BigQuery Studio 노트북에서 PySpark 코드 실행
이 문서에서는 BigQuery Python 노트북에서 PySpark 코드를 실행하는 방법을 보여줍니다.
시작하기 전에
아직 만들지 않았다면 Google Cloud 프로젝트와 Cloud Storage 버킷을 만듭니다.
프로젝트 설정
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 사용할 수 있는 버킷이 없으면 프로젝트에 Cloud Storage 버킷을 만듭니다.
노트북 설정하기
- 노트북 사용자 인증 정보: 기본적으로 노트북 세션은 사용자 인증 정보를 사용합니다. 또는 세션 서비스 계정 사용자 인증 정보를 사용할 수 있습니다.
- 사용자 사용자 인증 정보: 사용자 계정에는 다음 Identity and Access Management 역할이 있어야 합니다.
- Dataproc 편집자 (
roles/dataproc.editor역할) - BigQuery Studio 사용자 (
roles/bigquery.studioUser역할) - 세션 서비스 계정에 대한 서비스 계정 사용자 (roles/iam.serviceAccountUser) 역할
이 역할에는 서비스 계정을 가장하는 데 필요한
iam.serviceAccounts.actAs권한이 포함되어 있습니다.
- Dataproc 편집자 (
- 서비스 계정 사용자 인증 정보: 노트북 세션에 사용자 사용자 인증 정보 대신 서비스 계정 사용자 인증 정보를 지정하려면 세션 서비스 계정에 다음 역할이 있어야 합니다.
- 사용자 사용자 인증 정보: 사용자 계정에는 다음 Identity and Access Management 역할이 있어야 합니다.
- 노트북 런타임: 다른 런타임을 선택하지 않는 한 노트북에서 기본 Vertex AI 런타임을 사용합니다. 자체 런타임을 정의하려면 Google Cloud 콘솔의 런타임 페이지에서 런타임을 만드세요. NumPy 라이브러리를 사용하는 경우 노트북 런타임에서 Spark 3.5에서 지원하는 NumPy 버전 1.26을 사용하세요.참고
- 노트북 사용자 인증 정보: 기본적으로 노트북 세션은 사용자 인증 정보를 사용합니다. 또는 세션 서비스 계정 사용자 인증 정보를 사용할 수 있습니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
