This document describes the overall architecture of a machine learning (ML) system using TensorFlow Extended (TFX) libraries. It also discusses how to set up a continuous integration (CI), continuous delivery (CD), and continuous training (CT) for the ML system using Cloud Build and Vertex AI Pipelines.
In this document, the terms ML system and ML pipeline refer to ML model training pipelines, rather than model scoring or prediction pipelines.
This document is for data scientists and ML engineers who want to adapt their CI/CD practices to move ML solutions to production on Google Cloud, and who want to help ensure the quality, maintainability, and adaptability of their ML pipelines.
This document covers the following topics:
- Understanding CI/CD and automation in ML.
- Designing an integrated ML pipeline with TFX.
- Orchestrating and automating the ML pipeline using Vertex AI Pipelines.
- Setting up a CI/CD system for the ML pipeline using Cloud Build.
MLOps
To integrate an ML system in a production environment, you need to orchestrate the steps in your ML pipeline. In addition, you need to automate the execution of the pipeline for the continuous training of your models. To experiment with new ideas and features, you need to adopt CI/CD practices in the new implementations of the pipelines. The following sections give a high-level overview of CI/CD and CT in ML.
ML pipeline automation
In some use cases, the manual process of training, validating, and deploying ML models can be sufficient. This manual approach works if your team manages only a few ML models that aren't retrained or aren't changed frequently. In practice, however, models often break down when deployed in the real world because they fail to adapt to changes in the dynamics of environments, or the data that describes such dynamics.
For your ML system to adapt to such changes, you need to apply the following MLOps techniques:
- Automate the execution of the ML pipeline to retrain new models on new data to capture any emerging patterns. CT is discussed later in this document in the ML with Vertex AI Pipelines section.
- Set up a continuous delivery system to frequently deploy new implementations of the entire ML pipeline. CI/CD is discussed later in this document in the CI/CD setup for ML on Google Cloud section.
You can automate the ML production pipelines to retrain your models with new data. You can trigger your pipeline on demand, on a schedule, on the availability of new data, on model performance degradation, on significant changes in the statistical properties of the data, or based on other conditions.
CI/CD pipeline compared to CT pipeline
The availability of new data is one trigger to retrain the ML model. The availability of a new implementation of the ML pipeline (including new model architecture, feature engineering, and hyperparameters) is another important trigger to re-execute the ML pipeline. This new implementation of the ML pipeline serves as a new version of the model prediction service, for example, a microservice with a REST API for online serving. The difference between the two cases is as follows:
- To train a new ML model with new data, the previously deployed CT pipeline is executed. No new pipelines or components are deployed; only a new prediction service or newly trained model is served at the end of the pipeline.
- To train a new ML model with a new implementation, a new pipeline is deployed through a CI/CD pipeline.
To deploy new ML pipelines quickly, you need to set up a CI/CD pipeline. This pipeline is responsible for automatically deploying new ML pipelines and components when new implementations are available and approved for various environments (such as development, test, staging, pre-production, and production).
The following diagram shows the relationship between the CI/CD pipeline and the ML CT pipeline.

Figure 1. CI/CD and ML CT pipelines.
The output for these pipelines is as follows:
- If given new implementation, a successful CI/CD pipeline deploys a new ML CT pipeline.
- If given new data, a successful CT pipeline trains a new model and deploys it as a prediction service.
Designing a TFX-based ML system
The following sections discuss how to design an integrated ML system using TensorFlow Extended (TFX) to set up a CI/CD pipeline for the ML system. Although there are several frameworks for building ML models, TFX is an integrated ML platform for developing and deploying production ML systems. A TFX pipeline is a sequence of components that implement an ML system. This TFX pipeline is designed for scalable, high-performance ML tasks. These tasks include modeling, training, validation, serving inference, and managing deployments. The key libraries of TFX are as follows:
- TensorFlow Data Validation (TFDV): Used for detecting anomalies in the data.
- TensorFlow Transform (TFT): Used for data preprocessing and feature engineering.
- TensorFlow Estimators and Keras: Used for building and training ML models.
- TensorFlow Model Analysis (TFMA): Used for ML model evaluation and analysis.
- TensorFlow Serving (TFServing): Used for serving ML models as REST and gRPC APIs.
TFX ML system overview
The following diagram shows how the various TFX libraries are integrated to compose an ML system.

Figure 2. A typical TFX-based ML system.
