Statistiken zur Abfrageleistung abrufen
Das Ausführungsdiagramm für eine Abfrage ist eine visuelle Darstellung der Schritte, die BigQuery zum Ausführen der Abfrage ausführt. In diesem Dokument wird beschrieben, wie Sie mit der Ausführungsgrafik für Abfragen Probleme mit der Abfrageleistung diagnostizieren und Informationen zur Abfrageleistung einsehen können.
BigQuery bietet eine hohe Abfrageleistung, ist jedoch auch ein komplexes verteiltes System mit vielen internen und externen Faktoren, die sich auf die Abfragegeschwindigkeit auswirken können. Aufgrund der deklarativen Beschaffenheit von SQL kann die Komplexität der Abfrageausführung verborgen sein. Daher kann es schwierig sein, die Ursache dafür zu finden, sollten Ihre Abfragen langsamer als erwartet oder langsamer als vorherige Ausführungen ausgeführt werden.
Die Ausführungsgrafik für Abfragen bietet eine dynamische grafische Oberfläche zum Abrufen des Abfrageplans und der Details der Abfrageleistung. Sie können die Ausführungsgrafik für jede laufende oder abgeschlossene Abfrage aufrufen.
Über die Ausführungsgrafik für Abfragen können Sie auch Leistungsinformationen für Abfragen abrufen. Leistungsinformationen stellen Ihnen Best-Effort-Vorschläge zum Verbessern der Abfrageleistung bereit. Da die Abfrageleistung mehrteilig ist, liefern die Leistungsinformationen möglicherweise nur ein unvollständiges Bild der Gesamtabfrageleistung.
Erforderliche Berechtigungen
Zur Verwendung der Abfrageausführungsgrafik benötigen Sie die folgenden Berechtigungen:
bigquery.jobs.getbigquery.jobs.listAll
Diese Berechtigungen sind über die folgenden vordefinierten BigQuery-IAM-Rollen (Identity and Access Management) verfügbar:
roles/bigquery.adminroles/bigquery.resourceAdminroles/bigquery.resourceEditorroles/bigquery.resourceViewer
Struktur der Ausführungsgrafik
Das Diagramm zur Abfrageausführung bietet eine grafische Darstellung des Abfrageplans in der Console. Jedes Kästchen steht für eine Phase im Abfrageplan, z. B.:
- Eingabe: Daten aus einer Tabelle lesen oder bestimmte Spalten auswählen
- Join: Daten aus zwei Tabellen basierend auf der Bedingung
JOINzusammenführen - Aggregieren: Berechnungen wie
SUMdurchführen - Sortieren: Ergebnisse anordnen
Phasen bestehen aus Schritten, die die einzelnen Vorgänge beschreiben, die jeder Worker in einer Phase ausführt. Sie können auf eine Phase klicken, um sie zu öffnen und die zugehörigen Schritte aufzurufen. Die Phasen enthalten auch relative und absolute Zeitinformationen.
Die Namen der Phasen fassen die ausgeführten Schritte zusammen. Eine Phase mit join im Namen bedeutet beispielsweise, dass der Hauptschritt in der Phase ein JOIN-Vorgang ist. Phasennamen, die mit + enden, bedeuten, dass zusätzliche wichtige Schritte ausgeführt werden. Eine Phase mit JOIN+ im Namen führt beispielsweise einen Join-Vorgang und andere wichtige Schritte aus.
Die Linien, die Phasen verbinden, stellen den Austausch von Zwischendaten zwischen Phasen dar. BigQuery speichert die Zwischendaten während der Ausführung von Phasen im Shuffle-Arbeitsspeicher. Die Zahlen an den Rändern geben die geschätzte Anzahl der Zeilen an, die zwischen den Phasen ausgetauscht werden. Das Kontingent für den Shuffle-Arbeitsspeicher hängt von der Anzahl der Slots ab, die dem Konto zugewiesen sind. Wenn das Shuffle-Kontingent überschritten wird, kann der Shuffle-Arbeitsspeicher auf die Festplatte ausgelagert werden, was zu einer erheblichen Verlangsamung der Abfrageleistung führt.
Statistiken zur Abfrageleistung aufrufen
Console
So rufen Sie Informationen zur Abfrageleistung auf:
Öffnen Sie in der Google Cloud Console die Seite „BigQuery“.
Klicken Sie im Editor entweder auf Persönlicher Verlauf oder Projektverlauf.
Suchen Sie in der Liste der Abfragejobs nach den für Sie relevanten Abfragejob. Klicken Sie auf Aktionen und wählen Sie Abfrage im Editor öffnen aus.
