Ce document décrit deux architectures de référence permettant de créer une plate-forme d'apprentissage fédéré sur Google Cloud à l'aide de Google Kubernetes Engine (GKE). Les architectures de référence et les ressources associées qui sont décrites dans ce document sont compatibles avec les éléments suivants :
- Apprentissage fédéré intersilo
- Apprentissage fédéré inter-appareil, en s'appuyant sur l'architecture intersilo
Ce document s'adresse aux architectes cloud et aux ingénieurs en IA et ML qui souhaitent mettre en œuvre des cas d'utilisation d'apprentissage fédéré surGoogle Cloud. Il est également destiné aux décisionnaires qui évaluent s'il convient de mettre en œuvre l'apprentissage fédéré sur Google Cloud.
Architecture
Les schémas de la présente section illustrent une architecture intersilo et une architecture inter-appareils pour l'apprentissage fédéré. Pour en savoir plus sur les différentes applications pour ces architectures, consultez la section Cas d'utilisation.
Architecture intersilo
Le schéma suivant montre une architecture compatible avec l'apprentissage fédéré intersilo :

Le schéma précédent illustre un exemple simplifié d'architecture multisilo. Dans le diagramme, toutes les ressources se trouvent dans le même projet d'une organisation Google Cloud. Ces ressources incluent le modèle client local, le modèle client global et leurs charges de travail d'apprentissage fédéré associées.
Cette architecture de référence peut être modifiée pour prendre en charge plusieurs configurations de silos de données. Les membres du consortium peuvent héberger leurs silos de données de différentes manières :
- Sur Google Cloud, dans la même organisation Google Cloud et le même projet Google Cloud.
- Google CloudDans la même organisation, dans différents Google Cloud projets.Google Cloud
- Sur Google Cloud, dans différentes organisations Google Cloud .
- Dans des environnements privés, sur site ou dans d'autres clouds publics.
Pour que les membres participants puissent collaborer, ils doivent établir des canaux de communication sécurisés entre leurs environnements. Pour en savoir plus sur le rôle des membres participants à l'effort d'apprentissage fédéré, la manière dont ils collaborent et ce qu'ils partagent entre eux, consultez la page Cas d'utilisation.
L'architecture comprend les composants suivants :
- Un réseau cloud privé virtuel (VPC) et un sous-réseau.
- Un cluster GKE privé qui vous aide à effectuer les opérations suivantes :
- Isoler les nœuds de cluster d'Internet.
- Limiter l'exposition de vos nœuds de cluster et de votre plan de contrôle à Internet en créant un cluster GKE privé avec des réseaux autorisés.
- Utiliser des nœuds de cluster protégés qui utilisent une image de système d'exploitation renforcée.
- Activer Dataplane V2 pour une mise en réseau Kubernetes optimisée.
- Pools de nœuds GKE dédiés : vous créez un pool de nœuds dédié pour héberger exclusivement les applications et les ressources des locataires. Les nœuds comportent des rejets pour garantir que seules les charges de travail des locataires sont planifiées sur les nœuds locataires. Les autres ressources de cluster sont hébergées dans le pool de nœuds principal.
Chiffrement des données (activé par défaut) :
- Données au repos
- Données en transit
- Secrets de cluster au niveau de la couche d'application.
Chiffrement des données en cours d'utilisation, en activant éventuellement les nœuds Confidential Google Kubernetes Engine.
Des règles de pare-feu VPC qui appliquent les éléments suivants :
- Règles de référence qui s'appliquent à tous les nœuds du cluster.
- Règles supplémentaires qui ne s'appliquent qu'aux nœuds du pool de nœuds locataire. Ces règles de pare-feu limitent les entrées et sorties des nœuds locataires.
Cloud NAT pour autoriser la sortie vers Internet.
Des enregistrements Cloud DNS pour activer l'accès privé à Google afin que les applications du cluster puissent accéder aux API Google sans passer par Internet.
Des comptes de service, tels que répertoriés ci-dessous :
- Un compte de service dédié pour les nœuds du pool de nœuds locataire.
- Un compte de service dédié aux applications locataires à utiliser avec la fédération d'identité de charge de travail.
Compatibilité avec l'utilisation de Google Groupes pour le contrôle des accès basé sur les rôles (RBAC) dans Kubernetes.
Un dépôt Git pour stocker les descripteurs de configuration.
Un dépôt Artifact Registry pour stocker les images de conteneurs.
Config Sync et Policy Controller pour déployer la configuration et les règles.
Passerelles Cloud Service Mesh pour autoriser sélectivement le trafic entrant et sortant du cluster.
Buckets Cloud Storage pour stocker les pondérations des modèles globaux et locaux.
Accès à d'autres API Google et Google Cloud Par exemple, une charge de travail d'entraînement peut avoir besoin d'accéder à des données d'entraînement stockées dans Cloud Storage, BigQuery ou Cloud SQL.
Architecture inter-appareils
Le schéma suivant illustre une architecture compatible avec l'apprentissage fédéré entre appareils :
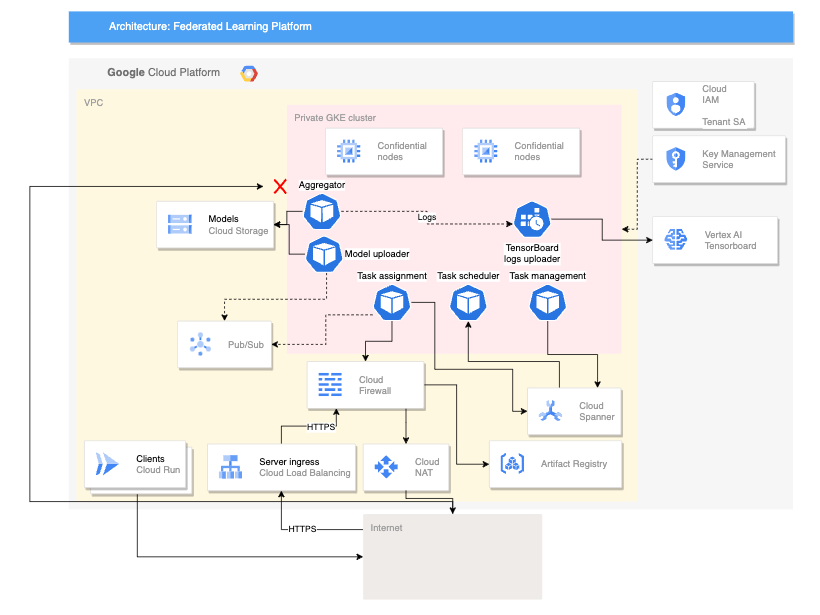
L'architecture multi-appareil précédente s'appuie sur l'architecture inter-silo avec l'ajout des composants suivants :
- Un service Cloud Run qui simule des appareils se connectant au serveur.
- Un Certificate Authority Service qui crée des certificats privés pour le serveur et les clients.
- Un TensorBoard Vertex AI pour visualiser le résultat de l'entraînement.
- Un bucket Cloud Storage pour stocker le modèle consolidé.
- Le cluster privé GKE qui utilise des nœuds confidentiels en guise de pool principal pour sécuriser les données utilisées.
L'architecture multi-appareils utilise des composants du projet FCP (Federated Compute Platform) (Open Source). Ce projet comprend les éléments suivants :
- Le code client permettant de communiquer avec un serveur et d'exécuter des tâches sur les appareils.