세부정보 창의 탭 표시줄에서 + 기호 옆에 있는 화살표를 클릭한 다음 노트북을 클릭합니다.
- 노트북에서 단일 세션을 구성하고 만듭니다.
- 대화형 세션 템플릿에서 Spark 세션을 구성한 다음 템플릿을 사용하여 노트북에서 세션을 구성하고 만듭니다.
BigQuery는 템플릿화된 Spark 세션 탭에 설명된 대로 템플릿화된 세션 코딩을 시작하는 데 도움이 되는
Query using Spark기능을 제공합니다. 편집기 창의 탭 표시줄에서 + 기호 옆에 있는 화살표 드롭다운을 클릭한 다음 노트북을 클릭합니다.
노트북 셀에서 다음 코드를 복사하고 실행하여 기본 Spark 세션을 구성하고 만듭니다.
- APP_NAME: 세션의 이름입니다(선택사항).
- 선택적 세션 설정: Dataproc API
Session설정을 추가하여 세션을 맞춤설정할 수 있습니다. 다음은 몇 가지 예입니다.RuntimeConfig: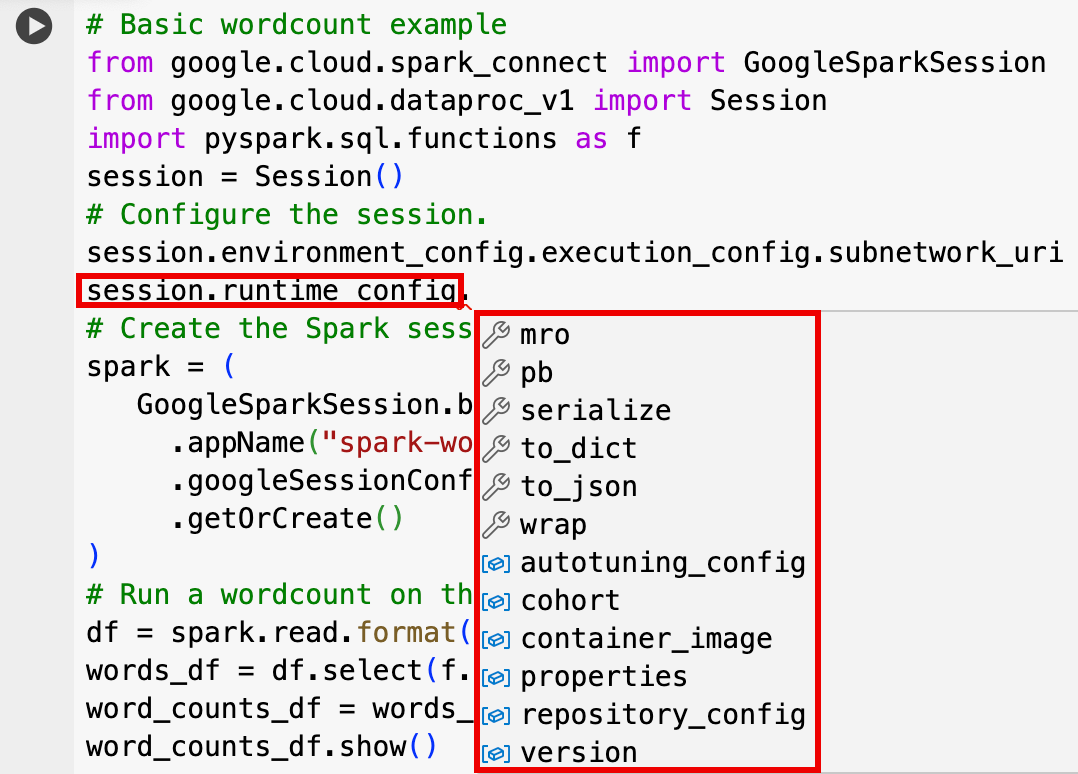
session.runtime_config.properties={spark.property.key1:VALUE_1,...,spark.property.keyN:VALUE_N}session.runtime_config.container_image = path/to/container/image
EnvironmentConfig: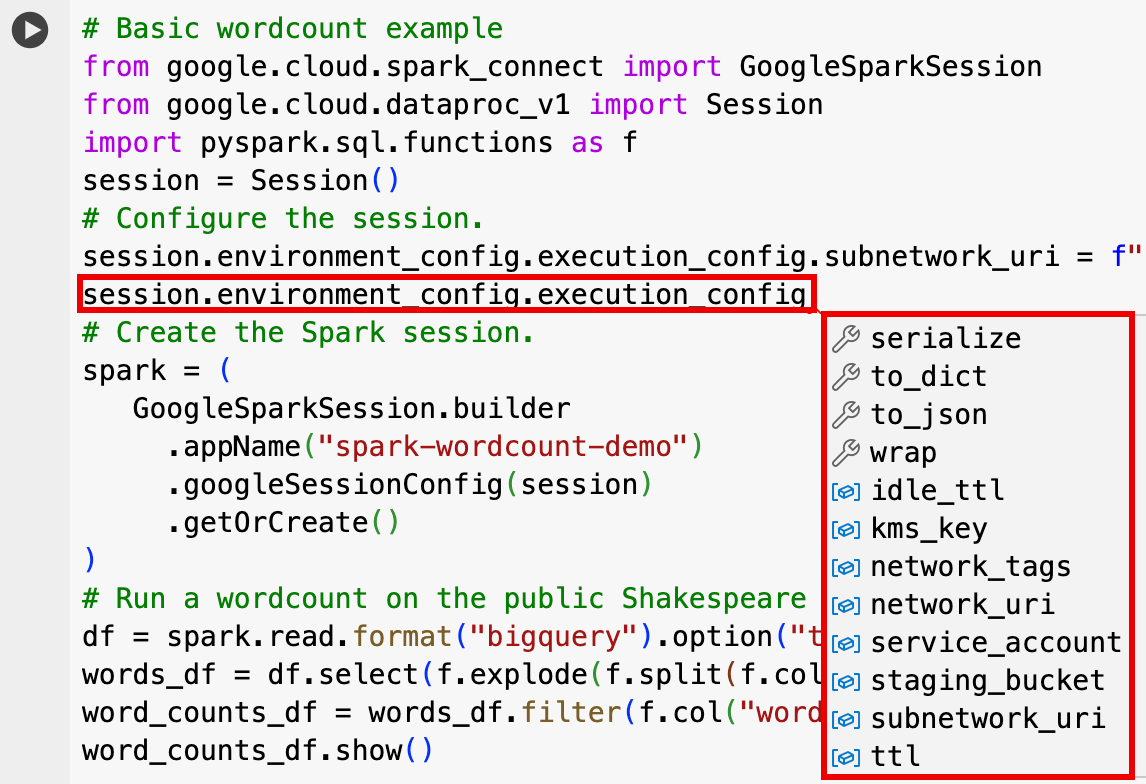
- session.environment_config.execution_config.subnetwork_uri = "SUBNET_NAME"
session.environment_config.execution_config.ttl = {"seconds": VALUE}session.environment_config.execution_config.service_account = SERVICE_ACCOUNT
- 편집기 창의 탭 표시줄에서 + 기호 옆에 있는 화살표 드롭다운을 클릭한 다음 노트북을 클릭합니다.
- 템플릿으로 시작에서 Spark를 사용하여 쿼리를 클릭한 다음 템플릿 사용을 클릭하여 노트북에 코드를 삽입합니다.
