クロスリージョン データセット レプリケーション
BigQuery データセット レプリケーションを使用すると、2 つの異なるリージョンまたはマルチリージョン間でデータセットの自動レプリケーションを設定できます。
概要
BigQuery でデータセットを作成するときに、データが保存されるリージョンまたはマルチリージョンを選択します。リージョンは、地理的エリア内のデータセンターの集まりで、マルチリージョンは、複数の地理的リージョンを含む広い地理的エリアです。データは、ここに含まれているリージョンの 1 つに保存され、マルチリージョン内で複製されません。リージョンとマルチリージョンの詳細については、BigQuery のロケーションをご覧ください。
BigQuery では、データセットのロケーション内の 2 つの異なるGoogle Cloud ゾーンに、データのコピーを常に保存しています。ゾーンは、リージョン内にある Google Cloud リソースのデプロイエリアです。どのリージョンでも、ゾーン間のレプリケーションで同期二重書き込みが実行されます。マルチリージョン ロケーションを選択しても複数リージョン間のレプリケーションやリージョン冗長性は提供されないため、リージョン停止の場合にデータセットの可用性が向上することはありません。データは地理的位置内の単一リージョンに保存されます。
地理的な冗長性をさらに高めるため、任意のデータセットを複製できます。BigQuery は、指定された別のリージョンにデータセットのセカンダリ レプリカを作成します。このレプリカは、他のリージョンの 2 つのゾーン間で非同期で複製されます。ゾーンのコピーは合計で 4 つになります。
データセット レプリケーション
データセットを複製すると、BigQuery は指定されたリージョンにデータを保存します。
プライマリ リージョン。データセットを初めて作成すると、BigQuery はデータセットをプライマリ リージョンに配置します。
セカンダリ リージョン。データセットのレプリカを追加すると、BigQuery はレプリカをセカンダリ リージョンに配置します。
初期の状態では、プライマリ リージョンのレプリカがプライマリ レプリカになり、セカンダリ リージョンのレプリカがセカンダリ レプリカになります。
プライマリ レプリカは書き込み可能で、セカンダリ レプリカは読み取り専用です。プライマリ レプリカへの書き込みは、セカンダリ レプリカに非同期で複製されます。各リージョン内では、データが 2 つのゾーンに冗長的に保存されます。ネットワーク トラフィックが Google Cloud ネットワークの外部に出ることはありません。
次の図は、データセットが複製されるときに発生するレプリケーションを示しています。
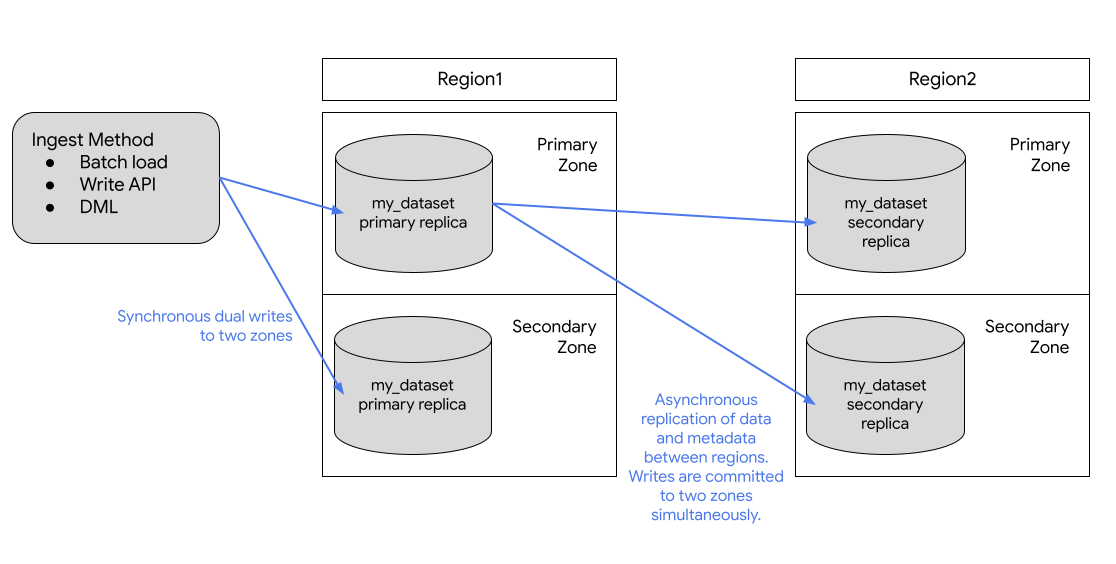
プライマリ リージョンがオンラインの場合は、セカンダリ レプリカに手動で切り替えることができます。詳細については、セカンダリ レプリカを昇格させるをご覧ください。
料金
複製されたデータセットについて、以下の費用が発生します。
- ストレージ。セカンダリ リージョンのストレージ バイトは、セカンダリ リージョンでの個別のコピーとして課金されます。BigQuery ストレージの料金をご覧ください。
- データ レプリケーション。データ レプリケーションの費用については、データ レプリケーションの料金をご覧ください。
データ レプリケーションは BigQuery によって管理され、スロットリソースは使用されません。データ レプリケーションの料金は別途請求されます。
セカンダリ リージョンのコンピューティング容量
セカンダリ リージョンのレプリカに対してジョブとクエリを実行するには、セカンダリ リージョン内のスロットを購入するか、オンデマンド クエリを実行する必要があります。
このスロットを使用して、セカンダリ レプリカから読み取り専用クエリを実行できます。セカンダリ レプリカをプライマリに昇格させると、これらのスロットを使用してレプリカへの書き込みを行うこともできます。
プライマリ リージョンと同じ数のスロットを購入することも、異なる数のスロットを購入することもできます。購入するスロットの数を減らすと、クエリのパフォーマンスに影響する可能性があります。