- Un protocole de communication client-serveur.
- Des points de connexion avec TensorFlow Federated pour définir plus facilement vos calculs fédérés.
Les composants FCP présentés dans le schéma précédent peuvent être déployés sous la forme d'un ensemble de microservices. Ces composants exercent les fonctions suivantes :
- Agrégateur : ce job lit les gradients des appareils et calcule le résultat agrégé avec la confidentialité différentielle.
- Collecteur : ce job s'exécute régulièrement pour interroger les tâches actives et les gradients chiffrés. Ces informations déterminent le début de l'agrégation.
- Importateur de modèles : ce job écoute les événements et publie les résultats afin que les appareils puissent télécharger les modèles mis à jour.
- Attribution de tâches : ce service d'interface distribue les tâches d'entraînement aux appareils.
- Gestion des tâches : ce job gère des tâches.
- Planificateur de tâches : ce job s'exécute régulièrement ou est déclenché par des événements spécifiques.
Produits utilisés
Les architectures de référence pour les deux cas d'utilisation de l'apprentissage fédéré utilisent les composants Google Cloud suivants :
- Google Cloud Kubernetes Engine (GKE) : GKE fournit la plate-forme de base pour l'apprentissage fédéré.
- TensorFlow Federated (TFF) : TFF fournit un framework Open Source pour le machine learning et pour d'autres calculs effectués sur des données décentralisées.
GKE fournit également les fonctionnalités suivantes à votre plate-forme d'apprentissage fédéré :
- Hébergement du coordinateur d'apprentissage fédéré : ce coordinateur est responsable de la gestion du processus d'apprentissage fédéré. Cette gestion inclut des tâches telles que la distribution du modèle global aux participants, l'agrégation des mises à jour des participants et la mise à jour du modèle global. GKE peut être utilisé pour héberger le coordinateur d'apprentissage fédéré de manière hautement disponible et évolutive.
- Hébergement de participants à l'apprentissage fédéré : ces participants sont chargés d'entraîner le modèle global sur leurs données locales. GKE peut être utilisé pour héberger des participants à l'apprentissage fédéré de manière sécurisée et isolée. Cette approche permet de s'assurer que les données des participants sont conservées localement.
- Mise à disposition d'un canal de communication sécurisé et évolutif : les participants à l'apprentissage fédéré doivent pouvoir communiquer avec le coordinateur d'apprentissage fédéré de manière sécurisée et évolutive. GKE peut être utilisé pour fournir un canal de communication sécurisé et évolutif entre les participants et le coordinateur.
- Gestion du cycle de vie des déploiements d'apprentissage fédéré : GKE peut être utilisé pour gérer le cycle de vie des déploiements d'apprentissage fédéré. Cette gestion inclut des tâches telles que le provisionnement des ressources, le déploiement de la plate-forme d'apprentissage fédéré et la surveillance des performances de cette plate-forme.
En plus de ces avantages, GKE fournit également un certain nombre de fonctionnalités pouvant être utiles pour les déploiements d'apprentissage fédéré, telles que :
- Clusters régionaux : GKE vous permet de créer des clusters régionaux, ce qui vous permet d'améliorer les performances des déploiements d'apprentissage fédéré en réduisant la latence entre les participants et le coordinateur.
- Règles de réseau : GKE vous permet de créer des règles de réseau afin d'améliorer la sécurité des déploiements d'apprentissage fédéré en contrôlant le flux de trafic entre les participants et le coordinateur.
- Équilibrage de charge : GKE propose un certain nombre d'options d'équilibrage de charge, ce qui permet d'améliorer l'évolutivité des déploiements d'apprentissage fédéré en répartissant le trafic entre les participants et le coordinateur.
TFF fournit les fonctionnalités suivantes pour faciliter l'implémentation des cas d'utilisation de l'apprentissage fédéré :
- Capacité à exprimer de manière déclarative les calculs fédérés, qui sont un ensemble d'étapes de traitement exécutées sur un serveur et un ensemble de clients. Ces calculs peuvent être déployés dans divers environnements d'exécution.
- Les agrégateurs personnalisés peuvent être créés à l'aide de la solution Open Source TFF.
- Compatibilité avec divers algorithmes d'apprentissage fédéré, y compris les algorithmes suivants :
- Moyenne fédérée : algorithme qui calcule la moyenne des paramètres de modèle des clients participants. Il est particulièrement bien adapté aux cas d'utilisation dans lesquels les données sont relativement homogènes et le modèle n'est pas trop complexe. Voici des cas d'utilisation types :
- Recommandations personnalisées : une entreprise peut utiliser la moyenne fédérée pour entraîner un modèle qui recommande des produits aux utilisateurs en fonction de leur historique d'achat.
- Détection des fraudes : un consortium de banques peut utiliser la moyenne fédérée pour entraîner un modèle qui détecte les transactions frauduleuses.
- Diagnostic médical : un groupe d'hôpitaux peut utiliser la moyenne fédérée pour entraîner un modèle permettant de diagnostiquer le cancer.
- Descente de gradient stochastique fédéré (FedSGD) : algorithme utilisant la descente de gradient stochastique pour mettre à jour les paramètres du modèle. Il convient parfaitement aux cas d'utilisation dans lesquels les données sont hétérogènes et le modèle complexe. Voici des cas d'utilisation types :
- Traitement du langage naturel : une entreprise peut utiliser FedSGD pour entraîner un modèle qui améliore la précision de la reconnaissance vocale.
- Reconnaissance d'images : une entreprise peut utiliser FedSGD pour entraîner un modèle capable d'identifier des objets dans des images.
- Maintenance prédictive : une entreprise peut utiliser FedSGD pour entraîner un modèle capable de prédire à quel moment une machine est susceptible de tomber en panne.
- Federated Adam : algorithme qui utilise l'optimiseur Adam pour mettre à jour les paramètres du modèle.
Voici des cas d'utilisation types :
- Systèmes de recommandation : une entreprise peut utiliser Federated Adam pour entraîner un modèle qui recommande des produits aux utilisateurs en fonction de leur historique d'achat.
- Classement : une entreprise peut utiliser Federated Adam pour entraîner un modèle de classement des résultats de recherche.
- Prédiction du taux de clics : une entreprise peut utiliser Federated Adam pour entraîner un modèle capable de prédire la probabilité qu'un utilisateur clique sur une annonce.
- Moyenne fédérée : algorithme qui calcule la moyenne des paramètres de modèle des clients participants. Il est particulièrement bien adapté aux cas d'utilisation dans lesquels les données sont relativement homogènes et le modèle n'est pas trop complexe. Voici des cas d'utilisation types :
Cas d'utilisation
Cette section décrit les cas d'utilisation pour lesquels les architectures intersilo et inter-appareils sont des choix appropriés pour votre plate-forme d'apprentissage fédéré.
L'apprentissage fédéré est une configuration de machine learning dans laquelle de nombreux clients entraînent un modèle de manière collaborative. Ce processus est dirigé par un coordinateur central. Les données d'entraînement restent décentralisées.
Dans le paradigme de l'apprentissage fédéré, les clients téléchargent un modèle global et l'améliorent en l'entraînant localement sur leurs données. Ensuite, chaque client renvoie ses mises à jour de modèle calculées au serveur central, dans lequel les mises à jour de modèle sont agrégées et une nouvelle itération du modèle global est générée. Dans ces architectures de référence, les charges de travail d'entraînement des modèles s'exécutent sur GKE.