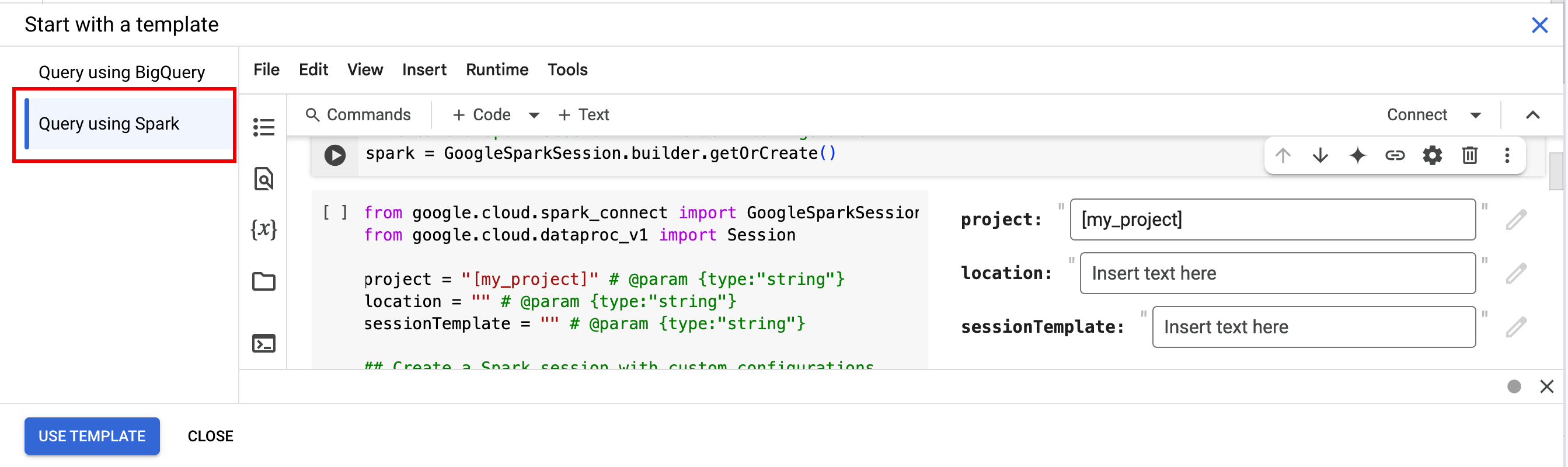
- 참고에 설명된 대로 변수를 지정합니다.
- 노트북에 삽입된 추가 샘플 코드 셀을 삭제할 수 있습니다.
- PROJECT: 프로젝트 ID. Google Cloud 콘솔 대시보드의 프로젝트 정보 섹션에 나열됩니다.
- LOCATION: 노트북 세션이 실행되는 Compute Engine 리전입니다. 제공되지 않으면 기본 위치는 노트북을 만드는 VM의 리전입니다.
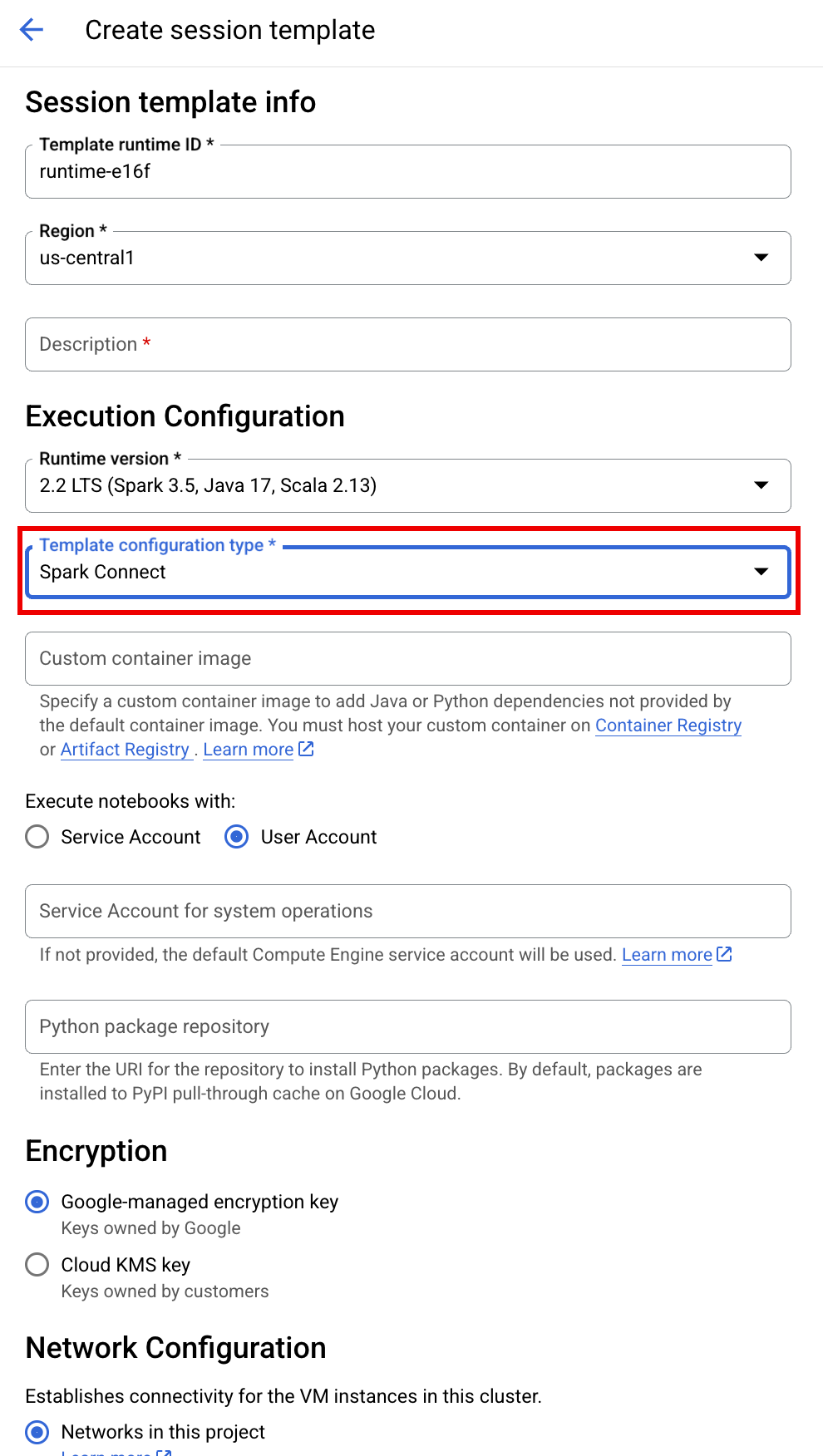
SESSION_TEMPLATE: 기존 대화형 세션 템플릿의 이름입니다. 세션 구성 설정은 템플릿에서 가져옵니다. 템플릿은 다음 설정도 지정해야 합니다.