ロケーションに関する留意事項
データセットのレプリカを追加する前に、BigQuery に複製する初期データセットを作成する必要があります(まだ存在しない場合)。追加されたレプリカのロケーションは、レプリカの追加時に指定したロケーションに設定されます。追加するレプリカのロケーションは、初期データセットのロケーションとは別にする必要があります。データセット内のデータは、データセットが作成されたロケーションとレプリカのロケーションとの間で継続的に複製されます。ビュー、マテリアライズド ビュー、BigLake 以外の外部テーブルなど、コロケーションが必要なレプリカの場合、ソースと異なるロケーションまたはソースと互換性のないロケーションにレプリカを追加すると、ジョブエラーが発生する可能性があります。
お客様がリージョン間でデータセットを複製すると、BigQuery はレプリカが作成されたロケーションにのみデータを配置します。
コロケーションの要件
データセット レプリケーションを使用するかどうかは、次のコロケーション要件によって決まります。
Cloud Storage
Cloud Storage 上のデータをクエリするには、Cloud Storage バケットとレプリカを同じ場所に配置する必要があります。レプリカを配置する場所を決定する際は、外部テーブルのロケーションに関する考慮事項をご覧ください。
制限事項
BigQuery データセットのレプリケーションには次の制限があります。
- BigQuery Storage Write API または
tabledata.insertAllメソッドからプライマリ レプリカに書き込まれ、セカンダリ レプリカに複製されるストリーミング データはベスト エフォートであり、レプリケーションの遅延が大きくなる可能性があります。 - Datastream または BigQuery 変更データ キャプチャからプライマリ レプリカに書き込まれ、セカンダリ レプリカに複製されるストリーミング upsert はベスト エフォートであり、レプリケーションの遅延が大きくなる可能性があります。レプリケーションが完了すると、セカンダリ レプリカの upsert は、テーブルに構成された
max_staleness値に従って、セカンダリ レプリカのテーブル ベースラインに統合されます。 - 複製されたデータセット内のテーブルできめ細かい DML を有効にすることはできません。また、きめ細かい DML が有効になっているテーブルを含むデータセットをレプリケートすることもできません。
- レプリケーションとスイッチオーバーは、SQL データ定義言語(DDL)ステートメントを介して管理されます。
- リージョンまたはマルチリージョンごとに、データセットあたり 1 つのレプリカに制限されます。同じ宛先リージョンに同じデータセットのセカンダリ レプリカを 2 つ作成することはできません。
- レプリカ内のリソースには、リソースの動作で説明されている制限が適用されます。
- ポリシータグとそれに関連するデータポリシーは、セカンダリ レプリカに複製されません。元のリージョン以外のリージョンにあるポリシータグを持つ列を参照するクエリは、そのレプリカが昇格しても失敗します。
- タイムトラベルは、セカンダリ レプリカの作成が完了した後に、セカンダリ レプリカでのみ使用できます。
- データセットでクロスリージョン レプリケーションを有効にするための宛先リージョンのサイズの上限は、デフォルトでは
usとeuのマルチリージョンは 10 PB、他のリージョンは 500 TB です。これらの上限は構成可能です。詳しくは、Google Cloud サポートまでお問い合わせください。 - 割り当ては論理リソースに適用されます。
- 複製できるのは、テーブル数が 100,000 未満のデータセットのみです。
- データセットの同じリージョンに追加(その後のドロップも)できるレプリカは、1 日に 4 つまでです。
- 帯域幅の制限があります。
replica_kms_key値が構成されていない場合、顧客管理の暗号鍵(CMEK)が適用されたテーブルは、セカンダリ リージョンでクエリできません。- BigLake テーブルはサポートされていません。