Figure 2 shows a typical TFX-based ML system. The following steps can be completed manually or by an automated pipeline:
- Data extraction: The first step is to extract the new training data from its data sources. The outputs of this step are data files that are used for training and evaluating the model.
- Data validation: TFDV validates the data against the expected (raw) data schema. The data schema is created and fixed during the development phase, before system deployment. The data validation steps detect anomalies related to both data distribution and schema skews. The outputs of this step are the anomalies (if any) and a decision on whether to execute downstream steps or not.
- Data transformation: After the data is validated, the data is split and
prepared for the ML task by performing data transformations and feature
engineering operations using TFT. The outputs of this step are data files to
train and evaluate the model, usually transformed in
TFRecordsformat. In addition, the transformation artifacts that are produced help with constructing the model inputs and embed the transformation process in the exported saved model after training. - Model training and tuning: To implement and train the ML model, use the
tf.KerasAPI with the transformed data produced by the previous step. To select the parameter settings that lead to the best model, you can use Keras tuner, a hyperparameter tuning library for Keras. Alternatively, you can use other services like Katib, Vertex AI Vizier, or the hyperparameter tuner from Vertex AI. The output of this step is a saved model that is used for evaluation, and another saved model that is used for online serving of the model for prediction. - Model evaluation and validation: When the model is exported after the training step, it's evaluated on a test dataset to assess the model quality by using TFMA. TFMA evaluates the model quality as a whole, and identifies which part of the data model isn't performing. This evaluation helps guarantee that the model is promoted for serving only if it satisfies the quality criteria. The criteria can include fair performance on various data subsets (for example, demographics and locations), and improved performance compared to previous models or a benchmark model. The output of this step is a set of performance metrics and a decision on whether to promote the model to production.
- Model serving for prediction: After the newly trained model is validated, it's deployed as a microservice to serve online predictions by using TensorFlow Serving. The output of this step is a deployed prediction service of the trained ML model. You can replace this step by storing the trained model in a model registry. Subsequently a separate model serving CI/CD process is launched.
For an example on how to use the TFX libraries, see the official TFX Keras Component tutorial.
TFX ML system on Google Cloud
In a production environment, the components of the system have to run at scale on a reliable platform. The following diagram shows how each step of the TFX ML pipeline runs using a managed service on Google Cloud, which ensures agility, reliability, and performance at a large scale.

Figure 3. TFX-based ML system on Google Cloud.
The following table describes the key Google Cloud services shown in figure 3:
| Step | TFX Library | Google Cloud service |
|---|---|---|
| Data extraction and validation | TensorFlow Data Validation | Dataflow |
| Data transformation | TensorFlow Transform | Dataflow |
| Model training and tuning | TensorFlow | Vertex AI Training |
| Model evaluation and validation | TensorFlow Model Analysis | Dataflow |
| Model serving for predictions | TensorFlow Serving | Vertex AI Inference |
| Model Storage | N/A | Vertex AI Model Registry |
- Dataflow
is a fully managed, serverless, and reliable service for running
Apache Beam
pipelines at scale on Google Cloud. Dataflow
is used to scale the following processes:
- Computing the statistics to validate the incoming data.
- Performing data preparation and transformation.
- Evaluating the model on a large dataset.
- Computing metrics on different aspects of the evaluation dataset.
- Cloud Storage
is a highly available and durable storage for binary large objects.
Cloud Storage hosts artifacts produced
throughout the execution of the ML pipeline, including the following:
- Data anomalies (if any)
- Transformed data and artifacts
- Exported (trained) model
- Model evaluation metrics
- Vertex AI Training is a managed service to train ML models at scale. You can execute model training jobs with pre-build containers for TensorFlow, Scikit learn, XGBoost and PyTorch. You can also run any framework using your own custom containers. For your training infrastructure you can use accelerators and multiple nodes for distributed training. In addition, a scalable, Bayesian optimization-based service for a hyperparameter tuning is available
- Vertex AI Inference is a managed service to run batch predictions using your trained models and online predictions by deploying your models as a microservice with a REST API. The service also integrates with Vertex Explainable AI and Vertex AI Model Monitoring to understand your models and receive alerts when there is a feature or feature attribution skew and drift.
