DETECTION,CROP_HINTS,FACE_DETECTION"専用サービス アカウントには、画像を含むバケットに対する読み取りアクセス権が必要です。つまり、そのアカウントは、同バケットに対する
roles/storage.objectViewerロールを付与されている必要があります。専用サービス アカウントの使用の詳細については、Dataflow のセキュリティと権限をご覧ください。
表示された URL を新しいブラウザタブで開くか、[Dataflow ジョブ] ページに移動して、test-vision-analytics パイプラインを選択します。
数秒後、Dataflow ジョブのグラフが表示されます。
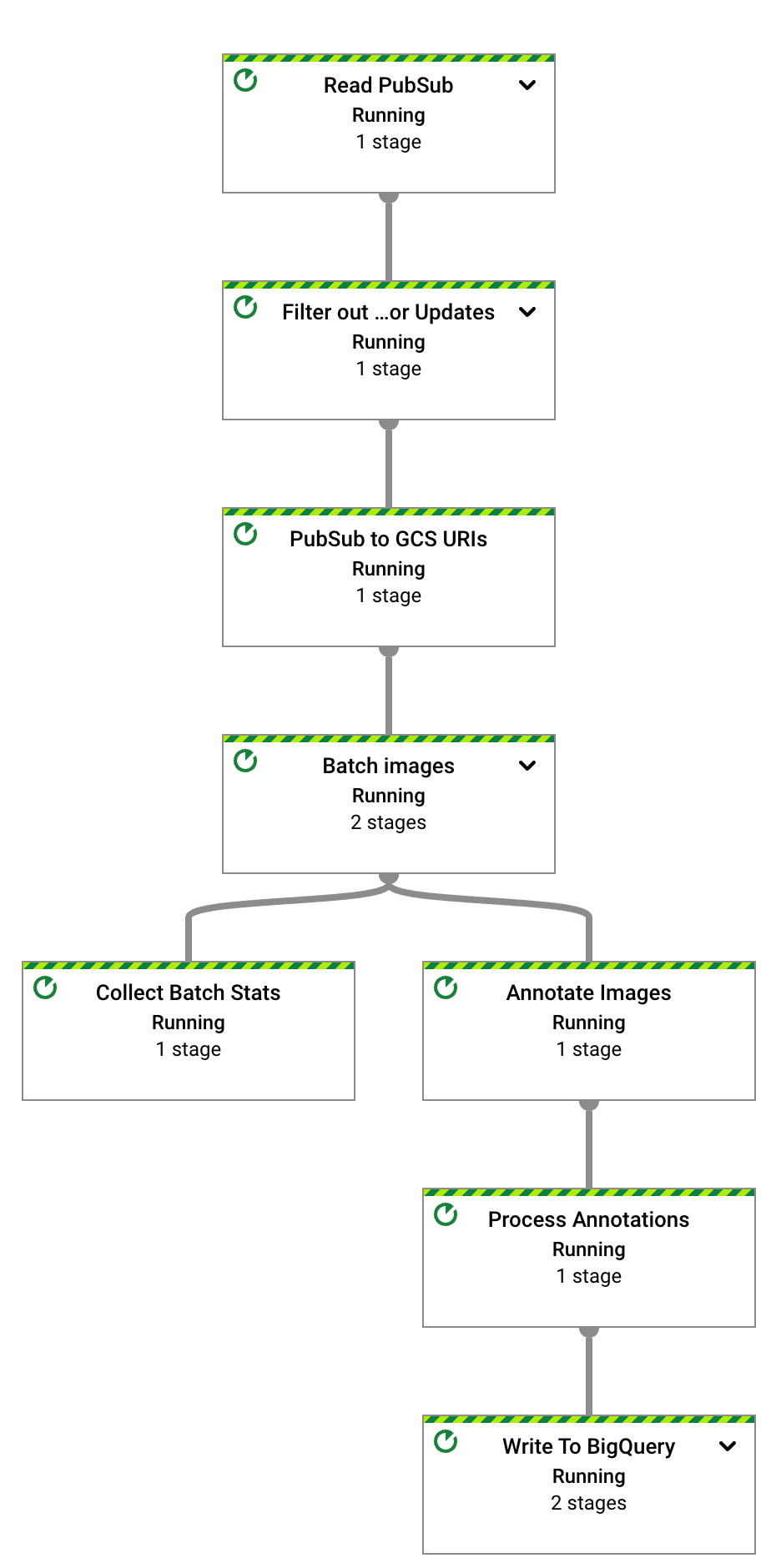
Dataflow パイプラインは現在実行中で、Pub/Sub サブスクリプションから入力通知を受信しようとしています。
6 つのサンプル ファイルを入力バケットにアップロードして、Dataflow 画像処理をトリガーします。
gcloud storage cp data-sample/* gs://${IMAGE_BUCKET}Google Cloud コンソールで、[カスタム カウンタ] パネルを見つけ、Dataflow のカスタム カウンタを確認し、Dataflow が 6 つの画像をすべて処理したことを確認します。パネルのフィルタ機能を使用して、正しい指標に移動できます。
numberOf接頭辞で始まるカウンタのみを表示するには、フィルタに「numberOf」と入力します。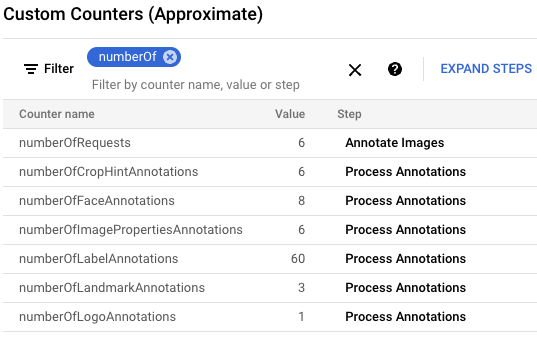
Cloud Shell で、テーブルが自動的に作成されたことを確認します。
bq query --nouse_legacy_sql "SELECT table_name FROM ${BIGQUERY_DATASET}.INFORMATION_SCHEMA.TABLES ORDER BY table_name"出力は次のとおりです。
+----------------------+ | table_name | +----------------------+ | crop_hint_annotation | | face_annotation | | image_properties | | label_annotation | | landmark_annotation | | logo_annotation | +----------------------+
landmark_annotationテーブルのスキーマを表示します。LANDMARK_DETECTION機能は、API 呼び出しから返された属性をキャプチャします。bq show --schema --format=prettyjson ${BIGQUERY_DATASET}.landmark_annotation出力は次のとおりです。
[ { "name":"gcs_uri", "type":"STRING" }, { "name":"feature_type", "type":"STRING" }, { "name":"transaction_timestamp", "type":"STRING" }, { "name":"mid", "type":"STRING" }, { "name":"description", "type":"STRING" }, { "name":"score", "type":"FLOAT" }, { "fields":[ { "fields":[ { "name":"x", "type":"INTEGER" }, { "name":"y", "type":"INTEGER" } ], "mode":"REPEATED", "name":"vertices", "type":"RECORD" } ], "name":"boundingPoly", "type":"RECORD" }, { "fields":[ { "fields":[ { "name":"latitude", "type":"FLOAT" }, { "name":"longitude", "type":"FLOAT" } ], "name":"latLon", "type":"RECORD" } ], "mode":"REPEATED", "name":"locations", "type":"RECORD" } ]次の
