Abfragejobs in BigQuery enthalten Diagnoseinformationen zum Abfrageplan und zeitlichen Ablauf. Dies ähnelt den Informationen, die von Anweisungen wie EXPLAIN in anderen Datenbank- und Analysesystemen bereitgestellt werden. Diese Informationen können aus den API-Antworten von Methoden wie jobs.get abgerufen werden.
Bei Abfragen mit langer Ausführungszeit aktualisiert BigQuery diese Statistiken regelmäßig. Diese Aktualisierungen erfolgen zwar unabhängig von der Häufigkeit, mit der der Jobstatus abgefragt wird, aber in der Regel nicht häufiger als alle 30 Sekunden. Abfragejobs, die keine Ausführungsressourcen verwenden (zum Beispiel Probelaufanfragen oder Ergebnisse, die mithilfe von im Cache gespeicherten Ergebnissen bereitgestellt werden können), enthalten diese zusätzlichen Diagnoseinformationen nicht. Andere Statistiken können jedoch vorhanden sein.
Hintergrund
Bei der Ausführung eines Abfragejobs in BigQuery wird die deklarative SQL-Anweisung in einen Ausführungsgraphen umgewandelt. Dieser wird in mehrere Abfragephasen aufgeteilt, die sich wiederum aus detaillierten Sätzen von Ausführungsschritten zusammensetzen. BigQuery nutzt eine stark verteilte parallele Architektur zum Ausführen dieser Abfragen. In den Phasen werden dabei die Arbeitseinheiten modelliert, die viele potenzielle Worker parallel ausführen können. Die Phasen kommunizieren über eine schnelle verteilte Shuffle-Architektur miteinander.
Innerhalb des Abfrageplans werden die Begriffe Arbeitseinheiten und Worker verwendet, um Informationen zur Parallelisierung zu liefern. An anderer Stelle in BigQuery kann der Begriff Slot vorkommen, bei dem es sich um eine abstrahierte Darstellung mehrerer Aspekte der Abfrageausführung handelt, einschließlich Rechen-, Speicher- und E/A-Ressourcen. Jobstatistiken der obersten Ebene liefern eine Schätzung der Kosten einzelner Abfragen. Dafür wird die totalSlotMs-Schätzung der Abfrage unter Verwendung dieser abstrahierten Berechnung genutzt.
Eine weitere wichtige Eigenschaft der Architektur für die Abfrageausführung ist, dass sie dynamisch ist. Das bedeutet, dass der Abfrageplan während einer laufenden Abfrage geändert werden kann. Häufig werden während der Ausführung einer Abfrage Phasen eingeführt, um die Datenverteilung auf die Worker der Abfrage zu verbessern. Bei Abfrageplänen, in denen dies der Fall ist, werden diese Phasen normalerweise als Neupartitionierung bezeichnet.
Neben dem Abfrageplan stellen Abfragejobs auch eine Zeitachse für die Ausführung bereit, in der die abgeschlossenen, ausstehenden und aktiven Arbeitseinheiten der Abfrage-Worker aufgeführt sind. Eine Abfrage kann sich gleichzeitig in mehreren Phasen mit aktiven Workern befinden. Die Zeitachse dient dazu, den Gesamtfortschritt der Abfrage anzuzeigen.
Informationen in der Google Cloud Console aufrufen
In der Google Cloud Console können Sie Details zum Abfrageplan für eine abgeschlossene Abfrage anzeigen lassen. Klicken Sie hierzu auf die Schaltfläche Ausführungsdetails (neben der Schaltfläche Ergebnisse).
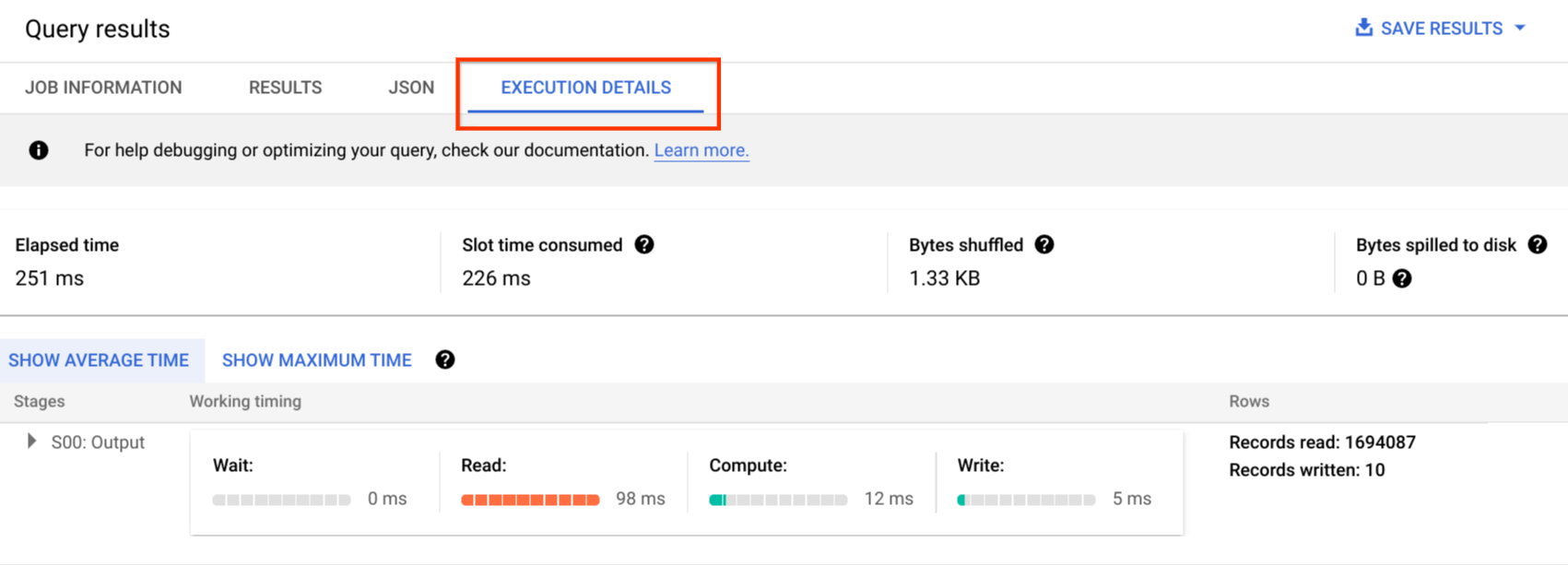
Informationen des Abfrageplans
Innerhalb der API-Antwort werden Abfragepläne als Liste von Abfragephasen dargestellt. Jedes Element in der Liste enthält eine Übersichtsstatistik pro Phase, detaillierte Informationen zu jedem Schritt und zeitliche Klassifizierungen der Phasen. In der Google Cloud -Konsole werden nicht alle Details gerendert, können aber in den API-Antworten enthalten sein.