- 外部データセットまたは連携データセットは複製できません。
- BigQuery Omni のロケーションはサポートされていません。
- 障害復旧用にデータ レプリケーションを構成する場合、次のリージョンペアは構成できません。
us-central1-usマルチリージョンus-west1-usマルチリージョンeu-west1-euマルチリージョンeu-west4-euマルチリージョン
- ルーティン レベルのアクセス制御は複製できませんが、ルーティンのデータセット レベルのアクセス制御は複製できます。
リソースの動作
セカンダリ レプリカ内のリソースでは、次のオペレーションはサポートされていません。
セカンダリ レプリカは読み取り専用です。セカンダリ レプリカにリソースのコピーを作成する必要がある場合は、リソースをコピーするか、最初にリソースをクエリしてから、セカンダリ レプリカの外部で結果を実現する必要があります。たとえば、CREATE TABLE AS SELECT を使用して、セカンダリ レプリカ リソースから新しいリソースを作成します。
プライマリ レプリカとセカンダリ レプリカには次の違いがあります。
| リージョン 1 プライマリ レプリカ | リージョン 2 セカンダリ レプリカ | 注 |
|---|---|---|
| BigLake テーブル | BigLake テーブル | サポートされていません。 |
| 外部テーブル | 外部テーブル | 外部テーブル定義のみが複製されます。Cloud Storage バケットがレプリカと同じロケーションに配置されていない場合、クエリは失敗します。 |
| 論理ビュー | 論理ビュー | 論理ビューと同じロケーションにないデータセットまたはリソースを参照する論理ビューは、クエリを実行すると失敗します。 |
| マネージド テーブル | マネージド テーブル | 違いはありません。 |
| マテリアライズド ビュー | マテリアライズド ビュー | 参照されるテーブルがマテリアライズド ビューと同じリージョンにない場合、クエリは失敗します。複製されたマテリアライズド ビューでは、ビューの最大ステイルネスを超えるステイルネスが発生することがあります。 |
| モデル | モデル | マネージド テーブルとして保存。 |
| リモート関数 | リモート関数 | 接続はリージョン単位です。リモート関数と同じロケーションにないデータセットまたはリソース(接続)を参照するリモート関数は、実行時に失敗します。 |
| ルーティン | ユーザー定義関数(UDF)またはストアド プロシージャ | ルーティンと同じロケーションにないデータセットまたはリソースを参照するルーティンは、実行時に失敗します。接続を参照するルーティン(リモート関数など)は、ソースリージョンの外部では機能しません。 |
| 行アクセス ポリシー | 行アクセス ポリシー | 違いはありません。 |
| 検索インデックス | 検索インデックス | 複製されません。 |
| ストアド プロシージャ | ストアド プロシージャ | ストアド プロシージャと同じロケーションにないデータセットまたはリソースを参照するストアド プロシージャは、実行時に失敗します。 |
| テーブル クローン | マネージド テーブル | セカンダリ レプリカでディープコピーとして課金 |
| テーブル スナップショット | テーブル スナップショット | セカンダリ レプリカでディープコピーとして課金 |
| テーブル値関数(TVF) | TVF | TVF と同じロケーションにないデータセットまたはリソースを参照する TVF は、実行時に失敗します。 |
| UDF | UDF | UDF と同じロケーションにないデータセットまたはリソースを参照する UDF は、実行時に失敗します。 |
停止のシナリオ
クロスリージョン レプリケーションは、リージョン全体が停止した場合の障害復旧計画として使用するものではありません。プライマリ レプリカのリージョンでリージョン全体が停止した場合、セカンダリ レプリカをプロモートすることはできません。セカンダリ レプリカは読み取り専用であるため、プライマリ レプリカのリージョンが復元されるまで、セカンダリ レプリカで書き込みジョブを実行できず、セカンダリ リージョンをプロモートすることはできません。障害復旧の準備について詳しくは、マネージド障害復旧をご覧ください。
