Ce document décrit une architecture de référence qui vous aide à créer un mécanisme d'exportation de journaux évolutif, tolérant aux pannes et prêt à l'emploi, qui diffuse les journaux et les événements de vos ressources dans Google Cloud vers Splunk. Splunk est un outil d'analyse populaire qui offre une plate-forme unifiée de sécurité et d'observabilité. En fait, vous avez le choix d'exporter les données de journalisation vers Splunk Enterprise ou Splunk Cloud Platform. Si vous êtes administrateur, vous pouvez également utiliser cette architecture pour des opérations informatiques ou des cas d'utilisation de sécurité.
Cette architecture de référence suppose une hiérarchie de ressources semblable au schéma suivant. Tous les journaux des ressources Google Cloud au niveau de l'organisation, du dossier et du projet sont regroupés dans un récepteur agrégé. Le récepteur agrégé envoie ensuite ces journaux à un pipeline d'exportation de journaux, qui traite les journaux et les exporte vers Splunk.

Architecture
Le schéma suivant illustre l'architecture de référence que vous utilisez lorsque vous déployez cette solution. Ce diagramme montre comment les données de journal circulent deGoogle Cloud vers Splunk.

Cette architecture comprend les composants suivants :
- Cloud Logging: pour démarrer le processus, Cloud Logging collecte les journaux dans un récepteur de journaux agrégé au niveau de l'organisation et les envoie à Pub/Sub.
- Pub/Sub: le service Pub/Sub crée ensuite un seul sujet et un seul abonnement pour les journaux, puis les transmet au pipeline Dataflow principal.
- Dataflow: cette architecture de référence comporte deux pipelines Dataflow :
- Pipeline Dataflow principal: au cœur du processus, le pipeline Dataflow principal est un pipeline de flux de données Pub/Sub vers Splunk qui extrait les journaux de l'abonnement Pub/Sub et les transmet à Splunk.
- Pipeline Dataflow secondaire: parallèlement au pipeline Dataflow principal, le pipeline Dataflow secondaire est un pipeline de flux de données Pub/Sub vers Pub/Sub permettant de relire les messages en cas d'échec d'une diffusion.
- Splunk: à la fin du processus, Splunk Enterprise ou Splunk Cloud Platform agit en tant que collecteur d'événements HTTP (HEC pour "HTTP Event Collector") et reçoit les journaux pour une analyse plus approfondie. Vous pouvez déployer Splunk sur site, dans Google Cloud en tant que SaaS ou via une approche hybride.
Cas d'utilisation
Cette architecture de référence utilise une approche cloud de type Push. Dans cette méthode de type Push, vous utilisez le modèle Dataflow Pub/Sub vers Splunk pour diffuser des journaux vers un collecteur d'événements HTTP (HEC) Splunk. L'architecture de référence traite également de la planification de la capacité du pipeline Dataflow et de la façon de gérer les échecs de diffusion potentiels en cas de problèmes de serveur ou de réseau temporaires.
Bien que cette architecture de référence se concentre sur les journaux Google Cloud , vous pouvez utiliser la même architecture pour exporter d'autres données Google Cloud , telles que les modifications d'éléments en temps réel et les résultats de sécurité. En intégrant les journaux de Cloud Logging, vous pouvez continuer à utiliser les services partenaires existants tels que Splunk comme solution unifiée d'analyse des journaux.
La méthode de type Push pour diffuser des données Google Cloud dans Splunk présente les avantages suivants:
- Service géré. En tant que service géré, Dataflow gère les ressources requises dans Google Cloud pour les tâches de traitement de données telles que l'exportation de journaux.
- Charge de travail répartie. Cette méthode vous permet de répartir les charges de travail sur plusieurs nœuds de calcul pour le traitement en parallèle. Il n'y a donc pas de point de défaillance unique.
- Sécurité. Étant donné que Google Cloud transfère vos données vers le collecteur HEC de Splunk, aucune tâche de maintenance ou de sécurité n'est nécessaire pour la création et la gestion des clés de compte de service.
- Autoscaling. Le service Dataflow effectue l'autoscaling du nombre de nœuds de calcul en réponse aux variations du volume de journaux entrants et des tâches en attente.