- 런타임 버전
2.3+ 노트북 유형:
Spark Connect예:
- 런타임 버전
APP_NAME: 세션의 이름입니다(선택사항).
- 공개 셰익스피어 데이터 세트에 대해 wordcount를 실행합니다.
- BigLake metastore에 저장된 메타데이터를 사용하여 Iceberg 테이블을 만듭니다.
- APP_NAME: 세션의 이름입니다(선택사항).
- PROJECT: 프로젝트 ID. Google Cloud 콘솔 대시보드의 프로젝트 정보 섹션에 나열됩니다.
- REGION 및 SUBNET_NAME: Compute Engine 리전과 세션 리전의 서브넷 이름을 지정합니다. Apache Spark용 서버리스는 지정된 서브넷에서 비공개 Google 액세스 (PGA)를 사용 설정합니다.
- LOCATION: 기본
BigQuery_metastore_config.location및spark.sql.catalog.{catalog}.gcp_location는US이지만 지원되는 BigQuery 위치를 선택할 수 있습니다. - BUCKET 및 WAREHOUSE_DIRECTORY: Iceberg 웨어하우스 디렉터리에 사용되는 Cloud Storage 버킷 및 폴더입니다.
- CATALOG_NAME 및 NAMESPACE: Iceberg 카탈로그 이름과 네임스페이스가 결합되어 Iceberg 테이블(
catalog.namespace.table_name)을 식별합니다. - APP_NAME: 세션의 이름입니다(선택사항).
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
프로젝트 리소스 창에서 프로젝트를 클릭한 다음 네임스페이스를 클릭하여
sample_iceberg_table테이블을 나열합니다. 세부정보 표를 클릭하여 카탈로그 테이블 구성 열기 정보를 확인합니다.입력 및 출력 형식은 Iceberg에서 사용하는 표준 Hadoop
InputFormat및OutputFormat클래스 형식입니다.
툴바에서 + 코드를 클릭하여 새 코드 셀을 삽입합니다. 새 코드 셀에
Start coding or generate with AI가 표시됩니다. 생성을 클릭합니다.생성 편집기에서 자연어 프롬프트를 입력한 후
enter아이콘을 클릭합니다. 프롬프트에spark또는pyspark키워드가 포함되어야 합니다.샘플 프롬프트:
create a spark dataframe from order_items and filter to orders created in 2024
샘플 출력:
spark.read.format("bigquery").option("table", "sqlgen-testing.pysparkeval_ecommerce.order_items").load().filter("year(created_at) = 2024").createOrReplaceTempView("order_items") df = spark.sql("SELECT * FROM order_items")Gemini Code Assist가 관련 테이블과 스키마를 가져오도록 하려면 Dataproc Metastore 인스턴스에 Data Catalog 동기화를 사용 설정하세요.
사용자 계정에 Data Catalog 쿼리 테이블에 대한 액세스 권한이 있는지 확인합니다. 이를 위해
DataCatalog.Viewer역할을 할당합니다.- 노트북 셀에서
spark.stop()를 실행합니다. - 노트북에서 런타임을 종료합니다.
- 런타임 선택기를 클릭한 다음 세션 관리를 클릭합니다.
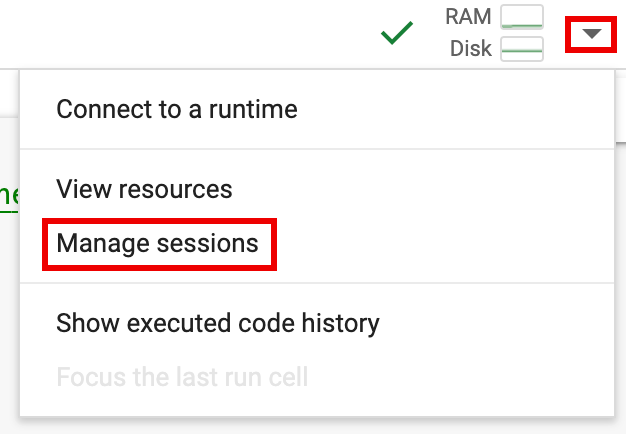
- 활성 세션 대화상자에서 종료 아이콘을 클릭한 다음 종료를 클릭합니다.