Wählen Sie den Tab Ausführungsgrafik aus, um eine grafische Darstellung aller Phasen der Abfrage zu sehen:
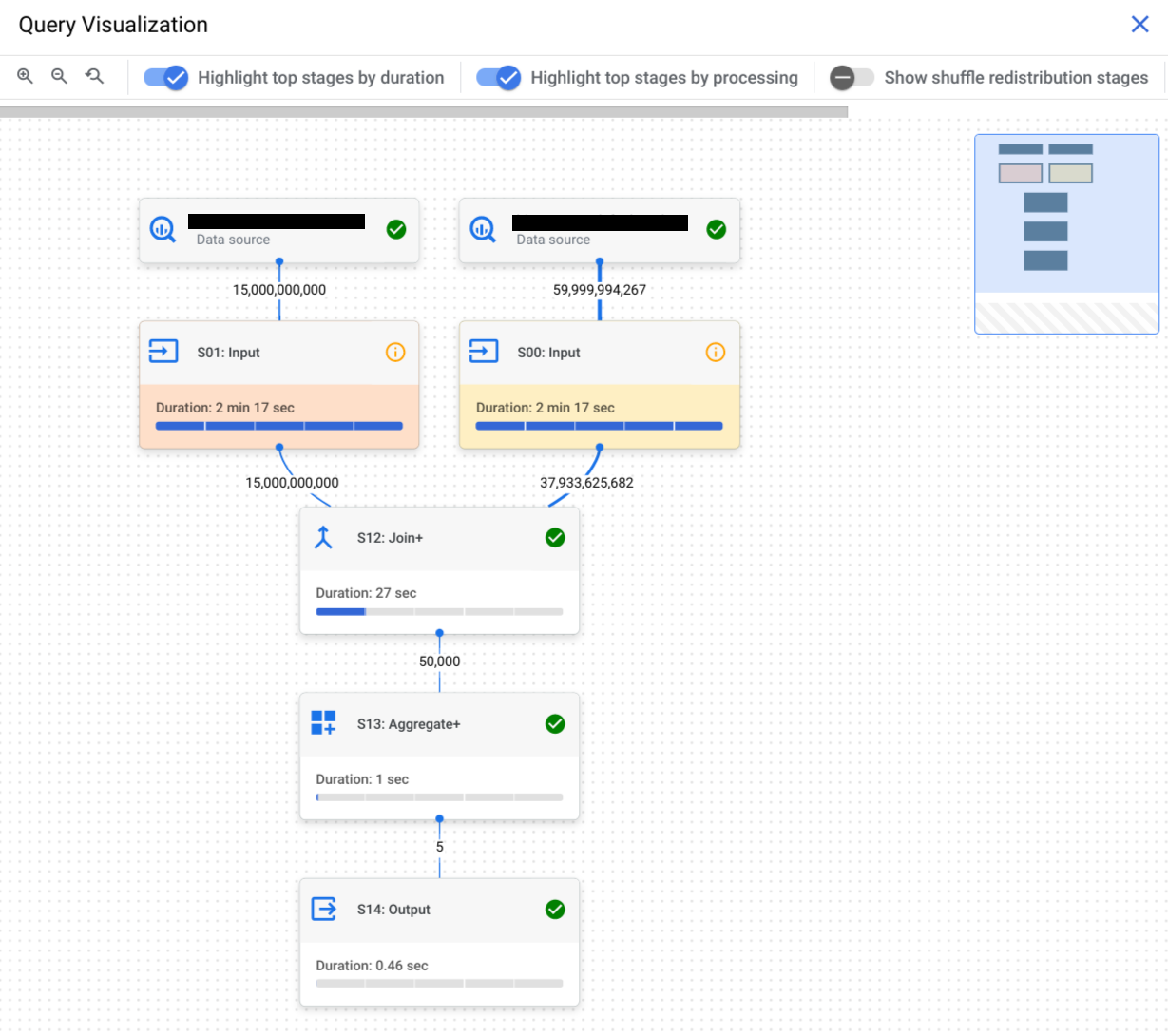
Sehen Sie sich das angezeigte Symbol an, um festzustellen, ob eine Abfragephase Leistungsstatistiken enthält. Phasen mit dem Informationssymbol haben Leistungsstatistiken. Phasen mit einem Häkchensymbol haben keine Leistungsstatistiken.
Klicken Sie auf eine Phase, um den Bereich „Phasendetails“ zu öffnen. Dort finden Sie die folgenden Informationen:
- Informationen zum Abfrageplan für die Phase.
- Die in der Phase ausgeführten Schritte.
- Zulässige Leistungsstatistiken.