- Tolérance aux pannes. En cas de problèmes de serveur ou de réseau temporaires, la méthode de type Push tente automatiquement de renvoyer les données au collecteur HEC de Splunk. Elle est également compatible avec les sujets non traités (également appelés sujets des lettres mortes) pour les messages de journal non distribuables afin d'éviter toute perte de données.
- Simplicité. Vous évitez les frais de gestion et le coût d'exécution d'un ou plusieurs redirecteurs lourds dans Splunk.
Cette architecture de référence s'applique aux entreprises de nombreux secteurs, y compris les services réglementés tels que les produits pharmaceutiques et les services financiers. Lorsque vous choisissez d'exporter vos données Google Cloud vers Splunk, vous pouvez choisir de le faire pour les raisons suivantes:
- Analyse commerciale
- Opérations informatiques
- Surveillance des performances des applications
- Opérations de sécurité
- Conformité
Alternatives de conception
Une autre méthode d'exportation des journaux vers Splunk consiste à extraire les journaux deGoogle Cloud. Dans cette méthode de type Pull, vous utilisez les API Google Cloud pour récupérer les données via le module complémentaire Splunk pour Google Cloud. Vous pouvez choisir d'utiliser la méthode de type Pull dans les situations suivantes:
- Votre déploiement Splunk ne propose pas de point de terminaison HEC de Splunk.
- Votre volume de journaux est faible.
- Vous souhaitez exporter et analyser les métriques Cloud Monitoring, les objets Cloud Storage, les métadonnées de l'API Cloud Resource Manager, les données de facturation Cloud ou des journaux à faible volume.
- Vous gérez déjà un ou plusieurs redirecteurs lourds dans Splunk.
- Vous utilisez le gestionnaire de données d'entrées hébergé pour Splunk Cloud.
Gardez également à l'esprit les considérations supplémentaires qui surviennent lorsque vous utilisez cette méthode de type Pull :
- Un seul nœud de calcul gère la charge de travail d'ingestion de données, ce qui ne permet pas d'autoscaling.
- Dans Splunk, l'utilisation d'un redirecteur lourd pour extraire des données peut créer un point de défaillance unique.
- La méthode de type Pull nécessite la création et la gestion des clés de compte de service que vous utilisez pour configurer le module complémentaire Splunk pour Google Cloud.
Avant d'utiliser le module complémentaire Splunk, les entrées de journal doivent d'abord être acheminées vers Pub/Sub à l'aide d'un récepteur de journal. Pour créer un récepteur de journaux avec un sujet Pub/Sub comme destination, consultez la section Créer un récepteur.
Assurez-vous d'accorder le rôle Diffuseur Pub/Sub (roles/pubsub.publisher) à l'identité du rédacteur du récepteur sur cette destination de sujet Pub/Sub. Pour en savoir plus sur la configuration des autorisations de destination du récepteur, consultez la section Définir les autorisations de destination.
Pour activer le module complémentaire Splunk, procédez comme suit :
- Dans Splunk, suivez les instructions Splunk pour installer le module complémentaire Splunk pour Google Cloud.
- Créez un abonnement pull Pub/Sub pour le sujet Pub/Sub vers lequel les journaux sont acheminés, si vous n'en avez pas déjà un.
- Créez un compte de service.
- Créez une clé de compte de service pour le compte de service que vous venez de créer.
- Attribuez au compte de service le rôle Lecteur Pub/Sub (
roles/pubsub.viewer) et Abonné Pub/Sub (roles/pubsub.subscriber) pour permettre au compte de recevoir des messages de l'abonnement Pub/Sub. Dans Splunk, suivez les instructions Splunk pour configurer une nouvelle entrée Pub/Sub dans le module complémentaire Splunk pour Google Cloud.
Les messages Pub/Sub issus de l'exportation des journaux apparaissent dans Splunk.
Pour vérifier que le module complémentaire fonctionne, procédez comme suit :
- Dans Cloud Monitoring, ouvrez l'Explorateur de métriques.
- Dans le menu Ressources, sélectionnez
pubsub_subscription. - Dans les catégories Métrique, sélectionnez
pubsub/subscription/pull_message_operation_count. - Surveillez le nombre d'opérations d'extraction de messages pendant une à deux minutes.