bq queryコマンドを実行して、API によって生成されたアノテーション データを表示します。このコマンドを実行すると、6 つの画像で検出されたすべてのランドマークが、最も可能性の高いスコアで並べ替えられます。bq query --nouse_legacy_sql "SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score, locations FROM ${BIGQUERY_DATASET}.landmark_annotation ORDER BY score DESC"出力は次のようになります。
+------------------+-------------------+------------+---------------------------------+ | file_name | description | score | locations | +------------------+-------------------+------------+---------------------------------+ | eiffel_tower.jpg | Eiffel Tower | 0.7251996 | ["POINT(2.2944813 48.8583701)"] | | eiffel_tower.jpg | Trocadéro Gardens | 0.69601923 | ["POINT(2.2892823 48.8615963)"] | | eiffel_tower.jpg | Champ De Mars | 0.6800974 | ["POINT(2.2986304 48.8556475)"] | +------------------+-------------------+------------+---------------------------------+
アノテーションに固有のすべての列の詳細については、
AnnotateImageResponseをご覧ください。ストリーミング パイプラインを停止するには、次のコマンドを実行します。パイプラインは処理する Pub/Sub 通知がなくても実行され続けます。
gcloud dataflow jobs cancel --region ${REGION} $(gcloud dataflow jobs list --region ${REGION} --filter="NAME:test-vision-analytics AND STATE:Running" --format="get(JOB_ID)")次のセクションでは、画像のさまざまな画像特徴を分析するクエリの例を紹介します。
Cloud Shell で、Dataflow パイプライン パラメータを変更して、大規模なデータセット向けに最適化されるようにします。スループットを向上させるには、
batchSizeとkeyRangeの値も増やします。Dataflow は、必要に応じてワーカー数をスケーリングします。./gradlew run --args=" \ --runner=DataflowRunner \ --jobName=vision-analytics-flickr \ --streaming \ --enableStreamingEngine \ --diskSizeGb=30 \ --autoscalingAlgorithm=THROUGHPUT_BASED \ --maxNumWorkers=5 \ --project=${PROJECT} \ --region=${REGION} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=LABEL_DETECTION,LANDMARK_DETECTION \ --datasetName=${BIGQUERY_DATASET} \ --batchSize=16 \ --keyRange=5"データセットが大きいため、Cloud Shell を使用して Kaggle から画像を取得し、Cloud Storage バケットに送信することはできません。