- Vertex AI Model Registry lets you manage the lifecycle of your ML models. You can version your imported models and view their performance metrics. A model can then be used for batch predictions or deploy your model for online serving using Vertex AI Inference
Orchestrating the ML system using Vertex AI Pipelines
This document has covered how to design a TFX-based ML system, and how to run each component of the system at scale on Google Cloud. However, you need an orchestrator in order to connect these different components of the system together. The orchestrator runs the pipeline in a sequence, and automatically moves from one step to another based on the defined conditions. For example, a defined condition might be executing the model serving step after the model evaluation step if the evaluation metrics meet predefined thresholds. Steps can also run in parallel in order to save time, for example validate the deployment infrastructure and evaluate the model. Orchestrating the ML pipeline is useful in both the development and production phases:
- During the development phase, orchestration helps the data scientists to run the ML experiment, instead of manually executing each step.
- During the production phase, orchestration helps automate the execution of the ML pipeline based on a schedule or certain triggering conditions.
ML with Vertex AI Pipelines
Vertex AI Pipelines is a Google Cloud managed service that lets you orchestrate and automate ML pipelines where each component of the pipeline can run containerized on Google Cloud or other cloud platforms. Pipeline parameters and artifacts generated are automatically stored on Vertex ML Metadata which allows lineage and execution tracking. Vertex AI Pipelines service consists of the following:
- A user interface for managing and tracking experiments, jobs, and runs.
- An engine for scheduling multistep ML workflows.
- A Python SDK for defining and manipulating pipelines and components.
- Integration with Vertex ML Metadata to save information about executions, models, datasets, and other artifacts.
The following constitutes a pipeline executed on Vertex AI Pipelines:
- A set of containerized ML tasks, or components. A pipeline component is self-contained code that is packaged as a Docker image. A component performs one step in the pipeline. It takes input arguments and produces artifacts.
- A specification of the sequence of the ML tasks, defined through a Python domain-specific language (DSL). The topology of the workflow is implicitly defined by connecting the outputs of an upstream step to the inputs of a downstream step. A step in the pipeline definition invokes a component in the pipeline. In a complex pipeline, components can execute multiple times in loops, or they can be executed conditionally.
- A set of pipeline input parameters, whose values are passed to the components of the pipeline, including the criteria for filtering data and where to store the artifacts that the pipeline produces.
The following diagram shows a sample graph of Vertex AI Pipelines.
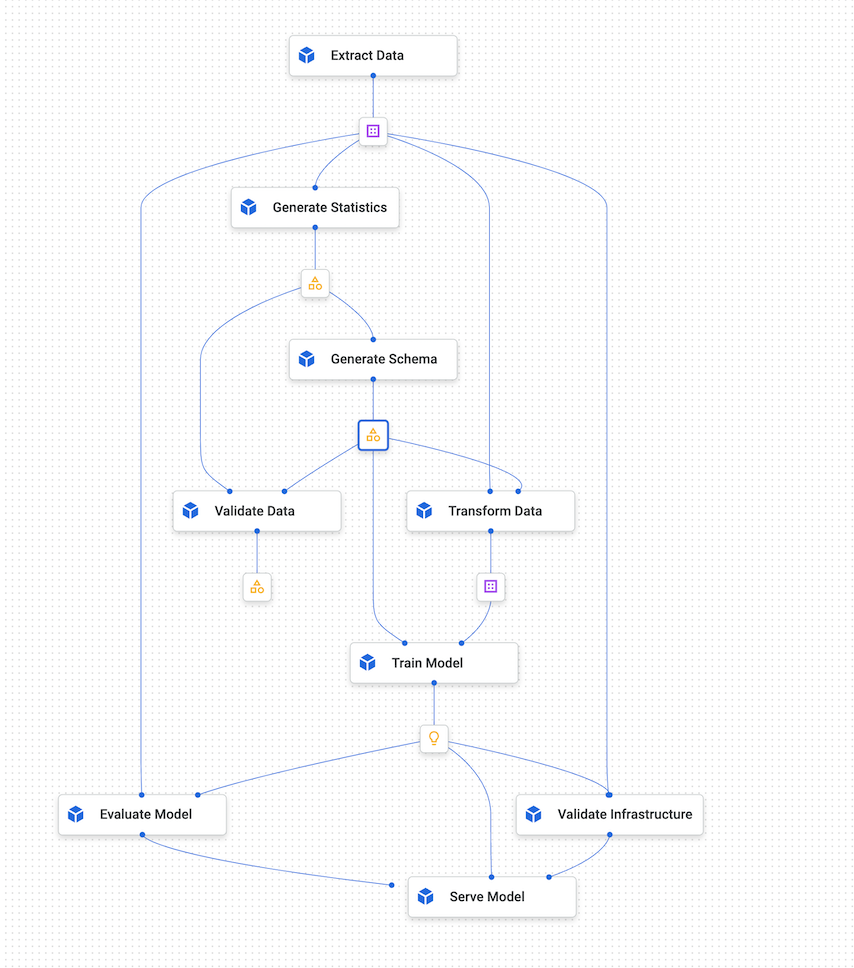
Figure 4. A sample graph of Vertex AI Pipelines.