Considérations de conception
Les consignes suivantes peuvent vous aider à développer une architecture répondant aux exigences de votre organisation en termes de sécurité, de confidentialité, de conformité, d'efficacité opérationnelle, de fiabilité, de tolérance aux pannes, de performances et d'optimisation des coûts.
Sécurité, confidentialité et conformité
Les sections suivantes décrivent les considérations de sécurité concernant cette architecture de référence :
- Utiliser des adresses IP privées pour sécuriser les VM compatibles avec le pipeline Dataflow
- Activer l'accès privé à Google
- Limiter le trafic HEC entrant Splunk aux adresses IP connues utilisées par Cloud NAT
- Stocker le jeton HEC de Splunk dans Secret Manager
- Créer un compte de service de nœud de calcul Dataflow personnalisé pour appliquer les bonnes pratiques de moindre privilège
- Configurer la validation SSL d'un certificat CA racine interne si vous utilisez une autorité de certification privée
Utiliser des adresses IP privées pour sécuriser les VM compatibles avec le pipeline Dataflow
Vous devez limiter l'accès aux VM de nœud de calcul utilisées dans le pipeline Dataflow. Pour restreindre l'accès, déployez ces VM avec des adresses IP privées. Cependant, ces VM doivent également pouvoir utiliser HTTPS pour diffuser les journaux exportés vers Splunk et accéder à Internet. Pour fournir cet accès HTTPS, vous avez besoin d'une passerelle Cloud NAT qui attribue automatiquement des adresses IP Cloud NAT aux VM qui en ont besoin. Assurez-vous de mapper le sous-réseau contenant les VM à la passerelle Cloud NAT.
Activer l'accès privé à Google
Lorsque vous créez une passerelle Cloud NAT, l'accès privé à Google est automatiquement activé. Toutefois, pour permettre aux nœuds de calcul Dataflow ayant des adresses IP privées d'accéder aux adresses IP externes utilisées par les API et les services Google Cloud, vous devez également activer manuellement l'accès privé à Google pour le sous-réseau.
Limiter le trafic entrant HEC Splunk aux adresses IP connues utilisées par Cloud NAT
Si vous souhaitez limiter le trafic dans un sous-ensemble d'adresses IP connues à l'aide de la solution HEC de Splunk, vous pouvez réserver des adresses IP statiques et les attribuer manuellement à la passerelle Cloud NAT. Selon votre déploiement Splunk, vous pouvez ensuite configurer vos règles de pare-feu d'entrée HEC Splunk avec ces adresses IP statiques. Pour en savoir plus sur Cloud NAT, consultez la page Configurer et gérer la traduction d'adresses réseau avec Cloud NAT.
Stocker le jeton HEC de Splunk dans Secret Manager
Lorsque vous déployez le pipeline Dataflow, vous pouvez transmettre la valeur du jeton de l'une des manières suivantes :
- Texte brut
- Texte chiffré avec une clé Cloud Key Management Service
- Version du secret chiffrée et gérée par Secret Manager
Dans cette architecture de référence, vous utilisez l'option Secret Manager, car elle constitue le moyen le moins complexe et le plus efficace de protéger votre jeton HEC Splunk. Cette option évite également la fuite du jeton HEC Splunk dans la console Dataflow ou dans les détails de la tâche.
Dans Secret Manager, un secret contient un ensemble de versions de secrets. Chaque version de secret stocke les données réelles du secret, telles que le jeton HEC Splunk. Si vous choisissez ultérieurement d'effectuer une rotation de votre jeton HEC Splunk comme mesure de sécurité supplémentaire, vous pouvez ajouter le nouveau jeton en tant que nouvelle version de secret à ce secret. Pour obtenir des informations générales sur la rotation des secrets, consultez la section À propos des calendriers de rotation.