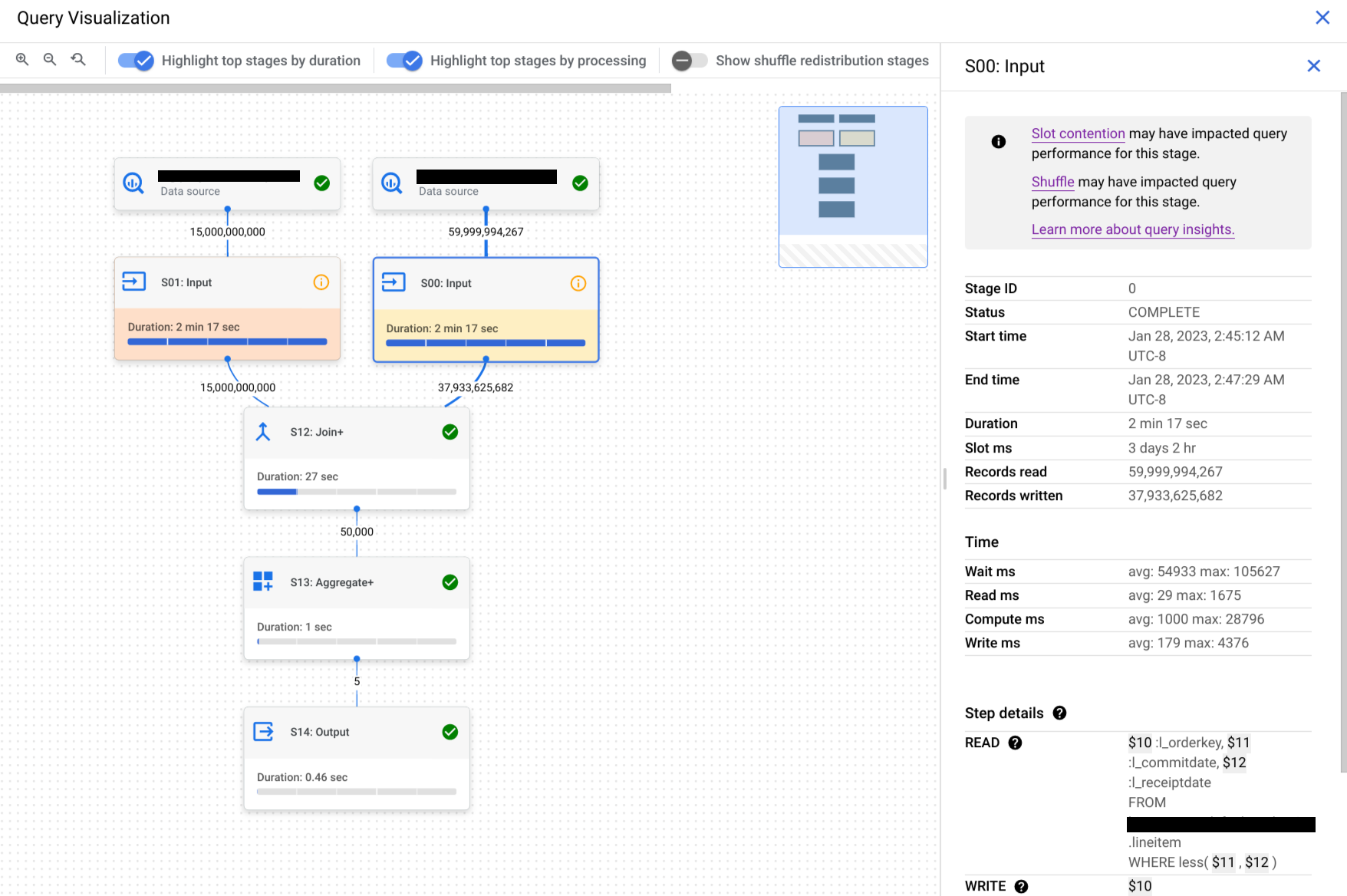
Optional: Wenn Sie eine Abfrage prüfen, die gerade ausgeführt wird, klicken Sie auf Synchronisieren, um die Ausführungsgrafik so zu aktualisieren, dass sie den aktuellen Status der Abfrage widerspiegelt.

Optional: Klicken Sie auf Top-Phasen nach Dauer hervorheben, um die obersten Phasen nach Phasendauer im Diagramm hervorzuheben.

Optional: Um die Top-Phasen in der Grafik nach Slot-Zeit hervorzuheben, klicken Sie auf Top-Phasen nach Verarbeitung hervorheben.