- 런타임 선택기를 클릭한 다음 세션 관리를 클릭합니다.
Google Cloud 콘솔에서 노트북 코드를 예약합니다(노트북 가격 책정이 적용됨).
노트북 코드를 일괄 워크로드로 실행합니다(Apache Spark용 서버리스 가격 책정 적용).
로컬 터미널 또는 Cloud Shell의 파일에 노트북 코드를 다운로드합니다.
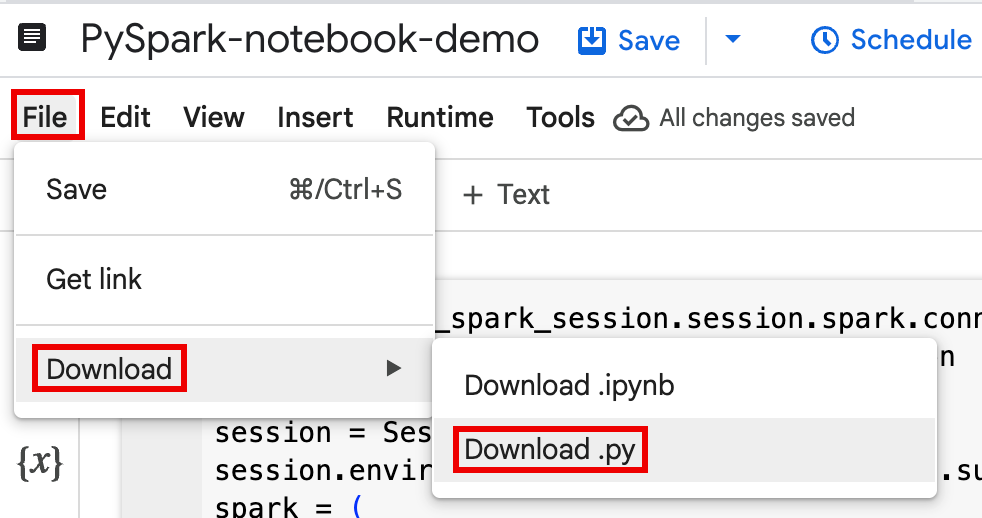
Google Cloud 콘솔의 BigQuery Studio 페이지에서 탐색기 창에 있는 노트북을 엽니다.
메뉴 표시줄을 펼치려면 keyboard_arrow_down 헤더 표시 전환을 클릭합니다.
파일 > 다운로드를 클릭한 다음 Download.py를 클릭합니다.
requirements.txt생성.py파일을 저장한 디렉터리에pipreqs를 설치합니다.pip install pipreqs
pipreqs를 실행하여requirements.txt를 생성합니다.pipreqs filename.py
Google Cloud CLI를 사용하여 로컬
requirements.txt파일을 Cloud Storage의 버킷에 복사합니다.gcloud storage cp requirements.txt gs://BUCKET/
다운로드한
.py파일을 수정하여 Spark 세션 코드를 업데이트합니다.셸 스크립트 명령어를 삭제하거나 주석 처리합니다.
Spark 세션을 구성하는 코드를 삭제한 다음 구성 매개변수를 배치 워크로드 제출 매개변수로 지정합니다. (Spark 배치 워크로드 제출 참고)
예:
코드에서 다음 세션 서브넷 구성 줄을 삭제합니다.
session.environment_config.execution_config.subnetwork_uri = "{subnet_name}"배치 워크로드를 실행할 때
--subnet플래그를 사용하여 서브넷을 지정합니다.gcloud dataproc batches submit pyspark \ --subnet=SUBNET_NAME
간단한 세션 생성 코드 스니펫을 사용합니다.
간소화 전 다운로드된 노트북 코드 샘플
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session
session = Session() spark = DataprocSparkSession \ .builder \ .appName("CustomSparkSession") .dataprocSessionConfig(session) \ .getOrCreate()
간소화된 후의 배치 워크로드 코드입니다.
from pyspark.sql import SparkSession
spark = SparkSession \ .builder \ .getOrCreate()
-
자세한 내용은 Spark 배치 워크로드 제출을 참고하세요.
requirements.txt파일이 포함된 Cloud Storage 버킷을 가리키는 --deps-bucket 플래그를 포함해야 합니다.예:
gcloud dataproc batches submit pyspark FILENAME.py \ --region=REGION \ --deps-bucket=BUCKET \ --version=2.3
참고:
- FILENAME: 다운로드하여 수정한 노트북 코드 파일의 이름입니다.
- REGION: 클러스터가 있는 Compute Engine 리전입니다.