Créer un compte de service de nœud de calcul Dataflow personnalisé pour appliquer les bonnes pratiques de moindre privilège
Les nœuds de calcul du pipeline Dataflow utilisent le compte de service de nœud de calcul Dataflow pour accéder aux ressources et exécuter des opérations. Par défaut, les nœuds de calcul utilisent le compte de service Compute Engine par défaut de votre projet en tant que compte de service de nœud de calcul, ce qui leur accorde des autorisations étendues pour toutes les ressources de votre projet. Toutefois, pour exécuter des tâches Dataflow en production, nous vous recommandons de créer un compte de service personnalisé avec un ensemble minimal de rôles et d'autorisations. Vous pouvez ensuite attribuer ce compte de service personnalisé à vos nœuds de calcul de pipeline Dataflow.
Le schéma suivant répertorie les rôles que vous devez attribuer à un compte de service pour permettre aux nœuds de calcul Dataflow d'exécuter une tâche Dataflow.
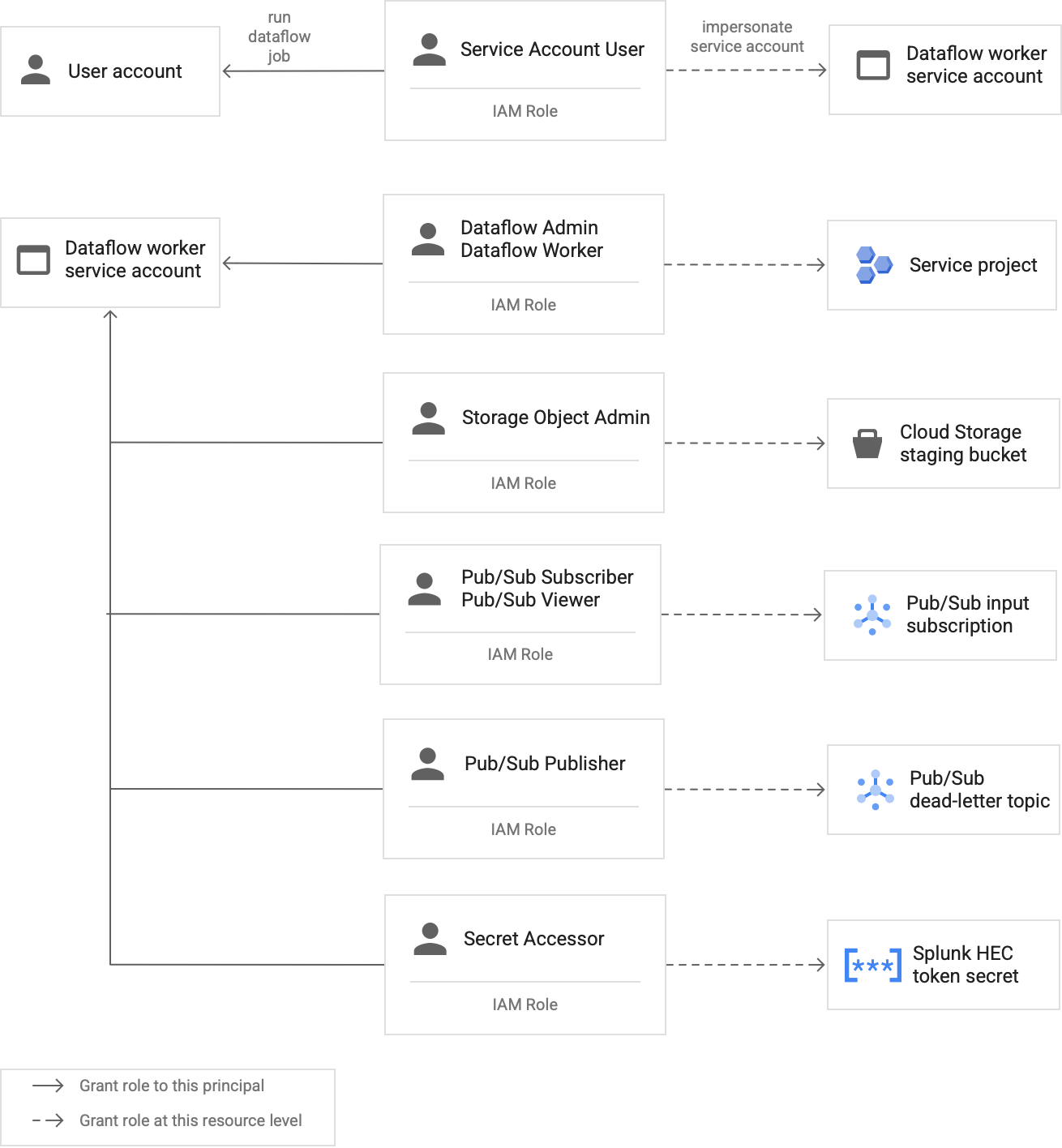
Comme illustré dans le schéma, vous devez attribuer les rôles suivants au compte de service de votre nœud de calcul Dataflow :
- Administrateur Dataflow
- Nœud de calcul Dataflow
- Administrateur des objets Storage
- Abonné Pub/Sub
- Lecteur Pub/Sub
- Diffuseur Pub/Sub
- Accesseur de secrets
Configurer la validation SSL avec un certificat CA racine interne lorsque vous utilisez une autorité de certification privée
Par défaut, le pipeline Dataflow utilise le magasin de confiance par défaut du nœud de calcul Dataflow pour valider le certificat SSL de votre point de terminaison HEC Splunk. Si vous utilisez une autorité de certification privée pour signer un certificat SSL utilisé par le point de terminaison HEC Splunk, vous pouvez importer votre certificat CA racine interne dans le magasin de confiance. Les nœuds de calcul Dataflow peuvent ensuite utiliser le certificat importé pour valider le certificat SSL.
Vous pouvez utiliser et importer votre propre certificat CA racine interne pour les déploiements Splunk avec des certificats autosignés ou privés. Vous pouvez également désactiver complètement la validation SSL à des fins de développement et de test en interne. Cette méthode d'autorité de certification racine interne est optimale pour les déploiements Splunk internes qui ne sont pas connectés à Internet.
Pour en savoir plus, consultez les sections Paramètres de modèle Dataflow Pub/Sub vers Splunk