Optional: Klicken Sie auf Shuffle-Umverteilungsphasen anzeigen, um die Shuffle-Umverteilungsphasen in die Grafik aufzunehmen.

Mit dieser Option können Sie die Neupartitionierungs- und Coalesce-Phasen anzeigen lassen, die in der Standardausführungsgrafik ausgeblendet sind.
Während der Ausführung der Abfrage werden Repartition- und Coalesce-Phasen eingeführt. Sie werden verwendet, um die Datenverteilung auf die Worker zu verbessern, die die Abfrage verarbeiten. Da diese Phasen nicht mit Ihrem Abfragetext zusammenhängen, werden sie ausgeblendet, um den angezeigten Abfrageplan zu vereinfachen.
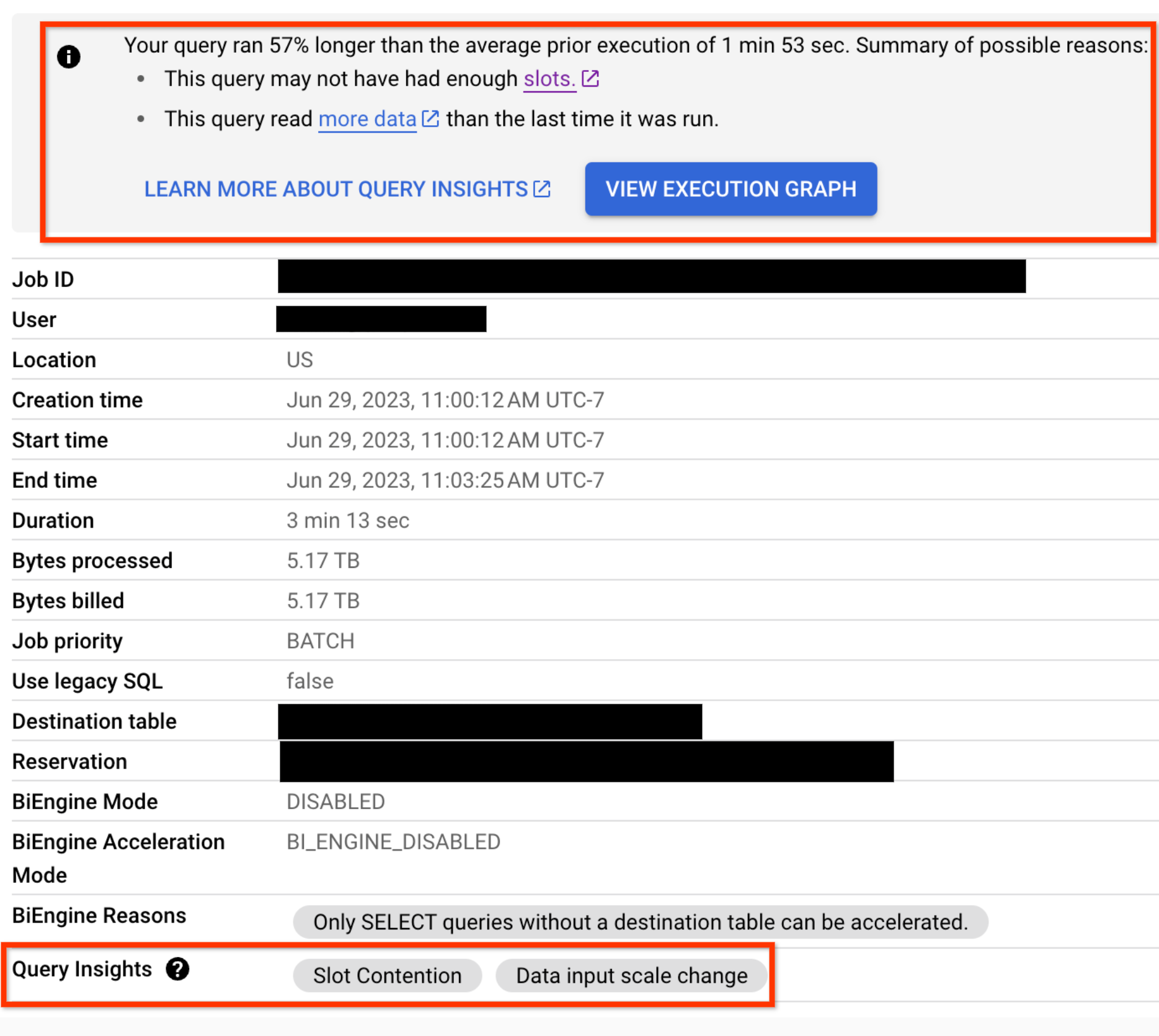
Für jede Abfrage, bei der Leistungsregressionen auftreten, werden auf dem Tab Jobinformationen Leistungsinformationen angezeigt:
SQL
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
SELECT `bigquery-public-data`.persistent_udfs.job_url( project_id || ':us.' || job_id) AS job_url, query_info.performance_insights FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS_BY_PROJECT WHERE DATE(creation_time) >= CURRENT_DATE - 30 -- scan 30 days of query history AND job_type = 'QUERY' AND state = 'DONE' AND error_result IS NULL AND statement_type != 'SCRIPT' AND EXISTS ( -- Only include queries which had performance insights SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_standalone_insights ) WHERE slot_contention OR insufficient_shuffle_quota UNION ALL SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_change_insights ) WHERE input_data_change.records_read_diff_percentage IS NOT NULL );
Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
API
Sie können Statistiken zur Abfrageleistung in einem nicht grafischen Format abrufen, indem Sie die API-Methode jobs.list aufrufen und die zurückgegebenen Informationen JobStatistics2 prüfen.