そうするためには、ディスクサイズが大きい VM を使用する必要があります。
Kaggle ベースの画像を取得して Cloud Storage バケットに送信するには、GitHub リポジトリのストレージ バケットにアップロードされる画像をシミュレートするセクションの手順を行います。
Dataflow UI で使用可能なカスタム指標を調べて、コピープロセスの進行状況を確認するには、[Dataflow ジョブ] ページに移動して、
vision-analytics-flickrパイプラインを選択します。Dataflow パイプラインがすべてのファイルを処理するまで、カスタム カウンタは定期的に変更されます。出力は、次のカスタム カウンタ パネルのスクリーンショットのようになります。データセット内のファイルの 1 つが不適切な形式であり、
rejectedFilesカウンタがそれを反映しています。これらのカウンタ値はおおよその値です。実際の値はさらに大きくなる可能性があります。また、Vision API による処理の精度が向上するため、アノテーションの数も変化する可能性が高くなります。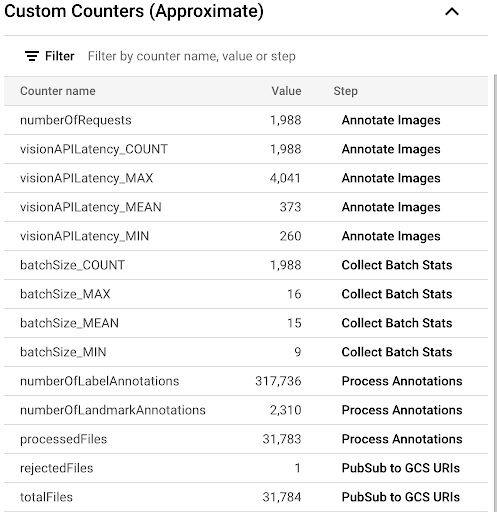
利用可能なリソースに近づいているか、または超過しているかどうかを確認するには、Vision API の割り当てページをご覧ください。
この例では、Dataflow パイプラインは割り当ての約 50% しか使用していません。使用している割り当ての割合に基づいて、
keyRangeパラメータの値を増やして、パイプラインの並列処理を増やすことができます。パイプラインをシャットダウンします。
gcloud dataflow jobs list --region $REGION --filter="NAME:vision-analytics-flickr AND STATE:Running" --format="get(JOB_ID)"Google Cloud コンソールで、BigQuery の [クエリエディタ] ページに移動し、次のコマンドを実行して、データセットの上位 20 個のラベルを表示します。
SELECT description, count(*)ascount \ FROM vision_analytics.label_annotation GROUP BY description ORDER BY count DESC LIMIT 20出力は次のようになります。
+------------------+-------+ | description | count | +------------------+-------+ | Leisure | 7663 | | Plant | 6858 | | Event | 6044 | | Sky | 6016 | | Tree | 5610 | | Fun | 5008 | | Grass | 4279 | | Recreation | 4176 | | Shorts | 3765 | | Happy | 3494 | | Wheel | 3372 | | Tire | 3371 | | Water | 3344 | | Vehicle | 3068 | | People in nature | 2962 | | Gesture | 2909 | | Sports equipment | 2861 | | Building | 2824 | | T-shirt | 2728 | | Wood | 2606 | +------------------+-------+