rootCaCertificatePath et disableCertificateValidation.
Efficacité opérationnelle
Les sections suivantes décrivent les considérations relatives à l'efficacité opérationnelle pour cette architecture de référence :
- Utiliser des fonctions définies par l'utilisateur pour transformer les journaux ou les événements en cours de transfert
- Relire les messages non traités
Utiliser des fonctions définies par l'utilisateur pour transformer les journaux ou les événements en cours de transfert
Le modèle Dataflow Pub/Sub vers Splunk est compatible avec les fonctions définies par l'utilisateur pour les transformations d'événements personnalisés. Les cas d'utilisation incluent l'enrichissement des enregistrements par le biais de champs supplémentaires, le masquage de certains champs sensibles ou le filtrage des enregistrements indésirables. Les fonctions définies par l'utilisateur permettent de modifier le format de sortie du pipeline Dataflow sans avoir à recompiler ou gérer le code du modèle. Cette architecture de référence utilise une fonction définie par l'utilisateur pour gérer les messages que le pipeline ne peut pas distribuer à Splunk.
Relire les messages non traités
Parfois, le pipeline reçoit des erreurs de distribution et n'essaie pas de distribuer à nouveau le message. Dans ce cas, Dataflow envoie ces messages non traités à un sujet non traité, comme indiqué dans le schéma suivant. Une fois que vous avez corrigé la cause première de l'échec de distribution, vous pouvez relire les messages non traités.
Les étapes suivantes décrivent le processus illustré dans le schéma précédent :
- Le pipeline de distribution principal de Pub/Sub vers Splunk transfère automatiquement les messages non distribuables vers le sujet non traité, à des fins d'enquête utilisateur.
L'opérateur ou l'ingénieur en fiabilité des sites (SRE) examine les messages ayant échoué dans l'abonnement non traité. L'opérateur résout les problèmes et corrige la cause de l'échec de diffusion. Par exemple, la correction d'une mauvaise configuration du jeton HEC peut permettre la distribution des messages.
L'opérateur déclenche la répétition du pipeline de messages ayant échoué. Ce pipeline Pub/Sub vers Pub/Sub (mis en surbrillance dans la section en pointillés du schéma précédent) est un pipeline temporaire qui retourne les messages ayant échoué de l'abonnement non traité vers le sujet du récepteur de journaux d'origine.