L'apprentissage fédéré incorpore le principe de confidentialité de la minimisation des données en limitant les données collectées à chaque étape de calcul, en limitant l'accès aux données, et en traitant puis en supprimant les données le plus tôt possible. En outre, la définition du problème de l'apprentissage fédéré est compatible avec d'autres techniques de protection de la confidentialité, telles que l'utilisation de la confidentialité différentielle (DP) pour améliorer l'anonymisation du modèle afin de garantir que le modèle final ne mémorise pas les données de chaque utilisateur.
En fonction du cas d'utilisation, l'entraînement des modèles avec l'apprentissage fédéré peut présenter des avantages supplémentaires :
- Conformité : dans certains cas, les réglementations peuvent limiter la façon dont les données peuvent être utilisées ou partagées. L'apprentissage fédéré peut être utilisé pour se conformer à ces réglementations.
- Efficacité de la communication : dans certains cas, il est plus efficace d'entraîner un modèle sur des données distribuées que de centraliser les données. Par exemple, les ensembles de données sur lesquels le modèle doit être entraîné sont trop volumineux pour être déplacés et centralisés.
- Rendre les données accessibles : l'apprentissage fédéré permet aux organisations de maintenir les données d'entraînement décentralisées dans des silos de données par utilisateur ou par organisation.
- Précision du modèle plus élevée : l'entraînement sur des données utilisateur réelles (tout en garantissant la confidentialité) plutôt que sur des données synthétiques (parfois appelées données de proxy) améliore souvent la précision du modèle.
Il existe différents types d'apprentissage fédéré, caractérisés par l'origine des données et l'emplacement des calculs locaux. Les architectures décrites dans ce document se concentrent sur deux types d'apprentissage fédéré : intersilo et inter-appareils. Les autres types d'apprentissage fédéré n'entrent pas dans le cadre du présent document.
L'apprentissage fédéré est également classé selon la manière dont les ensembles de données sont partitionnés, à savoir :
- Apprentissage fédéré horizontal (HFL) : ensembles de données ayant les mêmes caractéristiques (colonnes), mais des échantillons différents (lignes). Par exemple, plusieurs hôpitaux peuvent disposer de dossiers patient ayant les mêmes paramètres médicaux, mais des populations différentes.
- Apprentissage fédéré vertical (VFL) : ensembles de données avec les mêmes échantillons (lignes), mais des caractéristiques différentes (colonnes). Par exemple, une banque et une entreprise d'e-commerce peuvent avoir des données client avec des personnes qui se chevauchent, mais des informations financières et d'achat différentes.
- Apprentissage par transfert fédéré (FTL) : chevauchement partiel des échantillons et des caractéristiques entre les ensembles de données. Par exemple, deux hôpitaux peuvent disposer de dossiers de patients concernant les mêmes personnes et des paramètres médicaux partagés, mais également des caractéristiques uniques dans chaque ensemble de données.
Dans le calcul fédéré intersilo, les membres participants sont des organisations ou des entreprises. En pratique, le nombre de membres est généralement faible (par exemple, une centaine de membres). Le calcul intersilo est généralement utilisé dans les cas où les organisations participantes disposent d'ensembles de données différents, mais où elles souhaitent entraîner un modèle partagé ou analyser des résultats agrégés sans partager leurs données brutes. Par exemple, les membres participants peuvent avoir leurs environnements dans différentes organisations Google Cloud , par exemple lorsqu'ils représentent différentes entités juridiques, ou dans la même organisationGoogle Cloud , par exemple lorsqu'ils représentent différents services de la même entité juridique.
Il est possible que les membres participants ne puissent pas considérer les charges de travail des autres membres comme des entités fiables. Par exemple, un membre participant peut ne pas avoir accès au code source d'une charge de travail d'entraînement qu'il reçoit d'un tiers, tel que le coordinateur. Étant donné qu'il ne peut pas accéder à ce code source, le membre participant ne peut pas s'assurer que la charge de travail est entièrement fiable.
Pour éviter qu'une charge de travail non approuvée accède à vos données ou ressources sans autorisation, nous vous recommandons de procéder comme suit :
- Déployez les charges de travail non approuvées dans un environnement isolé.
- N'accordez aux charges de travail non fiables que les droits d'accès et les autorisations strictement nécessaires pour effectuer les cycles d'entraînement qui leur sont attribués.
Pour vous aider à isoler les charges de travail potentiellement non fiables, ces architectures de référence mettent en œuvre des contrôles de sécurité, tels que la configuration d'espaces de noms Kubernetes isolés, où chaque espace de noms dispose d'un pool de nœuds GKE dédié. La communication entre espaces de noms et entre trafic entrant et trafic sortant du cluster sont interdits par défaut, sauf si vous remplacez explicitement ce paramètre.
Voici des exemples de cas d'utilisation de l'apprentissage fédéré intersilo :
- Détection des fraudes : l'apprentissage fédéré peut être utilisé pour entraîner un modèle de détection des fraudes sur des données réparties sur plusieurs organisations. Par exemple, un consortium de banques peut utiliser l'apprentissage fédéré pour entraîner un modèle qui détecte les transactions frauduleuses.
- Diagnostic médical : l'apprentissage fédéré peut être utilisé pour entraîner un modèle de diagnostic médical sur des données distribuées entre plusieurs hôpitaux. Par exemple, un groupe d'hôpitaux pourrait utiliser l'apprentissage fédéré pour entraîner un modèle permettant de diagnostiquer le cancer.
L'apprentissage fédéré inter-appareils est un type de calcul fédéré dans lequel les membres participants sont des appareils d'utilisateur final tels que des téléphones mobiles, des véhicules ou des appareils IoT. Le nombre de membres peut atteindre plusieurs millions, voire plusieurs dizaines de millions.
Le processus d'apprentissage fédéré inter-appareils est semblable à celui de l'apprentissage fédéré intersilo. Toutefois, vous devez également adapter l'architecture de référence afin de prendre en compte certains facteurs supplémentaires pertinents lorsque vous gérez des milliers, voire des millions d'appareils. Vous devez déployer des charges de travail d'administration pour gérer les scénarios rencontrés dans les cas d'utilisation de l'apprentissage fédéré inter-appareils. Par exemple, la nécessité de coordonner un sous-ensemble de clients qui se présentera lors de l'entraînement. L'architecture inter-appareils offre cette possibilité en vous permettant de déployer les services FCP. Ces services disposent de charges de travail comportant des points de connexion avec TFF. TFF permet d'écrire le code qui gère cette coordination.
Voici des exemples de cas d'utilisation de l'apprentissage fédéré inter-appareils :
- Recommandations personnalisées : vous pouvez utiliser l'apprentissage fédéré inter-appareils pour entraîner un modèle de recommandation personnalisé sur des données distribuées sur plusieurs appareils. Par exemple, une entreprise peut utiliser l'apprentissage fédéré pour entraîner un modèle qui recommande des produits aux utilisateurs en fonction de leur historique d'achat.
- Traitement du langage naturel : l'apprentissage fédéré peut être utilisé pour entraîner un modèle de traitement du langage naturel sur des données distribuées sur plusieurs appareils. Par exemple, une entreprise peut utiliser l'apprentissage fédéré pour entraîner un modèle qui améliore la précision de la reconnaissance vocale.