特定のラベルを持つ画像に存在する他のラベルを、頻度でランク付けします。
DECLARE label STRING DEFAULT 'Plucked string instruments'; WITH other_labels AS ( SELECT description, COUNT(*) count FROM vision_analytics.label_annotation WHERE gcs_uri IN ( SELECT gcs_uri FROM vision_analytics.label_annotation WHERE description = label ) AND description != label GROUP BY description) SELECT description, count, RANK() OVER (ORDER BY count DESC) rank FROM other_labels ORDER BY rank LIMIT 20;出力は次のとおりです。上記のコマンドで使用した「Plucked string instruments」ラベルの場合、次のように表示されます。
+------------------------------+-------+------+ | description | count | rank | +------------------------------+-------+------+ | String instrument | 397 | 1 | | Musical instrument | 236 | 2 | | Musician | 207 | 3 | | Guitar | 168 | 4 | | Guitar accessory | 135 | 5 | | String instrument accessory | 99 | 6 | | Music | 88 | 7 | | Musical instrument accessory | 72 | 8 | | Guitarist | 72 | 8 | | Microphone | 52 | 10 | | Folk instrument | 44 | 11 | | Violin family | 28 | 12 | | Hat | 23 | 13 | | Entertainment | 22 | 14 | | Band plays | 21 | 15 | | Jeans | 17 | 16 | | Plant | 16 | 17 | | Public address system | 16 | 17 | | Artist | 16 | 17 | | Leisure | 14 | 20 | +------------------------------+-------+------+
検出されたランドマークのトップ 10 を表示します。
SELECT description, COUNT(description) AS count FROM vision_analytics.landmark_annotation GROUP BY description ORDER BY count DESC LIMIT 10出力は次のとおりです。
+--------------------+-------+ | description | count | +--------------------+-------+ | Times Square | 55 | | Rockefeller Center | 21 | | St. Mark's Square | 16 | | Bryant Park | 13 | | Millennium Park | 13 | | Ponte Vecchio | 13 | | Tuileries Garden | 13 | | Central Park | 12 | | Starbucks | 12 | | National Mall | 11 | +--------------------+-------+