- BUCKET
requirements.txt파일이 포함된 Cloud Storage 버킷의 이름입니다. --version: Spark 런타임 버전 2.3이 선택되어 배치 워크로드를 실행합니다.
코드를 커밋합니다.
- 일괄 워크로드 코드를 테스트한 후 CI/CD 파이프라인의 일부로 GitHub, GitLab, Bitbucket과 같은
git클라이언트를 사용하여.ipynb또는.py파일을 저장소에 커밋할 수 있습니다.
- 일괄 워크로드 코드를 테스트한 후 CI/CD 파이프라인의 일부로 GitHub, GitLab, Bitbucket과 같은
Cloud Composer로 일괄 워크로드를 예약합니다.
- 자세한 내용은 Cloud Composer로 Apache Spark용 서버리스 워크로드 실행을 참고하세요.
- YouTube 동영상 데모: BigQuery와 통합된 Apache Spark의 강력한 기능 활용하기
- Dataproc에서 BigLake metastore 사용
- Apache Spark용 서버리스에서 BigLake metastore 사용
가격 책정
가격 정보는 BigQuery 노트북 런타임 가격 책정을 참고하세요.
BigQuery Studio Python 노트북 열기
BigQuery Studio 노트북에서 Spark 세션 만들기
BigQuery Studio Python 노트북을 사용하여 Spark Connect 대화형 세션을 만들 수 있습니다. 각 BigQuery Studio 노트북에는 연결된 활성 Spark 세션이 하나만 있을 수 있습니다.
다음과 같은 방법으로 BigQuery Studio Python 노트북에서 Spark 세션을 만들 수 있습니다.
단일 세션
새 노트북에서 Spark 세션을 만들려면 다음 단계를 따르세요.
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )다음을 바꿉니다.
템플릿 기반 Spark 세션
노트북 셀에 코드를 입력하고 실행하여 기존 세션 템플릿을 기반으로 Spark 세션을 만들 수 있습니다. 노트북 코드에서 제공하는
session구성 설정은 세션 템플릿에 설정된 동일한 설정을 재정의합니다.빠르게 시작하려면
Query using Spark템플릿을 사용하여 Spark 세션 템플릿 코드로 노트북을 미리 채우세요.from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Configure the session with an existing session template. session_template = "SESSION_TEMPLATE" session.session_template = f"projects/{project}/locations/{location}/sessionTemplates/{session_template}" # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )BigQuery Studio 노트북에서 PySpark 코드 작성 및 실행
노트북에서 Spark 세션을 만든 후 세션을 사용하여 노트북에서 Spark 노트북 코드를 실행합니다.
Spark Connect PySpark API 지원: Spark Connect 노트북 세션은 DataFrame, Functions, Column을 비롯한 대부분의 PySpark API를 지원하지만 SparkContext, RDD 및 기타 PySpark API는 지원하지 않습니다. 자세한 내용은 Spark 3.5에서 지원되는 항목을 참고하세요.
Spark Connect 노트북 직접 쓰기: BigQuery Studio 노트북의 Spark 세션은 직접 데이터 쓰기를 수행하도록 Spark BigQuery 커넥터를 사전 구성합니다. DIRECT 쓰기 메서드는 BigQuery에 직접 데이터를 쓰는 BigQuery Storage Write API를 사용합니다. INDIRECT 쓰기 메서드는 Apache Spark 배치용 서버리스의 기본값으로, 중간 Cloud Storage 버킷에 데이터를 쓴 다음 BigQuery에 데이터를 씁니다(INDIRECT 쓰기에 관한 자세한 내용은 BigQuery에서 데이터를 읽고 쓰기 참고).
Dataproc 전용 API: Dataproc은
addArtifacts메서드를 확장하여PyPI패키지를 Spark 세션에 동적으로 추가하는 작업을 간소화합니다.version-scheme형식(pip install와 유사)으로 목록을 지정할 수 있습니다. 이렇게 하면 Spark Connect 서버가 모든 클러스터 노드에 패키지와 종속 항목을 설치하여 UDF의 작업자가 사용할 수 있도록 합니다.textdistance및random2를 사용하는 UDF가 작업자 노드에서 실행되도록 지정된textdistance버전과 호환되는 최신random2라이브러리를 클러스터에 설치하는 예spark.addArtifacts("textdistance==4.6.1", "random2", pypi=True)노트북 코드 도움말: BigQuery Studio 노트북은 클래스 또는 메서드 이름 위로 포인터를 가져가면 코드 도움말을 제공하고, 코드를 입력할 때 코드 완성 도움말을 제공합니다.