次の表に、複製されたデータにリージョン全体の停止がどのように影響するのかを示します。
| リージョン 1 | リージョン 2 | 停止リージョン | 影響 |
|---|---|---|---|
| プライマリ レプリカ | セカンダリ レプリカ | リージョン 2 | セカンダリ レプリカに対してリージョン 2 で実行されている読み取り専用ジョブが失敗します。 |
| プライマリ レプリカ | セカンダリ レプリカ | リージョン 1 | リージョン 1 で実行されているジョブがすべて失敗します。読み取り専用ジョブは、セカンダリ レプリカが配置されているリージョン 2 で引き続き実行されます。リージョン 2 のコンテンツは、リージョン 1 と正常に同期されるまでは古くなります。 |
データセット レプリケーションを使用する
このセクションでは、データセットを複製し、セカンダリ レプリカを昇格して、セカンダリ リージョンで BigQuery 読み取りジョブを実行する方法について説明します。
必要な権限
レプリカの管理に必要な権限を取得するには、bigquery.datasets.update 権限を付与するよう管理者に依頼してください。
データセットを複製する
データセットを複製するには、ALTER SCHEMA ADD REPLICA DDL ステートメントを使用します。
リージョンまたはマルチリージョン内にまだ複製されていないデータセットには、レプリカを追加できます。レプリカを追加した後、最初のコピー オペレーションが完了するまでに時間がかかります。データのレプリケーション中も、プライマリ レプリカを参照するクエリを実行でき、クエリの処理能力は低下しません。マルチリージョンの地域内でデータを複製することはできません。
次の例では、us-central1 リージョンに my_dataset という名前のデータセットを作成し、us-east4 リージョンにレプリカを追加します。
-- Create the primary replica in the us-central1 region. CREATE SCHEMA my_dataset OPTIONS(location='us-central1'); -- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `my_replica` OPTIONS(location='us-east4');
セカンダリ レプリカが正常に作成されたことを確認するには、INFORMATION_SCHEMA.SCHEMATA_REPLICAS ビューで creation_complete 列をクエリします。
セカンダリ レプリカが作成されたら、クエリのロケーションをセカンダリ リージョンに明示的に設定してクエリを実行できます。ロケーションが明示的に設定されていない場合、BigQuery はデータセットのプライマリ レプリカのリージョンを使用します。
セカンダリ レプリカを昇格させる
プライマリ リージョンがオンラインの場合は、セカンダリ レプリカを昇格できます。昇格により、セカンダリ レプリカが書き込み可能なプライマリに切り替わります。このオペレーションは、セカンダリ レプリカがプライマリ レプリカに追いつくと数秒以内に完了します。セカンダリ レプリカが追い付かない場合、追い付くまで昇格は完了しません。プライマリを含むリージョンが停止した場合、セカンダリ レプリカをプライマリに昇格させることはできません。
次の点にご注意ください。
- 昇格の進行中は、テーブルへのすべての書き込みでエラーが返されます。昇格が開始されると、古いプライマリ レプリカへの書き込みはすぐにできなくなります。
- 昇格の開始時に完全には複製されていないテーブルは、ステイル読み取りを返します。
レプリカをプライマリ レプリカに昇格させるには、ALTER SCHEMA SET
OPTIONS DDL ステートメントを使用して primary_replica オプションを設定します。