Statistiken zur Abfrageleistung interpretieren
In diesem Abschnitt erfahren Sie mehr über Bedeutung der Leistungsinformationen und wie Sie mit diesen umgehen.
Leistungsinformationen sind für zwei Zielgruppen vorgesehen:
Analysten: Sie führen Abfragen in einem Projekt aus. Sie möchten herausfinden, warum eine Abfrage, die Sie schon einmal ausgeführt haben, unerwartet langsam ausgeführt wird, und Tipps zur Verbesserung der Abfrageleistung erhalten. Sie haben die in Erforderliche Berechtigungen beschriebenen Berechtigungen.
Administratoren von Data Lakes oder Data Warehouses: Sie verwalten die BigQuery-Ressourcen und ‑Reservierungen Ihrer Organisation. Sie haben die Berechtigungen, die der Rolle „BigQuery-Administrator“ zugeordnet sind.
In jedem der folgenden Abschnitte finden Sie Anleitungen dazu, wie Sie mit einer Leistungsinformation umgehen, die auf Ihrer jeweiligen Rolle basiert.
Slot-Konflikt
Wenn Sie eine Abfrage ausführen, versucht BigQuery, die für die Abfrage erforderlichen Arbeiten in Aufgaben zu unterteilen. Eine Aufgabe ist ein einzelner Datenabschnitt, der in eine Phase ein- und ausgegeben wird. Ein einzelner Slot nimmt eine Aufgabe auf und führt diesen Datenabschnitt für die Phase aus. Im Idealfall werden diese Aufgaben parallel in BigQuery-Slots ausgeführt, um eine hohe Leistung zu erzielen. Slot-Konflikte treten auf, wenn Ihre Abfrage viele Aufgaben hat, die ausgeführt werden können, aber BigQuery nicht genügend verfügbare Slots zum Ausführen hat.
Was Sie tun sollten, wenn Sie ein Analyst sind
Reduzieren Sie die Daten, die Sie in Ihrer Abfrage verarbeiten, indem Sie der Anleitung unter In Abfragen verarbeitete Daten reduzieren folgen.
Was Sie tun sollten, wenn Sie ein Analyst sind
Führen Sie die folgenden Aktionen aus, um die Slot-Verfügbarkeit zu erhöhen oder die Slot-Nutzung zu verringern:
- Wenn Sie die On-Demand-Preise von BigQuery verwenden, verwenden Ihre Abfragen einen gemeinsamen Slot-Pool. Vielleicht sollten Sie stattdessen zu kapazitätsbasierten Analysepreisen wechseln und Reservierungen erwerben. Mit Reservierungen können Sie dedizierte Slots für die Abfragen Ihrer Organisation reservieren.
Wenn Sie BigQuery-Reservierungen verwenden, muss die Reservierung, die dem Projekt zugewiesen ist, in dem die Abfrage ausgeführt wurde, genügend Slots enthalten. In den folgenden Fällen hat die Reservierung möglicherweise nicht genügend Slots:
- Es gibt andere Jobs, die Reservierungsslots belegen. Mit Ressourcendiagrammen für Administratoren können Sie sehen, wie Ihre Organisation die Reservierung nutzt.
- Für die Reservierung sind nicht genügend Slots zugewiesen, um Abfragen schnell genug auszuführen. Mit dem Slot-Estimator können Sie schätzen, wie groß Ihre Reservierungen sein sollten, um die Aufgaben Ihrer Abfragen effizient zu verarbeiten.