Kubeflow Pipelines SDK
The Kubeflow Pipelines SDK lets you create components, define their orchestration, and run them as a pipeline. For details about Kubeflow Pipelines components, see Create components in the Kubeflow documentation.
You can also use the TFX Pipeline DSL and use TFX components. A TFX component encapsulates metadata capabilities. The driver supplies metadata to the executor by querying the metadata store. The publisher accepts the results of the executor and stores them in metadata. You can also implement your custom component, which has the same integration with the metadata. You can compile your TFX pipelines to a Vertex AI Pipelines compatible YAML using tfx.orchestration.experimental.KubeflowV2DagRunner. Then, you can submit the file to Vertex AI Pipelines for execution.
The following diagram shows how in Vertex AI Pipelines, a containerized task can invoke other services such as BigQuery jobs, Vertex AI (distributed) training jobs, and Dataflow jobs.

Figure 5. Vertex AI Pipelines invoking Google Cloud managed services.
Vertex AI Pipelines lets you orchestrate and automate a production ML pipeline by executing the required Google Cloud services. In figure 5, Vertex ML Metadata serves as the ML metadata store for Vertex AI Pipelines.
Pipeline components aren't limited to executing TFX-related services on Google Cloud. These components can execute any data-related and compute-related services, including Dataproc for SparkML jobs, AutoML, and other compute workloads.
Containerizing tasks in Vertex AI Pipelines has the following advantages:
- Decouples the execution environment from your code runtime.
- Provides reproducibility of the code between the development and production environment, because the things you test are the same in production.
- Isolates each component in the pipeline; each can have its own version of the runtime, different languages, and different libraries.
- Helps with composition of complex pipelines.
- Integrates with Vertex ML Metadata for traceability and reproducibility of pipeline executions and artifacts.
For a comprehensive introduction to Vertex AI Pipelines, see the list of available notebooks examples.
Triggering and scheduling Vertex AI Pipelines
When you deploy a pipeline to production, you need to automate its executions, depending on the scenarios discussed in the ML pipeline automation section.
The Vertex AI SDK lets you operate the pipeline programmatically. The google.cloud.aiplatform.PipelineJob class includes APIs to create experiments, and to deploy and run pipelines. By using the SDK, you can therefore invoke Vertex AI Pipelines from another service to achieve scheduler or event based triggers.

Figure 6. Flow diagram demonstrating multiple triggers for Vertex AI Pipelines using Pub/Sub and Cloud Run functions.
In figure 6 you can see an example on how to trigger the Vertex AI Pipelines service to execute a pipeline. The pipeline is triggered using the Vertex AI SDK from a Cloud Run function. The Cloud Run function itself is a subscriber to the Pub/Sub and is triggered based on new messages. Any service that wants to trigger the execution of the pipeline can publish on the corresponding Pub/Sub topic. The preceding example has three publishing services:
- Cloud Scheduler is publishing messages on a schedule and therefore triggering the pipeline.
- Cloud Composer is publishing messages as part of a larger workflow, like a data ingestion workflow that triggers the training pipeline after BigQuery ingests new data.
- Cloud Logging publishes a message based on logs that meet some filtering criteria. You can set up the filters to detect the arrival of new data or even skew and drift alerts generated by the Vertex AI Model Monitoring service.
Setting up CI/CD for ML on Google Cloud
Vertex AI Pipelines lets you orchestrate ML systems that involve multiple steps, including data preprocessing, model training and evaluation, and model deployment. In the data science exploration phase, Vertex AI Pipelines help with rapid experimentation of the whole system. In the production phase, Vertex AI Pipelines lets you automate the pipeline execution based on new data to train or retrain the ML model.
CI/CD architecture
The following diagram shows a high-level overview of CI/CD for ML with Vertex AI Pipelines.