滝が写っている可能性が高い画像を特定します。
SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score FROM vision_analytics.landmark_annotation WHERE LOWER(description) LIKE '%fall%' ORDER BY score DESC LIMIT 10出力は次のとおりです。
+----------------+----------------------------+-----------+ | file_name | description | score | +----------------+----------------------------+-----------+ | 895502702.jpg | Waterfall Carispaccha | 0.6181358 | | 3639105305.jpg | Sahalie Falls Viewpoint | 0.44379658 | | 3672309620.jpg | Gullfoss Falls | 0.41680416 | | 2452686995.jpg | Wahclella Falls | 0.39005348 | | 2452686995.jpg | Wahclella Falls | 0.3792498 | | 3484649669.jpg | Kodiveri Waterfalls | 0.35024035 | | 539801139.jpg | Mallela Thirtham Waterfall | 0.29260656 | | 3639105305.jpg | Sahalie Falls | 0.2807213 | | 3050114829.jpg | Kawasan Falls | 0.27511594 | | 4707103760.jpg | Niagara Falls | 0.18691841 | +----------------+----------------------------+-----------+
ローマのコロセウムから 3 km 以内のランドマークの画像を探します(
ST_GEOPOINT関数は、コロセウムの経度と緯度を使用します)。WITH landmarksWithDistances AS ( SELECT gcs_uri, description, location, ST_DISTANCE(location, ST_GEOGPOINT(12.492231, 41.890222)) distance_in_meters, FROM `vision_analytics.landmark_annotation` landmarks CROSS JOIN UNNEST(landmarks.locations) AS location ) SELECT SPLIT(gcs_uri,"/")[OFFSET(3)] file, description, ROUND(distance_in_meters) distance_in_meters, location, CONCAT("https://storage.cloud.google.com/", SUBSTR(gcs_uri, 6)) AS image_url FROM landmarksWithDistances WHERE distance_in_meters < 3000 ORDER BY distance_in_meters LIMIT 100このクエリを実行すると、コロッセオの画像が複数あるだけでなく、コンスタンティヌスの凱旋門、パラティーノの丘、その他の写真撮影の多い場所の画像も表示されます。
前のクエリを貼り付けることで、BigQuery Geo Viz でデータを可視化できます。地図上のポイントを選択すると、その詳細が表示されます。
