Geclusterte Tabellen verwalten
In diesem Dokument wird beschrieben, wie Sie Informationen zu geclusterten Tabellen in BigQuery abrufen und den Zugriff darauf steuern.
Hier finden Sie weitere Informationen:
- Weitere Informationen zur Unterstützung geclusterter Tabellen in BigQuery finden Sie unter Einführung in geclusterte Tabellen.
- Informationen zum Erstellen geclusterter Tabellen finden Sie unter Geclusterte Tabellen erstellen.
Hinweise
Sie benötigen die Berechtigung bigquery.tables.get, um Informationen zu Tabellen abzurufen. Die folgenden vordefinierten IAM-Rollen enthalten bigquery.tables.get-Berechtigungen:
roles/bigquery.metadataViewerroles/bigquery.dataViewerroles/bigquery.dataOwnerroles/bigquery.dataEditorroles/bigquery.admin
Wenn ein Nutzer mit der Berechtigung bigquery.datasets.create ein Dataset erstellt, hat er dafür außerdem Zugriff als bigquery.dataOwner.
Mit dem bigquery.dataOwner-Zugriff hat der Nutzer die Möglichkeit, Informationen über Tabellen in einem Dataset abzurufen.
Weitere Informationen zu IAM-Rollen und Berechtigungen in BigQuery finden Sie unter Vordefinierte Rollen und Berechtigungen.
Zugriff auf geclusterte Tabellen steuern
Wenn Sie den Zugriff auf Tabellen und Ansichten konfigurieren möchten, können Sie einer Entität auf den folgenden Ebenen, geordnet vom größten zulässigen Ressourcenbereich zum kleinsten, eine IAM-Rolle zuweisen:
- auf einer übergeordneten Ebene in der Google Cloud -Ressourcenhierarchie, z. B. der Projekt-, Ordner- oder Organisationsebene
- auf der Dataset-Ebene
- auf der Tabellen- oder Ansichtsebene
Sie können den Datenzugriff innerhalb von Tabellen auch mithilfe der folgenden Methoden einschränken:
Der Zugriff über eine durch IAM geschützte Ressource ist additiv. Wenn eine Entität beispielsweise keinen Zugriff auf übergeordneter Ebene (z. B. Projektebene) hat, können Sie der Entität Zugriff auf Dataset-Ebene gewähren. Die Entität hat dann Zugriff auf die Tabellen und Ansichten im Dataset. Wenn die Entität dagegen weder Zugriff auf übergeordneter Ebene noch auf Dataset-Ebene hat, können Sie der Entität Zugriff auf Tabellen- oder Ansichtsebene gewähren.
Wenn Sie in der Google Cloud-Ressourcenhierarchie IAM-Rollen auf einer höheren Ebene zuweisen, z. B. auf Projekt-, Ordner- oder Organisationsebene, erhält die Entität Zugriff auf eine Vielzahl von Ressourcen. Wenn Sie beispielsweise einer Entität auf Projektebene eine Rolle zuweisen, erhält diese Entität Berechtigungen, die für alle Datasets im gesamten Projekt gelten.
Durch das Zuweisen einer Rolle auf Dataset-Ebene werden die Vorgänge angegeben, die eine Entität für Tabellen und Ansichten in diesem bestimmten Dataset ausführen darf, auch wenn die Entität keinen Zugriff auf einer höheren Ebene hat. Informationen zum Konfigurieren von Zugriffssteuerungen auf Dataset-Ebene finden Sie unter Zugriff auf Datasets steuern.
Durch das Zuweisen einer Rolle auf Tabellen- oder Ansichtsebene werden die Vorgänge angegeben, die eine Entität für bestimmte Tabellen und Ansichten ausführen darf, auch wenn die Entität keinen Zugriff auf einer höheren Ebene hat. Informationen zum Konfigurieren von Zugriffssteuerungen auf Tabellenebene finden Sie unter Zugriff auf Tabellen und Ansichten steuern.
Sie können auch benutzerdefinierte IAM-Rollen erstellen. Wenn Sie eine benutzerdefinierte Rolle erstellen, hängen die erteilten Berechtigungen von den spezifischen Vorgängen ab, die die Entität ausführen soll.
Sie können für eine durch IAM geschützte Ressource keine "Ablehnen"-Berechtigung festlegen.
Weitere Informationen zu Rollen und Berechtigungen finden Sie in der IAM-Dokumentation unter Informationen zu Rollen und in BigQuery-IAM-Rollen und -Berechtigungen.