- Prédire les besoins en maintenance du véhicule : l'apprentissage fédéré peut être utilisé pour entraîner un modèle capable de prédire à quel moment un véhicule est susceptible de nécessiter une maintenance. Ce modèle peut être entraîné sur des données collectées à partir de plusieurs véhicules. Cette approche permet au modèle d'apprendre des expériences de tous les véhicules, sans compromettre la confidentialité de chaque véhicule.
Le tableau suivant récapitule les caractéristiques des architectures intersilo et inter-appareils, et vous montre comment classer le type de scénario d'apprentissage fédéré applicable à votre cas d'utilisation.
| Caractéristique | Calculs fédérés intersilo | Calculs fédérés inter-appareils |
|---|---|---|
| Taille de la population | Généralement petite (par exemple, moins d'une centaine d'appareils) | Évolutif pour prendre en charge des milliers, des millions ou des centaines de millions d'appareils |
| Membres participants | Organisations ou entreprises | Appareils mobiles, appareils de périphérie, véhicules |
| Partitionnement de données le plus courant | HFL, VFL et FTL | HFL |
| Sensibilité des données | Données sensibles que les participants ne souhaitent pas partager entre eux au format brut | Données trop sensibles pour être partagées avec un serveur central |
| Disponibilité des données | Les participants sont presque toujours disponibles | Seule une petite partie des participants est disponible à tout moment |
| Exemples de cas d'utilisation | Détection des fraudes, diagnostic médical, prévisions financières | Suivi de remise en forme, reconnaissance vocale, classification d'images |
Considérations de conception
Cette section fournit des conseils pour vous aider à utiliser cette architecture de référence afin de développer une ou plusieurs architectures répondant à vos exigences spécifiques en termes de sécurité, de fiabilité, d'efficacité opérationnelle, de coût et de performances.
Considérations de conception d'une architecture intersilo
Pour mettre en œuvre une architecture d'apprentissage fédéré intersilo dansGoogle Cloud, vous devez mettre en œuvre les conditions préalables minimales ci-dessous, qui sont expliquées plus en détail dans les sections suivantes :
- Établir un consortium d'apprentissage fédéré
- Déterminer le modèle de collaboration que le consortium d'apprentissage fédéré doit mettre en œuvre.
- Déterminer les responsabilités des organisations participantes
Outre ces conditions préalables, le propriétaire de la fédération doit effectuer d'autres actions, qui n'entrent pas dans le cadre de ce document, telles que :
- Gérer le consortium d'apprentissage fédéré.
- Concevoir et mettre en œuvre un modèle de collaboration.
- Préparer, gérer et exploiter les données d'entraînement du modèle et le modèle que le propriétaire de la fédération a l'intention d'entraîner.
- Créer, conteneuriser et orchestrer des workflows d'apprentissage fédéré.
- Déployer et gérer des charges de travail d'apprentissage fédéré.
- Configuration des canaux de communication permettant aux organisations participantes de transférer des données de manière sécurisée
Établir un consortium d'apprentissage fédéré
Un consortium d'apprentissage fédéré est le groupe d'organisations qui participent à un effort d'apprentissage fédéré intersilo. Les organisations du consortium ne partagent que les paramètres des modèles de ML. Vous pouvez chiffrer ces paramètres pour renforcer la confidentialité. Si le consortium d'apprentissage fédéré permet la pratique, les organisations peuvent également agréger des données qui ne contiennent pas d'informations personnelles.
Déterminer un modèle de collaboration pour le consortium d'apprentissage fédéré
Le consortium d'apprentissage fédéré peut mettre en œuvre différents modèles de collaboration, tels que les suivants :
- Un modèle centralisé composé d'une seule organisation de coordination, appelée propriétaire de fédération ou orchestrateur, et un ensemble de organisations participantes ou propriétaires de données.
- Un modèle décentralisé composé d'organisations qui se coordonnent en tant que groupe.
- Un modèle hétérogène composé d'un consortium d'organisations participantes variées, qui apportent toutes des ressources différentes au consortium.
Dans le présent document, nous partons du principe que le modèle de collaboration est un modèle centralisé.
Déterminer les responsabilités des organisations participantes
Après avoir choisi un modèle de collaboration pour le consortium d'apprentissage fédéré, le propriétaire de la fédération doit déterminer les responsabilités des organisations participantes.
Le propriétaire de la fédération doit également effectuer les opérations suivantes lorsqu'il commence à créer un consortium d'apprentissage fédéré :
- Coordonner l'effort d'apprentissage fédéré.
- Concevoir et mettre en œuvre le modèle de ML global et les modèles de ML à partager avec les organisations participantes
- Définissez les séries d'apprentissage fédérées : l'approche d'itération du processus d'entraînement de ML.
- Sélectionnez les organisations participantes qui participent à une série de formations fédérées donnée. Cette sélection est appelée cohorte.
- Concevez et mettez en œuvre une procédure de validation d'appartenance au consortium pour les organisations participantes.
- Mettez à jour le modèle de ML global et les modèles de ML à partager avec les organisations participantes.
- Fournissez aux organisations participantes les outils permettant de vérifier que le consortium d'apprentissage fédéré répond à leurs exigences en termes de confidentialité, de sécurité et de réglementation.
- Fournissez aux organisations participantes des canaux de communication sécurisés et chiffrés.
- Fournir aux organisations participantes toutes les données agrégées non confidentielles nécessaires à l'exécution de chaque série d'apprentissage fédéré.
Les organisations participantes assument les responsabilités suivantes :
- fournir et gérer un environnement isolé et sécurisé (un silo). Le silo est l'endroit où les organisations participantes stockent leurs propres données et où est mis en œuvre l'entraînement du modèle de ML. Les organisations participantes ne partagent pas leurs propres données avec d'autres organisations.
- Entraînez les modèles fournis par le propriétaire de la fédération à l'aide de sa propre infrastructure de calcul et de ses propres données locales.
- Partager les résultats de l'entraînement du modèle avec le propriétaire de la fédération sous la forme de données agrégées, après la suppression des informations personnelles.
Le propriétaire de la fédération et les organisations participantes peuvent utiliser Cloud Storage pour partager les modèles mis à jour et les résultats de l'entraînement.
Le propriétaire de fédération et les organisations participantes affinent l'entraînement du modèle de ML jusqu'à ce que celui-ci réponde à leurs exigences.
Mettre en œuvre l'apprentissage fédéré sur Google Cloud
Une fois que vous avez établi le consortium d'apprentissage fédéré et déterminé sa collaboration, nous recommandons aux organisations participantes d'effectuer les opérations suivantes :
- Provisionnez et configurez l'infrastructure nécessaire au consortium d'apprentissage fédéré.
- Mettez en œuvre le modèle de collaboration.
- Démarrez l'effort d'apprentissage fédéré.
Provisionner et configurer l'infrastructure pour le consortium d'apprentissage fédéré
Lors du provisionnement et de la configuration de l'infrastructure du consortium d'apprentissage fédéré, il appartient au propriétaire de la fédération de créer et de distribuer les charges de travail qui entraînent les modèles de ML fédérés aux organisations participantes. Étant donné qu'un tiers (le propriétaire de la fédération) a créé et fourni les charges de travail, les organisations participantes doivent prendre les précautions nécessaires lors du déploiement de ces charges de travail dans leurs environnements d'exécution.