Phasenübersicht
Die Übersichtsfelder für jede Phase können Folgendes enthalten:
| API-Feld | Beschreibung |
|---|---|
id |
Eindeutige numerische ID für die Phase. |
name |
Einfacher zusammenfassender Name für die Phase. Die steps innerhalb der Phase liefern zusätzliche Details zu den Ausführungsschritten. |
status |
Ausführungsstatus der Phase. Folgende Status sind möglich: PENDING, RUNNING, COMPLETE, FAILED und CANCELLED. |
inputStages |
Eine Liste der IDs, die die Abhängigkeitsgrafik der Phase bilden. Eine JOIN-Phase benötigt zum Beispiel oft zwei abhängige Phasen, die die Daten auf der linken und rechten Seite der JOIN-Beziehung vorbereiten. |
startMs |
Zeitstempel in Millisekunden der Epoche, der angibt, wann der erste Worker in der Phase mit der Ausführung begonnen hat. |
endMs |
Zeitstempel in Millisekunden der Epoche, der angibt, wann der letzte Worker die Ausführung abgeschlossen hat. |
steps |
Detaillierte Liste der Ausführungsschritte innerhalb der Phase. Weitere Informationen finden Sie im nächsten Abschnitt. |
recordsRead |
Eingabegröße der Phase als Anzahl der Datensätze aller Worker der Phase. |
recordsWritten |
Ausgabegröße der Phase als Anzahl der Datensätze aller Worker der Phase. |
parallelInputs |
Anzahl der parallelisierbaren Arbeitseinheiten für die Phase. Je nach Phase und Abfrage kann hiermit die Anzahl der Spaltensegmente innerhalb einer Tabelle oder die Anzahl der Partitionen innerhalb eines Zwischen-Shuffles dargestellt sein. |
completedParallelInputs |
Anzahl der Arbeitseinheiten innerhalb der Phase, die abgeschlossen wurden. Bei einigen Abfragen müssen nicht alle Eingaben in einer Phase abgeschlossen sein, damit die Phase abgeschlossen werden kann. |
shuffleOutputBytes |
Stellt die Gesamtzahl der Byte dar, die in allen Workern in einer Abfragephase geschrieben wurden. |
shuffleOutputBytesSpilled |
Abfragen, die erhebliche Datenmengen zwischen Phasen übertragen, müssen möglicherweise auf eine laufwerkbasierte Übertragung zurückgreifen. Die Statistik zur Menge der übergebenen Byte informiert darüber, wie viele Daten an das Laufwerk übergeben wurden. Hängt von einem Optimierungsalgorithmus ab, sodass er nicht für jede Abfrage deterministisch ist. |
Zeitliche Klassifizierung pro Phase
Die Abfragephasen ermöglichen auch eine zeitliche Klassifizierung, sowohl in absoluter als auch relativer Form. Da jede Ausführungsphase Aktivitäten von einem oder mehreren unabhängigen Workern beinhaltet, werden sowohl die durchschnittliche als auch die längste Zeitdauer angegeben. Diese Werte geben die durchschnittliche Leistung aller Worker einer Phase sowie die Leistung des langsamsten Workers einer bestimmten Klassifizierung wieder. Die durchschnittliche und maximale Zeitdauer wird darüber hinaus absolut und relativ dargestellt. Bei den verhältnisbasierten Statistiken werden die Daten als Anteil der längsten Zeit geliefert, die ein Worker in einem Segment verbracht hat.
In der Google Cloud Console werden die zeitlichen Informationen der Phasen mithilfe relativer Zeitdarstellungen angegeben.
Die zeitlichen Informationen der Phasen werden folgendermaßen dargestellt:
| Relative Zeitdauer | Absolute Zeitdauer | Verhältniszähler |
|---|---|---|
waitRatioAvg |
waitMsAvg |
Zeit, die der durchschnittliche Worker auf die Planung gewartet hat. |
waitRatioMax |
waitMsMax |
Zeit, die der langsamste Worker auf die Planung gewartet hat. |
readRatioAvg |
readMsAvg |
Zeit, die der durchschnittliche Worker mit dem Lesen von Eingabedaten verbracht hat. |
readRatioMax |
readMsMax |
Zeit, die der langsamste Worker mit dem Lesen von Eingabedaten verbracht hat. |
computeRatioAvg |
computeMsAvg |
Zeit, die der durchschnittliche Worker CPU-gebunden verbracht hat. |
computeRatioMax |
computeMsMax |
Zeit, die der langsamste Worker CPU-gebunden verbracht hat. |
writeRatioAvg |
writeMsAvg |
Zeit, die der durchschnittliche Worker mit dem Schreiben von Ausgabedaten verbracht hat. |
writeRatioMax |
writeMsMax |
Zeit, die der langsamste Worker mit dem Schreiben von Ausgabedaten verbracht hat. |
Schrittübersicht
Schritte enthalten die Vorgänge, die jeder Worker in einer Phase ausführt. Sie werden als sortierte Liste von Vorgängen dargestellt. Jeder Schrittvorgang hat eine Kategorie, wobei einige Vorgänge ausführlichere Informationen liefern. Im Abfrageplan können folgende Kategorien von Vorgängen vorhanden sein:
| Schrittkategorie | Beschreibung |
|---|---|
READ |
Ein Lesevorgang von einer oder mehreren Spalten aus einer Eingabetabelle oder einem Zwischen-Shuffle. In den Schrittdetails werden nur die ersten sechzehn Spalten, die gelesen werden, zurückgegeben. |
WRITE |
Ein Schreibvorgang von mindestens einer Spalte in eine Ausgabetabelle oder ein Zwischen-Shuffle. Bei HASH-partitionierten Ausgaben aus einer Phase umfasst dies auch die Spalten, die als Partitionsschlüssel verwendet werden. |
COMPUTE |
Auswertung von Ausdrücken und SQL-Funktionen. |
FILTER |
Wird von den Klauseln WHERE, OMIT IF und HAVING verwendet. |
SORT |
ORDER BY-Vorgang, der die Spaltenschlüssel und die Sortierreihenfolge enthält. |
AGGREGATE |
Implementiert Aggregationen für Klauseln wie GROUP BY oder COUNT. |
LIMIT |
Implementiert die LIMIT-Klausel. |
JOIN |
Implementiert Joins für Klauseln wie JOIN und andere. Enthält den Join-Typ und möglicherweise die Join-Bedingungen. |
ANALYTIC_FUNCTION |
Ein Aufruf einer Fensterfunktion (auch als "Analysefunktion" bezeichnet). |
USER_DEFINED_FUNCTION |
Ein Aufruf einer benutzerdefinierten Funktion. |
Schrittdetails verstehen
BigQuery bietet Schrittdetails, in denen erläutert wird, was in den einzelnen Schritten einer Phase passiert ist. Wenn Sie die Schritte in einer Phase kennen, können Sie die Quelle von Problemen mit der Abfrageleistung ermitteln.
So rufen Sie die Schrittdetails für eine Phase auf:
Klicken Sie im Bereich Abfrageergebnisse auf Ausführungsgrafik.

Klicken Sie auf die gewünschte Phase, um ein Feld mit Phaseninformationen zu öffnen.