Dies können Sie mit einer der folgenden Lösungen machen:
- Fügen Sie dieser Reservierung weitere Slots hinzu (entweder Referenz-Slots oder maximale Reservierungs-Slots).
- Erstellen Sie eine zusätzliche Reservierung und weisen Sie sie dem Projekt zu, in dem die Abfrage ausgeführt wird.
- Verteilen Sie ressourcenintensive Abfragen entweder über die Zeit innerhalb einer Reservierung oder über verschiedene Reservierungen.
Die Tabellen, die Sie abfragen, müssen geclustert sein. Clustering trägt dazu bei, dass BigQuery Spalten mit korrelierten Daten schnell lesen kann.
Die Tabellen, die Sie abfragen, müssen partitioniert sein. Bei nicht partitionierten Tabellen liest BigQuery die gesamte Tabelle. Durch das Partitionieren von Tabellen wird sichergestellt, dass Sie nur die Teilmenge Ihrer Tabellen abfragen, die Sie interessiert.
Unzureichendes Shuffle-Kontingent
Bevor Sie Ihre Abfrage ausführen, teilt BigQuery die Logik Ihrer Abfrage inPhasen auf. BigQuery-Slots führen die Aufgaben für jede Phase aus. Wenn ein Slot die Ausführung der Aufgaben einer Phase abgeschlossen hat, werden die Zwischenergebnisse in Shuffle gespeichert. In den nachfolgenden Phasen Ihrer Abfrage werden Daten aus dem Shuffle gelesen, um die Ausführung der Abfrage fortzusetzen. Ein unzureichendes Shuffle-Kontingent tritt auf, wenn Ihre Daten, die in den Shuffle geschrieben werden müssen, Ihre Shuffle-Kapazität übersteigen.
Was Sie tun sollten, wenn Sie ein Analyst sind
Ähnlich wie bei Slot-Konflikten kann die Reduzierung der von Ihren Abfragen verarbeiteten Datenmenge die Shuffle-Nutzung reduzieren. Folgen Sie dazu der Anleitung in In Abfragen verarbeitete Daten reduzieren.
Bestimmte Vorgänge in SQL führen in der Regel zu einer stärkeren Nutzung von Shuffle, insbesondere JOIN-Vorgänge und GROUP BY-Klauseln.
Wenn möglich, kann die Reduzierung der Datenmenge in diesen Vorgängen die Shuffle-Nutzung reduzieren.
Was Sie tun sollten, wenn Sie ein Analyst sind
Verringern Sie die Belegung von Shuffle-Kontingenten. Führen Sie dazu die folgenden Aktionen aus:
- Ähnlich wie bei Slot-Konflikten verwenden Ihre Abfragen einen gemeinsamen Slot-Pool, wenn Sie die On-Demand-Preise von BigQuery verwenden. Vielleicht sollten Sie stattdessen zu kapazitätsbasierten Analysepreisen wechseln und Reservierungen erwerben. Mit Reservierungen erhalten Sie dedizierte Slots und Shuffle-Kapazität für die Abfragen Ihrer Projekte.
Wenn Sie BigQuery-Reservierungen verwenden, enthalten Slots dedizierte Shuffle-Kapazität. Wenn in Ihrer Reservierung einige Abfragen ausgeführt werden, die Shuffle in großem Umfang verwenden, kann dies dazu führen, dass andere parallel ausgeführte Abfragen nicht genügend Shuffle-Kapazität erhalten. Sie können feststellen, welche Jobs die Shuffle-Kapazität stark nutzen, indem Sie die Spalte
period_shuffle_ram_usage_ratioin der AnsichtINFORMATION_SCHEMA.JOBS_TIMELINEabfragen.Dies können Sie mit einer der folgenden Lösungen machen:
- Fügen Sie dieser Reservierung weitere Slots hinzu.
- Erstellen Sie eine zusätzliche Reservierung und weisen Sie sie dem Projekt zu, in dem die Abfrage ausgeführt wird.
- Verteilen Sie Shuffle-intensive Abfragen entweder über die Zeit innerhalb einer Reservierung oder über verschiedene Reservierungen hinweg.
Änderung der Dateneingabeskalierung
Diese Leistungsinformationen zeigen an, dass Ihre Abfrage für eine bestimmte Eingabetabelle mindestens 50 % mehr Daten liest als beim letzten Ausführen der Abfrage. Mit dem Tabellenänderungsverlauf können Sie feststellen, ob die Größe einer der in der Abfrage verwendeten Tabellen kürzlich erhöht wurde.
Was Sie tun sollten, wenn Sie ein Analyst sind
Reduzieren Sie die Daten, die Sie in Ihrer Abfrage verarbeiten, indem Sie der Anleitung unter In Abfragen verarbeitete Daten reduzieren folgen.