Les organisations participantes doivent configurer leurs environnements en fonction de leurs bonnes pratiques de sécurité individuelles et appliquer des contrôles qui limitent le champ d'application et les autorisations accordées à chaque charge de travail. En plus de suivre leurs bonnes pratiques individuelles de sécurité, nous recommandons au propriétaire de la fédération et aux organisations participantes de prendre en compte les vecteurs de menaces spécifiques à l'apprentissage fédéré.
Mettre en œuvre le modèle de collaboration
Une fois l'infrastructure du consortium d'apprentissage fédéré préparée, le propriétaire de la fédération conçoit et met en œuvre les mécanismes permettant aux organisations participantes d'interagir entre elles. Cette approche suit le modèle de collaboration choisi par le propriétaire du consortium d'apprentissage fédéré.
Démarrer l'effort d'apprentissage fédéré
Après avoir mis en œuvre le modèle de collaboration, le propriétaire de la fédération met en œuvre le modèle de ML global à entraîner, puis les modèles de ML à partager avec l'organisation participante. Une fois ces modèles de ML prêts, le propriétaire de la fédération entame la première phase de l'effort d'apprentissage fédéré.
À chaque phase de l'effort d'apprentissage fédéré, le propriétaire de la fédération effectue les opérations suivantes :
- Distribue les modèles de ML à partager avec les organisations participantes.
- Attend que les organisations participantes fournissent les résultats de l'entraînement des modèles de ML partagés par le propriétaire de la fédération.
- Collecte et traite les résultats d'entraînement produits par les organisations participantes.
- Met à jour le modèle de ML global lors de la réception des résultats de formation appropriés des organisations participantes.
- Met à jour les modèles de ML à partager avec les autres membres du consortium, le cas échéant.
- Prépare les données d'entraînement pour la prochaine série d'apprentissage fédéré.
- Démarre la prochaine série d'apprentissage fédéré.
Sécurité, confidentialité et conformité
Cette section décrit les facteurs à prendre en compte lorsque vous utilisez cette architecture de référence pour concevoir et créer une plate-forme d'apprentissage fédéré surGoogle Cloud. Ces recommandations s'appliquent aux deux architectures décrites dans le présent document.
Les charges de travail d'apprentissage fédéré que vous déployez dans vos environnements peuvent vous exposer, vous, vos données, vos modèles d'apprentissage fédéré et votre infrastructure, à des menaces susceptibles d'avoir un impact sur votre entreprise.
Pour vous aider à renforcer la sécurité de vos environnements d'apprentissage fédéré, ces architectures de référence configurent des contrôles de sécurité GKE qui se concentrent sur l'infrastructure de vos environnements. Ces contrôles peuvent ne pas être suffisants pour vous protéger contre les menaces spécifiques à vos charges de travail d'apprentissage fédéré et à vos cas d'utilisation. Compte tenu de la spécificité de chaque charge de travail d'apprentissage fédéré et de chaque cas d'utilisation, les contrôles de sécurité visant à sécuriser l'implémentation de votre apprentissage fédéré n'entrent pas dans le cadre de ce document. Pour plus d'informations et d'exemples sur ces menaces, consultez Considérations sur la sécurité de l'apprentissage fédéré.
Contrôles de sécurité GKE
Cette section décrit les contrôles que vous appliquez avec ces architectures pour vous aider à sécuriser votre cluster GKE.
Sécurité renforcée des clusters GKE
Ces architectures de référence vous aident à créer un cluster GKE qui implémente les paramètres de sécurité suivants :
- Limiter l'exposition de vos nœuds de cluster et de votre plan de contrôle à Internet en créant un cluster GKE privé avec des réseaux autorisés.
- Utiliser des nœuds protégés qui exploitent une image de nœud renforcée avec l'environnement d'exécution
containerd. - Augmenter l'isolation des charges de travail locataires à l'aide de GKE Sandbox.
- Chiffrer les données au repos par défaut.
- Chiffrez les données en transit par défaut.
- Chiffrer les secrets de cluster au niveau de la couche d'application.
- Vous pouvez éventuellement chiffrer les données en cours d'utilisation en activant les nœuds Confidential Google Kubernetes Engine.
Pour en savoir plus sur les paramètres de sécurité GKE, consultez les pages Renforcer la sécurité d'un cluster et À propos du tableau de bord de la stratégie de sécurité.
Règles de pare-feu VPC
Les Règles de pare-feu de cloud privé virtuel (VPC) décident quel trafic est autorisé depuis ou vers des VM Compute Engine. Les règles vous permettent de filtrer le trafic au niveau de la VM, en fonction des attributs de couche 4.
Vous créez un cluster GKE avec les règles de pare-feu de cluster GKE par défaut. Ces règles de pare-feu permettent la communication entre les nœuds du cluster et le plan de contrôle GKE, ainsi qu'entre les nœuds et les pods du cluster.
Vous appliquez des règles de pare-feu supplémentaires aux nœuds du pool de nœuds locataires. Ces règles de pare-feu limitent le trafic de sortie provenant des nœuds locataires. Cette approche peut accroître l'isolation des nœuds locataires. Par défaut, l'ensemble du trafic sortant des nœuds locataires est refusé. Toute sortie requise doit être explicitement configurée. Vous pouvez par exemple créer des règles de pare-feu autorisant le trafic sortant des nœuds locataires vers le plan de contrôle GKE et les API Google en utilisant l'accès privé à Google. Les règles de pare-feu sont ciblées sur les nœuds locataires à l'aide du compte de service associé au pool de nœuds locataires.
Espaces de noms
Les espaces de noms vous permettent de définir un champ d'application pour les ressources associées au sein d'un cluster, telles que les pods, les services et les contrôleurs de réplication. Ils vous permettent également de déléguer la responsabilité de l'administration des ressources associées en tant qu'unité. Par conséquent, les espaces de noms font partie intégrante de la plupart des modèles de sécurité.
Les espaces de noms constituent une fonctionnalité importante de l'isolation du plan de contrôle. Cependant, ils ne permettent pas l'isolation des nœuds, des plans de données ou des réseaux.
Une approche courante consiste à créer des espaces de noms pour des applications individuelles. Par exemple, vous pouvez créer l'espace de noms myapp-frontend pour le composant de l'interface utilisateur d'une application.
Ces architectures de référence vous aident à créer un espace de noms dédié pour héberger les applications tierces. L'espace de noms et ses ressources sont traités comme un locataire au sein de votre cluster. Vous appliquez des règles et des contrôles à l'espace de noms pour limiter le champ d'application des ressources qu'il contient.
Règles de réseau
Les règles de réseau appliquent les flux de trafic réseau de couche 4 en se basant sur les règles de pare-feu au niveau du pod. Les règles de réseau sont appliquées à un espace de noms.
Dans les architectures de référence décrites dans le présent document, vous appliquez des règles de réseau à l'espace de noms du locataire qui héberge les applications tierces. Par défaut, la règle de réseau refuse tout trafic vers et depuis les pods de l'espace de noms. Tout trafic requis doit être explicitement ajouté à une liste d'autorisation. Par exemple, les règles de réseau dans ces architectures de référence autorisent explicitement le trafic vers les services de cluster requis, tels que le DNS interne du cluster et le plan de contrôle Cloud Service Mesh.