次の点にご注意ください。クエリの設定で、ジョブのロケーションをセカンダリ リージョンに明示的に設定する必要があります。BigQuery でロケーションを指定するをご覧ください。
次の例では、us-east4 レプリカをプライマリに昇格させます。
ALTER SCHEMA my_dataset SET OPTIONS(primary_replica = 'us-east4')
セカンダリ レプリカが正常に昇格したことを確認するには、INFORMATION_SCHEMA.SCHEMATA_REPLICAS ビューで replica_primary_assignment_complete 列をクエリします。
データセットのレプリカを削除する
レプリカを削除してデータセットのレプリケーションを停止するには、ALTER SCHEMA DROP REPLICA DDL ステートメントを使用します。
次の例では、us レプリカを削除します。
ALTER SCHEMA my_dataset DROP REPLICA IF EXISTS `us`;
データセット全体を削除するには、まずセカンダリ レプリカを削除する必要があります。すべてのセカンダリ レプリカを削除せずにデータセット全体を削除すると(たとえば DROP
SCHEMA ステートメントを使用すると)、次のエラーが発生します。
The dataset replica of the cross region dataset 'project_id:dataset_id' in region 'REGION' is not yet writable because the primary assignment is not yet complete.
詳細については、セカンダリ レプリカを昇格させるをご覧ください。
データセットのレプリカを一覧表示する
プロジェクト内のデータセットのレプリカを一覧表示するには、INFORMATION_SCHEMA.SCHEMATA_REPLICAS ビューにクエリします。
データセットを移行する
クロスリージョン データセット レプリケーションを使用すると、データセットをリージョン間で移行できます。次の例は、クロスリージョン レプリケーションを使用して、既存の my_migration データセットを US マルチリージョンから EU マルチリージョンに移行するプロセスを示しています。
データセットを複製する
移行プロセスを開始するには、まず、データの移行先となるリージョンにデータセットを複製します。このシナリオでは、my_migration データセットを EU マルチリージョンに移行します。
-- Create a replica in the secondary region. ALTER SCHEMA my_migration ADD REPLICA `eu` OPTIONS(location='eu');
これにより、EU マルチリージョンに eu という名前のセカンダリ レプリカが作成されます。プライマリ レプリカは、US マルチリージョン内の my_migration データセットです。
セカンダリ レプリカを昇格させる
データセットの EU マルチリージョンへの移行を継続するため、セカンダリ レプリカを昇格させます。
ALTER SCHEMA my_migration SET OPTIONS(primary_replica = 'eu')
昇格が完了すると、eu がプライマリ レプリカになります。これは書き込み可能なレプリカです。
移行を完了する
US マルチリージョンから EU マルチリージョンへの移行を完了するには、us レプリカを削除します。この手順は必須ではありませんが、移行以外の目的ではデータセット レプリカが必要でない場合に便利です。
ALTER SCHEMA my_migration DROP REPLICA IF EXISTS us;
データセットは EU マルチリージョンに配置されており、my_migration データセットのレプリカはありません。データセットが EU マルチリージョンに正常に移行されました。移行されるリソースの一覧については、リソースの動作をご覧ください。
顧客管理の暗号鍵(CMEK)