다음 예에서는
DataprocSparkSession을 입력합니다. 이 클래스 이름 위로 포인터를 가져가면 코드 완성 및 문서 도움말이 표시됩니다.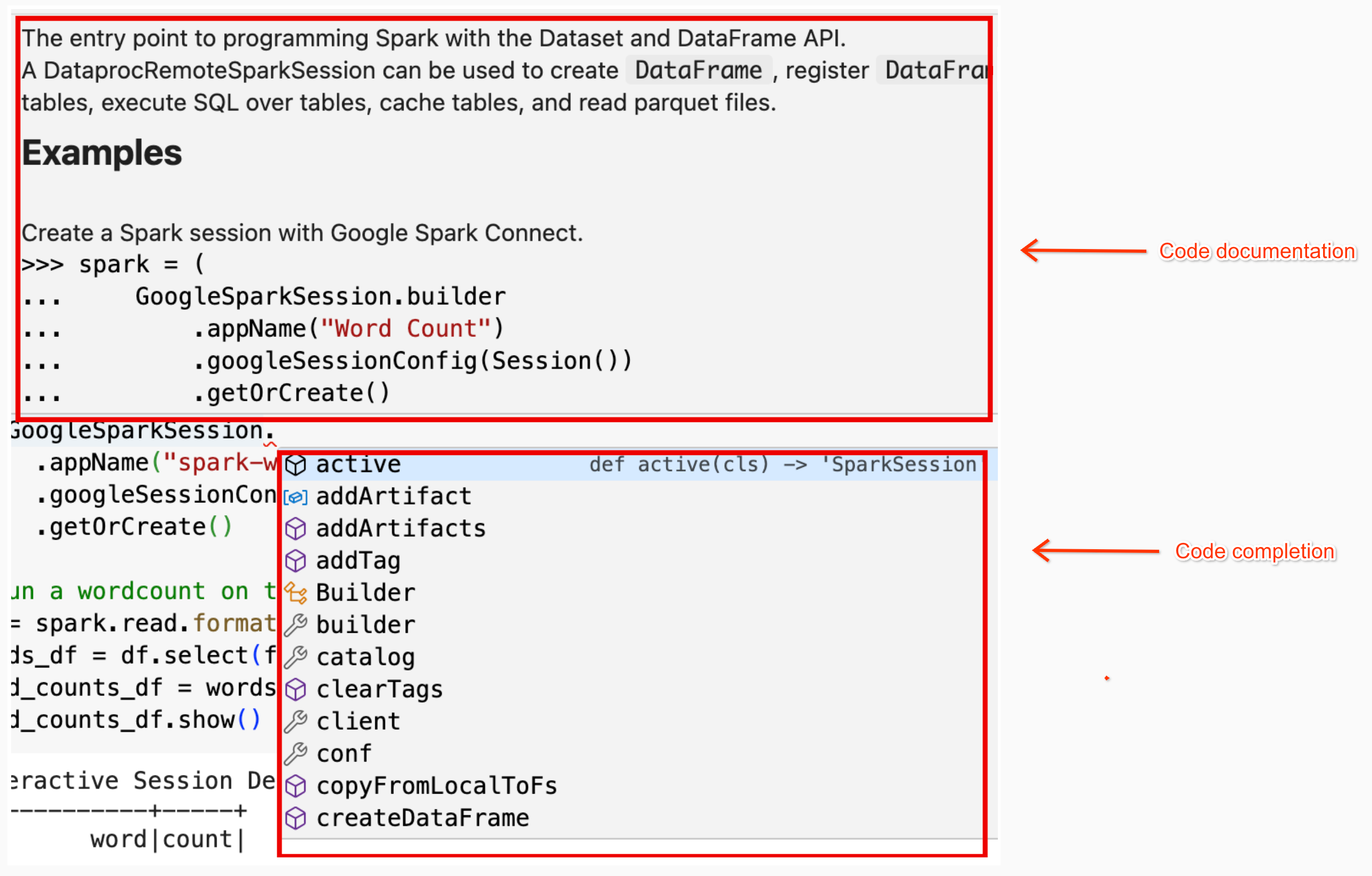
BigQuery Studio 노트북 PySpark 예시
이 섹션에서는 다음 작업을 실행하는 PySpark 코드가 포함된 BigQuery Studio Python 노트북 예를 제공합니다.
Wordcount
다음 Pyspark 예시에서는 Spark 세션을 만든 다음 공개
bigquery-public-data.samples.shakespeare데이터 세트에서 단어 발생 횟수를 계산합니다.# Basic wordcount example from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Run a wordcount on the public Shakespeare dataset. df = spark.read.format("bigquery").option("table", "bigquery-public-data.samples.shakespeare").load() words_df = df.select(f.explode(f.split(f.col("word"), " ")).alias("word")) word_counts_df = words_df.filter(f.col("word") != "").groupBy("word").agg(f.count("*").alias("count")).orderBy("word") word_counts_df.show()다음을 바꿉니다.
출력:
셀 출력에 wordcount 출력의 샘플이 나열됩니다. Google Cloud 콘솔에서 세션 세부정보를 보려면 대화형 세션 세부정보 보기 링크를 클릭합니다. Spark 세션을 모니터링하려면 세션 세부정보 페이지에서 Spark UI 보기를 클릭합니다.