Rufen Sie im Bereich mit den Phaseninformationen den Abschnitt Schrittdetails auf.
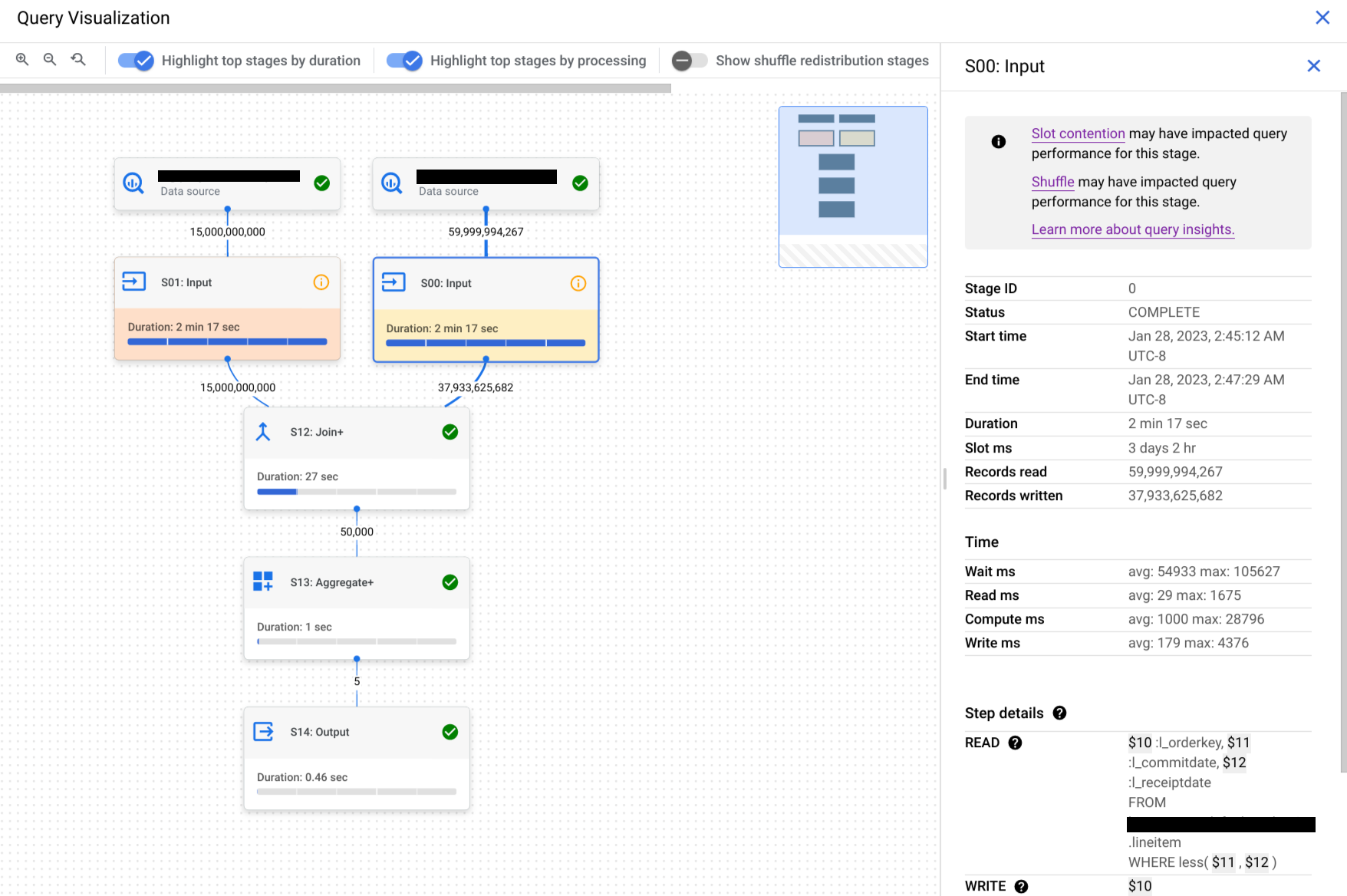
Jeder Schritt besteht aus Teilschritten, die beschreiben, was in diesem Schritt passiert ist. In Teilschritten werden Variablen verwendet, um die Beziehungen zwischen Schritten zu beschreiben. Variablen beginnen mit einem Dollarzeichen, gefolgt von einer eindeutigen Nummer.
Hier ist ein Beispiel für Schrittdetails einer Phase mit Variablen, die zwischen Schritten geteilt werden:
READ $30:l_orderkey, $31:l_quantity FROM lineitem AGGREGATE GROUP BY $100 := $30 $70 := SUM($31) WRITE $100, $70 TO __stage00_output BY HASH($100)
Die Schrittdetails des Beispiels führen Folgendes aus:
In der Phase wurden die Spalten
l_orderkeyundl_quantityaus der Tabellelineitemmit den Variablen$30bzw.$31gelesen.Die Phase wird anhand der Variablen
$30und$31zusammengefasst und die Zusammenfassungen werden in den Variablen$100bzw.$70gespeichert.In der Phase wurden die Ergebnisse der Variablen
$100und$70für das Shuffling geschrieben. In der Phase wurde$100verwendet, um die Ergebnisse der Phase zufällig anzuordnen.
BigQuery kann Schrittdetails kürzen, wenn der Ausführungsgraph der Abfrage so komplex ist, dass die Bereitstellung vollständiger Phasenschrittdetails beim Abrufen von Abfrageinformationen zu Problemen mit der Nutzlastgröße führen würde.
Schritte mit Abfragetext verstehen
Wenn Sie während der Vorschau Unterstützung benötigen, senden Sie eine E-Mail an bq-query-inspector-feedback@google.com.
Es kann schwierig sein, die Beziehung zwischen den Schritten der Phase und der Anfrage zu verstehen. Im Abschnitt Abfragetext sehen Sie, wie sich einige Schritte auf den ursprünglichen Abfragetext beziehen.
Im Abschnitt Abfragetext werden verschiedene Teile des ursprünglichen Abfragetexts hervorgehoben. Außerdem werden die Schritte angezeigt, die dem Abfragetext unmittelbar vor dem hervorgehobenen ursprünglichen Abfragetext zugeordnet sind. Nur die Schritte, die direkt über einem markierten Teil des ursprünglichen Abfragetexts stehen, beziehen sich auf den markierten Abfragetext.

Der Screenshot zeigt folgende Zuordnungen:
Der Schritt
AGGREGATE: GROUP BY $100 := $30wird auf den Abfragetextselect l_orderkeyzurückgeführt.Der Schritt
READ: FROM lineitemwird dem Abfragetextselect ... from lineitemzugeordnet.Der Schritt
AGGREGATE: $70 := SUM($31)wird auf den Abfragetextsum(l_quantity)zurückgeführt.
Nicht alle Schritte lassen sich auf den Abfragetext zurückführen.