Informationen zu geclusterten Tabellen abrufen
Wählen Sie eine der folgenden Optionen aus:
Console
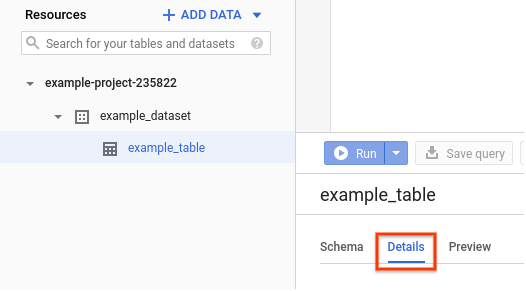
Wechseln Sie in der Google Cloud -Console zum Bereich Ressourcen.
Klicken Sie auf den Dataset-Namen, um das Dataset einzublenden. Klicken Sie dann auf den Namen der Tabelle, die Sie aufrufen möchten.
Klicken Sie auf Details.
Die Details der Tabelle werden angezeigt, einschließlich der Clustering-Spalten.
SQL
Bei geclusterten Tabellen können Sie in der Ansicht INFORMATION_SCHEMA.COLUMNS die Spalte CLUSTERING_ORDINAL_POSITION abfragen, um den 1-indexierten Versatz der Clustering-Spalten in der Tabelle zu ermitteln:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
CREATE TABLE mydataset.data (column1 INT64, column2 INT64) CLUSTER BY column1, column2; SELECT column_name, clustering_ordinal_position FROM mydataset.INFORMATION_SCHEMA.COLUMNS;
Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
Die Ordinalposition des Clusters ist 1 für column1 und 2 für column2.
Weitere Tabellenmetadaten sind über die Ansichten TABLES, TABLE_OPTIONS, COLUMNS und COLUMN_FIELD_PATH in INFORMATION_SCHEMA verfügbar.
bq
Führen Sie den Befehl bq show aus, um alle Tabelleninformationen aufzurufen. Verwenden Sie das Flag --schema, wenn nur Informationen zum Tabellenschema angezeigt werden sollen. Mit dem Flag --format kann die Ausgabe gesteuert werden.
Wenn Sie Informationen zu einer Tabelle in einem anderen Projekt als Ihrem Standardprojekt abrufen, fügen Sie dem Dataset die Projekt-ID im folgenden Format hinzu: project_id:dataset
bq show \ --schema \ --format=prettyjson \ PROJECT_ID:DATASET.TABLE
Ersetzen Sie Folgendes:
PROJECT_ID: Ihre Projekt-IDDATASET: der Name des DatasetsTABLE: der Name der Tabelle
Beispiele:
Geben Sie den folgenden Befehl ein, um alle Informationen zu myclusteredtable in mydataset aufzurufen. mydataset in Ihrem Standardprojekt.
bq show --format=prettyjson mydataset.myclusteredtable
Die Ausgabe sollte so in etwa aussehen:
{
"clustering": {
"fields": [
"customer_id"
]
},
...
}
API
Mithilfe der Methode bigquery.tables.get geben Sie alle relevanten Parameter an.
Geclusterte Tabellen in einem Dataset auflisten
Die Berechtigungen und die Vorgehensweise zum Auflisten von geclusterten Tabellen sind dieselben wie für partitionierte Tabellen. Weitere Informationen finden Sie unter Tabellen in einem Dataset auflisten.
Clustering-Spezifikation ändern
Sie können die Clustering-Spezifikationen einer Tabelle ändern oder entfernen oder die Gruppe geclusterter Spalten in einer geclusterten Tabelle ändern. Diese Methode zum Aktualisieren der Gruppe von Clustering-Spalten ist nützlich für Tabellen, die kontinuierliche Streaming-Insert-Anweisungen verwenden, da diese Tabellen durch andere Methoden nicht einfach ausgetauscht werden können.
Führen Sie die folgenden Schritte aus, um eine neue Clustering-Spezifikation auf nicht partitionierte oder partitionierte Tabellen anzuwenden.
Aktualisieren Sie im bq-Tool die Clustering-Spezifikation Ihrer Tabelle, damit sie dem neuen Clustering entspricht:
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
Ersetzen Sie Folgendes:
CLUSTER_COLUMN: die Spalte, nach der Sie Cluster gruppieren, z. B.mycolumnDATASET: der Name des Datasets, das die Tabelle enthält, z. B.mydatasetORIGINAL_TABLE: der Name der ursprünglichen Tabelle, z. B.mytable
Sie können auch die API-Methode
tables.updateodertables.patchaufrufen, um die Clustering-Spezifikation zu ändern.Führen Sie die folgende
UPDATE-Anweisung aus, um alle Zeilen gemäß der neuen Clustering-Spezifikation zu clustern:UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
Nächste Schritte
- Informationen zum Abfragen geclusterter Tabellen finden Sie unter Geclusterte Tabellen abfragen.
- Einführung in partitionierte Tabellen
- Informationen zum Erstellen partitionierter Tabellen finden Sie unter Partitionierte Tabellen erstellen.