Interactive Session Detail View: LINK +------------+-----+ | word|count| +------------+-----+ | '| 42| | ''All| 1| | ''Among| 1| | ''And| 1| | ''But| 1| | ''Gamut'| 1| | ''How| 1| | ''Lo| 1| | ''Look| 1| | ''My| 1| | ''Now| 1| | ''O| 1| | ''Od's| 1| | ''The| 1| | ''Tis| 4| | ''When| 1| | ''tis| 1| | ''twas| 1| | 'A| 10| |'ARTEMIDORUS| 1| +------------+-----+ only showing top 20 rows
Iceberg 테이블
PySpark 코드를 실행하여 BigLake metastore 메타데이터로 Iceberg 테이블 만들기
다음 예시 코드에서는 BigLake metastore에 저장된 테이블 메타데이터로
sample_iceberg_table을 만든 다음 테이블을 쿼리합니다.from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f # Create the Dataproc Serverless session. session = Session() # Set the session configuration for BigLake Metastore with the Iceberg environment. project_id = "PROJECT" region = "REGION" subnet_name = "SUBNET_NAME" location = "LOCATION" session.environment_config.execution_config.subnetwork_uri = f"{subnet_name}" warehouse_dir = "gs://BUCKET/WAREHOUSE_DIRECTORY" catalog = "CATALOG_NAME" namespace = "NAMESPACE" session.runtime_config.properties[f"spark.sql.catalog.{catalog}"] = "org.apache.iceberg.spark.SparkCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.catalog-impl"] = "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_project"] = f"{project_id}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_location"] = f"{location}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.warehouse"] = f"{warehouse_dir}" # Create the Spark Connect session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Create the namespace in BigQuery. spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;") # Create the Iceberg table. spark.sql("DROP TABLE IF EXISTS `sample_iceberg_table`"); spark.sql("CREATE TABLE sample_iceberg_table (id int, data string) USING ICEBERG;") spark.sql("DESCRIBE sample_iceberg_table;") # Insert table data and query the table. spark.sql("INSERT INTO sample_iceberg_table VALUES (1, \"first row\");") # Alter table, then query and display table data and schema. spark.sql("ALTER TABLE sample_iceberg_table ADD COLUMNS (newDoubleCol double);") spark.sql("DESCRIBE sample_iceberg_table;") df = spark.sql("SELECT * FROM sample_iceberg_table") df.show() df.printSchema()참고:
셀 출력에는 추가된 열이 있는
sample_iceberg_table이 나열되고 Google Cloud 콘솔의 대화형 세션 세부정보 페이지 링크가 표시됩니다. 세션 세부정보 페이지에서 Spark UI 보기를 클릭하여 Spark 세션을 모니터링할 수 있습니다.
Interactive Session Detail View: LINK +---+---------+------------+ | id| data|newDoubleCol| +---+---------+------------+ | 1|first row| NULL| +---+---------+------------+ root |-- id: integer (nullable = true) |-- data: string (nullable = true) |-- newDoubleCol: double (nullable = true)
BigQuery에서 테이블 세부정보 보기
BigQuery에서 Iceberg 테이블 세부정보를 확인하려면 다음 단계를 따르세요.
기타 예
Pandas DataFrame (
df)에서 SparkDataFrame(sdf)을 만듭니다.sdf = spark.createDataFrame(df) sdf.show()Spark
DataFrames에서 집계를 실행합니다.from pyspark.sql import functions as F sdf.groupby("segment").agg( F.mean("total_spend_per_user").alias("avg_order_value"), F.approx_count_distinct("user_id").alias("unique_customers") ).show()Spark-BigQuery 커넥터를 사용하여 BigQuery에서 읽습니다.
spark.conf.set("viewsEnabled","true") spark.conf.set("materializationDataset","my-bigquery-dataset") sdf = spark.read.format('bigquery') \ .load(query)Gemini Code Assist로 Spark 코드 작성
Gemini Code Assist에 노트북에서 PySpark 코드를 생성해 달라고 요청할 수 있습니다. Gemini Code Assist는 관련 BigQuery 및 Dataproc Metastore 테이블과 스키마를 가져오고 사용하여 코드 응답을 생성합니다.
노트북에서 Gemini Code Assist 코드를 생성하려면 다음을 수행합니다.
Gemini Code Assist 코드 생성 도움말
Spark 세션 종료
BigQuery Studio 노트북에서 Spark Connect 세션을 중지하려면 다음 작업 중 하나를 수행하면 됩니다.
BigQuery Studio 노트북 코드 오케스트레이션
다음과 같은 방법으로 BigQuery Studio 노트북 코드를 오케스트레이션할 수 있습니다.
Google Cloud 콘솔에서 노트북 코드 예약
다음과 같은 방법으로 노트북 코드를 예약할 수 있습니다.
노트북 코드를 일괄 워크로드로 실행
다음 단계를 완료하여 BigQuery Studio 노트북 코드를 일괄 워크로드로 실행합니다.
노트북 오류 문제 해결
Spark 코드가 포함된 셀에서 오류가 발생하면 셀 출력에서 대화형 세션 세부정보 보기 링크를 클릭하여 오류를 해결할 수 있습니다 (단어 수 및 Iceberg 테이블 예 참고).
알려진 문제 및 해결 방법
오류: Python 버전
3.10로 생성된 노트북 런타임이 Spark 세션에 연결하려고 하면PYTHON_VERSION_MISMATCH오류가 발생할 수 있습니다.해결 방법: Python 버전
3.11로 런타임을 다시 만듭니다.다음 단계