Wenn in einer Abfrage Ansichten verwendet werden und die Schritte der Phase Zuordnungen zum Abfragetext einer Ansicht haben, werden im Bereich Abfragetext der Ansichtsname und der Abfragetext der Ansicht mit den zugehörigen Zuordnungen angezeigt. Wenn die Ansicht jedoch gelöscht wird oder Sie die bigquery.tables.get-IAM-Berechtigung für die Ansicht verlieren, werden im Bereich Abfragetext die Zuordnungen der Stufen für die Ansicht nicht angezeigt.
Schritte interpretieren und optimieren
In den folgenden Abschnitten wird erläutert, wie Sie die Schritte in einem Abfrageplan interpretieren und Ihre Abfragen optimieren können.
Schritt READ
Der Schritt READ bedeutet, dass eine Phase auf Daten zugreift, um sie zu verarbeiten. Daten können direkt aus den in einer Abfrage referenzierten Tabellen oder aus dem Shuffle-Speicher gelesen werden.
Wenn Daten aus einer vorherigen Phase gelesen werden, liest BigQuery Daten aus dem Shuffle-Speicher. Die Menge der gescannten Daten wirkt sich auf die Kosten aus, wenn Sie On-Demand-Slots verwenden, und auf die Leistung, wenn Sie Reservierungen verwenden.
Potenzielle Leistungsprobleme
- Umfangreicher Scan einer nicht partitionierten Tabelle:Wenn für die Abfrage nur ein kleiner Teil der Daten benötigt wird, kann dies darauf hindeuten, dass ein Tabellenscan ineffizient ist. Partitionierung kann eine gute Optimierungsstrategie sein.
- Scan einer großen Tabelle mit einem kleinen Filterverhältnis:Dies deutet darauf hin, dass der Filter die gescannten Daten nicht effektiv reduziert. Überprüfen Sie gegebenenfalls die Filterbedingungen.
- Auf Festplatte ausgelagerte Shuffle-Bytes:Dies deutet darauf hin, dass die Daten nicht effektiv mit Optimierungstechniken wie Clustering gespeichert werden, mit denen ähnliche Daten in Clustern zusammengefasst werden könnten.
Optimieren
- Gezieltes Filtern:Verwenden Sie
WHERE-Klauseln strategisch, um irrelevante Daten so früh wie möglich in der Abfrage herauszufiltern. Dadurch wird die Datenmenge reduziert, die von der Abfrage verarbeitet werden muss. - Partitionierung und Clustering:BigQuery verwendet Tabellenpartitionierung und Clustering, um bestimmte Datensegmente effizient zu finden.
Sorgen Sie dafür, dass Ihre Tabellen basierend auf Ihren typischen Abfragemustern partitioniert und geclustert werden, um die während der
READ-Schritte gescannten Daten zu minimieren. - Relevante Spalten auswählen:Vermeiden Sie
SELECT *-Anweisungen. Wählen Sie stattdessen bestimmte Spalten aus oder verwenden SieSELECT * EXCEPT, um das Lesen unnötiger Daten zu vermeiden. - Materialisierte Ansichten:Mit materialisierten Ansichten können häufig verwendete Aggregationen vorab berechnet und gespeichert werden. Dadurch muss bei Abfragen, in denen diese Ansichten verwendet werden, möglicherweise nicht auf die Basistabellen zugegriffen werden.
READ
Schritt COMPUTE
Im Schritt COMPUTE führt BigQuery die folgenden Aktionen für Ihre Daten aus:
- Wertet Ausdrücke in den Klauseln
SELECT,WHERE,HAVINGund anderen Klauseln der Abfrage aus, einschließlich Berechnungen, Vergleichen und logischen Operationen. - Führt integrierte SQL-Funktionen und benutzerdefinierte Funktionen aus.
- Filtert Datenzeilen basierend auf Bedingungen in der Abfrage.
Optimieren
Der Abfrageplan kann Engpässe im Schritt COMPUTE aufdecken. Suchen Sie nach Phasen mit umfangreichen Berechnungen oder einer hohen Anzahl verarbeiteter Zeilen.
COMPUTE-Schritt mit Datenvolumen in Beziehung setzen:Wenn in einer Phase erhebliche Berechnungen durchgeführt werden und ein großes Datenvolumen verarbeitet wird, ist sie möglicherweise ein guter Kandidat für die Optimierung.- Verzerrte Daten:Wenn das Berechnungsmaximum für Phasen deutlich höher ist als der Berechnungsdurchschnitt, bedeutet das, dass in der Phase ein unverhältnismäßig hoher Zeitaufwand für die Verarbeitung einiger Datensegmente angefallen ist. Sehen Sie sich die Datenverteilung an, um festzustellen, ob es Datenabweichungen gibt.
- Datentypen berücksichtigen:Verwenden Sie für Ihre Spalten die richtigen Datentypen. Wenn Sie beispielsweise Ganzzahlen, Datums-/Uhrzeitangaben und Zeitstempel anstelle von Strings verwenden, kann sich die Leistung verbessern.
Schritt WRITE
WRITE Schritte werden für Zwischendaten und die endgültige Ausgabe ausgeführt.
- In den Shuffle-Speicher schreiben:Bei einer mehrstufigen Abfrage werden im Schritt
WRITEdie verarbeiteten Daten häufig zur weiteren Verarbeitung an eine andere Phase gesendet. Das ist typisch für den Shuffle-Speicher, in dem Daten aus mehreren Quellen kombiniert oder aggregiert werden. Die in dieser Phase geschriebenen Daten sind in der Regel ein Zwischenergebnis und nicht die endgültige Ausgabe. - Endgültige Ausgabe:Das Abfrageergebnis wird entweder in die Zieltabelle oder in eine temporäre Tabelle geschrieben.
Hash-Partitionierung
Wenn in einer Phase des Abfrageplans Daten in eine hashpartitionierte Ausgabe geschrieben werden, schreibt BigQuery die in der Ausgabe enthaltenen Spalten und die als Partitionierungsschlüssel ausgewählte Spalte.
Optimieren
Der Schritt WRITE selbst lässt sich zwar nicht direkt optimieren, aber wenn Sie seine Rolle verstehen, können Sie potenzielle Engpässe in früheren Phasen erkennen:
- Geschriebene Daten minimieren:Optimieren Sie die vorherigen Phasen durch Filtern und Aggregieren, um die in diesem Schritt geschriebene Datenmenge zu reduzieren.
Partitionierung:Das Schreiben profitiert stark von der Tabellenpartitionierung. Wenn die Daten, die Sie schreiben, auf bestimmte Partitionen beschränkt sind, kann BigQuery schneller schreiben.
Wenn die DML-Anweisung eine
WHERE-Klausel mit einer statischen Bedingung für eine Tabellenpartitionsspalte enthält, ändert BigQuery nur die relevanten Tabellenpartitionen.Kompromisse bei der Denormalisierung:Die Denormalisierung kann manchmal zu kleineren Ergebnismengen im Zwischenschritt
WRITEführen. Allerdings gibt es auch Nachteile wie eine erhöhte Speichernutzung und Probleme mit der Datenkonsistenz.
Schritt JOIN
Im Schritt JOIN werden Daten aus zwei Datenquellen in BigQuery zusammengeführt.