Image_url属性には、画像ファイルへのリンクが含まれます。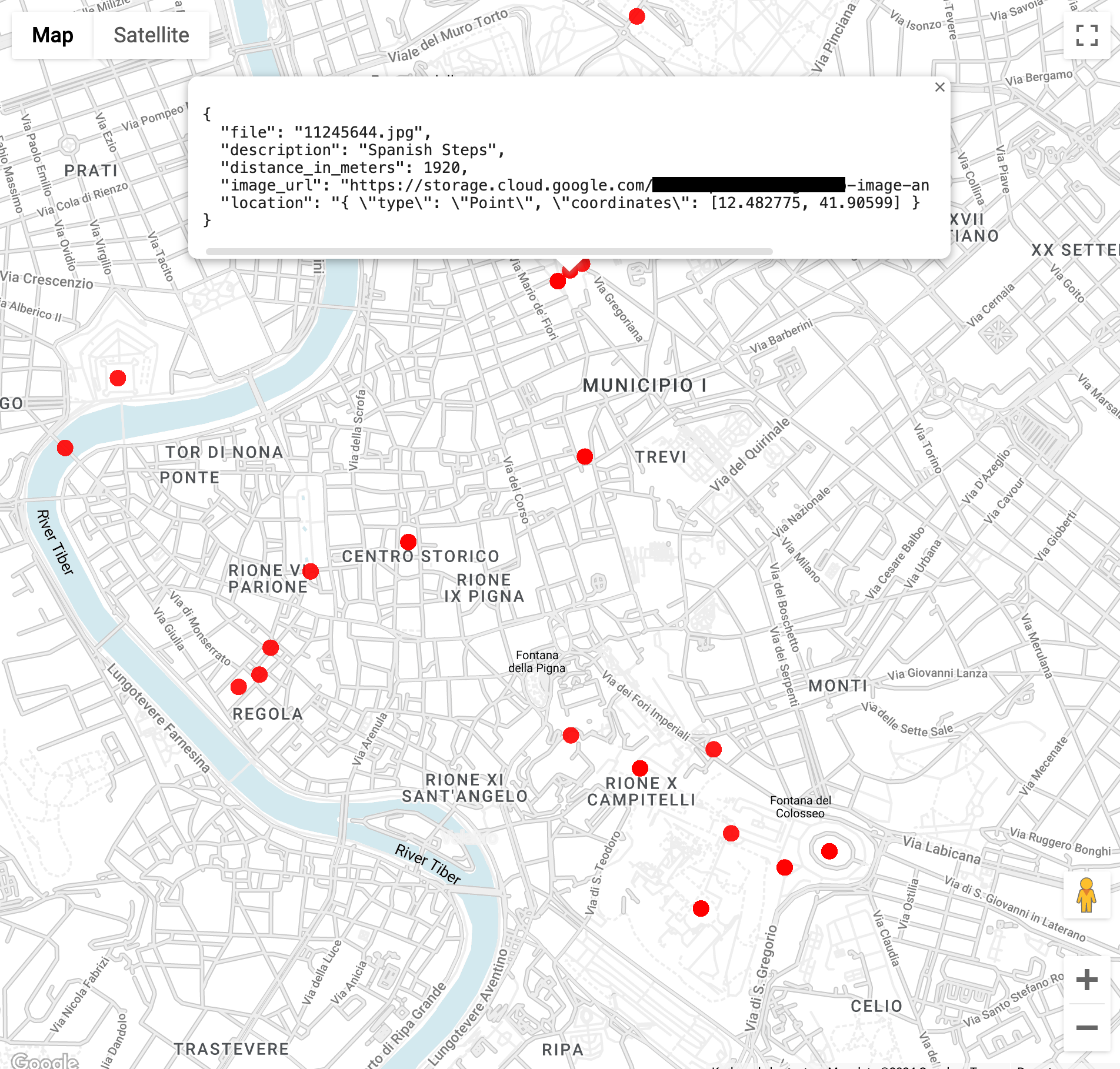
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。
- サイト信頼性エンジニアリング マネージャー | Masud Hasan
- ソリューション アーキテクト Sergei Lilichenko
- テクニカル アカウント マネージャー | Lakshmanan Sethu
- カスタマー エンジニア | Jiyeon Kang
- カスタマー エンジニア | Sunil Kumar Jang Bahadur
実装されたすべての Vision API 機能の Dataflow パイプラインを実行する
Dataflow パイプラインは、アノテーションが付けられたファイル内の特定の Vision API 機能と属性をリクエストして処理します。
次の表に示すパラメータは、このデプロイの Dataflow パイプラインに固有のものです。標準 Dataflow 実行パラメータの一覧については、Dataflow パイプライン オプションを設定するをご覧ください。
| パラメータ名 | 説明 |
|---|---|
|
Vision API へのリクエストに含める画像の数。デフォルトは 1 です。この値は最大 16 まで増やすことができます。 |
|
出力 BigQuery データセットの名前。 |
|
画像処理機能のリスト。このパイプラインは、ラベル、ランドマーク、ロゴ、顔、クロップヒント、画像プロパティの機能をサポートしています。 |
|
Vision API への並列呼び出しの最大数を定義するパラメータ。デフォルトは 1 です。 |
|
さまざまなアノテーションのテーブル名を含む文字列パラメータ。各テーブルにはデフォルト値が用意されています(例: label_annotation)。 |
|
不完全な画像バッチがある場合に、画像を処理するまでの待機時間。デフォルト値は 30 秒です。 |
|
入力の Cloud Storage 通知を受信する Pub/Sub サブスクリプションの ID。 |
|
Vision API で使用するプロジェクト ID。 |
Flickr30K データセットの分析
このセクションでは、Kaggle でホストされている公開 Flickr30k 画像データセットでラベルとランドマークを検出します。
BigQuery でアノテーションを分析する
このデプロイでは、ラベルとランドマークのアノテーションについて 30,000 枚を超える画像を処理しました。このセクションでは、これらのファイルに関する統計情報を収集します。これらのクエリは、BigQuery ワークスペースの GoogleSQL で実行するか、bq コマンドライン ツールを使用できます。
表示される数値は、このデプロイのサンプルクエリの結果とは異なる場合があります。Vision API は分析の精度を常に向上させています。最初にソリューションをテストした後で同じ画像を分析すると、より豊富な結果が得られます。
クエリ結果について注意事項があります。位置情報は通常、ランドマークのために存在しています。同じ画像に、同じランドマークの位置を複数含めることができます。この機能は、AnnotateImageResponse 型で説明されています。
LocationInfo 要素は複数存在することがあります。これは、ある位置で画像内のシーンの場所を示し、別の位置で画像の撮影位置を示す可能性があるためです。
クリーンアップ
このガイドで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
Google Cloud プロジェクトを削除する
課金を停止する最も簡単な方法は、チュートリアル用に作成した Google Cloud プロジェクトを削除することです。
リソースを個別に削除する場合は、GitHub リポジトリのクリーンアップ セクションの手順に沿って操作します。
次のステップ
寄稿者
作成者:
その他の寄稿者: