파티션을 나눈 테이블 소개
파티션을 나눈 테이블은 파티션이라고 하는 세그먼트로 분할되어 데이터를 더 쉽게 관리하고 쿼리할 수 있습니다. 큰 테이블을 작은 파티션으로 나누면 쿼리 성능을 높일 수 있으며 쿼리에서 읽는 바이트 수를 줄여 비용을 제어할 수 있습니다. 테이블을 분할하려면 테이블을 세그먼트로 나누는 데 사용되는 파티션 열을 지정합니다.
쿼리에서 파티션 나누기 열의 값에 대해 한정 필터가 사용되는 경우 BigQuery가 필터와 일치하는 파티션을 스캔하고 남은 파티션을 건너뛸 수 있습니다. 이 프로세스를 프루닝이라고 합니다.
파티션을 나눈 테이블에서 데이터는 데이터의 한 파티션을 포함하는 각 물리적 블록에 저장됩니다. 파티션을 나눈 각 테이블은 테이블을 수정하는 모든 작업에서 정렬 속성에 대한 다양한 메타데이터를 유지합니다. 메타데이터를 통해 BigQuery가 쿼리를 실행하기 전에 쿼리 비용을 더 정확히 예측할 수 있습니다.
파티션 나누기를 사용해야 하는 경우
다음과 같은 시나리오에서 테이블 파티션 나누기를 고려하세요.
- 테이블의 일부만 스캔하여 쿼리 성능을 개선하려고 합니다.
- 테이블 작업이 표준 테이블 할당량을 초과하며 테이블 작업을 특정 파티션 열 값으로 범위를 지정하여 더 높은 파티션을 나눈 테이블 할당량을 허용할 수 있습니다.
- 쿼리를 실행하기 전에 쿼리 비용을 결정하려고 합니다. BigQuery는 파티션을 나눈 테이블에서 쿼리를 실행하기 전에 쿼리 비용 추정치를 제공합니다. 파티션을 나눈 테이블을 프루닝한 후 쿼리 테스트 실행을 수행하여 쿼리 비용을 추정하여 쿼리 비용에 대한 추정치를 계산합니다.
- 다음과 같은 파티션 수준 관리 기능 중 하나를 사용하고자 합니다.
- 지정된 기간이 지난 후 전체 파티션을 자동으로 삭제하려면 파티션 만료 시간을 설정합니다.
- 테이블의 다른 파티션에 영향을 주지 않고 로드 작업을 사용하여 특정 파티션에 데이터를 작성합니다.
- 전체 테이블을 스캔하지 않고 특정 파티션을 삭제합니다.
다음과 같은 경우 테이블을 파티션으로 나누는 대신 테이블을 클러스터링하는 것이 좋습니다.
- 파티셔닝이 허용하는 것보다 더 많은 세부사항이 필요합니다.
- 쿼리는 일반적으로 여러 열에 대해 필터 또는 집계를 사용합니다.
- 열 또는 열 그룹에 있는 값 수의 카디널리티가 큽니다.
- 쿼리를 실행하기 전에 엄격한 비용 추정이 필요하지 않습니다.
- 파티션을 나누면 파티션당 소량의 데이터가 생성됩니다(10GB 미만). 작은 파티션을 여러 개 만들면 테이블의 메타데이터가 증가하여 테이블을 쿼리할 때 메타데이터 액세스 시간에 영향을 줄 수 있습니다.
- 파티션 나누기를 사용하면 파티션을 나눈 테이블의 한도를 넘어서 많은 파티션 수가 생성됩니다.
- DML 작업은 테이블에서 대부분의 파티션을 자주(예: 몇 분마다) 수정합니다.
이 경우 테이블 클러스터링을 사용하면 사용자 정의 정렬 속성을 기반으로 특정 열의 데이터를 클러스터링하여 쿼리를 가속화할 수 있습니다.
클러스터링과 테이블 파티션 나누기를 결합하여 더욱 세부적으로 정렬할 수도 있습니다. 이 방법에 대한 자세한 내용은 클러스터링된 테이블 및 테이블 파티션 나누기 결합을 참조하세요.
파티셔닝 유형
이 섹션에서는 테이블을 파티션으로 나누는 다양한 방법을 설명합니다.
정수 범위로 파티션 나누기
특정 INTEGER 열의 값 범위를 기준으로 테이블의 파티션을 나눌 수 있습니다. 정수 범위로 파티션을 나눈 테이블을 만들려면 다음을 지정해야 합니다.
- 파티션 나누기 열
- 파티션 나누기 범위의 시작 값(해당 값 포함)
- 파티션 나누기 범위의 종료 값(해당 값 제외)
- 파티션 내 각 범위의 간격
예를 들어 다음 사양을 사용하여 정수 범위 파티션을 만든다고 가정하겠습니다.
| 인수 | 값 |
|---|---|
| 열 이름 | customer_id |
| 시작 | 0 |
| End | 100 |
| interval | 10 |
이 테이블은 customer_id 열을 기준으로 간격 10의 범위로 파티션이 나눠집니다.
0~9 값을 하나의 파티션에 포함하고, 10~19 값을 다음 파티션에 포함하고, 이런 방식으로 최대 99까지 포함합니다. 이 범위를 벗어나는 값은 __UNPARTITIONED__라는 파티션에 포함됩니다. customer_id가 NULL인 모든 행은 __NULL__이라는 파티션에 포함됩니다.
정수 범위로 파티션을 나눈 테이블에 대한 자세한 내용은 정수 범위로 파티션을 나눈 테이블 만들기를 참고하세요.
시간 단위 열로 파티션 나누기
테이블의 DATE, TIMESTAMP 또는 DATETIME 열에서 테이블의 파티션을 나눌 수 있습니다. 테이블에 데이터를 쓰면 BigQuery는 열의 값을 기준으로 데이터를 올바른 파티션에 자동으로 넣습니다.
TIMESTAMP 및 DATETIME 열의 파티션에는 시간별, 일별, 월간 또는 연간 세부사항이 포함될 수 있습니다. DATE 열의 파티션에는 일별, 월간 또는 연간 세부사항이 포함될 수 있습니다. 파티션 경계는 UTC 시간을 기반으로 합니다.
예를 들어 DATETIME 열에서 월별 파티션 나누기를 사용하여 테이블의 파티션을 나눈다고 가정해 보겠습니다. 다음 값을 테이블에 삽입하면 행이 다음 파티션에 기록됩니다.
| 열 값 | 파티션(월별) |
|---|---|
DATETIME("2019-01-01") |
201901 |
DATETIME("2019-01-15") |
201901 |
DATETIME("2019-04-30") |
201904 |
또한 두 개의 특수 파티션이 만들어집니다.
__NULL__: 파티션 나누기 열에NULL값이 있는 행을 포함합니다.__UNPARTITIONED__: 파티션 나누기 열의 값이 1960-01-01 이전 또는 2159-12-31 이후인 행을 포함합니다.
시간 단위 열로 파티션을 나눈 테이블에 대한 자세한 내용은 시간 단위 열로 파티션을 나눈 테이블 만들기를 참고하세요.
수집 시간으로 파티션 나누기
수집 시간으로 파티션을 나눈 테이블을 만들면 BigQuery는 BigQuery가 데이터를 수집하는 시간을 기준으로 파티션에 자동으로 행을 할당합니다. 파티션에 대해 시간별, 일별, 월간 또는 연간 세부사항을 선택할 수 있습니다. 파티션 경계는 UTC 시간을 기반으로 합니다.
더 세분화된 시간을 사용할 때 데이터가 테이블당 최대 파티션 수에 도달할 수 있는 경우 대신 덜 세분화된 시간을 사용합니다. 예를 들어 일 대신 월을 기준으로 파티션을 나누면 파티션 수를 줄일 수 있습니다. 파티션 열을 클러스터링하여 성능을 더욱 개선할 수도 있습니다.
수집 시간으로 파티션을 나눈 테이블에는 _PARTITIONTIME이라는 유사 열이 있습니다.
이 열의 값은 파티션 경계(예: 시간별 또는 일별)로 잘린 각 행의 수집 시간입니다. 예를 들어 시간별로 파티션을 나누는 수집 시간으로 파티션을 나눈 테이블을 만들고 다음 시간에 데이터를 전송한다고 가정해 보겠습니다.
| 수집 시간 | _PARTITIONTIME |
파티션(시간별) |
|---|---|---|
| 2021-05-07 17:22:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 17:40:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 18:31:00 | 2021-05-07 18:00:00 | 2021050718 |
이 예시의 테이블은 시간별 파티션 나누기를 사용하므로 _PARTITIONTIME 값은 시간 경계로 잘립니다. BigQuery는 이 값을 사용하여 데이터에 적합한 파티션을 결정합니다.
또한 특정 파티션에 데이터를 쓸 수도 있습니다. 예를 들어 이전 데이터를 로드하거나 시간대에 맞게 조정해야 할 수 있습니다. 0001-01-01과 9999-12-31 사이의 유효한 날짜를 사용할 수 있습니다. 그러나 DML 문은 1970-01-01 이전 또는 2159-12-31 이후의 날짜를 참조할 수 없습니다. 자세한 내용은 특정 파티션에 데이터 쓰기를 참조하세요.
_PARTITIONTIME을 사용하는 대신 _PARTITIONDATE를 사용할 수도 있습니다.
_PARTITIONDATE 유사 열에는 _PARTITIONTIME 유사 열의 값에 해당하는 UTC 날짜가 포함됩니다.
일별, 시간별, 월간 또는 연간 파티션 나누기 선택
시간 단위 열 또는 수집 시간을 기준으로 테이블의 파티션을 나눌 때 파티션에 일별, 시간별, 월간, 연간 세부사항을 포함할지 선택합니다.
일변 파티션 나누기는 기본 파티션 나누기 유형입니다. 일별 파티션 나누기는 데이터가 긴 기간에 걸쳐 있거나 시간이 지남에 따라 데이터가 계속 추가되는 경우에 적합합니다.
테이블에 단기간(일반적으로 타임스탬프 값이 6개월 미만)에 걸쳐 있는 데이터가 많은 경우 시간별 파티션 나누기를 선택합니다. 시간별 파티션 나누기를 선택할 경우 파티션 수가 파티션 한도 내에 있는지 확인합니다.
테이블의 일별 데이터 양이 상대적으로 적지만 긴 기간에 걸쳐 있는 경우 월간 또는 연간 파티션 나누기를 선택합니다. 워크플로가 긴 기간(예: 500개가 넘는 날짜)에 걸쳐 있는 행을 자주 업데이트하거나 추가해야 하는 경우 이 옵션을 사용하는 것이 좋습니다. 이러한 시나리오에서는 파티션 나누기 열의 클러스터링과 함께 월간 또는 연간 파티션 나누기를 사용하여 최고의 성능을 달성합니다. 자세한 내용은 이 문서의 클러스터링된 테이블과 파티션을 나눈 테이블 결합을 참조하세요.
클러스터링된 테이블과 파티션을 나눈 테이블 결합
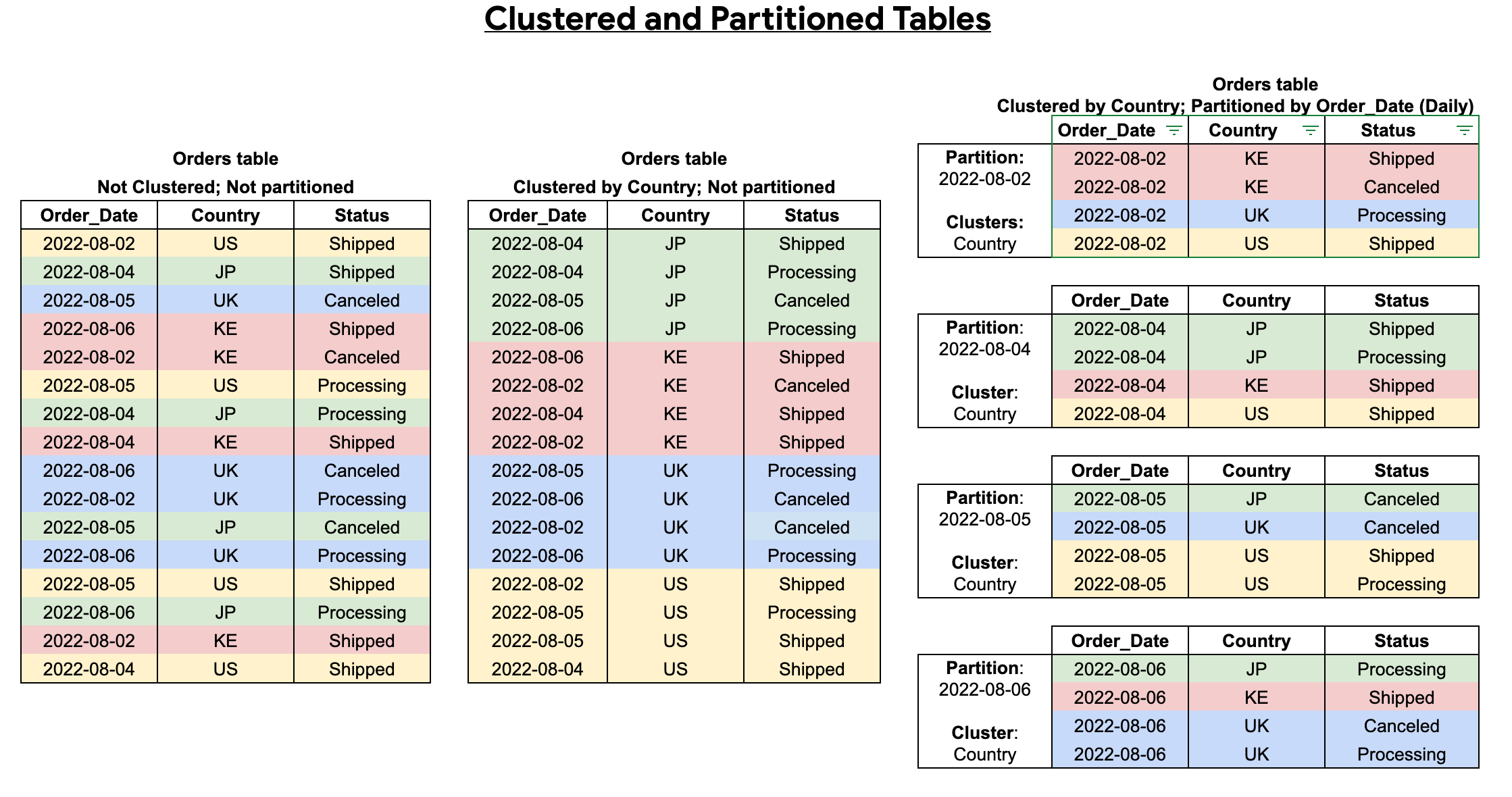
테이블 파티션 나누기를 테이블 클러스터링과 결합하면 더욱 세부적으로 정렬하여 쿼리를 보다 최적화할 수 있습니다.
클러스터링된 테이블에는 사용자 정의 정렬 속성에 따라 데이터를 정렬하는 클러스터링된 열이 포함됩니다. 이러한 클러스터링된 열의 데이터는 테이블 크기에 따라 적응적으로 크기가 조정되는 스토리지 블록으로 정렬됩니다. 클러스터링된 열을 기준으로 필터링하는 쿼리를 실행하면 BigQuery는 전체 테이블 또는 테이블 파티션 대신 클러스터링된 열을 기준으로 관련 블록만 스캔합니다. 테이블 파티션 나누기와 클러스터링을 모두 사용하는 결합된 접근 방식에서는 먼저 테이블 데이터를 파티션으로 분할한 다음 클러스터링 열을 통해 각 파티션 내의 데이터를 클러스터링합니다.
클러스터링되고 파티션을 나눈 테이블을 만들 때 다음 다이어그램과 같이 보다 세부적인 정렬을 달성할 수 있습니다.
파티션 나누기와 분할 비교
테이블 샤딩은 [PREFIX]_YYYYMMDD와 같은 이름 프리픽스를 사용하여 여러 테이블에 데이터를 저장하는 방법입니다.
파티션을 나눈 테이블이 성능이 더 우수하므로 테이블 샤딩보다 파티션 나누기를 권장합니다. 샤딩된 테이블의 경우 BigQuery는 각 테이블의 스키마와 메타데이터의 복사본을 유지관리해야 합니다. 또한 BigQuery는 쿼리된 각 테이블의 권한을 확인해야 할 수 있습니다. 이 때문에 쿼리 오버헤드도 추가되고 쿼리 성능에 영향을 미칩니다.
이전에 날짜로 샤딩된 테이블을 만든 경우 이 테이블을 수집 시간으로 파티션을 나눈 테이블로 변환할 수 있습니다. 자세한 내용은 날짜로 샤딩된 테이블을 수집 시간으로 파티션을 나눈 테이블로 변환을 참조하세요.
파티션 데코레이터
파티션 데코레이터를 사용하면 테이블의 파티션을 참조할 수 있습니다. 예를 들어 특정 파티션에 데이터를 쓰는 데 사용할 수 있습니다.
파티션 데코레이터는 table_name$partition_id 형식이며, 여기서 partition_id 세그먼트의 형식은 파티션 나누기 유형에 따라 다릅니다.
| 파티션 나누기 유형 | 형식 | 예 |
|---|---|---|
| 매시간 | yyyymmddhh |
my_table$2021071205 |
| 매일 | yyyymmdd |
my_table$20210712 |
| 매월 | yyyymm |
my_table$202107 |
| 매년 | yyyy |
my_table$2021 |
| 정수 범위 | range_start |
my_table$40 |
파티션의 데이터 탐색
지정된 파티션의 데이터를 둘러보려면 파티션 데코레이터와 함께 bq head 명령어를 사용합니다.
예를 들어 다음 명령어는 2018-02-24 파티션에서 my_dataset.my_table의 처음 10개 행에 있는 모든 필드를 나열합니다.
bq head --max_rows=10 'my_dataset.my_table$20180224'
테이블 데이터 내보내기
파티션을 나눈 테이블에서 데이터를 내보내는 방법은 파티션을 나누지 않은 테이블에서 데이터를 내보내는 방법과 동일합니다. 자세한 내용은 테이블 데이터 내보내기를 참조하세요.
개별 파티션에서 데이터를 내보내려면 bq extract 명령어를 사용하고 테이블 이름에 파티션 데코레이터를 추가합니다. 예를 들면 my_table$20160201입니다. 또한 테이블 이름에 파티션 이름을 추가하여 __NULL__ 및 __UNPARTITIONED__ 파티션에서 데이터를 내보낼 수 있습니다. 예를 들면 my_table$__NULL__ 또는 my_table$__UNPARTITIONED__입니다.
제한사항
파티션을 나눈 테이블에는 다음과 같은 제한사항이 있습니다.
legacy SQL로는 파티션을 나눈 테이블을 쿼리하거나 쿼리 결과를 파티션을 나눈 테이블에 쓸 수 없습니다.
BigQuery는 여러 열의 파티션 나누기를 지원하지 않습니다. 테이블 파티션을 나누는 데에는 하나의 열만 사용할 수 있습니다.
파티션을 나누지 않은 기존 테이블을 파티션을 나눈 테이블로 직접 변환할 수는 없습니다. 파티션 나누기 전략은 테이블이 생성될 때 정의됩니다. 대신
CREATE TABLE문을 사용하여 기존 테이블의 데이터를 쿼리하여 새 파티션 테이블을 만듭니다.시간 단위 열로 파티션을 나눈 테이블에는 다음과 같은 제한사항이 적용됩니다.
- 파티션 나누기 열은 스칼라
DATE,TIMESTAMP또는DATETIME열이어야 합니다. 열의 모드는REQUIRED나NULLABLE일 수는 있지만REPEATED(배열 기반)이어서는 안 됩니다. - 파티션 나누기 열은 최상위 필드여야 합니다.
RECORD(STRUCT)의 리프 필드는 파티션 나누기 열로 사용할 수 없습니다.
시간 단위 열로 파티션을 나눈 테이블에 대한 자세한 내용은 시간 단위 열로 파티션을 나눈 테이블 만들기를 참고하세요.
- 파티션 나누기 열은 스칼라
정수 범위로 파티션을 나눈 테이블에는 다음과 같은 제한사항이 적용됩니다.
- 파티션 나누기 열은
INTEGER열이어야 합니다. 열의 모드는REQUIRED나NULLABLE일 수는 있지만REPEATED(배열 기반)여서는 안 됩니다. - 파티션 나누기 열은 최상위 필드여야 합니다.
RECORD(STRUCT)의 리프 필드는 파티션 나누기 열로 사용할 수 없습니다.
정수 범위로 파티션을 나눈 테이블에 대한 자세한 내용은 정수 범위로 파티션을 나눈 테이블 만들기를 참고하세요.
- 파티션 나누기 열은
할당량 및 한도
BigQuery에서 파티션을 나눈 테이블에는 한도가 정의되어 있습니다.
할당량과 한도는 다음을 포함하여 파티션을 나눈 테이블을 대상으로 실행할 수 있는 여러 작업 유형에도 적용됩니다.
모든 할당량 및 한도에 대한 자세한 내용은 할당량 및 한도를 참조하세요.
테이블 가격 책정
BigQuery에서 파티션을 나눈 테이블을 만들고 사용할 때 부과되는 비용은 파티션에 저장되는 데이터와 데이터를 대상으로 실행하는 쿼리의 양에 따라 결정됩니다.
파티션에 데이터 로드하기, 파티션 복사, 파티션에서 데이터 내보내기를 포함하여 파티션을 나눈 테이블 작업 중 많은 작업이 무료입니다. 이러한 작업은 무료지만 BigQuery의 할당량 및 한도가 적용됩니다. 모든 무료 작업에 대한 자세한 내용은 가격 책정 페이지의 무료 작업을 참조하세요.
BigQuery의 비용 관리 권장사항은 BigQuery의 비용 관리를 참조하세요.
테이블 보안
파티션을 나눈 테이블의 액세스 제어는 표준 테이블의 액세스 제어와 동일합니다. 자세한 내용은 테이블 액세스 제어 소개를 참조하세요.
다음 단계
- 파티션을 나눈 테이블을 만드는 방법은 파티션을 나눈 테이블 만들기를 참조하세요.
- 파티션을 나눈 테이블을 관리하고 업데이트하는 방법을 알아보려면 파티션을 나눈 테이블 관리를 참조하세요.
- 파티션을 나눈 테이블 쿼리에 대한 자세한 내용은 파티션을 나눈 테이블 쿼리를 참조하세요.