Joins können Join-Bedingungen enthalten. Joins sind ressourcenintensiv. Beim Verknüpfen großer Datenmengen in BigQuery werden die Join-Schlüssel unabhängig voneinander sortiert, um im selben Slot zu landen. So wird der Join lokal in jedem Slot ausgeführt.
Der Abfrageplan für den Schritt JOIN enthält in der Regel die folgenden Details:
- Join-Muster:Gibt den verwendeten Join-Typ an. Jeder Typ definiert, wie viele Zeilen aus den verknüpften Tabellen in das Ergebnisset aufgenommen werden.
- Join-Spalten:Das sind die Spalten, die zum Abgleichen von Zeilen zwischen den Datenquellen verwendet werden. Die Auswahl der Spalten ist entscheidend für die Join-Leistung.
Join-Muster
- Broadcast Join:Wenn eine Tabelle, in der Regel die kleinere, auf einem einzelnen Worker-Knoten oder ‑Slot in den Arbeitsspeicher passt, kann BigQuery sie an alle anderen Knoten übertragen, um den Join effizient auszuführen. Suchen Sie in den Schrittdetails nach
JOIN EACH WITH ALL. - Hash-Join:Wenn Tabellen groß sind oder ein Broadcast-Join nicht geeignet ist, kann ein Hash-Join verwendet werden. BigQuery verwendet Hash- und Shuffle-Vorgänge, um die linken und rechten Tabellen so zu mischen, dass die übereinstimmenden Schlüssel im selben Slot landen, um einen lokalen Join durchzuführen. Hash-Joins sind ein aufwendiger Vorgang, da die Daten verschoben werden müssen. Sie ermöglichen jedoch einen effizienten Abgleich von Zeilen über Hashes hinweg. Suchen Sie in den Schrittdetails nach
JOIN EACH WITH EACH. - Self Join:Ein SQL-Antipattern, bei dem eine Tabelle mit sich selbst verknüpft wird.
- Cross Join:Ein SQL-Antipattern, das zu erheblichen Leistungsproblemen führen kann, da es größere Ausgabedaten als die Eingaben generiert.
- Verzerrter Join:Die Datenverteilung für den Join-Schlüssel in einer Tabelle ist sehr verzerrt und kann zu Leistungsproblemen führen. Suchen Sie nach Fällen, in denen die maximale Rechenzeit im Abfrageplan deutlich höher ist als die durchschnittliche Rechenzeit. Weitere Informationen finden Sie unter Join mit hoher Kardinalität und Partitionierung.
Debugging
- Großes Datenvolumen:Wenn im Abfrageplan eine erhebliche Menge an Daten angezeigt wird, die während des
JOIN-Schritts verarbeitet werden, untersuchen Sie die Join-Bedingung und die Join-Schlüssel. Sie können die Daten filtern oder selektivere Join-Schlüssel verwenden. - Verzerrte Datenverteilung:Analysieren Sie die Datenverteilung von Join-Schlüsseln. Wenn eine Tabelle sehr verzerrt ist, sollten Sie Strategien wie das Aufteilen der Abfrage oder das Vorabfiltern in Betracht ziehen.
- Joins mit hoher Kardinalität:Joins, die deutlich mehr Zeilen als die Anzahl der linken und rechten Eingabezeilen erzeugen, können die Abfrageleistung drastisch verringern. Vermeiden Sie Joins, die eine sehr große Anzahl von Zeilen erzeugen.
- Falsche Reihenfolge der Tabelle:Achten Sie darauf, dass Sie den richtigen Join-Typ ausgewählt haben, z. B.
INNERoderLEFT, und die Tabellen entsprechend den Anforderungen Ihrer Abfrage von der größten zur kleinsten sortiert haben.
Optimieren
- Selektive Join-Schlüssel:Verwenden Sie für Join-Schlüssel nach Möglichkeit
INT64anstelle vonSTRING.STRING-Vergleiche sind langsamer alsINT64-Vergleiche, da bei ihnen jedes Zeichen in einem String verglichen wird. Für Ganzzahlen ist nur ein Vergleich erforderlich. - Vor dem Verknüpfen filtern:Wenden Sie
WHERE-Klauselfilter auf einzelne Tabellen an, bevor Sie sie verknüpfen. Dadurch wird die Datenmenge reduziert, die für den Join-Vorgang erforderlich ist. - Funktionen für Join-Spalten vermeiden:Rufen Sie keine Funktionen für Join-Spalten auf. Stattdessen sollten Sie Ihre Tabellendaten während der Aufnahme oder nach der Aufnahme mit ELT-SQL-Pipelines standardisieren. Bei diesem Ansatz müssen Join-Spalten nicht dynamisch geändert werden. Das ermöglicht effizientere Joins, ohne die Datenintegrität zu beeinträchtigen.
- Self Joins vermeiden:Self Joins werden häufig verwendet, um zeilenabhängige Beziehungen zu berechnen. Self-Joins können jedoch die Anzahl der Ausgabezeilen potenziell vervierfachen, was zu Leistungsproblemen führen kann. Verwenden Sie statt Self Joins Fensterfunktionen (analytische Funktionen).
- Große Tabellen zuerst:Das Tool zur Optimierung von SQL-Abfrage kann zwar festlegen, welche Tabelle auf welcher Seite der Verknüpfung stehen sollte. Es ist aber dennoch empfehlenswert, die verknüpften Tabellen entsprechend zu sortieren. Am sinnvollsten ist es, die größte Tabelle an die erste Stelle zu setzen, gefolgt von der kleinsten, und dann in absteigender Reihenfolge fortzufahren.
- Denormalisierung:In einigen Fällen können Joins vollständig vermieden werden, indem Tabellen strategisch denormalisiert werden (redundante Daten hinzufügen). Dieser Ansatz hat jedoch Nachteile in Bezug auf Speicherplatz und Datenkonsistenz.
- Partitionierung und Clustering:Wenn Sie Tabellen anhand von Join-Schlüsseln partitionieren und zusammengehörige Daten gruppieren, können Sie Joins erheblich beschleunigen, da BigQuery dann auf relevante Datenpartitionen zugreifen kann.
- Verzerrte Joins optimieren:Um Leistungsprobleme aufgrund von verzerrten Joins zu vermeiden, filtern Sie Daten aus der Tabelle so früh wie möglich vorab oder teilen Sie die Abfrage in zwei oder mehr Abfragen auf.
Schritt AGGREGATE
Im Schritt AGGREGATE werden Daten in BigQuery zusammengefasst und gruppiert.
Debugging
- Phasendetails:Sehen Sie sich die Anzahl der Eingabe- und Ausgaberow für die Aggregation sowie die Shuffle-Größe an, um festzustellen, wie viel Datenreduzierung durch den Aggregationsschritt erreicht wurde und ob Daten-Shuffling beteiligt war.
- Shuffle-Größe:Eine große Shuffle-Größe kann darauf hindeuten, dass während der Aggregation eine erhebliche Menge an Daten zwischen Worker-Knoten verschoben wurde.