Join mit hoher Kardinalität
Wenn eine Abfrage einen Join mit nicht eindeutigen Schlüsseln auf beiden Seiten des Joins enthält, kann die Größe der Ausgabetabelle erheblich größer sein als die Größe der Eingabetabellen. Diese Erkenntnis zeigt, dass das Verhältnis von Ausgabezeilen zu Eingabezeile hoch ist und liefert Informationen zu dieser Zeilenanzahl.
Was Sie tun sollten, wenn Sie ein Analyst sind
Prüfen Sie Ihre Join-Bedingungen, um zu bestätigen, dass die Erhöhung der Größe der Ausgabetabelle erwartet wird. Vermeiden Sie die Verwendung von Cross Joins.
Wenn Sie einen Cross Join verwenden müssen, versuchen Sie, eine GROUP BY-Klausel zum Voraggregieren von Ergebnissen oder eine Fensterfunktion zu verwenden. Weitere Informationen finden Sie unter Daten vor Verwendung eines JOIN reduzieren.
Partitionsverzerrung
Wenn Sie für dieses Feature Feedback geben oder Support anfordern möchten, senden Sie eine E-Mail an bq-query-inspector-feedback@google.com.
Eine ungleichmäßige Datenverteilung kann dazu führen, dass Abfragen langsam ausgeführt werden. Wenn eine Abfrage ausgeführt wird, teilt BigQuery die Daten in kleine Partitionen für die parallele Verarbeitung auf. Eine Verzerrung tritt auf, wenn Daten ungleichmäßig auf diese Partitionen verteilt sind. Das liegt häufig an häufig vorkommenden Werten in Join- oder Gruppierungsschlüsseln, wodurch einige Partitionen deutlich größer als andere sind. Da ein einzelner Slot eine gesamte Partition verarbeitet und die Arbeit nicht aufteilen kann, kann eine zu große Partition die Verarbeitung verlangsamen, zu Fehlern vom Typ „Ressource überschritten“ führen und im Extremfall den Slot zum Absturz bringen.
Während Sie einen JOIN-Vorgang ausführen, partitioniert BigQuery die Daten auf der linken und rechten Seite des Joins anhand der Join-Schlüssel. Wenn eine Partition zu groß ist, versucht BigQuery, die Daten neu zu verteilen. Wenn die Abweichung zu stark ist, um vollständig ausgeglichen zu werden, wird der JOIN-Phase im Ausführungsdiagramm die Statistik zur Partitionsabweichung hinzugefügt.
Partitionsverzerrung erkennen
Auf dem Tab Ausführungsdiagramm in BigQuery Studio können Sie herausfinden, in welcher Phase der Abfrage die Partitionierung ungleichmäßig ist. Der Insight wird auf der Bühne markiert. Anhand der Stufendetails können Sie den relevanten Teil des Abfragetexts und die verarbeiteten Tabellen ermitteln. Weitere Informationen finden Sie unter Schritte mit Abfragetext verstehen.
Beispiel
Die folgende Abfrage verknüpft Repository-Informationen mit Dateiinformationen. Eine Verzerrung kann auftreten, wenn einige Repositories viel mehr Dateien als andere enthalten.
SELECT r.repo_name, COUNT(f.path) AS file_count
FROM `bigquery-public-data.github_repos.sample_repos` AS r
JOIN `bigquery-public-data.github_repos.sample_files` AS f
ON r.repo_name = f.repo_name
WHERE r.watch_count > 10
GROUP BY r.repo_name
Der Join-Schlüssel ist repo_name. In der Tabelle sample_repos muss repo_name eindeutig sein. In der Tabelle sample_files kann repo_name jedoch mehrmals vorkommen. Wenn einige repo_name-Werte in sample_files unverhältnismäßig häufig vorkommen, führt dies zu einer Datenabweichung.
Um zu prüfen, ob eine Datenabweichung vorliegt, analysieren Sie die Verteilung des Join-Schlüssels in der größeren Tabelle (in diesem Fall sample_files). Führen Sie die folgende Abfrage aus, um die Verteilung von repo_name zu bewerten:
SELECT repo_name, COUNT(*) AS occurrences
FROM `bigquery-public-data.github_repos.sample_files`
GROUP BY repo_name
ORDER BY occurrences DESC
Bei sehr großen Tabellen können Sie mit der Funktion APPROX_TOP_COUNT die häufigsten Werte effizient schätzen.