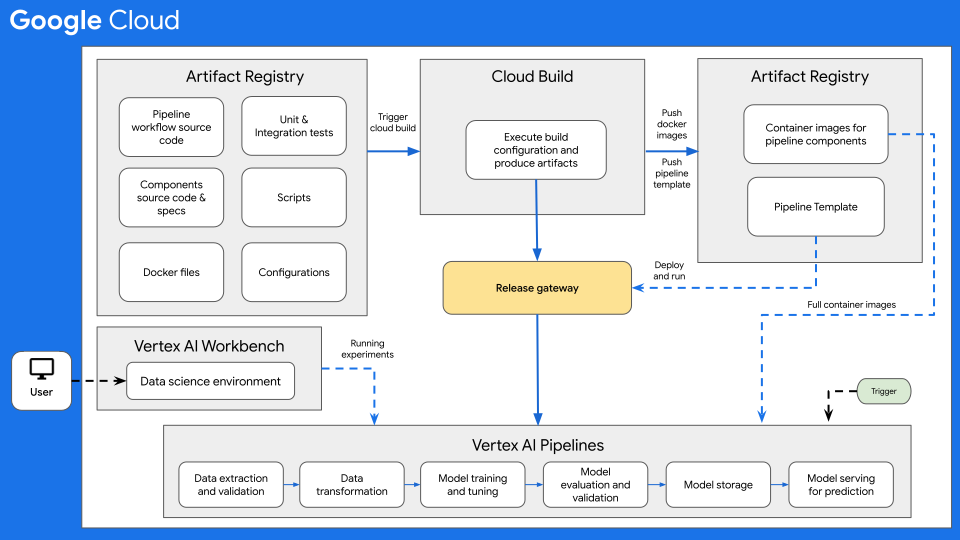
Figure 7: High-level overview of CI/CD with Vertex AI Pipelines.
At the core of this architecture is Cloud Build. Cloud Build can import source from Artifact Registry, GitHub, or Bitbucket, and then execute a build to your specifications, and produce artifacts such as Docker containers or Python tar files.
Cloud Build executes your build as a series of build steps,
defined in a
build configuration file
(cloudbuild.yaml). Each build step runs in a Docker container. You can
either
use the supported build steps
provided by Cloud Build, or
write your own build steps.
The Cloud Build process, which performs the required CI/CD for your ML system, can be executed either manually or through automated build triggers. Triggers execute your configured build steps whenever changes are pushed to the build source. You can set a build trigger to execute the build routine on changes to the source repository, or to execute the build routine only when changes match certain criteria.
In addition, you can have build routines (Cloud Build configuration files) that are executed in response to different triggers. For example, you can have build routines that are triggered when commits are made to the development branch or to the main branch.
You can use configuration variable
substitutions
to define the environment variables at build time. These substitutions are
captured from triggered builds. These variables include $COMMIT_SHA,
$REPO_NAME, $BRANCH_NAME, $TAG_NAME, and $REVISION_ID. Other
non-trigger-based variables are $PROJECT_ID and $BUILD_ID. Substitutions are
helpful for variables whose value isn't known until build time, or to reuse an
existing build request with different variable values.
CI/CD workflow use case
A source code repository typically includes the following items:
- The Python pipelines workflow source code where the pipeline workflow is defined
- The Python pipeline components source code and the corresponding component specification files for the different pipeline components such as data validation, data transformation, model training, model evaluation, and model serving.
- Dockerfiles that are required to create Docker container images, one for each pipeline component.
- Python unit and integration tests to test the methods implemented in the component and overall pipeline.
- Other scripts, including the
cloudbuild.yamlfile, test triggers and pipeline deployments. - Configuration files (for example, the
settings.yamlfile), including configurations to the pipeline input parameters. - Notebooks used for exploratory data analysis, model analysis, and interactive experimentation on models.
In the following example, a build routine is triggered when a developer pushes source code to the development branch from their data science environment.