- Datenverteilung prüfen:Achten Sie darauf, dass die Daten gleichmäßig auf die Partitionen verteilt sind. Eine ungleichmäßige Datenverteilung kann zu unausgeglichenen Arbeitslasten im Aggregationsschritt führen.
- Aggregationen überprüfen:Analysieren Sie die Aggregationsklauseln, um zu bestätigen, dass sie notwendig und effizient sind.
Optimieren
- Clustering:Clustern Sie Ihre Tabellen nach Spalten, die häufig in
GROUP BY-,COUNT- oder anderen Aggregationsklauseln verwendet werden. - Partitionierung:Wählen Sie eine Partitionierungsstrategie aus, die zu Ihren Abfragemustern passt. Erwägen Sie, nach Aufnahmezeit partitionierte Tabellen zu verwenden, um die Menge der während der Aggregation gescannten Daten zu reduzieren.
- Früher aggregieren:Führen Sie Aggregationen nach Möglichkeit früher in der Abfragepipeline durch. Dadurch kann die Datenmenge reduziert werden, die während der Aggregation verarbeitet werden muss.
- Optimierung des Shuffling:Wenn das Shuffling ein Engpass ist, sollten Sie nach Möglichkeiten suchen, es zu minimieren. Sie können beispielsweise Tabellen denormalisieren oder Clustering verwenden, um relevante Daten zusammenzufassen.
Sonderfälle
- DISTINCT-Aggregate:Abfragen mit
DISTINCT-Aggregaten können rechenintensiv sein, insbesondere bei großen Datasets. Erwägen Sie Alternativen wieAPPROX_COUNT_DISTINCTfür ungefähre Ergebnisse. - Große Anzahl von Gruppen:Wenn bei der Abfrage eine große Anzahl von Gruppen generiert wird, kann dies viel Arbeitsspeicher beanspruchen. In solchen Fällen sollten Sie die Anzahl der Gruppen begrenzen oder eine andere Aggregationsstrategie verwenden.
Schritt REPARTITION
Sowohl REPARTITION als auch COALESCE sind Optimierungstechniken, die BigQuery direkt auf die gemischten Daten in der Abfrage anwendet.
REPARTITION:Mit diesem Vorgang soll die Datenverteilung auf die Worker-Knoten ausgeglichen werden. Angenommen, nach dem Shuffling erhält ein Worker-Knoten eine unverhältnismäßig große Datenmenge. Im SchrittREPARTITIONwerden die Daten gleichmäßiger verteilt, sodass kein einzelner Worker zum Engpass wird. Das ist besonders wichtig für rechenintensive Vorgänge wie Joins.COALESCE:Dieser Schritt erfolgt, wenn nach dem Shuffling viele kleine Daten-Buckets vorhanden sind. Im SchrittCOALESCEwerden diese Buckets in größere Buckets zusammengefasst, wodurch der Aufwand für die Verwaltung zahlreicher kleiner Datenmengen reduziert wird. Das kann besonders hilfreich sein, wenn Sie mit sehr kleinen Zwischenergebnismengen arbeiten.
Wenn Sie in Ihrem Abfrageplan die Schritte REPARTITION oder COALESCE sehen, bedeutet das nicht unbedingt, dass ein Problem mit Ihrer Abfrage vorliegt. Das ist oft ein Zeichen dafür, dass BigQuery die Datenverteilung proaktiv optimiert, um die Leistung zu verbessern. Wenn diese Vorgänge jedoch wiederholt auftreten, kann das darauf hindeuten, dass Ihre Daten von Natur aus verzerrt sind oder dass durch Ihre Abfrage zu viele Daten verschoben werden.
Optimieren
So können Sie die Anzahl der REPARTITION-Schritte reduzieren:
- Datenverteilung:Achten Sie darauf, dass Ihre Tabellen effektiv partitioniert und gruppiert sind. Bei gut verteilten Daten ist die Wahrscheinlichkeit, dass nach dem Shuffling erhebliche Ungleichgewichte auftreten, geringer.
- Abfragestruktur:Analysieren Sie die Abfrage auf potenzielle Quellen für Datenabweichungen. Gibt es beispielsweise sehr selektive Filter oder Joins, die dazu führen, dass auf einem einzelnen Worker nur eine kleine Teilmenge der Daten verarbeitet wird?
- Join-Strategien: Testen Sie verschiedene Join-Strategien, um zu sehen, ob sie zu einer ausgewogeneren Datenverteilung führen.
So können Sie die Anzahl der COALESCE-Schritte reduzieren:
- Aggregationsstrategien:Führen Sie Aggregationen möglichst früh in der Abfragepipeline aus. So kann die Anzahl kleiner Zwischenergebnismengen reduziert werden, die möglicherweise
COALESCE-Schritte verursachen. - Datenvolumen:Wenn Sie mit sehr kleinen Datasets arbeiten, ist
COALESCEmöglicherweise kein großes Problem.
Überoptimieren Sie nicht. Durch eine vorzeitige Optimierung können Ihre Abfragen komplexer werden, ohne dass sich dadurch wesentliche Vorteile ergeben.
Erläuterung zu föderierten Abfragen
Mit föderierten Abfragen können Sie eine Abfrageanweisung mit der EXTERNAL_QUERY-Funktion an eine externe Datenquelle senden.
Für föderierte Abfragen wird die Optimierungstechnik SQL-Pushdowns verwendet. Im Abfrageplan werden alle Vorgänge angezeigt, die an die externe Datenquelle übertragen wurden. Wenn Sie beispielsweise die folgende Abfrage ausführen:
SELECT id, name
FROM EXTERNAL_QUERY("<connection>", "SELECT * FROM company")
WHERE country_code IN ('ee', 'hu') AND name like '%TV%'
Der Abfrageplan enthält die folgenden Phasenschritte:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, country_code
FROM (
/*native_query*/
SELECT * FROM company
)
WHERE in(country_code, 'ee', 'hu')
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
In diesem Plan steht table_for_external_query_$_0(...) für die Funktion EXTERNAL_QUERY. In den Klammern sehen Sie die Abfrage, die von der externen Datenquelle ausgeführt wird. Daraus lässt sich Folgendes ableiten:
- Eine externe Datenquelle gibt nur drei ausgewählte Spalten zurück.
- Eine externe Datenquelle gibt nur Zeilen zurück, für die
country_codeentweder'ee'oder'hu'ist. - Der Operator
LIKEwird nicht per Push übertragen und wird aber von BigQuery ausgewertet.
Wenn keine Push-downs vorhanden sind, zeigt der Abfrageplan die folgenden Phasenschritte an:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, description, country_code, primary_address, secondary address
FROM (
/*native_query*/
SELECT * FROM company
)
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Dieses Mal gibt eine externe Datenquelle alle Spalten und alle Zeilen aus der Tabelle company zurück und BigQuery führt die Filterung durch.