SELECT APPROX_TOP_COUNT(repo_name, 100)
FROM `bigquery-public-data.github_repos.sample_files`
Wenn die Anzahl der Top-Werte um Größenordnungen höher ist als die anderer Werte, liegt eine Datenabweichung vor.
Partitionsverzerrung verringern
Sie können die folgenden Strategien verwenden, um die Partitionierungsabweichung zu beheben:
- Daten frühzeitig filtern: Reduzieren Sie die Menge der verarbeiteten Daten, indem Sie Filter so früh wie möglich in Ihrer Abfrage anwenden. Dadurch kann die Anzahl der Zeilen, die mit ungleichmäßig verteilten Schlüsseln verknüpft sind, reduziert werden, bevor sie Vorgänge wie
JOINoderGROUP BYerreichen. Abfrage aufteilen, um verzerrte Schlüssel zu isolieren: Wenn die Abweichung durch einige bestimmte Schlüsselwerte verursacht wird, ähnlich dem Feld
repo_nameim vorherigen Beispiel, sollten Sie die Abfrage aufteilen. Verarbeiten Sie die Daten für die asymmetrischen Schlüssel separat von den restlichen Daten und kombinieren Sie die Ergebnisse dann mitUNION ALL.Beispiel: Einen häufig verwendeten Schlüssel isolieren.
-- Query for the skewed key SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name = 'popular_repo' GROUP BY r.repo_name UNION ALL -- Query for all other keys SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name != 'popular_repo' GROUP BY r.repo_nameNULL-Werte und Standardwerte verarbeiten: Eine häufige Ursache für Verzerrungen ist eine große Anzahl von Zeilen mitNULL-Werten oder leeren Strings in Schlüsselspalten. Wenn Sie diese Zeilen nicht für die Analyse benötigen, filtern Sie sie mit einerWHERE-Klausel vor demJOINoderGROUP BYheraus.Vorgänge neu anordnen: Bei Abfragen mit mehreren Joins kann die Reihenfolge wichtig sein. Führen Sie Joins, die die Anzahl der Zeilen erheblich reduzieren, möglichst früh in der Abfrage aus.
Näherungsfunktionen verwenden: Bei Aggregationen für verzerrte Daten sollten Sie überlegen, ob ein ungefähres Ergebnis akzeptabel ist. Funktionen wie
APPROX_COUNT_DISTINCTsind toleranter gegenüber Datenabweichungen als genaue Funktionen wieCOUNT(DISTINCT).
Informationen zur Abfragephase auswerten
Zusätzlich zu Statistiken zur Abfrageleistung können Sie auch die folgenden Richtlinien verwenden, wenn Sie Details zur Abfragephase prüfen, um festzustellen, ob ein Problem mit einer Abfrage vorliegt:
- Wenn der Wert von Wartezeit in ms für eine oder mehrere Phasen im Vergleich zu vorherigen Ausführungen der Abfrage hoch ist:
- Prüfen Sie, ob Sie genügend Slots für Ihre Arbeitslast haben. Andernfalls wenden Sie das Load-Balancing an, wenn Sie ressourcenintensive Abfragen ausführen, damit diese nicht miteinander konkurrieren.
- Wenn der Wert für Wartezeit in ms höher ist als für nur eine Phase, sehen Sie sich die Phase davor an, um zu sehen, ob ein Engpass eingeführt wurde. Umstände wie erhebliche Änderungen an den Daten oder dem Schema der an der Abfrage beteiligten Tabellen können sich auf die Abfrageleistung auswirken.
- Wenn der Wert der Shuffle-Ausgabe-Byte für eine Phase im Vergleich zu den vorherigen Ausführungen der Abfrage oder im Vergleich zu einer vorherigen Phase hoch ist, bewerten Sie die in dieser Phase verarbeiteten Schritte, um festzustellen, ob unerwartet große Datenmengen erstellt werden. Eine häufige Ursache hierfür ist, dass ein Schritt einen
INNER JOINverarbeitet, bei dem auf beiden Seiten des Joins doppelte Schlüssel vorhanden sind. Dies kann zu einer unerwartet großen Datenmenge führen. - Verwenden Sie die Ausführungsgrafik, um die obersten Phasen nach Dauer und Verarbeitung anzusehen. Berücksichtigen Sie die Menge der erzeugten Daten und ob sie der Größe der in der Abfrage angegebenen Tabellen entsprechen. Ist dies nicht der Fall, prüfen Sie die Schritte in diesen Phasen, um festzustellen, ob einer davon möglicherweise eine unerwartete Menge an Zwischendaten verursacht.
Nächste Schritte
- Richtlinien zur Abfrageoptimierung mit Tipps zur Verbesserung der Abfrageleistung