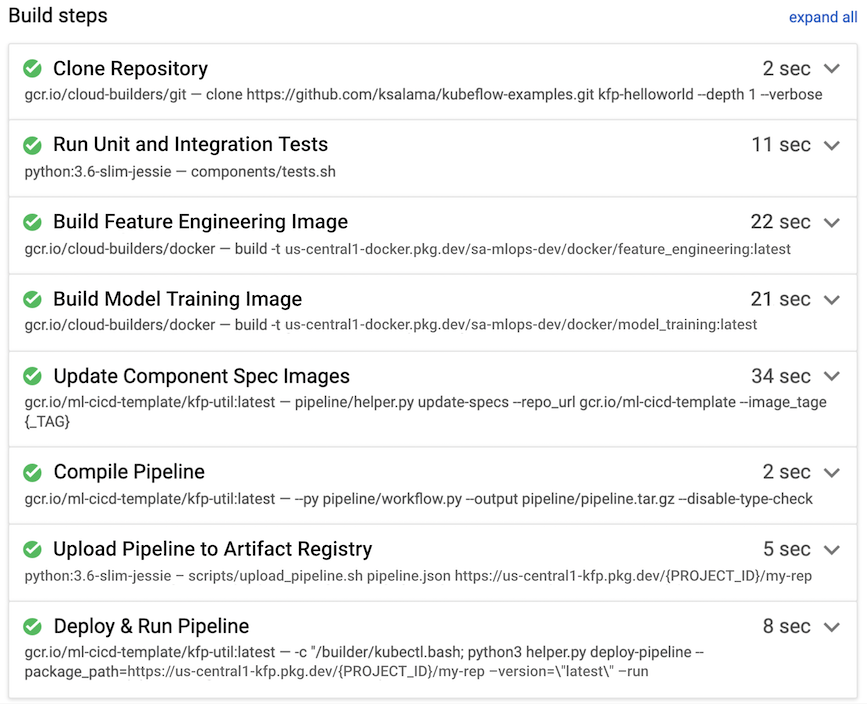
Figure 8. Example build steps performed by Cloud Build.
Cloud Build typically performs the following build steps, which are also shown in figure 7:
- The source code repository is copied to the Cloud Build
runtime environment, under the
/workspacedirectory. - Run unit and integration tests.
- Optional: Run static code analysis by using an analyzer such as Pylint.
- If the tests pass, the Docker container images are built, one for each
pipeline component. The images are tagged with the
$COMMIT_SHAparameter. - The Docker container images are uploaded to the Artifact Registry (as shown in figure 7).
- The image URL is updated in each of the
component.yamlfiles with the created and tagged Docker container images. - The pipeline workflow is compiled to produce the
pipeline.jsonfile. - The
pipeline.jsonfile is uploaded to Artifact Registry. - Optional: Run the pipeline with the parameter values as part of an integration test or production execution. The executed pipeline generates a new model and could also deploy the model as an API on Vertex AI Inference.
For a production ready end-to-end MLOps example that includes CI/CD using Cloud Build, see Vertex Pipelines End-to-end Samples on GitHub.
Additional considerations
When you set up the ML CI/CD architecture on Google Cloud, consider the following:
- For the data science environment, you can use a local machine, or a Vertex AI Workbench.
- You can configure the automated Cloud Build pipeline to skip triggers, for example, if only documentation files are edited, or if the experimentation notebooks are modified.
- You can execute the pipeline for integration and regression testing as a
build test. Before the pipeline is deployed to the target
environment, you can use the
wait()method to wait for the submitted pipeline run to complete. - As an alternative to using Cloud Build, you can use other build systems such as Jenkins. A ready-to-go deployment of Jenkins is available on Google Cloud Marketplace.
- You can configure the pipeline to deploy automatically to different environments, including development, test, and staging, based on different triggers. In addition, you can deploy to particular environments manually, such as pre-production or production, typically after getting a release approval. You can have multiple build routines for different triggers or for different target environments.
- You can use Apache Airflow, a popular orchestration and scheduling framework, for general-purpose workflows, which you can run using the fully managed Cloud Composer service.
- When you deploy a new version of the model to production, deploy it as a canary release to get an idea of how it will perform (CPU, memory, and disk usage). Before you configure the new model to serve all live traffic, you can also perform A/B testing. Configure the new model to serve 10% to 20% of the live traffic. If the new model performs better than the current one, you can configure the new model to serve all traffic. Otherwise, the serving system rolls back to the current model.
What's next
- Learn more about GitOps-style continuous delivery with Cloud Build.
- For an overview of architectural principles and recommendations that are specific to AI and ML workloads in Google Cloud, see the AI and ML perspective in the Well-Architected Framework.
- For more reference architectures, diagrams, and best practices, explore the Cloud Architecture Center.
Contributors
Authors:
- Ross Thomson | Cloud Solutions Architect
- Khalid Salama | Staff Software Engineer, Machine Learning
Other contributor: Wyatt Gorman | HPC Outbound Product Manager