Config Sync
Config Sync synchronise vos clusters GKE avec les configurations stockées dans un dépôt Git. Le dépôt Git sert de source unique d'informations pour la configuration et les règles de votre cluster. Config Sync est déclaratif. Il vérifie en permanence l'état du cluster et applique l'état déclaré dans le fichier de configuration afin d'appliquer les règles, ce qui permet d'éviter les écarts de configuration.
Vous devez installer Config Sync dans votre cluster GKE. Vous configurez Config Sync pour synchroniser les configurations et les règles de cluster à partir d'un dépôt Cloud Source Repository. Les ressources synchronisées incluent les éléments suivants :
- Configuration de Cloud Service Mesh au niveau du cluster
- Règles de sécurité au niveau du cluster
- Configuration et règles au niveau de l'espace de noms locataire, y compris les règles de réseau, les comptes de service, les règles RBAC et la configuration de Cloud Service Mesh
Policy Controller
Policy Controller de l'édition Enterprise de Google Kubernetes Engine (GKE) est un contrôleur d'admission dynamique pour Kubernetes qui applique des stratégies basées sur CustomResourceDefinition (basées sur CRD) exécutées par l'agent OPA (Open Policy Agent).
Les contrôleurs d'admission sont des plug-ins Kubernetes qui interceptent les requêtes adressées au serveur d'API Kubernetes avant la persistance d'un objet, mais après l'authentification et l'autorisation de la requête. Les contrôleurs d'admission peuvent vous servir à limiter l'utilisation d'un cluster.
Vous devez installer Policy Controller dans votre cluster GKE. Ces architectures de référence incluent des exemples de règles permettant de sécuriser votre cluster. Vous appliquez automatiquement les règles à votre cluster à l'aide de Config Sync. Vous appliquez les règles suivantes :
- Règles sélectionnées pour appliquer la sécurité des pods. Par exemple, vous appliquez des règles qui empêchent les pods d'exécuter des conteneurs privilégiés et qui nécessitent un système de fichiers racine en lecture seule.
- Règles de la bibliothèque de modèles Policy Controller. Par exemple, vous appliquez une règle qui désactive les services de type NodePort.
Cloud Service Mesh
Cloud Service Mesh est un maillage de services qui vous aide à simplifier la gestion des communications sécurisées entre les services. Ces architectures de référence configurent Cloud Service Mesh de sorte qu'il effectue les opérations suivantes :
- Injecter automatiquement des proxys side-car.
- Appliquer la communication mTLS entre les services du réseau maillé.
- Limiter le trafic sortant du réseau maillé aux hôtes connus uniquement.
- Limiter le trafic entrant provenant uniquement de certains clients.
- Vous permettre de configurer des règles de sécurité réseau basées sur l'identité du service plutôt que sur l'adresse IP des pairs sur le réseau.
- Limiter la communication autorisée entre les services du réseau maillé. Par exemple, les applications de l'espace de noms du locataire ne sont autorisées à communiquer qu'avec les applications du même espace de noms, ou avec un ensemble d'hôtes externes connus.
- Acheminer tout le trafic entrant et sortant via des passerelles de maillage sur lesquelles vous pouvez appliquer d'autres contrôles du trafic.
- Permet une communication sécurisée entre les clusters.
Rejets et affinités de nœuds
Les rejets de nœuds et l'affinité de nœud sont des mécanismes de Kubernetes qui vous permettent d'influencer la planification des pods sur les nœuds de cluster.
Les nœuds rejetés suppriment les pods. Kubernetes ne programme pas un pod sur un nœud rejeté, sauf si celui-ci dispose d'une tolérance pour ce rejet. Vous pouvez utiliser des rejets de nœuds pour réserver l'utilisation des nœuds à certaines charges de travail ou locataires. Les rejets et les tolérances sont souvent utilisés dans les clusters mutualisés. Pour en savoir plus, consultez la documentation sur les nœuds dédiés avec rejets et tolérances.
L'affinité de nœuds vous permet de limiter les pods aux nœuds portant des libellés spécifiques. Si un pod a une exigence d'affinité de nœud, Kubernetes ne le planifie pas, sauf si le nœud possède un libellé qui correspond à cette affinité. Vous pouvez utiliser l'affinité de nœuds pour vous assurer que les pods sont programmés sur les nœuds appropriés.
Vous pouvez utiliser des rejets de nœuds et l'affinité de nœuds ensemble pour vous assurer que les pods de charge de travail locataires sont exclusivement programmés sur des nœuds réservés au locataire.
Ces architectures de référence vous aident à contrôler la planification des applications locataires de différentes manières :
- Créer un pool de nœuds GKE dédié au locataire. Chaque nœud du pool possède un rejet associé au nom du locataire.
- Application automatique de la tolérance et de l'affinité de nœuds appropriées à tout pod ciblant l'espace de noms du locataire. Vous appliquez la tolérance et l'affinité à l'aide des mutations PolicyContrôller.
Moindre privilège
Une bonne pratique de sécurité consiste à adopter un principe du moindre privilège pour vos projets et ressourcesGoogle Cloud tels que les clusters GKE. Avec cette approche, les applications qui s'exécutent dans votre cluster, ainsi que les développeurs et les opérateurs qui l'utilisent, ne disposent que de l'ensemble minimal d'autorisations requis.
Ces architectures de référence vous aident à utiliser les comptes de service du moindre privilège de différentes manières :
- Chaque pool de nœuds GKE reçoit son propre compte de service. Par exemple, les nœuds du pool de nœuds locataires utilisent un compte de service dédié à ces nœuds. Les comptes de service de nœud sont configurés avec les autorisations minimales requises.
- Le cluster utilise Workload Identity Federation for GKE pour associer les comptes de service Kubernetes aux comptes de service Google. De cette manière, les applications locataires peuvent disposer d'un accès limité à toutes les API Google requises sans télécharger ni stocker de clé de compte de service. Par exemple, vous pouvez autoriser le compte de service à lire les données d'un bucket Cloud Storage.
Ces architectures de référence vous aident à restreindre l'accès aux ressources du cluster de différentes manières :
- Vous créez un exemple de rôle Kubernetes RBAC doté d'autorisations limitées pour gérer les applications. Vous pouvez attribuer ce rôle aux utilisateurs et aux groupes qui gèrent les applications dans l'espace de noms du locataire. En appliquant ce rôle limité aux utilisateurs et groupes, ces utilisateurs ne disposent que des autorisations nécessaires pour modifier les ressources d'application dans l'espace de noms du locataire. Ils ne disposent pas des autorisations nécessaires pour modifier les ressources au niveau du cluster ou les paramètres de sécurité sensibles tels que les règles Cloud Service Mesh.
Autorisation binaire
L'autorisation binaire vous permet d'appliquer des stratégies que vous définissez concernant les images de conteneurs déployées dans votre environnement GKE. L'autorisation binaire n'autorise que le déploiement des images de conteneurs conformes aux stratégies que vous avez définies. Il interdit le déploiement de toute autre image de conteneur.
Dans cette architecture de référence, l'autorisation binaire est activée avec sa configuration par défaut. Pour inspecter la configuration par défaut de l'autorisation binaire, consultez la page Exporter le fichier YAML de stratégie.