Metadaten der Zeitachse
Die Abfragezeitachse zeigt den Fortschritt zu bestimmten Zeitpunkten und bietet aktuelle Ansichten des gesamten Abfragefortschritts. Die Zeitachse wird als eine Reihe von Stichproben dargestellt, die folgende Details enthalten:
| Feld | Beschreibung |
|---|---|
elapsedMs |
Seit Beginn der Abfrageausführung verstrichene Millisekunden. |
totalSlotMs |
Eine kumulative Darstellung der von der Abfrage verwendeten Slot-Millisekunden. |
pendingUnits |
Gesamtzahl der geplanten Arbeitseinheiten, die auf Ausführung warten. |
activeUnits |
Gesamtzahl der aktiven Arbeitseinheiten, die derzeit von den Workern verarbeitet werden. |
completedUnits |
Gesamtzahl der Arbeitseinheiten, die während der Ausführung dieser Abfrage abgeschlossen wurden. |
Beispielabfrage
Die folgende Abfrage zählt die Anzahl der Zeilen im öffentlichen Shakespeare-Dataset und hat eine zweite bedingte Zählung, die Ergebnisse auf Zeilen beschränkt, die auf „Hamlet“ verweisen:
SELECT
COUNT(1) as rowcount,
COUNTIF(corpus = 'hamlet') as rowcount_hamlet
FROM `publicdata.samples.shakespeare`
Klicken Sie auf Ausführungsdetails, um den Abfrageplan anzuzeigen:
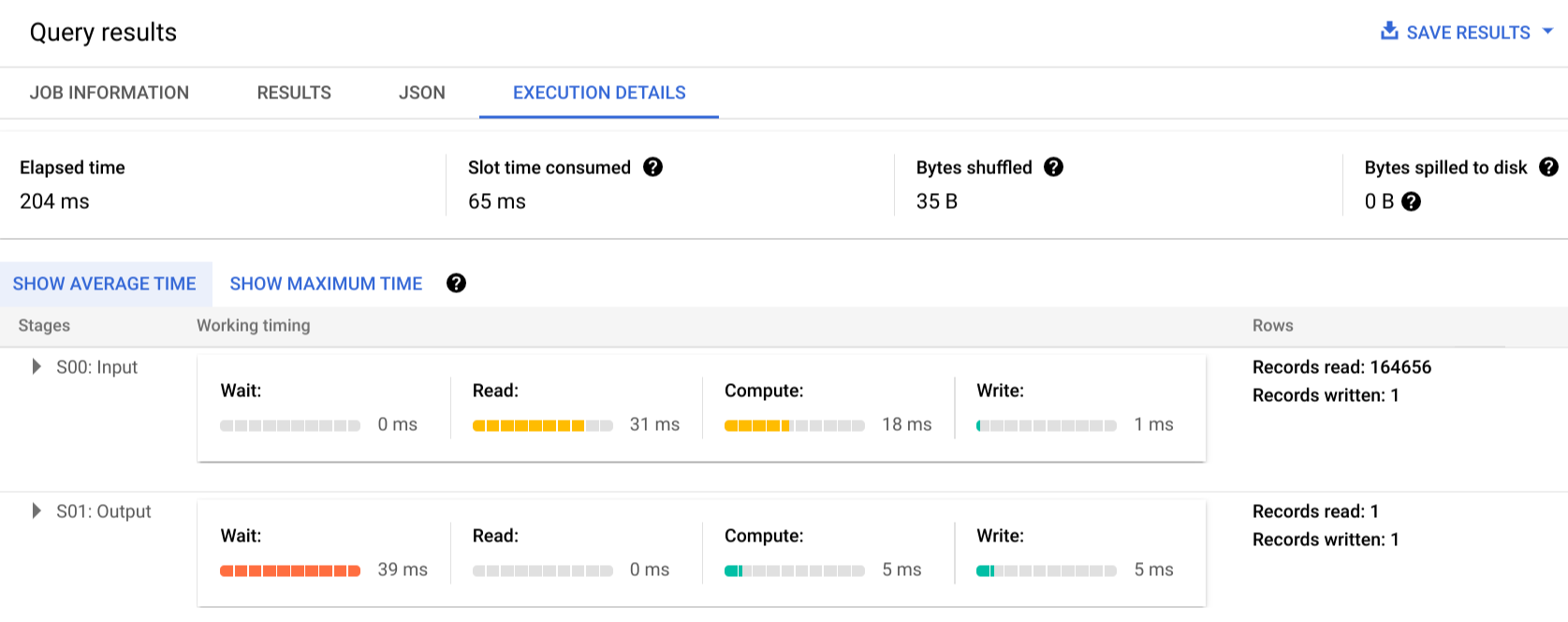
Die Farbindikatoren zeigen die relative Zeitdauer für alle Schritte in allen Phasen an.
Um mehr über die Schritte der Ausführungsphasen zu erfahren, klicken Sie auf das , woraufhin die Details für die Phase maximiert werden:
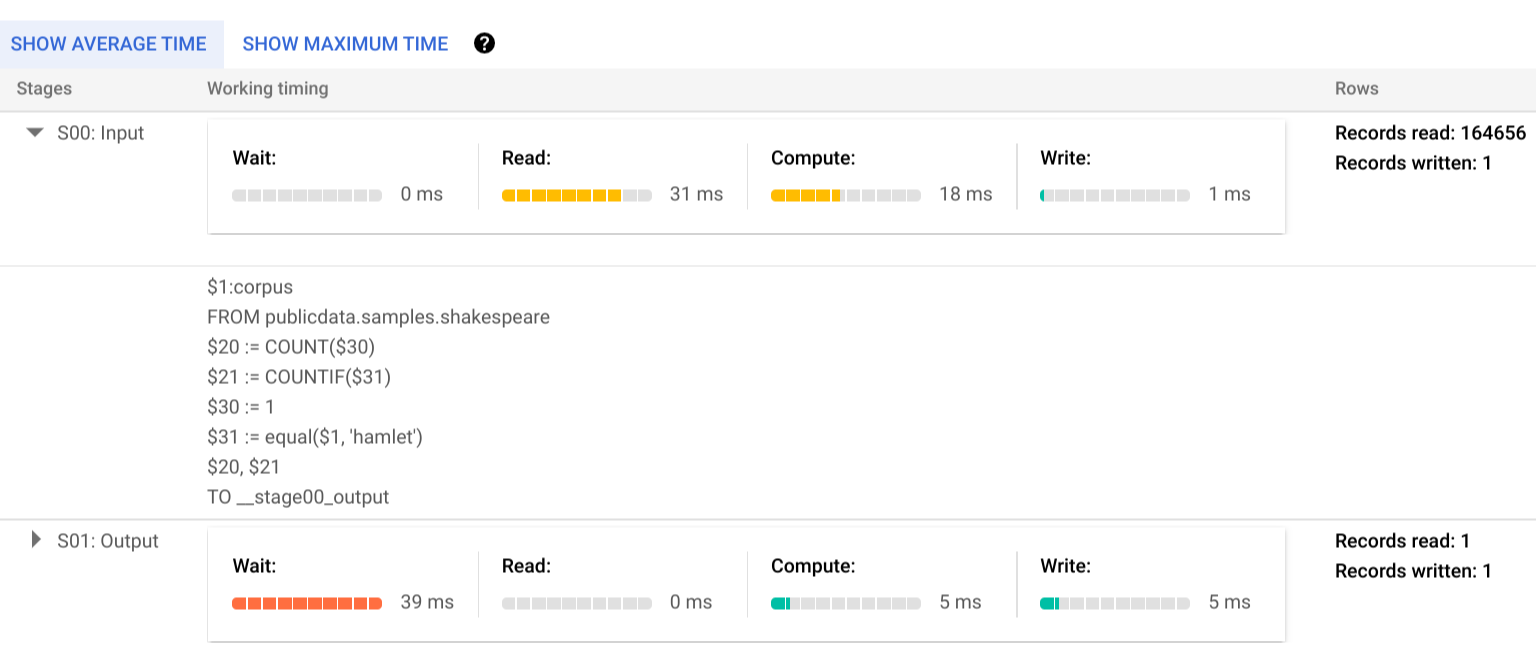
In diesem Beispiel war die längste Zeit in einem Segment die Zeit, die der einzelne Worker in Phase 01 auf den Abschluss von Phase 00 gewartet hat. Dies liegt daran, dass Phase 01 von der Eingabe von Phase 00 abhängig war und erst gestartet werden konnte, nachdem die Ausgabedaten in der ersten Phase in den Zwischen-Shuffle geschrieben wurden.