Le pipeline de livraison principal effectue un nouveau traitement des messages ayant échoué précédemment. Cette étape nécessite que le pipeline utilise une UDF#39;utilisateur pour détecter et décoder correctement les charges utiles des messages ayant échoué. Le code suivant est un exemple de fonction qui met en œuvre cette logique de décodage conditionnel, y compris le décompte des tentatives de distribution à des fins de suivi:
// If the message has already been converted to a Splunk HEC object // with a stringified obj.event JSON payload, then it's a replay of // a previously failed delivery. // Unnest and parse the obj.event. Drop the previously injected // obj.attributes such as errorMessage and timestamp if (obj.event) { try { event = JSON.parse(obj.event); redelivery = true; } catch(e) { event = obj; } } else { event = obj; } // Keep a tally of delivery attempts event.delivery_attempt = event.delivery_attempt || 1; if (redelivery) { event.delivery_attempt += 1; }
Fiabilité et tolérance aux pannes
En ce qui concerne la fiabilité et la tolérance aux pannes, le tableau 1 ci-dessous répertorie certaines erreurs de diffusion Splunk possibles. Le tableau répertorie également les attributs errorMessage correspondants que le pipeline enregistre avec chaque message avant de les transférer vers le sujet non traité.
Tableau 1 : Types d'erreurs de diffusion Splunk
| Type d'erreurs de diffusion | Nouvelle tentative automatique par pipeline ? | Exemple d'attribut errorMessage |
|---|---|---|
Erreur réseau temporaire |
Oui |
ou
|
Erreur 5xx du serveur Splunk |
Oui |
|
Erreur 4xx du serveur Splunk |
Non |
|
Serveur Splunk en panne |
Non |
|
Certificat SSL Splunk non valide |
Non |
|
Erreur de syntaxe JavaScript dans la fonction définie par l'utilisateur |
Non |
|
Dans certains cas, le pipeline applique un intervalle exponentiel entre les tentatives et tente à nouveau de distribuer le message. Par exemple, lorsque le serveur Splunk génère un code d'erreur 5xx, le pipeline doit redistribuer le message. Ces codes d'erreur se produisent lorsque le point de terminaison HEC Splunk est surchargé.
Il est également possible qu'un problème persistant empêche l'envoi d'un message au point de terminaison HEC. Pour de tels problèmes persistants, le pipeline n'essaie pas de distribuer à nouveau le message. Voici des exemples de problèmes persistants :
- Erreur de syntaxe dans la fonction définie par l'utilisateur.
- Jeton HEC non valide qui oblige le serveur Splunk à générer une réponse de serveur "Forbidden"
4xx.
Optimisation des performances et des coûts
En ce qui concerne l'optimisation des performances et des coûts, vous devez déterminer la taille maximale et le débit de votre pipeline Dataflow. Vous devez calculer les valeurs de taille et de débit appropriées pour que votre pipeline puisse gérer le volume quotidien de journaux (Go/jour) et la fréquence des messages de journal (événements par seconde ou EPS) provenant de l'abonnement Pub/Sub en amont.
Vous devez sélectionner les valeurs de taille et de débit pour que le système ne souffre d'aucun des problèmes suivants :
- Retards dus à la mise en attente de messages ou à des limitations de bande passante pour les messages.
- Coûts supplémentaires liés au surprovisionnement d'un pipeline.
Après avoir effectué les calculs de taille et de débit, vous pouvez utiliser les résultats pour configurer un pipeline optimal afin d'équilibrer les performances et les coûts. Pour configurer la capacité de votre pipeline, utilisez les paramètres suivants :
- Les indicateurs Type de machine et Nombre de machines font partie de la commande gcloud qui déploie le job Dataflow. Ces options vous permettent de définir le type et le nombre de VM à utiliser.
- Les paramètres Parallélisme et Nombre de lots font partie des paramètres du Modèle Dataflow Pub/Sub vers Splunk. Ces paramètres sont importants pour augmenter les EPS tout en évitant de surcharger le point de terminaison HEC Splunk.
Les sections suivantes expliquent ces paramètres. Le cas échéant, ces sections fournissent également des formules et des exemples de calcul utilisant chaque formule. Ces exemples de calculs et les valeurs obtenues supposent qu'une organisation présente les caractéristiques suivantes :
- Génère 1 To de journaux quotidiennement.