Pour plus d'informations sur la configuration des règles, consultez les conseils spécifiques suivants :
- Google Cloud CLI
- Google Cloud console
- L'API REST
- Ressource Terraform
google_binary_authorization_policy
Validation des attestations inter-organisations
Vous pouvez utiliser l'autorisation binaire pour valider les attestations générées par un signataire tiers. Par exemple, dans un cas d'utilisation d'apprentissage fédéré entre silo, vous pouvez valider les attestations créées par une autre organisation participante.
Pour valider les attestations créées par un tiers, procédez comme suit :
- Recevez les clés publiques utilisées par le tiers pour créer les attestations que vous devez valider.
- Créez les certificateurs pour valider les attestations.
- Ajoutez les clés publiques que vous avez reçues du tiers aux certificateurs que vous avez créés.
Pour en savoir plus sur la création de certificateurs, consultez les conseils spécifiques suivants :
- Google Cloud CLI
- Google Cloud console
- l'API REST ;
- la ressource Terraform
google_binary_authorization_attestor
Considérations relatives à la sécurité pour l'apprentissage fédéré
Malgré son modèle strict de partage de données, l'apprentissage fédéré n'est pas intrinsèquement sécurisé contre toutes les attaques ciblées. Vous devez prendre ces risques en compte lorsque vous déployez l'une des architectures décrites dans ce document. Il existe également le risque de fuites d'informations inattendues sur les modèles de ML ou les données d'entraînement de modèle. Par exemple, un pirate pourrait compromettre intentionnellement le modèle de ML global ou les cycles d'apprentissage fédéré, ou exécuter une attaque par minutage (un type d'attaque de canal secondaire) pour recueillir des informations sur la taille des ensembles de données d'entraînement.
Les menaces les plus courantes contre une implémentation d'apprentissage fédéré sont les suivantes :
- Mémorisation de données d'entraînement intentionnelle ou involontaire. L'implémentation de votre apprentissage fédéré ou un pirate informatique peut stocker intentionnellement ou involontairement des données de manière difficile à travailler. Un pirate informatique pourrait être en mesure de collecter des informations sur le modèle de ML global ou sur les cycles passés de l'effort d'apprentissage fédéré en effectuant une ingénierie inverse des données stockées.
- Extraire des informations des mises à jour du modèle global de ML. Au cours de l'effort d'apprentissage fédéré, un pirate informatique peut effectuer une rétro-ingénierie des mises à jour du modèle de ML global que le propriétaire de la fédération collecte auprès des organisations et des appareils participants.
- Le propriétaire de la fédération peut compromettre les séries d'appels. Le propriétaire d'une fédération compromise peut contrôler un silo frauduleux et lancer une série d'efforts d'apprentissage fédéré. À la fin de la série, le propriétaire de la fédération compromise pourrait être en mesure de collecter des informations sur les mises à jour qu'il collecte de manière légitime auprès des organisations et des appareils participants en comparant ces mises à jour à celles produites par le silo malveillant.
- Les organisations et les appareils participants peuvent compromettre le modèle de ML global. Au cours de l'effort d'apprentissage fédéré, un pirate informatique peut tenter d'affecter de manière malveillante les performances, la qualité ou l'intégrité du modèle de ML global en produisant des mises à jour malveillantes ou sans conséquences.
Pour atténuer l'impact des menaces décrites dans cette section, nous vous recommandons de respecter les bonnes pratiques suivantes :
- Régler le modèle pour réduire au minimum la mémorisation des données d'entraînement.
- Mettre en œuvre des mécanismes visant à protéger la vie privée.
- Auditer régulièrement le modèle de ML global, les modèles de ML que vous souhaitez partager, les données d'entraînement et l'infrastructure que vous avez mise en œuvre pour atteindre vos objectifs d'apprentissage fédéré.
- Mettre en œuvre un algorithme d'agrégation sécurisée pour traiter les résultats d'entraînement produits par les organisations participantes.
- Générer et distribuer de manière sécurisée des clés de chiffrement de données à l'aide d'une infrastructure à clé publique.
- Déployer une infrastructure sur une plate-forme d'informatique confidentielle.
Les propriétaires de fédération doivent également effectuer les étapes supplémentaires suivantes :
- Vérifier l'identité de chaque organisation participante et l'intégrité de chaque silo dans le cas d'architectures intersilos, ainsi que l'identité et l'intégrité de chaque appareil dans le cas d'architectures inter-appareils.
- Limiter la portée des mises à jour au modèle global de ML que les organisations et les appareils participants peuvent produire.
Fiabilité
Cette section décrit les facteurs de conception à prendre en compte lorsque vous utilisez l'une des architectures de référence de ce document pour concevoir et créer une plate-forme d'apprentissage fédéré sur Google Cloud.
Lorsque vous concevez votre architecture d'apprentissage fédéré sur Google Cloud, nous vous recommandons de suivre les instructions de cette section pour améliorer la disponibilité et l'évolutivité de la charge de travail, et pour rendre votre architecture résiliente aux pannes et aux sinistres.
GKE : GKE accepte plusieurs types de clusters que vous pouvez adapter aux exigences de disponibilité de vos charges de travail et à votre budget. Par exemple, vous pouvez créer des clusters régionaux qui répartissent le plan de contrôle et les nœuds sur plusieurs zones d'une même région, ou des clusters zonaux dont le plan de contrôle et les nœuds se trouvent dans une seule zone. Les architectures de référence intersilo et inter-appareils reposent sur des clusters GKE régionaux. Pour en savoir plus sur les aspects à prendre en compte lors de la création de clusters GKE, consultez la page Choix de configuration des clusters.
En fonction du type de cluster, ainsi que de la répartition du plan de contrôle et des nœuds du cluster entre les régions et les zones, GKE offre différentes fonctionnalités de reprise après sinistre pour protéger vos charges de travail contre les pannes zonales et régionales. Pour en savoir plus sur les fonctionnalités de reprise après sinistre de GKE, consultez la page Concevoir une solution de reprise après sinistre pour les pannes d'infrastructures cloud : Google Kubernetes Engine.
Google Cloud Load Balancing : GKE accepte plusieurs méthodes d'équilibrage de charge du trafic vers vos charges de travail. Les implémentations GKE des API Kubernetes Gateway et Kubernetes Service vous permettent de provisionner et de configurer automatiquement Cloud Load Balancing pour exposer de manière sécurisée et fiable les charges de travail s'exécutant dans vos clusters GKE.
Dans ces architectures de référence, tout le trafic d'entrée et de sortie passe par des passerelles Cloud Service Mesh. Ces passerelles vous permettent de contrôler étroitement la manière dont le trafic circule à l'intérieur et à l'extérieur de vos clusters GKE.
Défis de fiabilité pour l'apprentissage fédéré inter-appareils
L'apprentissage fédéré inter-appareils présente un certain nombre de problèmes de fiabilité qui ne sont pas rencontrés dans les scénarios intersilos. En voici quelques-unes :
- Connectivité de l'appareil peu fiable ou intermittente
- Stockage limité sur l'appareil
- Ressources de calcul et de mémoire limitées
Une connectivité peu fiable peut entraîner des problèmes tels que les suivants :
- Mises à jour obsolètes et divergences de modèles : lorsque les appareils rencontrent une connectivité intermittente, les mises à jour de leur modèle local peuvent devenir obsolètes, représentant des informations obsolètes par rapport à l'état actuel du modèle global. L'agrégation de mises à jour non actualisées peut entraîner une divergence du modèle, où le modèle global s'écarte de la solution optimale en raison d'incohérences dans le processus d'entraînement.