セカンダリ レプリカを作成するときに、顧客管理の Cloud Key Management Service 鍵が自動的に複製されることはありません。複製されたデータセットで暗号化を維持するには、追加されたレプリカのロケーションに replica_kms_key を設定する必要があります。replica_kms_key は、ALTER SCHEMA ADD REPLICA DDL ステートメントを使用して設定できます。
CMEK を使用したデータセット レプリケーションは、次のように動作します。
ソース データセットに
default_kms_keyがある場合は、ALTER SCHEMA ADD REPLICADDL ステートメントを使用するときに、レプリカ データセットのリージョンで作成されたreplica_kms_keyを指定する必要があります。ソース データセットに
default_kms_keyの値が設定されていない場合、replica_kms_keyは設定できません。default_kms_keyまたはreplica_kms_keyのいずれか(または両方)で Cloud KMS 鍵のローテーションを使用している場合、複製されたデータセットは鍵のローテーション後もクエリ可能です。- プライマリ リージョンでの鍵のローテーションでは、ローテーション後に作成されたテーブルでのみ鍵バージョンが更新されます。鍵のローテーションより前に存在していたテーブルでは、ローテーション前に設定された鍵バージョンを引き続き使用します。
- セカンダリ リージョンで鍵のローテーションを行うと、セカンダリ レプリカ内のすべてのテーブルが新しい鍵バージョンに更新されます。
- プライマリ レプリカをセカンダリ レプリカに切り替えると、セカンダリ レプリカ(以前のプライマリ レプリカ)内のすべてのテーブルが新しい鍵バージョンに更新されます。
- 鍵のローテーション前にプライマリ レプリカ内のテーブルに設定された鍵バージョンが削除されると、鍵バージョンが更新されるまで、鍵のローテーション前に設定された鍵バージョンを使用しているテーブルに対してクエリを実行することはできません。鍵バージョンを更新するには、古い鍵バージョンが有効になっている(無効化または削除されていない)必要があります。
ソース データセットに
default_kms_keyの値が設定されていないものの、ソース データセット内に CMEK が適用された個々のテーブルがある場合、複製されたデータセットでこれらのテーブルをクエリすることはできません。テーブルに対してクエリを実行する手順は次のとおりです。- ソース データセットの
default_kms_key値を追加します。 ALTER SCHEMA ADD REPLICADDL ステートメントを使用して新しいレプリカを作成する場合は、replica_kms_keyオプションに値を設定します。CMEK テーブルは、宛先リージョンでクエリできます。
宛先リージョンのすべての CMEK テーブルは、ソース リージョンで使用されている鍵に関係なく、同じ
replica_kms_keyを使用します。- ソース データセットの
CMEK を使用してレプリカを作成する
次の例では、replica_kms_key 値が設定された us-west1 リージョンにレプリカを作成します。CMEK 鍵の場合は、暗号化と復号を行う BigQuery サービス アカウント権限を付与します。
-- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `us-west1` OPTIONS(location='us-west1', replica_kms_key='my_us_west1_kms_key_name');
CMEK の制限事項
CMEK が適用されたデータセットを複製する場合、次の制限があります。
レプリカの作成後に、複製された Cloud KMS 鍵を更新することはできません。
データセットのレプリカの作成後に、ソース データセットの
default_kms_key値を更新することはできません。指定された
replica_kms_keyが宛先リージョンで有効でない場合、データセットは複製されません。
次のステップ
- BigQuery 予約方法を学習する。
- BigQuery の信頼性に関する機能について学習する。