- La taille moyenne du message est de 1 Ko.
- Le pic des messages est deux fois supérieur à la moyenne.
Votre environnement Dataflow étant unique, vous devez remplacer les exemples de valeurs par les valeurs de votre propre organisation au fur et à mesure que vous franchissez les étapes.
Type de machine
Bonne pratique : Définissez l'indicateur --worker-machine-type sur n2-standard-4 pour sélectionner la taille de machine offrant le meilleur rapport performance-coût.
Comme le type de machine n2-standard-4 peut gérer 12 000 EPS, nous vous recommandons de l'utiliser comme référence pour tous vos nœuds de calcul Dataflow.
Pour cette architecture de référence, définissez l'indicateur --worker-machine-type sur la valeur n2-standard-4.
Nombre de machines
Bonne pratique : Définissez l'option --max-workers pour contrôler le nombre maximal de nœuds de calcul nécessaires pour gérer le pic d'EPS attendu.
L'autoscaling de Dataflow permet au service de modifier de manière adaptative le nombre de nœuds de calcul utilisés pour exécuter votre pipeline de flux en cas de modifications de l'utilisation et de la charge des ressources. Pour éviter le surprovisionnement lors de l'autoscaling, nous vous recommandons de toujours définir le nombre maximal de machines virtuelles utilisées en tant que nœuds de calcul Dataflow. Vous définissez le nombre maximal de machines virtuelles avec l'indicateur --max-workers lorsque vous déployez le pipeline Dataflow.
Dataflow provisionne le composant de stockage de manière statique comme suit :
Un pipeline d'autoscaling déploie un disque persistant pour chaque nœud de calcul par flux potentiel. La taille de disque persistant par défaut est de 400 Go et vous définissez le nombre maximal de nœuds de calcul avec l'option
--max-workers. Les disques sont installés à tout moment sur les nœuds de calcul en cours d'exécution, y compris le démarrage.Étant donné que chaque instance de nœud de calcul est limitée à 15 disques persistants, le nombre minimal de nœuds de calcul de démarrage est de
⌈--max-workers/15⌉. Ainsi, si la valeur par défaut est--max-workers=20, l'utilisation (et le coût) du pipeline est la suivante :- Stockage : statique avec 20 disques persistants.
- Calcul : dynamique avec au moins deux instances de nœud de calcul (⌈20/15⌉ = 2) et un maximum de 20.
Cette valeur équivaut à 8 To sur un disque persistant. Cette taille de disque persistant peut entraîner des coûts inutiles si les disques ne sont pas complètement utilisés, en particulier si seulement un ou deux nœuds de calcul sont exécutés la majorité du temps.
Pour déterminer le nombre maximal de nœuds de calcul dont vous avez besoin pour votre pipeline, utilisez les formules suivantes dans l'ordre :
Déterminez la moyenne des événements par seconde (EPS) à l'aide de la formule suivante :
\( {AverageEventsPerSecond}\simeq\frac{TotalDailyLogsInTB}{AverageMessageSizeInKB}\times\frac{10^9}{24\times3600} \)Exemple de calcul : avec des exemples de valeurs de 1 To de journaux par jour avec une taille de message moyenne de 1 Ko, cette formule génère une valeur EPS moyenne de 11 500 EPS.
Déterminez le pic d'EPS soutenu à l'aide de la formule suivante, où le multiplicateur N représente la nature intensive de la journalisation :
\( {PeakEventsPerSecond = N \times\ AverageEventsPerSecond} \)Exemple de calcul : pour un exemple de valeurN=2 et la valeur moyenne EPS de 11 500 que vous avez calculée à l'étape précédente, cette formule génère une valeur maximale d'EPS soutenue de 23 000 EPS.
Déterminez le nombre maximal de processeurs virtuels requis à l'aide de la formule suivante :
\( {maxCPUs = ⌈PeakEventsPerSecond / 3k ⌉} \)Exemple de calcul : en utilisant le pic d'EPS soutenu de 23 000 que vous avez calculé à l'étape précédente, cette formule génère un maximum de ⌈23 / 3⌉ = 8 cœurs de processeur virtuel.