- Contributions déséquilibrées et modèles biaisés : une communication intermittente peut entraîner une répartition inégale des contributions des appareils participants. Les appareils disposant d'une mauvaise connectivité peuvent concourir à une baisse du nombre de mises à jour, ce qui entraîne une représentation déséquilibrée de la distribution des données sous-jacente. Ce déséquilibre peut biaiser le modèle global lié aux données d'appareils disposant de connexions plus fiables.
- Augmentation de la surcharge de communication et de la consommation d'énergie : une communication intermittente peut entraîner une augmentation des coûts de communication, car les appareils peuvent avoir besoin de renvoyer des mises à jour perdues ou corrompues. Ce problème peut également augmenter la consommation d'énergie des appareils, en particulier ceux dont l'autonomie de batterie est limitée, car ils peuvent avoir besoin de maintenir des connexions actives plus longtemps pour garantir une transmission réussie des mises à jour.
Pour atténuer certains des effets causés par la communication intermittente, les architectures de référence du présent document peuvent être utilisées avec le FCP.
Une architecture système qui exécute le protocole FCP peut être conçue pour répondre aux exigences suivantes :
- Gérer les cycles de longue durée.
- Activer l'exécution spéculative (les séries peuvent commencer avant que le nombre de clients requis ne soit rassemblé en prévision de davantage de vérification suffisamment rapidement).
- Permettre aux appareils de choisir les tâches auxquelles ils souhaitent participer. Cette approche peut activer des fonctionnalités telles que l'échantillonnage sans remplacement, qui est une stratégie d'échantillonnage où chaque unité d'échantillon d'une population n'a qu'une seule chance d'être sélectionnée. Cette approche permet d'atténuer les contributions déséquilibrées et les modèles biaisés
- Extensible pour des techniques d'anonymisation telles que la confidentialité différentielle (DP) et l'agrégation de confiance (TAG).
Pour atténuer les limitations des capacités de stockage et de calcul des appareils, les techniques suivantes peuvent vous aider :
- Comprendre quelle est la capacité maximale disponible pour exécuter le calcul d'apprentissage fédéré.
- Comprendre la quantité de données pouvant être conservées à un moment donné.
- Concevoir le code d'apprentissage fédéré côté client pour qu'il s'adapte aux ressources de calcul et de mémoire RAM disponibles sur les clients.
- Comprendre les implications d'un manque d'espace de stockage et mettre en œuvre un processus pour gérer cela.
Optimisation des coûts
Cette section fournit des conseils pour optimiser le coût de création et d'exécution de la plate-forme d'apprentissage fédéré sur Google Cloud que vous établissez à l'aide de la présente architecture de référence. Ces recommandations s'appliquent aux deux architectures décrites dans le présent document.
L'exécution de charges de travail sur GKE peut vous aider à optimiser les coûts de votre environnement en provisionnant et en configurant vos clusters en fonction des besoins en ressources de vos charges de travail. Cela permet également d'activer des fonctionnalités qui reconfigurent vos clusters et vos nœuds de cluster de manière dynamique, telles que le scaling automatique des nœuds et des pods des clusters, et le redimensionnement des clusters.
Pour plus d'informations sur l'optimisation du coût de vos environnements GKE, consultez la page Bonnes pratiques pour l'exécution d'applications Kubernetes à coût maîtrisé sur GKE.
Efficacité opérationnelle
Cette section décrit les facteurs à prendre en compte pour optimiser l'efficacité lorsque vous utilisez cette architecture de référence pour créer et exécuter une plate-forme d'apprentissage fédéré sur Google Cloud. Ces recommandations s'appliquent aux deux architectures décrites dans le présent document.
Pour améliorer l'automatisation et la surveillance de votre architecture d'apprentissage fédéré, nous vous recommandons d'adopter les principes MLOps, qui sont des principes DevOps dans le contexte des systèmes de machine learning. Appliquer le MLOps signifie que vous ciblez l'automatisation et la surveillance à toutes les étapes de la construction d'un système de ML, y compris l'intégration, les tests, la publication, le déploiement et la gestion de l'infrastructure. Pour en savoir plus sur le MLOps, consultez la page MLOps : Pipelines de livraison continue et d'automatisation dans le cadre du machine learning.
Optimisation des performances
Cette section décrit les facteurs à prendre en compte pour optimiser les performances de vos charges de travail lorsque vous utilisez cette architecture de référence pour créer et exécuter une plate-forme d'apprentissage fédéré sur Google Cloud. Ces recommandations s'appliquent aux deux architectures décrites dans le présent document.
GKE accepte plusieurs fonctionnalités pour redimensionner et faire évoluer automatiquement et manuellement votre environnement GKE afin de répondre aux exigences de vos charges de travail, tout en vous aidant à éviter le surprovisionnement des ressources. Par exemple, vous pouvez utiliser l'outil de recommandation pour générer des insights et des recommandations afin d'optimiser votre utilisation des ressources GKE.
Lorsque vous envisagez de faire évoluer votre environnement GKE, nous vous recommandons de concevoir des plans à court, moyen et long terme en fonction de la manière dont vous souhaitez faire évoluer vos environnements et charges de travail. Par exemple, comment comptez-vous développer votre empreinte GKE dans quelques semaines, mois et années ? Préparer un plan vous aide à tirer le meilleur parti des fonctionnalités d'évolutivité fournies par GKE, à optimiser vos environnements GKE et à réduire les coûts. Pour en savoir plus sur la planification de l'évolutivité des clusters et des charges de travail, consultez la page À propos de l'évolutivité de GKE.
Pour améliorer les performances de vos charges de travail de ML, vous pouvez adopter les Cloud Tensor Processing Units (Cloud TPU), des accélérateurs d'IA conçus par Google qui sont optimisés pour l'entraînement et l'inférence de grands modèles d'IA.
Déploiement
Pour déployer les architectures de référence intersilo et inter-appareils décrites dans ce document, consultez le dépôt GitHub Apprentissage fédéré sur Google Cloud.
Étapes suivantes
- Découvrez comment mettre en œuvre vos algorithmes d'apprentissage fédéré sur la plate-forme TensorFlow Federated.
- En savoir plus sur les avancées et les problèmes ouverts dans l'apprentissage fédéré.
- Documentez-vous sur l'apprentissage fédéré sur le blog Google AI.
- Regardez comment Google utilise la confidentialité lors de l'utilisation de l'apprentissage fédéré avec des informations agrégées anonymisées pour améliorer les modèles de ML.
- Consultez la page Vers l'apprentissage fédéré à grande échelle.
- Découvrez comment mettre en œuvre un pipeline MLOps pour gérer le cycle de vie des modèles de machine learning.
- Pour obtenir une présentation des principes et des recommandations d'architecture spécifiques aux charges de travail d'IA et de ML dans Google Cloud, consultez la perspective de l'IA et du ML dans le framework Well-Architected.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.
Contributeurs
Auteurs :
- Grace Mollison | Responsable des solutions
- Marco Ferrari | Architecte de solutions cloud
Autres contributeurs :
- Chloé Kiddon | Ingénieur logiciel et manager
- Laurent Grangeau | Architecte de solutions
- Lilian Felix | Ingénieur cloud
- Christiane Peters | Architecte en sécurité cloud