Fehlerberichte
Abfragejobs können während der Ausführung fehlschlagen. Da die Informationen des Abfrageplans regelmäßig aktualisiert werden, können Sie sehen, an welcher Stelle innerhalb der Ausführungsgrafik der Fehler aufgetreten ist. In der Google Cloud Console wird durch ein Häkchen bzw. ein Ausrufezeichen neben den Phasennamen angezeigt, ob eine Phase erfolgreich war oder fehlgeschlagen ist.
Weitere Informationen zum Interpretieren und Beheben von Fehlern finden Sie in der Anleitung zur Fehlerbehebung.
API-Beispieldarstellung
Die Informationen des Abfrageplans sind in der Jobantwort enthalten und können durch Aufrufen von jobs.get abgerufen werden.
Der folgende Code ist ein Auszug aus einer JSON-Antwort für einen Job, der die Beispielabfrage zu Hamlet liefert und sowohl Informationen über den Abfrageplan als auch die Zeitachse anzeigt.
"statistics": {
"creationTime": "1576544129234",
"startTime": "1576544129348",
"endTime": "1576544129681",
"totalBytesProcessed": "2464625",
"query": {
"queryPlan": [
{
"name": "S00: Input",
"id": "0",
"startMs": "1576544129436",
"endMs": "1576544129465",
"waitRatioAvg": 0.04,
"waitMsAvg": "1",
"waitRatioMax": 0.04,
"waitMsMax": "1",
"readRatioAvg": 0.32,
"readMsAvg": "8",
"readRatioMax": 0.32,
"readMsMax": "8",
"computeRatioAvg": 1,
"computeMsAvg": "25",
"computeRatioMax": 1,
"computeMsMax": "25",
"writeRatioAvg": 0.08,
"writeMsAvg": "2",
"writeRatioMax": 0.08,
"writeMsMax": "2",
"shuffleOutputBytes": "18",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "164656",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$1:corpus",
"FROM publicdata.samples.shakespeare"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$20 := COUNT($30)",
"$21 := COUNTIF($31)"
]
},
{
"kind": "COMPUTE",
"substeps": [
"$30 := 1",
"$31 := equal($1, 'hamlet')"
]
},
{
"kind": "WRITE",
"substeps": [
"$20, $21",
"TO __stage00_output"
]
}
]
},
{
"name": "S01: Output",
"id": "1",
"startMs": "1576544129465",
"endMs": "1576544129480",
"inputStages": [
"0"
],
"waitRatioAvg": 0.44,
"waitMsAvg": "11",
"waitRatioMax": 0.44,
"waitMsMax": "11",
"readRatioAvg": 0,
"readMsAvg": "0",
"readRatioMax": 0,
"readMsMax": "0",
"computeRatioAvg": 0.2,
"computeMsAvg": "5",
"computeRatioMax": 0.2,
"computeMsMax": "5",
"writeRatioAvg": 0.16,
"writeMsAvg": "4",
"writeRatioMax": 0.16,
"writeMsMax": "4",
"shuffleOutputBytes": "17",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "1",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$20, $21",
"FROM __stage00_output"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$10 := SUM_OF_COUNTS($20)",
"$11 := SUM_OF_COUNTS($21)"
]
},
{
"kind": "WRITE",
"substeps": [
"$10, $11",
"TO __stage01_output"
]
}
]
}
],
"estimatedBytesProcessed": "2464625",
"timeline": [
{
"elapsedMs": "304",
"totalSlotMs": "50",
"pendingUnits": "0",
"completedUnits": "2"
}
],
"totalPartitionsProcessed": "0",
"totalBytesProcessed": "2464625",
"totalBytesBilled": "10485760",
"billingTier": 1,
"totalSlotMs": "50",
"cacheHit": false,
"referencedTables": [
{
"projectId": "publicdata",
"datasetId": "samples",
"tableId": "shakespeare"
}
],
"statementType": "SELECT"
},
"totalSlotMs": "50"
},
Ausführungsinformationen verwenden
BigQuery-Abfragepläne liefern Informationen darüber, wie der Dienst Abfragen ausführt. Da es sich um einen verwalteten Dienst handelt, sind die Möglichkeiten, ob einige Details direkt umsetzbar sind, jedoch begrenzt. Viele Optimierungen erfolgen automatisch durch Nutzung des Dienstes. Dies kann sich von anderen Umgebungen unterscheiden, in denen Optimierung, Bereitstellung und Monitoring spezialisiertes, fachkundiges Personal erfordern.
Informationen zu konkreten Verfahren, die die Ausführung und Leistung von Abfragen verbessern können, finden Sie in der Dokumentation zu Best Practices. Anhand des Abfrageplans und der Zeitachsenstatistiken können Sie nachvollziehen, ob die Ressourcenauslastung in bestimmten Phasen besonders hoch ist. Eine JOIN-Phase, in der weit mehr Ausgabezeilen als Eingabezeilen generiert werden, könnte zum Beispiel darauf hindeuten, dass früher in der Abfrage gefiltert werden sollte.
Darüber hinaus können Sie mithilfe der Informationen der Zeitachse feststellen, ob eine bestimmte Abfrage langsam ist, weil sie isoliert ausgeführt wird oder weil sie mit anderen Abfragen um dieselben Ressourcen konkurriert. Wenn die Anzahl der aktiven Einheiten während der gesamten Lebensdauer der Abfrage begrenzt ist, die Menge der in der Warteschlange enthaltenen Arbeitseinheiten jedoch hoch bleibt, spricht dies möglicherweise dafür, dass durch Reduzierung der Anzahl gleichzeitiger Abfragen die Ausführungszeit für bestimmte Abfragen erheblich verkürzt werden kann.