Déterminez le nombre maximal de nœuds de calcul Dataflow à l'aide de la formule suivante :
\( maxNumWorkers = ⌈maxCPUs / 4 ⌉ \)Exemple de calcul : en utilisant l'exemple de valeur maximale de nombre de processeurs virtuels de 8 calculée à l'étape précédente, cette formule [8/4] génère un nombre maximal de 2 pour un type de machine
n2-standard-4.
Pour cet exemple, vous devez définir l'option --max-workers sur une valeur de 2 basée sur l'ensemble d'exemples de calculs précédent. Toutefois, n'oubliez pas d'utiliser vos propres valeurs et calculs uniques lorsque vous déployez cette architecture de référence dans votre environnement.
Parallélisme
Bonne pratique : Définissez le paramètre parallelism dans le modèle Dataflow Pub/Sub vers Splunk sur deux fois le nombre de processeurs virtuels utilisés par le nombre maximal de nœuds de calcul Dataflow.
Le paramètre parallelism permet de maximiser le nombre de connexions HEC parallèles à Splunk, ce qui optimise le taux d'EPS de votre pipeline.
La valeur parallelism par défaut de 1 désactive le parallélisme et limite le débit de sortie. Vous devez remplacer ce paramètre par défaut pour prendre en compte deux à quatre connexions parallèles par processeur virtuel, ainsi que le nombre maximal de nœuds de calcul déployés. En règle générale, vous calculez la valeur de remplacement de ce paramètre en multipliant le nombre maximal de nœuds de calcul Dataflow par le nombre de processeurs virtuels par nœud de calcul, puis en doublant la valeur obtenue.
Pour déterminer le nombre total de connexions parallèles au collecteur HEC de Splunk sur l'ensemble des nœuds de calcul Dataflow, utilisez la formule suivante :
Exemple de calcul : En utilisant l'exemple d'un maximum de 8 processeurs virtuels précédemment calculé pour le nombre de machines, cette formule génère un nombre de connexions parallèles de 16 (8 x 2).
Pour cet exemple, vous devez définir le paramètre parallelism sur une valeur 16 basée sur l'exemple de calcul précédent. Toutefois, n'oubliez pas d'utiliser vos propres valeurs et calculs uniques lorsque vous déployez cette architecture de référence dans votre environnement.
Nombre de lots
Bonne pratique : Pour permettre au HEC de Splunk de traiter les événements par lot plutôt qu'un par un, définissez le paramètre batchCount sur une valeur. entre 10 et 50 événements/requête pour les journaux.
La configuration du nombre de lots permet d'augmenter l'EPS et de réduire la charge sur le point de terminaison HEC de Splunk. Ce paramètre combine plusieurs événements en un seul lot pour un traitement plus efficace. Nous vous recommandons de définir le paramètre batchCount sur une valeur comprise entre 10 et 50 événements/requête pour les journaux, à condition que le délai maximal de mise en mémoire tampon de deux secondes soit acceptable.
Étant donné que la taille moyenne des messages de journal est de 1 Ko dans cet exemple, nous vous recommandons de regrouper au moins 10 événements par requête. Pour cet exemple, vous devez définir le paramètre batchCount sur la valeur 10. Toutefois, n'oubliez pas d'utiliser vos propres valeurs et calculs uniques lorsque vous déployez cette architecture de référence dans votre environnement.
Pour en savoir plus sur ces recommandations en matière d'optimisation des performances et des coûts, consultez la page Planifier votre pipeline Dataflow.
Étape suivante
- Pour obtenir la liste complète des paramètres du modèle Dataflow Pub/Sub vers Splunk, consultez la documentation Dataflow Pub/Sub vers Splunk.
- Pour obtenir les modèles Terraform correspondants pour vous aider à déployer cette architecture de référence, consultez le dépôt GitHub
terraform-splunk-log-export. Il inclut un tableau de bord Cloud Monitoring prédéfini pour surveiller votre pipeline Dataflow Splunk. - Pour en savoir plus sur les métriques et la journalisation personnalisées Dataflow avec Splunk, afin de vous aider à surveiller vos pipelines Dataflow Splunk et à résoudre les problèmes associés, consultez l'article de blog Nouvelles fonctionnalités d'observabilité pour vos pipelines de streaming Dataflow Splunk.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.